Книга: От атомов к древу. Введение в современную науку о жизни
Назад: ЧАСТЬ II МЕХАНИЗМ ЖИЗНИ
Дальше: 10. эукариотная клетка
9. генетическая информация
И если бы самому ему пришло в голову задаться вопросом, почему, например, дети похожи на родителей, он бы только подивился неожиданному баловству мысли, узревшей вопрос в естественном порядке вещей, а искать ответ он бы даже не попытался.Аркадий и Борис Стругацкие. Отягощенные злом, или сорок лет спустя
О том, что наследственность существует, люди знали всегда. Признаки передаются от предков к потомкам и у человека, и у животных, и у растений. Простой крестьянин, живший век или два назад, мог не иметь ровно никаких теоретических представлений об устройстве природы, но уж то, что детям положено быть похожими на родителей, он знал твердо. И это имело для него ясное практическое значение: в русских деревнях невесту присматривали “по породе”, стремясь, чтобы у нее в роду не было наследственных заболеваний, калек или сумасшедших. Не менее наглядным был опыт разведения домашних животных и растений. Никто из людей, имевших хоть какое-то отношение к сельскому хозяйству, в существовании наследственности не сомневался.
Примечательно, что ни в одном из трех дореволюционных изданий словаря Даля слова “наследственность” все же нет. Очевидно, народному сознанию это явление представлялось настолько естественным, что особое обозначение для него не требовалось. Скорее наоборот, удивление вызывали слишком явные отклонения от точного наследования (мол, “в кого ты такой уродился?”). Для подобных отклонений в науке придумано понятие “изменчивость”. В целом — на это стоит обратить внимание — о наследственности обычно говорят в том случае, если она хотя бы потенциально не является абсолютно точной, то есть если хоть какая-то изменчивость все же налицо. Эти понятия — взаимодополняющие.
Любому, кто пытался осмыслить явление наследственности, было ясно: дети получают от своих родителей нечто, решающим образом влияющее на их качества. Как же это “передаваемое нечто” можно назвать? Отец биологических наук Аристотель воспользовался тут довольно сложным понятием “энтелехия”. Аристотелевская энтелехия — это нематериальная сущность, определяющая форму и структуру развивающегося организма. Жизнь этой концепции оказалась очень долгой, некоторые биологи обращались к ней еще в первой половине XX века. Но сейчас энтелехию окончательно вытеснило другое понятие, гораздо более четкое: наследственная информация.
Почему энтелехия исчезла из науки? Не в последнюю очередь потому, что ее так никто никогда и не сумел количественно измерить. Информация же вполне измерима, о чем прекрасно знает любой пользователь современного компьютера. А ведь наследственная информация по своей природе ничем принципиально не отличается от той, которая записывается и копируется в технических устройствах.
Есть два способа записи информации — аналоговый и цифровой. При аналоговой записи кодирующий параметр может меняться сколь угодно постепенно: например, форма звуковой дорожки на виниловой пластинке (если в наше время еще кто-нибудь помнит, что это такое) повторяет форму той самой звуковой волны, которую нужно записать. При цифровой записи кодирующий параметр может принимать всего несколько строго определенных значений безо всяких промежутков между ними. Предельный случай цифровой записи — это двоичный код, где кодирующий параметр может принимать всего два значения: или 0, или 1. Технология записи обычного текста — тоже типично цифровая. Есть строго определенный набор букв, промежуточные состояния между которыми не предусматриваются.
Важнейший для понимания всей современной биологии факт состоит в следующем: наследственная информация — цифровая. В XVIII веке об этом догадался французский физик Пьер Луи Моро де Мопертюи. А через 100 лет к тому же выводу пришел всем известный Грегор Мендель — тоже физик, но увлекшийся ботаникой и ставший в ней первоклассным специалистом. Причем если Мопертюи опирался на наблюдения, то Мендель доказал цифровой характер наследственной информации уже экспериментально. Конечно, ни Мопертюи, ни Мендель не знали терминов, которые мы сейчас употребляем, но с нашей формулировкой насчет цифровой записи они наверняка согласились бы.
Отступление об основателях
Пьер Луи Моро де Мопертюи был одним из самых блестящих умов французского Просвещения. Он не преподавал в университетах, не имел профессорского звания, а просто занимался наукой в свое удовольствие, время от времени публикуя результаты исследований. И это очень рано сделало его известным ученым и членом нескольких академий — в XVIII веке такое еще было вполне возможно. Именно Мопертюи получил решающие данные о форме Земли, доказав, что она представляет собой сплюснутый с полюсов эллипсоид вращения, как и было несколько ранее предсказано Ньютоном. Мопертюи открыл (и математически обосновал) принцип наименьшего действия — один из самых общих принципов физики, оказавшийся полезным для вычислений как в механике, так и в оптике. Убежденный космополит, Мопертюи по приглашению короля Фридриха Великого переехал из Парижа в Берлин и там стал президентом Прусской академии наук. Это создало ему большие проблемы на родине через несколько лет, когда началась Семилетняя война между Францией и Пруссией, — увы, жизнь мыслителей в разделенном мире редко бывает безоблачной. Умер он в возрасте 61 года в эмиграции, в Базеле, в 1759 году, военные события которого, по мнению многих историков, определили поражение Франции в борьбе за мировое господство.
Заинтересовавшись теорией наследственности, Мопертюи не стал пытаться разглядывать структуру клеток под микроскопом: он прекрасно понимал, что текущее состояние естественных наук не позволит там ничего толком разобрать. Он выбрал совершенно другой путь, а именно занялся исследованием человеческих родословных. Фактически он применил известный кибернетический принцип “черного ящика”: если мы и не можем пока вскрыть механизм наследственности, то некоторые его черты наверняка можно будет описать, если аккуратно сопоставить данные “на входе” и “на выходе”.
Прежде всего Мопертюи показал, что наследственные качества совершенно равноправно передаются потомкам от обоих родителей. Это называлось бипарентальной теорией наследственности, и в XVIII веке в этом были убеждены далеко не все. Одни ученые считали, что зародыш получает наследственные качества в основном от отца (анималькулисты), другие — что в основном от матери (овисты). Мопертюи с фактами в руках опроверг обе эти теории. Что же касается его собственных взглядов на наследственность, то их можно сформулировать в нескольких пунктах.
* Предки передают потомкам наследственное вещество, состоящее из материальных частиц (“задатков”), между которыми существует химическое сродство еще неизвестного типа. Эти частицы являются носителями памяти. Для каждой части организма существует своя наследственная частица, определяющая свойства этой части.* При размножении организмов наследственные частицы по каким-то еще не известным закономерностям расходятся и комбинируются заново.* В одном организме могут сочетаться разные наследственные частицы, контролирующие один и тот же признак. В этом случае одна частица может “перекрывать” (l'emporte) влияние другой. Здесь Мопертюи открыл явление, которое Мендель в следующем веке назовет доминированием.* Комбинация наследственных частиц при возникновении нового организма может быть неточной. Если какая-то частица потеряна, возникает урод, лишенный соответствующего органа (monstre par defaut). Если какая-то частица лишняя, то возникает урод с избыточными органами (monstre par exces). Здесь пока можно лишь сказать, что современная генетика действительно знает подобные эффекты.* Спонтанные изменения наследственных частиц могут мгновенно создавать новые наследуемые признаки. Хорошей иллюстрацией тут послужило явление человеческой многопалости. У двух нормальных родителей, не имевших в обозримом прошлом никаких многопалых предков, может внезапно родиться ребенок с многопалостью, которая потом оказывается наследственной. Документально подтвердив такой случай, Мопертюи фактически открыл мутации (хотя этого термина тогда еще не было).* При скрещиваниях могут создаваться новые сочетания наследственных частиц и, тем самым, новые разновидности организмов. Именно это делает человек при разведении домашних животных и растений. Нет никаких оснований считать, что те же самые процессы не происходят в дикой природе. Здесь у Мопертюи теория наследственности естественным образом переходит в теорию эволюции: получается, что одного без другого не бывает. Насколько мы сейчас понимаем, это абсолютно верно. Хотя даже ученые XIX–XX веков, знавшие гораздо больше, чем Мопертюи, пришли к этой мысли далеко не сразу.
