ГЛАВА ДЕСЯТАЯ
ТЫ ТАМ ЕСТЬ, БОГ? ЭТО Я, БАЙЕСОВСКИЙ ВЫВОД
Многие опасаются эпохи больших данных. В какой-то степени страшит будущее: а вдруг начнут воплощаться пока еще туманные перспективы, что алгоритмы, обеспеченные достаточным объемом данных, начнут справляться с задачей логического вывода лучше самого человека. Людям внушает страх все сверхъестественное: существа, умеющие трансформироваться; какие-то сущности, восстающие из мертвых; создания, способные приходить к таким умозаключениям, которые нам и не снились. Было по-настоящему жутко, когда бездушная статистическая модель, внедренная по программе маркетингового анализа (Guest Marketing Analytics) в сети розничных магазинов Target, учитывая данные о покупках, пришла к правильному умозаключению, что одна из покупательниц (прошу прощения, гостей) — девушка-подросток из Миннесоты — беременна. На основании какой-то загадочной формулы, граничащей с колдовством, было проанализировано увеличение доли определенных покупок: лосьона без запаха, витаминов и ватных шариков. И вот результат: компания Target начала отправлять своей покупательнице купоны на товары для новорожденных — к большому изумлению отца девушки, который, будучи всего лишь человеческим существом, обладал довольно убогими дедуктивными способностями и все еще оставался в неведении. Страшно даже подумать, что мы живем в мире, где Google, Facebook, ваш мобильник и, черт побери, даже Target знают о вас больше, чем собственные родители.
Но, может быть, стоило бы меньше бояться внушающих ужас сверхмощных алгоритмов и больше тревожиться о плохих.
Начнем с того, что плохой алгоритм может оказаться самым лучшим. Алгоритмы, поддерживающие работу компаний в Кремниевой долине, с каждым годом становятся все более изощренными, а вводимые в них данные — все более объемными и полезными. Согласно модели будущего, Google должен знать вас: его центральное хранилище данных, обрабатывая миллионы микронаблюдений («Сколько времени он колебался, прежде чем щелкнуть на этом…», «Как долго его очки Google Glass задержались на том…» и так далее), начнет предвосхищать ваши поступки, предпочтения и даже мечты, особенно что касается покупок, которые вы захотите сделать, или вас убедят, что вы этого хотите.
Именно так все может быть! Но может и не быть. Существует множество математических задач, в которых обеспечение большего количества данных повышает точность полученного результата довольно предсказуемым способом. Чтобы предсказать траекторию движения астероида, необходимо измерить скорость его движения и определить местоположение, а также оценить гравитационное воздействие его астрономических соседей. Чем больше связанных с астероидом параметров вы сможете измерить, тем более точную траекторию его движения вам удастся составить.
Однако некоторые задачи похожи скорее на прогноз погоды. Это еще одна ситуация, в которой важнейшую роль играет наличие большого объема подробных данных, а также вычислительных ресурсов для их быстрой обработки. В 1950 году первой вычислительной машине ENIAC понадобилось двадцать четыре часа, чтобы создать имитационную модель погоды на сутки — это стало поразительным достижением в области компьютерных вычислений космической эры. В 2008 году такие вычисления были выполнены на мобильном телефоне Nokia 6300 менее чем за секунду. В наше время прогнозы погоды не просто составляются быстрее — они намного точнее и охватывают более продолжительный период. Типичный прогноз погоды на пять дней в 2010 году был таким же точным, как прогноз на три дня в 1986 году.
Хотелось бы думать, что прогнозы будут становиться все лучше и лучше по мере усиления нашей способности собирать данные. Не сможем ли мы в конечном счете реализовать в высшей степени точную имитационную модель атмосферы всей планеты в компьютерном парке где-нибудь под штаб-квартирой сети The Weather Channel? В таком случае, чтобы узнать погоду в следующем месяце, вам понадобится просто выполнить имитационное моделирование, охватывающее немного более длительный период.
Все это заманчиво, но невозможно. Энергия в атмосфере циркулирует очень быстро, меняя масштаб от крохотного до глобального; при этом даже малейшие изменения в одном месте и времени могут повлечь за собой совершенно другие последствия в другом месте через несколько дней. С формальной точки зрения, погода хаотична. Именно в процессе численного изучения погоды Эдвард Лоренц открыл математическую концепцию хаоса. «Один метеоролог отметил, что, если теория была бы правильной, одного взмаха крыльев чайки было бы достаточно, для того чтобы навсегда изменить погодные условия. Это противоречие еще не решено, но самые последние данные как будто говорят в пользу чаек», — писал он.
Существует жесткое ограничение в отношении того, на какой период мы можем прогнозировать погоду, сколько бы данных нам ни удалось собрать. Лоренц считал, что этот период должен быть не более двух недель, и усилия метеорологов всего мира до сих пор не дали нам оснований ставить этот предел под сомнение.
К чему ближе человеческое поведение — к астероиду или погоде? Безусловно, все зависит от того, о каком аспекте человеческого поведения идет речь. Как минимум в одном смысле поведение человека прогнозировать даже труднее, чем погоду. У нас есть очень хорошая математическая модель для погоды, позволяющая нам составлять более точные прогнозы хотя бы на краткосрочный период при наличии доступа к большему объему данных — даже если потом присущий этой системе хаос неизбежно берет верх. В случае человеческого поведения у нас такой модели нет и, видимо, никогда не будет. Это делает задачу прогнозирования гораздо более трудной.
Онлайновая компания Netflix, работающая в области индустрии развлечений, в 2006 году организовала конкурс с главным призом в один миллион долларов, чтобы определить, сможет ли кто-нибудь в мире написать алгоритм, который будет справляться с задачей по рекомендациям фильмов клиентам лучше, чем алгоритм самой компании. Казалось, финишная черта находится не так уж далеко от старта: победителем должна была стать первая программа, которая на 10% лучше справится с задачей рекомендации фильмов клиентам, чем программа Netflix.
Участникам конкурса предоставили огромное количество данных о почти полумиллионе пользователей Netflix и около миллиона анонимных мнений, оценивающих 17 700 фильмов. Задача состояла в том, чтобы предсказать, как пользователи оценят фильмы, которых еще не видели. Есть данные — много данных, имеющих непосредственное отношение к поведению, — и вы пытаетесь прогнозировать это поведение. Очень сложная задача. В итоге прошло целых три года, прежде чем кто-то смог превысить 10%-ную планку, причем произошло это, лишь когда несколько групп, принимавших участие в конкурсе, объединились и создали гибрид «почти пригодных» алгоритмов. Они надеялись, что это мощное алгоритмическое чудо выведет их на финишную прямую. Netflix так и не использовала победивший алгоритм в своем бизнесе, поскольку к моменту завершения конкурса компания уже переходила от рассылки DVD-дисков по почте к трансляции фильмов методом потокового вещания, что делало неиспользованные рекомендации совсем бесполезными. Наверняка кто-то из вас пользовался услугами Netflix (или Amazon, или Facebook, или любого сайта, пытающегося навязать вам выбор продуктов на основании собранных о вас данных), поэтому вы и без меня знаете, насколько неудачны и до смешного нелепы их рекомендации. Но, по мере того как ваш профиль начнет пополняться все большим количеством данных, их советы будут становиться более уместными. А может быть, и не будут.
С точки зрения таких компаний, нет ничего плохого в том, что они занимаются сбором и уточнением ваших данных. Конечно, для Target было бы удобнее всего, если они могли бы точно узнавать о беременности клиенток, отслеживая данные на их карточках постоянного покупателя. Но они этого не могут и потому не знают, беременны вы или нет. Тем не менее даже догадки о вашей беременности принесли бы компании пользу и дали бы возможность делать свои прогнозы на 10% точнее, чем сейчас. То же самое касается Google. Компании нет необходимости точно знать, какой продукт вы хотите приобрести; все, что ей нужно, — иметь чуть более точное представление о ваших предпочтениях, чем конкурирующие фирмы. Как правило, компании работают с невысокой рентабельностью. Для вас нет ничего страшного, прогнозируете ли вы свое поведение точнее хотя бы процентов на десять или нет, но для компаний 10% — это довольно большие деньги. Во время проведения конкурса я спросил вице-президента Netflix Джима Беннетта, который занимался вопросами рекомендаций, почему компания предложила столь большой приз. Он ответил, что мне следовало бы спросить, почему приз такой маленький. На первый взгляд небольшое повышение эффективности рекомендаций на 10% позволило бы возместить этот миллион долларов за меньшее время, чем то, которое понадобилось для создания еще одного фильма The Fast and the Furious («Форсаж»).
