Книга: Путеводитель для влюбленных в математику
Назад: Глава 20 Вероятность в медицине
Дальше: Глава 22 Демократический выбор и теорема Эрроу
Глава 21
Хаос
Что делает событие непредсказуемым? Предыдущие главы были посвящены понятию вероятности. Центральная идея теории вероятностей заключается в том, что некоторые феномены случайны: их нельзя предсказать в точности, поскольку они недетерминированы. Разумно и эффективно рассматривать некоторые феномены внешнего мира, такие как вращение брошенного кубика, в качестве случайных.
Но случаен ли бросок костей в действительности? Возможно, если мы детально знаем все характеристики кубика – от скорости вращения в зависимости от плотности воздуха в комнате до коэффициента трения о поверхность стола, мы сумеем в точности определить, какой гранью вверх он остановится. Возможно, вращение кубика не случайно – просто это чрезвычайно сложное явление.
Есть ли что-нибудь случайное? Физики утверждают, что некоторые феномены действительно непредсказуемы; таков основополагающий принцип квантовой механики. Поведение элементарных частиц, таких как электрон и фотон, нельзя предсказать, поскольку неопределенность – одно из их фундаментальных свойств.
Другие физические, биологические и социальные феномены могут быть чрезвычайно хорошо смоделированы с помощью теории вероятностей. Это потрясающе. Но насколько они случайны? Не исключено, что они чересчур сложны для понимания.
Так возникает главный вопрос этой главы: может ли система быть простой, полностью детерминированной, но все же непредсказуемой?
Функции
Ключевая идея этой главы – итерация функций. Под итерацией мы подразумеваем повторение одной и той же операции снова и снова. Что математики подразумевают под функцией?
Функции можно рассматривать в качестве своего рода «черных ящиков», преобразующих одно число в другое. Вообразим, что у черного ящика есть входной лоток, куда мы засыпаем числа, дальше мы крутим ручку, машина делает свое дело, и на выходе из ящика вываливаются новые числа.
Например, представим себе ящик, выполняющий следующую операцию. Мы бросаем туда число, он возводит его в квадрат, добавляет к результату единичку и выплевывает то, что получилось. Дадим этой функции имя; назовем ее «возведи в квадрат и прибавь один». Вот как она работает с числом 3:
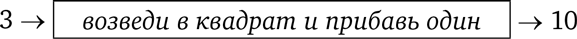
Описывать действия функции словами обременительно, гораздо проще использовать математические символы. Что касается числа 3, мы вначале возводим его в квадрат: 3² = 9, а затем прибавляем единичку: 3² + 1 = 10. Как будет выглядеть результат с числом 4? Очевидным образом, 4² + 1 = 17.
Вместо длинных имен (вроде «возведи-в-квадрат-и-прибавь-один»), математики обозначают функцию какой-нибудь буквой, чаще всего f. Число, с которым имеет дело функция, помещают в круглые скобки сразу за буквой, например: f(4).
Эта форма записи удобна для описания функции:
f(x) = x² + 1.
Это значит, что функция превращает число x в число x² + 1.
Вот еще один пример. Определим новую функцию g таким образом:
g(x) = 1 + x + x².
Чему равно g(3)? Мы подставляем число 3 в формулу и получаем:
g(3) = 1 + 3 + 3² = 13.
Функции можно комбинировать, чтобы одна операция следовала за другой. Подумаем, чему равно f(g(2)).
Это выражение вынуждает нас вычислить функцию f от какой-то величины. От какой? Она зависит от того, чему равно g(2). А чему оно равно? g(2) = 1 + 2 + 2² = 7. А теперь посчитаем f(7) = 7² + 1 = 50. Если уложить всё в одну строчку, получится:
f(g(2)) = f(7) = 50.
Давайте проверим, хорошо ли вы усвоили материал. Посчитайте g(f(2)). Это не 50! Верный ответ – в конце главы.
Вернемся к определению итерации. Как я уже сказал, итерация означает просто повторение одной и той же операции снова и снова. Еще раз: итерация означает просто повторение одной и той же операции снова и снова. Еще раз: итерация означает просто повторение… (Окей, надеюсь, вы уловили юмор.)