Интересно, что Мопертюи не допускал никакого наследования благоприобретенных признаков, в отличие от многих ученых XIX и даже XX веков, державшихся так называемого ламаркизма — версии эволюционной теории, согласно которой приобретенные полезные признаки постепенно, в ряду поколений, трансформируются в наследственные. Это особенно важно для Франции, где ламаркизм долгое время был очень влиятелен. На самом деле “мопертюистская” традиция старше ламаркистской. Именно ее по большому счету и продолжает современная генетика.
Есть версия, что Пьер Луи Моро де Мопертюи послужил одним из прототипов доктора Моро, героя знаменитого романа Уэллса “Остров доктора Моро”. Прямых доказательств этому нет, но совпадение первой части фамилии — Моро — с фамилией доктора, скорее всего, не случайно. И атмосфера в этом романе в целом подходящая.
Итак, Мопертюи первым пришел к выводу, что материальная основа наследственности (какой бы она ни была) образована дискретными частицами, которые не смешиваются между собой. В XIX веке это было подтверждено экспериментально. Например, французский ботаник Огюстен Сажрэ скрещивал дыни разных сортов, отличающихся друг от друга формой плодов. Поначалу Сажрэ ожидал, что у межсортовых гибридов форма плодов будет какой-нибудь промежуточной. Вместо этого оказалось, что у разных особей гибридов встречаются признаки, свойственные или одному, или другому исходному сорту, и эти признаки как бы “конкурируют” между собой в ряду поколений, переходных же состояний между ними нет. Эти и другие данные убедили Сажрэ, что наследственные качества определяются некими устойчивыми единицами (он называл их “зачатками”), которые не могут сливаться или смешиваться. Передаваясь от родителей к детям, они вступают в самые разные комбинации, но сами по себе остаются стабильными, примерно как атомы в химических реакциях.
Через 20 лет после Сажрэ австриец Грегор Мендель продемонстрировал в серии аккуратнейших опытов, что такой механизм наследственности действительно работает — по крайней мере, у некоторых растений. Более того, Мендель показал, что знание этого механизма позволяет делать проверяемые количественные предсказания. “Задатки” Мопертюи, “зачатки” Сажрэ или “факторы” Менделя — это разные названия для дискретных частиц наследственности, в некотором смысле эквивалентных буквам, составляющим текст; недаром в классической генетике их именно буквами и обозначали. Любая отдельно взятая частица такого типа либо унаследована данным организмом, либо нет. Это и есть цифровой способ передачи информации.
Закончить этот разговор, как всегда, можно подходящей цитатой из Станислава Лема. В его рассказе “Одиссей из Итаки” говорится о вымышленном (к сожалению) ученом, который пришел к идее цифровой записи наследственной информации еще в начале эпохи Возрождения:
“...Есть среди них увесистый том некоего Мираля Эссоса из Беотии, который изобретательностью превзошел Леонардо да Винчи; после него остались проекты логической машины из спинного мозга лягушек; задолго до Лейбница он додумался до идеи монад и предустановленной гармонии; он применил трехценностную логику к некоторым физическим феноменам; он утверждал, что живые существа рождают подобных себе потому, что в их семенной жидкости содержатся письма, написанные микроскопическими буковками, и комбинации таких “писем” определяют строение взрослой особи; все это — в XV веке”.
Вот с теми самыми “микроскопическими буковками”, которыми написаны эти “письма”, мы сейчас и познакомимся.
Атомы наследственности
Открытия Мопертюи, Сажрэ и Менделя были несовершенны в одном важном для нас аспекте. Частицы, которые они принимали за элементарные единицы наследственности, таковыми на самом деле вовсе не были. Все эти “задатки” и “факторы” вполне поддаются дроблению на более мелкие части (как мы сейчас совершенно точно знаем). В XIX веке просто не существовало методов, позволяющих это увидеть. А вот в XX веке, с началом так называемых исследований тонкой структуры гена, сразу стало ясно, что “атомы наследственности” — если они и есть в природе — должны быть гораздо мельче.
И все-таки сторонники дискретности оказались в конечном счете правы. Неделимые носители наследственной информации действительно существуют. Это — нуклеотиды. Вот они-то и есть те самые “буквы”, которыми написан генетический текст. Надо заметить, что нуклеотид — это достаточно крупная молекула по меркам обычной химии (см. главу 7). И если его расщепить на части, то они носителями наследственной информации уже не будут. Таким образом, “атом наследственности” можно считать обнаруженным.
В оправдание исследователей прошлых веков надо сказать, что они очень многое угадали верно. Дело в том, что дискретность существует на разных уровнях. Нуклеотиды объединяются в гораздо более крупные комплексы, которые бывают чрезвычайно устойчивыми и очень часто (хотя и не всегда!) в самом деле ведут себя как независимые друг от друга единицы. Вот именно это явление и зафиксировал Мендель. Ну а о существовании самих нуклеотидов ни он, ни тем более его предшественники не имели никакого понятия: время для этого еще не пришло.
Зато к середине XX века биохимики со всей определенностью выяснили, что главным носителем наследственной информации служит ДНК (см. главу 8). Молекула ДНК — это, попросту говоря, длинная цепочка нуклеотидов, которые бывают четырех типов: адениновый (А), тиминовый (Т), гуаниновый (Г) или цитозиновый (Ц). Итак, генетический “алфавит” — четырехбуквенный. В общем-то, ничего особенного. В двоичном коде всего две “буквы”, в наиболее ходовой версии латинского алфавита 26, ну а здесь четыре.
Цепочка ДНК вполне подобна тексту, где записана некая информация четырехбуквенным алфавитом. С той особенностью, что эта цепочка — двойная. Надо, впрочем, заметить, что такая особенность не является абсолютно необходимой для хранения генетической информации: она просто полезна, но не больше. Дублирование молекулы ДНК заметно повышает надежность системы (если одна цепь почему-то разрушится — есть вторая), но ничего не прибавляет к самому содержанию записанных нуклеотидным текстом сообщений.
Однако что же это за сообщения? Как раз к тому времени, когда биологи выяснили генетическую роль ДНК, ответ (полученный другими биологами и оказавшийся правильным) был готов. Крупные устойчивые комплексы нуклеотидов — гены — должны каким-то образом нести информацию о структуре белков, тех самых огромных молекул, которые делают в клетке почти все (см. главу 3). Множество генов (геном) некоторым неизвестным нам пока способом определяет собой множество белков (протеом). Вот именно этот вывод и оформился в сознании биологов к середине 1950-х годов.
Тут надо оговориться, что геном — это вообще-то не только набор генов. В геномах обычно есть и другие участки ДНК, ни в какие гены не входящие (но они нас пока не интересуют). Что касается самих генов, то каждый из них включает тысячи нуклеотидов, а очень часто и десятки тысяч. Целые геномы обычно состоят из миллионов нуклеотидов, а иногда и из миллиардов. И в принципе все эти нуклеотиды можно пересчитать, современные биохимические методы вполне позволяют это сделать.
Как же геном кодирует белки?
Начнем с того, что любой белок — это цепочка аминокислот. Причем всегда линейная, то есть неветвящаяся. Именно здесь это становится очень важно. Порядок аминокислот в цепочке называется первичной структурой белка (см. главу 3). Все остальные уровни структуры — вторичная, третичная и четвертичная — относятся уже к сворачиванию аминокислотной цепи в объеме, в трехмерном пространстве.
И вот тут возникает важнейший факт, который вообще-то относится к физической химии, но — внезапно — оказывается ключевым для понимания такой тонкой материи, как наследственность. Факт этот следующий. Первичная структура белка (то есть аминокислотная последовательность), как правило, однозначно определяет все остальные уровни его структуры, то есть всю укладку молекулы в объеме. Именно поэтому простая линейная последовательность нуклеотидов — иначе говоря, нуклеотидный текст — может полностью определить все свойства любой сколь угодно сложной белковой молекулы. Ведь первичная структура такой молекулы тоже линейна, и ее тоже можно считать текстом. Только вот “буквы” в этих текстах разные.
И перед нами немедленно возникает следующий вопрос: каким образом нуклеотидный “алфавит” переводится в аминокислотный?
