10. Оповещения на основании данных временных рядов
Автор — Джейми Уилкинсон
Под редакцией Кавиты Джулиани
Пусть запросы идут, а ваш пейджер молчит.
Традиционное благословение SR-инженеров
Мониторинг, находящийся на нижнем уровне иерархии потребностей производства, критически важен для стабильной работы вашего сервиса. Благодаря мониторингу владельцы могут принимать рациональные решения о влиянии изменений на сервис, грамотно реагировать на критические ситуации и, конечно же, обосновывать необходимость самого сервиса: измерять и оценивать, насколько он соответствует бизнес-целям (см. главу 6).
Независимо от того, обслуживается сервис SR-инженерами или нет, он должен поддерживать возможность мониторинга.
Мониторинг очень крупной системы может быть трудно обеспечить по нескольким причинам:
• огромное количество компонентов, которые необходимо анализировать;
• необходимость ограничивать нагрузку на инженеров, ответственных за систему.
Системы мониторинга компании Google не просто измеряют простые показатели вроде средней задержки отклика незагруженного европейского веб-сервера. Мы также должны понимать распределение величины этой задержки среди всех серверов в данном регионе. Это знание позволит нам определить, какие факторы влияют на задержку.
Учитывая масштабы наших систем, совершенно неприемлемо проектировать их так, чтобы оповещения приходили обо всех сбоях на всех машинах. Такие данные больше похожи на «шум», и на них трудно отреагировать. Мы стараемся создавать приложения, устойчивые к сбоям систем, от которых они зависят. Вместо того чтобы требовать управления множеством индивидуальных компонентов, крупная система должна собирать сигналы и отсекать ненужные значения. Нам требуются системы мониторинга, которые позволят отправлять оповещения о самых важных показателях сервиса, но при этом сохранять уровень детализации для того, чтобы при необходимости исследовать отдельные компоненты.
Системы мониторинга компании Google развивались на протяжении десяти лет, пройдя путь от традиционных моделей пользовательских сценариев, которые снимают показания и рассылают нам оповещения, до нового подхода. В этом современном подходе сбор временных рядов стал основным процессом новой системы мониторинга, а сценарии были заменены мощным языком для преобразования временных рядов в графики и оповещения.
Укрепление позиций Borgmon
Практически сразу после того, как в 2003 году была создана инфраструктура по планированию задач Borg [Verma, 2015], в качестве ее дополнения была спроектирована новая система мониторинга — Borgmon.
| Мониторинг с помощью временных рядов за пределами Google В этой главе описывается архитектура и программный интерфейс инструмента мониторинга, который является основополагающим для развития и надежности компании Google на протяжении почти десяти лет… Но как это поможет вам, наш дорогой читатель? Не так давно в сфере мониторинга произошел Кембрийский взрыв: появились системы Riemann, Heka, Bosun и Prometheus1. Это инструменты с открытым исходным кодом, которые очень похожи на систему оповещения Borgmon, основанную на временных рядах. В частности, Prometheus очень похожа на Borgmon, особенно если сравнивать два языка их правил. Принципы сбора переменных и вычисления правил остаются одинаковыми для всех этих программ. Сами программы предоставляют рабочую среду, где вы можете экспериментировать, и, я надеюсь, она поможет вам реализовать идеи, которые появятся после прочтения этой главы. |
Вместо того чтобы выполнять предоставленные пользователями сценарии для обнаружения сбоев системы, Borgmon полагается на общепринятый формат представления данных. Это позволяет организовать масштабный сбор данных, не затрачивая слишком много ресурсов, и обойтись без выполнения подпроцессов и настройки сетевого соединения. Мы называем это мониторингом методом белого ящика (в главе 6 мы сравнивали виды мониторинга методами белого и черного ящика).
Данные применяются как для построения графиков и диаграмм, так и для генерирования оповещений; это делается на основе простой арифметической обработки. Поскольку сбором данных занимается уже не «короткоживущий» процесс, все накопленные данные могут быть использованы и для расчета в целях генерирования оповещений.
Эти особенности помогают «поддерживать простоту», как описано в главе 6. Они дают возможность ограничивать связанную с обслуживанием системы нагрузку на сотрудников, работающих с сервисами, чтобы им легче было реагировать на постоянные изменения, происходящие в системе по мере ее роста.
