ГЛАВА XIX: Искусственный Интеллект: виды на будущее
Ситуации «почти» и ситуации гипотетические
ПРОЧИТАВ «КОНТРАФАКТУС», один из моих друзей сказал мне: «Мой дядя был почти президентом США!» «Правда?» — спросил я. «Конечно», — ответил он, — «он был капитаном торпедного катера ПТ108». (Джон Ф. Кеннеди был капитаном ПТ109.)
Именно об этом идет речь в «Контрафактусе». У нас в голове каждый день рождаются мысленные варианты ситуаций, с которыми нам приходится сталкиваться, идей, которые у нас возникают или событий, происходящих вокруг. При этом некоторые детали остаются без изменений, в то время как другие «сдвигаются». Какие детали мы сдвигаем? Какие нам даже в голову не приходит изменить? Какие события воспринимаются нами на некоем глубинном интуитивном уровне как близкие родственники событий, случившихся на самом деле? Что мы считаем «почти» случившимся, чем-то, что «могло» случиться, хотя совершенно точно знаем, что в действительности этого не произошло? Какие альтернативные версии событий сами собой возникают у нас в мозгу, когда мы слышим какой-нибудь рассказ? Почему одни контрафактические ситуации кажутся нам менее «контрафактическими», чем другие? В конце концов, совершенно ясно, что чего не было, того не было. У «неслучаемости» нет никаких степеней. То же самое верно и в отношении «почти» случившихся ситуаций. Мы часто жалуемся, что какое-то событие «чуть не случилось»; не менее часто мы произносим те же слова с облегчением. Но это «чуть не» находится в нашем мозгу, а не во внешних фактах.
Вы едете на машине по проселочной дороге и внезапно перед вами появляется рой пчел. Вместо того, чтобы беспристрастно отметить происходящее, ваш мозг тут же создает целый рой «повторов». Как правило, вы думаете что-то вроде: «Хорошо, что окошко было закрыто!» — или же: «Ах, черт, если бы только окошко было закрыто…» «Хорошо, что я не на велосипеде!» «Лучше бы я проехал здесь на пять секунд раньше.» Странными, но возможными повторами были бы: «Если бы это был олень, я мог бы быть сейчас мертв!» или «Могу поспорить, что эти пчелы предпочли бы столкнуться с розовым кустом!» А вот повторы еще страннее: «Жаль, что это были пчелы, а не долларовые купюры!» «Хорошо, что пчелы не цементные!» «Лучше бы это была всего одна пчела, вместо целого роя.» «Не хотел бы я оказаться на месте этих пчел!» Какие сдвиги кажутся нам естественными, а какие нет — и почему?
В недавнем номере журнала «Нью-Йоркер» был перепечатан следующий отрывок из «Филадельфия Уэлкомат»:
Если бы Леонардо да Винчи родился женщиной, потолок Сикстинской капеллы мог бы никогда не быть расписан. А если бы Микеланджело был сиамскими близнецами, то работа могла бы оказаться законченной вдвое быстрее.
Смысл этого замечания не в том, что подобные гипотетические ситуации ложны, а в том, что люди, которым может придти в голову «сдвинуть» пол или число данного человека, должны быть не совсем нормальными. Интересно то, что в том же номере, ничтоже сумняшеся, напечатали следующую фразу, завершающую обзор книги:
Я думаю, что ему (профессору Филиппу Франку) очень понравились бы обе эти книги.
Однако бедный профессор Франк уже умер; ясно, что бессмысленно предполагать, что кто-то может прочитать книги, изданные после его смерти. Почему же эта фраза воспринимается нами всерьез? Дело в том, что в каком-то трудноуловимом смысле сдвиг параметров в этом случае не нарушает нашего чувства «возможного» так сильно, как в предыдущих примерах. Что-то здесь позволяет нам вообразить легче, чем в других случаях, что «при прочих равных» меняется именно этот параметр. Но почему? Каким образом наша классификация событий и людей позволяет нам на каком-то глубоком уровне определять, что может быть сдвинуто без проблем и что не подлежит сдвигу?
Посмотрите, насколько естественным кажется нам переход от скучного утверждения «Я не знаю английского» к более интересному сослагательному наклонению «Я бы хотел знать английский» и, наконец, к богатому смыслом гипотетическому «Если бы я знал английский, я бы читал Диккенса и Шекспира в оригинале». Насколько плоским и мертвым был бы разум, для которого отрицание являлось бы непроницаемым барьером! Живой разум всегда способен увидеть окно в мир возможностей.
Мне кажется, что гипотетические «почти» ситуации и бессознательно вырабатываемые возможные миры представляют из себя один из богатейших источников информации о том, каким образом люди организуют и классифицируют свои впечатления о мире. Красноречивый сторонник подобного взгляда, лингвист и переводчик Джон Штейнер написал в своей книге «После Вавилонского столпотворения»:
Гипотетические ситуации, воображаемые условия, синтаксис контрафактического и случайного вполне могут быть порождающим центром человеческого языка… (Они) не просто придают речи философскую и грамматическую сложность. Не менее, чем будущие времена, с которыми, как мы чувствуем, они тесно связаны и вместе с которыми, возможно, должны быть отнесены к более широкой категории предположительных или альтернативных событий, «если бы» предложения лежат в основе динамики человеческих чувств…Мы отличаемся умением и необходимостью отрицать и переигрывать реальные ситуации, воображать и выражать мир иначе.... Нам нужно какое-то слово, которое обозначало бы эту возможность языка, это стремление к выражению «иначести». … Может быть, слово «альтерность» подошло бы для определения ситуаций, отличных от данной, — контрафактических высказываний и миров, куда нас уводит наше воображение, образов, которыми мы населяем свою голову и с помощью которых создаем изменчивую и часто фиктивную среду своего физического и общественного существования.
В завершение, Штейнер поет контрафактический гимн контрафактичности:
Маловероятно, что человек, существовал бы таким, каким мы его знаем, если бы в языке не было фиктивных, контрафактических, анти-детерминистских оборотов, если бы он не обладал семантической способностью, рожденной и сохраняющейся в «лишних» областях коры мозга, — способностью представлять и выражать возможности, лежащие за пределами органического разложения и смерти.
Создание «гипотетических миров» происходит настолько случайно и естественно, что мы почти не отдаем себе отчета в том, что делаем. Мы выбираем из всех воображаемых миров тот, который в каком-то внутреннем, интеллектуальном смысле ближе всего к реальности. Мы сравниваем реальность с тем, что воспринимаем как почти реальное. Благодаря этому мы получаем некое неуловимое чувство перспективы по отношению к действительности. Наш Ленивец — это странный вариант действительности: мыслящее существо, неспособное к созданию гипотетических миров (по крайней мере, он утверждает, что такой способности у него нет — но вы, вероятно, заметили, что на самом деле его речь полна контрафактов!) Подумайте, насколько беднее была бы наша интеллектуальная жизнь, если бы мы не обладали творческой способностью выбираться из реального мира в эти соблазнительные «а что, если бы…». С точки зрения изучения человеческого мышления эти экскурсы очень интересны, поскольку в большинстве случаев они происходят бессознательно. Это означает, что знание о том, что попадает в область гипотетических миров, а что нет, открывает для нас окно в подсознание.
Один из способов увидеть природу нашей мысленной метрики в перспективе состоит в том, чтобы «вышибить клин клином». Это сделано в Диалоге, где нашей «гипотетической способности» пришлось вообразить такой мир, в котором само понятие гипотетической способности действует в воображаемом мире. Первый гипотетический повтор Диалога, в котором мяч не оказывается вне игры, вообразить совсем нетрудно. На самом деле, он пришел мне в голову благодаря вполне обычному замечанию человека, сидевшего рядом со мной на футбольном матче. Это замечание меня удивило и заставило задуматься о том, почему кажется естественным вообразить именно такой гипотетический мир, а не тот, в котором изменен счет или количество штрафных. Затем я стал перебирать другие, еще менее вероятные изменения, такие, как погода (это есть в Диалоге), вид игры (тоже в Диалоге) и другие, еще более сумасбродные варианты (и это в Диалоге). Однако я заметил, что то, что смешно варьировать в одной ситуации, может оказаться легко вообразимым в другой. Например, иногда вы можете вполне естественно задуматься о том, как пошла бы игра, если мяч был другой формы (например, когда вам приходится играть в баскетбол слабо накачанным мячом); однако когда вы смотрите баскетбол по телевизору, такое просто не приходит вам в голову.
Уровни стабильности
Тогда мне показалось (и кажется до сих пор), что возможность изменения какой-либо черты события (или обстоятельства) зависит от множества вложенных один в другой контекстов, в которых это событие (или обстоятельство) нами воспринимается. Сюда хорошо подходят математические термины постоянная, параметр и переменная. Часто математики, физики и другие ученые, производя вычисления, говорят:«с — постоянная, p — параметр и v — переменная.» Они имеют в виду, что каждая из этих величин, включая постоянную, может варьироваться, но при этом существует некая иерархия изменяемости. В ситуации, представляемой символами, с устанавливает некое основное условие; p — менее основное условие, которое может варьироваться, пока с остается неизменным; и, наконец, v может меняться сколько угодно при неизменных с и p. Нет смысла представлять, что v остается фиксированным, а изменяются с и p, поскольку с и p устанавливают тот контекст, в котором v приобретает значение. Представьте себе, к примеру, зубного врача, у которого есть список его пациентов и для каждого пациента — описание его зубов. Вполне разумно (и весьма выгодно) иметь постоянного пациента и менять состояние его зубов. С другой стороны, совершенно бессмысленно пытаться оставлять неизменным какой-то определенный зуб и менять пациентов. (Разумеется, иногда наилучшим решением бывает сменить зубного врача…)
Мы строим наше мысленное представление о ситуации постепенно, слой за слоем. Низший уровень устанавливает самый глубокий аспект контекста, иногда настолько глубокий, что он вообще не может варьироваться. Например, трехмерность мира настолько вошла в наше сознание, что большинству из нас не приходит в голову воображать какие-либо вариации на эту тему. Это, так сказать, постоянная постоянная. Затем идут слои, временно устанавливающие некие зафиксированные аспекты ситуаций; их можно назвать глубинными допущениями. Это те вещи, которые мы обычно считаем за неизменные, хотя и знаем, что в принципе они могли бы измениться. Этот слой все еще можно назвать «постоянным». Например, когда мы смотрим футбол, такими постоянными являются правила игры. Далее следуют «параметры» — они могут варьироваться с большей легкостью, но мы временно принимаем их за неизменные. В нашем футбольном примере параметрами могут являться погода, команда противников и так далее. Скорее всего, существуют несколько слоев параметров. Наконец, мы достигаем самого неустойчивого аспекта ситуации — переменных. Это такие вещи, как положение «вне игры», неудачный удар по воротам и тому подобное; здесь нам легко на мгновение представить себе альтернативное положение дел.
Фреймы и вложенные контексты
Термин фрейм (кадр, группа данных) сейчас в моде среди специалистов по искусственному интеллекту; его можно определить, как численное представление данного контекста. Этот термин, как и многие идеи о фреймах, обязан своим происхождением Марвину Минскому, хотя само это понятие витало в воздухе уже несколько лет. Можно сказать, что мысленные представления о ситуациях включают фреймы, вложенные один в другой. Каждый из аспектов ситуации обладает собственным фреймом. Такие вложенные фреймы напоминают мне множество комодов. Выбирая фрейм, вы выбираете определенный комод. В него может быть вставлено несколько ящиков — «подфреймов». При этом каждый из этих ящиков, в свою очередь, является комодом. Как можно вставить целый комод в отверстие для одного-единственного ящика? Проще простого — надо уменьшить и деформировать второй комод. В конце концов, он ведь не физический предмет, а воображаемый! Во внешнем комоде может быть несколько разных гнезд, куда должны быть вставлены ящики; затем мы начинаем вставлять ящики в гнезда внутренних комодов (или подфреймов). Этот процесс может продолжаться рекурсивно.
Живая сюрреалистическая картина того, как комод сплющивают и сгибают, чтобы запихать его в гнездо любой величины, очень важна, так как она намекает на то, что наши понятия сплющиваются и сгибаются в зависимости от контекстов, в которые мы их запихиваем. Что происходит с вашим представлением о «человеке», когда вы думаете о футболистах? Безусловно, это искаженное представление, навязанное вам общим контекстом. Вы засунули фрейм «человек» в гнездо фрейма «футбольный матч». Теория представления знаний в форме фреймов опирается на идею, что мир состоит из почти закрытых подсистем, каждая из которых может служить контекстом для других, при этом они не слишком прерываются и почти не причиняют перебоев в процессе.
