28. Ускоренное обучение SR-инженеров для работы на дежурствах и не только
Автор — Эндрю Уиддоусан.
Под редакцией Шилайи Нукалы
Как я могу прицепить реактивный ранец на своих новичков и при этом держать в курсе более опытных SR-инженеров?
Вы наняли новых SR-инженеров, что теперь?
Вы наняли новых служащих для своей организации, и они начинают свой путь как SR-инженеры. Теперь вам нужно научить их выполнять свою работу. Инвестирование в образование новых SR-инженеров поможет им стать отличными инженерами. Обучение улучшит их профессиональные навыки, сделает их более целостными и сбалансированными.
Успешные команды SR-инженеров строятся на доверии — для того чтобы поддерживать сервис в стабильном состоянии, вам нужно верить, что ваши коллеги по дежурству знают, как работает ваша система, могут диагностировать ее атипичное поведение, не стесняются попросить помощи и способны реагировать в стрессовых ситуациях, чтобы спасти ситуацию. Очень важно, хоть этого и недостаточно, рассматривать обучение SR-инженеров с точки зрения «Что должен знать новичок для того, чтобы начать работать на дежурстве». Учитывая требования к доверию, вам также нужно задать следующие вопросы.
• Как имеющиеся дежурные инженеры могут оценить готовность новичка к работе на дежурстве?
• Как мы можем воспользоваться энтузиазмом и любопытством наших новичков, чтобы принести пользу для SRE?
• Как я могу внести свой вклад в обучение новых сотрудников?
Различные люди предпочитают разные методики обучения. Естественно, в вашей команде будут абсолютно разные люди и пользоваться только одной методикой недальновидно. Таким образом, не существует методики, которая лучше всего подойдет для обучения новых SR-инженеров, и определенно ни одна магическая формула не сработает для всех подряд команд SR-инженеров. В табл. 28.1 перечислены рекомендованные методы обучения (и соответствующие антиметоды), которые хорошо известны SR-инженерам компании Google. Эти приемы представляют собой широкий диапазон возможностей, доступных для того, чтобы качественно обучить вашу команду основным концепциям SRE как в текущий момент, так и на постоянной основе.
Таблица 28.1. Приемы обучения SR-инженеров
| Рекомендованные методы | Нежелательные методы |
| Разработка конкретных последовательных упражнений для учеников | Поручение ученикам низкоквалифицированной работы (например, с оповещениями или тикетами) для их обучения; боевые крещения |
| Стимулирование к обратному проектированию (реверс-инжинирингу), статистическому анализу и изучению основных принципов | Обучение с помощью операционных процедур, чек-листов и сценариев |
| Мотивация к анализу сбоев путем чтения студентами постмортемов | Отношение к сбоям как к секретной информации, которая должна быть погребена, чтобы можно было избежать ответственности |
| Создание локализованных, но реалистичных сбоев для учеников, чтобы они осваивали системы мониторинга и инструменты | Предоставление возможности что-то исправить только после того, как ученик начал работать на дежурстве |
| Имитация в группе катастроф для объединения подходов команды к решению проблем | Создание в команде экспертов, чьи знания и приемы относятся к разным категориям |
| Периодический допуск учеников к дежурствам в качестве практикантов (теневое дежурство) и сравнение их заметок с заметками дежурного инженера | Назначение ученика основным дежурным инженером при отсутствии у него полного понимания работы сервиса |
| Объединение учеников с инженерами-экспертами для повторения определенных разделов плана обучения инженеров | Рассмотрение планов обучения работе на дежурстве как неизменных и неприкосновенных для всех, кроме экспертов |
| Обособление нестандартной работы над проектом для выполнения учениками с предоставлением им возможности частично вступить во владение стеком технологий | Предоставление всей работы над новым проектом самым опытным сотрудникам; поручение новичкам лишь мелкой работы |
В остальной части этой главы приведены основные подходы, которые мы считаем эффективными при ускоренном обучении SR-инженеров для работы на дежурствах и не только. Эти методы можно представить в виде схемы самообучения SR-инженеров (рис. 28.1).
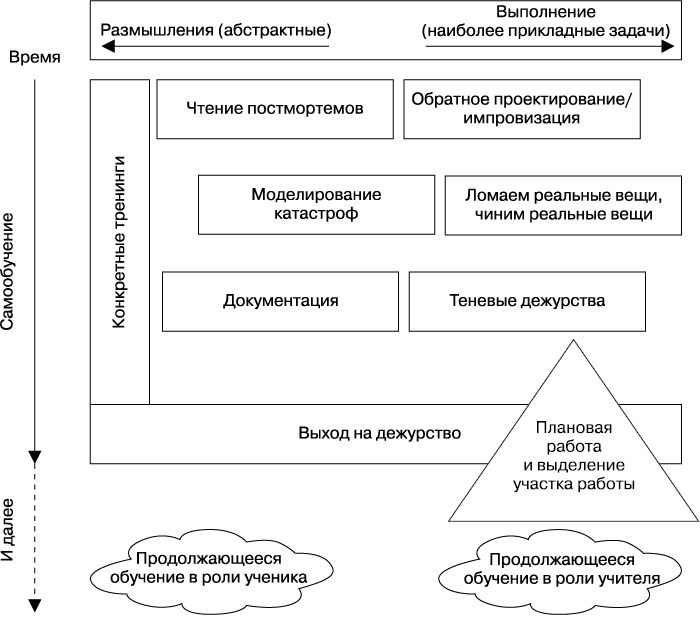
Рис. 28.1. План по выходу на самообучение SR-инженера для работы на дежурствах и не только
На этом рисунке показаны лучшие приемы, которые команды SR-инженеров могут выбрать для того, чтобы помочь выйти на самообучение своих новых сотрудников. Из множества представленных здесь инструментов вы можете выбрать те, которые наилучшим образом подходят вашей команде.
