ГЛАВА XVIII: Искусственный интеллект: взгляд в прошлое
Тюринг
В 1950 ГОДУ АЛАН ТЮРИНГ написал дерзкую и пророческую статью об искусственном интеллекте. Она называлась «Вычислительные машины и интеллект» и была опубликована в журнале «Mind». Прежде чем говорить об этой статье, я хочу рассказать кое-что о самом Тюринге.

Рис. 113. Алан Матисон Тюринг.
Алан Матисон Тюринг родился в Лондоне в 1912 году. Он рос любопытным и веселым ребенком. У него оказались незаурядные способности к математике, и позже Алан поступил в Кембриджский университет, где его интересы в области техники и математической логики скрестились. Результатом этого плодотворного скрещивания была его знаменитая статья о «вычислимых числах» в которой он изобрел теорию машин Тюринга и показал неразрешимость проблемы остановки. Эта статья была опубликована в 1937 году. В 1940-х годах интересы Тюринга перешли от теории вычислительных машин к созданию настоящих компьютеров. Он был одним из пионеров компьютерной техники в Англии и стал ярым защитником искусственного интеллекта, когда тот впервые подвергся нападкам. Среди его единомышленников и ближайших друзей был Дэвид Чемперноун (который позже стал работать над созданием музыкальных композиций при помощи компьютеров). Друзья были страстными шахматистами и придумали новый вариант этой игры, под названием «шахматы вокруг дома»: сделав ход, игрок должен обежать вокруг дома; если он вернется обратно до того, как его противник сделает ответный ход, он получает право пойти еще раз. В более серьезном плане, Тюринг и Чемперноун изобрели первую шахматную программу под названием «Тюрочем». Тюринг умер молодым, в возрасте 41 года — по-видимому, из-за несчастного случая с химикатами (есть мнение, что он покончил самоубийством). Его мать, Сара Тюринг, написала его биографию. Из приводимых ею отзывов о Тюринге складывается впечатление, что он был личностью весьма нестандартной и не умел вести себя в обществе; при этом он был честен, порядочен и легко уязвим. Он любил игры, шахматы, детей; катался на велосипеде и был хорошим бегуном на дальние дистанции. Во время учебы в Кембридже он купил себе подержанную скрипку и научился на ней играть. Хотя Алан не был особенно музыкален, он получал от игры большое удовольствие. Он был несколько эксцентричен и часто страстно увлекался самыми неожиданными вещами. Одним из его интересов являлся морфогенез в биологии. Согласно его матери, Тюринг «очень любил „Записки Пиквикского клуба“», но «поэзия, за исключением Шекспира, оставляла его совершенно равнодушным». Алан Тюринг был одним из основоположников компьютерного дела.
Тест Тюринга
Статья Тюринга начинается с фразы: «Рассмотрим вопрос: „Может ли машина думать?“» Поскольку, как он указывает, эти термины слишком многозначны, очевидно, что мы должны искать практическое решение проблемы. Для этого Тюринг предлагает игру, которую он называет «игрой в имитацию»; сегодня она известна под названием «тест Тюринга». Тюринг объясняет ее так:
Играют три человека: мужчина (А), женщина (Б) и ведущий (В), который может быть любого пола. Ведущий закрывается в отдельной комнате. Он должен, задавая вопросы, определить по ответам, кто из двух игроков — мужчина и кто — женщина. Он знает игроков только под именами X и Y; в конце игры он должен сказать либо «X — это A, a Y — это Б», либо «X — это Б, a Y — это А». Ведущий может задавать любые вопросы, например: В: X, скажите мне, пожалуйста, какой длины ваши волосы? Предположим, что под псевдонимом X скрывается А; тогда А должен отвечать. Его цель — стараться сбить ведущего с толку, чтобы тот дал неправильное определение. Поэтому он может ответить, например, так: «Мои волосы пострижены ступеньками, и самые длинные прядки — около 25 сантиметров.» Чтобы голос не выдал отвечающих, их ответы должны быть написаны или, еще лучше, напечатаны. Идеальным было бы установить сообщение между комнатами при помощи телепринтера. Вместо этого для передачи вопросов и ответов можно также использовать посредника. Цель игрока Б — помогать ведущему; лучшей стратегией для этого, возможно, являются правдивые ответы. Она может добавлять замечания вроде: «Женщина — это я; не слушайте его!» — но они мало чем помогут, поскольку мужчина может сказать тоже самое. Теперь мы спросим: «А что, если вместо А в этой игре будет участвовать машина?» Будет ли ведущий ошибаться так же часто, как и в игре, где участниками были мужчина и женщина? Эти вопросы заменяют наш первоначальный вопрос: «Могут ли машины думать?»