Одна из основных идей, касающихся фреймов, состоит в том, что каждый фрейм ожидает некоего определенного содержания. Этому образу соответствуют комоды, в каждом гнезде которых есть по встроенному, но непрочно закрепленному ящику под названием значение по умолчанию. Если я попрошу вас представить себе берег реки, у вас в голове появится некая картина; однако большинство ее черт могут быть изменены, если я добавлю какие-либо детали: «во время засухи», или «в Бразилии», или «без пляжа». Благодаря значениям по умолчанию рекурсивный процесс заполнения гнезд может быть завершен. В самом деле, вы можете сказать: «Я заполню гнезда на трех уровнях, а дальше буду пользоваться значениями по умолчанию.» Взятый вместе с этими значениями фрейм содержит информацию о собственных границах и эвристику для переключения на другие фреймы в том случае, если эти границы нарушаются.
Многоуровневая структура фрейма дает возможность увидеть его крупным планом и рассмотреть все его детали с какого угодно приближения. Для этого надо только сосредоточить внимание на соответствующем фрейме, затем на одном из его подфреймов и так далее, пока вы не получите всех требуемых деталей. Это похоже на дорожный атлас России, в котором кроме карты страны на первой странице есть карты областей, областных центров и даже некоторых небольших городов, если вам понадобится больше сведений. Можно вообразить себе атлас с каким угодно количеством деталей, включая кварталы, дома, комнаты и так далее — словно вы смотрите в телескоп с линзами разной мощи, каждая из которых имеет свое предназначение. Важно то, что можно свободно выбирать между различными масштабами; детали часто бывают неважны и только мешают.
Поскольку сколь угодно разные фреймы можно засунуть в гнезда других фреймов, возможны конфликты и «столкновения». Схема аккуратно организованного всеобщего множества слоев «постоянных», «параметров» и «переменных» — всего лишь упрощение. На самом деле, у каждого фрейма есть собственная иерархия изменяемости. Именно поэтому анализ нашего восприятия такой сложной игры как футбол, со множеством подфреймов, подподфреймов и так далее, представляется весьма запутанной операцией. Каким образом все эти фреймы взаимодействуют между собой? Как разрешаются конфликты, когда один фрейм утверждает: «Это постоянная», а другой в то же время говорит: «Это переменная»? Я не могу дать ответа на эти глубокие и сложные вопросы теории фреймов. Пока еще не достигнуто соглашение по поводу того, что в действительности представляют из себя фреймы и как можно использовать их в программах ИИ. Некоторые из моих предположений на этот счет вы найдете в следующем разделе, в котором говорится о некоторых задачах в области узнавания зрительных структур — я называю их «задачами Бонгарда».
Задачи Бонгарда
Задачи Бонгарда (ЗБ) — это проблемы, подобные тем, которые предложил в своей книге «Проблема узнавания» русский ученый Михаил Моисеевич Бонгард. На рис. 119 показана типичная ЗБ — #51 из ста задач, приведенных в книге.
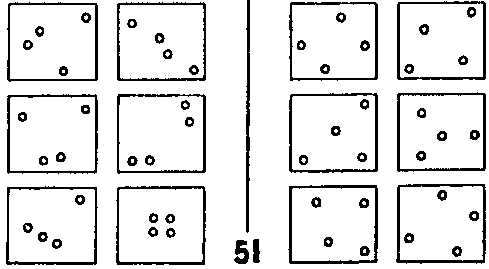
Рис. 119. Задача Бонгарда #51. (Из книги М. Бонгарда «Проблема узнавания».)
Эти интереснейшие задачи могут быть предложены людям, компьютерам или даже представителям внеземных цивилизаций. Каждая задача состоит из двенадцати фигур, взятых в рамку (они так и называются рамками): шесть левых рамок составляют класс I, шесть правых — класс II. Рамки можно пронумеровать следующим образом:
I-А I-Б II-А II-Б
I-В I-Г II-В II-Г
I-Д I-Е II-Д II-Е
Задача состоит в том, чтобы обнаружить, чем рамки класса I отличаются от рамок класса II.
В программе для решения задач Бонгарда было бы несколько ступеней, на которых первичные данные постепенно превращались бы в описания. Ранние ступени относительно негибки; гибкость последующих ступеней увеличивается. Последние ступени обладают свойством, которое я называю «экспериментальностью». Это означает, что на этой стадии представление о картине всегда пробное. Описание высшего уровня может быть переделано в любой момент при помощи приемов, используемых на последних ступенях. Идеи, представленные ниже, также экспериментальны. Сначала я попытаюсь дать общие идеи, не останавливаясь на трудностях; затем постараюсь объяснить все тонкости, трюки и так далее. Таким образом, ваше понимание того, как это все работает, может изменяться по мере того, как вы читаете дальше. Это будет как раз в духе нашей дискуссии!
Предварительная обработка выбирает мини-словарь
Представьте себе, что дана некая задача Бонгарда. Прежде всего, телекамера считывает первичные данные. Затем эти данные проходят предварительную обработку. Это значит, что в них выделяются наиболее важные черты. Названия этих черт составляют «мини-словарь» задачи; они выбираются из общего «словаря выдающихся черт». Вот некоторые типичные термины из этого словаря:
отрезок, поворот, горизонтальный, вертикальный, черный, белый, маленький, большой, остроконечный, круглый…
На второй стадии предварительной обработки используются некоторые знания об элементарных фигурах; если таковые обнаруживаются, их названия также включаются в мини-словарь. Здесь могут быть выбраны такие термины:
треугольник, круг, квадрат, углубление, выступ, прямой угол, вершина, точка пересечения, стрелка…
Приблизительно в этот момент в человеческом интеллекте встречаются сознательное и бессознательное. Что же происходит потом?
Описания высшего уровня
После того, как ситуация до некоторой степени «понята» в знакомых нам терминах, программа «оглядывается кругом» и предлагает пробное описание одной или нескольких рамок. Эти описания весьма просты. Например:
наверху, внизу, справа от, слева от, внутри, снаружи, близко от, далеко от, параллельно, перендикулярно, в ряд, рассеяны, на равном расстоянии друг от друга, на неравном расстоянии друг от друга и т. д.
Могут использоваться также определенные и неопределенные числовые описания:
1,2,3,4,5, … много, несколько и т. д
Могут быть построены и более сложные описания, такие как:
правее, менее близко к, почти параллельно и т. д.
Таким образом, типичная рамка — скажем, 1-Е из ЗБ #47 (рис. 120) — может быть описана различными способами. Можно сказать, что в ней имеются:
три фигуры
или
три белых фигуры
или
один круг направо
или
два треугольника и круг
или
два повернутых кверху треугольника
или
одна большая фигура и две маленьких фигуры
или
одна изогнутая фигура и две прямолинейных фигуры
или
круг с одной и той же фигурой внутри и снаружи него.

Рис. 120. Задача Бонгарда # 47. (Из книги Бонгарда «Проблема узнавания»)
Каждое из этих описаний рассматривает рамку сквозь некий «фильтр». Вне контекста, каждое из описаний может быть полезно. Однако оказывается, что в контексте данной задачи все они «ошибочны». Иными словами, зная различие между классами I и II, вы не смогли бы, исходя только из этих описаний, сказать, к какому классу принадлежит данная рамка. В данном контексте основной чертой описываемой рамки является то, что она включает:
круг с треугольником внутри.
Обратите внимание, что человек, услышавший это описание, не сможет восстановить оригинальную картинку, однако сумеет узнать картинки, отличающиеся данной чертой.
Это напоминает музыкальный стиль: вы можете безошибочно распознавать произведения, написанные Моцартом, и в то же время быть неспособным написать ничего похожего на его музыку.
Взгляните теперь на рамку I-Г задачи #91 (Рис. 121). Перегруженным, но «верным» описанием в контексте ЗБ #91 будет:
круг с тремя прямоугольными выемками.
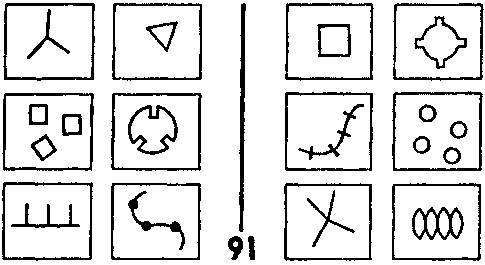
Рис. 121. Задача Бонгарда # 91. (Из книги Бонгарда «Проблема узнавания».)
Обратите внимание, насколько сложно это описание: слово «с» действует в нем как отрицание, давая понять, что «круг», на самом деле, не является кругом — это почти круг, но… Более того, выемки не являются полными прямоугольниками. В нашем использовании языка для описания предметов есть немало тонкостей. Ясно, что большое количество информации здесь опущено и можно было бы опустить еще больше. A priori очень трудно понять, какую информацию лучше отбросить, а какую необходимо сохранить. Поэтому нам нужно, путем эвристики, закодировать некий метод для разумного компромисса. Разумеется, если нам необходимо восстановить отброшенную информацию, мы всегда можем спуститься на низшие уровни описания (к менее блочной картине), так же как люди могут все время обращаться к данной задаче Бонгарда с тем, чтобы проверить правильность их догадок. Таким образом, метод состоит в создании правил, объясняющих, как
создавать пробные описания для каждой рамки;
сравнивать их с пробными описаниями других рамок каждого класса
переделывать описания
(1) добавляя информацию;
(2) отбрасывая информацию;
(3) рассматривая ту же информацию под другим углом.
Этот процесс повторяется до тех пор, пока мы не найдем различия между двумя классами.
Эталоны и детектор сходства
Хорошей стратегией было бы построение описаний, как можно более структурно схожих между собой, поскольку любая схожая структура облегчает процесс сравнения. К этой стратегии относятся два важных элемента теории. Один из них — идея «описания-схемы» или эталона; другой — идея детектора сходства.
Сначала рассмотрим детектор сходства. Это особый активный элемент, присутствующий на всех уровнях программы (На разных уровнях могут быть детекторы различных типов.) Он беспрерывно работает, проверяя индивидуальные описания и сравнивая их между собой в поисках черт, повторяющихся от одного описания к другому. Обнаружение сходства приводит в действие операции, изменяющие одно или несколько описаний.
Теперь перейдем к эталонам. После окончания обработки данных мы сразу пытаемся создать эталон или схему описаний — один и тот же формат для описаний всех рамок данной задачи. Идея здесь состоит в том, что каждое описание может быть разбито на несколько подописаний, а те, если это необходимо, в свою очередь могут быть разбиты на подподописания. Вы достигаете дна, спускаясь к примитивным понятиям на уровне препроцессора. Важно найти такой способ разбивания на подпрограммы, который отразил бы общность между всеми рамками; иначе «псевдо-порядок», который вы введете в мир, окажется бессмысленным и ненужным.
На основе какой информации строятся эталоны? Рассмотрим это на примере. Возьмем ЗБ #49 (рис. 122). Предварительная обработка информации сообщает нам, что каждая рамка состоит их нескольких маленьких «о» и большой замкнутой кривой. Эти ценные сведения стоит включить в эталон. Таким образом, наша первая попытка создания эталона выглядит так:
большая замкнутая кривая: —
маленькие «о»: —
Это очень просто: в описании-эталоне есть два гнезда, куда надо будет вставить подописания.

Рис. 122. Задача Бонгарда #49. (Из книги Бонгарда «Проблема узнавания»).