На этом рисунке показаны две оси.
• Горизонтальная ось представляет диапазон разных видов работы, который ранжируется от абстрактных до прикладных процессов.
• Вертикальная ось представляет время. Поначалу новые SR-инженеры почти не владеют информацией о системах и сервисах, за которые они будут нести ответственность, поэтому изучение отчетов о происшествиях (постмортемов), в которых детально описано, как эти системы давали сбой, станут отличным отправным пунктом. Новые SR-инженеры также могут выполнить обратное проектирование этих систем с самых основ, поскольку они сами начинают с нуля. Как только они станут лучше понимать эти системы и перейдут к выполнению конкретных операций, они будут готовы выходить на теневые дежурства и начать исправлять неполную или устаревшую документацию.
Ниже даны советы по интерпретации этого рисунка.
• Участие в дежурствах — это важный этап в карьере нового SR-инженера, после чего обучение становится менее прозрачным, неопределенным и самоуправляемым — именно поэтому вы видите пунктирные линии вокруг действий, которые становятся доступны после того, как SR-инженер начинает дежурить.
• Треугольная форма работы над проектами и выделения участка работы указывает на то, что работа над проектом начинается с малого и со временем увеличивается, становясь более сложной, и, скорее всего, продолжается и после дежурства.
• Одни из этих действий и практик очень абстрактные/пассивные, а другие — прикладные/активные. Некоторые действия являются комбинацией обоих типов. Желательно использовать разнообразные методы обучения.
• Для максимального эффекта практическая деятельность в процессе обучения должна подчиняться соответствующим правилам: одни операции можно выполнить сразу, другие должны происходить сразу после того, как SR-инженер официально начинает дежурить, а третьи необходимо выполнять на постоянной основе даже опытным SR-инженерам. Конкретные тренинги необходимо продолжать проводить на протяжении всего времени от вступления инженера в должность и вплоть до начала его работы на дежурствах.
Первый тренинг: структурировать хаос
Как говорится в этой книге, команды SR-инженеров совмещают проактивную и реактивную работу. Перед каждой командой SR-инженеров должна стоять цель ограничивать и снижать количество реактивной работы путем увеличения проактивности, и подход, с помощью которого вы нанимаете новичков, не должен стать исключением. Рассмотрим следующий очень распространенный, но, к сожалению, неоптимальный процесс найма.
Джон — новый член команды SR-инженеров, обслуживающих сервис FooServer. Более опытные SR-инженеры делают большое количество грязной работы — отвечают на тикеты, обрабатывают оповещения и выполняют утомительные отправки бинарных файлов. В первый день работы Джону поручают отслеживать все входящие тикеты. Ему говорят, что он может попросить любого члена команды SR-инженеров предоставить ему информацию, необходимую для расшифровки тикета. «Конечно, поначалу тебе придется нелегко, — говорит Джону менеджер, — но в конце концов ты начнешь разбираться с этими тикетами гораздо быстрее. Когда-нибудь ты узнаешь все об используемых нами инструментах и поддерживаемых системах». Опытный инженер комментирует: «А сейчас мы бросим тебя в самое глубокое место озера».
Этот метод «боевого крещения» для ориентирования новичков зачастую инициирован самими членами команды. Управляемые операционной работой реактивные команды SR-инженеров «тренируют» своих новичков, заставляя их… реагировать! Раз за разом. Однако существует вероятность, что такая стратегия охладит пыл некоторых способных инженеров. Несмотря на то что такой подход может в итоге привести к созданию хороших операционистов, его результаты будут неудовлетворительны. Описанный подход также предполагает, что многие (или даже большинство) сложности, с которыми сталкивается команда, могут быть изучены в процессе работы, а не рассуждений. Если какой-то работе, с которой сталкивается человек, занимающийся тикетами, можно обучиться, выполняя простые упражнения, то она не относится к обязанностям SR-инженера.
У новичков в службе SRE возникают следующие вопросы.
• Над чем я работаю?
• Какого прогресса я добиваюсь?
• Когда эти действия позволят мне получить достаточно опыта, чтобы я мог начать дежурить?
