Книга: Про GOOGLE
Назад: Глава 6. Правила существуют затем, чтобы их нарушать
Дальше: Глава 8. Лозунг
Глава 7. Y2K
По мере того как 31 декабря 1999 года подбиралось все ближе, весь мир с ужасом ждал прихода цифрового бабайки, известного как Y2K, что представляет собой сокращение от «year 2000» (2000 год).
В чем была проблема? Что ж, в первые годы развития технологий большинство программистов использовали только последние две цифры года при написании компьютерного кода или вводе данных. Если ты родился в 1980 году, это записывалось как 80.
Почему это имело столь большое значение? Компьютеры не понимали разницу между годами 1900-м и 2000-м. Поскольку обе даты заканчиваются на два нуля. Как такое может повлиять на часы? Банкоматы? Военные ракетные системы? Персональные компьютеры? Пенсионные льготы? Регистрации в школах? Больничные записи? Банковские записи? За одну ночь ты мог состариться с 12 до 112 лет. Инженеры и программисты круглосуточно работали, стараясь исправить программное обеспечение для устранения этой ошибки.
Между тем средства массовой информации также волновались по поводу наступления 2000 года. Истерия поглотила газетные заголовки и теленовости. Угроза технологического террора вырисовывалась огромной. Это было похоже на невидимого монстра, скрывающегося под кроватью. Но что он мог сделать? Существовал ли он вообще?
И вот, когда часы пробили полночь – не так уж много и произошло. Такой себе получился цифровой конец света. И о чем теперь всем говорить? Очевидно, о Google.
В то время как остальной мир вошел в новое тысячелетие технологически ошарашенным, Google начал Новый год, сразу же став медиасенсацией. А что самое лучшее в таком внимании со стороны СМИ? Это была бесплатная реклама, да притом в огромном количестве. Слухи о Google распространялись по всему миру с помощью новостей, заставляя все больше и больше пользователей попробовать его в действии. А они, в свою очередь, рассказывали своим друзьям, семьм и коллегам. Google рос с поразительной скоростью в 50 процентов в месяц на протяжении каждого месяца с самого начала.
В марте 2000 года журнал Time выразил «Восторг от Google». В мае 2000 года журнал New Yorker объявил Google «поисковой системой для избранных». Time Digital провозгласила в мае 2000 года, что «Google настолько впереди своих конкурентов, насколько лазер впереди тупого бревна». Ух! В декабре 2000 года Business Week озаглавили свою статью «Окупится ли непорочность Google?».
И эти пользователи были не просто учениками, сотрудниками и друзьями из Стэнфордского университета. Они могли быть не только из Калифорнии. Или с Западного побережья. Или вообще американцами. Тропа пользователей теперь окружала весь земной шар. К осени 2000 года Google выпустил версии на французском, немецком, итальянском, шведском, финском, испанском, португальском, голландском, норвежском, датском, китайском, японском и корейском языках.
Сегодня Google доступен на 150 языках, в том числе на клингонском. Хммм… NUQDAQ ‘OH PUCHPA’’E’.
Между тем все высокотехнологичные компании Силиконовой долины, окружавшие их, разорялись одна за другой. Еще несколько лет назад, в 1990-х годах, компании, специализирующиеся на технологиях, выросли до невероятных высот. Те стартапы буквально купались в деньгах. Некоторое время казалось, что венчурные капиталисты и ангелы-инвесторы просто не успевали раздавать деньги достаточно быстро.
Это было массовой истерией. Пока вдруг все не остановилось.
Технологический пузырь лопнул. Не всем было суждено добиться успеха. И когда люди лучше осмыслили феномен «Дикого Запада» Всемирной сети и научились его использовать, остались только сильнейшие.
