Книга: Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
Назад: Три стадии жизни
Дальше: Недоразумения
Контроверзы
Поставленный вопрос – повод для полемики, даже больше того – для контроверзы. Ведущие AI-эксперты не только кардинально расходятся в своих мнениях, но даже их эмоциональные оценки грядущего диаметрально противоположны – от уверенного оптимизма до серьезной озабоченности. Среди них нет согласия даже относительно краткосрочных прогнозов об AI-экономике, последствиях для правовых отношений и новых вооружений, и эти расхождения заметно возрастают, если расширить временной горизонт и поставить вопрос о сильном искусственном интеллекте (AGI), достигающем человеческого уровня или превосходящем его и потому открывающем возможность для Жизни 3.0. Сильный искусственный интеллект решает практически любую задачу, в том числе способен к самообучению, в отличие от слабого искусственного интеллекта, вроде того что успешно играет в шахматы.
Примечательно, что контроверза относительно искусственного интеллекта имеет своим центром не один, а два разных вопроса: “когда?” и “что?”. Когда это случится (если такое вообще может случиться), и что оно может означать для человечества? На мой взгляд, можно выделить три направления, к каждому из которых следует отнестись серьезно, поскольку они представлены выдающимися мировыми мыслителями. Я изобразил эти направления на рис. 1.2, дав каждому свое наименование: цифро-утописты, техноскептики и участники движения за дружественный AI. А теперь позвольте мне дать характеристику наиболее ярким представителям из каждого лагеря.
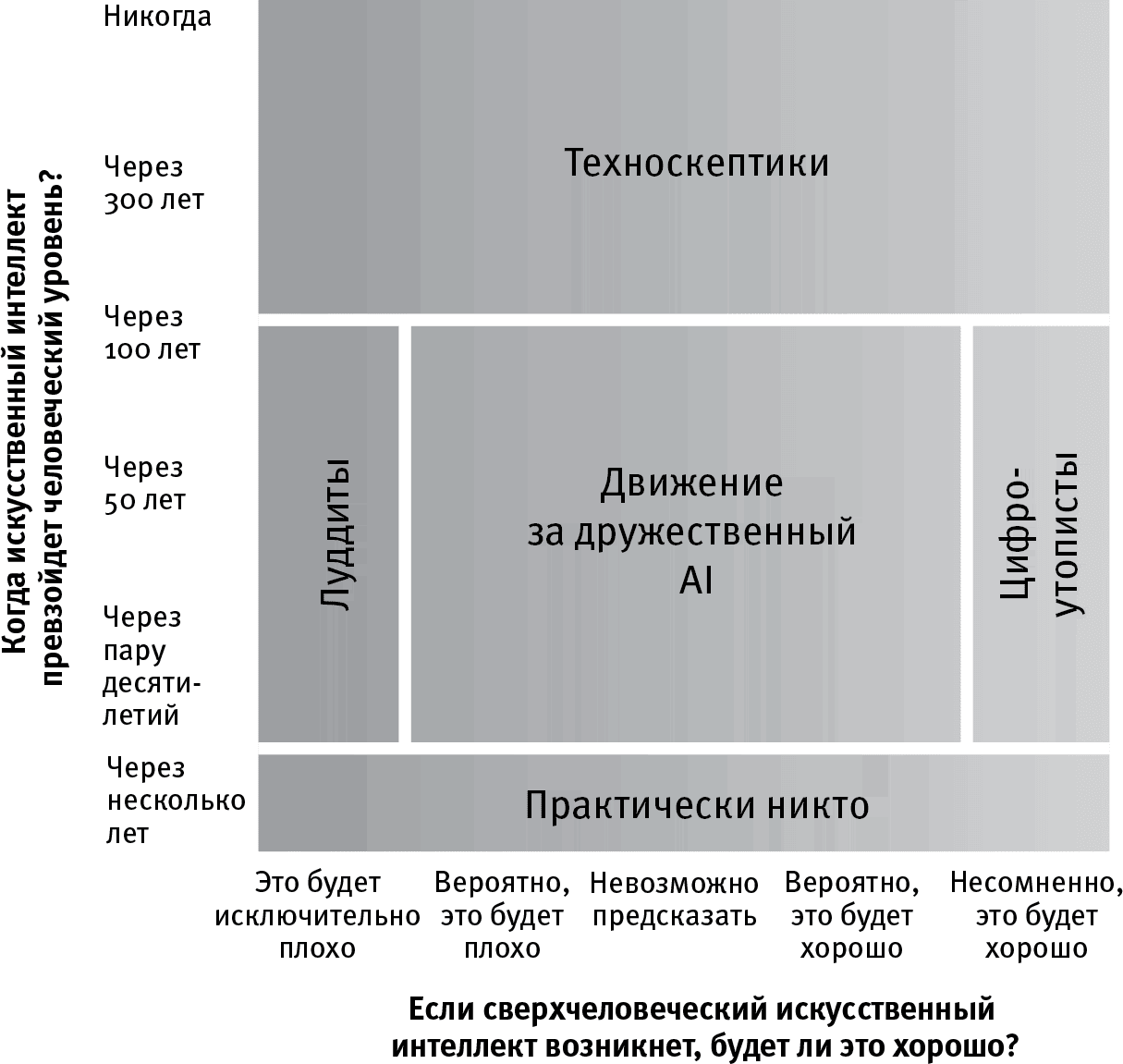
Рис. 1.2.