Если человек только окончил университет или сменил место работы, изменив при этом служебную роль (с традиционного разработчика ПО или системного администратора) на таинственную роль SR-инженера, то этого зачастую достаточно, чтобы пошатнуть его самоуверенность. Для более замкнутых личностей (особенно в отношении второго и третьего вопросов) неопределенность, вызываемая запутанными или непрозрачными ответами, может привести к замедлению обучения или проблемам с запоминанием. Вместо этого рассмотрим подходы, описанные в следующих разделах. Эти предложения настолько же конкретны, насколько может быть конкретным любой тикет или оповещение, но они также последовательны и поэтому более полезны.
Кумулятивные и методичные пути обучения
Постарайтесь как-то упорядочить систему обучения, чтобы ваши новые SR-инженеры понимали, куда они движутся. Любой вид обучения подойдет лучше применения случайных тикетов и прерываний, но вам придется немного потрудиться, чтобы правильно преподнести теорию и практику. Абстрактные концепции, которые появятся несколько раз на протяжении обучения новичка, должны быть описаны заранее. Кроме того, ученики должны получить опыт из первых рук настолько быстро, насколько это возможно на практике.
Для изучения вашей платформы и подсистем требуется начальная точка. Задумайтесь о том, что будет лучше — групповые тренировки с использованием сходных задач или обычный порядок выполнения. Например, если ваша команда отвечает за действующий в реальном времени обслуживающий стек, который работает с пользователями, рассмотрим следующий порядок обучения.
1. Как запрос входит в систему. Основные принципы работы с сетями и дата-центрами, балансировка нагрузки на фронтенде, прокси и т.д.
2. Обслуживание фронтенда. Фронтенды приложений, журналирование запросов, целевые показатели уровня обслуживания и т.д.
3. Сервисы среднего уровня. Кэши, балансировка нагрузки на бэкенде.
4. Инфраструктура. Бэкенды, инфраструктура и вычислительные ресурсы.
5. Объединяем все вместе. Приемы отладки, процедуры эскалации и сценарии для неотложных ситуаций.
Только от вас и от SR-инженеров, помогающих вам структурировать, разрабатывать и подавать курс обучения, зависит то, как вы будете предоставлять возможности для обучения (неформальные беседы, сухая теория или практические упражнения). Команда SR-инженеров, работающая с системой поиска, структурировала процесс обучения с помощью документа, который называется «чек-лист обучения работе на дежурстве». Упрощенный раздел этого чек-листа может выглядеть так.
| Сервер агрегации результатов (Mixer) | |
| Фронтенд: сервер фронтенда. Вызываемые бэкенды: сервер получения результатов, сервер геолокации, база данных персонализации. SRE-эксперты: Салли У., Дэйв К., Джен П. Контакты разработчиков: Джим Т., results-team@ | Изучите перед тем, как двигаться дальше: на каких кластерах развернут сервер; как откатить релиз сервера; какие бэкенды считаются «лежащими на критическом пути» и почему |
| Прочтите и проанализируйте следующие документы: обзор агрегированных результатов: раздел «Выполнение запросов»; обзор агрегированных результатов: раздел «Производство»; план: как развернуть новый сервер агрегации результатов; анализ производительности сервера | Вопросы для самопроверки: Как меняется расписание релизов, если на привычный для релиза день выпадает праздник компании? Как вы можете обнаружить плохую отправку набора данных, связанного с геолокацией? |
Обратите внимание на то, что в этом разделе никак не закодированы процедуры, этапы диагностики или сценарии. Вместо этого он представляет собой относительно устойчивое описание, сконцентрированное непосредственно на перечислении контактов экспертов, подчеркивании наиболее полезной документации, указании того, какие базовые знания вы должны собрать и усвоить, а также задании наводящих вопросов, на которые можно ответить только после получения базовых знаний. В нем также показаны конкретные результаты, чтобы ученик знал, какого рода знания и навыки он получит после завершения этого раздела чек-листа.
Всем заинтересованным сторонам нужно понять, сколько информации запомнит обучаемый. Несмотря на то что такой механизм обратной связи не обязательно должен быть формальным (например, иметь форму теста), лучше всего добавить домашние задания, где будут задаваться вопросы о том, как работает ваш сервис. Удовлетворительные ответы, проверенные ментором, являются признаком того, что обучение можно переводить на следующий уровень. Вопросы, связанные с внутренней кухней вашего сервиса, могут звучать так.
• Какие бэкенды этого сервера считаются «лежащими на критическом пути» и почему?
• Какие части этого сервера должны быть упрощены или автоматизированы?
• Как вы думаете, где находится первое узкое место этой архитектуры? Если бы вам нужно было устранить это узкое место, как бы вы это сделали?
В зависимости от того, как сконфигурированы права доступа для вашего сервиса, вы также можете реализовать многоуровневую модель доступа. Первый уровень доступа даст вашим ученикам лишь возможность рассмотреть внутреннее устройство ваших компонентов в режиме «только чтение», а более высокие уровни позволят им изменять состояние производственной системы. Удовлетворительное выполнение сценариев чек-листа, предназначенного для обучения работе на дежурстве, позволит вашему ученику получить более обстоятельный доступ к системе. Команда SR-инженеров, работающая над сервисом Google Search, называет эти уровни бонусами на пути к дежурствам, поскольку ученики в конечном счете получают высшие уровни доступа к системе.