ЗНАЕТ ЛИ FACEBOOK, ЧТО ВЫ ТЕРРОРИСТ?
Итак, корпорации, имеющие доступ к большим массивам информации, по-прежнему обладают довольно ограниченными знаниями о ваших персональных данных. Что тогда вас волнует?
И все-таки причины для беспокойства есть. Вот одна из них. Предположим, группа специалистов Facebook решает разработать метод определения, кто из пользователей социальной сети может быть причастен к террористической деятельности, направленной против Соединенных Штатов Америки. В математическом плане эта задача не сильно отличается от определения вероятности, что пользователю Netflix понравится фильм Ocean’s Thirteen («Тринадцать друзей Оушена»). Как правило, Facebook известны реальные имена пользователей и их место жительства, поэтому компания может использовать информацию из открытых источников для составления списка профилей, принадлежащих людям, уже имевшим судимости за террористические преступления или за поддержку террористических группировок. Далее начинается математика. Склонны ли террористы делать больше обновлений в день по сравнению с общей совокупностью пользователей этой социальной сети? или меньше? или этот показатель у них такой же, как и у всех остальных? Есть ли слова, которые чаще появляются в их обновлениях? Есть ли музыкальные группы, спортивные команды или продукты, к которым они особенно испытывают или не испытывают симпатию? Сложив все это вместе, вы можете присвоить каждому пользователю балл, отражающий вашу лучшую оценку вероятности, что у данного пользователя есть или будут связи с террористическими группировками. Примерно то же самое делают в Target, когда сопоставляют данные о ваших покупках для определения вероятности, беременны вы или нет.
Однако существует одна важная особенность: беременность — явление довольно распространенное, тогда как терроризм — скорее редкое. Почти во всех случаях расчетная вероятность того, что данный пользователь станет террористом, крайне мала. Таким образом, итогом этого проекта стал бы не центр профилактики преступлений — как в фильме Minority Report («Особое мнение»), — в котором всеобъемлющий алгоритм Facebook раньше вас узнает, что вы собираетесь совершить преступление. Представьте себе нечто более непритязательное: скажем, список сотен тысяч пользователей, о которых Facebook с определенной степенью достоверности может сказать следующее: «Вероятность того, что люди из этой группы могут быть террористами или пособниками терроризма, в два раза больше, чем в случае обычных пользователей Facebook».
Что вы сделаете, если обнаружите, что человек, входящий в этот список, живет с вами по соседству? Наверное, позвоните в ФБР?
Прежде чем предпринимать этот шаг, давайте нарисуем еще одну матрицу.
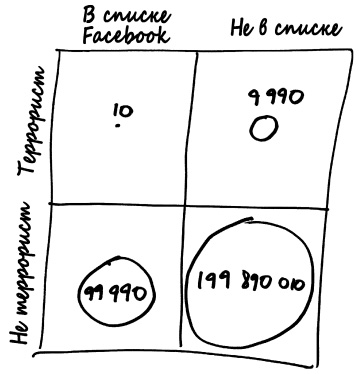
Содержимое этой матрицы — около 200 миллионов пользователей сети Facebook в Соединенных Штатах. Линия между верхней и нижней частями матрицы отделяет будущих террористов (верхняя часть) от невиновных (нижняя часть). Безусловно, любая террористическая ячейка в США довольно немногочисленна. Скажем, если быть максимально подозрительными, в стране есть около 10 тысяч людей, за которыми федералам действительно стоит присматривать. Это один из каждых 20 тысяч пользователей общей пользовательской базы.
Разделение матрицы на левую и правую часть, собственно, и есть то, что делает Facebook: с левой стороны находится сотня тысяч людей, которых в Facebook считают с высокой степенью вероятности связанными с терроризмом. Давайте поверим Facebook на слово, будто их алгоритм настолько хорош, что отмеченные таким образом люди могут быть террористами с вероятностью в два раза большей, чем обычные пользователи. Следовательно, в этой группе один из 10 тысяч пользователей, или 10 человек, окажутся террористами, тогда как 99 990 — нет.
Если 10 из 10 000 будущих террористов находятся в верхней левой клетке, значит, в верхней правой находятся оставшиеся 9990 пользователей. С помощью тех же рассуждений можно сделать такой вывод: в пользовательской базе Facebook есть 199 990 000 людей, не являющихся террористами; 99 990 из них были отмечены алгоритмом и находятся в нижней левой клетке; оставшиеся 199 890 010 пользователей относятся к нижней правой клетке. Если сложить значения всех четырех клеток матрицы, получится 200 000 000 пользователей — другими словами, все пользователи Facebook в США.
Где-то в этой матрице, состоящей из четырех клеток, находится и ваш сосед по дому.
Но где именно? Он болтается где-то в левой половине матрицы, поскольку в Facebook его отнесли к числу подозреваемых, — и это все, что вы знаете.
Следует обратить внимание, что в левой половине матрицы почти нет террористов. На самом деле вероятность того, что ваш сосед невиновен, составляет 99,99%.
В каком-то смысле это ситуация аналогична той панике, возникшей в Англии из-за противозачаточных препаратов. Включение пользователя в список Facebook в два раза увеличивает вероятность, что он террорист, что звучит ужасно. Но исходная вероятность сама по себе крайне мала, поэтому, если вы увеличите ее в два раза, она по-прежнему останется совсем небольшой.
Однако эту ситуацию можно интерпретировать и другим способом, который еще больше подчеркивает, насколько вероломными и сбивающими с толку могут быть рассуждения о неопределенности. Задайте себе такой вопрос: если человек на самом деле не является будущим террористом, какова вероятность, что его без всяких на то оснований включат в список Facebook?
В представленной выше матрице это означает следующее: если вы находитесь в нижней строке матрицы, какова вероятность того, что ваше место именно в левой клетке?
Это достаточно легко вычислить. В нижней половине матрицы 199 990 000 пользователей, из которых 99 990 находятся слева. Следовательно, вероятность того, что алгоритм Facebook отметит невиновного человека как потенциального террориста, составляет:
99 990/199 990 000,
или около 0,05%.
Все верно: невиновный человек имеет всего один шанс из двух тысяч, что Facebook неправильно отнесет его к числу потенциальных террористов!
Какие чувства вы испытываете по отношению к своему соседу теперь?
Ход рассуждений, лежащий в основе p-значения, дает нам четкий ориентир. Нулевая гипотеза состоит в том, что ваш сосед не террорист. В соответствии с этой гипотезой (другими словами, исходя из невиновности соседа) вероятность того, что он появится в «красном списке» Facebook, составляет всего 0,05%, гораздо ниже порога статистической значимости 1 из 20. Другими словами, согласно правилам, которым в подавляющем большинстве случаев подчиняется современная наука, вы имеете все основания отбросить эту нулевую гипотезу и объявить своего соседа террористом.
Вот только вероятность того, что он не террорист, равна 99,99%.
Тем не менее почти нет шансов на то, что алгоритм отметит невиновного человека как террориста. В то же время почти все люди, которых выделяет алгоритм, невиновны. Похоже на парадокс, но на самом деле это не так. Таково положение дел. Если вы сделаете глубокий вдох и внимательно присмотритесь к матрице, вы все поймете.
Суть вот в чем. На самом деле существуют два вопроса, которые вы можете задать. На первый взгляд они кажутся одинаковыми, но это не так.
Вопрос 1: какова вероятность, что человек попадет в список Facebook, при условии что он не террорист?
Вопрос 2: какова вероятность, что человек не террорист, при условии что он входит в список Facebook?
Эти вопросы отличаются друг от друга, поскольку на них даются разные ответы. По-настоящему разные ответы. Мы уже видели, что ответ на первый вопрос — около 1 из 2000, тогда как ответ на второй вопрос — 99,99%. И именно ответ на второй вопрос вам нужен.
Величины, о которых идет речь в этих вопросах, обозначаются термином «условные вероятности»: «вероятность того, что имеет место Х, при условии Y». А мы ломаем здесь голову над тем, что вероятность Х при условии Y — это не то же самое, что вероятность Y при условии Х.
Если сказанное кажется вам знакомым, так и должно быть: это именно та проблема, с которой мы столкнулись, когда рассматривали доказательство от маловероятного; p-значение — это ответ на вопрос:
«Вероятность, что наблюдаемый результат эксперимента будет иметь место при условии, что нулевая гипотеза правильна».