Большинство споров вокруг сильного искусственного интеллекта (не уступающего человеческому в любом виде деятельности) вращаются около двух вопросов: когда (если такое вообще возможно) он появится и будет ли его появление благоприятно для человечества. Техноскептики и цифро-утописты соглашаются, что поводов для беспокойства у нас нет, но по совершенно различным причинам: первые убеждены, что универсальный искусственный интеллект человеческого уровня (AGI) в обозримом будущем не появится, вторые не сомневаются в его появлении, но убеждены, что оно практически гарантированно будет благоприятно для человечества. Представители движения за дружественный AI соглашаются, что озабоченность уместна и продуктивна, потому что исследования в области AI-безопасности и публичные обсуждения связанных с ней вопросов повышают вероятность благоприятного исхода. Луддиты убеждены в скверном исходе и протестуют против искусственного интеллекта. Отчасти этот рисунок навеян публикацией: (проверена 12.05.2018).
Цифро-утописты
Ребенком я был уверен, что все миллиардеры просто сочатся помпезностью и невежеством. Когда в 2008 году в Google я впервые встретил Ларри Пейджа, он напрочь разрушил оба этих стереотипа. Впечатление подчеркнутой небрежности в одежде создавалось джинсами и ничем не примечательной майкой, словно он собрался на университетский пикник. Задумчивая манера говорить и мягкий голос, скорее, успокоили и расслабили меня, чем напугали и напрягли. 18 июля 2015 года мы снова увиделись в Напа-Вэлли на вечеринке, устроенной Илоном Маском и его тогдашней женой Талулах, и между нами немедленно завязался разговор о копрологических интересах наших детей. Я порекомендовал ему литературную классику Энди Гриффитса – The Day My Butt Went Psycho, которую он тут же себе заказал. Мне пришлось напомнить себе, что этот человек, вероятно, войдет в историю как оказавший на нее наибольшее влияние: если, как я думаю, сверхчеловеческому искусственному интеллекту суждено просочиться во все уголки нашей Вселенной еще при моей жизни, то это может случиться исключительно благодаря решениям Ларри.
С нашими женами, Люси и Мейей, мы отправились ужинать, и во время еды мы обсуждали, непременно ли машины будут обладать сознанием – идея, как он утверждал, совершенно ложная и пустая. А уже ночью, после коктейля, у них с Илоном разразился длинный и бурный спор о будущем искусственно интеллекта. Уже близился рассвет, а толпа любопытных зевак вокруг них продолжала расти. Ларри яростно защищал позицию, которую я бы отождествил с цифро-утопистами: он говорил, что цифровая жизнь – естественный и желательный новый этап космической эволюции, и если мы дадим ей свободу, не пытаясь удушить или поработить ее, то это принесет безусловную пользу всем. На мой взгляд, Ларри самый яркий и последовательный выразитель идей цифро-утопизма. Он утверждал, что если жизни суждено распространиться по всей Вселенной, в чем сам он был убежден, то произойти это может только в цифровом виде. Самую большую тревогу у него вызывала опасность, что AI-паранойя способна затормозить наступление цифровой утопии и даже спровоцировать попытку силой овладеть искусственным интеллектом в нарушение главного лозунга Google “Не твори зла!”. Илон старался вернуть Ларри на землю и без конца спрашивал его, откуда такая уверенность, что цифровая жизнь не уничтожит вокруг все то, что нам дорого. Ларри то и дело принимался обвинять Илона в “видошовинизме” – стремлении приписать более низкий статус одним формам жизни в сравнении с другими на том простом основании, что главный химический элемент в их молекулах кремний, а не углерод. Мы еще вернемся к подробному обсуждению этих важных аргументов ниже, начиная с главы 4.
