Глава 2. Вычислительная сложность
Практически любой расчет можно выполнить несколькими способами. Из них следует выбирать такие, которые позволяют выполнить вычисления за наименьшее время.
Ада Лавлейс
Сколько времени потребуется, чтобы разложить по порядку 26 перетасованных карт? А если у вас будет 52 карты, уйдет ли на эту же операцию вдвое больше времени? И насколько больше его потребуется на тысячу карточных колод? Ответ неразрывно связан с методом, который используется для сортировки карт.
Метод — это список однозначных команд, служащих для достижения цели. Метод, который всегда требует конечной серии операций, называется алгоритмом. Например, алгоритм сортировки карт представляет собой метод, где определены некие операции для сортировки колоды из 26 карт по масти и достоинству.
На меньшее количество операций нужно меньше вычислительной мощности. Нам нравятся быстрые решения, поэтому мы следим за числом операций в наших алгоритмах. В случае со многими алгоритмами необходимое число операций быстро растет с увеличением объема входных данных. В нашем случае может потребоваться всего несколько операций для сортировки 26 карт, но в четыре раза больше операций для сортировки 52 карт!
Чтобы избежать непредвиденных сложностей, связанных с раздуванием задачи, нужно узнать временную сложность алгоритма. В этой главе пойдет речь о том, как:
 рассчитывать и интерпретировать временные сложности;
рассчитывать и интерпретировать временные сложности;
 выражать их рост при помощи необычной нотации «О большое»;
выражать их рост при помощи необычной нотации «О большое»;
 избегать экспоненциальных алгоритмов;
избегать экспоненциальных алгоритмов;
 убедиться, что у вашего компьютера достаточно памяти.
убедиться, что у вашего компьютера достаточно памяти.
Но прежде нам предстоит узнать, как определяется временная сложность алгоритма.
Временная сложность записывается как: T(n). Она показывает количество операций, которые алгоритм выполняет при обработке входящих данных объема n. Также T(n) называют стоимостью выполнения алгоритма. Если наш алгоритм сортировки игральных карт подчиняется T(n) = n2, то мы можем предсказать, насколько больше потребуется времени, чтобы отсортировать колоду двойного размера: 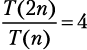 .
.
Надейтесь на лучшее, но готовьтесь к худшему
Будет ли быстрее отсортирована колода карт, которая уже почти упорядочена? Объем входящих данных — не единственная характеристика, влияющая на количество требуемых алгоритмом операций. Когда алгоритм может иметь разные значения T(n) для одного n, мы обращаемся к случаям, или, говоря по-другому, вариантам развития событий.
• Лучший случай — это ситуация, когда для любых входящих данных установленного объема требуется минимальное количество операций. В сортировке такое происходит, когда входящие данные уже упорядочены.
• Худший случай — когда для любых входящих данных данного объема требуется максимальное количество операций. Во многих алгоритмах сортировки такое случается, когда данные на входе передаются в обратном порядке.
• Средний случай предполагает среднее количество операций, обычно нужных для обработки входящих данных этого объема. Для сортировки средним считается случай, когда входящие данные поступают в произвольном порядке.
Худший случай — самый важный из всех. Ориентируясь на него, вы обеспечиваете себе гарантию. Когда ничего не говорится о сценарии, ориентируйтесь на худший случай. Далее мы узнаем, как на практике анализировать события c учетом худшего варианта их развития.

Рис. 2.1. Оценка времени
2.1. Оценка затрат времени
Временную сложность алгоритма определяют, подсчитывая основные операции, которые ему требуются для гипотетического набора входных данных объема n. Мы продемонстрируем это на примере сортировки выбором, алгоритма сортировки с вложенным циклом. Внешний цикл for обновляет текущую позицию, с которой ведется работа, внутренний цикл for выбирает элемент, который затем подставляется в текущую позицию:
function selection_sort(list)
for current ← 1 … list.length – 1
smallest ← current
for i ← current + 1 … list.length
if list[i] < list[smallest]
smallest ← i
list.swap_items(current, smallest)
Давайте посмотрим, что произойдет со списком из n элементов в худшем случае. Внешний цикл совершит n – 1 итераций и в каждой из них выполнит две операции (одно присвоение и один обмен значениями), всего 2n-2 операций. Внутренний цикл сначала выполнится n – 1 раз, затем n – 2 раза, n – 3 раза и т.д. Мы уже знаем, как суммировать эти типы последовательностей:

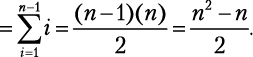
В худшем случае условие if всегда соблюдается. Это означает, что внутренний цикл выполнит одно сравнение и одно присвоение 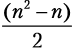 раз, отсюда n2 – n операций. В целом стоимость алгоритма 2n – n складывается из операций внешнего цикла и n2 операций внутреннего цикла. Мы получаем временную сложность:
раз, отсюда n2 – n операций. В целом стоимость алгоритма 2n – n складывается из операций внешнего цикла и n2 операций внутреннего цикла. Мы получаем временную сложность:
T(n) = n2 + n – 2.
