Книга: Руководство по DevOps
Назад: Глава 11. Запустить и практиковать непрерывную интеграцию
Дальше: Глава 13. Архитектура низкорисковых релизов
Глава 12. Автоматизация и запуск релизов с низким уровнем риска
Чак Росси — технический директор в Facebook. Одна из его задач — контроль за ежедневным релизом кода. В 2012 г. Росси так описал процесс: «Начиная с часа дня я переключаюсь в “режим эксплуатации” и вместе с командой готовлюсь запустить обновления, которые выйдут на в этот день. Эта наиболее напряженная часть работы в значительной степени зависит от решений моей команды и от прошлого опыта. Мы стремимся убедиться, что каждый, кто вносил релизные изменения, отчитывается за них, а также активно тестирует и поддерживает изменения».
Незадолго до релиза все разработчики релизных изменений должны появиться на своем канале интернет-чата — отсутствующим разработчикам приходит возврат обновлений, автоматически удаленных из пакета развертывания. Росси продолжает: «Если все хорошо и наши инструменты тестирования и “канареечные тесты” успешны, мы нажимаем большую красную кнопку, и весь “парк” серверов получает новый код. В течение 20 минут тысячи и тысячи компьютеров переходят на новый код без какого-либо заметного влияния на тех, кто использует сайт».
Позже в том же году Росси увеличил частоту релизов программного обеспечения до двух раз в день. Он объяснил, что второй релиз кода позволил инженерам, находящимся не на Западном побережье США, «вносить изменения и отправлять их так же быстро, как любой другой инженер в компании», а также предоставил всем еще одну возможность каждый день отправлять код и запускать новые функциональные возможности.
Количество разработчиков в неделю, развертывающих свой код
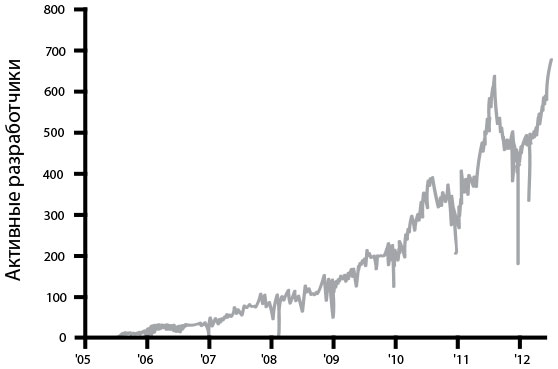
Рис. 16. Количество разработчиков Facebook в неделю, развертывающих свой код (источник: Chuck Rossi, Ship early and ship twice as often)
Кент Бек, создатель методологии экстремального программирования, один из основных сторонников разработки на основе тестирования и технический наставник в компании Facebook, прокомментировал стратегию релиза кода компании в статье, опубликованной на его странице в Facebook: «Чак Росси отметил: создается впечатление, что за одно развертывание Facebook может обработать только ограниченное количество изменений. Если мы хотим сделать больше изменений, то нам нужно выполнить больше развертываний. Это привело к неуклонному росту темпов развертывания в течение последних пяти лет, с одного раза в неделю до ежедневного, а затем — до трех раз в день для кода PHP и с шестинедельного до четырехнедельного, а затем двухнедельного цикла развертывания мобильных приложений. Улучшение было обеспечено главным образом инженерной группой, ответственной за релизы».
Используя непрерывную интеграцию и развертывание кода с помощью процесса с низким уровнем риска, компания Facebook сделала развертывание кода частью повседневной работы разработчиков, чем способствовала их производительности. Для этого необходимо, чтобы развертывание кода было автоматизированным, повторяемым и предсказуемым. Хотя в методиках, описанных выше, наши код и среды тестировались вместе, скорее всего, развертывание в производство выполнялось не очень часто, поскольку делалось вручную, занимало много времени, было трудным и утомительным, оказывалось подвержено ошибкам и часто вытекало из неудобной и ненадежной передачи работы от отдела разработки к отделу эксплуатации.
И поскольку все это непросто, мы склонны делать так все реже, что приводит к другой самоусиливающейся нисходящей спирали. Откладывая развертывание изменений в производство, мы накапливаем все больше различий между кодом, который будет развернут, и кодом, в данный момент работающим в производстве, увеличивающим размер пакетной работы. Так растет риск неожиданных результатов, вызванных изменением, а также трудности, связанные с их исправлением.
В этой главе мы снизим внутренние трения, связанные с развертыванием в производство, чтобы оно могло выполняться часто и легко, как разработчиками, так и отделом эксплуатации. Мы можем сделать это за счет расширения конвейера развертывания.
Вместо простой непрерывной интеграции кода в среде, близкой к производственной, обеспечим продвижение в производство любой сборки, проходящей автоматизированные тесты и процессы валидации или по запросу (например, нажатием на кнопку), или автоматически (например, любая сборка, которая проходит все тесты, развертывается автоматически).
Поскольку в данной главе описано значительное количество методик, то, чтобы не прерывать представления концепций, будут использоваться обширные сноски, многочисленные примеры и дополнительная информация.
Автоматизируем процесс развертывания
Достижение таких же результатов, как в компании Facebook, требует наличия автоматизированного механизма, развертывающего код в производственную среду. Если процесс развертывания существует много лет, то особенно необходимо в полной мере документировать все его этапы, например в картах процесса создания продукта. Их мы можем собрать в ходе рабочих совещаний или постепенно пополняя документацию (например, в форме wiki).
После того как мы задокументировали процесс, наша цель — упростить и автоматизировать как можно больше выполняемых вручную шагов, а именно:
• упаковка кода подходящим для развертывания образом;
• создание предварительно настроенных образов виртуальных машин или контейнеров;
• автоматизация развертывания и настройки конфигурации промежуточного ПО;
• копирование пакетов или файлов на производственные серверы;
• перезапуск серверов, приложений или служб;
• создание файлов конфигурации из шаблонов;
• запуск автоматизированных smoke-тестов, чтобы убедиться, что система работает и правильно настроена;
• запуск процедур тестирования;
• сценарии и автоматизация миграции базы данных.
Где это возможно, будем перерабатывать архитектуру с целью удаления некоторых шагов, в частности требующих длительного времени. Желая уменьшить опасность ошибок и потери знаний, мы также хотели бы сократить не только сроки выполнения, но и в максимально возможной степени — количество случаев, когда работа передается от одного отдела другому.
Если разработчики сосредоточатся на автоматизации и оптимизации процесса развертывания, это может привести к существенным улучшениям потока развертывания, таким как отсутствие необходимости новых развертываний или создание новых сред при небольших изменениях конфигурации приложений.