Хотя в тот вечер у бассейна Ларри оказался в меньшинстве, у цифровой утопии, в защиту которой он так красноречиво выступал, немало выдающихся сторонников. Робототехник и футуролог Ганс Моравец своей книгой Mind Children 1988 года, ставшей классикой жанра, воодушевил целое поколение цифро-утопистов. Его дело было подхвачено и поднято на новую высоту Рэем Курцвейлом. Ричард Саттон, один из пионеров такой важной AI-отрасли, как машинное обучение, выступил со страстным манифестом цифро-утопистов на нашей конференции в Пуэрто-Рико, о которой я скоро расскажу.
Техноскептики
Следующая группа мыслителей тоже мало беспокоится по поводу AI, но совсем по другой причине: они думают, что создание сверхчеловечески сильного искусственного интеллекта настолько сложно технически, что никак не может произойти в ближайшие сотни лет, и беспокоиться об этом сейчас просто глупо. Я называю такую позицию техноскептицизмом, и ее предельно красноречиво сформулировал Эндрю Ын: “Бояться восстания роботов-убийц – все равно что переживать по поводу перенаселения Марса”. Эндрю был тогда ведущим специалистом в Baidu, китайском аналоге Google, и он недавно повторил этот аргумент во время нашего разговора в Бостоне. Он также сказал мне, что предчувствует потенциальный вред, исходящий от разговоров об AI-рисках, так как они могут замедлить развитие всех AI-исследований. Подобные мысли высказывает и Родни Брукс, бывший профессор MIT, стоявший за созданием роботизированного пылесоса Румба и промышленного робота Бакстера. Мне представляется любопытным тот факт, что хотя цифро-утописты и техноскептики сходятся во взглядах на исходящую от AI угрозу, они не соглашаются друг с другом почти ни в чем другом. Большинство цифро-утопистов ожидают появления сильного AI (AGI) в период от двадцати до ста лет, что, по мнению техноскептиков, – ни на чем не основанные пустые фантазии, которые они, как и все предсказания технологической сингулярности, называют “бреднями гиков”. Когда я в декабре 2014 года встретил Родни Брукса на вечеринке, посвященной дню его рождения, он сказал мне, что на 100 % убежден, что ничего такого не может случиться при моей жизни. “Ты уверен, что имел в виду не 99 %?” – спросил я его потом в электронном письме. “Никаких 99 %. 100 %. Этого просто не случится, и все”.
Движение за дружественный AI
Впервые встретив Стюарта Рассела в парижском кафе в июне 2014 года, я подумал: “Вот настоящий британский джентльмен!”. Выражающийся ясно и обдуманно, с мягким красивым голосом, с авантюрным блеском в глазах, он показался мне современной инкарнацией Филеаса Фогга, любимого мною в детстве героя классического романа Жюля Верна Вокруг света за 80 дней. Хотя он один из самых известных среди ныне живущих исследователей искусственного интеллекта, соавтор одного из главных учебников на этот счет, его теплота и скромность позволили мне чувствовать себя легко во время беседы. Он рассказал, как прогресс в исследованиях искусственного интеллекта привел его к убеждению, что появление AGI человеческого уровня уже в этом столетии – вполне реальная возможность, и хотя он с надеждой смотрит на будущее, благополучный исход не гарантирован. Есть несколько ключевых вопросов, на которые мы должны ответить в первую очередь, и они так сложны, что исследовать их нужно начинать прямо сейчас, иначе ко времени, когда понадобится ответ, мы можем оказаться не готовы его дать.
Сегодня взгляды Стюарта в той или иной степени разделяет большинство, и немало групп по всему миру занимаются вопросами AI-безопасности, как он и призывал. Но так было не всегда. В статье Washington Post 2015 год назван годом AI-безопасности. А до тех пор рассуждения о рисках, связанных с разработками искусственного интеллекта, вызывали раздражение у большинства исследователей, относившихся к ним как к призывам современных луддитов воспрепятствовать прогрессу в этой области. Как мы увидим в главе 5, опасения, подобные высказанным Стюартом, были достаточно отчетливо артикулированы еще более полувека назад разработчиком первых компьютеров Аланом Тьюрингом и математиком Ирвингом Гудом, который работал с Тьюрингом над взломом германских шифров в годы Второй мировой войны. В прошлом десятилетии такие исследования велись лишь горсткой мыслителей, не занимавшихся созданием AI профессионально, среди них, например, Элиезер Юдковски, Майкл Вассар и Ник Бострём. Их работа мало влияла на исследователей AI-мейнстрима, которые были полностью поглощены своими ежедневными задачами по улучшению “умственных способностей” разрабатываемых ими систем и не задумывались о далеких последствиях своего возможного успеха. Среди них я знал и таких, кто испытывал определенные опасения, но не рисковал говорить о них публично, дабы не навлечь на себя обвинений коллег в алармизме и технофобии.