Однако нам нужно знать другую условную вероятность:
«Вероятность, что нулевая гипотеза правильна при условии наблюдения определенного результата эксперимента».
Опасность возникает именно в случае, когда мы путаем вторую величину с первой. И такая путаница имеет место повсюду, не только в научных исследованиях. Когда окружной прокурор наклоняется к жюри присяжных и объявляет «Есть один шанс из пяти миллионов, повторяю, один шанс из пяти миллионов, что ДНК невиновного человека совпадет с ДНК, обнаруженной на месте преступления», он отвечает на первый вопрос: «Какова вероятность того, что невиновный человек выглядит виновным?» Однако работа жюри присяжных в том, чтобы найти ответ на второй вопрос: «Какова вероятность, что на первый взгляд виновный подсудимый невиновен?» На этот вопрос окружной прокурор уже не поможет им ответить.
* * *
Пример с Facebook и террористами объясняет, почему плохие алгоритмы должны вызывать не только такое же беспокойство, что и хорошие, но и большее. Мало приятного в том, что Target знает о вашей беременности. Гораздо хуже, если вы не террорист, но Facebook считает вас таковым.
Может быть, вы думаете, что Facebook никогда не станет составлять список потенциальных террористов (налоговых мошенников, педофилов) или делать такой список общедоступным, в случае если он все-таки будет создан. Зачем им это надо? На чем здесь можно заработать деньги? Может, так и есть. Однако Агентство национальной безопасности США также собирает данные о жителях Америки, являются ли они пользователями Facebook или нет. Происходит нечто вроде составления черного списка — если только вы не думаете, что в АНБ регистрируют метаданные о всех наших телефонных звонках лишь ради того, чтобы давать операторам мобильной связи полезные советы, где им следует построить дополнительные сигнальные вышки. Большие данные — не магическая сила; они не говорят федералам, кто террорист, а кто нет. Но, чтобы составлять длинные списки людей, по тем или иным причинам отмеченных красным флажком, отнесенных к группе повышенного риска или обозначенных как «подозреваемые», — никакого волшебства не нужно. Большинство людей, включенных в такие списки, не имеют никакого отношения к терроризму. Вы уверены, что не принадлежите к их числу?
ПАРАПСИХОЛОГИЧЕСКОЕ РАДИО И ПРАВИЛО БАЙЕСА
Чем обусловлен этот явный парадокс красного списка террористов? Почему механизм р-значения, который кажется столь разумным, так плохо работает в таком контексте? Причина вот в чем: р-значение учитывает, какую долю пользователей Facebook отмечает флажком (примерно 1 из 2000), но полностью игнорирует относительное количество людей, которые принадлежат к числу террористов. Когда вы пытаетесь определить, является ли ваш сосед тайным террористом, у вас есть важная предварительная информация: большинство людей не террористы! Попробуйте проигнорировать этот факт. Как сказал Рональд Эйлмер Фишер, вы должны оценить каждую гипотезу «в свете эмпирических данных» о том, что вы уже о ней знаете.
Но как это сделать?
Здесь необходимо вспомнить историю о парапсихологическом радио.
В 1937 году все были помешаны на телепатии. Книга психолога Джозефа Бэнкса Райна New Frontiers of the Mind («Новые рубежи разума»), которая в успокаивающе рассудительном тоне, с использованием количественных оценок рассказывала удивительные вещи об экспериментах Райна с экстрасенсорным восприятием в Университете Дьюка, стала бестселлером и лучшей книгой по версии клуба «Книга месяца», а парапсихологические способности были животрепещущей темой разговоров во время коктейлей по всей стране. Эптон Синклер, автор известного романа The Jungle («Джунгли»), выпустил в 1930 году целую книгу Mental Radio («Ментальное радио») об экспериментах Райна и о парапсихологическом взаимодействии со своей женой Мэри. Эта тема была настолько популярной, что Альберт Эйнштейн написал предисловие к немецкому изданию книги; ученый не стал активно поддерживать идею телепатии, но отметил, что книга Синклера «заслуживает самого пристального внимания» со стороны психологов.
Разумеется, средства массовой информации хотели поучаствовать в общем безумии. Компания Zenith Radio Corporation в сотрудничестве с Райном организовали 5 сентября 1937 года масштабный эксперимент, который был возможен только благодаря имеющейся в их распоряжении новой технологии коммуникации. Пять раз подряд ведущий эксперимента запускал колесо рулетки, а несколько людей, считающих себя телепатами, смотрели на него. При каждом запуске колеса шарик останавливался либо в черной, либо красной ячейке, а парапсихологи изо всех сил концентрировали свое внимание на соответствующем цвете, передавая по всей стране сигнал по собственному каналу вещания. Слушателей радиостанции попросили использовать свои парапсихологические способности для максимальной передачи ментального сигнала и написать в адрес радиостанции письмо, указав последовательность из пяти цветов, сигнал о которых они получили. Ответили более сорока тысяч слушателей радиостанции, и даже в следующих передачах, когда эксперимент утратил свою новизну, в Zenith Radio Corporation получали тысячи ответов в неделю. Это была проверка парапсихологических способностей в масштабе, недоступном для Райна, работавшем в своем кабинете в Университете Дьюка с каждым испытуемым в отдельности. Этот эксперимент был своего рода предтечей эры больших данных.
В конечном счете результаты эксперимента оказались неблагоприятными для телепатии. Однако накопленные данные об ответах оказались весьма полезными для психологов в совершенно другом смысле. Слушатели пытались воспроизвести последовательности черных и красных ячеек (далее будем обозначать их буквами B (black — черные ячейки) и R (red — красные ячейки)), выпавших в случае пяти вращений колеса рулетки. Вот эти 32 возможные последовательности:
| BBBBB | BBRBB | BRBBB | BRRBB |
| BBBBR | BBRBR | BRBBR | BRRBR |
| BBBRB | BBRRB | BRBRB | BRRRB |
| BBBRR | BBRRR | BRBRR | BRRRR |
| RBBBB | RBRBB | RRBBB | RRRBB |
| RBBBR | RBRBR | RRBBR | RRRBR |
| RBBRB | RBRRB | RRBRB | RRRRB |
| RBBRR | RBRRR | RRBRR | RRRRR |
Все эти последовательности могут реализоваться с равной вероятностью, поскольку каждое вращение колес с равной вероятностью приводит к попаданию шарика в красную или черную ячейку. А поскольку на самом деле слушатели не принимали никаких парапсихологических эманаций, можно предположить, что их ответы с равной вероятностью совпадут с одним из этих 32 вариантов.
Но это не так. В действительности открытки с ответами, которые прислали слушатели, были распределены весьма неравномерно. Такие последовательности, как BBRBR и BRRBR, слушатели присылали намного чаще, чем можно было бы ожидать при условии случайного выбора, тогда как последовательность RBRBR встречалась гораздо реже, чем ожидалось, а последовательности RRRRR почти не было.
Скорее всего, это вас не удивляет. Последовательность RRRRR почему-то не кажется случайной, как в случае последовательности BBRBR, хотя вращение колеса рулетки может привести к появлению обеих последовательностей с равной вероятностью. Что происходит? Что мы на самом деле подразумеваем, когда говорим, что одна последовательность букв «менее случайна», чем другая?
Вот еще один пример. Быстро загадайте число от 1 до 20.
Вы выбрали 17?
Да, этот фокус не всегда срабатывает, но если вы предложите людям выбрать число от 1 до 20, число 17 выбирают чаще всего. А если вы попросите выбрать число от 0 до 9, чаще всего выбирают 7. Напротив, числа, которые заканчиваются на 0 и 5, выбирают гораздо реже, чем можно было бы ожидать от ряда случайных чисел, — они просто кажутся людям менее случайными. Это приводит к возникновению парадокса. Подобно тому как участники эксперимента с парапсихологическим радио пытались составить случайные последовательности R и B, получив в итоге совершенно неслучайный результат, так и люди, выбирающие случайные числа, склонны делать выбор, заметно отклоняющийся от случайности.
В Иране в 2009 году проводили президентские выборы, которые выиграл действующий на то время президент Махмуд Ахмадинежад. После этого появилось множество обвинений, что результаты выборов были сфальсифицированы. Но как можно проверить легитимность подсчета голосов в стране, правительство которой не допустило к участию в этом процессе независимых наблюдателей?