Целевая, а не черновая работа над проектом
SR-инженеры решают проблемы, дайте же им решить серьезную проблему! На первых порах даже незначительное чувство ответственности за сервис, которым управляет команда, может творить чудеса при обучении. Кроме того, чувство вовлеченности позволит наладить доверительные отношения с более опытными инженерами, поскольку они будут учить своих младших товарищей управлению новыми компонентами или процессами. В компании Google стараются сразу поручить каждому инженеру определенный участок работы: все SR-специалисты получают стартовый проект. В результате новые сотрудники максимально быстро знакомятся с инфраструктурой и как можно раньше начинают вносить небольшой, но полезный вклад в общее дело. Поскольку SR-инженер параллельно обучается и работает над проектом, это позволяет ему быстрее понять функциональное назначение сервиса, чего не произошло бы, если бы он тратил время только на работу или только на обучение. Рассмотрим несколько неплохих схем работы.
• Создание небольшого изменения функциональности, заметного пользователям, в обслуживающем стеке, и последовательное сопровождение релиза этой функциональности вплоть до его промышленной эксплуатации. Понимание набора инструментов разработки и процесса релиза бинарного файла способствует развитию эмпатии среди разработчиков.
• Добавление функциональности для наблюдения за сервисом там, где в данный момент есть «белые пятна». Новичкам придется аргументировать логику наблюдения, согласовав их понимание системы с тем, как она себя (неправильно) ведет на самом деле.
• Автоматизация проблемных мест, которые были недостаточно проблемны для того, чтобы их автоматизировали ранее. Это позволит новому инженеру оценить работу службы SRE, связанную с избавлением от рутины, возникающей при выполнении повседневных операций.
Подготовка выдающихся реверс-инженеров, умеющих импровизировать
Мы можем дать рекомендации, как обучать новых SR-инженеров, но чему мы должны их обучать? Учебный материал будет зависеть от технологий, которые используются для выполнения задачи, но более важный вопрос заключается в следующем: какого рода инженеров мы пытаемся подготовить? Поскольку SR-инженеры работают над проектами разного масштаба и разной сложности, они не могут себе позволить быть сконцентрированными только на операционной работе, быть традиционными системными администраторами. В дополнение к тому, что они имеют склад ума, необходимый для решения крупномасштабных задач, SR-инженеры должны иметь следующие характерные особенности.
• По мере выполнения своих задач они столкнутся с системами, которых никогда не видели, поэтому они должны знать, как выполнять обратное проектирование.
• При работе в больших масштабах будут появляться аномалии, которые трудно обнаружить, поэтому SR-инженерам нужна способность мыслить статистически, а не процедурно, чтобы решать такие задачи.
• Когда стандартные процедуры решения задач не работают, они должны уметь импровизировать.
Подробнее рассмотрим эти характеристики, чтобы понять, как можно дать нашим SR-инженерам требуемые знания и навыки.
Обратное проектирование: узнаем, как работают системы
Инженерам интересно узнать, как работают системы, которых они никогда не видели ранее — или, если быть точнее, как работают текущие версии систем, с которыми они взаимодействовали ранее. Имея базовое понимание того, как работают системы компании, а также подробно изучая процесс отладки, RPC-процедуры и журналы бинарных файлов, SR-инженеры начинают лучше справляться с неожиданными проблемами в системах с неизвестной архитектурой. Обучите своих инженеров основам диагностики и отладки ваших приложений и позвольте им практиковаться в выводе заключений на основе поверхностных данных, чтобы такое поведение вошло в привычку при работе с будущими сбоями.
Статистика и сравнение: последователи научного метода под давлением
Можно рассматривать подход SR-инженеров к реагированию на инциденты в крупномасштабных системах как перемещение по массивному дереву решений. За короткое время, которое выделяется на реагирование, SR-инженеры могут предпринять лишь несколько действий из доступного множества, ставя перед собой цель справиться со сбоем либо в краткосрочной, либо в долгосрочной перспективе. Поскольку времени зачастую мало, SR-инженеры должны эффективно отсечь лишние ветви этого дерева решений. Способность сделать это частично приходит с опытом, который нарабатывается со временем при работе с производственными системами. Параллельно нужно учиться осторожно выдвигать гипотезы, которые по мере их доказательства или неподтверждения еще больше сузят пространство решений.
Говоря другими словами, отслеживание сбоев системы зачастую похоже на игру «Какой предмет не похож на другие?», где в роли «предметов» выступают версии ядра, архитектура ЦП, бинарные версии вашего стека, региональная структура трафика или сотни других факторов. С точки зрения архитектуры команда отвечает за то, чтобы все эти факторы можно было проконтролировать, индивидуально проанализировать и сравнить. Однако мы также должны обучать наших новых SR-инженеров так, чтобы они стали хорошими аналитиками с самого начала их работы.