Что дальше? Если размер нашего списка был n = 8, а затем мы его удвоили, то время сортировки увеличится в 3,86 раза:
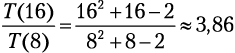 .
.
Если мы снова удвоим размер списка, нам придется умножить время на 3,9. Дальнейшие удвоения дадут коэффициенты 3,94, 3,97, 3,98. Заметили, как результат становится все ближе и ближе к 4? Это значит, что сортировка 2 млн элементов потребует в четыре раза больше времени, чем сортировка 1 млн элементов.
Понимание роста затрат
Допустим, объем входящих данных алгоритма очень велик, и мы его еще увеличиваем. Чтобы предсказать, как изменится время выполнения, нам не нужно знать все члены функции T(n). Мы можем аппроксимировать T(n) по ее наиболее быстрорастущему члену, который называется доминантным членом.
Учетные карточки  Вчера вы опрокинули коробку с учетными карточками, и вам пришлось потратить два часа на сортировку выбором, чтобы все исправить. Сегодня вы рассыпали 10 коробок. Сколько времени вам потребуется, чтобы расставить карточки в исходном порядке?
Вчера вы опрокинули коробку с учетными карточками, и вам пришлось потратить два часа на сортировку выбором, чтобы все исправить. Сегодня вы рассыпали 10 коробок. Сколько времени вам потребуется, чтобы расставить карточки в исходном порядке?
Мы уже убедились, что сортировка выбором подчиняется T(n) = = n2 + n – 2. Наиболее быстро растущим членом является n2, поэтому мы можем записать T(n) ≈ n2. Приняв, что в одной коробке лежит n карточек, мы находим:
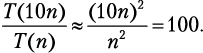
Вам потребуется приблизительно 100 × (2 часа) = 200 часов! А что, если сортировать по другому принципу? Например, есть метод под названием «сортировка пузырьком», временная сложность которого определяется формулой T(n) = 0,5n2 + 0,5n. Наиболее быстро растущий член тогда даст T(n) ≈ 0,5n2, следовательно:
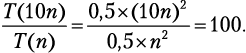

Рис. 2.2. Уменьшение масштаба n2, n2 + n – 2 и 0,5n2 + 0,5n с увеличением n
Коэффициент 0,5 сам себя аннулирует! Понять мысль, что оба выражения — n2 – n – 2 и 0,5n2 + 0,5n — растут как n2, не так-то просто. Почему доминантный член функции игнорирует все другие числа и оказывает наибольшее влияние на рост? Давайте попытаемся эту концепцию представить визуально.
На рис. 2.2 изображены графики двух временных сложностей, которые мы рассмотрели, рядом с графиком n2 на разных уровнях масштабирования. По мере увеличения значения n графики, судя по всему, становятся все ближе и ближе. На самом деле вместо точек в функции T(n) = ∙ n2 + ∙ n + ∙ вы можете подставить любые числа, и она по-прежнему будет расти как n2.
Запомните, такой эффект сближения кривых работает, если наиболее быстро растущий член — одинаковый. График функции с линейным ростом (n) никогда не будет сближаться с графиком квадратичного роста (n2), который, в свою очередь, никогда не догонит график, имеющий кубический рост (n3).
Вот почему в случаях с очень большими объемами входных данных алгоритмы с квадратично растущей стоимостью показывают худшую производительность, чем алгоритмы с линейной стоимостью, но все же намного лучшую, чем алгоритмы с кубической стоимостью. Если вы все поняли, то следующий раздел будет для вас простым: мы всего лишь познакомимся с необычной формой записи, которую программисты используют для выражения этих идей.
2.2. Нотация «О большое»
Существует специальная форма записи, которая обозначает классы роста временных затрат: нотация «О большое». Функция с членом, растущим не быстрее 2n, обозначается как O(2n); функция, растущая не быстрее квадратичной, — как O(n2); функция с линейным или более пологим ростом — как O(n) и т.д. Данная форма записи используется для выражения доминантного члена функций стоимости алгоритмов в худшем случае — это общепринятый способ выражения временной сложности.