Генетический код
Пока большинство биологов считало гены белками, все было относительно просто. Белок, как мы знаем, представляет собой линейную цепочку аминокислот, которые могут чередоваться в любом порядке. Двадцать аминокислот — это количество, вполне сравнимое с количеством букв в каком-нибудь древнем алфавите, вроде греческого или финикийского. Такая система кодирования позволяет хранить любую информацию не хуже, чем в обычной книге. Получается, что “белок является как бы длинным предложением, записанным с помощью двадцати букв”.
Правда, надо тут же заметить, что до открытия великой двойной спирали практически никто из биологов в таких понятиях не рассуждал. Перейти с привычного “аналогового” языка традиционной биологии на “цифровой” язык новой биологии, изучающей информационные процессы, им и в дальнейшем было непросто. Многим даже очень крупным ученым, профессионально сложившимся до 1953 года, это вообще так никогда и не удалось. Идея цифровой записи наследственной информации вживалась в биологию с удивительным трудом, несмотря на то что со времен работ Менделя к тому времени прошло уже почти 100 лет. Впору предположить, что эта идея противоречила какой-то фундаментальной особенности склада ума большинства людей, выбиравших биологию своей профессией.
Так или иначе после открытия генетической роли ДНК все заметно усложнилось. Стало понятно, что “базой данных”, хранящей последовательности белков, служит не какой-то особый белок, специально приспособленный для записи информации (как это вполне можно было бы вообразить), а совершенно другой полимер, резко отличающийся от белка химически и к тому же содержащий всего-навсего четыре типа мономеров вместо 20. Так возникла проблема перекодировки, или, в более привычных нам терминах, проблема генетического кода.
Тут обязательно нужно пояснение. В сети и публицистике довольно часто встречается мнение, будто генетический код — примерно то же самое, что и генетическая информация. Так вот, это совершенно неправильно. Код — это не сама информация, а словарь, с помощью которого ее можно прочитать. Или более строго: генетический код — это способ перевода друг в друга текстов, записанных с помощью двух разных алфавитов — нуклеотидного и аминокислотного. Своего рода шифровальный ключ. Последнее — даже не метафора: первые теоретики, писавшие о генетическом коде, сразу предложили использовать для его расшифровки математический аппарат криптографии, благо эта наука после Второй мировой войны была развита отлично.
Итак, чего стоит ожидать от генетического кода? У тех ученых, которые сразу после открытия двойной спирали ДНК первыми занялись этим вопросом, получилось примерно следующее:
* аминокислот в составе белков 20, а разновидностей нуклеотидов в ДНК всего четыре. Значит, каждая аминокислота должна кодироваться не одним нуклеотидом, а неким их сочетанием. Примерно так, например, вводятся с помощью клавиш китайские и японские иероглифы;* отличающихся друг от друга двоек нуклеотидов (дублетов) может существовать максимум 16. Для кодирования всех аминокислот этого не хватит. Значит, генетический код должен быть как минимум триплетным;* отличающихся друг от друга троек нуклеотидов (триплетов) может существовать максимум 64. То есть их намного больше, чем аминокислот. Значит, каждая аминокислота, скорее всего, кодируется не одним триплетом, а несколькими разными. Таким образом, надо ожидать, что генетический код — избыточный (иногда это называют заимствованным из квантовой физики термином “вырожденный”).
Человека, который первым опубликовал эти соображения, звали Георгий Антонович Гамов. Это был крупный физик-теоретик, причастный к созданию теории Большого взрыва. Занятия биологией для него были эпизодом, но очень плодотворным. Гамов вычислил “на кончике пера” основные параметры генетического кода, и вскоре эксперименты показали, что предсказал он их в основном правильно.
Почти одновременно с Гамовым и, похоже, даже немного раньше очень сходные выкладки совершенно независимо подготовил другой ученый — молодой советский эмбриолог Александр Александрович Нейфах. Но его статью не приняли к публикации! “Редакция “Известий Академии наук. Серия биологическая” отклонила статью, сославшись на то, что формальные математические соображения неприменимы к такой самобытной науке, как биология”. Эта история как нельзя лучше показывает, насколько трудно было подавляющему большинству биологов переключиться с “аналогового” мышления на “цифровое”. А Нейфах в результате остался без приоритета, и вся советская наука вместе с ним. После Гамова публиковать статью с теми же расчетами было уже бессмысленно.
“Самым трудным в проблеме кода было понять, что код существует, — писал соавтор Гамова Мартинас Ичас. — На это потребовалось целое столетие. Когда это поняли, то для того, чтобы разобраться в деталях, хватило каких-нибудь десяти лет”.
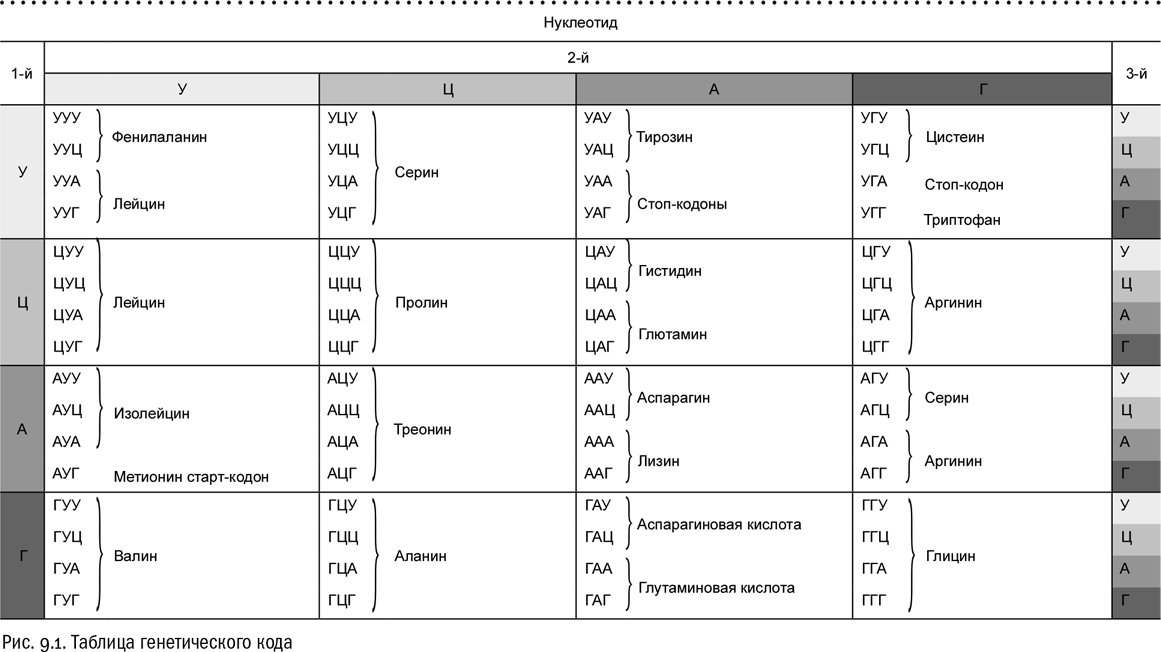
Полный генетический код выглядит достаточно просто. Это таблица из 64 ячеек, в каждой из которых значится определенная тройка нуклеотидов (вернее, азотистых оснований, входящих в их состав, — ведь все остальные части в нуклеотидах, составляющих ДНК, одинаковы). Эти тройки называются кодонами. Генетический код состоит из 61 кодона, кодирующего аминокислоты, и трех стоп-кодонов, на которых синтез белковой цепи останавливается. Есть всего две аминокислоты, кодирование которых не является избыточным, то есть подчиняется правилу “одна аминокислота — один кодон”. Это метионин и триптофан. Любая другая аминокислота кодируется как минимум двумя разными кодонами. Многие аминокислоты кодируются четырьмя кодонами, а некоторые даже шестью.
Кодоны, кодирующие одну и ту же аминокислоту, называются синонимичными. Например, кодон ТТТ (три тимина подряд) кодирует аминокислоту фенилаланин, и кодон ТТЦ (тимин-тимин-цитозин) — тоже. Довольно часто (но не всегда!) бывает, что синонимичные кодоны отличаются друг от друга только последней “буквой”, как мы это в случае с фенилаланином и видим.