Так и в поисковой индустрии не было неуязвимых компаний. Большинство поисковых систем не могли поспеть за темпами роста сети, особенно это касалось тех, что по-прежнему использовали ключевые слова для выдачи результатов поиска. К тому времени люди поняли правила игры в этой системе и стали «наполнять» веб-страницы популярными ключевыми словами. Они даже скрывали эти поисковые слова в коде своего сайта, чтобы ты не мог их увидеть. А значит, если бы ты вбил слово «Калифорния», неизвестно, какие бы результаты ты получил. Фактически ты мог щелкнуть по сайту, который оказывался схемой быстрой покупки. Как спамеры проворачивали это? Одним из способов было расположение ключевых слов на фоне сайта. Таким образом, белый фон может быть сплошь заполнен словом «Калифорния», написанным белым текстом, так что ты не заметишь.
Так было, если ты искал не через Google. Чем больше становился веб, тем лучше были результаты Google. Чем больше веб-страниц, тем больше обратных ссылок. А чем больше обратных ссылок, тем точнее рейтинг страницы. А сайты, которые пытались обхитрить систему, обычно не обладали множеством обратных ссылок.
К концу 2000 года, пока остальная технологическая индустрия выглядела как бесплодная пустошь, шесть тысяч компьютеров Google обрабатывали 15 миллионов запросов в день. Пятнадцать миллионов. Новые языки, новые пользователи и сеть, разрастающаяся на миллиарды страниц в течение года, были теми барьерами, что постоянно держали в напряжении. Поисковик Google теперь был монстром с более чем тремя тысячами компьютеров, сканирующих Интернет, индексирующих ссылки и ранжирующих веб-страницы. Команда инженеров Google заботилась о результатах поиска, программном обеспечении и обо всем остальном на кухне Google, всегда пытаясь совершенствовать результаты пользователей. Алгоритм поиска постоянно анализировался, чтобы оставаться на вершине.
К осени 2000 года Ларри описал состояние поисковой системы Google следующим образом: «Если распечатать весь наш каталог, его высота была бы семьдесят миль! У нас есть шесть тысяч компьютеров. Так что у нас достаточно места для хранения сотни копий Интернета».
«Я не вижу конца тому, что нам еще предстоит сделать, – говорил Ларри в то время, – если в следующем году мы не будем намного лучше, мы будем забыты».
И он был прав. Результатам поиска необходимо было быть не только точными, но также и актуальными. Представь, будто ты услышал, как твои друзья обсуждают выпуск крутой новой игры. Ты садишься за поиск и не находишь ни единого упоминания о ней среди результатов поиска – совсем. Нигде. Ничего. Пусто. Шиш. Вот это была бы проблема. А для Google – первоклассный способ превратиться из героя в ничтожество менее чем за секунду.
Вот что произойдет, если сканеры Google не будут достаточно часто индексировать Интернет. Чтобы избежать такой проблемы, Google начал обновлять свой веб-каталог как можно чаще. Это означало, что результаты Google стали еще и «самыми свежими» в мире.
Google Новости
11 СЕНТЯБРЯ 2001 ГОДА, ПОСЛЕ ТОГО, КАК ПЕРВЫЙ САМОЛЕТ АТАКОВАЛ ВСЕМИРНЫЙ ТОРГОВЫЙ ЦЕНТР, все находились в замешательстве относительно того, что на самом деле происходит. Был ли это маленький самолет? Несчастный случай? Но спустя семнадцать минут второй пассажирский самолет врезался в Южную башню прямо в прямом эфире, приводя все население в ужас. Было ясно, что нападениям подвергается вся страна.
Было трудно найти информацию. Не было никаких смартфонов для записи происходящего или трансляции в прямом эфире на еще не созданном тогда Facebook. Сети вещания передавали информацию, как только они ее получали. Но все эти усилия столкнулись с немыслимыми препятствиями: от перегруженных сотовых сетей и потери телевизионной передачи с башен на крыше Всемирного торгового центра до поиска убежища журналистами во время обрушения зданий. Было невероятно трудно осознать, запечатлеть и как-то передать то, что происходило.
Между тем весь мир пытался понять, что же именно происходит, почему это происходит и кто несет за это ответственность.
Потребность в информации была запредельной.