Подумаем о функции f(x) = x² + 1. Запись f(f(x)) означает, что мы применяем операцию f дважды: берем число x, закидываем его в функцию f, а потом снова закидываем то, что получилось, в функцию f. Вот пример:
f(f(2)) = f(2² + 1) = f(5) = 5² + 1 = 26.
Можно проводить итерацию сколько угодно раз. Например, трижды:
f(f(f(2))) = f(f(5)) = f(26) = 26² + 1 = 677.
Когда мы выходим на четвертую итерацию, запись становится громоздкой. Поэтому вместо f(f(f(f(x)))) мы будем записывать f⁴(x), подразумевая, что верхний индекс означает не возведение в степень, а последовательное применение функции. Для положительного целого числа n выражение f n(x) означает:

Итерация логистического отображения
Сейчас мы проитерируем функции вида f(x) = mх(1 – х), где m – некое число. Это семейство функций называется логистическим отображением. Во всех случаях мы будем начинать с числа x = 0,1, итерировать функцию и наблюдать за происходящим. Мы начнем с функции:
f(x) = 2,5x (1 – x).
Начнем с x = 0,1 и на первом шаге посчитаем:
f(0,1) = 2,5 × 0,1 × (1–0,1) = 2,5 × 0,1 × 0,9 = 0,225.
Применим f снова:
f ²(0,1) = f(0,225) = 2,5 × 0,225 × (1–0,225) = 2,5 × 0,225 × 0,775 = 0,4359375.
Прибегнем к помощи компьютера. Программа, итерирующая f, даст такие результаты:
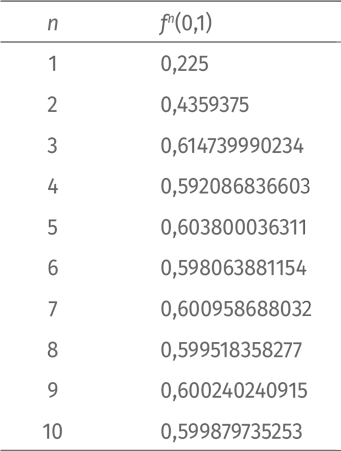
Заметим, что успешное итерирование все больше и больше приближает нас к 0,6. Есть хороший способ продемонстрировать это наглядно. Отметим на графике величины f(0,1), f(f(0,1)), f(f(f(0,1))) и т. д. На оси абсцисс нанесем номера итераций, n. На каждом шаге будем отмечать значение f n(x) («нулевая» итерация – это наше начальное число 0,1). Соединим все точки отрезками. Вот что получится:
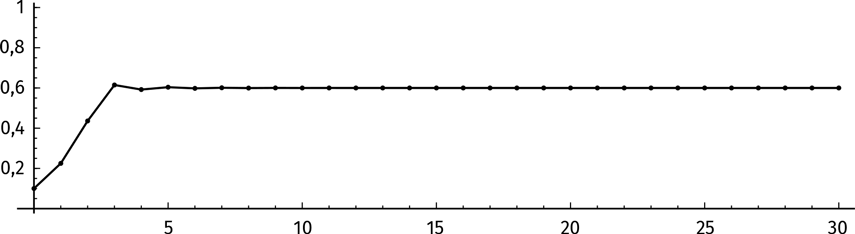
Мы видим, что итерации f(x) сходятся к числу 0,6.
А что, собственно, особенного в числе 0,6? Заметим, что
f(0,6) = 2,5 × 0,6 × (1–0,6) = 2,5 × 0,6 × 0,4 = 0,6.
Число 0,6 называют неподвижной точкой функции f, поскольку применение функции к этому числу не меняет его: f(0,6) = 0,6.