Вместо тимина (Т) в таблице генетического кода можно везде поставить урацил (У) и наоборот (см. рис. 9.1). Эти два азотистых основания в данном контексте взаимозаменяемы. Дело в том, что они очень похожи друг на друга по структуре: урацил, так же как и тимин, может комплементарно спариваться с аденином, и только с ним. Единственная метильная группа, которой тимин отличается от урацила, никак на это его свойство не влияет.
Откуда берутся белки
Разобравшись в самых общих чертах с тем, как генетическая информация записывается, посмотрим теперь, как она читается. Процесс чтения информации всегда подразумевает, что эта информация вызывает в воспринимающей системе некоторое активное ответное действие. В случае генетической информации таким действием, очевидно, будет синтез белка с “продиктованной” геном аминокислотной последовательностью. Итак, откуда же в клетке берутся белки?
Это хорошо известно. Для синтеза белков служит специальная сложная молекулярная машина, называемая рибосомой (см. рис. 9.2). Любая рибосома “собрана” из нескольких молекул РНК и довольно большого набора (несколько десятков) особых белков, дело которых — обеспечивать сборку других белков. РНК, образующая основу рибосом, так и называется рибосомной РНК, сокращенно рРНК. Например, у животных и растений молекул рРНК в каждой рибосоме четыре. Рибосомная РНК обычно составляет около 70% всей РНК клетки, потому что рибосом очень много: молекулы всевозможных белков со временем изнашиваются, и их надо постоянно производить взамен.
Любой белок по определению кодируется собственным геном и синтезируется на рибосоме. Именно этим белки отличаются от других пептидов (см. главу 3). Мимоходом отметим, что пептиды, не являющиеся белками, в живой природе тоже встречаются. В их состав могут входить непротеиногенные аминокислоты — в том числе бета-аминокислоты и D-аминокислоты, которых в белках никогда не бывает. Небелковые пептиды всегда короткие, и для их синтеза нужны ферменты, то есть опять же “нормальные” белки рибосомного происхождения.
Сам процесс синтеза белка на рибосоме называется трансляцией. Отметим два момента, очень важных для того, чтобы понять ее механизм.
Во-первых, аминокислоты, из которых строится белок, поступают в рибосому из окружающего внутриклеточного раствора — там они всегда есть. Но поступают они оттуда вовсе не в свободном виде. Каждая аминокислота предварительно связывается со специальным, предназначенным только для нее переносчиком, и воспринимается рибосомой только в этом состоянии.
Во-вторых, нуклеиновая кислота, с молекулы которой рибосома считывает транслируемую последовательность, — как ни странно, отнюдь не ДНК. Прямо с ДНК трансляция в живой природе не идет никогда. Это редкий в биологии случай, когда можно сделать категоричное утверждение без всяких оговорок.
Ну а с чего же тогда трансляция идет? Молекулярно-биологические исследования довольно быстро выявили два факта, помогающих ответить на этот вопрос.
* Для синтеза белка совершенно необходима РНК, причем — внимание! — не только рибосомная, но и какая-то еще.* У таких организмов, как животные и растения, ДНК находится в клеточном ядре, в то время как синтез белка всегда идет снаружи от ядра, в цитоплазме. То есть эти процессы четко разделены в пространстве.
При таких вводных было весьма логично предположить следующее. Накануне трансляции где-то в ядре (если оно есть) синтезируется некая молекула-посредник, копирующая нуклеотидную последовательность того участка ДНК, который надо транслировать в белок. (В английском молекула с такой функцией называется словом messenger, однокоренным с широко известным словом message — сообщение, послание.) Затем эта молекула-посредник покидает ядро, перемещается к месту синтеза белка и дает рибосоме “инструкцию”, в каком порядке соединять аминокислоты. В результате получается белок с последовательностью, определенной соответствующим геном. Но сама ДНК при этом остается в покое — с рибосомой она ни в какой момент не контактирует.
Описанная молекула-посредник действительно существует. Она называется информационной РНК, или сокращенно иРНК. Информационная РНК точно повторяет последовательность заданного участка ДНК — разумеется, с заменой дезоксирибозы на рибозу, а тимина на урацил (см. главу 8). Иногда информационную РНК называют матричной (мРНК) — тут заодно получается калька с английского термина messenger RNA, mRNA. Информационная и матричная РНК — синонимы. Но в целом в русском научном языке термин “информационная РНК” встречается чаще, и тут мы будем пользоваться именно им. Итак, информационная РНК — та молекула, с которой непосредственно идет трансляция. Именно с нее считывается информация, необходимая для синтеза белка.
Что делают гены
Перенос информации с ДНК на РНК называется транскрипцией (переписыванием). Это достаточно интересный процесс, механизм которого хорошо изучен. Но, прежде чем о нем рассказывать, давайте сделаем краткое отступление на тему того, как вообще современный человек может узнать что-то о законах природы.
Проблема состоит вот в чем. Когда идет разговор о науке, почти невозможно сообщить кому-то что-то важное, не опираясь, как на ступеньку, на уже существующее знание каких-нибудь элементарных (а иногда и не слишком элементарных) вещей, которые должны быть заранее знакомы всем собеседникам. Как замечал главный программист Института чародейства и волшебства Александр Привалов, “невозможно, например, объяснить термин “гиперполе” человеку, плохо разбирающемуся в теории физического вакуума”. И даже более того, от авторитетных коллег этого ученого мы узнаем, что “курс управления умклайдетом (то есть волшебной палочкой) занимает восемь семестров и требует основательного знания квантовой алхимии”. Стоит ли удивляться, что “самые интересные и изящные научные результаты сплошь и рядом обладают свойством казаться непосвященным заумными и тоскливо-непонятными”? Увы и увы, все это намного ближе к истине, чем широко известное неосторожное высказывание Ричарда Фейнмана: “Если вы ученый и не можете в двух словах объяснить пятилетнему ребенку, чем вы занимаетесь, — вы шарлатан”. Крайне сомнительно, что сам Фейнман (при всей его признанной гениальности) смог бы быстро, внятно и без потерь для смысла объяснить пятилетнему ребенку основы своей любимой квантовой электродинамики. Во всяком случае, в реальности ему понадобились для такого объяснения несколько пространных лекций, причем не перед пятилетними детьми, а перед студентами, которые уж точно лучше, чем дети, были подготовлены к восприятию подобного материала. И то он потом признавался, что долго обдумывал, как бы подойти к теме.
С другой же стороны, любая область науки всегда открывается небольшим числом базовых понятий, которые, как правило, сами по себе очень просты. А уж если они известны, то и по-настоящему сложную вещь становится возможно сообщить в одной короткой фразе. Вот тут-то и обнажается красота чистых идей.
Короче говоря, научное (и в том числе биологическое) знание сугубо иерархично. Это следует принять как факт. И сейчас у нас есть возможность оценить, насколько это на самом деле полезно. Ведь мы теперь уже знаем, что такое водородная связь, фермент, мономер, полимер, нуклеозид, нуклеотид, ДНК, РНК, 3'-конец, 5'-конец, комплементарность и антипараллельность. Про все эти понятия рассказано в предыдущих главах (со 2-й по 8-ю). Вот почему в рассказе про транскрипцию мы обойдемся без введения.
Итак, в начале процесса транскрипции двойная спираль ДНК частично раскручивается, ее цепи разделяются (естественно, с разрывом водородных связей), и фермент под названием ДНК-зависимая РНК-полимераза ползет по одной из цепей от 3'-конца к 5'-концу, синтезируя комплементарную этой цепи РНК. Отметим, что синтезируемая РНК точно так же, как и вторая цепочка ДНК, антипараллельна той цепи, которой она комплементарна. Это означает, что 5'-конец и 3'-конец у нее направлены в другую сторону (см. рис. 9.3).