Двое студентов магистратуры Колумбийского университета Бернд Бебер и Александра Скаццо придумали хитрый способ использовать сами числа в качестве доказательства фальсификации, по сути «убедив» официальные данные о подсчете голосов свидетельствовать против самих себя. Они проанализировали официальные общие результаты четырех основных кандидатов в каждой из двадцати девяти провинций Ирана, то есть всего 116 чисел. Если это были бы подлинные результаты голосования, последние цифры чисел могли быть только случайными. Они должны были быть случайным образом распределены среди цифр 0, 1, 2, 3, 4, 5, 6, 7, 8 и 9, причем почти равномерно: каждая из этих цифр должна была появиться в результатах подсчета голосов в 10% случаев.
Но вот как выглядели результаты подсчета голосов в Иране на самом деле. Среди последних цифр проанализированных чисел было слишком много цифр 7, гораздо больше справедливой доли. Это были не цифры, полученные в результате случайного процесса, а цифры, написанные людьми, которые пытались придать им случайный вид. Само по себе это не является доказательством, что результаты выборов были сфальсифицированы, но дает основания так считать.
Мы, люди, всегда делаем умозаключения, всегда используем наблюдения, для того чтобы уточнить свои суждения по поводу различных конкурирующих теорий, сталкивающихся друг с другом в рамках нашего представления о мире. В некоторых концепциях мы убеждены твердо, почти непоколебимо («Завтра солнце взойдет», «Когда вы выпускаете вещи из рук, они падают»), но в других уверены менее («Если сегодня я сделаю зарядку, то буду хорошо спать ночью», «Телепатии не существует»). У нас есть теории по поводу большого и малого, по поводу того, с чем мы сталкиваемся каждый день, и того, с чем мы столкнулись лишь один раз в жизни. Когда мы находим доводы за или против этих концепций, наша уверенность в них колеблется то в одну, то в другую сторону.
Наша стандартная теория в отношении колеса рулетки состоит в том, что на нем равное количество красных и черных ячеек, а также что шарик с одинаковой вероятностью попадает на красное или на черное. Но есть и конкурирующие теории: например, на колесе больше ячеек того или иного цвета. Давайте упростим ситуацию и будем исходить из предположения, что в вашем распоряжении есть только три теории.
red (больше красных ячеек): колесо сделано так, чтобы шарик попадал на красное в 60% случаев.
fair (равное количество ячеек): на колесе равное количество ячеек обоих цветов, поэтому шарик в половине случаев попадает на красное и в половине случаев — на черное.
black (больше черных ячеек): колесо сделано так, чтобы шарик попадал на черное в 60% случаев.
Какую степень достоверности вы приписываете этим трем теориям? Возможно, вы считаете, что на колесе рулетки одинаковое количество черных и красных ячеек, если только у вас нет оснований думать иначе. Может быть, по вашему мнению, равное количество ячеек (fair) — это правильная теория с вероятностью 90%, что оставляет по 5% теории о том, что больше черных ячеек (black), и теории о том, что больше красных ячеек (red). Мы можем нарисовать для этой ситуации такую же матрицу, как и для списка Facebook.
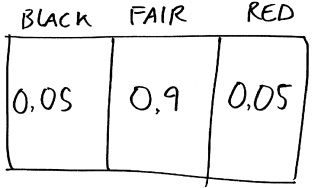
В этой матрице записано то, что в теории вероятностей обозначается термином «априорная вероятность». Разные люди по-разному оценивают значения априорной вероятности: настоящий циник мог бы приписать каждой теории вероятность 1/3, тогда как человек с твердой верой в высокую нравственность производителей колес рулетки может приписать теориям red и black вероятность всего 1% в случае каждой из них.
Однако эти априорные вероятности не являются фиксированными. Если мы получим данные, говорящие в пользу той или иной теории (скажем, шарик пять раз подряд выпадает на красное), степень нашей уверенности в истинности различных теорий может измениться. Как это могло бы проявиться в данном случае? Лучший способ выяснить это сводится к тому, чтобы рассчитать больше условных вероятностей и нарисовать матрицу большего размера.
Какова вероятность, что мы запустим колесо рулетки пять раз и получим последовательность RRRRR? Ответ зависит от того, какая теория истинна. В случае теории fair при каждом запуске колеса рулетки вероятность того, что шарик попадет в красную ячейку, равна 1/2, а значит, вероятность получения последовательности RRRRR составляет
1/2 × 1/2 × 1/2 × 1/2 × 1/2 = 1/32 = 3,125%.
Другими словами, вероятность последовательности RRRRR точно такая же, как и в случае остальных 31 последовательности.
Однако, если верна теория BLACK, вероятность попадания шарика в красную ячейку при каждом запуске равна 40%, или 0,4, а значит, вероятность последовательности RRRRR составляет:
0,4 × 0,4 × 0,4 × 0,4 × 0,4 = 1,024%.
Если же верна теория red, вероятность попадания шарика в красную ячейку при каждом запуске равна 60%, а значит, вероятность последовательности RRRRR составляет:
0,6 × 0,6 × 0,6 × 0,6 × 0,6 = 7,76%.
Теперь давайте увеличим количество клеток в матрице с трех до шести.
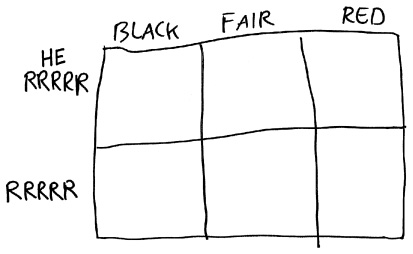
Столбцы этой матрицы по-прежнему соответствуют трем теориям: black, fair и red. Но теперь мы разбиваем каждый столбец на две клетки, одна из которых соответствует получению последовательности RRRRR, а другая — отсутствию этой последовательности. Мы уже выполнили все математические вычисления, необходимые для определения чисел, которые необходимо записать в клетках матрицы. Например, априорная вероятность того, что fair — это правильная теория, составляет 0,9. А 3,125% от этой вероятности, 0,9 × 0,03125 (или около 0,0281), следует записать в клетке, в которой fair — правильная теория, а шарики выпадают в последовательности RRRRR. Число 0,8719 попадает в клетку «теория fair истинна, не RRRRR», так что сумма вероятностей в столбце fair составляет 0,9.
Априорная вероятность попадания в столбец red равна 0,05. Следовательно, вероятность того, что теория red истинна и что шарики выпадают в последовательности RRRRR, составляет 7,76% от 5%, или 0,0039. Это составляет 0,0461 для клетки «теория red истинна, RRRRR».
Теория black также имеет априорную вероятность 0,05. Однако эта теория не так хорошо согласуется с вероятностью последовательности RRRRR. Вероятность того, что теория black истинна, а шарики выпадают в последовательности RRRRR, равна всего 1,024% от 5%, или 0,0005.
Вот как выглядит наша матрица с заполненными клетками.
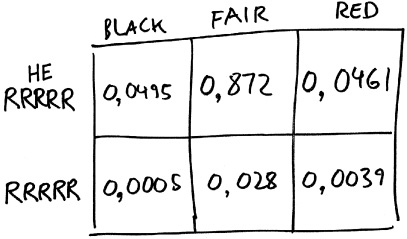
(Обратите внимание, что сумма чисел во всех клетках матрицы равна единице. Именно так и должно быть, поскольку шесть клеток матрицы представляют все возможные варианты.)
Что произойдет с нашими теориями, если мы запустим колесо и действительно получим последовательность RRRRR? Это была бы хорошая новость для теории red и плохая новость для теории black. Именно это мы и видим. Попадание шарика в красные ячейки пять раз подряд означает, что мы находимся в нижней строке матрицы из шести клеток, причем вероятность 0,0005 соответствует теории black, 0,028 теории fair и 0,0039 теории red. Другими словами, при условии формирования последовательности RRRRR наша новая оценка состоит в том, что вероятность истинности теории fair в семь раз больше вероятности теории red, а вероятность теории red примерно в восемь раз больше вероятности теории black.
Если вы хотите перевести эти относительные величины в вероятность, выраженную в процентах, вам нужно просто вспомнить, что общая вероятность всех возможных вариантов должна быть равной единице. Сумма чисел в нижней строке равна 0,0325; следовательно, чтобы обеспечить сумму этих чисел, равную единице, без изменения соотношения между ними, можно просто разделить каждое число на 0,0325. В итоге вы получите следующее.
Вероятность того, что теория black истинна, равна 1,5%.
