Книга: Руководство по DevOps
Назад: Глава 12. Автоматизация и запуск релизов с низким уровнем риска
Дальше: Часть IV. Второй путь: методики обратной связи
Глава 13. Архитектура низкорисковых релизов
Почти все известные примеры применения DevOps, используемые в качестве образцов, были обречены из-за проблем архитектуры. Об этом уже говорилось в историях LinkedIn, Google, eBay, Amazon и Etsy. В каждом случае компании смогли успешно прийти к архитектурам, более соответствующим текущим организационным потребностям.
Это принцип эволюционной архитектуры: Джез Хамбл отмечает, что архитектура «всех успешных продуктов или организаций обязательно развивается в ходе жизненного цикла». До перехода в Google Рэнди Шуп в 2004–2011 гг. работал главным инженером и ведущим архитектором eBay. Он отмечает, что «и eBay, и Google находятся в процессе пятой полной переработки архитектуры ПО сверху донизу».
Он размышляет: «Оглядываясь назад, я понимаю, что некоторые технологии и выбор архитектуры выглядят замечательными, а другие — неперспективными. Весьма вероятно, что каждое решение в свое время наилучшим образом служило целям организации. Если бы мы в 1995 г. попытались осуществить что-то эквивалентное микросервисам, то мы, скорее всего, потерпели бы неудачу, проект разрушился бы под собственной тяжестью и, возможно, вместе со всей компанией и с нами».
Задача в том, чтобы обеспечивать переход с имеющейся у нас архитектуры на необходимую. В случае с eBay, когда компании надо было переделать архитектуру, они сначала делали небольшой экспериментальный проект, чтобы показать, что они понимают проблемы достаточно хорошо, чтобы предпринять необходимые меры. Например, когда команда Рэнди Шупа в 2006 г. планировала переделать некоторые части сайта на полный набор языка Java, она искала область, дающую наибольший эффект в обмен на вложенные деньги, и с этой целью отсортировала страницы сайта по величине дохода, приносимой каждой из них. Она выбрала области с самыми большими доходами, остановив отбор, когда бизнес-отдача от очередных страниц оказалась недостаточно большой, чтобы оправдать затраченные усилия.
То, что команда Шупа сделала в eBay, хрестоматийный пример эволюционного проектирования с использованием метода, называющегося «удушающее приложение» (strangler application): вместо «вырезания» старого сервиса с архитектурой, больше не помогающей достичь наших организационных целей, и замещения его новым кодом мы скрываем существующую функциональность за API, чтобы избежать дальнейших изменений. Вся новая функциональность затем реализуется в новых сервисах, использующих новую желаемую архитектуру и выполняющих при необходимости вызовы старой системы.
Шаблон удушающего приложения особенно полезен для облегчения миграции отдельных частей монолитного приложения или сильно связанных сервисов в слабо связанные. Слишком часто нам приходится работать в рамках архитектуры с сильно связанными и переплетенными друг с другом частями, нередко созданной несколько лет (или десятилетий) назад.
Последствия слишком сильно связанной архитектуры очень легко заметить: каждый раз, когда мы пытаемся зафиксировать код в основной ветке или зарелизить код в производственную среду, мы рискуем вызвать глобальные сбои (например, мы можем нарушить выполнение всех остальных тестов, функциональность сайта или даже вообще его работу). Каждое небольшое изменение требует огромных объемов работы по согласованию и координации, выполняемой несколько дней или недель, а также одобрения каждой команды, которую потенциально могут затронуть эти изменения. Развертывание становится проблематичным, количество изменений, объединяемых в один пакет для развертывания, растет, что еще сильнее усложняет интеграцию и увеличивает усилия, необходимые для тестирования, а это повышает и без того уже высокую вероятность, что что-то пойдет не так.
Даже развертывание небольших изменений может потребовать координации с сотнями (или даже тысячами) других разработчиков, и взаимодействие с любым из них может вызвать катастрофический сбой, потенциально требующий нескольких недель на поиск и устранение проблемы (это приводит к появлению другого симптома: «Разработчики используют только 15 % своего времени на создание кода, а остальная часть тратится на совещаниях»).
Все эти факторы способствуют использованию крайне небезопасных систем работы, когда небольшие изменения могут вызвать неожиданные и катастрофические последствия. Они также часто способствуют развитию страха перед процессами интеграции и развертывания нашего кода и укрепляют нисходящую спираль, вызывающую стремление выполнять развертывание менее часто.