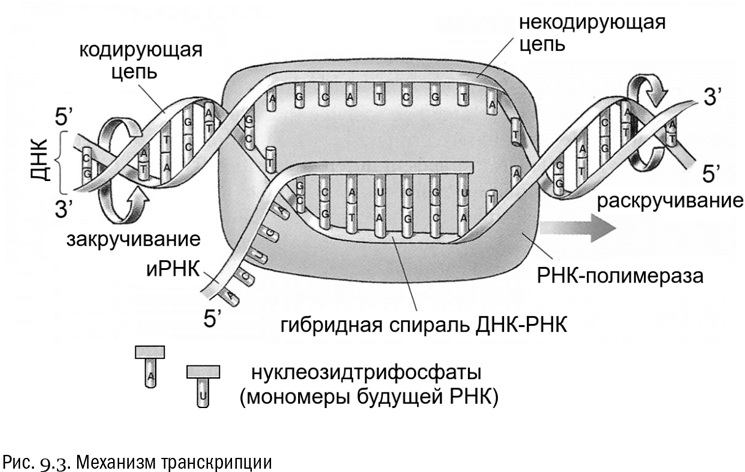
Цепь ДНК, с которой идет транскрипция, называют кодирующей, противоположную — некодирующей. Тут возникает вопрос: откуда РНК-полимераза “знает”, какая из цепей — кодирующая? Ответ: РНК-полимераза распознает кодирующую цепь по наличию в ней особой сигнальной нуклеотидной последовательности — промотора. В некодирующей цепи промотора нет, а есть комплементарная ему последовательность, которая распознана РНК-полимеразой не будет.
Пока мы еще не запутались, обратим внимание, что получающаяся в итоге иРНК будет повторять нуклеотидную последовательность именно некодирующей цепи (в том значении этого термина, которое мы сейчас приняли). Только, конечно, с повсеместной заменой тимина на урацил, как и при любом переносе информации с ДНК на РНК.
Ну, а мономерами, из которых строится новая молекула нуклеиновой кислоты, в клетке всегда служат нуклеозидтрифосфаты, то есть нуклеотиды с дополнительными фосфатными группами. В данном случае это АТФ, ГТФ, ЦТФ и УТФ. “Лишние” фосфатные группы от них в процессе транскрипции отсекаются, а то, что остается, монтируется в сахарофосфатный остов новой РНК.
Вот, собственно, и все. Теперь мы знаем, что делают гены. Если отбросить всевозможные оговорки, ответ будет простым: они транскрибируются. Смысл существования любого гена состоит в том, чтобы рано или поздно синтезировалась РНК, повторяющая его нуклеотидную последовательность. Иначе говоря, чтобы произошла транскрипция. А механизм транскрипции — вот он, перед нами.
Центральная догма
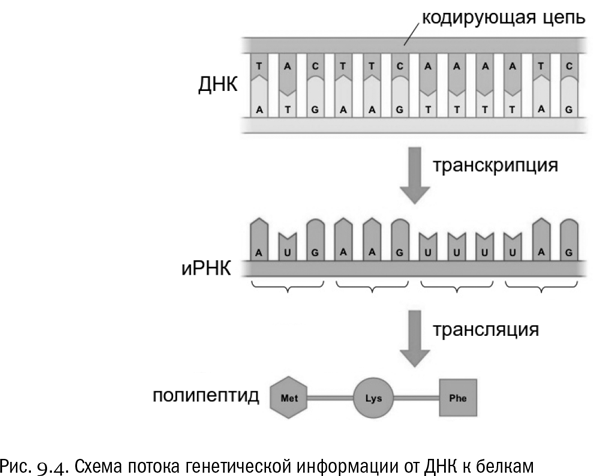
Теперь мы можем объединить наши знания о транскрипции и трансляции в простую общую схему. Вот она:
ДНК⇩ транскрипцияРНК⇩ трансляциябелок
Именно так устроен поток генетической информации, который почти непрерывно бурлит в любой живой клетке. Он направлен от ДНК к белкам и проходит через РНК, служащую в передаче информации совершенно необходимым посредником.
Ключом к передаче информации тут, конечно, служит генетический код. Заглянув в таблицу генетического кода, мы можем, например, убедиться, что РНКовая последовательность АУГААГУУУУАГ кодирует аминокислоты метионин (АУГ), лизин (ААГ) и фенилаланин (УУУ). Четвертый присутствующий здесь кодон — УАГ — является стоп-кодоном. Это как бы “знак препинания”, на котором транскрипция прерывается. Если же подняться по пути потока информации выше, к ДНК, мы увидим, что обсуждаемому фрагменту соответствует последовательность АТГААГТТТТАГ в некодирующей цепи ДНК и ТАЦТТЦААААТЦГ — в кодирующей. Почему именно так, сразу станет понятно, если взглянуть на уже знакомый нам механизм транскрипции и вспомнить правила комплементарности: А в двойной цепи ДНК всегда спаривается с Т, а Г с Ц.
Переведем дух и поздравим себя. Отныне мы знакомы с великой формулой “ДНК → РНК → белок”, которая с легкой руки Фрэнсиса Крика получила название центральной догмы молекулярной биологии. Эта формула (как и большинство подобных кратких формул) на самом деле требует множества оговорок, но самое главное о потоке генетической информации мы теперь знаем. Информация передается с ДНК на белок через посредство РНК (см. рис. 9.4).
Заодно мы сейчас видим, почему таблицу генетического кода лучше сразу давать в РНКовом варианте, то есть с заменой Т на У. Во-первых, в реальной живой природе трансляция всегда идет именно с РНК. А во-вторых, в ДНК нам пришлось бы постоянно разбираться в том, какая цепь кодирующая, а какая некодирующая (причем аминокислотной последовательности белка будет парадоксальным образом соответствовать последовательность некодирующей цепи, которая не транскрибируется). С точки зрения существа дела это ничего не меняет, а вот запутать может здорово. Переходя сразу к РНК, мы этих сложностей избегаем.
Центральная догма (дополнение)
Не нами замечено, что читателей научно-популярных книг по биологии, а также слушателей научно-популярных лекций и тому подобную публику можно приближенно разделить на две группы: тех, для кого заклинание “ДНК-РНК-белок” имеет какой-то смысл, и тех, для кого оно пока ничего не значит. Первая категория — это, что называется, “продвинутые пользователи”, у вторых, вероятно, все еще впереди. Мы с вами теперь знаем, что такое “центральная догма”, а значит, относимся к первой категории. Как видим, тут нет ничего особенно сложного. Но давайте посмотрим на нее, на “догму”, повнимательнее.
Само слово “догма” в этом контексте является просто провокационной шуткой Фрэнсиса Крика (термин “центральная догма” предложил именно он). Ясно, что на самом деле в естественных науках никаких догм не бывает. И история “центральной догмы молекулярной биологии” отлично подтверждает это.
Сначала “центральная догма” выглядела просто: информация в клетке движется строго однонаправленно, по пути ДНК — РНК — белок. Однако на большинстве современных схем мы увидим не только стрелочку, направленную от ДНК к РНК (это транскрипция), но еще и другую стрелочку, направленную, наоборот, от РНК к ДНК. Примерно вот так:
ДНК ⇔ РНК ⇒ белок
Эта новая стрелочка обозначает обратную транскрипцию, то есть синтез ДНК, воспроизводящей последовательность заданной РНК. Обратная транскрипция — очень серьезное отступление от первоначально сформулированной “центральной догмы”, настолько серьезное, что поначалу в него просто-напросто не поверили. Сейчас известно, что это вполне реальный процесс (на нем специализируются некоторые вирусы). Однако важнее всего тут сам факт: встречный поток генетической информации все-таки существует. Фермент, синтезирующий ДНК по последовательности данной РНК, называется, естественно, РНК-зависимой ДНК-полимеразой.
Обратная транскрипция упоминается в знаменитой повести Стругацких “За миллиард лет до конца света”. Один из героев этой повести, биолог Валентин Вайнгартен, говорит друзьям: “Вы этого, отцы, понять не можете, это связано с обратной транскриптазой, она же РНК-зависимая ДНК-полимераза, она же просто ревертаза, это такой фермент в составе онкорнавирусов, и это, я вам прямо скажу, отцы, пахнет нобелевкой…” Между прочим, Стругацкие здесь поразительно точны. Действие повести “За миллиард лет до конца света” происходит в 1972 году, именно в тот исторический момент, когда открытие обратной транскрипции было актуальной научной новостью.
Кодаза и код
А теперь вернемся к процессу трансляции. В нем остались интересные детали, которые нам стоит обсудить.
Откуда рибосома “знает”, какую именно аминокислоту она должна в данный момент присоединить к растущей белковой цепочке? Оказывается, в этом ей помогает еще одна разновидность РНК. Это — транспортная РНК (тРНК), занимающаяся только переносом аминокислот.