Импровизация: когда случается неожиданное
Вы пробуете применить свое решение для того, чтобы исправить сбой, но оно не работает. Найти разработчиков системы, выдавшей сбой, не представляется возможным. Что делать? Импровизировать! Изучите принципы работы нескольких инструментов, которые могут хотя бы частично решить вашу проблему, — это позволит вам попрактиковаться в применении глубокой защиты при создании ваших собственных вариантов поведения для решения подобных проблем. Строгое следование процедурам во время сбоя и, как результат, игнорирование аналитических способностей, может серьезно усложнить поиск основной причины. Ситуация, когда процесс поиска ошибок приостанавливается, может еще больше ухудшиться, если SR-инженер делает слишком много непроверенных предположений о причине сбоя. Это ценный урок, который SR-инженеры должны усвоить как можно раньше.
Какой курс обучения и практические занятия мы можем предложить новым SR-инженерам для того, чтобы направить их по верному пути, учитывая эти три важные характеристики? Вам нужно продумать собственное информационное наполнение учебного курса с учетом всех описанных особенностей в дополнение к другим требованиям, характерным для вашей культуры SRE. Рассмотрим один урок, который, по нашему мнению, учитывает все указанные ранее моменты.
Связываем все воедино: обратное проектирование сервиса, находящегося в промышленной эксплуатации
Когда пришло время изучить (часть стека технологий сервиса Google Maps), (новый SR-инженер) спросила, может ли она вместо пассивного прослушивания лекций сделать это самостоятельно — изучить все с помощью методик обратного проектирования, а остальные потом подскажут ей, что она пропустила. Каков был результат? Ее знания оказались более уместными и полезными, чем они могли бы быть после прослушивания моей лекции, а я обслуживал эту часть сервиса более пяти лет!
Пол Кован, SR-инженер компании Google
Один из первых уроков для новичков должен быть на тему обратного проектирования сервиса, находящегося в промышленной эксплуатации (без помощи его владельцев). Поставленная задача на первый взгляд кажется простой. Все сотрудники сервиса Google News: SR-инженеры, программные инженеры, менеджеры и т.д. — уехали в круиз по Бермудскому треугольнику. Мы ничего не слышали о них уже 30 дней, как и наши ученики, определенные в команду Google News. Новичкам нужно понять, как работает стек сервиса от начала до конца, чтобы управлять им и поддерживать его работу.
Получив эту задачу, ученики выполняют интерактивные упражнения, где отслеживают путь, который проходит запрос браузера через нашу инфраструктуру. На каждом этапе мы делаем акцент на том, что очень важно разобрать несколько способов исследования взаимодействия между производственными серверами, чтобы соединение не было потеряно. В середине урока мы даем ученикам задание найти другую конечную точку для входящего трафика, показывая, что наше изначальное предположение было слишком узким. Далее мы предлагаем им найти другие пути через стек. Мы используем производственные бинарные файлы, которые самостоятельно сообщают о своей подключаемости к RPC, а также доступные нам системы мониторинга методом черного и белого ящика, позволяющие определить направление запросов пользователей. В процессе выполнения этого задания мы строим схему системы и рассматриваем ее компоненты — общую инфраструктуру, которую наши ученики, скорее всего, еще встретят в работе.
В конце урока ученики получают еще одно задание. Каждый ученик возвращается в свою команду и просит более опытного коллегу помочь ему выбрать стек или участок стека, который он будет обслуживать, находясь на дежурстве. Используя навыки, полученные в ходе урока, ученик самостоятельно создает схему этого стека и показывает ее более опытным инженерам. Он наверняка пропустит несколько незначительных деталей, и это послужит основой для обсуждения. При этом опытный инженер в процессе урока и сам узнает что-то новое, пополнив свои знания о постоянно изменяющейся системе. Из-за быстрого изменения производственных систем важно, чтобы ваша команда приветствовала любую возможность повторно ознакомиться с системой.
Пять приемов для вдохновления дежурных работников
Работа на дежурстве — не единственная важная обязанность любого SR-инженера, но производственная разработка обычно подразумевает какое-то количество срочных уведомлений. Человек, способный ответственно отнестись к работе на дежурстве, должен хорошо понимать, как функционирует система. Поэтому мы используем термин «способный работать на дежурстве» как синоним выражения «имеет достаточное количество знаний и может разобраться в том, чего он не знает».
Охотники за сбоями: чтение отчетов о происшествиях и обмен ими
Тот, кто не помнит историю, обречен ее повторять.
Джордж Сантаяна, философ и эссеист
Отчеты о происшествиях, или постмортемы (см. главу 15), являются важной частью непрерывного улучшения. Они представляют собой безобвинительный способ найти основную причину существенного и видимого пользователю сбоя. При написании такого отчета имейте в виду, что больше всего он пригодится инженеру, который еще даже не нанят. Без радикального переписывания вы можете внести небольшие правки в свои отчеты, чтобы сделать их «обучающими».
Но и самые лучшие отчеты могут оказаться бесполезными, если они прозябают на дне виртуальной базы данных. Из этого следует, что ваша команда должна собирать и курировать особо ценные отчеты для того, чтобы сделать их ресурсами для обучения новичков. Некоторые отчеты созданы по стандартному сценарию, но «обучающие постмортемы», способные поведать о структурных дефектах или новых сбоях крупномасштабных систем, ценятся учениками на вес золота.