Исходя из перспективы развития корпоративной архитектуры, нисходящая спираль — следствие второго закона архитектурной термодинамики, особенно в больших и сложных организациях. Чарльз Бец, автор книги Architecture and Patterns for IT Service Management, Resource Planning, and Governance: Making Shoes for the Cobbler’s Children, отмечает: «Владельцы IT-проектов не несут ответственности за свой вклад в общую систему энтропии». Другими словами, сокращение общей сложности и увеличение продуктивности всех наших команд редко становится целью отдельного проекта.
В этой главе мы опишем шаги, которые можно предпринять, чтобы повернуть нисходящую спираль вспять, рассмотрим основные архитектурные архетипы, изучим характерные черты архитектуры, позволяющие повысить продуктивность работы разработчиков, тестируемость, развертываемость и безопасность, а также оценим стратегии, дающие возможность осуществить безопасную миграцию с текущей архитектуры, какой бы она ни была, на ту, что лучше обеспечивает достижение наших организационных целей.
Архитектура, обеспечивающая производительность, тестируемость и безопасность
В отличие от сильно связанной архитектуры, препятствующей производительности сотрудников и их способности безопасно вносить изменения, слабо связанная архитектура с хорошо определенными интерфейсами, повышающими возможность модулей взаимодействовать друг с другом, способствует повышению производительности и безопасности. Она позволяет небольшим, продуктивным, «двухпиццевым» командам создавать небольшие изменения, разворачиваемые безопасно и независимо от других команд. И поскольку каждый такой сервис имеет также хорошо определенный API, он позволяет легче тестировать сервисы и создавать контракты и соглашения об уровне обслуживания между командами.
Облачное хранилище данных компании Google
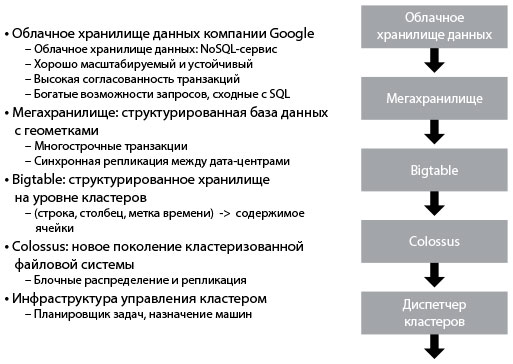
Рис. 22. Облачное хранилище данных компании Google (источник: Shoup, From the Monolith to Micro-services)
Согласно описанию Рэнди Шупа, «этот тип архитектуры отлично служил Google, в частности для такой службы, как Gmail и еще пяти или шести других сервисов более низкого уровня. Их она использовала, и каждый базировался на весьма специфических функциях. Любая служба поддерживается небольшой командой, создающей и запускающей функциональность этой службы, и каждая команда потенциально может использовать различные технологии. Другой пример — служба облачного хранилища данных Google, один из крупнейших NoSQL-сервисов в мире. Несмотря на это, она поддерживается командой из восьми человек. Это возможно в значительной степени из-за того, что сервис основан на нескольких слоях зависимых служб, построенных друг на друге».
Ориентированная на сервисы архитектура позволяет небольшим командам работать над более мелкими и простыми единицами развертывания. Каждая команда может развертывать их независимо, быстро и безопасно. Шуп отмечает, что «организации с этими типами архитектуры, такие как Google и Amazon, показывают, как это может повлиять на организационные структуры, создавая гибкость и масштабируемость. Обе организации имеют десятки тысяч разработчиков, небольшие команды невероятно продуктивны».
Архитектурные архетипы: монолитный или микросервисы
В определенный момент своей истории почти все организации, использующие сейчас DevOps, были отягощены плотно связанной, монолитной архитектурой. Успешно помогая им соответствовать требованиям рынка или требованиям к продуктам, она создавала риск сбоев организационной структуры, если пользователям надо было значительно расширять деятельность (например, монолитное приложение на C++ компании eBay в 2001 г., монолитное приложение OBIDOS компании Amazon в том же году, монолитное клиентское Rails-приложение Twitter в 2009 г. и монолитное приложение Leo компании LinkedIn в 2011 г.). В каждом из этих случаев компании смогли перепроектировать свои системы и заложить основы не только выживания, но и процветания и победы на рынке.