Однако для этого необходимо, чтобы разработчики действовали в тесном контакте с отделом эксплуатации для обеспечения того, чтобы все инструменты и процессы, созданные нами, могли использоваться в ходе процесса и чтобы отдел эксплуатации не отчуждался от общего процесса и не надо было заново изобретать колесо.
Многие инструменты, обеспечивающие непрерывную интеграцию и тестирование, также поддерживают возможность расширить конвейер развертывания, так что проверенные сборки могут быть введены в производство, обычно после приемочных испытаний (например, Jenkins Build Pipeline plugin, ThoughtWorks Go.cd and Snap CI, Microsoft Visual Studio Team Services и Pivotal Concourse).
Среди требований к нашему конвейеру развертывания следующие:
• развертывание одинаковым образом в любой среде: с помощью одного и того же механизма развертывания для всех сред (например, разработки, тестирования и производственной) наше развертывание в производство может быть гораздо более успешным, поскольку мы знаем, что оно уже было успешно выполнено не один раз в начале конвейера;
• smoke-тестирование наших развертываний: в ходе процесса развертывания мы должны протестировать, что можем подключаться к любой системе поддержки (например, базам данных, шинам сообщений, внешним сервисам), и запустить одну тестовую транзакцию через систему, чтобы убедиться, что наша система работает так, как задумано. Если любой из этих тестов не пройден, то мы должны остановить развертывание;
• поддержание согласованных сред: на предыдущих шагах мы создали процесс сборки среды за один шаг, с тем чтобы среды разработки, тестирования и производственные имели общий механизм их создания. Мы должны постоянно обеспечивать синхронизированность сред.
Конечно, в случае возникновения каких-либо проблем в ходе развертывания мы потянем шнур-андон и дружно набросимся на проблему, пока она не будет решена. Так же мы поступаем, если конвейер развертывания сбоит на любом из предыдущих шагов.
Практический пример
Ежедневное развертывание в компании CSG International (2013 г.)
Компания CSG International — один из крупнейших операторов по печати счетов в США. Скотт Праф, главный архитектор и вице-президент отдела разработки ПО, в рамках усилий по повышению предсказуемости и надежности выпусков программного обеспечения удвоил частоту релизов с двух до четырех в год (уменьшив интервал между развертываниями вдвое, с 28 недель до 14).Хотя команды разработчиков использовали непрерывную интеграцию для ежедневного развертывания их кода в средах тестирования, релизы в производственную среду выполнялись отделом эксплуатации. Праф отмечал: «Это как если бы у нас была “учебная команда”, ежедневно (или даже чаще) тренировавшаяся создавать низкорисковые тестовые среды, совершенствуя свои процессы и инструменты. Но производственная “играющая команда” упражнялась очень редко, всего два раза в год. Что еще хуже, она тренировалась в высокорисковой производственной среде, часто сильно отличавшейся от предпроизводственных сред, имевших различные ограничения — в средах разработки отсутствовали многие производственные ресурсы (средства обеспечения безопасности, брандмауэры, средства балансировки нагрузки и SAN)».Чтобы решить эту проблему, была создана общая команда эксплуатации (Shared Operations Team, SOT), отвечавшая за управление всеми средами (разработки, тестирования, производственной), ежедневно выполнявшая развертывание в средах разработки и тестирования, а каждые четырнадцать недель — развертывание в производство. Поскольку SOT выполняла развертывание каждый день, любые проблемы, с которыми она сталкивалась и которые не были исправлены, на следующий день возникали снова. Это побудило к автоматизации трудоемких или чреватых ошибками операций, проведенных вручную, и устранению любых проблем, которые потенциально могли бы повториться. Поскольку развертывание выполнялось почти сто раз перед релизом, большинство проблем задолго до него были найдены и устранены.Это позволило вытащить на свет проблемы, ранее известные только отделу эксплуатации. Но они тормозили весь поток создания ценности, и их надо было решать. Ежедневное развертывание обеспечивает ежедневную же обратную связь о том, какие методы сработали, а какие нет.Исполнители также сосредоточили внимание на том, чтобы сделать все среды как можно более аналогичными и как можно скорее, включая ограниченные права доступа и средства балансировки нагрузки. Праф пишет: «Мы настолько приблизили непроизводственные среды к производственной, насколько смогли, и стремились как можно точнее воспроизвести в них ограничения, имеющиеся в производственной среде. Ранее использование сред, сходных с производственными, вызвало изменение архитектурных решений с целью сделать их более приемлемыми в ограниченных или различающихся средах. При таком подходе каждый человек становится умнее».Праф также отмечает:«Мы столкнулись со многими случаями, когда изменялись схемы баз данных — либо 1) переданные в группу ДБА запросы в стиле “идите и разбирайтесь”, либо 2) автоматизированные тесты, работавшие с неоправданно малыми наборами данных (например, сотни мегабайт вместо сотен гигабайт), что вело к сбоям в производственном процессе. При прежнем способе работы это приводило к дискуссиям между командами до глубокой ночи в поисках козла отпущения и попытках размотать клубок проблем. Мы создали процесс разработки и развертывания, снявший необходимость передачи группе ДБА заданий на работу благодаря перекрестному обучению разработчиков, автоматизации изменения схемы и ежедневному выполнению этого процесса. Мы создали реалистичное тестирование нагрузки, не урезая данные заказчика, и в соответствии с идеальным решением выполняли миграцию каждый день. Благодаря этому мы сотни раз запускаем сервис с реалистичными сценариями еще до того, как он начнет обслуживать реальный производственный трафик».Полученные результаты были удивительными. Ежедневно выполняя развертывание и удвоив частоту релизов в производственную среду, удалось снизить количество сбоев на производстве на 91 %, MTTR уменьшилось на 80 %, а время развертывания служб в производство уменьшилось с четырнадцати дней до одного и проходит в режиме полного исключения операций, проводимых вручную.Праф сообщил: развертывание стало настолько рутинным процессом, что в конце первого дня команда эксплуатации играла в видеоигры. В дополнение к тому, что развертывание стало проходить более гладко и для разработчиков, и для эксплуатации, в 50 % случаев заказчик получал свою ценность за время, вдвое меньшее, чем обычно, что подчеркивало, насколько более частое развертывание полезнее для разработчиков, тестировщиков, отдела эксплуатации и клиентов.