Я чувствовал, что такая поляризация мнений не навсегда и что исследовательское сообщество должно рано или поздно примкнуть к обсуждению вопроса, как сделать AI дружественным. К счастью, я был не одинок. Весной 2014 года я основал некоммерческую организацию под названием “Институт будущего жизни” (Future of Life Institute, или, сокращенно, FLI; ), в чем мне помогали моя жена Мейя, мой друг физик Энтони Агирре, аспирантка Гарварда Виктория Краковна и создатель Skype Яан Таллин. Наша цель проста: чтобы у жизни было будущее и чтобы оно было, насколько это возможно, прекрасно! В частности, мы понимали, что развитие технологий дает жизни небывалые возможности, она может теперь либо процветать, как никогда ранее, либо уничтожить себя, и мы бы предпочли первое.
Наша первая встреча состоялась у нас дома 15 марта 2014 года и приняла характер мозгового штурма. В ней участвовало около 30 студентов и профессоров MIT, а также несколько мыслителей, живущих по соседству с Бостоном. Мы все пришли к согласию в том, что, хотя необходимо уделять некоторое внимание биотехнологии, ядерному оружию и климатическим изменениям, наша главная цель – сделать вопрос AI-безопасности центральным в данной исследовательской области. Мой коллега по MIT физик Фрэнк Вильчек, получивший Нобелевскую премию за то, что разобрался, как работают кварки, предложил нам для начала выступить с авторской колонкой в каком-нибудь популярном СМИ, чтобы привлечь к проблеме внимание и усложнить жизнь тем, кто хотел бы ее проигнорировать. Я связался со Стюартом Расселом (с которым тогда еще не был знаком) и со Стивеном Хокингом, еще одним моим коллегой-физиком, и они оба согласились присоединиться к нам с Фрэнком в качестве соавторов этой колонки. Что бы ни говорили об этом позже, но тогда New York Times отказалась публиковать нашу колонку, а за ней многие другие американские газеты, так что в итоге мы разместили ее в моем блоге на Huffington Post. Сама Арианна Хаффингтон, к моей радости, откликнулась письмом в электронной почте: “Я в восторге от поста! Мы поместим его #1!”, и это размещение нашей заметки в самой верхней позиции главной страницы вызвало лавину публикаций о AI-безопасности, заняв первые полосы многих изданий до конца года, с участием Илона Маска, Билла Гейтса и других знаковых фигур современных технологий. Книга Ника Бострёма Superintelligence, вышедшая той же осенью, подлила масла в огонь и еще больше подогрела публичную дискуссию.
Следующим шагом нашей кампании за дружественный AI, проводимой под эгидой Института, стала организация большой конференции при участии всех ведущих специалистов по искусственному интеллекту с целью разобраться во всех недоразумениях, достичь принципиального согласия и составить конструктивный план на будущее. Мы хорошо понимали, что убедить столь блистательную публику собраться на конференцию, организуемую неизвестными им аутсайдерами, будет не просто, и поэтому старались изо всех сил: мы запретили доступ на нее любым СМИ, тщательно выбрали место и время – январь месяц и пуэрто-риканский пляж, сделали бесплатным участие (нам позволила это щедрость Яана Таллина), мы придумали для нее наименее тревожное название, на какое только были способны: “Будущее AI: возможности и опасности”. Но самое главное – мы скооперировались со Стюартом Расселом и благодаря ему сумели пригласить в организационный комитет нескольких ведущих специалистов по искусственному интеллекту как из университетской среды, так и от бизнеса. В их числе был Демис Хассабис из лаборатории DeepMind, который как раз только что показал, что искусственный интеллект может обыграть человека даже в такую игру, как го. И чем больше я узнавал Демиса, тем больше понимал, что среди его амбициозных целей не только увеличение мощности искусственного интеллекта, но и достижение его дружественности.
Результатом стала невероятная встреча замечательных умов (см. рис. 1.3). К специалистам по искусственному интеллекту присоединились лучшие экономисты, юристы, лидеры технологии (включая Илона Маска) и иные мыслители (в том числе Вернор Виндж, придумавший термин “сингулярность”, вокруг которого все будет построено в главе 4). В конце концов все сложилось лучше, чем в наших самых смелых мечтах. Вероятно, все дело в удачном сочетании вина и солнца, а может быть, просто правильно было выбрано время: несмотря на полемическую повестку конференции, возник замечательный консенсус, изложенный в итоговом письме, , которое подписали более восьми тысяч человек, включая тех, без чьих имен не обойдется ни один справочник. Смысл письма заключался в том, что цель разработок искусственного интеллекта следует переопределить: создаваемый интеллект не должен быть неконтролируемым, он должен быть дружественным. В письме формулировался подробный список исследовательских задач, вокруг которых участники конференции соглашались концентрировать свою работу. Дружественный AI начинал превращаться в мейнстрим. Мы проследим за его прогрессом в этой книге.