Чтобы способствовать такому масштабному сбору данных, необходимо стандартизировать формат представления показателей. Более старый метод экспорта внутренних состояний (известный как varz) был формализован, чтобы у нас появилась возможность собирать все показатели для каждого конкретного объекта с помощью единственного запроса HTTP. Например, для того, чтобы вручную запросить показатели страницы, вы можете использовать следующую команду:
% curl
37
errors_total 12
Программа Borgmon способна получать данные от других систем Borgmon, поэтому мы можем строить иерархии, соответствующие топологии сервиса, собирая, обобщая и «прореживая» информацию на каждом уровне согласно общей стратегии. Обычно команда запускает один экземпляр системы Borgmon для каждого кластера, а также несколько экземпляров на глобальном уровне. Очень крупные сервисы разбиваются ниже уровня кластера на множество экземпляров-скраперов, которые, в свою очередь, наполняют данными экземпляр, работающий на уровне кластера.
Инструментарий для приложений
Обработчик HTTP /varz просто возвращает экспортируемые переменные в виде списка в текстовом формате, в виде разделенных пробелами ключей и значений, по одной паре в каждой строке. В дальнейшем была введена связанная (mapped) переменная, что позволило экспортирующей стороне определить несколько меток для имени переменной, а затем экспортировать таблицу значений или диаграмму. Пример переменной вида «ключ — значение» приведен ниже. Здесь мы видим 25 ответов HTTP 200 и 12 ответов HTTP 500:
map:code 200:25 404:0 500:12
Добавление показателя в программу требует всего одного объявления в том коде, где этот показатель нужен.
При взгляде назад становится очевидно, что такой текстовый интерфейс без заданной схемы значительно облегчает добавление нового инструментария, и это хорошо как для разработчиков, так и для команд SRE. Однако такой компромисс сказывается на ежедневном обслуживании. Отделение определения переменной от места, где она используется в правилах Borgmon, требует тщательного контроля за изменениями. На практике такой компромисс допустим, поскольку, помимо прочего, были созданы инструменты для проверки корректности правил и их генерирования.
| Экспорт переменных Компания Google глубоко пустила корни в Интернете: каждый из крупных языков, использованных в ней, имеет реализацию интерфейса экспортируемых переменных, который автоматически регистрирует HTTP-сервер, по умолчанию встроенный в каждый исполняемый файл Google2. Экземпляры экспортируемых переменных позволяют автору сервера выполнять очевидные операции вроде сложения значений, установки ключа для определенных значений и т.д. Библиотека expvar, написанная на языке Go3, и ее выходные данные в формате JSON представляют собой вариант такого API. |
Сбор экспортированных данных
Для поиска объектов экземпляр сервиса Borgmon настраивается согласно списку этих целей с использованием одного из методов разрешения имен. Список объектов зачастую является динамическим, поэтому такой подход с поиском сервисов снижает затраты на его обслуживание и позволяет выполнять мониторинг.
В заранее заданных интервалах Borgmon получает URI /varz для каждого объекта, декодирует результаты и сохраняет значения в памяти. Программа Borgmon также расширяет коллекцию для каждого экземпляра в списке объектов на весь интервал, поэтому коллекция для каждого из объектов не соответствует строго своим «коллегам».
Программа Borgmon также записывает «синтетические» переменные для каждой цели, чтобы определить:
• было ли разрешено имя для хоста и порта;
• ответил ли объект-цель на запрос о сборе данных;
• ответил ли объект-цель на проверку работоспособности;
• в какое время завершился сбор данных.
Эти «синтетические» переменные позволяют легко создавать правила для проверки доступности наблюдаемых задач.
Инструмент varz существенно отличается от SNMP (Simple Networking Monitoring Protocol — простой сетевой протокол мониторинга), который «разработан… для того, чтобы соответствовать минимальным требованиям к передаче данных и продолжать работать, когда другие сетевые приложения дают сбой» [Microsoft, 2003]. Использование HTTP для скраппинга противоречит этому принципу, однако опыт показывает, что это редко становится проблемой. Система сама по себе разработана таким образом, чтобы быть устойчивой к сбоям сети и машины, и Borgmon позволяет инженерам писать более умные правила оповещения, используя в качестве сигналов даже сами сбои при сборе данных.
Память временных рядов как хранилище данных
Сервисы обычно состоят из множества исполняемых файлов, запущенных как множество задач на множестве машин множества кластеров. Система Borgmon должна организованно хранить все эти данные, позволяя при этом гибко их запрашивать и делать их срезы.
Borgmon хранит все данные в базе, которая расположена в памяти и регулярно сохраняется на жесткий диск. Точки на графике записываются в формате (временная_метка, значение) и хранятся в отсортированных в хронологическом порядке списках, которые называются временными рядами. Каждый из них обозначается уникальным набором меток, имеющих вид имя=значение.
Как показано на рис. 10.1, временной ряд представляет собой одномерную матрицу чисел, растущую с течением времени. По мере того как вы делаете во временном ряду перестановки, матрица становится многомерной.