Отчеты не принадлежат только их авторам. Этим гордятся многие команды, пережившие и задокументировавшие свои самые крупные сбои. Собирайте свои лучшие отчеты и делайте их доступными для новичков, а также для заинтересованных людей из интегрированных команд. В свою очередь, попросите членов этих команд опубликовать свои самые лучшие постмортемы в тех случаях, когда вы можете получить к ним доступ.
Одни команды SR-инженеров в нашей компании создали «Клуб читателей постмортемов», где можно найти восхитительные и поучительные отчеты, а после прочтения — обсудить их. Авторы отчетов могут стать почетными гостями таких заседаний. Другие команды организуют собрания на тему «Сказки о неудачах», где авторы отчетов присутствуют полуформально, пересказывая сбой и, по сути, управляя дискуссией.
Регулярные чтения отчетов и обсуждение сбоев, включая условия запуска и способы миграции, творят чудеса при построении ментальной карты новых SR-инженеров и упрощают понимание производственной среды и поиск ответов на дежурствах. Постмортемы также прекрасно подходят в качестве основы для создания абстрактных сценариев будущих сбоев.
Катастрофа: ролевая игра
Раз в неделю мы проводим собрание. Мы выбираем жертву, которой вручается сценарий — зачастую реальный сценарий, взятый из анналов истории компании Google. Жертва, которая напоминает мне участника телешоу, говорит ведущему, что бы она сделала/запросила для того, чтобы понять или решить проблему, а ведущий рассказывает жертве, что случится в результате каждого действия. Это похоже на Zork для SR-инженеров. Вы находитесь в лабиринте запутанных консолей наблюдения, все они похожи друг на друга. Вы должны спасти невинных пользователей от попадания в пропасть Избыточной Задержки Обработки Запроса, спасти дата-центры от Практически Гарантированного Краха и спасти нас всех от позора, связанного с Некорректным Отображением Дудлов.
Роберт Кеннеди, бывший SR-инженер для сервиса Google Search и healthcare.gov6 (см. Life in the Trenches of healthcare.gov)
Когда у вас имеется группа SR-инженеров, навыки которых значительно различаются, что вы можете сделать для того, чтобы объединить их и позволить им учиться друг у друга? Как вы описываете культуру SRE и основные свойства вашей команды новичку? Как извещаете опытных сотрудников о новых изменениях и функциональности вашего стека? Команды Google SRE справляются с этими трудностями, придерживаясь проверенной временем традиции: регулярно разыгрывая катастрофы. Это упражнение еще часто называется «Колесом неудачи» или «Проходом по доске».
В идеале, если эти упражнения станут еженедельным ритуалом, каждый член группы узнает что-то новое. Схема проста и несколько напоминает настольную ролевую игру: гейм-мастер (game master, GM) выбирает двух участников команды как основного и вспомогательного дежурных работников. Эти два инженера во главе с гейм-мастером составляют команду. Объявляется о поступающем запросе, и команда рассказывает, что бы они сделали для того, чтобы сгладить последствия и изучить сбой.
Гейм-мастер тщательно готовит сценарий мероприятия. Он может быть основан на существовавшем ранее сбое, во время которого новые SR-инженеры еще не работали в компании, а старые инженеры могли его забыть. Или, возможно, сценарий — это анализ гипотетической ошибки в новой или готовой к запуску функциональности стека, что делает всех членов группы одинаково неготовыми к ситуации. Или, что еще лучше, коллеги могут найти новый сбой в производственной системе.
На протяжении следующих 30–60 минут основной и вспомогательный дежурные пытаются найти главную причину проблемы. GM с радостью предоставляет дополнительный контекст по мере рассмотрения проблемы, возможно информируя участников (и публику) о том, как выглядят графы на информационной панели системы мониторинга во время сбоя. Если инцидент требует участия другой команды, GM выступает в роли ее участника для проигрывания сценария. Ни один виртуальный сценарий не будет идеальным, поэтому GM может вернуть участников к теме, уводя их в сторону от ложных умозаключений, внося ясность с помощью дополнительных вводных или задавая неожиданные и острые вопросы.
Если ваша катастрофическая ролевая игра пройдет успешно, каждый чему-то научится: возможно, познакомится с новым инструментом или приемом, узнает о существовании другого взгляда на решение проблемы или (особенно доставляет удовольствие новым членам команды) осознает, что смог решить проблему этой недели, если его выбрали в качестве участника. При удачном раскладе это упражнение вдохновит участников команды с нетерпением ждать очередной ролевой игры и даже стать гейм-мастером.
Ломаем и чиним по-настоящему
Новичок может узнать о работе SRE, читая документацию, постмортемы или тренируясь. Разыгрывание катастроф поможет вовлечь его в эту игру. Однако опыт, полученный от исправления реальных производственных систем, поможет ему еще больше. Этого опыта у него будет предостаточно, как только он начнет работать на дежурстве, но подобное обучение должно начаться еще до того, как SR-инженер начнет дежурить. Поэтому предоставьте такой опыт как можно раньше, чтобы развить у ученика рефлексное реагирование, что позволит ему автоматически выбирать нужные инструменты и системы мониторинга компании для решения возникающих проблем.