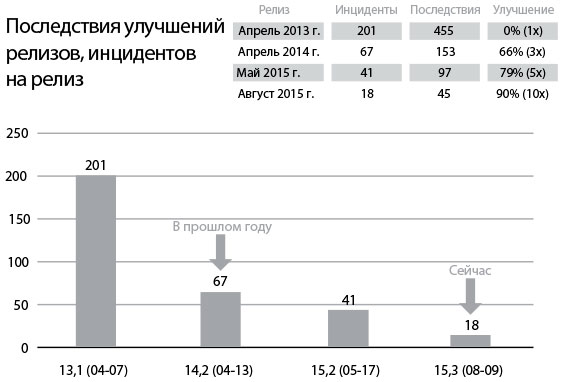
Рис. 17. Ежедневные развертывания и увеличение частоты релизов уменьшают число инцидентов в производстве и MTTR (источник: DOES15 — Scott Prugh & Erica Morrison — Conway & Taylor Meet the Strangler (v2.0), видео на YouTube, 29:39, размещено DevOps Enterprise Summit, 5 ноября 2015 г., )
Включите автоматизированное самообслуживание развертываний
Рассмотрим утверждение Тима Тишлера, директора по автоматизации эксплуатации компании Nike, об общем опыте поколения разработчиков: «Я никогда не испытывал большего удовлетворения своей деятельностью как разработчика, чем когда писал код, нажимал кнопку для развертывания и мог видеть производственные показатели, подтверждающие, что код действительно работает в производственной среде, и чем когда сам мог все исправить, если он все-таки не работал».
Возможности разработчиков самостоятельно развернуть код в производство, быстро увидеть, довольны ли клиенты новыми функциями, и быстро устранить любые проблемы без необходимости создавать задание для отдела эксплуатации уменьшились в течение последнего десятилетия — отчасти в результате контроля и надзора, возможно, вызванных нормами безопасности, и необходимостью соответствовать требованиям.
В результате общая практика — развертывание кода отделом эксплуатации, из-за разделения обязанностей — широко признанная практика в целях снижения риска сбоев производства и обманов. Однако для достижения результатов DevOps наша цель — начать доверять другим механизмам управления, которые могут смягчать риски в той же степени или даже более эффективно, например посредством автоматизированного тестирования, автоматического развертывания и экспертной оценки изменений. Доклад 2013 State of DevOps Report, подготовленный компанией Puppet Labs по результатам опроса более четырех тысяч профессионалов в области технологий, показал, что нет статистически значимой разницы в изменении показателей успешности между теми организациями, где развертывание производится отделом эксплуатации, и теми, где развертывание выполняют разработчики.
Другими словами, при наличии общих целей у разработчиков и отдела эксплуатации и тогда, когда существует прозрачность, ответственность и возможность учета результатов развертывания, уже не важно, кто именно выполняет развертывание. Фактически даже те, кто выполняет другие роли, — тестировщики и менеджеры проектов — способны развертывать определенные среды, чтобы иметь возможность быстро завершить работу, например настройку демонстрации конкретных функций в тестах или средах приемочного тестирования.
Чтобы создать лучшие условия для быстрого потока работы, нам нужен процесс продвижения кода по этапам. Он может быть выполнен и разработчиками, и отделом эксплуатации, причем в идеале без каких-либо действий вручную или передачи работы от одного сотрудника другому. Это влияет на следующие шаги:
• сборка: наш конвейер развертывания должен создавать пакеты из кода, взятого в системе контроля версий. Они могут быть развернуты в любой среде, включая производственную;
• тестирование: любой работник должен иметь возможность запускать любой или все наши наборы автоматизированных тестов на своей рабочей станции или на наших тестовых системах;
• развертывание: любой работник должен иметь возможность быстро развертывать эти пакеты в любой среде, к которой он имеет доступ, с помощью сценариев, также зафиксированных в системе контроля версий.
Эти методы позволяют успешно выполнить развертывание независимо от того, кто его будет выполнять.
Интегрируйте развертывание кода в конвейер развертывания
После того как процесс развертывания кода автоматизирован, мы можем сделать его частью конвейера развертывания. В связи с этим наша автоматизация развертывания должна обеспечивать следующие возможности:
• убедиться, что пакеты, созданные во время непрерывного процесса интеграции, подходят для развертывания в производство;
• с одного взгляда показать готовность производственных сред;
• обеспечить запускаемый одним нажатием кнопки и самообслуживаемый метод развертывания в производство любой подходящей версии упакованного кода;
• автоматически записывать для аудита и обеспечения соответствия требованиям, какие команды были выполнены и на какой машине, когда, кто санкционировал и каков был результат;
• выполнить smoke-тест, чтобы убедиться, что система работает правильно и параметры конфигурации, в том числе такие элементы, как строки подключений к базам данных, корректны;
• обеспечить быструю обратную связь для работника, чтобы он мог быстро определить, осуществилось ли развертывание (например, успешно ли оно прошло, работает ли приложение в производственной среде в соответствии с ожиданиями и так далее).
Цель — обеспечить, чтобы развертывание выполнялось быстро, мы не хотим ждать часами, пока сможем определить, успешно ли развертывание нашего кода или нет, а затем еще столько же времени тратить на развертывание кода, исправляющего обнаруженные ошибки. Сейчас мы имеем такие технологии, как контейнеры, и можем завершить развертывание даже в самых сложных средах в течение нескольких секунд или минут. Данные, опубликованные в докладе 2014 State of DevOps Report, подготовленном компанией Puppet Labs, свидетельствуют, что при высокой производительности время развертывания измеряется несколькими минутами или часами, в то время как при низкой производительности — месяцами.
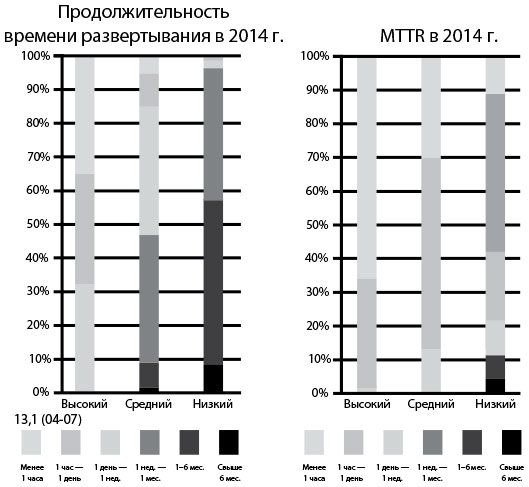
Рис. 18. Компании с высокой производительностью выполняют развертывание гораздо быстрее и также гораздо быстрее восстанавливают работу производственных сервисов после инцидентов (источник: доклад 2014 State of DevOps Report, подготовленный компанией Puppet Labs)
Создав такую возможность, мы используем кнопку «развернуть код», позволяющую быстро и безопасно вносить изменения, сделанные в нашем коде и наших средах, в производство с помощью нашего конвейера развертывания.
Практический пример
Самообслуживаемое развертывание разработчиками в компании Etsy — пример непрерывного развертывания (2014 г.)