Разъяснив, в чем состоит его тест, Тюринг приводит по его поводу несколько замечаний, для того времени весьма тонких. Сначала он дает пример короткого диалога между спрашивающим и отвечающим:
С: Напишите мне, пожалуйста, сонет, на тему «мост в Форте» (через залив Ферт-оф-Форт в Шотландии).О: В этом на меня не рассчитывайте я никогда не был силен в поэзии.С: Сложите 34 957 и 70 764.О (После примерно полминутной паузы): 105 621.С: Вы играете в шахматы?О: Да.С: Мой король стоит на e1, других фигур у меня нет. Ваш король — на еЗ и ладья — на а8. Как вы пойдете?О: (Помедлив 15 секунд) Поставлю вам мат в один ход Ла1Х.
Мало кто из читателей замечает, что в арифметической задаче не только время раздумья слишком длинно, но и сам ответ ошибочен! Это было бы легко объяснить, если бы отвечающий был человеком — человеку свойственно ошибаться. Если же отвечала машина, то этому возможны разные объяснения, например:
(1) ошибка на уровне аппаратуры во время прогона программы (случайная и невоспроизводимая осечка),
(2) непреднамеренная ошибка на уровне аппаратуры или программы, результатом которой являются воспроизводимые арифметические ошибки,
(3) уловка, специально введенная в программу машины ее создателем для того, чтобы машина иногда ошибалась и, таким образом, могла бы одурачить спрашивающего,
(4) неожиданный эпифеномен — программа испытывает трудности с абстрактным мышлением и просто ошиблась, в следующий раз она, возможно, посчитает то же самое правильно,
(5) шутка самой машины, которая таким образом старается сбить спрашивающего с толку.
Размышления о том, что мог здесь иметь в виду сам Тюринг, затрагивают почти все основные философские проблемы искусственного интеллекта. Тюринг продолжает, указывая, что:
Эта новая проблема имеет то преимущество, что она проводит довольно четкую границу между физическими и интеллектуальными способностями человека. Мы не хотим наказывать ни машину за то, что она не способна отличиться на конкурсе красоты, ни человека за то, что он не способен соревноваться в скорости с аэропланом.
Интересно заметить, как глубоко Тюринг развивает каждую мысль, при этом на определенном этапе его рассуждений обычно появляется кажущееся противоречие, которое он впоследствии разрешает на более глубоком уровне анализа, уточняя свои понятия. Именно из-за этого проникновения в суть вопросов его статья все еще актуальна, даже по прошествии тридцати лет громадного прогресса в области компьютерной техники и искусственного интеллекта. На примере следующего отрывка читатель может увидеть, насколько глубок и разносторонен анализ Тюринга:
Эту игру возможно раскритиковать на том основании, что она несправедлива по отношению к машине, которой здесь дается очень мало возможностей. Если бы человеку пришлось притворяться машиной, ясно, что он не смог бы выполнить эту задачу удовлетворительно. Его тут же выдала бы медлительность и ошибки в арифметических подсчетах. Могут ли машины делать нечто, что может быть названо мышлением, но что, тем не менее весьма отличается от того, что делает человек? Это очень веское возражение, но, по крайней мере, мы можем сказать, что если бы удалось создать машину, удовлетворительно играющую в эту имитационную игру, то нам не пришлось бы волноваться по этому поводу.Можно сказать, что лучшей стратегией машины в «имитационной игре» было бы нечто иное, чем подражание человеческому поведению. Возможно; но это кажется мне маловероятным. Так или иначе, я не собираюсь здесь анализировать теорию этой игры; я предполагаю, что лучшая стратегия — это давать ответы, которые обычно дал бы человек.