Транспортная РНК — одноцепочечная, но она причудливым образом фигурно сложена (см. рис. 9.5А). И, кроме того, на разных ее отрезках есть комплементарные друг другу участки, способные, сближаясь друг с другом, образовывать двойные спирали. Типичная конформация тРНК, перехваченная этими двойными спиралями в трех местах, имеет характерный вид трилистника и называется “клеверным листом”. (Между прочим, именно стилизованный “клеверный лист” тРНК является официальной эмблемой биологического факультета МГУ.) Для каждой аминокислоты есть своя тРНК, и чаще всего не одна.
Мимоходом отметим, что у транспортных РНК есть еще одна интересная особенность: в их состав входит много разных химически модифицированных нуклеотидов, которые называют минорными. Например, буквой ψ (“пси”) принято обозначать минорный нуклеотид псевдоуридин, в состав которого входит вместо урацила один его довольно экзотичный изомер. Транспортная РНК кодируется собственными генами, синтезируется путем транскрипции (точно так же, как информационная РНК), а потом некоторые нуклеотиды в ней модифицируются. Тем не менее по общей формуле это обычная нуклеиновая кислота.
Транспортная РНК — относительно небольшая молекула, ее длина обычно всего 70–90 нуклеотидов. Вблизи ее 3'-конца находится универсальная для всех тРНК концевая последовательность ЦЦА. (Тут стоит обратить внимание на то, что нуклеотидные последовательности по умолчанию принято читать от 5'-конца к 3'-концу, подобно тому, как обычный буквенный текст читают слева направо.) Именно к 3'-концу тРНК всегда присоединяется аминокислота.
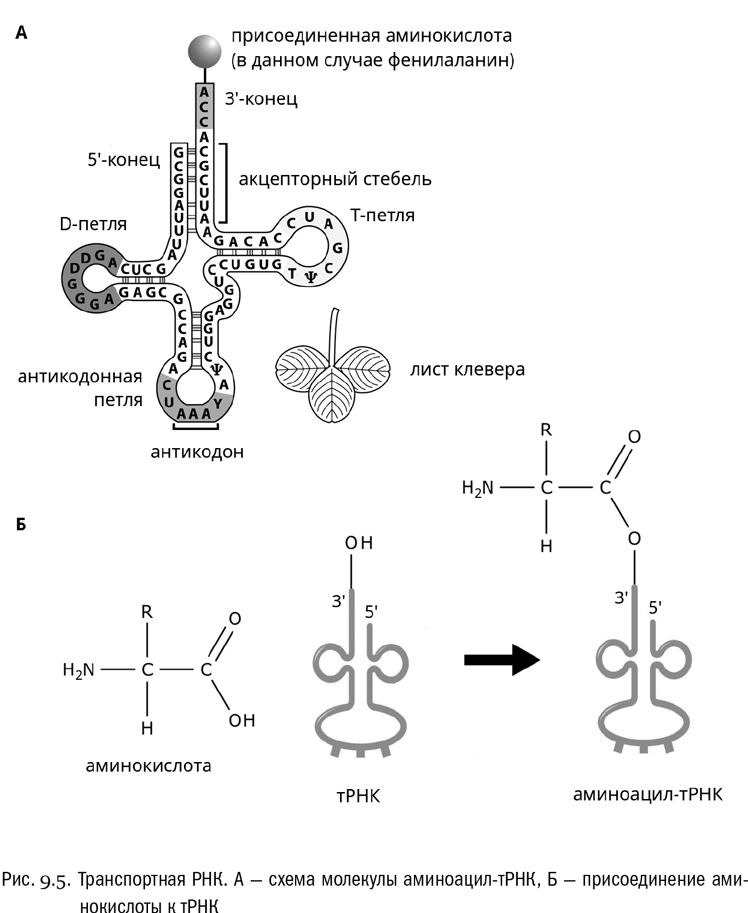
Само присоединение аминокислоты выглядит так (см. рис. 9.5Б). Фермент аминоацил-тРНК-синтетаза (он же просто кодаза) сшивает с выделением воды 3'-гидроксил концевого аденозина тРНК и карбоксильную группу аминокислоты. Последняя тем самым временно превращается в ковалентно связанный с рибозой остаток R–CH(NH2)–CO–, который называется аминоацилом. Также в этой реакции участвует АТФ, который расщепляется в ходе нее до АМФ. Но главный продукт реакции — это аминоацил-тРНК, то есть молекула транспортной РНК с висящей на “черешке клеверного листа” ковалентно пришитой аминокислотой, временно превратившейся в аминоацил.
На вершине самой дальней от “черешка” петли тРНК всегда находится антикодон — нуклеотидный триплет, комплементарный кодону той самой аминокислоты, которую данная тРНК переносит. Например, если аминокислота фенилаланин кодируется кодоном УУУ, то соответствующая транспортная РНК несет антикодон ААА (поскольку, как мы знаем, урацил комплементарен аденину). Чтобы соединение произошло правильно, активный центр кодазы должен одновременно распознать и молекулу тРНК, и аминокислоту — не какую угодно, а ту, которая кодируется триплетом, комплементарным антикодону этой тРНК. Это сложная задача, но кодаза с ней обычно справляется.
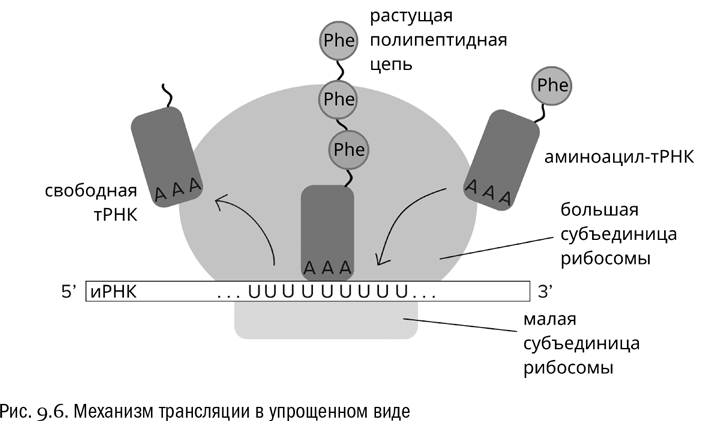
Дальше вступает в действие простой механизм (см. рис. 9.6). Во время трансляции любая проплывающая мимо аминоацил-тРНК может чисто случайно столкнуться с тем кодоном иРНК, который в данный момент находится в активном центре рибосомы. Но свяжется она с ним только в том случае, если ее антикодон будет этому кодону комплементарен. Тогда рибосома отрежет аминокислоту от тРНК, присоединит ее к растущей белковой цепочке, а сама продвинется по иРНК на один шаг вперед (в сторону 3'-конца). После чего цикл повторится.
Антикодон тРНК, связанной с рибомосой, всегда комплементарен кодону, находящемуся в данный момент в активном центре этой рибосомы. Иначе трансляция не пойдет. Добавим, что белок при трансляции всегда синтезируется от N-конца к C-концу, то есть от свободной аминогруппы к свободному карбоксилу, но не наоборот (см. главу 3). Именно поэтому аминокислотные последовательности белков в таком же порядке и записываются в базах данных.
Источниками энергии для трансляции (и для транскрипции тоже) служат нуклеозидтрифосфаты. Причем в данном случае это не столько уже знакомый нам АТФ, сколько гораздо менее распространенный ГТФ. Почему так? Ведь АТФ в клетке больше, а с точки зрения энергии выбор между АТФ и ГТФ не дает ни заметного проигрыша, ни заметного выигрыша, энергетическая “цена” реакций распада этих веществ примерно одна и та же.
Поставим вопрос иначе: почему вообще самой универсальной “энергетической валютой” стал АТФ, а не ГТФ, ЦТФ или УТФ? Простейшую подсказку можно получить, если взглянуть на формулы четырех азотистых оснований. Аденин — единственное из них, в котором нет ни одного атома кислорода. В молекулах гуанина, цитозина и урацила кислород есть. На древней Земле, где свободного кислорода в атмосфере было очень мало, аденин наверняка легче всего синтезировался, и, соответственно, адениновые нуклеотиды тоже. Клетки использовали тот химический субстрат, который был самым доступным. Возможно, как раз поэтому именно молекула АТФ стала универсальным переносчиком энергии.