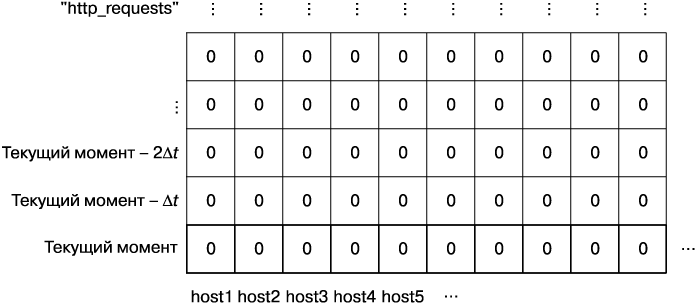
Рис. 10.1. Временной ряд для ошибок, имеющий метки исходных хостов, с которых они были получены
На практике структура представляет собой блок памяти фиксированного размера, именуемый также памятью временных рядов. У этого блока есть сборщик мусора, удаляющий самые старые записи, когда память заполняется. Интервал между самой свежей и самой старой записями называется временным горизонтом и показывает, сколько данных, готовых к запросам, хранится в оперативной памяти. Как правило, дата-центр и глобальный экземпляр Borgmon имеют размер, позволяющий хранить данные примерно за 12 часов для визуализирующих консолей и данные за гораздо меньший промежуток времени, если речь идет о сборщиках данных низшего уровня. Для хранения данных об одной точке на графике требуется примерно 24 байта, поэтому мы можем вместить миллион уникальных временных рядов для каждой минуты из 12 часов в объем памяти, чуть меньший чем 17 Гбайт RAM.
Периодически состояние внутренней памяти сохраняется во внешнюю систему, известную как Time-Series Database (TSDB, база данных временных рядов). Программа Borgmon может запрашивать у TSDB старые данные и, хотя эта база работает медленнее, она дешевле и более емкая, чем RAM Borgmon.
Метки и векторы
Как показано в примере на рис. 10.2, временные ряды сохраняются как последовательности чисел и временных меток, которые называются векторами. Как и векторы в линейной алгебре, эти векторы являются срезами и поперечными сечениями многомерной матрицы точек вне памяти временных рядов. В принципе, вы можете проигнорировать временные метки, поскольку значения добавляются в вектор с заданной периодичностью — например, каждую секунду, десять секунд или минуту.

Рис. 10.2. Пример временного ряда
Этот временной называется набором меток (labelset), поскольку он реализован как набор меток, представляющих собой пары ключ=значение. Одна из этих меток содержит само имя переменной, а соответствующий ключ появляется на странице varz.
Некоторые имена меток объявлены как важные. Для того чтобы можно было идентифицировать конкретный ряд в базе данных, он должен иметь как минимум следующие метки:
• var (переменная) — имя переменной;
• job (задача) — имя, заданное для типа наблюдаемого сервера;
• service (сервис) — в свободной форме определенная коллекция задач, которые обеспечивают сервис для пользователей, как внешних, так и внутренних;
• zone (зона) — принятая в Google абстракция, которая ссылается на местоположение (обычно это дата-центр) экземпляра Borgmon, выполняющего сбор данных для указанной переменной.
Объединение этих переменных дает что-то подобное приведенному ниже. Это называют переменным выражением:
{var=}
Запрос к временному ряду не включает указание всех этих меток, а поиск для набора меток возвращает все соответствующие ряды вектора. Поэтому мы можем вернуть вектор результатов, удалив метку instance из предыдущего запроса, если в кластере запущено больше одного экземпляра системы. Например, запрос:
{var=}
может вернуть в качестве результата пять рядов вектора с наиболее свежими значениями временных рядов:
{var=} 10
{var=} 9
{var=} 11
{var=} 0
{var=} 10
Источниками добавления меток во временной ряд могут служить:
• имя цели, например задание и экземпляр;
• сама цель, например переменные вида «ключ — значение»;
• конфигурация Borgmon, например примечание о местоположении или смене меток;
• модификация (перерасчет) правил Borgmon.
Мы также можем запросить временной ряд по времени, указав в выражении переменных требуемую продолжительность:
{var=)
Такой запрос вернет хронологию соответствующих выражению временных рядов за последние 10 минут. Если мы собираем точки на графике раз в минуту, то ожидаем получить десять точек за десятиминутное окно. Результат будет выглядеть примерно так:
{var=, ...} 0 1 2 3 4 5 6 7 8 9 10
{var=, ...} 0 1 2 3 4 4 5 6 7 8 9
{var=, ...} 0 1 2 3 5 6 7 8 9 9 11
{var=, ...} 0 0 0 0 0 0 0 0 0 0 0
{var=, ...} 0 1 2 3 4 5 6 7 8 9 10
Вычисление правил
Система Borgmon, по сути, представляет собой программируемый калькулятор с небольшим количеством «синтаксического сахара», который позволяет ему генерировать оповещения. Проанализировав уже описанные компоненты для сбора данных и их хранения, можно сделать вывод, что этот программируемый калькулятор подходит нам в качестве системы мониторинга :).