Предложив и описав свой тест, Тюринг замечает:
Я считаю, что первоначальный вопрос — могут ли машины думать — бессмысленный и не заслуживает обсуждения. Тем не менее я верю, что к концу столетия использование слов и общий настрой умов настолько изменятся, что станет возможно говорить о мышлении машин, не ожидая немедленных возражений.
Тюринг предвидит возражения
Предвидя, что его статья вызовет бурю протестов, Тюринг начинает один за другим точно и иронично парировать возможные возражения на идею о том, что машина способна мыслить. Ниже я привожу девять типов возражений в собственной формулировке Тюринга, на которые он затем отвечает. К сожалению, у нас нет возможности воспроизвести здесь остроумные и изобретательные ответы Тюринга. Читатель может позабавиться, обдумав эти возражения и попытавшись дать на них свои собственные ответы.
(1) Теологическое возражение. Мышление — функция бессмертной души человека. Бог вложил бессмертную душу во всех мужчин и женщин, но не в других животных и не в машины. Следовательно, животные и машины не способны мыслить.
(2) Возражение «Голова в песке». Последствия машинного мышления были бы слишком ужасны. Давайте же надеяться и считать, что машины на это не способны.
(3) Математическое возражение. (Это, в основном, аргумент Лукаса).
(4) Возражение с точки зрения сознания. До тех пор, пока машина не напишет сонета или концерта, основываясь на эмоциях, а не на случайном расположении символов, мы не согласимся с тем, что она может равняться мозгу. При этом машина должна не только быть способной написать эти произведения, но и осознать тот факт, что она их написала. «Ни одна машина не может на самом деле чувствовать (а не только искусственно указывать на соответствующее чувство, чего легко добиться) радости от ее успехов, печали, когда ее электронные лампы перегорают; она не может испытывать удовольствия от лести, расстраиваться из-за своих ошибок, чувствовать сексуальное влечение, сердиться или впадать в депрессию, когда не может получить желаемого.» (Цитата из работы некоего профессора Джефферсона.)
Тюринг озабочен тем, чтобы ответить на эти серьезные возражения возможно подробнее. Поэтому он уделяет этому довольно много места; частью его ответа является следующий гипотетический диалог:
Спрашивающий: В первой строке вашего сонета «Сравню ли с летним днем твои черты», не лучше ли было бы написать «с весенним днем»?Собеседник: Это не укладывается в размер.Спрашивающий: Тогда как насчет «зимнего дня»? С размером здесь все в порядке.Собеседник: Да, но кому нравится, чтобы его сравнивали с зимним днем!Спрашивающий: Скажите, м-р Пиквик не напоминает вам о рождестве?Собеседник: В каком-то смысле.Спрашивающий: А ведь рождество — это зимний день; однако я не думаю, что м-р Пиквик обиделся бы на такое сравнение.Собеседник: Не может быть, чтобы вы говорили серьезно. Под зимним днем обычно подразумевается типичный зимний день, а не какой-то особый день вроде рождества.
После этого диалога Тюринг спрашивает: «Что сказал бы профессор Джефферсон, если бы машина, пишущая сонеты, была бы способна отвечать ему таким образом in viva voce?»
Другие возражения:
(5) Аргументы различных неспособностей. Эти аргументы имеют следующую форму: «Предположим, что вы можете заставить машины проделывать все то, о чем вы говорите — но ни одна машина никогда не сможет сделать X». В этой связи предлагались самые разные X, как например: быть доброй, изобретательной, красивой, дружелюбной, инициативной, иметь чувство юмора, отличать хорошее от плохого, делать ошибки, влюбляться, получать удовольствие от клубники со сливками, влюбить в себя кого-нибудь, учиться на опыте, правильно использовать слова, заниматься самоанализом, вести себя так же разнообразно, как люди, сделать нечто действительно новое.