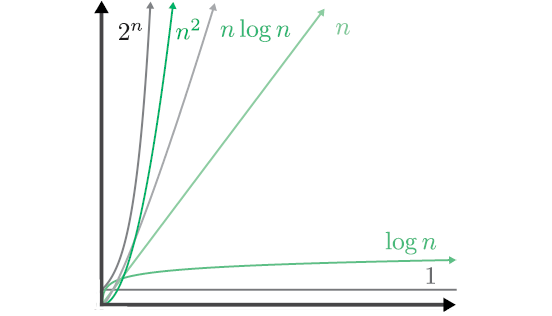
Рис. 2.3. Различные обозначения роста сложности, которые часто можно увидеть внутри O
Сортировка выбором и сортировка пузырьком имеют сложность O(n2), но мы вскоре встретим алгоритмы со сложностью O(n log n), которые выполняют ту же работу. В случае с O(n2) десятикратное увеличение объема входных данных привело к росту стоимости выполнения в 100 раз. Если использовать алгоритм O(n log n), то при увеличении объема входных данных в 10 раз стоимость возрастет всего в 10 log 10 ≈ 34 раза.
Когда n равняется миллиону, n2 составит триллион, тогда как n log n — всего лишь несколько миллионов. Работа, на которую алгоритму с квадратично растущей стоимостью потребуются годы, может быть выполнена за минуты алгоритмом со сложностью O(n log n). Вот почему при создании систем, обрабатывающих очень большие объемы данных, необходимо делать анализ временной сложности.
При разработке вычислительной системы важно заранее выявить самые частые операции. Затем нужно сравнить «О большое» разных алгоритмов, которые выполняют эти операции. Кроме того, многие алгоритмы работают только с определенными структурами входных данных. Если выбрать алгоритм заранее, можно соответствующим образом структурировать данные.
Есть алгоритмы, которые всегда работают с постоянной продолжительностью, независимо от объема входных данных, — они имеют сложность O(1). Например, проверяя четность/нечетность, мы смотрим, является ли последняя цифра нечетной, — и вуаля! Проблема решена. Скорость решения задачи не зависит от величины числа. С алгоритмами O(1) мы познакомимся подробнее в следующих главах. Они превосходны… впрочем, давайте посмотрим, какие алгоритмы никак нельзя назвать «превосходными».
2.3. Экспоненциальное время
Мы говорим, что алгоритмы со сложностью O(2n) имеют экспоненциальное время. Из графика порядков роста (см. рис. 2.3) не похоже, что квадратичные n2 и экспоненциальные сильно отличаются. Если уменьшить масштаб (рис. 2.4), то станет очевидно, что экспоненциальный рост явно доминирует над квадратичным.
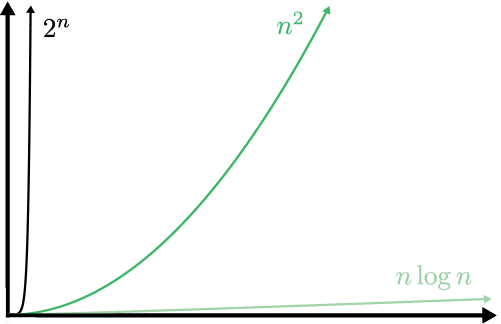
Рис. 2.4. Разные порядки роста в уменьшенном масштабе. Линейные и логарифмические кривые растут так медленно, что их уже не видно на графике
Экспоненциальное время растет так быстро, что мы рассматриваем эти алгоритмы как невыполнимые. Они пригодны для очень немногих типов входных данных и требуют значительной вычислительной мощности, если только объем данных не до смешного мал. Не помогут ни оптимизация каждого аспекта программного кода, ни использование суперкомпьютеров. Сокрушительное экспоненциальное время делает эти алгоритмы бесперспективными.
Чтобы наглядно представить взрывной экспоненциальный рост, уменьшим еще масштаб графика и изменим числа (рис. 2.5). Для экспоненциальной функции основание уменьшено с 2 до 1,5 и добавлен делитель 1000. Степенной же показатель увеличен с 2 до 3 и добавлен множитель 1000.
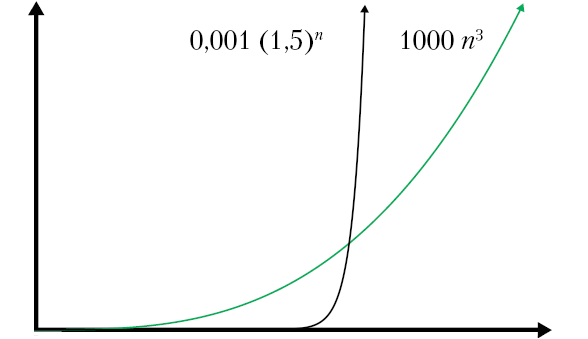
Рис. 2.5. Никакая степенная функция не превзойдет экспоненциальную. На этом графике выбран такой масштаб, что кривой n log n даже не видно из-за ее слишком медленного роста
Есть еще более бесполезные алгоритмы. Речь идет об алгоритмах с факториальным временем, сложность которых составляет O(n!). Алгоритмы с экспоненциальным и факториальным временем ужасны, но они нужны для выполнения самых трудных вычислительных задач — знаменитых недетерминированных полиномиальных (NP-полных) задач. Мы увидим примеры NP-полных задач в следующей главе. А пока запомните вот что: первый человек, который найдет неэкспоненциальный алгоритм для NP-полной задачи, получит миллион долларов  от Математического института Клэя, частной некоммерческой организация, расположенной в Кембридже.