В отличие от компании Facebook, где развертывание осуществляется релиз-инженерами, развертывание в компании Etsy может выполнять любой, кто захочет, например разработчик, работник отдела эксплуатации или отдела информационной безопасности. Процесс развертывания стал настолько безопасным и обычным, что и новые специалисты сумеют выполнять его в первый рабочий день, так же как члены правления компании и даже их домашние собачки!Как писал Ноа Сассман, архитектор тестирования компании Etsy, «в восемь утра, когда начинается обычный рабочий день, примерно 15 человек и их псов организуют очередь: все они ждут, чтобы коллективно развернуть до 25 наборов изменений до конца дня».Инженеры, желающие развернуть код, первым делом заходят в чат, где добавляют себя в очередь развертывания, смотрят на активность в процессе развертывания — кто еще находится в очереди, рассылают широковещательные сообщения о своих действиях и получают помощь от других инженеров, если требуется. Когда наступает очередь инженера выполнить развертывание, он получает уведомление в чате.Целью компании Etsy было сделать развертывание в производство легким и безопасным, с наименьшим количеством шагов и минимальным количеством формальностей. Еще до того, как разработчик зафиксирует код, он запустит на своей рабочей станции все 4500 модульных тестов, что займет менее одной минуты. Все вызовы внешних систем, таких как базы данных, закрыты заглушками.После того как инженеры зафиксируют изменения в основной ветке кода, мгновенно запускаются более семи тысяч автоматизированных тестов основной ветке на серверах непрерывной интеграции (CI — continuous integration). Сассман пишет: «Методом проб и ошибок мы пришли к выводу, что примерно 11 минут — это подходящий срок для максимальной продолжительности работы автоматизированных тестов в течение цикла. Это оставляет запас времени на повторный запуск тестов во время развертывания, если что-то сломается, и нужно будет вносить исправления, не выходя слишком далеко за принятый двадцатиминутный лимит времени».Если бы все тесты проводились последовательно, то, как отмечает Сассман, «7000 тестов основной ветки потребовали бы около получаса для своего выполнения. Поэтому мы делим эти тесты на подмножества и распределяем их по 10 серверам в нашем кластере Jenkins [CI]… Разделение тестов на наборы и параллельный их запуск дают нам нужный срок выполнения — 11 минут».
Следующими надо запустить smoke-тесты — тесты системного уровня, запускающие cURL для выполнения тестовых наборов PHPUnit. После этих тестов запускаются функциональные тесты, выполняющие сквозное тестирование GUI на рабочем сервере, содержащем либо тестовую среду, либо предпроизводственную среду (в компании ее называют «принцесса»), фактически представляющую собой производственный сервер, изъятый из ротации, что обеспечивает его точное соответствие производственной среде.
Эрик Кастнер пишет, что, после того как наступает очередь инженера выполнять развертывание, «Вы переходите к программе Deployinator (разработанный в компании инструмент, рис. 19) и нажимаете кнопку, чтобы перевести его в режим тестирования. В этом режиме она посещает “принцессу”… затем, когда код готов к работе в реальной производственной среде, вы нажимаете кнопку Prod, и вскоре ваш код работает в производстве, и все в IRC [канале чата] знают, кто выпустил какой код и опубликовал ссылку на список внесенных изменений. Те, кто отсутствует в чате, получают сообщение по электронной почте с той же информацией».
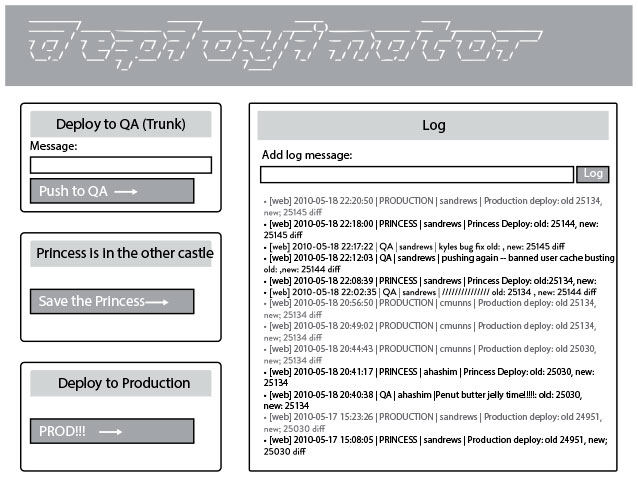
Рис. 19. Консоль программы Deployinator компании Etsy (источник: Erik Kastner, статья Quantum of Deployment на сайте , 20 мая 2010 г., )
В 2009 г. процесс развертывания Etsy вызывал стресс и страх. К 2011 г. он стал обычной операцией, выполняемой от 25 до 50 раз в день, помогая инженерам быстро передать их код в производство, предоставляя ценность клиентам.
Отделить развертывания от релизов
При традиционном запуске проекта разработки программного обеспечения даты релизов определяются нашими маркетинговыми сроками запуска в производство. Накануне вечером мы выполняем развертывание готового программного обеспечения (или настолько близкого к полной готовности, насколько мы смогли этого добиться) в производственную среду. На следующее утро мы объявляем о новых возможностях всему миру, начинаем принимать заказы, обеспечиваем клиентам новые возможности и так далее.
Вместе с тем слишком часто бывает, что дела идут не по плану. Мы можем столкнуться с такими производственными нагрузками, которые никогда не тестировали или даже вовсе их не предполагали. Они серьезно затруднят работу сервиса как для клиентов, так и для самой организации. Что еще хуже, для восстановления сервиса может потребоваться непростой процесс отката или в равной мере рискованная операция fix forward, когда мы вносим изменения непосредственно в производство, а это действительно плохой опыт для работников. Когда все наконец заработает, все сотрудники вздыхают с облегчением и радуются, что релизы ПО и их развертывание в производство происходят нечасто.
Конечно, мы знаем, что для достижения желаемого результата — гладкого и быстрого потока — необходимо выполнять развертывание чаще. Для этого нужно отделить развертывание в производственной среде от релиза версий. На практике слова «развертывание» и «релиз» часто используются как синонимы. Вместе с тем это два различных действия, служащие двум различным целям:
• развертывание — это установка заданной версии программного обеспечения в конкретной среде (например, развертывание кода в среде интеграционного тестирования или развертывание кода в производственной среде). В частности, развертывание может быть, а может и не быть связано с релизом новой функции для клиентов;
• релиз — это когда мы делаем функциональную возможность (или набор возможностей) доступной для всех наших клиентов или клиентам из определенного сегмента (например, мы включаем эту возможность для использования пятью процентами наших клиентов). Наши код и среды должны быть спроектированы таким образом, чтобы при релизе функциональности не требовалось изменение кода нашего приложения.