Монолитные архитектуры неплохи по своей сути, в реальности они часто становятся лучшим выбором для организации на раннем этапе жизненного цикла продукта. Как отмечает Рэнди Шуп, «нет идеальной архитектуры для всех продуктов и всех масштабов. Любая архитектура соответствует некоторому набору целей или диапазонам требований и ограничений, таких как время вывода на рынок, простота развития функциональности, масштабирование и так далее. Функциональность любого продукта или услуги почти наверняка будет изменяться с течением времени, так что нет ничего удивительного, что наши архитектурные потребности будут меняться. Что работает в масштабе 1x, редко работает в масштабе 10x или 100x».
Основные архитектурные архетипы показаны в табл. 3, каждая строка означает различные эволюционные потребности организации, каждый столбец показывает достоинства и недостатки разных архетипов. Как видно из таблицы, монолитная архитектура, поддерживающая стартапы (например, быстрое прототипирование новых функций и возможность отклонений или больших изменений в первоначальных стратегиях), очень отличается от архитектуры, требующей наличия сотен команд разработчиков, когда каждая должна быть в состоянии самостоятельно предоставлять продукт клиентам. Поддерживая эволюционность архитектур, мы можем добиться того, что наша архитектура всегда обслуживает текущие потребности организации.
Таблица 3. Архитектурные архетипы
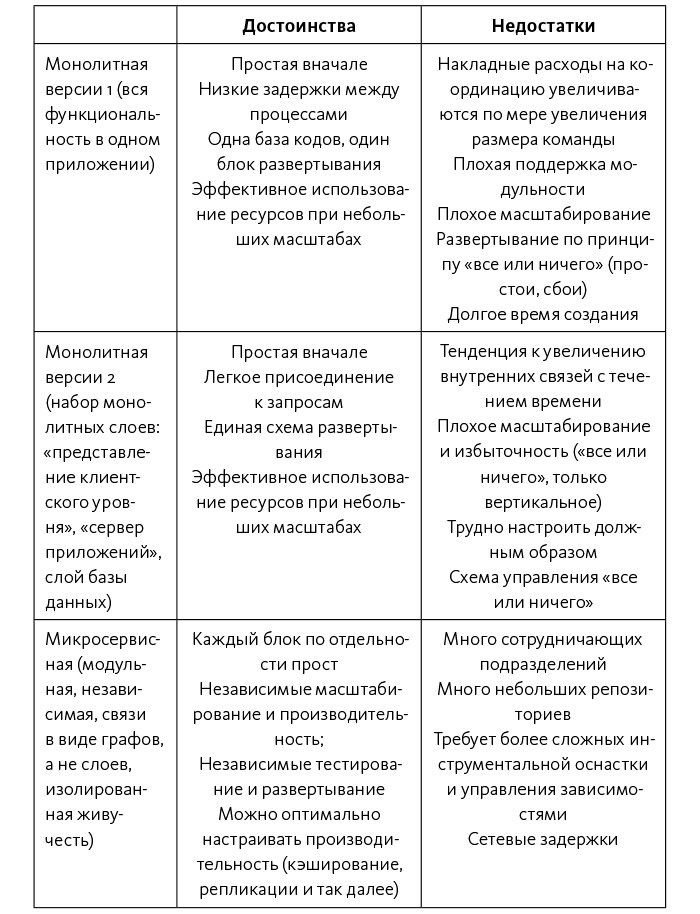
Источник: Shoup, From the Monolith to Micro-services.
Практический пример
Эволюционная архитектура в компании Amazon (2002 г.)