Но универсальность АТФ имеет и свои минусы. Дело в том, что из-за особой важности этого вещества его концентрация (а точнее, соотношение концентраций [АТФ]/[АМФ]) очень жестко контролируется внутриклеточными регуляторными системами. В многоклеточном организме слишком резкое отклонение этого параметра от нормы может вызвать даже “самоубийство” целой клетки, так называемый апоптоз. На ГТФ этот контроль не распространяется, поэтому менять его концентрацию можно гораздо свободнее. Возможно, смысл “подключения” транскрипции и трансляции к ГТФ состоит как раз в том, чтобы сделать эти жизненно важные процессы автономными, снизив их зависимость от всего остального происходящего в клетке.
Открытие механизма трансляции тут же дало ученым превосходный ключ к расшифровке генетического кода. Например, что будет, если синтезировать искусственную иРНК, в которую из всех азотистых оснований входит только урацил, и поместить ее в обычный водный раствор, предварительно добавив туда рибосомы, полный набор аминоацил-тРНК и источники энергии? Оказалось, что в этом случае прямо в пробирке, без всякого участия живых клеток, может синтезироваться белок, состоящий из одной-единственной аминокислоты, а именно из фенилаланина. Этот эксперимент был реально поставлен в 1960 году, и в результате его был расшифрован первый кодон — УУУ. Это кодон фенилаланина. Расшифровка всех остальных кодонов после этого была уже только делом биохимических опытов, пусть и непростых технически, но абсолютно прозрачных по смыслу. Завершить ее удалось всего за каких-то пять лет. К 1965 году генетический код был полностью взломан (cracked). Именно так это тогда называли в статьях, а еще чаще в разговорах, вполне в духе основоположника научного мировоззрения сэра Фрэнсиса Бэкона, некогда заявившего на весь мир, что знание — сила.
Экспрессия
Весь процесс переноса генетической информации от ДНК через РНК к белкам называется экспрессией генов. Тут мы в который раз, и теперь уже вплотную, сталкиваемся с понятием “ген”. И пора, пожалуй, немного его обсудить, прежде чем идти дальше.
Итак, что же такое ген? Слово это слышал каждый. Но вот дать строгое определение гена на самом деле не так уж и легко. Довольно часто встречается мнение, что ген — это участок ДНК, кодирующий структуру одного белка (концепция “один ген — один белок”). Для большинства генов это верно. Но не для всех. Например, белок, у которого есть четвертичная структура, кодируется несколькими генами. В самом деле, такой белок по определению состоит из нескольких аминокислотных цепочек, которые могут синтезироваться отдельно, а объединяться только после трансляции.
Еще большую проблему для “белкового” определения гена составляют РНК. Все клеточные РНК транскрибируются с генов, но довольно многие из них потом не транслируются ни в какие белки. Например, это относится ко всем рибосомным и транспортным РНК. Между тем те участки ДНК, на которых закодированы последовательности рРНК и тРНК, — это тоже гены, нет никаких оснований не считать их таковыми.
Обойти эти трудности можно, если решить, что ген — это единица транскрипции, то есть участок ДНК, кодирующий одну любую РНК (информационную, транспортную или рибосомную). Правда, к этому определению при желании тоже можно придраться: например, в некоторых геномах встречаются гены, которые транскрибируются обычно вместе, хотя кодируют разные белки. Словом, ген — это типичный пример общего понятия, которое в разных случаях может применяться немного по-разному.
Условимся, что если к слову “ген” не сделано никаких оговорок, то речь идет, скорее всего, о гене, который кодирует один белок, состоящий из одной аминокислотной цепочки, то есть из одного полипептида (см. главу 3). О рядовом гене, так сказать. В этом случае определение “один ген — один белок” будет верным.
Число генов у каждого отдельного живого существа обычно измеряется тысячами или первыми десятками тысяч. Например, у многоклеточных животных генов чаще всего 15 000–20 000. У бактерий — всего несколько тысяч или, в редких случаях, даже несколько сотен (правда, обладатели таких маленьких геномов могут жить только внутри чужих клеток, от которых и получают большую часть нужных веществ — своих ферментов им для этого, как правило, не хватает). А у некоторых цветковых растений число генов переваливает за 40 000, и вот это, видимо, уже близко к естественному пределу. Во всяком случае, сотен тысяч и миллионов генов ни у какого земного живого организма нет.
Всевозможные процессы “включения” и “выключения” генов, ослабления и усиления их активности и тому подобного в сумме называются регуляцией экспрессии. Надо сказать, что способы регуляции экспрессии невероятно многообразны. Прежде всего, экспрессию гена можно регулировать как на уровне транскрипции (запуск или прекращение синтеза РНК), так и на уровне трансляции (ускорение или задержка синтеза белка на готовой иРНК). Регуляция на уровне транскрипции — более базовая, на уровне трансляции — более тонкая, и ее мы пока не будем касаться.
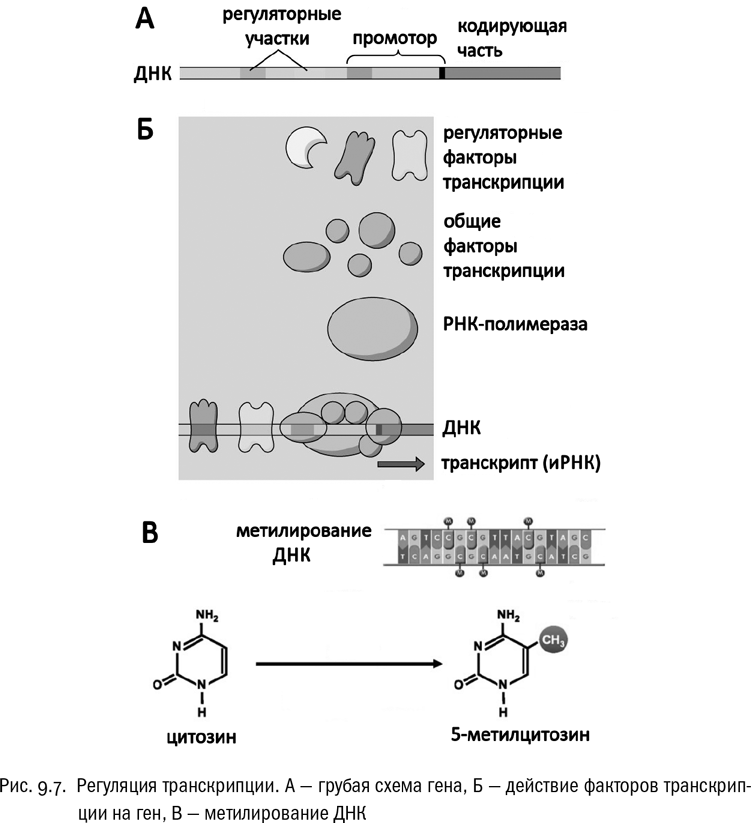
Но и транскрипцию можно регулировать по-разному. Давайте рассмотрим рядовой ген, то есть отрезок ДНК, несущий полную информацию о некотором белке (см. рис. 9.7А). Он состоит из кодирующей части, где записана последовательность аминокислот, и нескольких некодирующих участков, нужных только для регуляции работы самого гена. Главный из этих некодирующих участков называется промотором. Промотор — это та самая последовательность, которую обязательно должна распознать РНК-полимераза, чтобы транскрипция гена вообще произошла. А вот перед промотором находятся дополнительные регуляторные участки, которые нужны для связывания белков, влияющих на активность гена. Главный из таких белков: конечно, РНК-полимераза, которая, собственно говоря, транскрипцию и осуществляет. И ей в этом помогают еще несколько белков — так называемые общие факторы транскрипции, необходимые для самого процесса синтеза РНК. Но, кроме того, есть еще и регуляторные факторы транскрипции, которые в синтезе РНК непосредственно не участвуют. Их работа — связываться с ДНК, или облегчая, или затрудняя посадку РНК-полимеразы на соответствующий ген (см. рис. 9.7Б). ДНК-связывающий белок, усиливающий таким образом транскрипцию, называется активатором, а ДНК-связывающий белок, блокирующий транскрипцию, — репрессором. Белок-репрессор просто не дает РНК-полимеразе сесть в нужную точку ДНК, а белок-активатор, наоборот, меняет конформацию ДНК так, чтобы РНК-полимеразе было удобнее с ней связаться. Несколько упрощая, можно сказать, что белок-активатор включает ген, а белок-репрессор выключает его.