Другими словами, если мы объединяем понятия развертывания и релиза, это затрудняет оценку успешности результатов, а разделение двух действий усилит ответственность разработчиков и эксплуатации за успех быстрых и частых развертываний, позволяя владельцам продукта отвечать за успешность бизнес-результатов релизов (стоили ли создание и запуск функциональной возможности затраченного времени).
Методы, описанные выше, обеспечивают нам возможность быстрых и частых развертываний в производство созданных разработчиками функциональных возможностей, имея целью сокращение рисков и последствий ошибок развертывания. Остается риск релиза, то есть вопрос, обеспечивают ли функции, запущенные в производство, достижение желаемых заказчиком и нами результатов в бизнесе.
Если развертывание занимает много времени, это определяет, как часто мы можем выпускать на рынок новые возможности нашего ПО. Однако, когда мы получаем возможность выполнять развертывание по требованию, решение, как часто открывать новые возможности для клиентов, становится маркетинговым и бизнес-решением, а не техническим. Существуют две широкие категории принципов выполнения релизов, и мы можем их использовать:
• шаблоны релиза на основе среды: в этом случае мы имеем две или более сред, где выполняется развертывание, но только одна из них получает реальный трафик от клиентов (например, благодаря настройкам средств балансировки нагрузки). Новый код развертывается в среде без реальной нагрузки, и релиз будет произведен перенаправлением трафика к этой среде. Это исключительно эффективные шаблоны, поскольку они обычно не требуют внесения каких-либо изменений в наши приложения. Они включают в себя сине-зеленое (blue-green) развертывание, канареечное развертывание и кластерные иммунные системы (claster immune systems), все они будут обсуждаться ниже;
• шаблоны релизов на основе приложений: в этом случае мы изменяем наше приложение, с тем чтобы мы могли выборочно разблокировать и выпускать отдельные функциональности приложения путем небольших изменений конфигурации. Например, мы можем реализовать флаги функций, чтобы постепенно открывать новые возможности в производственной среде для команды разработчиков, или всех наших сотрудников, или 1 % наших клиентов, или, когда мы уверены в том, что релиз будет работать, как запланировано, для всей нашей клиентской базы. Как обсуждалось ранее, это делает возможным использование метода, называющегося теневым запуском, когда мы запускаем в производственной среде все функциональные возможности и проверяем их на клиентском трафике до релиза. Например, мы можем скрытно проверить новую функциональность на реальном трафике в течение нескольких недель перед запуском для выявления проблем, чтобы их можно было исправить до официального запуска.
Шаблоны релиза на основе среды
Отделение развертывания от релизов значительно изменяет порядок работы. Нам больше не придется выполнять развертывание в ночное время или в выходные дни, чтобы уменьшить риск негативного влияния на работу клиентов. Вместо этого мы можем выполнить развертывание в обычное рабочее время, давая возможность отделу эксплуатации работать тогда же, когда и все другие сотрудники.
В этом разделе основное внимание уделяется шаблонам релиза на основе среды, не требующим внесения изменений в код приложения. Мы можем сделать это за счет нескольких сред, в которых производится развертывание, но только одна получает реальный трафик клиентов. Тем самым мы значительно уменьшаем риск, связанный с передачей релизов в производство, и время развертывания.
Шаблон Blue-Green развертывания
Наиболее простой шаблон из трех называется сине-зеленым развертыванием. В этом шаблоне есть две производственные среды: синяя и зеленая. В любое время только одна обслуживает трафик клиента, на рис. 20 рабочая среда — зеленая.

Рис. 20. Шаблон сине-зеленого развертывания (источник: Джез Хамбл, Дэвид Фарли «Непрерывное развертывание ПО. Автоматизация процессов сборки, тестирования и внедрения новых версий программ»)
Для релиза новой версии сервиса мы развертываем его в неактивную среду, где можно выполнить тестирование, не прерывая работу пользователей. Когда мы уверены в том, что все работает нормально, то выполняем релиз, направляя трафик к голубой среде. Таким образом, эта среда становится рабочей, а зеленая — подготовительной. Откат можно выполнить перенаправлением трафика опять к зеленой среде.
Сине-зеленая схема развертывания — простой шаблон, его также чрезвычайно легко встроить в существующие системы. Он имеет огромные преимущества, например возможность выполнить развертывания в рабочее время и провести простые переналадки (например, изменение настроек маршрутизатора, изменение символьных ссылок) в часы непиковых нагрузок. Одно это может существенно улучшить условия работы команды, выполняющей развертывание.
Управление сменой баз данных
Проблему создает наличие двух версий приложения в производстве, зависящих от общей базы данных: когда при развертывании требуется изменить схему базы данных или в самой базе добавить, изменить либо удалить таблицу или колонку, она не в состоянии поддерживать обе версии приложения. Есть два общих подхода к решению:
• создание двух баз данных (например, синей и зеленой): каждая версия приложения — синяя (старая) и зеленая (новая) — имеет собственную базу данных. В процессе релиза мы ставим синюю базу данных в режим «только для чтения», выполняем ее резервное копирование, восстанавливаем данные в зеленую базу данных и, наконец, переключаем трафик на зеленую среду. Проблема этой модели в том, что, когда нам необходимо вернуться к синей версии, мы потенциально можем потерять транзакции, если только сначала не перенесем их вручную из зеленой версии;
• отделение изменений базы данных от изменений приложения: вместо того чтобы поддерживать две базы данных, мы отделяем релиз изменений в базе данных от релиза изменений в приложении, сделав две вещи. Во-первых, мы делаем только дополнения к нашей базе данных и никогда не видоизменяем существующие объекты базы данных, во-вторых, мы не делаем никаких предположений в нашем приложении о том, какая версия базы данных будет работать в производстве. Это сильно отличается от традиционного отношения к базам данных, то есть установки на то, чтобы избегать дупликации данных. Процесс отделения изменений базы данных от изменений приложения был использован компанией IMVU (и другими) приблизительно в 2009 г., что позволило ей делать 50 развертываний в день, причем некоторые из них требовали изменения базы данных.
Практический пример
Blue-Green развертывание для системы торговых точек компании Dixons Retail (2008 г.)