Централизованное вычисление правил в системе мониторинга вместо делегирования этой функции отделившимся подпроцессам означает, что вычисления могут быть запущены параллельно для многих похожих целей. Такая практика позволяет поддерживать относительно небольшой размер конфигурации (например, благодаря удалению повторяющегося кода), которая станет более функциональной благодаря своей выразительности.
Программы Borgmon, называемые также правилами Borgmon, состоят из простых алгебраических выражений, которые позволяют вычислить одни временные ряды на основании других. Эти правила могут быть довольно эффективными, поскольку дают возможность запросить хронологию одного временного ряда (например, временную ось), разные подмножества меток для нескольких временных рядов одновременно (например, пространственную ось) и выполнять многие математические операции.
Правила, если это возможно, работают параллельно в пуле потоков, но могут потребовать упорядочения, если вы используете в качестве входных данных правила, вычисляемые ранее. Размер векторов, возвращаемых с помощью запросов, также определяет общее время применения правила. Поэтому типична ситуация, когда в Borgmon добавляется контроль вычислительных ресурсов в ответ на то, что задача выполняется слишком медленно. При необходимости проведения более детального анализа внутренние показатели во время действия правил экспортируются для исследования производительности и для мониторинга самой системы мониторинга.
Агрегирование — это краеугольный камень вычисления правил в распределенной среде. Агрегирование требует объединения нескольких временных рядов, чтобы рассматривать задачи как единое целое. Используя эти объединения, можно вычислить общие показатели. Например, общая интенсивность запросов для задачи в дата-центре является суммой интенсивностей изменений всех счетчиков запросов.

Счетчик — это любая переменная, значение которой только увеличивается. Индикаторы же могут иметь любое значение. Счетчики отражают возрастающие значения, например пройденные километры, а индикаторы показывают текущее состояние, например количество оставшегося топлива или текущую скорость. При сборе данных в стиле Borgmon предпочтительнее использовать счетчики, поскольку они не теряют свое значение, если событие происходит между запросами данных. Если какое-то действие или изменение произойдет между запросами данных, то, скорее всего, при использовании индикаторов они останутся незамеченными.
Например, для веб-сервера мы хотим добавить оповещение, которое генерируется при условии, что его кластер начинает выдавать больше ошибок выполнения запросов, чем было определено в качестве лимита. Если говорить научным языком, оповещение должно запускаться, когда сумма интенсивностей кодов ответов, отличающихся от HTTP 200, для всех задач, отнесенная к сумме интенсивностей всех запросов для всех задач, начнет превышать некоторое значение.
Это можно сделать так.
1. Сначала мы собираем коды ответов для всех задач и размещаем их в векторах интенсивностей на текущий момент времени. Для каждого кода создается свой вектор.
2. Далее мы вычисляем общую интенсивность ошибок как сумму этого вектора, выводя на экран единственное значение для кластера в заданный момент времени. Этот общий уровень ошибок уже не учитывает коды HTTP 200, поскольку они не относятся к ошибкам.
3. После этого мы вычисляем соотношение количества ошибок с количеством запросов для всего кластера, разделив интенсивность ошибок на интенсивность поступления запросов, снова выводя на экран одно значение для кластера в заданный момент времени.
Каждое выводимое значение в любой момент присоединяется к выражению именованной переменной, что создает новый временной ряд. В результате мы можем проверить хронологию изменения уровня ошибок и частоту появления ошибок в разные промежутки времени.
Правила для интенсивности запросов можно написать на языке правил Borgmon таким образом:
rules <<<
# Compute the rate of requests for each task from the count of requests
{var=task:} =
rate({var=));
# Sum the rates to get the aggregate rate of queries for the cluster;
# 'without instance' instructs Borgmon to remove the instance label
# from the right hand side.
{var=dc:} =
sum without instance({var=task:})
>>>
Функция rate() принимает заключенное в скобки выражение и возвращает разность значений, разделенную на полное время, прошедшее между получением самого раннего и самого позднего значений.
Для примера данных временного ряда из рассмотренного ранее запроса результат выполнения правила task: будет выглядеть так:
{var=task:, ...} 1
{var=task:, ...} 0.9
{var=task:, ...} 1.1
{var=task:, ...} 0
{var=task:, ...} 1
А результаты выполнения правила dc: будут выглядеть так:
{var=dc:} 4
Второе правило использует первое в качестве входных данных.