Одно из наиболее изученных преобразований архитектуры произошло в компании Amazon. В интервью с обладателем награды ACM Turing и техническим специалистом компании Microsoft Джимом Греем Вернер Фогельс, технический директор компании Amazon, объяснил, что Amazon.com начал работу в 1996 г. как «монолитное приложение на веб-сервере, обращаясь к базе данных на серверной части. Это приложение, получившее название Obidos, эволюционировало, чтобы сохранить всю бизнес-логику, всю логику отображения и все функциональные возможности, которые в конце концов прославили Amazon: аналоги, рекомендации, Listmania, обзоры и так далее».С течением времени Obidos разросся и стал слишком запутанным, со сложными взаимосвязями отдельных частей. Его невозможно было масштабировать по мере необходимости. Фогельс рассказал Грею, что это означает: «Многие вещи, которые вы хотели бы видеть работающими в хорошей программной среде, больше не могут быть сделаны; множество сложных единиц программного обеспечения объединены в единую систему, но она больше не могла развиваться».Описывая процесс обдумывания новой желаемой архитектуры, он рассказывал Грею: «Мы прошли через период серьезного самоанализа и пришли к выводу о том, что сервис-ориентированная архитектура могла бы обеспечить уровень изоляции, достаточный для того, чтобы позволить нам создавать множество компонентов программного обеспечения быстро и независимо друг от друга».Фогельс отмечает: «Компания Amazon в течение последних пяти лет (2001–2005) прошла через большие изменения архитектуры, чтобы сменить двухуровневую монолитную архитектуру на полностью распределенную децентрализованную платформу сервисов, обслуживающую множество различных приложений. Потребовалось множество инноваций, чтобы такие изменения стали возможными, и мы были одними из первых, использовавших этот подход». Из опыта работы Фогельса в компании Amazon можно извлечь следующие уроки, имеющие большое значение для нашего понимания смен архитектуры:
• урок 1: при неукоснительном применении строгая ориентация на сервисы — отличный метод для достижения изоляции, вы можете добиться невиданного прежде уровня владения и управления;• урок 2: запрет прямого доступа клиентов к базе данных делает возможным выполнение масштабирования и повышение надежности вашего сервиса, не затрагивая клиентов;• урок 3: процессы разработки и эксплуатации получают значительную выгоду от перехода на сервис-ориентированную модель. Она стала ключевым фактором успеха в создании команд, быстро внедряющих инновации в интересах клиентов. Каждая служба имеет команду, несущую полную ответственность — от оценки функциональности до создания архитектуры, разработки и управления ее работой.
Применение этих результатов повышает продуктивность работы и надежность до показателей, захватывающих дух. В 2011 г. компания Amazon выполняла примерно 15 тысяч развертываний в день. К 2015 г. она выполняла почти 136 тысяч развертываний в день.
Используем шаблон «удушающих приложений», чтобы безопасно развивать архитектуру нашей организации
Термин «удушающее приложение» был введен Мартином Фаулером в 2004 г., после того как он увидел огромные удушающие лозы во время путешествия в Австралию и описал их так: «Они выбирают верхние ветви смоковницы и постепенно растут вниз по дереву, пока не укоренятся в почве. Долгие годы они разрастаются, приобретая фантастически красивые формы и постепенно удушая и убивая дерево, на котором паразитируют».
Определив, что нынешняя архитектура слишком сильно связана, мы можем безопасно запустить отвязывание части функциональности от нашей существующей архитектуры. Это позволит командам, поддерживающим отвязываемые функциональные возможности, самостоятельно разрабатывать, тестировать и развертывать их код в производство, делая это автономно и безопасно и снижая архитектурную энтропию.
Как говорилось ранее, шаблон удушающего приложения включает размещение существующей функциональности за API, где она остается неизменной, новые функции внедряются с помощью нашей желаемой архитектуры, при необходимости выполняя вызовы старой системы. Реализуя удушающее приложение, мы стремимся обеспечить доступ ко всем сервисам через версионированные API, также называемые версионированными или неизменяемыми сервисами.
Версионированные API позволяют нам изменить сервис без влияния на вызывающих его клиентов, что дает возможность системе быть более слабо связанной — если нам нужно изменить аргументы, мы создаем новую версию API и переводим команды, зависящие от нашего сервиса, на новую версию. В конце концов мы не сможем достичь цели изменения архитектуры, если позволим новому удушающему приложению стать тесно связанным с другими службами (например, подключаясь непосредственно к базе данных другой службы).
Если вызываемые службы не имеют четко определенных API, то мы должны создавать такие интерфейсы или по крайней мере скрыть сложность взаимодействия с такими системами использованием библиотеки клиента, имеющей четко определенный API.
Неоднократно отвязывая функциональность от существующих тесно связанных систем, мы перемещаем работу в безопасные и активные экосистемы, после чего разработчики могут стать гораздо более продуктивными, а устаревшие приложения уменьшат функциональность. Они даже могут исчезнуть полностью, когда все необходимые функции перейдут к новой архитектуре.