Джез Хамбл и Дейв Фарли, coавторы книги «Непрерывное развертывание ПО. Автоматизация процессов сборки, тестирования и внедрения новых версий программ», работали над проектом для компании Dixons Retail, большой британской розничной торговой компании, использовавшей тысячи POS-систем, находящихся в сотнях магазинов и работавших под несколькими торговыми марками.Хотя Blue-Green развертывание в основном ассоциируется с онлайновыми веб-сервисами, Норт и Фарли использовали этот шаблон, чтобы значительно снизить риски и потери времени на переналадку при обновлении ПО POS-терминалов.Обычно модернизация систем POS производится водопадным методом, как «большой взрыв»: POS-терминалы клиентов и централизованный сервер обновляются одновременно, что требует продолжительного выключения системы (часто на все выходные дни), а также значительной полосы пропускания сети, чтобы «протолкнуть» новое клиентское программное обеспечение во все розничные магазины. Если не получится провести модернизацию строго по плану, это может очень серьезно нарушить работу магазинов.Если пропускная способность сети недостаточна для одновременного обновления всех POS-систем, то традиционная стратегия невозможна. Чтобы решить эту проблему, была использована Blue-Green стратегия и созданы две производственные версии централизованного серверного программного обеспечения, чтобы обеспечить возможность одновременной поддержки старой и новой версий POS-терминалов клиентов.После того как это было сделано, за несколько недель до запланированного обновления POS-терминалов установщики новых версий клиентского программного обеспечения начали отправлять новое ПО в розничные магазины по медленным сетевым каналам и затем развертывать, пока POS-системы находились в неактивном состоянии. В то же время старые версии постоянно работали в нормальном режиме.Когда все POS-терминалы клиентов были подготовлены к обновлению (обновленный клиент и сервер были успешно протестированы вместе, и новое клиентское программное обеспечение было развернуто у всех клиентов), менеджерам магазинов было предоставлено право решить, когда переходить на новую версию.В зависимости от потребностей бизнеса некоторые менеджеры хотели бы использовать новые функциональные возможности немедленно, в то время как другие предпочитали подождать. В любом случае, независимо от того, выпускались ли новые функциональные возможности в работу немедленно или после ожидания, менеджерам это было гораздо удобнее по сравнению с централизованным выбором отделом эксплуатации единой даты обновления для всех.Результатом был значительно более плавный и быстрый релиз ПО, большая удовлетворенность менеджеров магазинов и гораздо меньшие нарушения обычного хода торговых операций. Кроме того, это применение Blue-Green релиза для приложений в виде толстых клиентов ПК демонстрирует, как методы DevOps могут универсально применяться в различных технологиях, зачастую удивительными способами, но с теми же фантастическими результатами.
Шаблоны канареечных релизов и cluster immune systems
Шаблон Blue-Green релиза прост в реализации и может значительно повысить безопасность релиза программного обеспечения. Существуют варианты этого шаблона, и они могут способствовать дальнейшему повышению безопасности и сокращению времени развертывания с помощью автоматизации, но за это потенциально придется расплачиваться дополнительным усложнением процесса.
Шаблон канареечного релиза автоматизирует процесс релиза, распространяя его последовательно на все более крупные и более критически важные среды, по мере того как мы убеждаемся в том, что код работает, как задумано.
Термин «канареечный релиз» придуман по аналогии с тем, как шахтеры в угольных шахтах брали с собой канареек в клетках, чтобы обнаруживать опасный уровень угарного газа. Если в шахте скапливалось много угарного газа, то он убивал канарейку до того, как становился опасным для шахтеров, и они успевали спастись.
При использовании этого шаблона, когда мы делаем выпуск, то наблюдаем, как программное обеспечение работает в каждой среде. Когда что-то кажется неправильным, мы выполняем откат, в противном случае мы выполняем развертывание в следующей среде.
На рис. 21 показаны группы сред в компании Facebook, созданные для поддержки этого шаблона релизов:
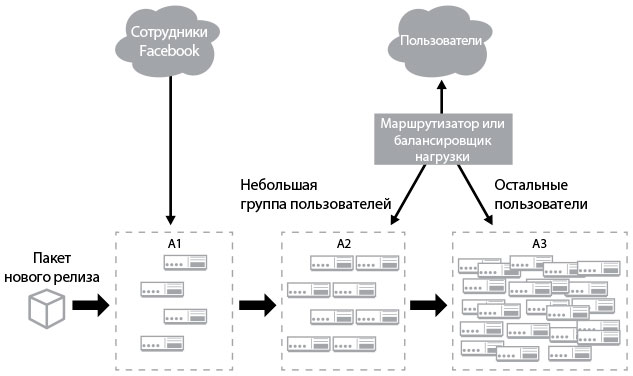
Рис. 21. Шаблон канареечного релиза (источник: Джез Хамбл, Дэвид Фарли «Непрерывное развертывание ПО. Автоматизация процессов сборки, тестирования и внедрения новых версий программ»)
• группа A1: производственные серверы, обслуживающие лишь внутренних сотрудников;
• группа A2: производственные серверы, обслуживающие лишь небольшую долю клиентов. Они развертываются при достижении определенных критериев (автоматически или вручную);
• группа A3: остальная часть производственных серверов, развертывающихся после того, как программное обеспечение на серверах в кластере А2 достигнет определенных критериев приемлемости.
Cluster immune system — расширение шаблона канареечного релиза, в ней системы мониторинга производства связываются с процессами релиза и автоматизируется откат на предыдущую версию кода, если производительность системы со стороны пользователя отклоняется от заданных показателей сильнее, чем ожидается. Например, когда коэффициенты пересчета для новых пользователей падают ниже сложившихся показателей на 15–20 %.
Этот тип защиты имеет два существенных преимущества. Во-первых, мы получаем защиту от дефектов. Их трудно найти с помощью автоматизированных тестов, скажем, изменения некоторых важных невидимых элементов веб-страницы (например, изменение CSS). Во-вторых, сокращается время, необходимое для обнаружения того, что в результате изменений снизилась производительность, и реагирования на это.
Шаблоны релиза на основе приложений обеспечивают более безопасный релиз
В предыдущем разделе на основе среды мы создали шаблоны, позволившие отделить развертывание от релиза посредством использования нескольких сред и коммутации потока реальных данных на ту или иную среду, что может быть полностью реализовано на уровне инфраструктуры.
В этом разделе мы опишем шаблоны релиза на основе приложений, которые можем реализовать в нашем коде, обеспечивая еще большую гибкость при безопасном релизе новых возможностей для наших клиентов, зачастую даже выпуская каждую функциональную возможность отдельно. Поскольку шаблоны релиза на основе приложений реализуются в самих приложениях, это требует участия разработчиков в данном процессе.
Реализация переключателей функциональности
Основной способ внедрения шаблонов релиза на основе приложений и приложения на основе потребления — реализация переключателей функциональности, предоставляющей механизм для выборочного включения и отключения функции без развертывания кода в производственную среду. С помощью переключателей можно также управлять тем, какие функции видны и доступны конкретным сегментам пользователей (например, внутренним сотрудникам, отдельным сегментам клиентов).