Гетерархическая программа
Теперь происходит интересная вещь, вызванная к жизни словами «замкнутая кривая». Один из важнейших узлов в программе — это нечто вроде семантической сети или сети понятий, в которой все известные программе существительные, прилагательные и так далее связаны и соотнесены между собой. Например, «замкнутая кривая» тесно связана с понятиями «внутри» и «снаружи». Сеть понятий битком набита информацией о связях между терминами: она говорит нам, что противоположно чему, что сходно с чем, какие вещи часто встречаются вместе и так далее. Небольшой кусочек концептуальной сети показан на рис. 123; я объясню его позже. Пока давайте вернемся к задаче #49. Понятия «внутри» и «снаружи» активируются благодаря тому, что в сети понятий они находятся вблизи от «замкнутой кривой». Это влияет на постройку эталона, в который вводятся гнезда для внутренней и внешней сторон кривой. Таким образом, вторым приближением эталона является:
большая замкнутая кривая: —
маленькие «о» внутри: —
маленькие «о» снаружи: —
В поисках дальнейших подразделений, термины «внутри» и «снаружи» заставят процедуры программы рассмотреть эти районы рамки. В районе рамки I-A ЗБ #49 обнаруживается следующее:
большая замкнутая кривая: круг
маленькие «о» внутри: три
маленькие «о» снаружи: три
Описанием рамки II-А той же задачи может быть:
большая замкнутая кривая: сигара
маленькие «о» внутри: три
маленькие «о» снаружи: три
В этот момент детектор сходства, работающий параллельно с другими операциями, обнаруживает повторение понятия «три» во всех гнездах, описывающих «о»; этого оказывается достаточно, чтобы снова модифицировать эталон. Обратите внимание, что первая модификация была предложена сетью понятий, а вторая — детектором сходства. Теперь наш эталон для задачи #49 приобретает такой вид:
большая замкнутая кривая: —
три маленьких «о» внутри: —
три маленьких «о» снаружи: —
Теперь, когда «три» поднялось уровнем выше и вошло в эталон, имеет смысл обратиться к его соседям по сети понятий. Один их них — «треугольник», что означает, что треугольники, состоящие из «о», могут оказаться важными для решения задачи. В результате оказывается, что эта дорога заводит в тупик, — но как мы могли знать об этом заранее? Человек, решающий эту задачу, скорее всего пошел бы тем же путем, так что хорошо, что наша программа нашла эту дорогу.
Описание рамки II-Д может быть таким:
большая замкнутая кривая: круг
три маленьких «о» внутри: равносторонний треугольник
три маленьких «о» снаружи: равносторонний треугольник
Разумеется, при этом было отброшено огромное количество информации о размерах, положении и ориентации этих треугольников и т. п. Но именно в этом и заключается смысл создания описаний вместо использования необработанных данных! Это похоже на «воронку», которую мы обсуждали в главе XI.
Сеть понятий
Нам не понадобится рассматривать решение задачи #49 целиком, поскольку мы уже показали, каким образом индивидуальные описания, эталоны, детектор сходства и сеть понятий непрерывно взаимодействуют между собой. Рассмотрим более подробно, что представляет из себя сеть понятий и каковы ее функции. Упрощенный ее фрагмент, приведенный на рис. 123, кодирует следующие идеи:
«высоко» и «низко» противоположны.
«сверху» и «снизу» противоположны.
«высоко» и «сверху» схожи.
«низко» и «снизу» схожи.
«справа» и «слева» противоположны.
различие между «справа-слева» подобно различию между «высоко-низко».
«противоположно» и «схоже» противоположны.
Обратите внимание, что мы можем говорить как об узлах, так и о связях сети. В этом смысле ни один объект в сети не находится уровнем выше другого. В другой части данной схемы закодированы следующие понятия:
Квадрат — это многоугольник.
Треугольник — это многоугольник.
Многоугольник — это замкнутая кривая.
Разница между треугольником и квадратом в том, что у первого 3 стороны, а у второго — 4.
4 схоже с 3.
Круг — это замкнутая кривая.
У замкнутой кривой есть внутренний и внешний районы. «Внутри» и «снаружи» противоположны.
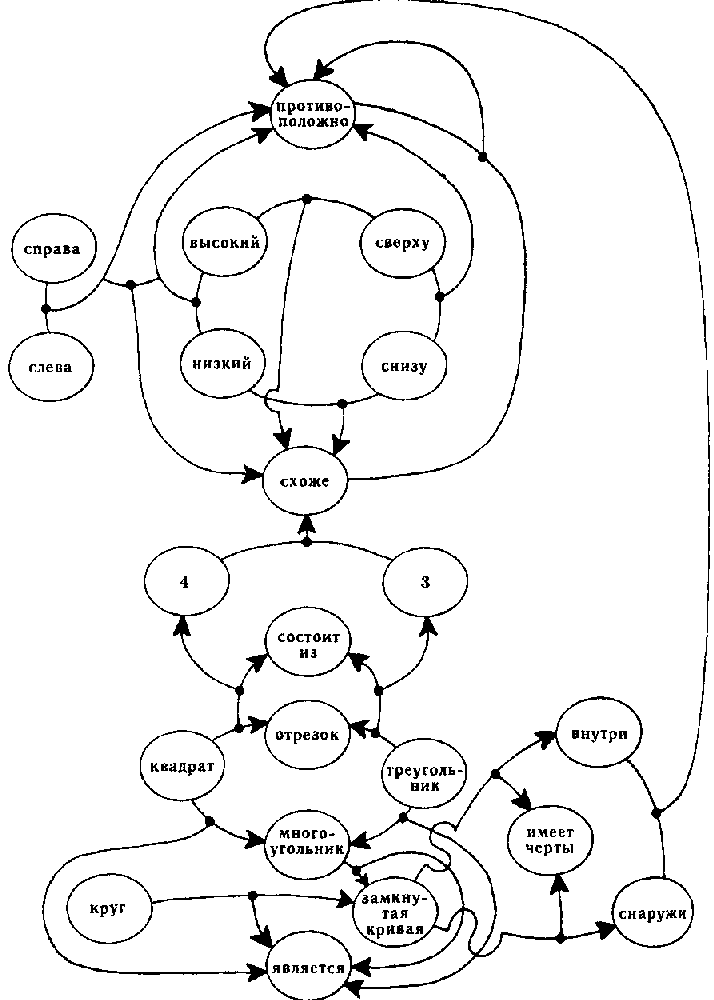
Рис. 123. Небольшая часть сети понятий программы для решения задач Бонгарда. «Узлы» соединены между собой «связями», которые, в свою очередь, могут быть связаны. Принимая связи за глаголы, а соединенные ими узлы за подлежащие и дополнения, можно построить на основе этой диаграммы разные русские предложения.
Сеть понятий очень широка. Кажется, что знания закодированы в ней только статистически, или декларативно, — но это верно лишь наполовину. На самом деле, ее знания граничат с процедурными, потому что сходство в сети действует как гид, или «подпрограммы», сообщая основной программе, как лучше понимать картинки в рамках.
Например, какая-нибудь из первых догадок может оказаться ошибочной, но при этом содержать зерно правильного ответа При первом взгляде на ЗБ #33 (рис. 124) можно подумать, что класс I содержит «колючие» фигуры, а класс II — «гладкие». Однако, если присмотреться, эта догадка оказывается неверной. Все же в ней есть ценная информация, и можно попытаться развить эту идею дальше, работая с теми понятиями сети, которые связаны с «колючим». Это понятие схоже с «острым», которое и оказывается отличительной чертой класса I. Таким образом, одна из основных функций сети понятий состоит в том, чтобы позволять модификацию ранних ошибочных идей и переход к вариациям, которые могут оказаться правильными.
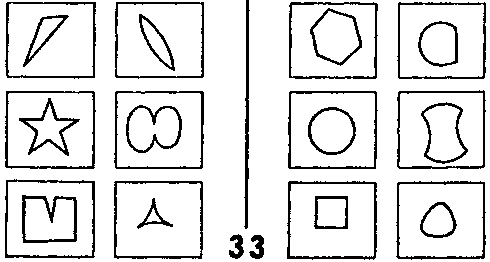
Рис. 124 Задачи Бонгарда.
Переход и пробность
Понятие перехода между похожими предметами родственно понятию восприятия одного предмета как вариации другого. Мы уже видели прекрасный пример этого — «круг с тремя выемками», который на самом деле вовсе не круг! Наши понятия должны быть до определенной степени гибкими. Ничто не должно оставаться совершенно неизменным. С другой стороны, они также не должны быть настолько бесформенными, что в них пропадет всякое значение. Все дело в том, чтобы знать, когда одно понятие может перейти в другое.
Такой переход лежит в основе решений задач Бонгарда ##85 — 87 (рис. 125). ЗБ #85 довольно проста. Предположим, что наша программа в процессе предварительной обработки данных узнает некий «отрезок». После этого ей легко посчитать отрезки и найти различие между классом I и классом II в ЗБ #85.
Теперь программа переходит к задаче #86. Ее основная методика состоит в том, чтобы опробовать все недавние идеи, оказавшиеся удачными. В реальном мире повторение сработавших ранее приемов часто увенчивается успехом, и Бонгард в своих задачах не стремится перехитрить этот тип эвристики—к счастью, он даже поощряет его. Таким образом, мы переходим к ЗБ #86, имея на вооружении две идеи («считать» и «отрезок»), слитые в одну: «считать отрезки». Но оказывается, что в ЗБ #86 вместо отрезков нужно считать последовательности линий. Последовательность линий здесь означает сцепление (одного или более) отрезков. Программа может догадаться об этом, например, благодаря тому, что ей известны оба понятия, «отрезок прямой» и «последовательность прямых», и что они расположены близко друг от друга в сети понятий. Другим, способом было бы изобретение понятия «последовательность прямых» — задача, мягко выражаясь, не из простых.
Далее следует ЗБ #87, в которой понятие «отрезок» обыгрывается по-иному. Когда один отрезок становится тремя? (См. рамку II-А.) Программа должна быть достаточно гибкой, чтобы переходить взад и вперед между различными описаниями данного фрагмента рисунка. Разумно сохранять в памяти старые описания, вместо того, чтобы их забывать и затем составлять снова, поскольку нет гарантии того, что новое описание окажется лучше прежнего. Таким образом, вместе с каждым старым описанием программа должна запоминать его сильные и слабые стороны. (Не правда ли, это начинает звучать довольно сложно?)
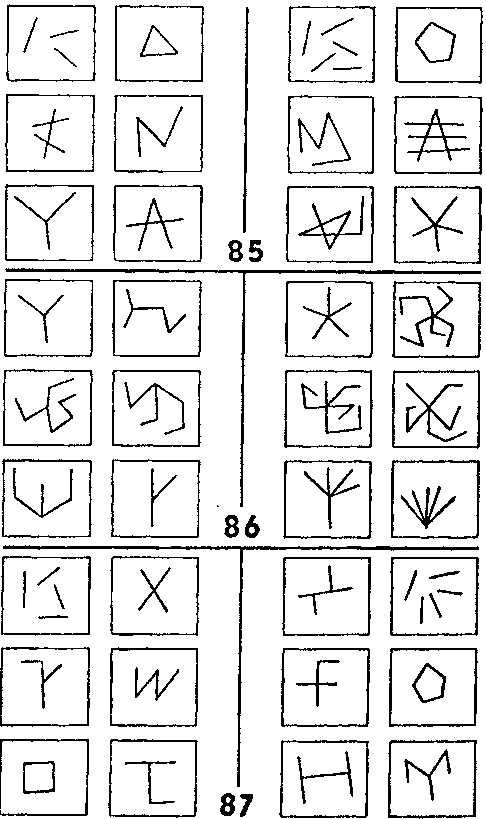
Рис. 125. Задачи Бонгарда ##85 — 87 (Из книги Бонгарда «Проблема узнавания»).
Мета-описания
Теперь мы подошли к другой жизненно важной части процесса узнавания; она имеет дело с уровнями абстракции и мета-описаниями. Для примера давайте вернемся к ЗБ #91 (рис. 121). Какой эталон можно здесь построить? С таким количеством вариантов трудно знать, откуда начинать. Но это уже само по себе является подсказкой! Это говорит нам, что различие между классами, скорее всего, существует на уровне, высшем чем уровень геометрических описаний. Это наблюдение подсказывает программе, что она может попытаться рассмотреть описания описаний — то есть мета-описания. Может быть, на этом втором уровне нам удастся обнаружить какие-либо общие черты, и, если повезет, найти достаточно сходства для того, чтобы создать эталон для мета-описаний. Таким образом, мы начинаем работу без эталона и создаем описания нескольких рамок; после того, как они закончены, мы описываем сами эти описания. Какие гнезда будут у нашего эталона для мета-описаний? Может быть, следующие:
использованные понятия: —
повторяющиеся понятия: —
названия гнезд: —
использованные фильтры: —
Существует множество других гнезд, которые могут быть использованы в мета-описаниях; это просто пример. Предположим теперь, что мы описали рамку I-Д в ЗБ #91. Ее «безэталонное» описание может выглядеть так:
горизонтальный отрезок.
вертикальный отрезок, находящийся на горизонтальном отрезке.
вертикальный отрезок, находящийся на горизонтальном отрезке.
вертикальный отрезок, находящийся на горизонтальном отрезке.