Вероятность того, что теория fair истинна, равна 86,5%.
Вероятность того, что теория red истинна, равна 12%.
Степень вашей уверенности в истинности теории red увеличилась почти в два раза, тогда как уверенность в теории black почти полностью сошла на нет. Этого и следовало ожидать! Вы видите, как шарик выпадает на красное пять раз подряд, так почему бы вам не начать более серьезно подозревать, что игра нечестная?
Шаг «разделить все на 0,0325» может показаться ситуативным трюком. Но на самом деле это действительно необходимо сделать. Если вам трудно понять это на интуитивном уровне, вот еще одна картина происходящего, которая многим нравится больше. Представьте себе, что есть десять тысяч колес рулетки. И есть десять тысяч комнат, в которых находятся разные колеса, и за каждым колесом играет какой-то человек. Один из людей, играющих в рулетку, — это вы. Но вы не знаете, какое именно колесо вам досталось! В таком случае можно построить модель вашего незнания истинного характера колеса, предположив, что среди исходных десяти тысяч колес в пяти сотнях колес было сделано больше черных ячеек, еще в пяти сотнях больше красных ячеек (red), а в остальных девяти тысячах колес равное количество черных и красных ячеек (fair).
Выполненные выше расчеты говорят о том, что последовательность RRRRR может быть в случае 281 колеса fair, 39 колес red и только 5 колес black. Следовательно, получив последовательность RRRRR, вы все равно не знаете, в какой из десяти тысяч комнат находитесь, но вам удалось существенно сократить количество вариантов: вы находитесь в одной из 325 комнат, в которых шарик выпал на красное пять раз подряд. А среди этих комнат в 281 из них (около 86,5%) колеса fair, в 39 (12%) колеса red и только в 5 (1,5%) колеса black.
Чем больше шариков попадает в красные ячейки, тем более благосклонно вы будете относиться к теории red (и тем меньше будете доверять теории black). Если вы увидели бы, как шарик попадает в красные ячейки десять раз подряд, а не пять, те же вычисления повысили бы вашу оценку вероятности истинности теории red до 25%.
Мы с вами рассчитали, как степень нашей уверенности в истинности различных теорий должна измениться после того, как шарик попадет в красную ячейку пять раз подряд. Полученная величина называется «апостериорная вероятность». Подобно тому как априорная вероятность описывает степень вашей уверенности в истинности теории до получения эмпирических данных, апостериорная вероятность характеризует степень уверенности после получения данных. При этом мы делаем байесовский вывод, поскольку переход от априорной к апостериорной вероятности основан на старой формуле теории вероятностей, которая называется теоремой Байеса. Эта теорема представлена в виде короткого алгебраического выражения, которое я вполне мог бы написать для вас прямо здесь и сейчас. Но я попытаюсь не делать этого, поскольку, если вы начнете применять формулу сугубо механически, не задумываясь о сложившейся ситуации, это может затруднить понимание того, что происходит на самом деле. Все, что вам нужно знать о происходящем здесь, уже можно увидеть в представленной выше матрице.
Апостериорная вероятность зависит не только от эмпирических данных, которые вы получаете, но и от априорной вероятности. Циник, который начал с априорной вероятности теорий black, fair и red, равной 1/3, отреагирует на пять красных ячеек подряд апостериорной оценкой, согласно которой вероятность истинности теории red равна 65%. Доверчивый человек, который начинает с присвоения теории red вероятности всего 1%, даст ей шанс быть истинной всего 2,5% даже после того, как шарик выпадет на красное пять раз подряд.
В байесовской системе степень вашей уверенности в чем-то после получения эмпирических данных зависит не только от того, о чем говорят эти данные, но и от того, в какой степени вы были уверены в этом в самом начале.
Это может показаться настораживающим. Разве наука не должна быть объективной? Вам хотелось бы заявить, что ваши убеждения основаны на одних только фактах, а не на каких-то априорных предубеждениях, с которыми вы вошли в эту дверь. Но давайте посмотрим правде в глаза: на самом деле ни у кого убеждения не формируются таким способом. Если в результате эксперимента получены статистически значимые доказательства, что новая модификация существующего лекарственного препарата замедляет развитие некоторых разновидностей рака, скорее всего вы будете достаточно уверены в эффективности нового препарата. Но, если вы получите те же результаты, поместив пациентов в пластиковую модель Стоунхенджа, разве примете вы, пусть даже неохотно, вывод, что это древнее сооружение действительно фокусирует энергию колебаний Земли на организме человека и останавливает развитие опухоли? Нет, не примете, потому что это полная чушь. Вы подумаете, что, по всей видимости, Стоунхенджу просто повезло. У вас разные априорные оценки этих двух теорий, поэтому в итоге вы по-разному интерпретируете эмпирические данные, несмотря на то что в численном выражении они одинаковы.
То же самое можно сказать об алгоритме поиска террористов, применяемом в Facebook, и о вашем соседе по дому. Присутствие соседа в списке потенциальных террористов действительно наводит на мысль, что он может им быть. Но ваша априорная вероятность истинности этой гипотезы должна быть крайне малой, поскольку большинство людей не являются террористами. Следовательно, несмотря на факт включения соседа в список, ваша апостериорная вероятность остается такой же малой, и вы не беспокоитесь по этому поводу — во всяком случае, не должны беспокоиться.
Полагаться исключительно на проверку значимости нулевой гипотезы — это значило бы поступать совершенно не по-байесовски: строго говоря, такой подход предлагает нам относиться к лекарству от рака и к пластиковому Стоунхенджу с одинаковым уважением. Можно ли считать это ударом по взглядам Фишера на статистику? Напротив. Когда Фишер говорит, что «ни у одного ученого нет фиксированного уровня значимости, в соответствии с которым он из года в год, при любых обстоятельствах отбрасывает гипотезы; скорее, он осмысливает каждую конкретную гипотезу в свете имеющихся доказательств и идей», он имеет в виду, что к научному выводу нельзя (или как минимум не следует) подходить сугубо механически; необходимо учитывать также сформировавшиеся ранее идеи и убеждения.
Впрочем, Фишер не был специалистом по байесовской статистике. В наши дни это словосочетание относится к целой совокупности практик и систем взглядов в статистике (когда-то не очень популярных, но сейчас довольно распространенных), которым свойственно общее расположение к аргументации, основанной на теореме Байеса, однако это не просто вопрос принятия во внимание как прежних убеждений, так и новых эмпирических данных. Байесов подход получил наибольшее распространение в различных видах вывода (например, в случае обучения вычислительных машин способности учиться на основе большого объема информации, полученной от человека), плохо сочетающихся с вопросами «да или нет», на решение которых был рассчитан подход Фишера. В действительности специалисты по байесовской статистике зачастую вообще не думают о нулевой гипотезе. Вместо того чтобы задавать вопрос: «Оказывает ли новый лекарственный препарат какое-либо воздействие?» — они могут больше интересоваться наиболее вероятным предположением прогностической модели, описывающей воздействие разных доз препарата на разные группы людей. А когда эти специалисты действительно говорят о гипотезах, они относительно свободно говорят о вероятности того, что гипотеза (скажем, новый препарат лучше существующего) истинна. Фишер не испытывал такой непринужденности в отношении вероятности истинности гипотез. Он считал, что язык вероятности используется должным образом только в ситуации, в которой имеет место некий реальный случайный процесс.
Теперь мы прибыли на берег огромного моря философских проблем, в которое погрузим только один-два пальца, не больше.
Когда мы называем теорему Байеса теоремой, это предполагает, что речь идет о непререкаемых истинах, подтвержденных математическим доказательством. Это и верно и нет. Все сводится к трудному вопросу о том, что мы имеем в виду, когда говорим «вероятность». Когда мы говорим, что вероятность истинности теории red составляет 5%, мы можем иметь в виду, что на самом деле существует огромное множество колес рулетки, в котором одна из двадцати рулеток сделана так, что шарик выпадает на красное в трех из пяти случаев, а также что любое колесо рулетки, с которым мы сталкиваемся, наугад выбрано из общего множества колес. Если мы имеем в виду именно это, тогда теорема Байеса — очевидный факт, подобный закону больших чисел, о котором шла речь в предыдущей главе. Эта теорема гласит, что в большом интервале времени при условиях, которые мы сформулировали в примере, 12% колес рулетки, выдающих последовательность RRRRR, — это рулетки, отдающие предпочтение красным ячейкам.