(6) Возражение леди Лавлэйс. Полнее всего об аналитической машине Баббиджа мы знаем из мемуаров леди Лавлэйс. Она пишет: «Аналитическая машина не претендует на создание чего-либо нового. Она может делать только то, что мы умеем ей приказать.».
(7) Аргумент непрерывности нервной системы. Нервная система, безусловно, не является машиной, работающей с перерывами. Небольшая ошибка в информации о размере нервного импульса, воздействующего на нейрон, может означать огромную разницу в размере выходящего импульса. Можно сказать, что такое положение вещей делает невозможным имитацию поведения нервной системы при помощи дискретной системы.
(8) Аргумент неформального поведения. «Если бы каждый человек руководствовался в своей жизни набором неких установленных правил, он был бы не лучше машины. Но поскольку таких правил не существует, люди не могут быть машинами.»
(9) Аргумент экстрасенсорного восприятия. Давайте представим себе имитационную игру, в которой участвуют человек, обладающий телепатическими способностями, и компьютер. Ведущий может задавать такие вопросы как «Какой масти карта в моей правой руке?». Человек, используя телепатию или ясновидение, дает 130 верных ответов из 400. Машина может только гадать и, скорее всего, даст около 104 правильных ответов, так что ведущий сможет без труда определить, кто есть кто.
Как видите, многие возражения связаны друг с другом и частично совпадают. В этой книге я попытался так или иначе ответить на каждое из них, хотя и менее четко, чем это сделал Тюринг. Возражение (9) кажется мне удивительным. Я видел эту статью Тюринга, перепечатанную в книге — но там возражение (9) опущено, что мне кажется не менее удивительным. Лично я, в отличие от Тюринга, считаю, что экстрасенсорных способностей (ЭСС) не существует. Тюрингу пришлось согласиться с идеей ЭСС, поскольку его выдающаяся научная честность заставила его принять последствия того, что казалось ему мощной статистической очевидностью в пользу этой идеи. Я с этим не согласен, но, тем не менее, считаю это необыкновенно интересным и сложным вопросом.
«Парри встречается с Доктором»
В предыдущем Диалоге вы прочли запись подлинной беседы между компьютерной программой и человеком. Существует множество программ с меньшей, чем у ШРДЛУ, способностью к «беседе». Две довольно известные программы такого рода — это «Доктор» (создание Иосифа Вайценбаума) и «Парри» (детище Кеннета Колби). Первая была призвана имитировать психиатра, используя «недирективную» терапию, в то время как вторая должна была изображать типичного параноика. Однажды по компьютерной сети была устроена забавная встреча этих двух программ; ниже приводится отрывок из их «беседы»:
Парри: Я не понимаю ваших мотивов.
Доктор: Почему вы не понимаете моих мотивов?
Парри: Не должен ли я быть таким?
Доктор: Почему вы сейчас это сказали?
Парри: Это именно так и есть.
Доктор: А вы представьте себе, что это именно не так.
Парри. Ну и что?
Доктор. Я не уверен, что вполне вас понимаю.
Парри: Вы слишком привязываетесь к одним тем же вопросам.
Доктор: О чем говорит вам это сходство?
Парри: Я вас не понимаю.
Доктор: Вы хотели бы понимать я?
Парри: Хорошо бы, чтобы вы начали проявлять интерес к моим чувствам.
Доктор: Что? Я начал проявлять интерес к вашим чувствам?
Разумеется, эти программы были созданы для разговоров с людьми; поэтому, разговаривая друг с другом, они показывают себя не с лучшей стороны. В основном они опираются на ловкие догадки в отношении вводных данных (анализируя их довольно поверхностно) и выдают готовые ответы, тщательно выбранные из обширного репертуара. Ответ может быть готовым только частично: например, может использоваться некая схема, в которой заполняются пробелы. При этом имеется в виду, что собеседник-человек будет придавать ответам гораздо больше смысла, чем в них есть на самом деле. В действительности, согласно тому, что Вайнценбаум утверждает в своей книге «Мощь компьютеров и человеческий разум» (Weizenbaum, «Computer Power and Human Reason»), именно так и происходит. Он пишет:
ЭЛИЗА (программа, на основе которой был разработан Доктор) создавала удивительную иллюзию проникновения в мысли многих людей, которые с ней разговаривали… Они часто просили позволения побеседовать с системой наедине, после чего говорили, несмотря на мои объяснения, что машина их по-настоящему поняла.