Разумеется, множество сведений было отброшено: то, что три вертикальных отрезка одинаковой длины, отстоят друг от друга на одно и то же расстояние и т. п. Но возможно и подобное описание. Мета-описание может выглядеть так:
использованные понятия: вертикальный-горизонтальный, отрезок, находящийся на
повторяющиеся понятия: 3 копии описания «вертикальный отрезок, находящийся на горизонтальном отрезке».
названия гнезд: —
использованные фильтры: —
Не все гнезда мета-описания должны быть заполнены: на этом уровне тоже возможно отбрасывание информации, как и на уровне «простого описания». Если бы мы теперь захотели составить описание и мета-описание любой другой рамки класса I, то гнездо «повторяющиеся описания» каждый раз содержало бы фразу «три копии ...» Детектор сходства заметил бы это и выбрал бы «тройничность» в качестве общей абстрактной черты рамок класса I. Таким же образом, путем мета-описаний может быть установлено, что «четверичность» — отличительная черта класса II.
Важность гибкости
Вы можете возразить, что использование мета-описаний в данном случае напоминает стрельбу по мухам из пушки, поскольку тройничность и четверичность могли быть найдены уже на первом уровне, если бы мы построили наше описание немного иначе. Это верно, но для нас важно иметь возможность решать эти задачи различными путями. Программа должна быть очень гибкой; она не должна быть обречена на провал, если ее «занесет» не туда. Я хотел проиллюстрировать общий принцип: когда построение эталона затруднено, потому что препроцессор запутывается среди различных деталей, это показывает, что здесь задействованы понятия на высших уровнях, о которых препроцессор ничего не знает.
Фокусирование и фильтрование
Теперь давайте рассмотрим другой вопрос: каким образом можно отбрасывать информацию. Ответ на этот вопрос включает два родственных понятия, которые я называю «фокусированием» и «фильтрованием». Фокусирование означает составление описания так, что оно сосредотачивается на каком-то одном районе картинки и «сознательно» оставляет без внимания все остальные. Фильтрование означает составление описания так, что оно видит содержимое картинки под каким-то определенным углом, и сознательно игнорирует все другие аспекты.
Таким образом, они дополняют друг друга: фокусирование имеет дело с объектами (грубо говоря, с существительными), а фильтрование — с понятиями (грубо говоря, с прилагательными).
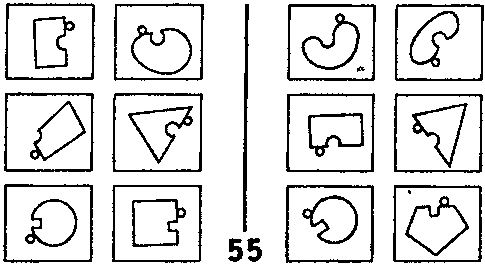
Рис. 126. Задача Бонгарда #55 (Из книги Бонгарда «Проблема узнавания»).
Для примера фокусирования рассмотрим ЗБ #55 (рис. 126). Здесь мы сосредотачиваемся на выемке и маленьком круге около нее, и оставляем без внимания все остальное. ЗБ #22 — это пример фильтрования. Мы отбрасываем все понятия, кроме размера. Для решения ЗБ #58 (рис. 128) требуется комбинация фокусирования и фильтрования.
Одним из важных способов получения идей для фокусирования и фильтрования является другой тип «фокусирования»: детальный анализ какой-либо особенно простой рамки — скажем, рамки с наименьшим количеством предметов. Очень полезным может оказаться сравнение между гобой простейших рамок обоих классов.
Но каким образом программа определяет, какие рамки самые простые, до того, как она производит их описание? Одним из способов определения простоты является поиск рамки с наименьшим количеством черт, найденных препроцессором. Это может быть сделано на ранних стадиях работы, поскольку для этого не нужен готовый эталон; на самом деле, это может быть использовано как поиск черт для включения в эталон. ЗБ #61 (рис. 129) — пример случая, когда такая техника дает плоды очень быстро.
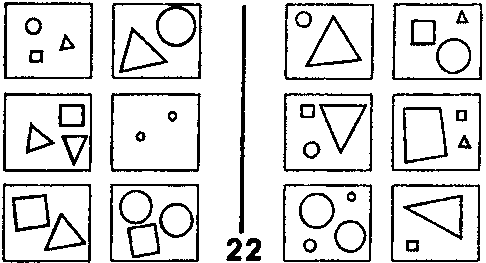
Рис. 127. Задача Бонгарда #22 (Из книги Бонгарда «Проблема узнавания»).
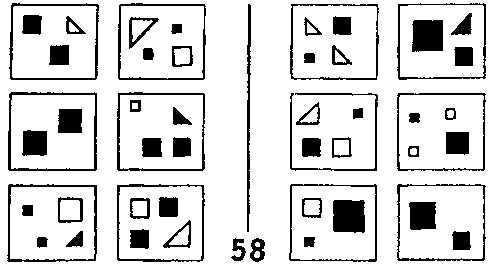
Рис. 128. Задача Бонгарда #58. (Из книги Бонгарда «Проблема узнавания»).
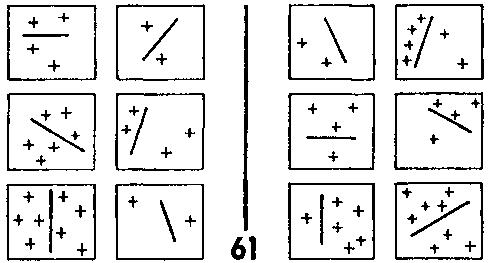
Рис. 129. Задача Бонгарда #61. (Из книги Бонгарда «Проблема узнавания»).
Наука и мир задач Бонгарда
Задачи Бонгарда можно интерпретировать как крохотную модель мира, занимающегося «наукой» — то есть поисками упорядоченных структур. В процессе этих поисков создаются и переделываются эталоны, гнезда переносятся с одного уровня обобщения на другой, используются фокусирование и фильтрование и т. д.
На каждом уровне сложности делаются свои открытия. Теория американского философа Куна о том, что странные события, которые он называет сдвигами парадигмы, отмечают границу между «нормальной» наукой и «концептуальными революциями», не кажется подходящей к нашему случаю, поскольку в данной системе сдвиги парадигмы происходят все время и на всех уровнях. Это объясняется гибкостью описаний.
Разумеется, некоторые открытия более «революционны», чем другие, поскольку они производят больший эффект. Например, мы можем обнаружить, что задачи #70 и #72 представляют из себя «одну и ту же задачу», рассмотренную на достаточно абстрактном уровне. Основная идея здесь в том, что в обеих задачах используется понятие «вложения» на глубине 1 и 2. Это новый уровень открытия в задачах Бонгарда. Существует еще более высокий уровень, касающийся всех картинок как целого. Если кто-либо не видел этого собрания, интересной задачей для него было бы попытаться представить себе, как эти картинки выглядят. Это было бы революционным открытием, хотя механизмы, которые при этом оперируют, не отличаются от механизмов, помогающих нам решать отдельные задачи Бонгарда.
По той же причине, настоящая наука не делится на «нормальные» периоды и периоды «концептуальных революций», сдвиги парадигм происходят в ней постоянно, большие и маленькие, на различных уровнях. Рекурсивные графики INT и график G (рис. 32 и 34) дают нам геометрическую модель этой идеи. Их структура полна скачков на всех уровнях, причем чем ниже уровень, тем меньше скачки.
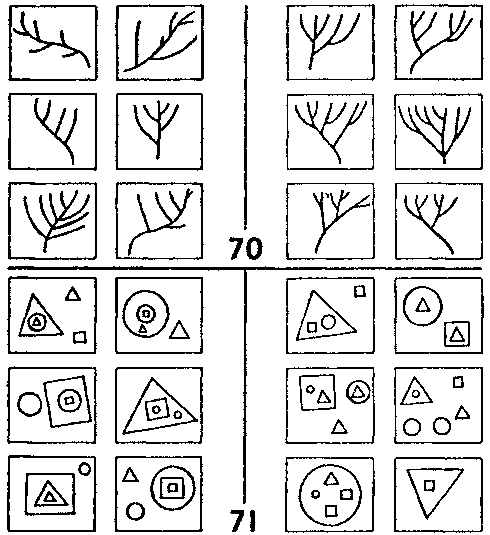
Рис. 130. Задачи Бонгарда ##70-71 (Из книги Бонгарда «Проблема узнавания»).
Связи с другими типами мысли
Чтобы поместить эту программу в контекст, я хочу упомянуть о том, как она соотносится с другими аспектами познания. Она зависит от других аспектов познания, а те, в свою очередь, зависят от нее. Поясню сначала ее зависимость от других аспектов познания. Интуиция, подсказывающая нам когда имеет смысл стереть различия, попытаться составить иное описание, вернуться по собственным следам, перейти на другой уровень и так далее, приходит только с общим опытом мышления. Поэтому так трудно определить эвристику для этих основных аспектов программы. Иногда наш опыт реального мира сложным образом влияет на то, как мы описываем и переописываем рамки. Например, кто может сказать, насколько знакомство с настоящими деревьями помогает в решении задачи #70? Маловероятно, что человеческая сеть понятий, относящихся к решению этих задач, может быть легко отделена от остальной сети понятий. Скорее интуиция, которую мы получили от созерцания и контакта с реальными предметами — расчески, поезда, цепочки, кубики, буквы, резинки и т. д., и т. п. — играет незаметную, но важную роль в решении подобных задач.
И наоборот, понимание ситуаций реального мира наверняка в большой степени зависит от зрительных образов и пространственной ориентации — таким образом, гибкий и эффективный способ представлять различные структуры (такие, как задачи Бонгарда) может только способствовать общей эффективности мыслительных процессов.
Мне кажется, что задачи Бонгарда были разработаны очень тщательно: в них есть некая универсальность, в том смысле, что у каждой из них — единственный правильный ответ. Разумеется, с этим можно спорить, утверждая, что то, что мы считаем «правильным», зависит от того, что мы — люди. Инопланетянин может совершенно с нами не согласиться. Несмотря на то, что у меня нет никакого конкретного свидетельства в пользу той или иной теории, я все-таки считаю, что задачи Бонгарда зависят от некоего чувства простоты и что люди — не единственные существа, обладающие этим чувством. То, что для этого важно быть знакомым с типично земными предметами, такими как расчески, поезда, резинки и тому подобное, не противоречит утверждению о том, что некое чувство простоты универсально, поскольку здесь важны не отдельные предметы, а тот факт, что вкупе они покрывают некое широкое пространство. Скорее всего, другие цивилизации будут обладать таким же большим репертуаром предметов и натуральных объектов и таким же обширным опытом. Поэтому мне кажется, что умение решать задачи Бонгарда находится близко к тому, что можно назвать «чистым» разумом — если таковой существует. Следовательно, с них можно начинать, если мы хотим изучить умение находить некое присущее схемам или сообщениям значение. К несчастью, мы привели здесь только небольшую часть этого замечательного собрания. Надеюсь, что многие читатели познакомятся со всем собранием, приведенным в книге Бонгарда (см. Библиографию).
Некоторые проблемы узнавания структур, которые полностью вросли в наше подсознание, довольно удивительны. Они включают:
узнавание лиц (неизменность лиц при возрастных изменениях, различных выражениях, разном освещении, разном расстоянии, под другим углом зрения и так далее);
узнавание тропинок в лесах и в горах — почему-то это всегда казалось мне одним из наиболее удивительных случаев узнавания схем. Однако это умеют делать и животные…
прочтение текста, написанного сотней, если не тысячей различных шрифтов.
Языки, рамки и символы, передающие сообщения
Одним из способов решения проблемы узнавания структур и других сложных проблем ИИ является так называемый «актерский» формализм Карла Хьюитта, подобный языку «Smalltalk», разработанному Аланом Кэйем и другими. Он заключается в том, что программа пишется в виде набора взаимодействующих актеров, которые могут обмениваться сложными сообщениями. Это чем-то напоминает гетерархическое собрание процедур, вызывающих друг друга. Основное различие состоит в том, что процедуры передают друг другу небольшое количество информации, в то время как сообщения, которыми обмениваются актеры, могут быть сколь угодно длинными и сложными.