Продублируем эксперимент с другой функцией того же семейства; на сей раз возьмем множитель m = 2,8; таким образом, функция приобретает вид f(x) = 2,8 x (1 – x). Как и в предыдущем случае, мы начнем итерирование с x = 0,1. Вот первые 10 значений:
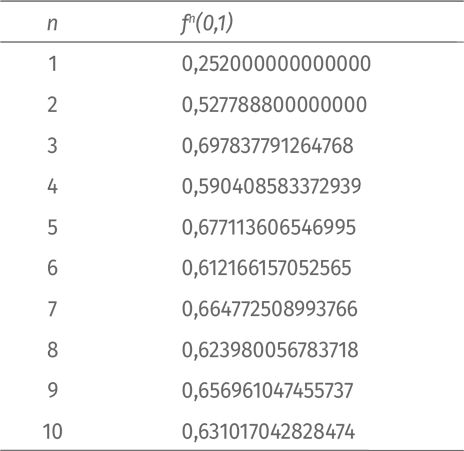
Похоже, итерации выплясывают вокруг 0,64. Продолжим итерировать и построим график:
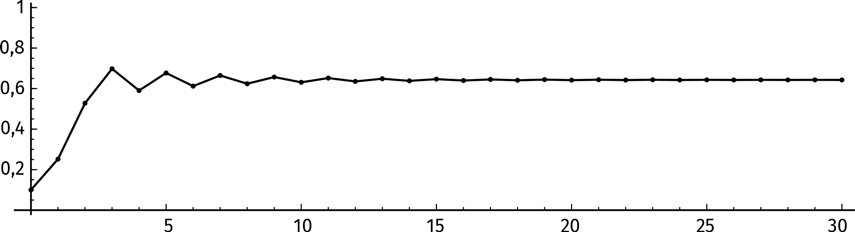
В пределах первых 10 итераций значения функции слегка колеблются вверх и вниз, но уже на 30-й они выравниваются. На какой величине? Это число между 0 и 1, такое, что f(x) = x. Нам остается решить незамысловатое уравнение:

Итерации f(x) = 2,8 x (1 – x) сходятся к числу 0,642857.
Итерирование логистического отображения f(x) = m x (1 – x) можно рассматривать в качестве простой эволюционирующей системы. Число x показывает состояние системы, а функция f диктует, как система эволюционирует при смещении на один шаг. В двух рассмотренных нами случаях (m = 2,5 и m = 2,8) долгосрочное поведение системы приводит к «равновесию» в неподвижной точке функции.
Мы продолжим исследование итераций логистического отображения в случае m = 3,2. Как и в предыдущих случаях, мы начнем с х = 0,1. Вот первые десять значений:

Что происходит? Итерации не сходятся к одной величине. Значения на четных шагах становятся меньше (это примерно 0,66; 0,64; 0,62; 0,6; 0,57), а на нечетных – растут (примерно 0,72; 0,74; 0,75; 0,77). Значения расходятся, а не сходятся!
Начертим график первых 30 итераций, чтобы изобразить наглядно проведение системы:
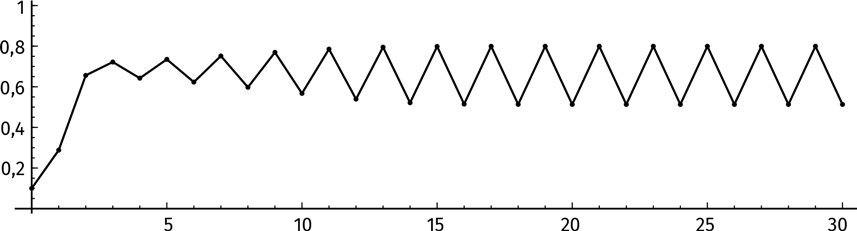
Посмотрите! Она не выравнивается к одному числу, а осциллирует между двумя величинами. Доведем вычисления до 50-й итерации. Вот последние строчки таблицы:

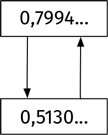
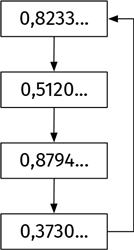
Долгосрочное поведение системы – осцилляция между двумя величинами, s = 0,799455… и t = 0,5130445… Эти числа таковы, что f(s) = t, а f(t) = s. Правило осцилляции можно изобразить так:
Какое еще поведение функции мы можем наблюдать, итерируя логистическое отображение? В следующем пункте нашей экспедиции m = 3,52. Посмотрим на график итераций f(x), f²(x), f³(x), …
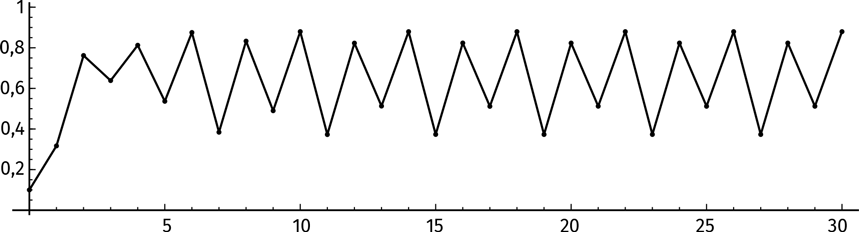
А вот таблица итераций:

Долгосрочное поведение функции занятно, но по-прежнему стабильно. Система идет по циклу из четырех величин ad infinitum, как показано на иллюстрации.