Метка instance более не выводится, поскольку не учитывается правилами агрегирования. Если бы она оставалась в правиле, система Borgmon не смогла бы просуммировать пять рядов.
В этих примерах мы используем временное окно, поскольку работаем с дискретными точками временного ряда, в отличие от непрерывных функций. Это упрощает получение интенсивностей по сравнению с выполнением расчетов, но также означает, что для вычисления интенсивности необходимо достаточное количество отсчетов. Нам также следует учитывать вероятность того, что некоторые из последних попыток сбора данных дадут сбой. Обратите внимание, что в исходной нотации выражения с переменными используется диапазон (10m), чтобы избежать ситуации, когда данные отсутствуют из-за ошибок, возникших при их сборе.
В этом примере мы также придерживаемся нашего соглашения, позволяющего улучшить читаемость. Имя каждой вычисляемой переменной состоит из трех частей, разделенных двоеточием. Они указывают уровень агрегирования, имя переменной и операцию, создавшую это имя. В этом примере по левую сторону находятся переменные «запросы HTTP для задач в десятиминутном промежутке» и «запросы HTTP для дата-центров в десятиминутном промежутке».
Теперь, когда мы знаем, как определить интенсивность запросов, мы можем на этой же основе вычислить интенсивность ошибок, а затем узнать соотношение ответов к запросам, чтобы видеть, сколько полезной работы выполняет сервис. Мы можем сравнить уровень (частоту появления) ошибок с целевым значением этого показателя для сервиса (см. главу 4) и сгенерировать оповещение в случае, если целевое значение не выполняется или его выполнение под угрозой:
rules <<<
# Compute a rate pertask and per 'code' label
{var=task:} =
rate by code({var=));
# Compute a cluster level response rate per 'code' label
{var=dc:} =
sum without instance({var=task:});
# Compute a new cluster level rate summing all non 200 codes
{var=dc:} = sum without code(
{var=dc:/};
# Compute the ratio of the rate of errors to the rate of requests
{var=dc:} =
{var=dc:}
/
{var=dc:};
>>>
Опять же такое вычисление демонстрирует соглашение, в рамках которого к имени переменной временного ряда добавляется имя операции, которая ее создала. Результат можно прочесть как «процент интенсивности ошибок HTTP для дата-центра в рамках десяти минут».
Результат работы этих правил может выглядеть следующим образом:
{var=task:}
{var=task:, ...} 1
{var=task:, ...} 0
{var=task:, ...} 0.5
{var=task:, ...} 0.4
{var=task:, ...} 1
{var=task:, ...} 0.1
{var=task:, ...} 0
{var=task:, ...} 0
{var=task:, ...} 0.9
{var=task:, ...} 0.1
{var=dc:}
{var=dc:, ...} 3.4
{var=dc:, ...} 0.6
{var=dc:/}
{var=dc:, ...} 0.6
{var=dc:}
{var=dc:, ...} 0.6
{var=dc:}
{var=dc:} 0.15
Здесь показан промежуточный запрос для правила dc:, который отфильтровывает все коды, не равные 200. Хотя значение выражений остается неизменным, вы можете увидеть, что метка для кода есть только в одном примере.
Как упоминалось ранее, правила Borgmon создают новые временные ряды, поэтому результаты вычислений хранятся в памяти временных рядов и могут быть проинспектированы точно так же, как и исходные временные ряды. Эта возможность позволяет создавать при необходимости новые специализированные запросы, выполнять их, вычислять и анализировать таблицы. Такая особенность может оказаться полезной при отладке во время дежурства, и, если эти ситуативно созданные запросы докажут свою полезность, они могут быть помещены в сервисную консоль на постоянной основе.
Оповещение
Когда правило оповещения вычисляется системой Borgmon, результатом может стать либо значение true, и тогда оповещение сработает, либо значение false. Практика показывает, что оповещения могут очень быстро менять свое состояние. Поэтому в правилах указывается минимальная продолжительность сигнала true, по прошествии которой отправляется оповещение. Обычно продолжительность устанавливается равной двум итерациям вычислений правил, чтобы гарантировать, что ошибки при сборе данных не вызвали ложное оповещение.
В следующем примере создается оповещение, которое срабатывает, когда уровень ошибок в течение 10 минут превышает 1 %, а общее количество ошибок превышает 1:
rules <<<
{var=dc:} > 0.01
and by job, error
{var=dc:} > 1
for 2m
=> ErrorRatioTooHigh
details "webserver error ratio at ((trigger_value))"
labels {severity=page};
>>>
В нашем примере коэффициент равен 0,15, что гораздо больше установленного в качестве границы значения 0,01. Однако количество ошибок в этот момент не превышает 1, поэтому оповещение будет неактивно. Как только количество ошибок превысит 1, оповещение на две минуты получит статус «ожидает», чтобы гарантировать, что состояние не временное, и только после этого оно будет запущено.
