Часть III. Практики
Говоря простым языком, SR-инженеры запускают сервисы, которые представляют собой набор несвязанных систем, и отвечают за работоспособность этих систем. Успешное управление сервисом включает в себя различные действия: разработку систем мониторинга, планирование пропускной способности, реагирование на критические ситуации, обеспечение принятия мер по устранению основных причин сбоев, и т.д. В этой части мы рассмотрим теорию и практику повседневных задач SR-инженеров: основы построения и эксплуатации крупных распределенных вычислительных систем.
Мы можем описать работоспособность системы — примерно так же, как Абрахам Маслоу описал человеческие потребности [Maslow, 1943] — от наиболее простых действий, необходимых для работы системы, до высших уровней функционирования, включая возможность самосовершенствования системы и управление развитием сервиса вместо точечного реагирования на проблемы. Мы лишь недавно осознали всю важность этого описания для формирования подходов к оценке сервиса в Google. Это произошло, когда несколько наших SR-инженеров, включая бывшего коллегу Майки Диккерсона, вынуждены были временно присоединиться к IT-команде правительства США для того, чтобы помочь им запустить сайт healthcare.gov в конце 2013 — начале 2014 года. В тот момент им нужен был способ объяснить, как повысить надежность системы.
Мы используем иерархию, показанную на рис. III.1, чтобы взглянуть на элементы, которые позволяют сделать сервис надежным: от наиболее простых до наиболее сложных.
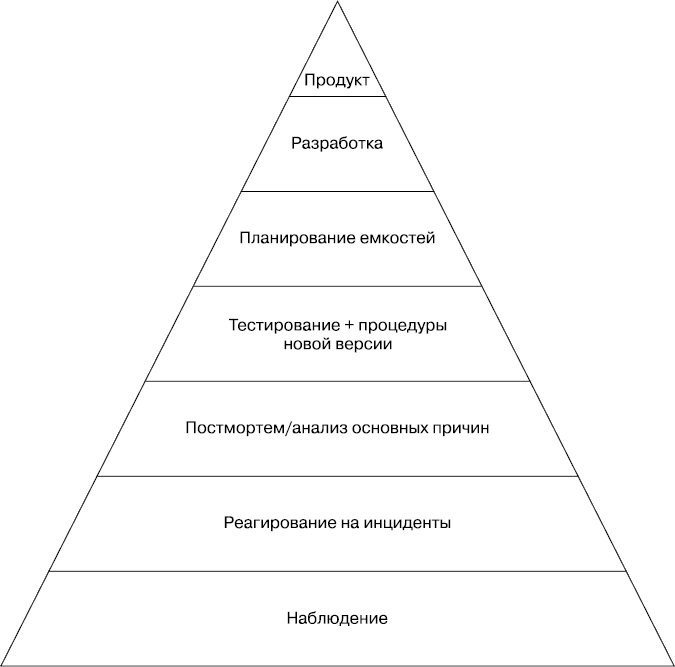
Рис. III.1. Иерархия надежности сервиса
Мониторинг
Без мониторинга вы не сможете сказать, работает ли сервис. Отсутствие продуманной инфраструктуры мониторинга приведет к тому, что вы будете работать вслепую. Может, посетители сайта увидят ошибку, а может, и нет, но вы должны знать о проблемах до того, как их заметят ваши пользователи. Инструменты и принципы мониторинга мы рассмотрим в главе 10 «Оповещения на основании данных временных рядов».
Реагирование в критических ситуациях
SR-инженеры не просто так ходят на дежурства. Поддержка дежурными «на связи» — это средство для осуществления наших главных задач и для того, чтобы знать, как именно работают (и как не работают!) распределенные вычислительные системы. Если мы найдем способ освободить себя от необходимости носить пейджер, то обязательно сделаем это. В главе 11 «Быть на связи» мы объясняем, как балансируем между дежурными обязанностями и другими служебными делами.
Узнав, что появилась проблема, как вы избавитесь от нее? Не обязательно сразу исправлять ее раз и навсегда — возможно, вы сумеете лишь «остановить кровотечение», временно отключив некоторую функциональность, или направить трафик на другой экземпляр сервиса, работающий корректно. Особенности решения, которое вы захотите реализовать, будут характерны для вашего сервиса и организации. Но эффективное реагирование на критические ситуации актуально для всех команд.
В первую очередь важно определить, что пошло не так. Соответствующий структурный подход мы описываем в главе 12 «Эффективная диагностика и решение проблем».
Во время аварии зачастую хочется поддаться панике и начать реагировать по ситуации. В главе 13 «Реагирование в критических ситуациях» мы советуем не поддаваться этому искушению, а в главе 14 «Управление в критических ситуациях» рассказываем, как эффективное управление в критических ситуациях смягчает их последствия и позволяет избавиться от тревожности в ожидании сбоев.