Но на самом деле речь идет не об этом. Когда мы утверждаем, что вероятность истинности теории red составляет 5%, мы говорим не о глобальном распределении работающих колес рулетки с систематической ошибкой (откуда нам знать об этом?), а скорее, о собственном психическом состоянии. Пять процентов — это степень нашей уверенности в том, что колесо рулетки, с которым мы имеем дело, смещено в сторону красных ячеек.
Кстати, Фишер полностью отказался принять такой подход. Он безжалостно раскритиковал книгу Джона Мейнарда Кейнса Treatise on Probability («Трактат о вероятности»), в которой говорится, что вероятность «измеряет “степень разумной убежденности”, которая приписывается теореме в свете представленных доказательств». Мнение Фишера об этой точке зрения прекрасно подытожено в заключительных строках: «Если студенты, изучающие математику в нашей стране, приняли бы изложенные в последнем разделе книги господина Кейнса взгляды как нечто непререкаемое, это оттолкнуло бы их от одной из самых перспективных областей прикладной математики, вызвав у некоторых отвращение, а большинство оставив в неведении».
Те, кто готов принять понимание вероятности как степень уверенности, могут рассматривать теорему Байеса не как обычное математическое уравнение, а как своего рода совет, представленный в численном виде. Эта теорема предоставляет в наше распоряжение правило (по поводу которого мы сами решаем, придерживаться его или нет) относительно того, как следует корректировать степень своей уверенности в чем-то в свете новых наблюдений. В новой, более общей форме такая трактовка вероятности стала темой еще более ожесточенных дискуссий. Есть самые непреклонные сторонники байесовской теории, считающие, что все наши убеждения должны быть сформированы посредством строгих байесовских вычислений или как минимум настолько строгих, насколько их способно сделать такими наше ограниченное познание. Другие считают правило Байеса неопределенным качественным ориентиром.
Байесовского видения мира уже достаточно, чтобы объяснить, почему последовательность RBRRB выглядит случайной, тогда как RRRRR нет, хотя обе они в равной степени маловероятны. Когда мы видим RRRRR, это усиливает теорию (теорию о том, что колесо настроено так, чтобы шарик чаще выпадал на красное), которой мы уже присвоили некую априорную вероятность. Но как насчет RBRRB? Представьте себе человека, придерживающегося на редкость непредвзятого мнения о рулетке, который присваивает некую умеренную вероятность теории о том, что колесо рулетки работает под управлением скрытой машины Руба Голдберга и выдает результат «красное, черное, красное, красное, черное». Почему бы нет? Увидев воочию, как шарик попадает в ячейки в последовательности RBRRB, такой человек найдет в этом веское доказательство в пользу данной теории.
Однако реальные люди совсем не так реагируют на вращение колеса рулетки, которое приводит к результату «красное, черное, красное, красное, черное». Мы не позволяем себе анализировать все абсурдные теории, которые можем построить, рассуждая логически. Наши априорные суждения не однообразные, а разнородные. Некоторым теориям мы присваиваем большой психологический вес, тогда как другие, такие как теория RBRRB, получают вероятность, практически неотличимую от нуля. Как мы выбираем теории, которым отдаем предпочтение? Как правило, простые теории нравятся нам больше, чем сложные; мы предпочитаем теории, основанные на аналогиях с тем, что нам уже известно, теориям, которые касаются совершенно новых явлений. Это может показаться несправедливым предубеждением, но без определенных предубеждений мы могли бы оказаться в состоянии непреходящего изумления. Ричард Фейнман описал подобный образ мыслей так:
Вы знаете, сегодня вечером со мной приключилась удивительная вещь: я шел сюда, на лекцию, и проходил через парковку. И вы не поверите, что произошло. Я увидел машину с номером ARW 357. Вы можете себе представить? Из всех миллионов машинных номеров в стране какова была вероятность того, что я увижу именно этот номер? Поразительно!
Если вы когда-либо употребляли самое популярное из не совсем легальных психотропных веществ, вам известно, что значит иметь слишком однообразные априорные суждения. Каждый стимул, который на вас воздействует, каким бы обыкновенным он ни был, кажется чрезвычайно значимым. Каждое событие захватывает все ваше внимание и требует, чтобы вы отреагировали на него. Это очень интересное психическое состояние, но оно не способствует тому, чтобы вы делали правильные выводы.
Байесовский подход объясняет, почему на самом деле Фейнман не был поражен: потому что он присваивает очень низкую априорную вероятность гипотезе о том, что некая космическая сила сделала так, чтобы он увидел номерной знак ARW 357 в тот вечер. Это объясняет, почему попадание шарика в красную ячейку пять раз подряд кажется нам «менее случайным», чем последовательность RBRRB: потому что первое приводит в действие теорию red, которой мы присвоили довольно большую априорную вероятность, тогда как второе нет. А число с нулем в конце кажется менее случайным, чем число с семеркой в конце, потому что первое подкрепляет теорию о том, что число, которое мы видим, представляет собой не точный итог, а приблизительную оценку.
Эта концептуальная схема помогает также решить некоторые загадки, с которыми мы уже сталкивались. Почему нас удивляет и даже вызывает подозрение, когда в розыгрыше лотереи два раза подряд выпадают номера 4, 21, 23, 34, 39, но этого не происходит, когда в один день выпадают номера 4, 21, 23, 34, 39, а на следующий день 16, 17, 18, 22, 39, хотя оба события в равной степени маловероятны? Безусловно, где-то в подсознании у вас уже сложилась какая-то теория — теория о том, что розыгрыши лотереи по какой-то причине с необычно высокой вероятностью выдают одни и те же номера подряд за короткий промежуток времени. Может быть, это происходит потому, что, по вашему мнению, владельцы лотереи подделывают результаты розыгрышей, либо потому, что некая космическая сила, любящая синхронию, придерживает весы фортуны, — не имеет значения. Возможно, вы верите в эту теорию не слишком сильно, а в глубине души считаете, будто существует один шанс из сотни тысяч, что действительно есть такое смещение в пользу повторяющихся номеров. Но это гораздо больше априорной вероятности, которую вы присваиваете теории о существовании тайного заговора в пользу сочетания 4, 21, 23, 34, 39 и 16, 17, 18, 22, 39. Именно эта теория совсем уж бредовая, но ведь вы не под воздействием наркотиков, поэтому и не обращаете на нее никакого внимания.
Если вдруг вы осознаете, что в какой-то мере верите в эту бредовую теорию, не беспокойтесь: скорее всего, полученные вами эмпирические данные не будут ее подтверждать, снижая вашу веру в этот бред до той степени, с которой в него верят другие, — если только данная бредовая теория не создана именно так, чтобы она могла пройти процесс отсева. Так работают теории заговора.
Предположим, близкий друг сообщает вам, что взрывы во время Бостонского марафона были организованы федеральным правительством, для того чтобы, например, обеспечить поддержку прослушивания телефонных разговоров Агентством национальной безопасности. Назовем это теорией Т. Доверяя своему другу, сначала вы присваиваете этой теории приемлемо высокую вероятность, скажем 0,1. Но затем вы получаете другую информацию: полиция определила местонахождение подозреваемых в совершении этого преступления, выживший подозреваемый признал свою вину и так далее. Каждый из этих фрагментов информации достаточно маловероятен, если исходить из теории Т, и каждый снижает степень вашей уверенности в истинности теории Т до тех пор, пока вы почти перестаете верить в эту теорию. Именно поэтому ваш друг и не предложит вам одну лишь теорию Т; он расскажет вам о теории U, согласно которой правительство и новостные СМИ вместе устроили заговор, в ходе которого газеты и сети кабельного телевидения передают ложную информацию в поддержку истории о том, что теракт был совершен исламскими радикалами. Совокупная теория T + U сначала должна иметь меньшую априорную вероятность: по существу, в нее труднее поверить, чем в теорию Т, поскольку в этом случае от вас требуется поверить одновременно в теорию Т и еще в одну. Но по мере поступления новых данных, которые скорее всего уничтожат только теорию Т, совокупная теория T + U остается нетронутой. Джохар Царнаев осужден? Ну да, именно этого вы и ожидали от федерального суда — Министерство юстиции держит все под контролем! Теория U служит в качестве своего рода байесовского защитного покрытия для теории Т, не позволяя новым данным проникать и растворять эту теорию. Это свойственно многим бредовым теориям: они заключены в достаточно прочную защитную оболочку, которая выражается в том, что эти теории согласуются со многими возможными наблюдениями, в связи с чем их трудно опровергнуть. Такие теории подобны мультирезистентной синегнойной палочке информационной экосистемы. В каком-то смысле они достойны восхищения.