Правило оповещения содержит небольшой шаблон для заполнения сообщения, куда входит информация о контексте: задача, для которой предназначено это оповещение, имя оповещения, числовое значение для срабатывания правила и т.д. Информация о контексте заполняется Borgmon при запуске оповещения, после чего оно отправляется в соответствующую RPC.
Система Borgmon соединена с центральным сервисом, известным как Alertmanager, который получает RPC с оповещениями, когда срабатывает правило, а затем еще раз, когда оповещение считается «отправляющимся». Alertmanager отвечает за маршрутизацию оповещений. Он может быть сконфигурирован для выполнения таких задач, как:
• задержка некоторых оповещений, если активны другие;
• дедуплицирование оповещений с одинаковыми наборами меток от нескольких экземпляров Borgmon;
• разветвление оповещений на входе и выходе, основанное на их наборах меток, в тот момент, когда запускаются несколько оповещений с одинаковыми наборами меток.
Как это описывалось в главе 6, команды отправляют свои оповещения, требующие немедленного рассмотрения, коллегам на дежурстве, а важные, но еще не критические оповещения — в очередь несрочных оповещений (тикетов). Все остальные оповещения должны быть сохранены в качестве справочных данных для информационных панелей мониторинга.
Более подробное руководство по проектированию оповещений вы можете найти в главе 4.
Разбиваем топологию системы мониторинга на части
Система Borgmon может импортировать данные временных рядов из других экземпляров Borgmon. Если попытаться собрать данные для всех задач сервиса глобально, такой процесс может быстро стать проблемой и единственной точкой отказа. Вместо этого для передачи данных временных рядов между экземплярами Borgmon применяется потоковый протокол, экономя время центрального процессора и байты сетевого трафика по сравнению с основанным на тексте форматом varz. Типичный процесс развертывания использует два и более глобальных экземпляра Borgmon для высокоуровневого агрегирования и один экземпляр в каждом дата-центре для наблюдения за всеми задачами, запущенными на данной площадке. (Компания Google разделяет производственную сеть на зоны для внесения изменений, поэтому наличие двух или более глобальных экземпляров предоставляет множество вариантов на случай обслуживания и отключений.)
Как показано на рис. 10.3, более сложные развертывания приводят к большему разбиению экземпляра дата-центра Borgmon на уровни скрапинга (зачастую это происходит из-за ограничений в объеме оперативной памяти и мощности процессора) и агрегирования (на этом уровне в основном выполняется вычисление правил). Иногда глобальный уровень разбивается на уровень вычисления правил и уровень информационных панелей. Экземпляр Borgmon более высокого уровня может фильтровать данные, передаваемые потоком от экземпляров более низкого уровня, чтобы глобальный экземпляр Borgmon не переполнял свою память временными рядами экземпляров нижнего уровня. Поэтому иерархия агрегирования собирает локальные кэши релевантных временных рядов, которые при необходимости можно проанализировать.
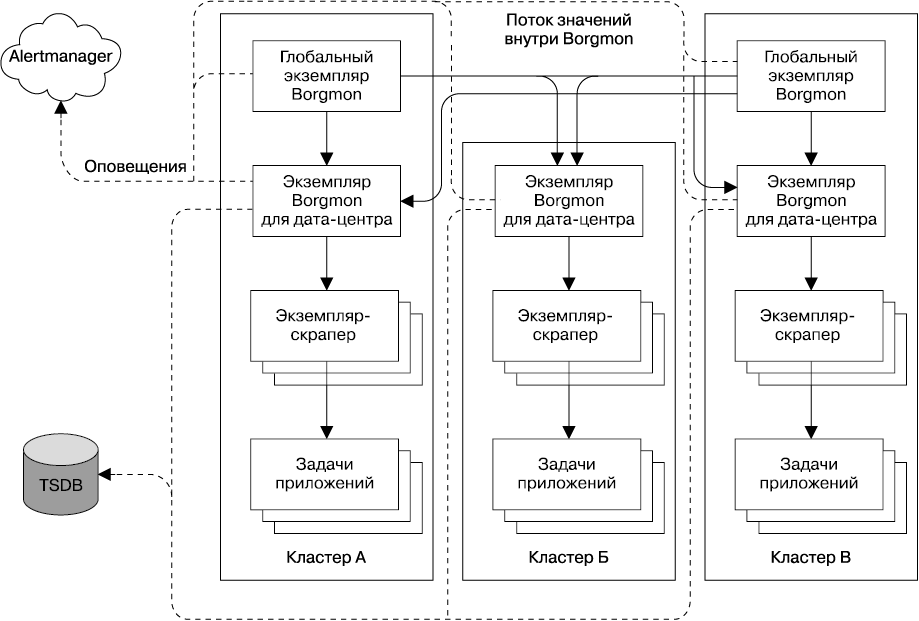
Рис. 10.3. Модель потока данных для иерархии экземпляров Borgmon в трех кластерах
Мониторинг методом черного ящика
Borgmon выполняет мониторинг методом белого ящика — система проверяет внутреннее состояние целевого сервиса, и ее правила создаются с ориентацией на это состояние. Понятный механизм такой модели дает вам широкие возможности, с помощью которых вы можете быстро понять, какие компоненты дают сбой, какие очереди переполнены и где появляются узкие места. Вы можете делать это, как реагируя на инцидент, так и тестируя развертывание новой функциональности.