В таких случаях важно, чтобы все выглядело максимально реалистично. В идеале ваша команда имеет стек технологий, расположенный в нескольких дата-центрах и снабжаемый таким образом, что у вас есть как минимум один экземпляр, от которого вы можете отвести реальный трафик и временно использовать его для обучения. Или же вы можете иметь небольшой тестовый экземпляр в вашем стеке, который можно одолжить на короткое время. Если это возможно, сымитируйте нагрузку, которая напоминает реальный пользовательский/клиентский трафик, а также потребление ресурсов.
Существует множество возможностей для обучения на реальных производственных системах, куда подается сымитированная нагрузка. Опытные SR-инженеры в такой системе сталкиваются с множеством проблем: неверной конфигурацией, утечками памяти, уменьшением производительности, аварийными запросами, нехваткой памяти в хранилищах и т.д. В этой реалистичной, но относительно свободной от риска среде наблюдатели могут управлять набором задач так, чтобы изменить поведение стека, заставив новых SR-инженеров искать различия, определять факторы, способствовавшие случившемуся, и в итоге восстанавливать системы, возвращая их к нормальному поведению.
Вместо того чтобы просить опытного SR-инженера тщательно спланировать определенный тип сбоя, который новички должны будут восстановить, можно двигаться в противоположном направлении: провести упражнение, которое потребует участия всей команды. Например, продолжая работу в хорошо знакомой конфигурации, можно незначительно повредить стек в выбранных узких местах. При этом необходимо наблюдать за работой сервиса до и после поломки с помощью системы мониторинга. Это упражнение любят SR-инженеры, работающие над системой Google Search. Их версия называется «Давайте сожжем поисковой кластер дотла!»
Упражнение выполняется так.
1. В группе мы обсуждаем, какие наблюдаемые характеристики производительности могут измениться, если мы навредим стеку.
2. Перед тем как вывести из строя систему, мы опрашиваем участников, узнавая их мнения и обоснования прогнозов реакции системы.
3. Мы проверяем предположения и обосновываем варианты поведения, которые наблюдаем.
Это упражнение нужно выполнять ежеквартально — оно позволяет избавиться от новых багов, которые периодически появляются в системе.
Документация как обучение
Многие команды SR-инженеров ведут чек-листы обучения работе на дежурстве — в них содержится структурированная информация и полный список технологий и концепций, связанных с поддерживаемыми системами. Все ученики должны ознакомиться с этим списком перед тем, как работать на теневых дежурствах. Уделите минуту и еще раз взгляните на чек-лист обучения работе на дежурстве, приведенный в табл. 28.1. Этот чек-лист служит различным целям для разных людей.
• Для учеников:
• изучение этого списка поможет понять, какие системы важны и почему. Когда ученики поймут это, они смогут перейти к изучению других тем вместо того, чтобы вникать в несущественные детали, которые можно разобрать и позже;
• документ помогает установить границы системы, которую поддерживает их команда.
• Для менторов и менеджеров: прогресс ученика, изучающего чек-лист, можно отследить. Чек-лист отвечает на следующие вопросы:
• над каким разделами вы работали сегодня;
• какие разделы оказались наиболее трудными.
• Для всех членов команды: документ становится социальным контрактом, с помощью которого (усвоив нужные навыки) ученик вступает в ряды дежурных работников. Этот чек-лист является своего рода стандартом, который должны поддерживать все члены команды.
В быстро изменяющихся средах документация может быстро устаревать. Устаревшая документация — это не такая большая проблема для опытных SR-инженеров, которые уже давно вникли во все тонкости системы. Новые специалисты гораздо больше нуждаются в актуальной документации, но они не всегда готовы вносить в нее изменения. При качественном структурировании документация для работы на дежурстве может стать адаптируемым справочником, в котором объединены как энтузиазм новичков, так и знания опытных инженеров, что позволяет сохранять его актуальность.
В команде, отвечающей за работу сервиса Google Search, мы встречаем новых членов команды, предварительно просмотрев чек-лист и отсортировав его разделы по степени актуальности. По мере обучения новых сотрудников мы даем им задание переписать один или два наиболее устаревших раздела. В чек-листе в каждом разделе указаны контакты опытных SR-инженеров и разработчиков, специализирующихся на той или иной технологии. Мы рекомендуем ученикам связаться с ними, чтобы подробнее разобраться в каждом процессе. Далее, когда они лучше знакомятся с содержимым и стилем чек-листа, они должны переписать определенный раздел, который затем рассматривают один или несколько SR-инженеров, указанных в качестве экспертов.
Периодически проводите теневые дежурства
И все же никакие гипотетические упражнения или другие методы обучения не помогут на 100 % подготовить SR-инженера к работе на дежурстве. В конечном счете работа с реальными сбоями всегда полезнее с точки зрения процесса обучения. Однако несправедливо заставлять новичков ожидать своего первого оповещения, чтобы начать реальное обучение.