Благодаря своему умения передавать сообщения, актеры становятся в каком-то смысле автономными агентами — их можно даже сравнить с самими компьютерами, а сообщения — с программами. Каждый актер может интерпретировать данное сообщение по-своему; таким образом, значение сообщения будет зависеть от актера, его получившего. Это объясняется тем, что в актерах есть часть программы, которая интерпретирует сообщения; поэтому интерпретаторов может быть столько же, сколько и актеров. Разумеется, интерпретаторы многих актеров могут оказаться идентичными; в действительности, это может быть большим преимуществом (так же важно, чтобы в клетке было множество плавающих в цитоплазме идентичных рибосом, каждая из которых будет интерпретировать сообщение — в данном случае, мессенджер ДНА — одинаковым образом).
Интересно подумать, как можно соединить понятие фреймов с понятием актеров. Давайте назовем фрейм, способный создавать и интерпретировать сложные сообщения, символом:
фрейм + актер = символ
Мы будем говорить здесь о том, как можно представить те неуловимые активные символы, которые обсуждались в главах XI и XII; поэтому в данной главе «символ» будет иметь то же значение. Не расстраивайтесь, если вы не сразу поймете, каким образом может произойти этот синтез. Это, действительно, неясно, — но это одно из самых многообещающих направлений исследований в ИИ. Более того, несомненно, что даже наилучшие синтетические представления будут менее мощными, чем символы человеческого мозга. В этом смысле, пожалуй, еще рановато называть объединения фреймов с актерами «символами», но это — оптимистический взгляд на вещи.
Давайте вернемся к темам, связанным с передачей сообщений. Должно ли данное сообщение быть направлено на определенный символ, или же оно должно быть брошено наугад, так же как мРНК брошен наугад в цитоплазму, где он должен найти свою рибосому? Если у сообщений есть предназначение, то у каждого символа должен быть адрес, по которому будут посланы соответствующие сообщения. С другой стороны, может существовать некая центральная «станция» для получения сообщений, где каждое сообщение будут храниться, как письмо до востребования, пока оно не понадобится какому-либо символу. Это — альтернатива доставке писем адресатам. Возможно, наилучшее решение — сосуществование обоих типов сообщений и возможность разных степеней срочности: сверхсрочное, срочное, обычное и так далее. Система почтовой связи — богатый источник идей для языков, передающих сообщения; она включает такие возможности как письмо с оплаченным ответом (сообщения, чьи отправители хотят срочно получить ответ), бандероли (очень длинные послания, которые могут быть посланы несрочным путем) и тому подобное. Когда вы исчерпаете запас почтовых идей, вашему воображению может дать толчок система телефонной связи.
Энзимы и ИИ
Другой источник идей для передачи сообщений — и обработки информации вообще — это, разумеется, клетка. Некоторые объекты клетки можно сравнить с актерами — в частности, эту роль выполняют энзимы. Активный центр каждого энзима работает как фильтр, который узнает только определенные типы субстратов (сообщений). Можно сказать, что у энзима есть «адрес». Благодаря своей третичной структуре, энзим «запрограммирован» так, чтобы провести некоторые операции с этим «сообщением» и затем снова выпустить его «в мир». Таким образом, путем передачи сообщения химическим путем от энзима к энзиму можно сделать очень многое. Мы уже описали сложные способы обратной связи в клетке (путем торможения или подавления). Эти механизмы показывают, что сложный контроль процессов может возникнуть из клеточного типа передачи сообщений.
Один из самых удивительных фактов, касающихся энзимов. — это то, что они бездействуют в ожидании нужного субстрата. Когда субстрат появляется, энзим внезапно начинает действовать, наподобие венериной мухоловки — насекомоядного растения. Подобная программа-триггер была использована в ИИ, где она получила название демона. Здесь важна идея наличия многих различных «семейств» подпрограмм, ожидающих активации. В клетке все сложные молекулы и органоиды строятся постепенно, шаг за шагом. Некоторые из этих новых структур сами являются энзимами и участвуют в построении новых энзимов — которые, в свою очередь, начинают строить другие типы энзимов и так далее. Подобные рекурсивные каскады энзимов очень сильно влияют на то, что делается в клетке. Было бы хорошо перенести подобный простой, ступенчатый процесс в ИИ — в построение полезных подпрограмм. Например, повторение — это способ вмонтировать некие структуры в аппаратуру нашего мозга, так что часто повторяемое поведение становится закодировано на подсознательном уровне. Было бы полезно найти аналогичный способ создания эффективных кусочков кода, которые могли бы производить такую же последовательность операций, как и нечто, выученное на высшем уровне «сознания». Каскады энзимов могут служить моделью того, как это может быть сделано. (Программа под названием «Hacker», написанная Геральдом Суссманом, создает и отлаживает небольшие подпрограммы способом, не слишком отличным от каскада энзимов.) Детектор сходства в программе, решающей задачи Бонгарда, мог бы сыграть роль такой энзимообразной подпрограммы. Подобно энзиму, этот детектор бродит вокруг, иногда натыкаясь на небольшие фрагменты данных. Когда пара его «активных центров» заполняется схожими структурами, детектор посылает сообщение другим частям программы (актерам). Пока программы соединены последовательно, иметь несколько копий детектора сходства не имеет смысла; однако в параллельном компьютере регулировка количества копий подпрограммы была бы способом регулировки также и предполагаемого времени до конца программы. Таким же образом, регулировка количества копий данного энзима в клетке регулирует скорость данного процесса. Создание новых детекторов было бы сравнимо с просачиванием обнаружения структур на низшие уровни нашего разума.
Расщепление и синтез
Две интересные дополнительные идеи, касающиеся взаимодействия символов, — это расщепление и синтез. Расщепление — это постепенное отделение нового символа от символа-родителя (то есть символа, послужившего эталоном для создания нового символа). Синтез — это то, что происходит, когда два ранее не связанных символа участвуют в «совместной активации», передавая сообщения между собой так интенсивно, что они становятся слитными; после чего эта комбинация начинает действовать как один символ. Расщепление — процесс более или менее неизбежный. Как только новый символ произведен на основе старого, он становится автономным, и его взаимодействие с окружающим миром отражается в его собственной внутренней структуре. Таким образом, то, что началось как совершенная копия, вскоре становится неточным, и все меньше и меньше походит на первоначальный символ. Синтез — вещь более тонкая. Когда два понятия сливаются в одно? Можно ли указать точный момент, когда это происходит? Понятие совместной активации открывает Пандорин ящик вопросов. Например, слышим ли мы отдельно слова «пар» и «ход», когда говорим о пароходе? Когда немец думает о перчатках («Handschuhe»), слышит ли он слова «Hand» и «Schuhe» («рука» и «обувь»)? А как насчет китайцев, чье слово «донг-хи» («восток-запад») означает «вещь»? Эта проблема переходит в область политики, когда некоторые люди высказывают мысль, что слова типа «медсестра» выражают недостаток уважения к женщинам. То, в какой степени в целом звучат отдельные части, варьируется, скорее всего, в зависимости от человека и от обстоятельств.
Основная проблема с понятием «синтеза» символов заключается в том, что очень трудно найти алгоритм, создающий новые значимые символы из символов, сталкивающихся между собой. Это подобно двум соединяющимся цепочкам ДНК. Каким образом можно взять части каждой из них и соединить их в новую значимую цепочку, в которой была бы закодирована особь того же класса? Или нового класса? Почти невероятно, что случайная комбинация ДНК окажется жизнеспособной, — вероятность этого такая же, как вероятность того, что перемешанные слова двух книг создадут третью книгу. Скорее всего, рекомбинация ДНК будет бессмысленна на всех уровнях, кроме самого низшего, именно потому, что в ДНК так много уровней значения… То же самое верно и для «рекомбинаций символов».
Эпигенез «Крабьего канона»
Мой Диалог «Крабий канон» кажется мне прототипом того, как две идеи столкнулись у меня в голове, соединились по-новому и вызвали к жизни новую словесную структуру. Разумеется, я все еще могу думать о музыкальных канонах и о диалогах раздельно; эти символы все еще могут быть активированы у меня в голове независимо друг от друга. Однако у этого синтетизированного символа для крабоканонических диалогов также есть собственный характерный вид активации. Чтобы проиллюстрировать понятие синтеза или «символической рекомбинации» более подробно, я хотел бы использовать пример создания «Крабьего канона». Во-первых, это мне хорошо известно, а во-вторых, это интересно и типично для того, чтобы показать, как далеко можно пойти в развитии какой-либо идеи. Я изложу это по стадиям, названным в честь мейоза — деления клеток, в котором участвует скрещивание хромосом, или генетическая рекомбинация, — источники разнообразия в эволюции.
ПРОФАЗА: Я начал с довольно простой идеи — что музыкальное произведение, например, канон, можно проимитировать словесно. Это было основано на наблюдении, что кусок текста и кусок музыкальной пьесы могут быть соотнесены между собой путем использования одной и той же абстрактной формы. Следующим шагом была попытка воплотить в жизнь некоторые возможности этой туманной идеи: здесь мне пришло в голову, что «голоса» канонов могут быть отображены в «действующих лицах» диалогов, — мысль все еще довольно очевидная.
Далее я стал перебирать специфические виды канонов и вспомнил, что в «Музыкальном приношении» был ракоходный канон. Тогда я только начинал писать Диалоги, и в них было лишь два действующих лица: Ахилл и Черепаха. Поскольку Баховский ракоходный канон — двухголосный, соответствие было полным: Ахилл был бы первым голосом, идущим вперед, а Черепаха — вторым, идущим назад. Однако здесь возникла следующая трудность: на каком уровне должно происходить обращение? На уровне букв? Предложений? После некоторого раздумья я заключил, что самым подходящим является уровень реплик, то есть драматического действия.
После того, как «скелет» Баховского канона был переведен, по крайней мере, в черновике, в словесную форму, оставалась одна проблема. Когда оба голоса встречались в середине, то получался период крайнего повторения — довольно серьезный недостаток. Как можно было поправить дело? Тут произошла странная вещь — типичное для творчества скрещение уровней: мне в голову пришло слово «краб» из названия канона, несомненно, из-за некоей его общности с понятием «черепахи». Я тотчас сообразил, что повторение в середине может быть предотвращено, если ввести туда реплику, произнесенную новым действующим лицом — Крабом! Так в «профазе» «Крабьего канона» из скрещивания Ахилла и Черепахи на свет появился Краб. (См. рис. 131).

Рис. 131. Схематическая диаграмма Диалога «Крабий канон».
МЕТАФАЗА: Итак, скелет моего «Крабьего канона» был готов. Я перешел ко второй стадии — «метафазе,» — в которой моей задачей было облечь скелет в плоть. Разумеется, это было нелегкой задачей. Мне пришлось изрядно попотеть в поисках пар фраз, которые имели бы смысл при прочтении в обратном порядке, и фраз с двойным значением, которые помогли бы мне создать подобную форму (например, «не стоит»). Два ранних варианта получились интересными, но слабоватыми. Когда, после годичного перерыва, я вернулся к работе над книгой, у меня было несколько новых идей для «Крабьего диалога». Одной из них было упоминание какого-либо Баховского канона в самом Диалоге. Сначала я собирался упомянуть о каноне под названием «Canon per augmentationem, contrario motu» из «Музыкального приношения» (этому канону у меня соответствует Диалог «Канон ленивца»). Однако это выглядело глуповато, так что в конце концов я решил, скрепя сердце, что в «Крабьем каноне» я могу говорить собственно о ракоходном каноне Баха. На самом деле, это оказалось поворотным пунктом в работе над Диалогом, о чем я тогда еще не догадывался.
Но если одно действующее лицо упоминает о Баховской пьесе, не будет ли звучать нелепо, если в соответствующем месте Диалога второе действующее лицо скажет точно то же самое? В книге и в мыслях у меня Эшер играл роль, подобную роли Баха; нельзя ли было немного изменить соответствующую реплику так, чтобы во второй раз она относилась к Эшеру? В конце концов, в строгом искусстве канонов ради красоты и элегантности иногда допускаются отступления от точного повторения темы. И как только я об этом подумал, мне тут же пришла в голову картина «День и ночь» (рис. 49). «Ну конечно!» — сказал я себе. «Ведь это тоже что-то вроде ракоходного канона, где два взаимно дополняющих голоса проводят одну и ту же тему направо и налево, гармонируя друг с другом!» Здесь мы снова сталкиваемся с понятием единой «концептуальной схемы», воплощенной в различных контекстах, — в данном случае, в музыке и в графике. Таким образом, я позволил Ахиллу говорить о Бахе, а Черепахе — об Эшере, но в параллельных выражениях, безусловно, это небольшое отступление от точного повторения не угрожало духу ракоходного канона.