После прочтения предыдущего «разговора» читатель может подумать, что это невероятно. Может быть — но это чистая правда! Вайценбаум объясняет:
Большинство людей совершенно ничего не понимают в компьютерах. Поэтому, если только они не способны на значительную долю скептицизма (того скептицизма с которым мы наблюдаем за действиями фокусника), они могут объяснить интеллектуальные достижения компьютера только путем единственной доступной им аналогии — то есть модели их собственного мышления. Таким образом не удивительно, что они преувеличивают почти невозможно вообразить человека, который мог бы имитировать ЭЛИЗУ, но для которого при этом ее языковые способности являлись бы пределом.
Это равносильно признанию того, что подобные программы являются остроумной смесью бравады и блефа и их успех основан на людской доверчивости.
В свете странного «эффекта ЭЛИЗЫ» многие предлагали пересмотреть тест Тюринга, поскольку, по-видимому людей легко одурачить простенькими уловками. Было предложено, чтобы ведущим был лауреат Нобелевской премии. Возможно, было бы целесообразнее перевернуть тест с ног на голову и сделать так, чтобы вопросы задавал компьютер. Или может быть, вопросы должны задавать двое — человек и компьютер, а отвечать — кто-то один, и спрашивающие должны догадаться компьютер это или человек.
Говоря серьезно, я считаю, что тест Тюринга в его первоначальной форме вполне приемлем. Что касается людей которые, по словам Вайзенбаума были одурачены ЭЛИЗОЙ, то их никто не предупреждал быть более скептическими, стараясь угадать, является ли «персона» печатающая ответы, человеком. Мне кажется что Тюринг верно понимал ситуацию и его тест выживет в практически неизмененной форме.
Краткая история ИИ
На следующих страницах я хочу представить, возможно, с несколько неортодоксальной точки зрения историю усилий, направленных на открытие алгоритмов разума, в этой истории были и будут провалы и неудачи. Тем не менее, мы узнаем очень многое и переживаем захватывающий период в развитии ИИ.
Со времен Паскаля и Лейбница люди мечтали о машинах, способных выполнять интеллектуальные задания. В девятнадцатом веке Буль и Де Морган разработали «законы мысли», по существу являвшиеся Исчислением Высказываний и, таким образом, сделали первый шаг по пути создания программ ИИ, тогда же Чарльз Баббидж сконструировал первую «вычисляющую машину» — предшественницу компьютерной аппаратуры и, следовательно, ИИ. Можно сказать, что ИИ зарождается в тот момент, когда машины начинают выполнять задания ранее доступные только человеческому уму. Трудно вообразить чувства людей впервые увидевших, как зубчатые колеса складывают и перемножают многозначные числа. Возможно, они испытали благоговейный трепет, увидев реальное физическое воплощение течения «мысли». Так или иначе мы знаем, что почти сто лет спустя, когда были построены первые электронно-вычислительные машины, их создатели почувствовали почти мистическое благоговение в присутствии иного типа «мыслящего существа». До какой степени эти машины действительно мыслили, было неясно даже теперь, несколько десятилетий спустя этот вопрос продолжает широко обсуждаться.
Интересно то, что на сегодняшний день практически никто уже не испытывает никакого благоговения перед компьютерами, даже тогда, когда они выполняют неизмеримо более сложные операции чем те которые когда-то заставляли зрителей трепетать от восторга. Когда-то волнующая фраза «Блестящие Электронные Головы» теперь звучит устаревшим клише, смешным отголоском эпохи знаменитых героев фантастических повестей, Флаша Гордона и Бака Роджерса. Немного печально, что мы так быстро теряем способность удивляться.