Когда новичок изучит все основы системы (например, завершив анализ чек-листа для работы на дежурстве), постарайтесь сконфигурировать вашу систему оповещения так, чтобы она копировала все поступающие вызовы для новичка, поначалу только в рабочее время. Такие теневые дежурства — отличная возможность для ментора взглянуть на прогресс ученика и отличная возможность для ученика получить представление о работе на дежурстве. После того как новичок какое-то время поработает в тени нескольких членов команды, уверенность команды в том, что этот человек готов к дежурствам, будет только расти. Внушение уверенности таким способом — эффективный метод построить доверительные отношения.
Когда поступает очередное экстренное уведомление, новый SR-инженер не становится ответственным за него, и это позволяет ему спокойнее работать. Теперь он основной наблюдатель, но он наблюдает развитие сбоя, а не его итоговый результат. Вполне возможно, что ученик и основной инженер, находящийся на дежурстве, проводят общую сессию работы в консоли или сидят рядом и делятся своими замечаниями. В удобное для всех время после сбоя дежурный работник может подробно рассмотреть все действия, которые он выполнил. Это упражнение позволит дежурному работнику, находящемуся в тени, лучше понять то, что на самом деле произошло.

Если произойдет сбой, для которого стоит написать постмортем, дежурный работник должен позволить новичку внести в него свою лепту. Но не оставляйте бумажную работу исключительно ученику, поскольку он может (неверно) усвоить, что написание подобных отчетов — грязная работа, которую следует поручать менее опытным сотрудникам.
Некоторые команды также делают финальный шаг: опытный дежурный работник какое-то время находится в тени ученика. Новичок становится основным дежурным инженером и работает со всеми оповещениями, но опытный работник остается в тени, самостоятельно диагностируя ситуацию, ничего не меняя. Опытный SR-инженер всегда сможет поддержать, помочь, подтвердить правильность действий и при необходимости дать совет.
На дежурстве и не только: обряд перехода и практика постоянного обучения
По мере увеличения знаний ученик достигнет точки в карьере, когда сможет комфортно работать с большей частью стека и импровизировать в непонятных ситуациях. К этому моменту он сможет работать на дежурствах. Некоторые команды проводят финальный экзамен для своих учеников перед тем, как наделить их правами и обязанностями дежурного работника. Новые SR-инженеры должны продемонстрировать, что они усвоили чек-лист, чтобы подтвердить свою готовность. Независимо от того, как вы пройдете этот рубеж, выход на дежурство — своеобразный обряд перехода, который должна отпраздновать вся команда.
Прекращается ли обучение, когда ученик начинает работать на дежурстве? Конечно, нет! Для того чтобы оставаться бдительными SR-инженерами, сотрудники вашей команды всегда должны быть активными и учитывать возможные изменения. Если вы будете отвлекаться на другие участки, части вашего стека могут измениться и расшириться, что приведет к устареванию знаний вашей команды.
Проводите регулярные курсы для всей команды, где обзоры новых и грядущих изменений вашего стека будут предоставлены в качестве презентаций от SR-инженеров, наблюдающих за этими изменениями, возможно, вместе с разработчиками. Если можете, запишите эти презентации, чтобы создать обучающую библиотеку для будущих учеников.
Существуют и другие пути для вовлечения в процесс обучения: рассмотрите возможность проведения семинаров, где SR-инженеры будут беседовать с коллегами-разработчиками. Чем лучше ваши коллеги-разработчики понимают вашу работу и трудности, с которыми вы сталкиваетесь, тем проще им будет принимать обоснованные решения для будущих проектов.
Итоги главы
Стартовые инвестиции в обучение SR-инженеров абсолютно стоят того — это нужно как ученикам, которые стремятся получить представление о производственной среде, так и командам, которые будут рады принять новичков в ряды дежурных работников. С помощью приемов, описанных в этой главе, вы быстрее подготовите всесторонне развитых SR-инженеров, постоянно улучшая при этом навыки команды. Только от вас зависит, как именно вы будете применять эти приемы, но задача ясна: как SR-инженер, вы должны «масштабировать» своих людей быстрее, чем вы масштабируете машины. Удачи вам и вашим командам в создании культуры обучения!
И не работает!
Примеры проактивной работы SR-инженеров: автоматизация ПО, консультирование по вопросам проектирования и координация запусков.
Примеры реактивной работы SR-инженеров: отладка, поиск проблем и обработка срочных ситуаций на дежурстве.
Дань видеоиграм недавнего прошлого.
Такой подход («следуй за RPC») также хорошо работает для систем пакетной обработки/конвейерных систем. Он начинается с операции, которая запускает систему. Для систем пакетной обработки этой операцией может быть появление данных, которые нужно обработать, транзакция, которую нужно подтвердить, или одно из множества других событий.
Например: «Вы получаете сообщение на пейджер от другой команды, в котором содержится более подробная информация. Вот что они говорят…»
Например: «Мы стремительно теряем деньги! Как вы собираетесь быстро решить эту проблему?»