От порядка к хаосу
Мы проследили долгосрочное поведение итераций логистического отображения f(x) = m x (1 – x). Итерации всегда приводили нас к стабильности. В некоторых случаях (m = 2,5 и m = 2,8) система сходилась к одной величине: неподвижной точке функции f. В других случаях (m = 3,2 и m = 3,52) она приобретала стабильный, предсказуемый ритм.
Жизнь хороша. Мы знаем исходную величину: x = 0,1. И мы знаем правило, по которому переходим от одного шага к другому: f(x) = m x (1 – x). Разумеется, мы можем предвидеть поведение функции на любом шаге до бесконечности. Верно?
Настало время для последнего примера: m = 3,9. Доверим подсчет первых 10 итераций компьютеру:
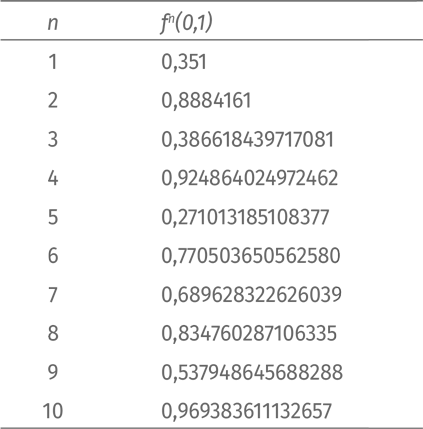
Что происходит? Неясно. Попробуем изобразить на графике первые 30 итераций:
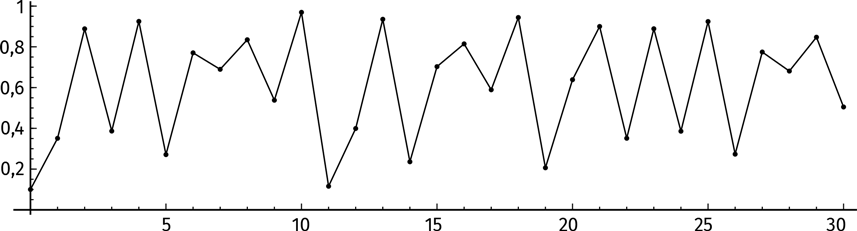
Хм… Ритм не прослеживается. Спокойствие, только спокойствие! Изобразим на графике первые 100 итераций.
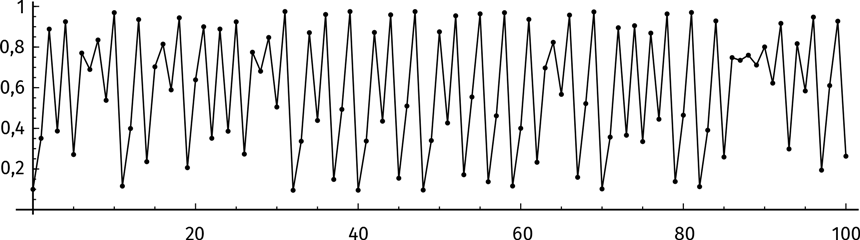
Колебания величин выглядят случайными. Разумеется, на самом деле это не так! Значение функции на каждом шаге можно точно подсчитать по формуле f(x) = 3,9 x (1 – x). Но итерации логистического отображения никогда не приведут к стабильности. Хаос будет длиться вечно.
Великолепно: итерации беспорядочны, но система предсказуема на 100 %!