Создав удушающее приложение, мы сможем избежать точного воспроизведения существующей функциональности в некоторых новых архитектурах или технологиях — часто наши бизнес-процессы более сложны, чем необходимо в связи с особенностями имеющихся систем, которые мы реплицируем (изучая пользователя, мы часто можем перепроектировать этот процесс, чтобы создать намного более простые и более рациональные средства для достижения наших бизнес-целей).
Наблюдение Мартина Фаулера подчеркивает этот риск: «Значительную часть моей трудовой деятельности составляло участие в переписывании критически важных систем. Вам может показаться, что это очень просто — написать новую программу, делающую то же самое, что и старая. Но такая работа всегда более сложна, чем кажется, и изобилует всевозможными рисками. Впереди маячит важная дата завершения проекта, и давление нарастает. В то время как новые функциональные возможности (всегда существуют новые функциональности) нравятся всем, старые никуда не деваются. Нередко в переписанную систему приходится добавлять даже старые ошибки».
Как и в случае с любым преобразованием, мы стремимся создать быстрый победный результат и рано доставить дополнительную ценность, еще до того как продолжим итерации. Предварительный анализ помогает нам определить наименьший возможный кусок работы, полезный для получения бизнес-результатов с использованием новой архитектуры.
Практический пример
Шаблон удушения в программе Blackboard Learn (2011 г.)
Компания Blackboard — один из пионеров предоставления технологии для учебных заведений с годовым доходом в размере примерно 650 миллионов долларов в 2011 г. В то время команда разработчиков флагманской программы Learn, пакетного программного обеспечения, установленного и запущенного локально на сайтах клиентов, ежедневно сталкивалась с последствиями использования унаследованной базы кода на J2EE, писавшейся еще в 1997 г. Как отмечал Давид Эшман, главный архитектор компании, «мы до сих пор имеем дело с фрагментами кода на языке Perl, встречающимися на многих участках нашего кода».В 2010 г. Эшман сосредоточился на сложности и растущем времени разработки, связанных со старой системой, отмечая, что «сборка, интеграция и тестирование процессов становились все более сложными и более склонными к ошибкам. И чем больше становился продукт, тем дольше длилась разработка новых функциональных возможностей и тем хуже были результаты, получаемые нашими клиентами. Даже получение обратной связи от процесса интеграции требовало от 24 до 36 часов».
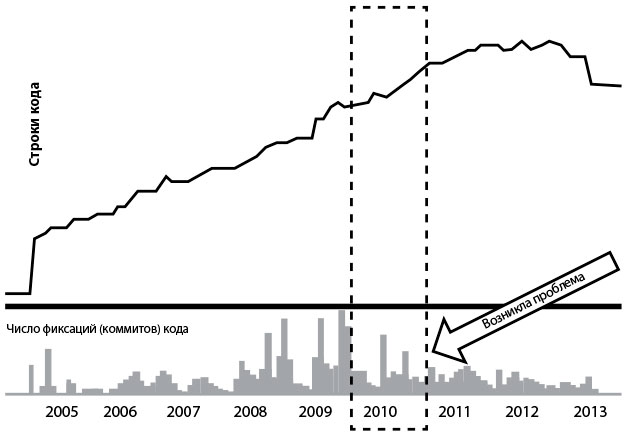
Рис. 23. Репозиторий кода Blackboard Learn до создания Building Blocks (источник: DOES14 — David Ashman — Blackboard Learn — Keep Your Head in the Clouds, видео на YouTube, 30:43, размещено 28 октября 2014 г. оргкомитетом конференции DevOps Enterprise Summit 2014, )
Как это начало влиять на производительность труда разработчиков, Эщман увидел на графиках, созданных на основе данных из репозитория исходного кода начиная с 2005 г.На рис. 24 верхний график показывает число строк кода в репозитории монолитной программы Blackboard Learn, нижний график показывает число фиксаций кода. Проблема, ставшая для Эшмана очевидной, заключалась в том, что количество фиксаций кода стало уменьшаться, объективно показывая нарастающую трудность внесения изменений в код, в то время как число строк кода продолжало увеличиваться. Эшман отмечал: «Эти графики свидетельствовали, что нам нужно что-то делать, в противном случае проблемы будут усугубляться, и этому не видно конца».