Постмортем и анализ основных причин
Мы стремимся настроить систему так, чтобы получать оповещения по поводу только новых и действительно существенных проблем наших сервисов. Решать раз за разом одну и ту же проблему может быть ужасно скучно. Фактически такой подход — один из ключевых факторов, отличающих философию SRE. Эта тема рассматривается в двух главах.
Формирование культуры отчетов о проблемах (постмортемов), не предусматривающей поиска виновных, — это первый шаг к пониманию того, что пошло не так (и что пошло по плану!). Об этом — глава 15 «Культура постмортема: учимся на ошибках».
С этой темой связана также глава 16 «Контроль неисправностей», где мы кратко описываем инструменты и средства, которые позволяют командам SRE отслеживать недавние аварии в «промышленных» системах, анализировать их причины и предпринятые действия.
Тестирование
Как только мы поняли, что именно идет не так, следующим шагом должна быть попытка предотвратить инцидент, поскольку предотвратить проблему гораздо важнее, чем исправить ее. Наборы тестов дают некоторые гарантии того, что наше ПО не генерирует определенные ошибки перед отправкой в эксплуатацию. О том, как их лучше использовать, мы поговорим в главе 17 «Тестирование надежности систем».
Планирование пропускной способности
В главе 18 «Разработка ПО службой SRE» мы предлагаем рассмотреть в качестве примера разработку Auxon — инструмента для автоматизации планирования пропускной способности.
За планированием пропускной способности логично следует балансировка нагрузки, которая позволяет гарантировать, что мы сможем соответствующим образом воспользоваться установленными мощностями. В главе 19 «Балансировка нагрузки на уровне фронтенда» мы рассмотрим, как запросы к нашим сервисам отправляются в дата-центры. Далее мы продолжим это обсуждение в главе 20 «Балансировка нагрузки в дата-центре» и главе 21 «Справляемся с перегрузками» — каждая из этих тем очень важна для гарантирования надежности сервиса.
Наконец, в главе 22 «Справляемся с каскадными сбоями» мы дадим советы о том, как справиться с каскадными сбоями при проектировании системы, а также в тех случаях, когда каскадный сбой уже произошел.
Разработка
Одними из основных особенностей подхода компании Google к обеспечению надежности сайтов являются проектирование крупномасштабных систем и инженерная работа внутри организации.
В главе 23 «Разрешение конфликтов: консенсус в распределенных системах и обеспечение надежности» мы объясняем понятие консенсуса (согласованности), которое (в виде алгоритма Паксос) лежит в основе многих распределенных систем компании Google, включая нашу глобальную распределенную систему cron. В главе 24 «Cron: планирование и расписание в распределенных системах» мы в общих чертах описываем систему, которая масштабируется на все дата-центры и даже за их пределы, что совсем не просто.
В главе 25 «Конвейеры обработки данных» рассматривается, какие формы могут принимать конвейеры по обработке данных: от периодически запускаемых одиночных задач MapReduce до систем, которые могут работать практически в режиме реального времени. Использование разных архитектур приводит к неожиданным проблемам, решать которые приходится постоянно.
Гарантия того, что сохраненные вами данные будут на месте в тот момент, когда вы захотите их прочитать, — основной смысл целостности данных. В главе 26 «Сохранность данных: как пишется, так и читается» мы объясняем, как безопасно хранить данные.
Продукт
Наконец, добравшись до самой верхушки пирамиды надежности, мы обнаруживаем, что имеем рабочий продукт. В главе 27 «Надежный масштабируемый выпуск продукта» мы рассказываем о том, как компания Google выпускает свои продукты, стремясь, чтобы пользователи были довольны с первого дня работы сервиса.
Другие источники от Google SRE
Как мы говорили ранее, процесс тестирования хрупок и ошибки в нем могут сильно повлиять на общую стабильность. В статье ACM [Krishan, 2012] мы объясняем, как в Google выполняется тестирование устойчивости в масштабах компании. Оно позволяет гарантировать, что мы сумеем справиться с непредвиденными ситуациями.
Несмотря на то что планирование производительности кажется темным искусством, полным таинственных таблиц, оно критически важно. Как показывает [Hixson, 2015a], для этого вам не потребуется хрустальный шар.
Наконец, новый интересный подход к безопасности корпоративной сети подробно рассматривается в [Ward, 2014]. Вы узнаете об инициативе перехода от сетей интранет с управлением доступом на основе привилегий к использованию идентификационных данных для устройств и пользователей. Такой подход, управляемый SR-инженерами на уровне инфраструктуры, определенно стоит учитывать при создании вашей следующей сети.
Майки покинул компанию Google летом 2014 года, чтобы стать первым администратором US Digital Service ().