Однако мониторинг методом белого ящика не дает полной картины для наблюдаемой системы. Применение только этого метода означает, что вы не знаете о том, что видят пользователи. Вы можете видеть только запросы, которые поступают к целевому сервису. Запросы, с которыми этого не происходит из-за ошибок DNS или из-за сбоя сервера, остаются незамеченными. Вы можете отправлять оповещения только о тех сбоях, которые ожидаете увидеть.
В Google эту проблему покрытия решают с помощью инструмента Prober. Он проверяет работу протокола вплоть до конечной точки и отправляет отчет об успехе или неудаче. Prober может отправлять оповещения непосредственно Alertmanager, или же его собственные данные varz могут быть получены экземпляром Borgmon. Prober может проверить процент полезной нагрузки в ответах протокола (например, HTML-содержимое HTTP-ответа) и убедиться, что содержимое соответствует ожиданиям, и даже извлечь и экспортировать значения как временной ряд. Команды часто применяют Prober для экспорта гистограмм задержки по операциям каждого типа и по каждому диапазону объемов полезной нагрузки, что позволяет проанализировать доступную пользователям производительность. Prober — это сочетание модели проверки и тестирования с расширенными возможностями по работе с переменными, позволяющими создавать временные ряды.
Prober можно либо поместить в клиентскую часть приложения, либо связать с балансировщиком нагрузки. Используя оба варианта, мы можем обнаруживать локализованные сбои и отменять вывод оповещений. Например, нам нужно наблюдать за сайтом , выровненным по нагрузке, и за веб-серверами каждого дата-центра, находящимися за балансировщиком нагрузки. Это позволяет нам узнать, например, что при сбое дата-центра трафик все еще обрабатывается, а также быстро выделить провал на графике в момент возникновения ошибок в работе сервиса.
Обслуживаем конфигурацию
Конфигурация Borgmon отделяет определение правил от наблюдаемых объектов-целей. Это означает, что один и тот же набор правил может быть применен ко многим объектам сразу и не нужно раз за разом писать одну и ту же конфигурацию. Такое разделение может показаться несущественным, но оно значительно снижает стоимость обслуживания системы мониторинга и позволяет избежать повторяемости при описании целевых систем.
Borgmon также поддерживает шаблоны языков. Эта макросоподобная система позволяет инженерам создавать библиотеки правил, которые можно использовать повторно. Такая функциональность также снижает повторяемость и, соответственно, вероятность появления ошибок в конфигурации.
Конечно, любая высокоуровневая программная среда может быть излишне сложной, поэтому Borgmon предоставляет способ создать масштабные модульные и регрессионные тесты, синтезируя их на основе данных временных рядов. Они позволяют гарантировать, что правила ведут себя именно так, как задумал их автор. Команда мониторинга систем в промышленной эксплуатации запускает сервис непрерывной интеграции, который выполняет набор этих тестов, упаковывает конфигурацию и отправляет ее во все экземпляры Borgmon. Перед тем как принять конфигурацию, экземпляры проверяют ее корректность.
В обширной библиотеке уже созданных шаблонов появились два класса конфигурации сервиса мониторинга. Первый класс просто кодирует схему переменных, экспортированных из заданной библиотеки кода, и любой пользователь библиотеки может повторно задействовать шаблон своего varz. Такие шаблоны существуют для библиотек HTTP-серверов, выделения памяти, хранилища для клиента, общих RPC-сервисов и пр. (Несмотря на то что в интерфейсе varz схема не объявляется, для библиотеки правил, связанной с библиотекой кода, схема будет объявлена.)
Второй класс библиотек появился из-за того, что мы создавали шаблоны для управления агрегированием данных задач разного масштаба — от выполняющихся на одном сервере до глобальных сервисов. Эти библиотеки содержат правила агрегирования для экспортируемых переменных. С помощью этих правил инженеры могут моделировать топологию своих сервисов.