• Мы знаем исходную величину: x = 0,1.
• Мы знаем правило перехода от одного шага к другому: x → f(x) = 3,9 x (1 – x).
Следовательно, мы можем вычислить состояние системы, скажем, на тысячной итерации. Верно?
Неверно.
Мы загнаны в угол стечением двух обстоятельств: ошибок округления и чувствительности системы к исходному состоянию. Обсудим каждое из них.
Когда мы проводим вычисления на калькуляторе или на компьютере, результат зачастую оказывается приблизительным. Например, если мы делим 1 на 3, наши приборы выдают десятичную дробь 0,3333333. В ней, скажем, семь знаков после запятой. На самом деле троек после запятой бесконечно много, но калькулятор ограничивается конечным количеством цифр. После нескольких итераций функции f(x) = 3,9 x (1 – x) количество знаков после запятой достигает дюжины. Рано или поздно компьютер выдает лишь приблизительный, а не точный результат. Обычно мы не придаем значения таким ошибкам. Если мы подсчитываем, сколько картин уместится на пустой стене, нас не волнует ошибка на одну триллионную. Почему ошибки округления имеют значение в данном случае?
Они ведут нас к загвоздке – чувствительности системы к исходному состоянию. Посчитаем итерации нашей функции, начиная с двух почти что равных величин: х = 0,1 и х = 0,10001. Интуитивно мы предполагаем, что скромная разница между исходными величинами не играет роли. Так ли это? Что произойдет?

Замечу, что первые десять итераций или около того не приводят к значительным отличиям. Но затем траектории начинают расходиться. Это можно проиллюстрировать на графиках эволюции той и другой системы. Сплошная линия соответствует итерированию системы с исходным значением 0,1. Пунктирная линия иллюстрирует итерирование системы с исходным значением 0,10001.
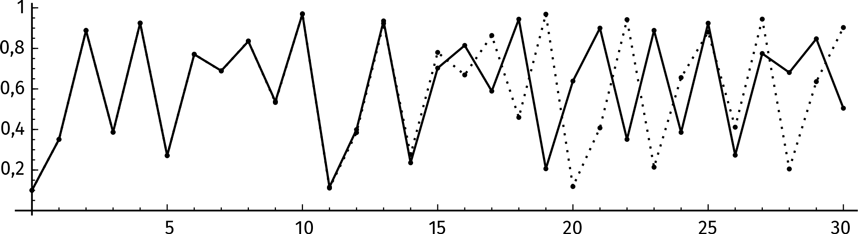
Каково значение f1000 (0,1)? К чему мы придем, если мы проделаем тысячу итераций функции f(x) = 3,9 x (1 – x)?
Разумеется, мы доверяем вычисления компьютеру, но получается какая-то чепуха. Проиллюстрируем этот факт, проделав вычисления трижды с разным уровнем точности (заданным количеством знаков после запятой). Мы получим следующие результаты:

Ни одна из этих величин не равна f 1000 (0,1) в точности.
Мы будем биться до последней капли крови. Компьютер может работать с произвольной точностью. Он может не округлять полученное значение. К чему это приведет?

Точное значение f ⁶ (0,1) имеет длину 127 знаков после запятой, а точное значение f ⁷ (0,1) растягивается после запятой на 255 знаков. Количество знаков после запятой увеличится примерно вдвое на каждой итерации. Нет настолько мощного компьютера, чтобы вычислить точное значение f1000 (0,1).
К чему мы пришли? Несмотря на то что мы знаем исходное состояние системы и правило перехода от одного шага к другому, мы не в силах в точности предугадать ее состояние на 1000-м шаге.
Можно доказать, что точное значение f1000 (0,1) лежит между 0 и 1, и задаться вопросом: какова вероятность того, что f1000 (0,1), скажем, больше 0,5?
Ответ: либо 0, либо 1, потому что здесь нет ничего случайного. Либо f1000 (0,1) > 0,5, либо f1000 (0,1) ≤ 0,5, третьего не дано. Никаких «может быть», ничего случайного.
Даже настолько простая система способна оказаться хаотичной. Она абсолютно детерминирована и в то же время непредсказуема.