Самое тут интересное, что регуляторные белки (и активаторы, и репрессоры, и любые другие), разумеется, тоже являются продуктами каких-то генов. И эти гены тоже должны быть кем-то или запущены, или заторможены. Гены, кодирующие регуляторные белки, очень легко взаимодействуют через свои продукты, включая и выключая друг друга и образуя в результате целые цепочки и сети. Неудивительно, что генные сети (gene regulatory networks, сокращенно GRN) стали популярнейшим объектом изучения современной биологии.
Еще один способ регуляции экспрессии — прямая химическая модификация ДНК. Самый частый вид такой модификации — метилирование цитозина (см. рис. 9.7В). В этом случае на определенном отрезке ДНК каждый цитозин получает дополнительную метильную группу и превращается в 5-метилцитозин. Такие участки ДНК транскрибируются слабее, “замолкают”. Метилирование ДНК обратимо и может быть снято соответствующими ферментами, если выключенные этим способом гены потребуется опять включить.
Репликация
Теперь нам осталось поговорить еще про репликацию, то есть копирование ДНК. Как-никак самовоспроизводство — одно из самых главных свойств живых организмов, а без репликации оно совершенно невозможно.
Репликация ДНК — полуконсервативная (см. рис. 9.8А). Двойная спираль расшивается с разрывом водородных связей, после чего к каждой нити ДНК достраивается комплементарная нить из находящихся в растворе нуклеозидтрифосфатов (превращающихся попутно в нуклеозидмонофосфаты). И в результате получается две двойные спирали, в каждой из которых одна цепь “старая”, а другая — “новая”.
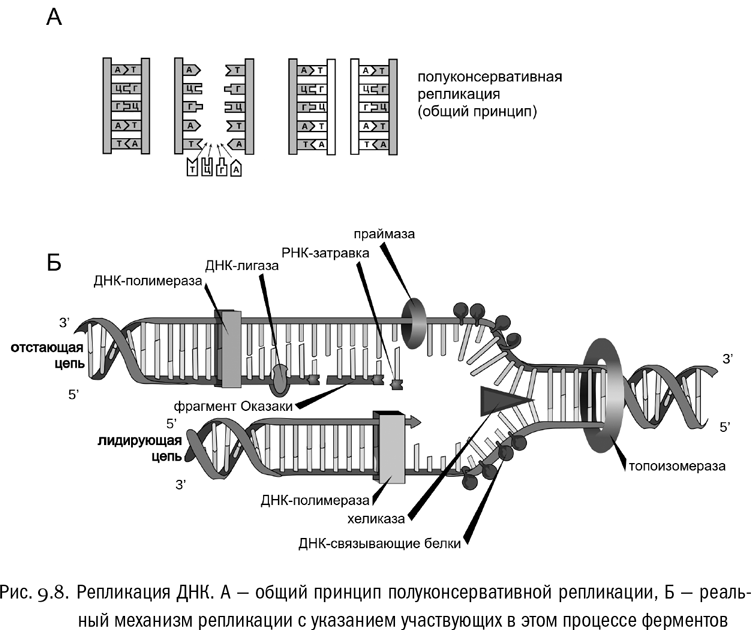
Фермент, который синтезирует из мономеров новую цепь ДНК, комплементарную к имеющейся, называется ДНК-полимеразой. На самом деле в любой клетке есть несколько ДНК-полимераз, отличающихся по функциям. Заодно тут сразу возникает несколько проблем, которые с одним классом ферментов в любом случае не решить (см. рис. 9.8Б).
Во-первых, чтобы репликация стала возможна, комплементарные цепи ДНК надо как-то разделить. Для этого фермент хеликаза разрывает водородные связи между азотистыми основаниями, а фермент топоизомераза раскручивает двойную спираль ДНК, разрывая для этого ковалентные связи между нуклеотидами и тут же сшивая их заново. Последнее неизбежно, потому что двойную спираль невозможно раскрутить, не разрывая, если нам недоступны ее концы. Для простоты можно представить себе вместо нее обыкновенный узел, концы шнурков от которого уходят куда-то в бесконечность, а нам тем не менее надо разделить шнурки, чтобы они шли параллельно и не перепутывались. Не будет другого выхода, кроме как разрезать их и потом сшить. Вот это топоизомераза и делает.
Во-вторых, ДНК-полимераза не может начать создавать новую цепь с нуля. Ей нужна затравка в виде короткой комплементарной РНК, которую синтезирует фермент праймаза. Новая ДНК может синтезироваться в виде целой серии фрагментов, ковалентно связанных с РНК-затравками (фрагменты Оказаки). Потом особые ферменты вырезают РНК, помещают на ее место комплементарные исходной цепи дезоксирибонуклеотиды, и ДНК-лигаза сшивает все это в единую цепь ДНК.
В-третьих, цепи ДНК антипараллельны. А любая ДНК-полимераза может двигаться по исходной цепи от 3'-конца к 5'-концу, но никак не наоборот. Это означает, что новая цепь ДНК синтезируется начиная с 5'-конца, так же как и РНК при транскрипции. ДНК-полимеразы, способной ползти по цепи в обратную сторону, в природе не существует. Поэтому две цепи ДНК вынужденно реплицируются по-разному. Цепь, по которой ДНК-полимераза может непрерывно ползти от 3'-конца к 5'-концу, называется лидирующей. Тут механизм репликации упрощен: ДНК-полимераза начинает с единственной РНКовой затравки и дальше может сколько угодно наращивать новую цепь вдоль исходной по мере того, как та раскрывается. Цепь, вдоль которой ДНК-полимераза непрерывно ползти не может, называется отстающей. ДНК-полимераза проходит ее отрезок за отрезком, как бы перемещаясь скачками и каждый раз начиная с новой затравки. Тут как раз и образуются фрагменты Оказаки, а потом лигаза сшивает их вместе.
Мы видим, что кроме ДНК-полимераз в репликации участвуют белки, раскручивающие ДНК и удерживающие ее в раскрученном состоянии, создающие затравку для новой цепи, и другие — в общей сложности несколько десятков белков. Очевидно, что в таком сложном, многоступенчатом, затратном процессе не может не быть ошибок. Собственно говоря, ошибки и так неизбежны в любом процессе копирования информации — просто из-за случайного характера движения молекул. Но чем больше этапов и состыковок, тем больше возможностей сделать что-то неточно. И действительно, процесс репликации ДНК всегда включает некоторую вполне заметную долю ошибок, которая отличается у разных живых организмов, но никогда не равняется нулю. Часть этих ошибок тут же исправляется (репарация), а часть сохраняется и передается следующим поколениям (конвариантная редупликация). Наличие конвариантной редупликации — это важнейшее свойство всех живых систем, отличающее их от всех неживых.
Тут не помешает историческая справка. Термин “конвариантная редупликация” придумал выдающийся генетик Николай Владимирович Тимофеев-Ресовский, и означает он самокопирование информационных молекул с сохранением случайно возникающих изменений. А еще это означает, что сейчас мы наконец добрались до самого смыслового ядра современной биологии. The very heart, как говорят англичане. Ведь биология — это, по сути, и есть наука о поведении конвариантно редуплицирующихся структур и их всевозможных надстроек. Именно благодаря конвариантной редупликации происходит биологическая эволюция. Более того, для любой конвариантно редуплицирующейся структуры эволюция физически неизбежна просто потому, что точность копирования информации никогда не бывает абсолютной и изменения накапливаются из поколения в поколение.
В современных научных и научно-популярных книгах молекулы, способные к самокопированию, принято называть репликаторами. Любой ген — это типичный репликатор. Он потому и существует, что способен создавать собственные копии, а вернее — побуждать организмы к созданию таких копий. От этих соображений остается один шаг до современной эволюционной теории.
Назад: ЧАСТЬ II МЕХАНИЗМ ЖИЗНИ
Дальше: 10. эукариотная клетка