Примерно тогда же я заметил, что случилось нечто удивительное: Диалог стал автореферентным, хотя я ничего подобного не планировал! Более того, это была косвенная автореферентность, поскольку герои нигде не упоминали о Диалоге, действующими лицами которого они в данный момент являлись. Вместо этого они говорили о структурах, на некотором абстрактном уровне изоморфных этому Диалогу. Иными словами, мой Диалог теперь имел тот же самый «концептуальный скелет», как и Гёделево утверждение G, и, таким образом, мог быть отображен на G примерно так же, как и Центральная Догма Типогенетики. Это было замечательно: нежданно-негаданно я нашел пример эстетического единства Гёделя, Эшера и Баха.
АНАФАЗА: Следующий шаг был довольно удивительным. У меня давно лежала монография Каролины Макгилаври, посвященная мозаичным работам Эшера; однажды, когда я стал ее перелистывать, мое внимание привлекла гравюра 23, которую я вдруг увидел в неожиданном свете: передо мной был самый настоящий крабий канон, как по форме, так и по содержанию! Эшер оставил эту картину без названия, и поскольку у него есть множество подобных мозаик с другими животными, возможно, что это совпадение формы и содержания было только моей случайной находкой. Так или иначе, эта безымянная гравюра была миниатюрной версией главной идеи моей книги — объединения формы и содержания. Так что я радостно окрестил гравюру «Крабьим каноном», поставил ее на место «Дня и ночи» и соответствующим образом изменил реплики Ахилла и Черепахи.
Однако это еще было не все. В то время я увлекался молекулярной биологией; однажды, перелистывая в магазине книгу Уатсона, я наткнулся в индексе на слово «палиндром». Найдя это слово в тексте, я обнаружил нечто удивительное, крабо-канонические структуры в ДНК. Тогда я изменил крабью речь, включив в нее замечание о том, что его любовь к странным движениям взад и вперед заложена в его генах.
ТЕЛОФАЗА: Последний шаг был сделан несколько месяцев спустя, когда, рассказывая кому-то о крабо-каноническом отрезке ДНК (рис. 43), я заметил, что «А», «Т» и «С», обозначающие, соответственно, аденин, тимин и цитозин, совпадали — mirabile dictu — с «А», «Т» и «С» Ахилла, Черепахи (Tortoise) и Краба (Crab). Более того, так же, как аденин и тимин попарно соединены в ДНК, Ахилл и Черепаха соединены в Диалоге. С другой стороны, «G», буква, спаренная в ДНК с «С», могла обозначать Гения. Я снова вернулся к Диалогу и немного изменил речь Краба, так что она отразила эту новую находку. Теперь у меня было соответствие структуры ДНК структуре Диалога. В этом смысле можно сказать, что ДНК было генотипом, в котором был закодирован фенотип — структура Диалога. Этот финальный аккорд снова подчеркнул автореференцию и придал Диалогу такое глубокое значение, которого я сам не ожидал.
Концептуальные скелеты и концептуальное отображение
Это более или менее полное описание эпигенеза «Крабьего канона». Этот процесс можно рассматривать как постепенное отображение идей друг на друга на разных уровнях абстракции. Я называю это концептуальным отображением, а абстрактные структуры, роднящие две разные идеи — концептуальными скелетами. Пример концептуального скелета — абстрактное понятие крабьего канона:
структура, состоящая из двух частей, которые проделывают одно и то же, но двигаются при этом в противоположных направлениях.
Это конкретный геометрический образ, с которым мы можем обращаться почти так же, как с задачей Бонгарда. Думая о «Крабьем каноне», я представляю себе две ленты, перекрещивающиеся в центре, где они соединены узлом (реплика Краба). Этот настолько наглядный образ, что он тут же отображается у меня в голове на образ двух хромосом, в середине соединенных центромерой — картина, прямо выведенная из мейозиса (см. рис. 132).

Рис. 132.
Именно этот образ навел меня на мысль описать создание «Крабьего канона» в терминах мейозиса — что само по себе, разумеется, также является примером концептуального отображения.
Рекомбинация идей
Существуют разные способы синтеза двух символов. Например, можно расположить идеи рядышком (словно идеи линейны!) и затем выбирать из каждой по кусочку и комбинировать их по-новому. Это напоминает генетическую рекомбинацию. Чем именно обмениваются хромосомы, и как они это делают? Они обмениваются генами. Что в символе сравнимо с геном? Если в символе есть рамкообразные гнезда, то, пожалуй, именно эти гнезда. Но какие из них должны быть обменены, и почему? Ответить на этот вопрос нам поможет синтез крабоканонического типа. Отображение понятия «музыкального канона-ракохода» на понятие «диалога» включало в себя несколько дополнительных отображений — в действительности, оно порождало дополнительные отображения. Как только было решено, что эти идеи должны быть отображены друг на друга, оставалось лишь взглянуть на них на том уровне, где были заметны аналогичные части, и затем начать их взаимное отображение. Этот рекурсивный процесс может идти на каком угодно уровне. Например, «голос» и «действующее лицо» возникли как соответствующие друг другу гнезда абстрактных понятий «музыкальный канон» и «диалог». Откуда же взялись сами эти абстрактные понятия? Это основная проблема отображения: откуда берутся абстрактные представления? Как можно получить абстрактное представление специфических понятий?
Абстракции, скелеты и аналогии
Концептуальный скелет — это некое абстрактное представление, полученное путем проецирования понятия на одно из его измерений. Мы уже имели дело с концептуальными скелетами, не называя их по имени. Например, многие идеи, касающихся задач Бонгарда, могут быть выражены в этих терминах. Это всегда интересно и часто полезно, когда мы обнаруживаем, что две (или более) идеи имеют сходный концептуальный скелет. Примером этого может служить странный набор понятий, упоминающихся в начале «Контрафактуса»: бициклопы, одноколесный тандем, мотоциклы «Зигзиг», игра в пинг-пинг, команда, разделившая первое место сама с собой, двухсторонний лист Мёбиуса, «близнецы Бах», фортепианный концерт для двух левых рук, одноголосная фуга, аплодирование одной рукой, двухканальный моно-магнитофон, четверка четвертьзащитников. Все эти идеи изоморфны, потому что у них один и тот же концептуальный скелет:
множественная вещь, разъятая на части и собранная ошибочно.
Две других идеи этой книги, разделяющие один и тот же концептуальный скелет, это (1) Черепахино решение Ахилловой головоломки — найти слово, начинающееся и кончающееся на «КА» (она предложила частицу «КА», соединяющие оба «ка» в одно) и (2) доказательство Теоремы Ослиного Мостика (Pons Asinorum), предложенное Паппусом и программой Гелернтера, в котором один треугольник представлен как два. Эти странные сооружения можно именовать «полу-двойняшками.»
Концептуальный скелет — нечто вроде набора постоянных черт идеи, которые, в отличие от ее параметров и переменных, должны оставаться неизменными при отображении ее на другие идеи или при выдумывании альтернативных миров. Поскольку в концептуальном скелете нет собственных параметров и переменных, он может лежать в основе нескольких различных идей. В каждом конкретном примере (как, скажем, «моно-тандем») есть уровни изменчивости, что позволяет нам модифицировать его по-разному. Хотя название «концептуальный скелет» вызывает образ чего-то жесткого и абсолютного, на самом деле он довольно гибок. На разных уровнях абстракции можно найти различные концептуальные скелеты. Например, «изоморфизм» между задачами Бонгарда #70 и #71, о котором я уже упоминал, включает концептуальный скелет более высокого уровня, чем тот, который требуется для решения обеих задач в отдельности.
Множественные представления
Концептуальные скелеты должны существовать не только на разных уровнях абстракции, но также в разных концептуальных измерениях. Возьмем, например, следующее изречение:
«Вице-президент — запасное колесо в автомобиле правительства.»
Как мы понимаем, что это означает (оставляя в стороне важнейший аспект этой фразы — ее юмор)? Если бы вам внезапно предложили сравнить правительство с автомобилем, вы могли бы найти разнообразные параллели: руль — президент и т. д. Но чему соответствует Дума? С чем сравнить пристяжные ремни? Поскольку отображаемые понятия очень различны, отображение неизбежно будет происходить на функциональном уровне. Следовательно, вы сосредоточите внимание на тех частях автомобиля, которые имеют отношение не к форме, а к функции. Более того, имеет смысл работать на довольно высоком уровне абстракции, где «функция» понимается в широком контексте. Поэтому в данном случае из следующих двух определений запасного колеса: (1) «замена для колеса с проколотой шиной» и (2) «замена для некоей не функционирующей части машины», вы выберете последнее. Автомобиль и правительство настолько различны, что вам приходится работать на высоком уровне абстракции.
Когда вы рассматриваете данное предложение, вам навязывается некое конкретное отображение. Однако оно вовсе не является для вас неестественным, поскольку среди многих определений вице-президента, у вас есть и такое: «замена для некоей не функционирующей части правительства.» Поэтому навязанное вам отображение в данном случае кажется естественным. Предположим теперь, для контраста, что вы хотите воспользоваться другим определением запасного колеса, — скажем, описанием его физических аспектов. Среди прочего, это определение утверждает, что запасное колесо «круглое и надутое». Ясно, что это нам не подходит. (Правда, один мой знакомый указал мне на то, что некоторые вице-президенты довольно-таки объемисты и большинство из них весьма надуты!)
Порты доступа
Одной из основных характеристик каждого индивидуального стиля мышления является то, как в нем классифицируются и запоминаются новые впечатления. Это определяет те «ручки», за которые данное воспоминание можно будет затем вытащить из памяти. Для событий, объектов и идей — для всего, что только можно представить — существует огромное разнообразие таких «ручек». Это поражает меня каждый раз, когда я протягиваю руку, чтобы включить радио в машине и, к моему удивлению, обнаруживаю, что оно уже включено! Тут происходит следующее: я использую два различных определения радио. Одно из них — «производитель музыки», другое — «рассеиватель скуки». Я знаю, что музыка уже играет. Но поскольку мне все равно скучно, я протягиваю руку, чтобы включить радио, прежде чем эти два образа успевают войти в контакт. Тот же «радиовключательный рефлекс» сработал однажды сразу после того, как я оставил сломанное радио в мастерской и ехал домой; мне захотелось послушать музыку. Странно! Для того же радио существует множество других представлений, как например:
штуковина с блестящими серебряными ручками
штуковина, которая постоянно перегревается
штуковина, для починки которой приходится улечься на спину
производитель помех
предмет с плохо закрепленными ручками
пример множественных представлений
Все они могут служить портами доступа. Хотя все они связаны с символом, представляющим в моей голове радио в машине, его активация через одно из этих представлений не активирует остальных. Маловероятно, чтобы, включая радио, я думал бы о том, что для его починки надо лечь на спину. Наоборот, когда я, лежа на спине, орудую отверткой, то вряд ли вспомню о том. как слушал по этому радио «Искусство фуги». Между различными аспектами символа существуют «перегородки», которые не позволяют моим мыслям переливаться туда-сюда в потоке свободных ассоциаций. Эти перегородки важны, поскольку они сдерживают и направляют поток моих мыслей.
Одно из мест, где эти перегородки очень жестки, — это разделение слов для одного и того же понятия на разных языках. Если бы перегородки были слабее, люди, знающие несколько языков, в разговоре постоянно перескакивали бы с одного языка на другой, что было бы очень неловко. Разумеется, взрослые, изучающие сразу два языка, часто путаются между ними. Перегородки между этими языками не так сильны и могут ломаться. Переводчики в этом смысле особенно интересны, поскольку они могут говорить на любом из своих языков так, словно перегородки между ними нерушимы, — и тут же, по команде, могут нарушить эти перегородки и попасть из одного языка в другой для перевода. Джордж Штейнер, с детства говоривший на трех языках, посвящает несколько страниц своей книги «После Вавилонского столпотворения» переплетению французского, английского и немецкого у него в мозгу и тому, каким образом разные языки позволяют разные порты доступа к понятиям.
Форсированное соответствие
Когда мы видим, что две идеи разделяют один и тот же концептуальный скелет, из этого могут получиться разные вещи. Обычно мы прежде всего разглядываем идеи крупным планом и, руководствуясь соответствиями на высших уровнях, пытаемся найти соответствующие части этих идей. Иногда сходство может быть прослежено рекурсивно также на низших уровнях, выявляя глубокий изоморфизм. Иногда соответствие прекращается раньше, указывая на аналогию или сходство. Иногда же найденное на высшем уровне сходство настолько притягательно, что, даже если сходство на низших уровнях не очевидно, мы его просто придумываем. У нас получается форсированное соответствие.