Огромное количество математических систем ведет себя хаотично, и многие из них позволяют строить модели явлений природы, например в метеорологии.
3x + 1, или проблема Коллатца
До сих пор мы говорили об итерациях логистических отображений. Мы закончили обсуждением разных типов функций и тернистой, неразрешимой проблемы их итерации.
Логистическое отображение – функция, заданная простой алгебраической формулой. Однако функции можно задавать иначе. Функция F, о которой сейчас пойдет речь, определена исключительно для положительных целых чисел и задана следующим образом:
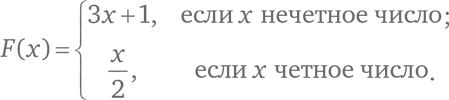
Эта функция задается двумя простыми алгебраическими формулами, но мы выбираем формулу в зависимости от того, четное число x или нечетное.
Пример:
• F (9) = 28. Число 9 – нечетное, поэтому мы руководствуемся формулой 3х + 1 и получаем 3 × 9 + 1 = 28;
• F (10) = 5. Число 10 – четное, поэтому мы руководствуемся формулой x/2 и получаем 10/2 = 5.
Вне зависимости от того, четное число мы подставляем в функцию или нечетное, ее значение будет целым положительным числом.
Короче говоря, если x – целое положительное число, F (x) – тоже целое положительное число.
Мы можем итерировать нашу функцию, потому что выходное значение удовлетворяет условию, наложенному на входное значение. Что мы получим, итерируя функцию при начальном значении x = 12?
• F (12) = 6, потому что число 10 четное;
• F² (12) = F (6) = 3, потому что число 6 четное;
• F³ (12) = F (3) = 10, потому что число 3 нечетное;
• F⁴ (12) = F (10) = 5.
Вот удобный способ проиллюстрировать итерации. Мы записываем 12 → 6, подразумевая, что значение функции от 12 равно 6. Мы можем записать итерации F следующим образом:

Тройка 4 → 2 → 1 повторяется! А что дальше? Так как F(1) = 4, F(4) = 2, F(2) = 1, следующие три значения те же самые.
Другими словами, когда мы дошли до числа 1, тройка 4 → 2 → 1 будет повторяться до бесконечности.
Начнем с другой величины, скажем с 9. Вот что мы имеем: 9 → 28 → 14 → 7 → 22 → 11 → 34 → 17 → 52 → 26 → 13 → 40 → 20 → 10 → 5 → 16 → 8 → 4 → 2 → 1.
Вот еще один впечатляющий ряд итераций:
27 → 82 → 41 → 124 → 62 → 31 → 94 → 47 → 142 → 71 → 214 → 107 → 322 → 161 → 484 → 242 → 121 → 364 → 182 → 91 → 274 → 137 → 412 → 206 → 103 → 310 → 155 → 466 → 233 → 700 → 350 → 175 → 526 → 263 → 790 → 395 → 1186 → 593 → 1780 → 890 → 445 → 1336 → 668 → 334 → 167 → 502 → 251 → 754 → 377 → 1132 → 566 → 283 → 850 → 425 → 1276 → 638 → 319 → 958 → 479 → 1438 → 719 → 2158 → 1079 → 3238 → 1619 → 4858 → 2429 → 7288 → 3644 → 1822 → 911 → 2734 → 1367 → 4102 → 2051 → 6154 → 3077 → 9232 → 4616 → 2308 → 1154 → 577 → 1732 → 866 → 433 → 1300 → 650 → 325 → 976 → 488 → 244 → 122 → 61 → 184 → 92 → 46 → 23 → 70 → 35 → 106 → 53 → 160 → 80 → 40 → 20 → 10 → 5 → 16 → 8 → 4 → 2 → 1.
Мы снова дошли до 1, но после ста с лишним итераций.
Гипотеза Коллатца заключалась в том, что вне зависимости от того, с какого целого положительного числа x мы начинаем, последовательность итераций рано или поздно достигает единицы и тройка 4 → 2 → 1 повторяется до бесконечности.
Проблема была решена самым умопомрачительным образом – штурм потребовал чудовищной дотошности математиков-профессионалов и математиков-любителей.