Рис. 1.3.
На конференцию в Пуэрто-Рико в январе 2015 года собралась замечательная группа исследователей различных аспектов искусственного интеллекта и смежных вопросов. В заднем ряду слева направо: Том Митчел, Шон О’х Эйгертейг, Хью Прайс, Шамиль Чандариа, Яан Таллин, Стюарт Рассел, Билл Хиббард, Блез Агуэра-и-Аркас, Андерс Зандберг, Дэниел Дьюи, Стюарт Армстронг, Льюк Мюльхойзер, Том Диттерих, Майкл Озборн, Джеймс Манийка, Аджай Агравал, Ричард Маллах, Ненси Чан, Мэтью Путман; Стоящие ближе, слева направо: Мэрилин Томпсон, Рич Саттон, Алекс Виснер-Гросс, Сэм Теллер, Тоби Орд, Йоша Бах, Катья Грейс, Адриан Веллер, Хизер Рофф-Перкинс, Дилип Джордж, Шейн Легг, Демис Хассабис, Вендель Валлах, Чарина Чой, Илья Суцкевер, Кент Уокер, Сесилия Тилли, Ник Бострём, Эрик Бриньоулфссон, Стив Кроссан, Мустафа Сулейман, Скотт Феникс, Нил Джейкобстейн, Мюррей Шанахан, Робин Хэнсон, Франческа Росси, Нейт Соареш, Илон Маск, Эндрю Макафи, Барт Зельман, Микеле Рэйли, Аарон Ван-Девендер, Макс Тегмарк, Маргарет Боден, Джошуа Грин, Пол Кристиано, Элиезер Юдковски, Дэвид Паркес, Лоран Орсо, Дж. Б. Шробель, Джеймс Мур, Шон Легассик, Мейсон Хартман, Хоуи Лемпель, Дэвид Владек, Джейкоб Стейнхардт, Майкл Вассар, Райан Кало, Сьюзан Янг, Оувейн Эванс, Рива-Мелисса Тец, Янош Крамар, Джофф Андерс, Вернор Виндж, Энтони Агирре; Сидят: Сэм Харрис, Томазо Поджо, Марин Сольячич, Виктория Краковна, Мейя Чита-Тегмарк. За камерой – Энтони Агирре (им также выполнена обработка фотографии в Фотошопе при содействии сидящего рядом искусственного интеллекта человеческого уровня).
В ходе конференции мы получили еще один урок: успех в создании искусственного интеллекта не просто будоражит мысль, он ставит серьезные вопросы, имеющие огромное моральное значение – от ответов на них зависит будущее всего живого, всей жизни. В прошлом моральная значимость принимаемых людьми решений могла быть очень велика, но она всегда оставалось ограниченной: человечество оправилось от самых жутких эпидемий, и даже величайшие империи в конце концов развалились. Прошлые поколения могли быть уверены, что наступит завтра и придут новые люди, пережившие обычные беды нашего мира: бедность, болезни, войны. И на конференции в Пуэрто-Рико были такие, кто говорил, что сейчас настало другое время: впервые, говорили они, мы можем построить достаточно мощную технологию, которая способна навсегда избавить мир от этих бед – или от самого человечества. Мы можем создать общества, которые будут процветать, как никогда ранее, на Земле и, возможно, не только, а можем создать кафкианское, за всеми следящее государство, от которого уже никогда не удастся избавиться.

Рис. 1.4.
Хотя СМИ часто изображают дело так, словно Илон Маск на ножах с AI-сообществом, на самом деле существует практически единодушное согласие по поводу необходимости исследований в области безопасности искусственного интеллекта. Здесь на фотографии 4 января 2015 года президент Ассоциации за развитие искусственного интеллекта Том Диттерих делится радостью со стоящим рядом Илоном Маском, который только что объявил о своем намерении финансировать новую программу исследований по AI-безопасности. У них из-за спин выглядывают сооснователи Института будущего жизни (FLI) Мейя Чита-Тегмарк и Виктория Краковна.
Назад: Три стадии жизни
Дальше: Недоразумения