от Математического института Клэя, частной некоммерческой организация, расположенной в Кембридже.
Очень важно распознать класс задачи, с которой вы имеете дело. Если она является NP-полной, то пытаться найти ее оптимальное решение — это все равно что сражаться с ветряными мельницами (если только вы не решили получить тот миллион долларов).
2.4. Оценка затрат памяти
Даже если бы мы могли выполнять операции бесконечно быстро, мы все равно столкнулись бы с ограничениями. Алгоритмам во время их исполнения нужна рабочая область для хранения промежуточных результатов. Эта область занимает память компьютера, отнюдь не бесконечную.
Мера рабочей области хранения, в которой нуждается алгоритм, называется пространственной сложностью. Анализ пространственной сложности выполняется аналогично анализу временной сложности. Разница лишь в том, что мы ведем учет не вычислительных операций, а памяти компьютера. Мы наблюдаем за тем, как эволюционирует пространственная сложность с ростом объема входных данных, точно так же, как делаем это в случае временной сложности.
Например, для сортировки выбором (см. раздел «Оценка затрат времени») нужна рабочая область хранения для фиксированного набора переменных. Число переменных не зависит от объема входных данных. Поэтому мы говорим, что пространственная сложность сортировки выбором составляет O(1) — независимо от объема входных данных она требует одного объема памяти компьютера для рабочей области хранения.
Однако многие другие алгоритмы нуждаются в такой рабочей области хранения, которая растет вместе с объемом входных данных. Иногда бывает невозможно удовлетворить потребности алгоритма в памяти. Вы не найдете подходящий алгоритм сортировки с временной сложностью O(n log n) и пространственной сложностью O(1). Ограниченность памяти компьютера иногда вынуждает искать компромисс. В случае если доступно мало памяти, вам, вероятно, потребуется медленный алгоритм с временной сложностью, потому что он имеет пространственную сложность O(1). В последующих главах мы увидим, как разумно выстроенная обработка данных способна улучшить пространственную сложность.
Подведем итоги
Из этой главы нам стало известно, что алгоритмы могут проявлять различный уровень «жадности» по отношению к потреблению вычислительного времени и памяти компьютера. Мы узнали, каким образом это можно диагностировать при помощи анализа временной и пространственной сложности, и научились вычислять временную сложность путем нахождения точной функции T(n), то есть количества выполняемых алгоритмом операций.
Мы увидели, как можно выражать временную сложность с помощью нотации «О большое» (O). На протяжении всей книги мы будем использовать ее, выполняя простой анализ временной сложности алгоритмов. Во многих случаях нет необходимости вычислять T(n), чтобы определить сложность алгоритма по «O большому». В следующей главе мы увидим более простые способы расчета сложности.
Еще мы увидели, что стоимость выполнения экспоненциальных алгоритмов имеет взрывной рост и делает их непригодными для входных данных большого объема. И мы узнали, как отвечать на вопросы:
• Насколько отличаются алгоритмы по числу требуемых для их выполнения операций?
• Как меняется время, необходимое алгоритму, при умножении объема входных данных на некую константу?
• Будет ли алгоритм по-прежнему выполнять приемлемое количество операций в случае, если вырастет объем входных данных?
• Если алгоритм выполняется слишком медленно для входных данных определенного объема, поможет ли его оптимизация или использование суперкомпьютера?
В следующей главе мы сосредоточимся на том, как связаны стратегии, лежащие в основе дизайна алгоритмов, с их временной сложностью.
Полезные материалы
• Кнут Д. Искусство программирования. Т. 1 (The Art of Computer Programming, см. ).
• Зоопарк вычислительной сложности (The Computational Complexity Zoo, hackerdashery, см. ).
Любезно предоставлено .
Чтобы разобраться в алгоритме, выполните его на бумаге с небольшим объемом входящих данных.
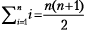 (см. раздел «Комбинаторика»).
(см. раздел «Комбинаторика»).
Читаются такие конструкции следующим образом: «алгоритм сортировки имеет временную сложность o-n-квадрат».
По поводу сложностей большого «О» большинства алгоритмов, которые выполняют типовые задачи, смотрите .
Было доказано, что неэкспоненциальный алгоритм для любой NP-полной задачи может быть обобщен для всех NP-полных задач. Поскольку мы не знаем, существует ли такой алгоритм, вы также получите миллион долларов, если докажете, что NP-полная задача не может быть решена с использованием неэкспоненциальных алгоритмов.