КОТ В ШЛЯПЕ, САМЫЙ ЧИСТЫЙ ЧЕЛОВЕК В УНИВЕРСИТЕТЕ И СОТВОРЕНИЕ ВСЕЛЕННОЙ
Когда я учился в университете, у меня был друг с предпринимательскими наклонностями, у которого возникла идея заработать в начале учебного года немного денег продажей футболок первокурсникам. В то время самые разнообразные футболки можно было купить в мастерской трафаретной печати примерно за четыре доллара, тогда как цена в университетском городке составляла десять долларов. В начале 1990-х было модно ходить на вечеринки в шляпе, напоминающей шляпу из фильма The Cat in the Hat («Кот в шляпе»). Поэтому мой друг собрал восемьсот долларов и заказал две сотни футболок с изображением Кота в шляпе, пьющего пиво. Футболки продавались быстро.
Мой предприимчивый друг был несколько ленив, поэтому так и не стал хорошим предпринимателем. Когда он продал восемьдесят футболок и вернул вложенные деньги, ему надоело целый день сидеть во дворе нашего городка, продавая футболки. В итоге коробка с ними отправилась к нему под кровать.
Неделю спустя наступил день стирки. Как я уже говорил, мой друг был ленив, и стирать ему не хотелось. И тут он вспомнил, что у него есть целая коробка чистых, совершенно новых футболок с изображением Кота в шляпе, потягивающего пиво. Что и решило проблему стирки.
Как оказалось, это решило проблему стирки и на следующий день.
И так дальше.
Но вот в чем ирония. Все вокруг считали моего друга самым нечистоплотным человеком в университете, потому что он каждый день носил одну и ту же футболку. Хотя на самом деле он был самым чистым человеком в университете, поскольку ежедневно надевал совершенно новую, еще не ношенную футболку!
Вот урок по поводу умозаключения: необходимо быть очень осторожными с тем множеством теорий, которое вы рассматриваете. Подобно тому как может быть не одно решение квадратного уравнения, может существовать несколько теорий, связанных с одним и тем же наблюдением, и, если мы не проанализируем все эти теории, наши выводы в состоянии совершенно сбить нас с пути.
Это возвращает нас к вопросу о Творце Вселенной.
Самый знаменитый аргумент в пользу сотворения этого мира Богом — это так называемый аргумент о замысле, который в самой простой его форме сводится к следующему: вы только посмотрите вокруг, неужели вы считаете, что настолько сложный и удивительный мир мог сформироваться всего лишь по воле случая и физических законов?
Более формально этот принцип сформулировал либеральный теолог Уильям Пейли в опубликованной в 1802 году книге Natural Theology; or, Evidences of the Existence and Attributes of the Deity, Collected from the Appearances of Nature («Естественная теология, или Свидетельства существования Бога и Его атрибутов, собранных из явлений природы»):
Пересекая луг, я, предположим, ударился ногой о камень, и, если бы меня спросили, как этот камень оказался там, я, наверное, ответил бы, что, насколько мне известно, он всегда там лежал. И было бы нелегко показать абсурдность такого ответа. Но, предположим, я нашел на земле часы, и, если бы потребовалось узнать, как часы оказались в этом месте, мне вряд ли бы пришло на ум дать такой же ответ, как и в предыдущем случае — мол, насколько мне известно, часы скорее всего всегда были там. Почему же такой ответ не подходит к случаю с часами так же, как к случаю с камнем? Почему он во втором случае не приемлем, как приемлем в первом? По той единственной причине, что когда мы начинаем изучать часы, то видим (чего мы не могли видеть в камне), что составные части часов изготовлены и собраны воедино для определенной цели, то есть они созданы и приспособлены так, чтобы производить движение, а это движение отрегулировано так, чтобы показывать, который сейчас час… Вывод, мы думаем, неизбежно таков, что у часов был создатель: в какое-то время и в каком-то месте должен был существовать мастер или мастера, создавшие их для той цели, которой они соответствуют; мастер или мастера, которые знали устройство часов и продумали, как их использовать (курсив Ричарда Суинберна. — Ред.).
Если это истинно в отношении часов, то насколько более это истинно в отношении воробья, или человеческого глаза, или человеческого мозга?
Книга Пейли имела огромный успех: она была издана пятнадцать раз за пятнадцать лет. Дарвин, который внимательно прочитал ее в колледже, сказал впоследствии: «Думаю, что я никогда не восхищался книгой больше, чем книгой Пейли “Естественная теология”: в прошлом я мог пересказать ее наизусть». А усовершенствованные разновидности аргумента Пейли образуют основу современного движения в поддержку концепции разумного замысла.
Разумеется, это классическое доказательство от маловероятного:
- если Бога нет, существование таких сложных объектов, как человеческие существа, было бы маловероятным;
- люди существуют;
- следовательно, маловероятно, что Бога нет.
Напоминает аргументацию, которую использовали искатели библейских кодов: если Бог не писал Тору, маловероятно, чтобы в тексте на свитке были столь точные записи имен и дат рождения раввинов!
Наверное, вам уже надоело, что я так часто это повторяю, но доказательство от маловероятного работает не всегда. Если мы действительно хотели бы представить в количественном выражении степень своей уверенности в том, что Бог создал Вселенную, нам следовало бы нарисовать другую байесовскую матрицу.
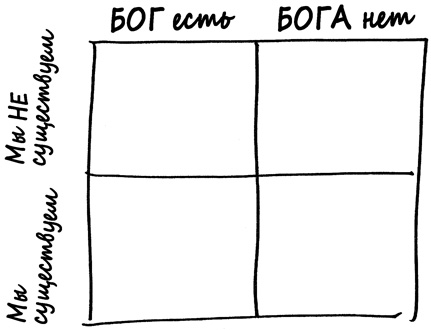
Первая трудность состоит в том, чтобы определить априорные вероятности. Сделать это довольно трудно. В случае рулетки мы задавали такой вопрос: какую вероятность мы присваиваем предположению, что колесо рулетки не работает надлежащим образом, прежде чем увидим его вращение? Теперь мы ставим вопрос так: какую вероятность мы присвоили бы гипотезе о существовании Бога, если не знали бы о существовании Вселенной, Земли и себе подобных?
В этот момент самым естественным шагом было бы развести руками и прибегнуть к принципу с очаровательным названием «принцип безразличия». Поскольку не существует принципиального способа сделать вид, что мы не знаем о собственном существовании, нам остается просто разделить априорную вероятность поровну, присвоив 50% теории, что Бог есть, и 50% — теории, что Бога нет.
Если истинна теория, что Бога нет, тогда столь сложные существа, как люди, должны были возникнуть по чистейшей случайности, чему, возможно, способствовал естественный отбор. Сторонники концепции разумного замысла сходятся во мнении, что подобное крайне маловероятно; давайте выразим все в числах и скажем, что эта вероятность составляет один шанс на миллиард миллиардов. Следовательно, в нижней правой клетке матрицы мы запишем одну миллиардмиллиардную от 50%, или одну двухмиллиардмиллиардную.
Но что если истинна теория, что Бог есть? Существует много вариантов того, в чем может быть выражено существование Бога; мы не знаем заранее, стал бы Бог, сотворивший Вселенную, создавать людей или любых других мыслящих существ, но любой Бог непременно обладал бы способностью сотворить разумную жизнь. Возможно, если Бог есть, существует один шанс на миллион, что Он создал бы таких существ, как мы.
Таким образом, наша матрица выглядит теперь так.
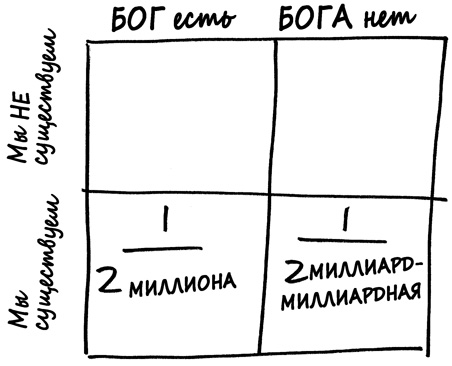
На этом этапе мы можем проанализировать эмпирические данные, а именно что мы существуем. Следовательно, истина находится где-то в нижней строке матрицы. А в нижней строке вы отчетливо видите, что вероятность в клетке «Бог есть» гораздо больше (в триллион раз!) вероятности в клетке «Бога нет».