Члены семей нуждались в новостях о пропавших близких. Каждому самолету в Северной Америке было приказано приземлиться. Пассажиры оказались в затруднительном положении. Их семьям тоже нужна была информация. А так как в новостных сообщениях стали упоминаться множество имен и слов, которые большинство американцев никогда раньше не слышали (такие как Усама бен Ладен, «Аль-Каида» и «Талибан»), все хотели получить больше информации.
Независимо, были ли люди непосредственно затронуты атаками или просто в ужасе наблюдали, им нужны были детали всех аспектов происходящего. В тот день трафик Google резко подскочил.
Пользователи вбивали в поисковую строку «башни-близнецы». Но результаты Google не выдавали никакой информации об атаках. Поискового бота запускали лишь месяц назад. Это означало, что результаты поиска устарели аж на месяц.
В тот сентябрьский день, когда весь мир пытался разобраться в том, что только что произошло и что это означало, каталога Google было недостаточно.
«Мы в Google подводили наших пользователей, – объяснил позже сотрудник Google Амит Сингхал, – поэтому мы разместили ссылки на все новостные организации, такие как CNN, прямо на нашей главной странице со словами «пожалуйста, перейдите на эти сайты, чтобы узнать новости дня»».
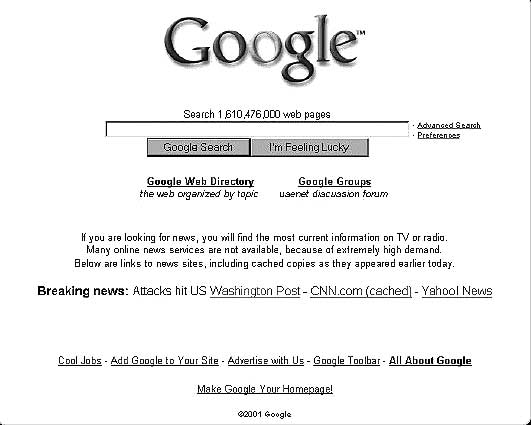
Снимок экрана Google.com от 11 сентября 2001 года
Но многие традиционные новостные сайты были перегружены увеличившимся трафиком. Быстрое решение Google заключалось в том, чтобы размещать ссылки на кэшированные (или сохраненные) версии различных новостных сайтов, доступные ранее тем днем. Это было придуманное на ходу решение, позволившее людям получить необходимую информацию. И эти ссылки были прямо на главной странице Google.
Сам Амит застрял тогда в Новом Орлеане. Вместе с другим разработчиком программного обеспечения Google, инженером Кришной Бхаратом, он направлялся в Луизиану для участия в конференции.
Когда они увидели сообщения об атаках, Кришна начал работать над решением проблемы с новостями.
«Кришна начал обдумывать эту проблему, – объясняет Амит, – и сказал: «Разве не было бы чудесно, если бы мы могли быстро сканировать новости и предоставлять нашим пользователям несколько точек зрения на одну историю?» Так и родились Новости Google».
В течение нескольких недель после атак зашкаливало количество поисковых запросов, связанных с новостями. Изменилось не только настроение страны, но и темы, которые искали в Google. Это было кардинальное изменение.
Будучи любителем новостей, Кришна начал работать над проблемой. Ему нравилось читать разнообразные новости, сопоставлять разные точки зрения. Так как бы разместить все эти статьи и взгляды в одном месте?
«Это бы пригодилось таким читателям, как я, да и самим журналистам, так как на то, чтобы узнать, что написали или сказали другие, уходило много времени, – объясняет Кришна, – особенно по таким темам, как 11 сентября, где существует много различных мнений. Так что я решил, что это проблема, которую действительно стоит решить».
Кришна приступил к работе. Он написал математические уравнения, которые бы выбирали истории подобно тому, как редактор выбирает их для газеты. Он распределил статьи по темам, чтобы они группировались. А потом он применил концепцию ранга, присвоив историям рейтинг, основанный на том, кто их написал, и других факторах. Методом проб и ошибок Кришна наконец пришел к алгоритму, который работал. Он назвал его StoryRank.
Через год Google News предоставил бесплатный доступ к 4500 источникам новостей. Сегодня Google News получает информацию от более чем 50 000 издателей.