Такие притянутые за уши соответствия каждый день встречаются в политических шаржах в газетах, государственные мужи изображаются в форме аэроплана, парохода, рыбы или Моны Лизы. Правительство становится человеком, птицей или нефтяной вышкой; договор — портфелем, мечом или банкой с червями… и так далее, и тому подобное. Интересно то, насколько легко мы можем проделать в уме предложенные отображения на нужную глубину, не находя слишком глубоких или слишком поверхностных соответствий.
Еще один пример запихивания одного предмета в форму другого — это мое решение описать создание «Крабьего канона» в терминах мейозиса. Это произошло постепенно. Сначала я заметил общий концептуальный скелет в «Крабьем каноне» и в образе хромосом, соединенных в середине центромерой; это послужило толчком к рождению форсированного соответствия. Затем я заметил сходство на высшем уровне, касающееся «роста», «стадий» и «рекомбинации». После этого я развил эту аналогию насколько смог. Экспериментирование, как в решении задач Бонгарда, сыграло важную роль; я шел вперед и снова возвращался, пока не натыкался на подходящее соответствие.
Третий пример концептуального отображения — схема Центральной Догмы Типогенетики. Сначала я заметил сходство на высшем уровне между открытиями математической логики и молекулярной биологии; затем я перенес поиски на низшие уровни, пока не нашел хорошей аналогии. Чтобы еще усилить эту аналогию, я выбрал нумерацию Гёделя, имитирующую Генетический Код. Этот элемент стоит особняком в форсированном соответствии, показанном на схеме Центральной Догмы.
Форсированные соответствия нелегко четко отделить от аналогий и метафор. Спортивные комментаторы часто используют живые образы, трудно поддающиеся классификации. Например, услышав метафору «Динамовцы забуксовали» трудно сообразить, что мы должны себе представить. Колеса у целой команды? У каждого игрока? Возможно, что ни то и не другое. Скорее всего, образ колес, крутящихся в грязи или на снегу, появляется у нас в голове всего на секунду и затем, таинственным образом, только нужные его части переносятся на образ футбольной команды. Насколько глубоко бывает в эту секунду соответствие образа автомобиля образу футбольный команды?
Повторение
Давайте попытаемся связать все это воедино. Я описал несколько идей, связанных с возникновением, манипуляцией и сравнением символов. Большинство из них так или иначе связаны с переходами между символами и их варьированием. Идея здесь в том, что в символах есть элементы жесткие и элементы более гибкие; все они происходят с разных уровней вложенных один в другой контекстов (фреймов). Свободные элементы могут быть легко заменены; в зависимости от обстоятельств, в результате такой замены может получиться «гипотетический повтор», форсированное соответствие или аналогия. Процесс, в котором одни части обоих символов варьируются, а другие остаюттся неизменными, может закончиться синтезом этих символов.
Творческие способности и случай
Понятно, что мы говорим здесь о механизмах творчества. Но не является ли это само по себе противоречием? Почти — но не совсем. Творчество — квинтэссенция того, что не механично. И тем не менее, каждый отдельный акт творчества механичен и может быть объяснен так же, как, например, икота. Этот механический субстрат творчества может быть скрыт он нашего взгляда, но он существует. И наоборот, даже на сегодняшний день в гибких компьютерных программах есть нечто немеханичное. Может быть, это еще не творческие способности, но в тот момент, когда программа перестает быть «прозрачной» для своих создателей, начинается приближение к творчеству.
Обычно считается, что случайность — это необходимый ингредиент творческих актов. Это может быть верным, но это никак не влияет на механичность — или, скорее, программируемость — творческих способностей. Мир — это огромная куча случайностей, и когда вы отражаете часть его в голове, то в вашем мозгу отражается и немного этой случайности. Поэтому схемы активации символов могут повести вас по самым причудливым, выбранным наугад дорогам просто потому, что они отражают ваше взаимодействие с непредсказуемым, сумасшедшим миром. То же самое может произойти и с программой компьютера. Случайность — это органическая черта мышления, а не то, что должно быть получено путем «искусственного оплодотворения», будь то игральные кости, распадающиеся ядра, таблицы случайных чисел или что-нибудь еще в этом роде. Не стоит оскорблять человеческие творческие способности, предполагая, что они базируются на подобных источниках!
То, что кажется нам случайным, часто представляет из себя эффект наблюдения над симметричной структурой через «кривой» фильтр. Изящный пример этого был изобретен Салвиати с его двумя способами описания числа π/4. Хотя десятичная дробь π/4 в действительности не является случайной, она достаточно случайна для практических нужд, можно сказать, что она «псевдослучайна». Математика полна псевдослучайностями — на всех творцов хватит! Так же, как наука полна «концептуальными революциями» на все уровнях и во все времена, индивидуальное мышление людей сплошь пронизано творческими актами. Мы находим их повсюду, а не только на высшем уровне. Большинство этих творческих актов весьма скромно и повторялось уже миллионы раз, но они- — двоюродные братья самого высокого и новаторского творчества. Компьютерные программы на сегодняшний день еще не совершают маленьких творческих актов; то, что они умеют делать, в основном механично. Это показывает, что они все еще далеки от удачной имитации нашего мышления — но постепенно они к этому приближаются.
Возможно, что высокотворческие идеи отличаются от обычных неким комбинированным чувством красоты, простоты и гармонии. По этому поводу у меня есть любимая «мета-аналогия», в которой я сравниваю аналогии с аккордами. Идея проста, схожие на вид мысли часто соотносятся между собой поверхностно, в то время как глубоко соотнесенные мысли на первый взгляд часто совсем несхожи. Сравнение с аккордами здесь естественно физически близко расположенные ноты гармонически отстоят друг от друга далеко (например, E-F-G [ми, фа, соль]), в то время, как гармонически близкие ноты физически далеки друг от друга (например. G-E-B [соль, ми, си]). Идеи, обладающие одним и тем же концептуальным скелетом, резонируют в некоей концептуальной гармонии; эти гармоничные «идеи-аккорды» часто отстоят весьма далеко друг от друга на воображаемой «клавиатуре идей». Разумеется, недостаточно просто взять интервал побольше — вы можете попасть на седьмую или девятую клавишу! Может быть, моя аналогия и есть такая «девятая клавиша,» отстоящая далеко, но тем не менее диссонантная.
Обнаружение повторяющихся структур на всех уровнях
В этой главе я остановился на задачах Бонгарда так подробно потому, что, когда вы их изучаете, вам становится ясно, что то трудно описуемое чувство схожих структур, которое мы, люди, получаем вместе с генами, содержит все механизмы представления знаний в мозгу. Это включает вложенные друг в друга контексты, концептуальные скелеты и концептуальное отображение; возможность перехода от одного понятия к другому; описания, мета-описания и их взаимодействие; расщепление и синтез символов; множественные представления (в различных «измерениях» и на различных уровнях абстракции); подразумеваемые элементы и тому подобное.
На сегодняшний день можно с уверенностью сказать, что если некая программа может замечать регулярности в одной области, она обязательно пропустит в другой области нечто, что нам, людям, кажется столь же очевидным. Если вы помните, я уже упоминал об этом в главе I, говоря, что машины могут не замечать повторяемости, в то время как люди на это не способны. Рассмотрим, например, ШРДЛУ. Если бы Эта Ойн печатала фразу «Возьми большой красный кубик и положи его на место» снова и снова; ШРДЛУ, не возражая, реагировала бы на это снова и снова, точно так же, как калькулятор может отвечать «4» снова и снова, если у человека хватит терпения печатать «2×2» снова и снова. Люди так не делают: если нечто повторяется снова и снова, они это обязательно заметят. ШРДЛУ не хватает потенциала для формирования новых понятий или узнавания схожих структур; у нее нет чувства повторяемости.
Гибкость языка
ШРДЛУ обладает удивительно гибким (в своих пределах) умением обращаться с языком. Эта программа понимает синтаксически очень сложные и даже двусмысленные предложения, если они могут быть проинтерпретированы на основе имеющихся данных, но она не способна понять «расплывчатого» языка. Возьмем, например, предложение «сколько кубиков надо поставить один на другой, чтобы получилась колокольня?» Мы тут же его понимаем, хотя, проинтерпретированное буквально, это предложение бессмысленно. И дело здесь не в использовании какой-то идиоматической фразы. «Поставить один на другой» — это неточное выражение, хотя люди понимают его без труда. Мало кто представит себе два кубика, каждый из которых стоит наверху другого.
Удивительно, насколько неточно мы используем язык — и все же нам удается общаться друг с другом! ШРДЛУ использует слова «металлическим» образом, в то время, как люди обращаются с ними как с губками или резиновыми мячиками. Если бы слова были гайками и болтами, люди могли бы просунуть любой болт в любую гайку, они просто затолкали бы один в другой, как в сюрреалистической картине, где все предметы представлены мягкими. Язык в людском употреблении становится почти текучим, несмотря на твердость его составляющих.
В последнее время внимание специалистов по ИИ в области понимания натурального языка сместилось от понимания отдельных предложений в сторону понимания больших кусков текста, такого, как рассказы и сказки для детей. Вот, например, незаконченная детская шутка, иллюстрирующая незаконченность ситуаций реальной жизни:
Один человек решил прокатиться на аэроплане.
К несчастью, он оттуда вывалился.
К счастью, у него был парашют.
К несчастью, парашют был сломан.
К счастью, он падал прямо на стог сена.
К несчастью, в стогу торчали вилы.
К счастью, он пролетел мимо вил.
К несчастью, он пролетел мимо стога.
Эта глупая история может продолжаться до бесконечности. Представить ее в системе фреймов было бы очень сложно: для этого понадобились бы одновременно активируемые фреймы для понятий человека, аэроплана, парашюта, падения и т. д.
Интеллект и эмоции
Или взгляните на эту коротенькую печальную историю:
Маша крепко зажала в кулаке веревочки новых красивых воздушных шаров. Вдруг налетел ветер и вырвал их у нее из рук Ветер отнес их к дереву. Шарики наткнулись на ветки и лопнули Машенька горько заплакала.
Чтобы понять эту историю, необходимо читать между строчками: Маша — маленькая девочка. Речь идет об игрушечных воздушных шарах с веревочками, чтобы ребенок мог их держать. Взрослому они могут не показаться красивыми, но в глазах ребенка они прекрасны. Маша стоит на улице или во дворе. «Они», которые ветер вырвал у Маши из рук, — это шарики. Ветер не понес Машу вместе с шариками — она их выпустила. Шарики могут лопнуть, наткнувшись на что-то острое. Лопнув, шарики утеряны безвозвратно. Маленькие дети любят шарики и могут быть горько разочарованы, когда те лопаются. Маша видела, как ее шарики лопнули. Дети плачут, когда им грустно. Маша горько плакала, потому что ей было очень грустно из-за потери шариков.
Это, скорее всего, только маленькая часть того, что не выражено на поверхностном уровне истории. Чтобы понять рассказ, программа должна все это знать. Вы можете возразить, что даже если программа и «понимает» рассказ на некоем интеллектуальном уровне, она все равно не поймет его «по-настоящему», пока сама не научится «горько плакать». Когда же компьютеры начнут это делать? Подобную антропоцентрическую точку зрения высказывает Иосиф Вайценбаум в своей книге «Мощь компьютеров и человеческий разум» (Weizenbaum. «Computer Power and Human Reason»), и я думаю, что это важная и очень глубокая тема. К несчастью, в данный момент многие специалисты по ИИ не желают, по разным причинам, серьезно относиться к этому вопросу. С другой стороны, они правы в том, что сейчас пока преждевременно думать о плачущих компьютерах; мы должны думать о том, как научить компьютеры понимать человеческую речь. В свое время мы столкнемся с более глубокими и сложными проблемами.
Перед ИИ лежит долгий путь
Иногда кажется, что, поскольку человеческое поведение настолько сложно, оно не управляется никакими правилами. Но это только иллюзия — все равно, что считать, что кристаллы и металлы появляются на свет, следуя жестким правилам, а жидкости и цветы — нет. Мы вернемся к этому вопросу в следующей главе.