По существу, это и есть выдвинутый Пейли «аргумент о замысле», как сказал бы современный приверженец байесовской теории. Существует много возражений против этого аргумента о замысле, а также огромное множество агрессивных книг на тему «вы должны стать такими же убежденными атеистами, как я», в которых можно прочитать об этих возражениях, поэтому позвольте мне сосредоточить свое внимание на возражении, которое ближе всего к рассматриваемым математическим концепциям. Речь идет о возражении «самый чистый человек в университете».
Вам наверняка известно, что самым знаменитым изречением Шерлока Холмса после восклицания «Элементарно, Ватсон!» было объяснение логического вывода: «Мой старый принцип состоит в том, чтобы исключить все невозможное. То, что останется, каким бы невероятным это ни выглядело, должно быть истиной».
Разве это не звучит невозмутимо, разумно и неоспоримо?
Но это еще не все. Шерлоку Холмсу следовало бы сказать нечто в таком роде:
Мой старый принцип состоит в том, чтобы исключить все невозможное. То, что останется, каким бы невероятным это ни выглядело, должно быть истиной, если только эта истина не является гипотезой, которую вам не пришло в голову проанализировать.
Менее лаконично, зато более корректно. Люди, которые пришли к выводу о том, что мой друг — самый нечистоплотный человек в университете, рассматривали только две гипотезы:
Чистюля: мой друг меняет футболки, стирает их, а затем снова начинает их менять, как нормальный человек.
Грязнуля: мой друг — нечистоплотный дикарь, который носит грязную одежду.
Вы можете начать с какой-либо априорной вероятности; исходя из своих воспоминаний об учебе в университете, я могу предположить, что было бы правильным присвоить теории Грязнули вероятность 10%. Но на самом деле не имеет значения, какую априорную вероятность вы выберете: теорию Чистюли опровергает наблюдение, что мой друг носит одну и ту же футболку каждый день. «Если исключить невозможное…»
Но подождите-ка, мистер Холмс: истинное объяснение, Ленивый предприниматель — это гипотеза, не вошедшая в список.
Аргумент о замысле сопряжен с такой же проблемой. Если вы допускаете только две гипотезы: БОГА НЕТ и БОГ ЕСТЬ, — богатую структуру живого мира вполне можно использовать в качестве доказательства в пользу истинности второй, а не первой гипотезы.
Однако есть и другие возможности. Как насчет гипотезы БОГИ ЕСТЬ, согласно которой мир в спешке был создан группой богов, пререкающихся друг с другом? В это верили многие великие цивилизации. Кроме того, вы ведь не можете отрицать, что существуют такие аспекты мира природы (здесь мне в голову приходит бамбуковый медведь), которые кажутся скорее результатом неохотного бюрократического компромисса, а не творением разума всеведущего божества, осуществляющего полный контроль над процессом творения. Если мы начнем с присвоения одной и той же априорной вероятности гипотезам БОГ ЕСТЬ и БОГИ ЕСТЬ — а почему бы и нет, если мы следуем принципу безразличия? — тогда байесовский вывод должен привести нас к гораздо большей уверенности в истинности не теории БОГ ЕСТЬ, а теории БОГИ ЕСТЬ.
Но зачем останавливаться на этом? Историям о происхождении Вселенной нет конца. Еще одна теория, которой придерживаются некоторые приверженцы имитационного моделирования, гласит, что на самом деле мы вообще не люди, а модели, существующие на суперкомпьютере, созданном другими людьми. Это звучит нелепо, но многие люди весьма серьезно относятся к этой идее (самый известный из них профессор философии Оксфордского университета Ник Бостром), а с точки зрения байесовской теории трудно объяснить, почему должно быть иначе. Людям нравится строить модели, имитирующие события реального мира; безусловно, если человечество не прекратит свое существование, наша способность создавать такие модели будет только усиливаться. В связи с этим вполне можно представить, что в свое время одним из элементов данных моделей станут обладающие сознанием существа, которые считают себя людьми.
Если истинна гипотеза имитации и Вселенная представляет собой модель, сконструированную людьми в более реальном мире, тогда вполне вероятно, что в этой Вселенной будут люди, поскольку люди любят имитировать людей! Я назвал бы это почти полной уверенностью (для целей нашего примера давайте говорить об абсолютной уверенности) в том, что в имитационном мире, созданном технологически развитым человечеством, будут (смоделированные) люди.
Если мы присвоим каждой из четырех гипотез, о которых шла речь выше, априорную вероятность 1/4, матрица будет выглядеть так.
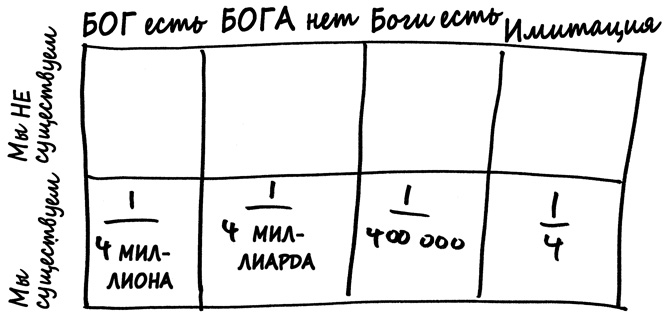
Учитывая тот факт, что мы все-таки существуем, истина находится где-то в нижней строке матрицы, но наибольшая вероятность — в клетке имитация. Да, существование человеческой жизни — это доказательство существования Бога, однако гораздо лучшее доказательство состоит в том, что наш мир был запрограммирован людьми, которые намного умнее нас.
Сторонники так называемого научного креационизма утверждают, что во время школьных занятий мы должны рассказывать о существовании создателя этого мира, но не потому, что так гласит Библия (это было бы просто непозволительно!), а по веским причинам, основанным на поразительной маловероятности существования человечества при условии истинности гипотезы, что Бога нет.
Но, если бы мы всерьез отнеслись к такому подходу, мы рассказывали бы десятиклассникам нечто в таком роде:
Некоторые утверждают, будто в высшей степени маловероятно, чтобы нечто столь сложное, как биосфера Земли, возникло сугубо в процессе естественного отбора без какого бы то ни было вмешательства извне. Вне всяких сомнений, самым вероятным объяснением является то, что на самом деле мы не физические существа, а обитатели компьютерной модели, выполненной людьми с намного более развитой технологией. Правда, с какой целью — мы точно не знаем. Возможно также, что мы созданы сообществом богов, похожих на тех богов, которым поклонялись древние греки. Еще больше людей верят в то, что один Бог создал Вселенную, но эту гипотезу следует считать менее обоснованной, чем другие гипотезы.
Думаете, школьному совету это понравилось бы?
Тогда мне лучше поспешить и обратить ваше внимание на следующее: на самом деле гипотеза, что все мы компьютерные модели, нравится мне не больше, чем аргумент Пейли о существовании Бога. Напротив, у меня возникло неприятное ощущение, будто эти аргументы свидетельствуют, что мы достигли предела количественного мышления. Мы привыкли выражать свою неуверенность в отношении чего-то в виде числа. Порой в этом даже есть свой смысл. Когда метеоролог говорит в вечерних новостях: «Завтра будет дождь с вероятностью 20%», — это означает, что из всего множества прошедших дней с условиями, напоминающими текущие условия, в 20% случаев на следующий день были дожди. Но что мы можем иметь в виду под фразой: «Вселенную создал Бог с вероятностью 20%»? Это не может означать, что Бог создал одну вселенную из пяти, а остальные возникли сами по себе. Дело в том, что я так и не нашел метод, который показался бы мне вполне подходящим для присвоения числовых значений нашей неопределенности в отношении важнейших вопросов такого рода. Как бы я ни любил числа, я считаю, что люди должны придерживаться какого-то из принципов: «Я не верю в Бога», «Я верю в Бога» или просто: «Я не уверен». Как бы я ни любил байесовский вывод, я считаю, что людям лучше обретать веру (или отбрасывать ее), не прибегая к числам. В этом деле математика хранит молчание.
Если не верите мне, поверьте Блезу Паскалю, математику и философу, написавшему в XVII столетии:
Бог или есть, или Его нет; но на какую сторону мы склонимся? Разум тут ничего определить не может.
Но это еще не все. Паскаль много что успел сказать в своих «Мыслях» (Pensées). В следующей главе мы обратимся и к его труду и его размышлениям по этому вопросу. Но сначала поговорим о лотерее.