Переключатель функциональности возможностей обычно реализуется через управление логикой работы приложений или элементов интерфейса с помощью условного оператора, включающего или отключающего функцию на основе параметра конфигурации, хранящегося где-то в системе. Это может быть просто файл конфигурации приложения (например, файлы конфигурации в форматах JSON, XML), либо он может быть реализован с помощью службы каталогов или даже веб-службы, специально разработанной для управления функцией переключения.
Переключение функциональных возможностей также дает возможность делать следующее:
• легко выполнять откат: функциональные возможности, создающие проблемы или нарушающие работу производственной среды, могут быть быстро и безопасно отключены простым изменением параметра функции переключения. Это особенно ценно, когда развертывания выполняются нечасто — выключение одной конкретной возможности, мешающей какой-то из заинтересованных сторон, обычно намного проще, чем откат всего релиза;
• ненавязчиво ухудшить производительность: если наши сервисы испытывают сильную нагрузку, что в обычных условиях требует от нас увеличения мощности оборудования или, что еще хуже, способно привести к сбоям в обслуживании, мы можем использовать переключение функциональных возможностей для снижения качества обслуживания. Другими словами, мы можем увеличить число пользователей, получающих ухудшенную функциональность (например, уменьшаем число клиентов, которые могут получить доступ к определенным возможностям, отключив функциональности, интенсивно использующие процессор, такие как рекомендации, и так далее);
• увеличить устойчивость нашей службы благодаря использованию сервис-ориентированной архитектуры: если у нас есть функциональность, опирающаяся на другой сервис, разработка которой еще не завершена, то мы все же можем развернуть нашу новую функциональность в производстве, но скрыть ее с помощью переключателя возможностей. Когда служба станет наконец доступной, мы можем включить эту функциональность. Аналогичным образом, если служба, от которой мы зависим, дает сбой, можно отключить функциональность для предотвращения ее вызовов клиентами, сохраняя в то же время остальную часть приложения работающей.
Чтобы мы могли находить ошибки в функциональных возможностях, использующих переключатели функциональности, автоматизированные приемочные тесты должны работать, когда включена полная функциональность (мы должны также убедиться, что наши переключатели функциональностей работают правильно!).
Переключатели функциональности позволяют выполнять раздельно развертывание кода и релиз новых функций. Далее в книге мы используем его для разработки, управляемой гипотезами, и A/B-тестирования, еще более развивая нашу способность достичь желаемых результатов в бизнесе.
Выполняйте теневые запуски
Переключатели функциональности позволяют развертывать новые функции в производственную среду, не делая их доступными для пользователей, то есть применяя метод, известный как теневой запуск. В этом случае мы развертываем все функциональные возможности в производственную среду и затем выполняем тестирование их работоспособности, пока они невидимы для клиентов. В случае крупных или рискованных изменений мы часто делаем развертывание за несколько недель до запуска в производственную среду, что дает нам возможность безопасного тестирования с ожидаемыми нагрузками, близкими к производственным.
Предположим, мы выполнили теневой запуск новой функциональной возможности. Она представляет собой значительный риск при релизе — это могут быть новые возможности поиска, процессы создания учетной записи или новые запросы к базе данных. После того как весь код находится в производственной среде, а новая функциональность отключена, мы можем изменить код сессии пользователя, чтобы он выполнял вызовы новых возможностей, однако, вместо того чтобы отображать пользователю результаты этих функций, мы журналируем их или просто отбрасываем.
Например, можно включить одному проценту наших пользователей, работающих в данный момент с сайтом, невидимые вызовы новой функциональности, которую мы собираемся зарелизить, чтобы увидеть, как она работает под нагрузкой. Выявив проблемы и устранив их, постепенно увеличим имитацию нагрузки за счет увеличения частоты вызовов и количества пользователей, проверяющих новую функциональность. Сделав это, можно безопасно имитировать нагрузки, близкие к производственным, и получить уверенность, что наш сервис будет работать так, как и должен.
Кроме того, запуская функциональность, мы можем постепенно выкатывать ее для небольших сегментов клиентов, приостанавливая релиз при обнаружении каких-либо проблем. Так мы сводим к минимуму число клиентов, получающих доступ к функциональности и сразу видящих, что она исчезла, если мы находим дефект или не в состоянии поддерживать требуемый уровень производительности.
В 2009 г., когда Джон Олспоу был вице-президентом отдела эксплуатации компании Flickr, он писал руководству компании Yahoo! о процессе теневого запуска: при таком процессе «увеличивается уверенность каждого работника почти до безразличия, если говорить о страхе перед возникновением проблем, связанных с нагрузкой на сервис. Я не имею представления, сколько развертываний кода в производство было выполнено в любой из дней в течение последних пяти лет, ведь в большинстве случаев я не беспокоился об этом, поскольку эти изменения сопровождались очень низкой вероятностью появления каких-либо нежелательных последствий. Если эти последствия все же проявлялись, любой из работников Flickr мог найти на веб-странице сведения о том, когда были внесены изменения, кто их внес, и точно узнать (строчка за строчкой), что именно было изменено».
Позднее, создав отвечающую нашим требованиям телеметрию в наших приложениях и средах, мы сможем обеспечить более быструю обратную связь для проверки сделанных нами предположений и бизнес-результатов сразу после развертывания функциональности в производство.
При этом не надо ждать, пока произойдет релиз в стиле «большого взрыва», чтобы проверить, действительно ли клиенты хотели бы использовать созданные нами функциональные возможности. Вместо этого к моменту объявления о релизе крупного обновления мы уже проверили бизнес-гипотезы и выполнили бесчисленное множество экспериментов по постоянному совершенствованию продукта с реальными клиентами, что помогло подтвердить: функциональности будут способствовать достижению клиентом желаемых результатов.
Практический пример
Теневой запуск чата Facebook (2008 г.)