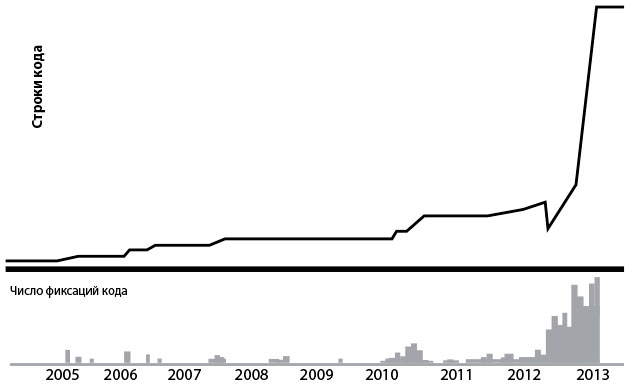
Рис. 24. Репозиторий кода Blackboard Learn с использованием Building Blocks (источник: DOES14 — David Ashman — Blackboard Learn — Keep Your Head in the Clouds, видео на YouTube, 30:43, размещено 28 октября 2014 г. оргкомитетом конференции DevOps Enterprise Summit 2014, )
В результате в 2012 г. Эшман сосредоточился на реализации проекта переработки архитектуры кода, использовавшего шаблон удушающего приложения. Команда достигла этого путем создания инструмента, названного Building Blocks. Он позволил разработчикам работать над отдельными модулями, отделенными от монолитной базы кода. Доступ к ним осуществлялся через фиксированные API. Это позволило командам работать автономнее, без необходимости постоянно общаться друг с другом и координировать свою деятельность с другими командами.Когда Building Blocks стал доступен разработчикам, размер репозитория монолитного исходного кода начал уменьшаться (измеренный в количестве строк кода). Эшман пояснил: это происходило потому, что разработчики перемещали код в репозиторий исходного кода модулей Building Blocks. «Фактически, — сообщил Эшман, — каждому разработчику, которому предоставлена возможность выбора, хотелось бы работать в базе кода Building Blocks, где они могли бы работать с большей автономностью, свободой и безопасностью».На графике выше показана связь между экспоненциальным ростом числа строк кода и экспоненциальным ростом числа фиксаций кода в репозитории Building Blocks. Новая база кода Building Blocks дала разработчикам возможность быть более продуктивными, и они сделали работу безопаснее, поскольку ошибки стали приводить к небольшим местным сбоям вместо крупных катастроф, влияющих на глобальную систему.Эшман заключает: «Когда разработчики начали работать с архитектурой Building Blocks, созданной с целью реализации впечатляющих улучшений в модульности кода, это позволило им работать более независимо и свободно. В сочетании с обновлениями в нашем процессе сборки это обеспечило им возможность быстрее и лучше получать обратную связь, что означает лучшее качество».
Заключение
Архитектура, в рамках которой работают наши сервисы, в значительной степени диктует то, как мы будем тестировать и развертывать наш код. Это было подтверждено в докладе 2015 State of DevOps Report компании Puppet Labs, показавшем, что архитектура — один из лучших инструментов предсказания производительности инженеров, работающих в ее рамках и того, насколько быстро и безопасно можно производить изменения.
Поскольку мы часто «застреваем» в архитектуре, оптимизированной для другого набора организационных целей или в далеком прошлом, постольку должны иметь возможность безопасно переходить с одной архитектуры на другую. В практических примерах из этой главы, а также в ранее приведенном примере компании Amazon показывались методики (например, шаблон удушающего приложения), способные помочь постепенно мигрировать с одной архитектуры на другую, давая возможность адаптироваться к потребностям организации.
Заключение к третьей части
В предыдущих главах третьей части мы рассмотрели архитектуру и технические методы, обеспечивающие быстрый поток работы от разработчиков к отделу эксплуатации, так что продукт может быть доставлено заказчикам быстро и безопасно.
В четвертой части мы будем создавать архитектуру и механизмы, обеспечивающие быстрое протекание процесса обратной связи в противоположном направлении, справа налево, чтобы быстрее найти и устранить проблемы, распространить обратную связь на всю организацию и обеспечить лучшие результаты нашей работы. Это позволит нашей организации еще больше увеличить скорость адаптации.
Назад: Глава 12. Автоматизация и запуск релизов с низким уровнем риска
Дальше: Часть IV. Второй путь: методики обратной связи