Процесс самой логики, происходящий в мозгу, может быть аналогичен последовательности операций с символическими структурами, — что-то вроде абстрактной аналогии китайского алфавита или описания событий на языке майя. Разница заключается в том, что элементами здесь являются не слова, но нечто вроде предложений или целых рассказов, связи между которыми образуют некую мета- или сверх-логику с собственными правилами.
Для большинства специалистов оказывается трудным выразить (и иногда даже вспомнить!), что именно побудило их заняться данной дисциплиной. Наоборот, сторонний наблюдатель может с легкостью понять, в чем очарование этой дисциплины, и точно это выразить. Думаю, что именно поэтому вышеприведенная цитата из Улама мне так нравится — она поэтично описывает всю странность исследований по ИИ и, тем не менее, выражает веру в успех. Действительно, здесь приходится часто опираться на веру — перед ИИ пока лежит весьма длинный путь!
Десять вопросов и возможных ответов
В заключение этой главы я хочу представить читателю десять «вопросов и возможных ответов», касающихся ИИ. Я не осмелился бы назвать их «ответами» — это всего лишь мои собственные мнения. Они могут меняться по мере того, как я узнаю больше об ИИ и эта область исследований продолжает развиваться. (Я буду употреблять здесь слова «программа» и «компьютер», несмотря на то, что они вызывают сильные механистичекие ассоциации. Однако в нижеследующем тексте фраза «программа ИИ» означает программу, намного опередившую сегодняшние, — то есть по-настоящему разумную программу.)
Вопрос: Будет ли компьютер когда-нибудь сочинять прекрасную музыку?
Возможный ответ: Да, но не скоро. Музыка — это язык эмоций, и до тех пор, пока компьютеры не испытают сложных эмоций, подобных человеческим, они не смогут создать ничего прекрасного. Они смогут создавать «подделки» — поверхностные формальные имитации чужой музыки. Однако несмотря на то, что можно подумать априори, музыка — это нечто большее, чем набор синтаксических правил. Программы-композиторы еще долго не смогут дать новых образцов музыкального искусства. Позвольте мне развить эту мысль. Я слышал мнение, что вскоре мы сможем управлять препрограммированной дешевой машинкой массового производства, которая, стоя у нас на столе, будет выдавать из своих стерильных внутренностей произведения, которые могли бы быть написаны Шопеном или Бахом, живи они подольше. Я считаю, что это гротескная и бессовестная недооценка глубины человеческого разума. «Программа», способная сочинять подобную музыку, должна будет самостоятельно бродить по свету, находя дорогу в лабиринте жизни и чувствуя каждое ее мгновение. Она должна будет испытать радость и одиночество леденящего ночного ветра, тоску по дорогой руке, недостижимость далекого города, горечь утраты после смерти близкого существа. Она должна будет познать смирение и усталость от жизни, отчаяние и пустоту, решимость и счастье победы, трепет благоговейного восторга. В ней должны будут сочетаться такие противоположности, как надежда и страх, боль и торжество, покой и тревога. Неотъемлемой ее частью должно быть чувство красоты, юмора, ритма, чувство неожиданного — и, разумеется, острое осознание магии творческого акта. В этом и только в этом — источник музыкального смысла.
Вопрос: Будут ли чувства запрограммированы явно?
Возможный ответ: Нет. Это было бы смешно. Никакая прямая симуляция эмоций — например, ПАРРИ — не сможет приблизиться к сложности человеческих переживаний, которые косвенно вызваны организацией нашего мозга. Программы или машины разовьют чувства таким же образом, как побочный продукт их структуры и организации, а не путем прямого программирования. Так, никто не напишет подпрограммы «влюбленности», так же как никто не напишет подпрограммы «совершения ошибок.» «Влюбленность» — это описание сложного процесса сложной системы; совсем не обязательно, чтобы в системе был некий отдельный модуль, отвечающий за это состояние.
Вопрос: Сможет ли думающий компьютер быстро вычислять?
Возможный ответ: Может быть, нет. Мы сами состоим из аппаратуры, которая проделывает сложные вычисления, но это не означает, что на уровне символов, там, где находимся «мы», нам известно, как делать те же самые вычисления. Иными словами, нам не удастся загрузить числа в собственные нейроны с тем, чтобы подсчитать, сколько мы должны в бакалейной лавке. К счастью для нас, уровень символов (то есть, мы сами) не имеет доступа к нейронам, ответственным за мышление, — иначе мы потеряли бы голову. Перефразируя Декарта еще раз,
«Я мыслю; следовательно, у меня нет доступа к уровню, на котором я суммирую.»
Скорее всего, в случае разумной программы ситуация будет аналогична. Программа не должна иметь доступа к цепям, где происходит процесс мышления, — иначе она потеряет ЦП. Говоря серьезно, я думаю, что машина, которая сможет пройти тест Тюринга, будет вычислять так же медленно, как и мы с вами, и по той же причине. Она будет представлять число «два» не как два бита «10», а как некое понятие так же, как это делают люди, — понятие, нагруженное такими ассоциациями, как слова «пара» и «двойка», понятия четности и нечетности, форма числа «2» и так далее. С подобным дополнительным багажом думающая программа станет складывать довольно медленно. Разумеется, мы могли бы снабдить ее, так сказать, «карманным калькулятором» (или встроить его в сам компьютер). Тогда она вычисляла бы очень быстро, но делала бы это точно так же, как человек с калькулятором. В машине было бы две части, надежная, но безмозглая часть и разумная, но ошибающаяся часть. Надеяться на безошибочное действие такой составной системы можно было бы не более, чем на систему, состоящую из машины и человека. Так что, если вам нужны правильные ответы, лучше пользуйтесь исключительно калькулятором и не добавляйте к нему разум!
Вопрос: Будут ли такие шахматные программы, которые смогут выиграть у кого угодно?
Возможный ответ: Нет. Могут быть созданы программы, которые смогут обыгрывать кого угодно, но они не будут исключительно шахматными программами. Они будут программами общего разума и, так же как люди, они будут обладать характером. «Хотите сыграть партию в шахматы?» — «Нет, шахматы мне уже надоели. Лучше давайте поговорим о поэзии…» Приблизительно такой разговор вы сможете иметь с программой, которая будет способна выиграть у кого угодно. Дело в том, что настоящий разум непременно основан на возможности общего обзора — так сказать, запрограммированной способности «выходить из системы» по крайней мере в том объеме, в каком мы сами обладаем такой способностью. С возникновением этой способности вы теряете контроль над программой — она переступает некий порог, и вам остается только расхлебывать заваренную вами кашу.
Вопрос: Будут ли в памяти программы некие места, где будут храниться параметры, управляющие поведением программы, так что, если бы вы забрались внутрь программы и поменяли их, программа стала бы умнее или глупее, более творческой или более заинтересованной в футболе? Короче, сможете ли вы «настраивать» программу, «подкручивая ее ручки» на относительно низком уровне?
Возможный ответ: Нет. Программа будет почти безразлична к изменениям любого данного элемента памяти, так же, как не меняемся и мы, несмотря на то, что тысячи нейронов нашего мозга ежедневно умирают. (!) Однако, если вы зайдете слишком далеко в вашей возне с программой, вы можете ее сломать, точно так же, как если бы вы небрежно провели нейрохирургию человеческого существа. В программе не будет никакого «магического» места, где будет расположен, скажем, ее коэффициент умственного развития. Это будет одной из черт, возникающей на основе низших уровней, и локализовать ее будет невозможно. То же самое верно и в отношении «количества объектов, которое программа может удержать в своей кратковременной памяти», «ее любви к физике» и так далее, и тому подобное.
Вопрос: Можно ли «настроить» какую-нибудь разумную программу так, чтобы она действовала, как я или как вы — или как нечто среднее между нами?
Возможный ответ: Нет. Разумная программа будет так же мало походить на хамелеона, как и человек. Она будет опираться на постоянство своей памяти и не сможет произвольно менять характер. Идея изменения внутренних параметров с тем, чтобы «настроиться на новую индивидуальность» указывает на смехотворную недооценку сложности личности.
Вопрос: Будет ли у разумной программы «сердце», или же она будет состоять их «бессмысленных циклов и последовательностей тривиальных операций» (выражаясь словами Марвина Мински)?
Возможный ответ: Если бы мы могли увидеть всю программу насквозь, как видим дно мелкого пруда, мы наверняка увидели бы только «бессмысленные циклы и последовательности тривиальных операций» — и никакого «сердца». Существует два крайних взгляда на ИИ: один из них утверждает, что человеческий разум по неким фундаментальным и мистическим причинам запрограммировать невозможно. Другой говорит, что стоит только собрать нужные «эвристические инструменты — множественные оптиматизаторы, способы узнавания регулярностей, планирующие алгебры, рекурсивные процедуры управления и так далее», и у нас будет разумная программа. Я нахожусь где-то посредине: мне кажется, что «пруд» ИИ окажется так глубок и мутен, что нам не удастся увидеть его дна. При взгляде с вершины циклы будут незаметны, так же, как на сегодняшний день электроны, переносящие ток, незаметны большинству программистов. Когда будет создана программа, выдержавшая тест Тюринга, мы увидим в ней «сердце», хотя и будем знать, что его там нет.
Вопрос: Будут ли когда-нибудь созданы «сверх-разумные» программы ИИ?
Возможный ответ Не знаю. Непонятно, сумеем ли мы понять «сверх-разум» или общаться с ним и есть ли вообще какой-нибудь смысл у этого понятия. Например, наш собственный разум связан со скоростью нашего мышления. Если бы наши рефлексы были в десять раз быстрее или медленнее, у нас могли бы развиться совершенно иные понятия о мире. У создания с радикально иным представлением о мире может просто не оказаться с нами многих точек соприкосновения. Я часто спрашиваю себя, могут ли существовать музыкальные произведения, являющиеся по отношению к Баху тем, чем Бах является по отношению к фольклорным мелодиям — так сказать, «Бах в квадрате». Смог бы я понять подобную музыку? Может быть, вокруг меня уже есть подобная музыка, но я просто ее не узнаю, точно так же, как собаки не понимают языка. Идея сверх-разума очень странна. Так или иначе, я не считаю это сегодняшней целью исследований в области ИИ (хотя, если мы когда-нибудь достигнем уровня человеческого разума, сверх-разум, несомненно, станет следующей задачей — и не только для нас, но и для наших искусственных коллег, которые будут так же, как и мы заинтересованы в проблемах ИИ и сверх-разума). Вероятно, что программы ИИ будут интересоваться общими проблемами ИИ — и это вполне понятно.
Вопрос: Вы, кажется, утверждаете, что программы ИИ будут практически неотличимы от людей. Будет ли между ними какая-нибудь разница?
Возможный ответ: Скорее всего, разница между программами ИИ и людьми будет больше, чем разница между большинством людей. Почти невозможно вообразить, что «тело», в котором будет расположена такая программа, не окажет на нее сильнейшего влияния. Так что, если только она не будет расположена в превосходной имитации человеческого тела, — а это вовсе не обязательно! — у нее, скорее всего, будут совершенно иные понятия о том, что важно, интересно и так далее. Витгенштейн однажды сделал следующее забавное замечание: «Если бы лев заговорил, мы бы его не поняли». Эта мысль напоминает мне о картине Руссо, где в залитой лунным светом пустыне изображены мирный лев и спящая цыганка. Но откуда Витгенштейн это знает? Мне кажется, что любая думающая программа ИИ, даже если мы и сможем с ней разговаривать, будет казаться нам весьма чуждой. Поэтому нам будет очень трудно понять, действительно ли перед нами разумная программа, или просто некая программа «с завихрениями».
Вопрос: Поймем ли мы, благодаря созданию разумных программ что такое интеллект, сознание, свободная воля и «Я»?
Возможный ответ: Возможно — но все зависит от того, что вы имеете в виду под словом «понимать». На интуитивном уровне, каждый из нас уже сейчас понимает все эти понятия настолько хорошо, как только возможно. Это подобно слушанию музыки. Улучшилось ли ваше понимание Баха от того, что вы проанализировали его вдоль и поперек? Или же вы лучше понимали его тогда, когда каждый нерв вашего тела трепетал от восторга? Понимаем ли мы, каким образом скорость света постоянна в любой инерционной системе отсчета? Мы можем проделать все расчеты, но ни у кого в мире нет настоящего интуитивного понимания теории относительности. Возможно, что никто никогда не поймет полностью на интуитивном уровне загадки интеллекта и сознания. Каждый из нас может понимать отдельных людей, и, скорее всего, это максимум того, на что мы способны.
Назад: Контрафактус
Дальше: Канон Ленивца