На протяжении почти десятилетия Facebook был одним из наиболее широко посещаемых интернет-сайтов по критериям числа просмотренных страниц и уникальных пользователей сайта. В 2008 г. он насчитывал более 70 миллионов активных пользователей, ежедневно посещающих сайт, что создало определенные проблемы для группы, разрабатывающей новую функциональность — чат Facebook.Евгений Летучий, инженер команды, разрабатывавшей чат, писал о том, как количество одновременных пользователей создало огромную проблему для разработчиков ПО: «Наиболее ресурсоемкой операцией, выполнявшейся в системе чата, была отнюдь не отправка сообщений. Нет, это было отслеживание для каждого пользователя состояния всех его друзей — “в сети”, “нет на месте”, “не в сети”, — чтобы можно было начать разговор».Реализация этой требующей больших вычислительных мощностей функции было одним из крупнейших технических начинаний за всю историю Facebook, она заняла почти год. Сложность проекта была отчасти обусловлена широким набором технологий, необходимых для достижения требуемой производительности, в том числе C++, JavaScript и PHP, а также тем, что они впервые использовали в серверной инфраструктуре язык Erlang.После года энергичной работы команда разработки чата зафиксировала свой код в системе контроля версий, после чего он стал развертываться в производство по крайней мере один раз в день. Сначала функциональность чата была видна только команде чата. Позднее она стала видимой для всех внутренних сотрудников компании, но была полностью скрыта от внешних пользователей Facebook с помощью Gatekeeper, службы переключения функций компании Facebook.В рамках теневого запуска каждый пользовательский сеанс Facebook, запускающий JavaScript в пользовательском браузере, загружал в него тестовую программу: элементы пользовательского интерфейса чата были скрыты, но клиент-браузер мог посылать невидимые сообщения тестового чата на уже развернутый в производственной среде сервис, позволяя имитировать производственные нагрузки во всем проекте, находить и устранять проблемы с производительностью задолго до выпуска клиентского релиза.При этом каждый пользователь Facebook — участник программы массового нагрузочного тестирования, позволившей команде обрести уверенность, что системы могут обрабатывать реальные производственные нагрузки. Релиз чата и запуск его в производство требовали только двух действий: изменения настроек конфигурации Gatekeeper, чтобы сделать функцию чата видной некоторой части внешних пользователей, и загрузки пользователями Facebook нового кода JavaScript, обрабатывающего UI-чат и отключающего невидимое средство тестирования. Если бы что-то пошло не так, двух шагов было бы достаточно для отката изменений. Когда наступил день запуска чата Facebook, все прошло удивительно успешно и спокойно: без особых усилий чат был масштабирован от нуля до 70 миллионов пользователей за одну ночь. В процессе релиза функциональность чата постепенно включалась для все большего количества пользователей, сначала для внутренних сотрудников Facebook, затем для 1 % клиентов, затем для 5 % и так далее. Как писал Летучий, «секрет перехода от нуля к семидесяти миллионам пользователей за одну ночь — ничего не делать с наскока».
Обзор непрерывной доставки и непрерывного развертывания на практике
В уже упоминавшейся книге «Непрерывное развертывание ПО. Автоматизация процессов сборки, тестирования и внедрения новых версий программ» Джез Хамбл и Дэвид Фарли дали определение термина «непрерывная доставка». Термин «непрерывное развертывание» был впервые упомянут Тимом Фицем в записи блога «Непрерывное развертывание в IMVU: делаем невозможное — 50 развертываний в день». Однако в 2015 г. в ходе работы над этой книгой Джез Хамбл прокомментировал: «В последние пять лет наблюдается путаница вокруг терминов “непрерывная доставка” и “непрерывное развертывание”, и, безусловно, мои собственные идеи и определения изменились со времени написания книги. Каждая организация должна создавать свои варианты методов, исходя из того, в чем она нуждается. Область нашего внимания, ключевые моменты — не форма, а результаты: развертывание должно проходить с низким уровнем риска и запускаться одним нажатием кнопки по требованию».
Его обновленные определения непрерывной доставки и непрерывного развертывания звучат так:
«Когда все разработчики работают с небольшими заданиями в основной ветке кода или все работают вне основной ветки над недолго живущими ветками функций, регулярно объединяемыми с основной, и когда основная ветка постоянно поддерживается в состоянии готовности к развертыванию и мы можем делать релизы кода по требованию одним нажатием кнопки в обычное рабочее время, — мы делаем непрерывную доставку. Если разработчики допускают регрессионные ошибки, включающие дефекты, проблемы производительности, вопросы безопасности, перебои в работе и так далее, то они быстро получают обратную связь. Когда такие проблемы обнаруживаются, они немедленно исправляются, так что основная ветка всегда находится в готовности к развертыванию.В дополнение к сказанному выше, когда мы развертываем хорошие сборки в производственную среду на регулярной основе и с помощью самообслуживания (развертывание выполняет либо разработчик, либо отдел эксплуатации), это обычно означает, что мы выполняем развертывание в производство по крайней мере один раз в день на каждого разработчика или, возможно, даже автоматически развертываем каждое изменение кода, зафиксированное разработчиком, — все это означает, что мы вовлечены в режим непрерывного развертывания.
Определенная таким образом непрерывная доставка — необходимое условие для обеспечения непрерывного развертывания, так же как непрерывная интеграция — необходимое условие для непрерывной доставки. Непрерывное развертывание удобно преимущественно в контексте веб-сервисов, предоставляемых через интернет. Однако непрерывная доставка может применяться почти в любом контексте, где мы хотим получить развертывания и релизы высокого качества, быстро выполняемые и обеспечивающие весьма предсказуемые результаты с низким риском, в том числе встраиваемые системы, готовые коммерческие компоненты и мобильные приложения.
В компаниях Amazon и Google большинство команд практикуют непрерывную доставку, хотя некоторые выполняют непрерывное развертывание: имеются существенные различия между командами в том, как часто они развертывают код и каким образом выполняются развертывания. Команды имеют право на выбор способа развертывания исходя из управляемых рисков. Например, команда Google App Engine часто выполняет развертывание один раз в день, в то время как Google Search — несколько раз в неделю.
Аналогично в большинстве примеров, представленных в этой книге, используется непрерывная доставка: это разработка встроенного программного обеспечения принтеров HP LaserJet, система печати счетов компании CSG, работающая на 20 технологических платформах, включая приложения для мейнфреймов, написанные на языке COBOL, разработки компаний Facebook и Etsy. Эти же шаблоны могут использоваться для разработки программного обеспечения, работающего на мобильных телефонах, наземных станциях управления космическими спутниками и так далее.
Заключение
Как показывают приведенные выше примеры из деятельности компаний Facebook, Etsy и CSG, релизы и развертывания не обязательно должны иметь высокую степень напряженности и требовать драматических усилий десятков или сотен инженеров, работающих в круглосуточном режиме, чтобы завершить эти операции. Вместо этого они могут быть рутинными как часть повседневной работы.
При этом мы можем сократить время развертывания с месяца до нескольких минут, позволяя нашим организациям быстро доставлять ценность клиентам, не вызывая хаоса и сбоев в работе. Кроме того, обеспечив совместную работу разработчиков и отдела эксплуатации, мы можем в конечном счете сделать условия работы этого отдела более гуманными.
Назад: Глава 11. Запустить и практиковать непрерывную интеграцию
Дальше: Глава 13. Архитектура низкорисковых релизов