Например, сервис может предоставлять единый глобальный API, но располагаться в нескольких дата-центрах. Внутри каждого дата-центра сервис состоит из нескольких уровней, каждый из которых включает в себя несколько задач с произвольным количеством заданий. Инженер может смоделировать такое разбиение с помощью правил Borgmon, чтобы при отладке подкомпоненты были изолированы от остальной части системы. В таких группировках судьбы компонентов обычно взаимосвязаны: отдельных задач — из-за конфигурационных файлов, заданий — из-за того, что они размещены в одном дата-центре, а физических сайтов — из-за общей сети.
Соглашения по именованию меток сделали возможным такое разделение: Borgmon добавляет метки, указывающие имя экземпляра цели, а также логическую группу и дата-центр, где она размещается. Эти метки могут быть использованы для группирования и агрегирования временных рядов.
Поскольку у нас есть несколько вариантов применения меток для временных рядов, можно безболезненно заменять один другим.
• Метки, которые определяют разбиение самих данных (например, наш код HTTP-ответа для переменной ).
• Метки, которые определяют источник данных (например, экземпляр или имя задачи).
• Метки, которые показывают местоположение или агрегирование данных внутри сервиса в целом (например, метка zone, которая описывает физическое местоположение, метка shard, описывающая логическое группирование задач).
Шаблонная природа этих библиотек позволяет их гибко использовать. Один и тот же шаблон можно применять для агрегирования данных на каждом уровне.
Десять лет спустя
Borgmon преобразовал модель проверки и оповещения для одной цели в массовый сбор переменных и централизованное вычисление правил для множества временных рядов, обеспечивая оповещение и диагностику.
Такое разделение позволяет масштабировать систему мониторинга в соответствии с размером контролируемой системы, но независимо от количества правил оповещения. Подобные правила проще обслуживать, поскольку они абстрагированы от принятого формата временных рядов. Новые приложения поставляются с уже готовыми для экспорта показателями для всех компонентов и библиотек, связанных с ними, а также с шаблонами для агрегирования и для консоли, что еще больше облегчает реализацию.
Гарантия того, что затраты на обслуживание растут медленнее, чем размер сервиса, — это основа, благодаря которой работа по обслуживанию системы мониторинга (и вся поддерживающая операционная работа) может быть выполнимой. Эта идея встречается во всех областях деятельности SR-инженеров, а усилия самих SR-инженеров направлены на то, чтобы довести масштаб всех сфер своей деятельности до глобального.
Десять лет — это большой промежуток времени, и, конечно же, сегодня системы мониторинга компании Google преобразились в результате экспериментов, нацеленных на их непрерывное улучшение по мере роста компании.
Даже несмотря на то, что Borgmon остается внутренней системой компании Google, идея рассматривать данные временных рядов как источник данных для генерирования оповещений теперь доступна всем благодаря инструментам с открытым исходным кодом вроде Prometheus, Riemann, Heka, Bosun, а также другим, которые могли появиться к тому моменту, когда вы возьмете в руки эту книгу.
Prometheus — это система мониторинга и создания временных рядов с открытым исходным кодом. Доступна по адресу .
Многие команды, в которых нет SR-инженеров, применяют генератор для того, чтобы избежать использования стандартных шаблонов и выполнения постоянных обновлений. Они считают, что такой генератор гораздо проще применять (хотя он и менее мощный), чем непосредственно модифицировать правила.
Многие другие приложения используют свои протоколы сервисов для того, чтобы экспортировать свое внутреннее состояние. OpenLDAP экспортирует его с помощью поддерева cn-Monitor; MySQL может отправлять отчет о состоянии с помощью запроса SHOW VARIABLES; Apache имеет собственный обработчик mod_status.
.
Система именования Borg (Borg Naming System, BNS) описана в главе 2.
Вспомните, как в главе 6 мы рассматривали разницу между оповещением о симптомах и о причинах.
Этот 12-часовой горизонт является магическим значением, которое предназначено для получения достаточного количества информации для отладки инцидента, случившегося в RAM, и касается быстрых запросов. При этом требуется совсем небольшой объем оперативной памяти.
Метки service и zone elided здесь не приводятся ради экономии места, но они будут в выведенном программой выражении.
Синтаксический прием, облегчающий восприятие текста программы.
Вычисление суммы интенсивностей вместо интенсивности изменения сумм защищает итоговый результат от сбросов счетчиков или потери данных. Такие события могут произойти из-за перезапуска задачи или ошибки при сборе данных.
Несмотря на отсутствие в varz типизации, большинство из них являются обычными счетчиками. Функция rate системы Borgmon обрабатывает все особые случаи при сбросе счетчиков.
Метки service и zone опущены по соображениям экономии места.
Метки service и zone опущены из соображений экономии места.