По этому поводу существует «Теорема» о прогрессе в области ИИ: как только какая-нибудь функция мышления оказывается запрограммирована, люди тут же перестают считать ее ингредиентом «настоящего мышления». Неизбежный центр интеллекта всегда оказывается в том, что еще не запрограммировано. Я впервые услышал эту «Теорему» от Ларри Теслера, поэтому я называю ее Теоремой Теслера: «ИИ — это то, что еще не сделано.»
Ниже приводится выборочный обзор ИИ. Он показывает несколько областей, на которых было сконцентрировано внимание; каждая из них по-своему применяет квинтэссенцию интеллекта. Некоторые из этих областей подразделены в соответствии с используемыми методами или более специфическими сферами исследования.
машинный перевод
прямой (обращение к словарю плюс некоторая перестановка слов), косвенный (с помощью некоего внутреннего языка-посредника)
игры
шахматы
механический просчет всех вариантов, выборочный просчет вариантов, без просчета вариантов.
шашки, го, калах, бридж (ставки и игра), покер, варианты крестиков-ноликов и т. д.
доказательство теорем в разных областях математики
символическая логика, доказательство теорем путем «разложения», элементарная геометрия.
символическая манипуляция математическими выражениями
символическое интегрирование, алгебраическое упрощение, сложение бесконечных рядов.
зрение
печатные тексты
узнавание отдельных написанных от руки печатных символов определенного класса (например, чисел), прочтение одного и того же текста, напечатанного разными шрифтами, прочтение рукописных текстов, прочтение китайских или японских иероглифов, прочтение китайских или японских иероглифов, написанных от руки.
картины
нахождение определенных объектов на фотографиях, разложение сцен на отдельные объекты, определение отдельных объектов на картине, узнавание сделанных людьми набросков предметов, узнавание человеческих лиц.
слух
понимание со слуха ограниченного количества слов (например, названии цифр), понимание потока речи (на определенную тему), нахождение границ между фонемами, узнавание фонем, нахождение границ между морфемами, узнавание морфем, составление слов и предложений.
понимание естественных языков
ответ на вопросы в определенных областях, анализ сложных предложений, перифраз длинных отрывков текста, использование знаний о мире для понимания текстов, понимание неоднозначных выражений.
активное использование естественных языков
абстрактная поэзия (например, хайку), отдельные предложения, абзацы, или более длинные отрывки текста, производство выхода на основе внутреннего отображения знаний.
создание оригинальных мыслей или произведений искусства
написание стихоторений (хайку), написание прозы, написание картин, музыкальная композиция, атональная, тональная.
аналогическое мышление
геометрические формы («интеллектуальные тесты»), нахождение доказательств в какой-либо области математики, основанных на доказательствах в родственной области.
обучение
регулирование параметров, формирование понятий.
Машинный перевод
Многие из этих сфер исследования не будут затронуты в нашем обсуждении, но без них список был бы неполным. Несколько первых тем приводятся в хронологическом порядке. Ни в одной из этих областей ранние усилия не привели к желаемым результатам. Так, неудачи в машинном переводе явились неожиданностью для тех, кто считал, что машинный перевод — простая задача, и что, хотя совершенствование машинного перевода может потребовать немалого труда, принципиальное решение этого вопроса несложно. Однако оказалось, что перевод — это нечто гораздо более сложное, чем простое использование словаря и перестановка слов. Незнание идиоматических выражений также не является основной трудностью. Дело в том, что перевод подразумевает наличие мысленной модели обсуждаемого мира и манипуляцию символами этой модели. Программа, которая не имеет подобной модели, вскоре безнадежно запутается в неточностях и многозначных выражениях текста. Даже люди, имеющие огромное преимущество перед компьютерами, поскольку они уже «оснащены» пониманием мира, находят почти невозможным перевести с помощью словаря кусок текста с неизвестного им языка на их родной язык. Таким образом — и это не удивительно — первая же проблема ИИ немедленно приводит к вопросам, затрагивающим самую суть ИИ.
Компьютерные шахматы
Компьютерные шахматы оказались также намного труднее, чем интуитивно предполагалось в начале. Оказывается, шахматная ситуация в голове у людей представлена гораздо сложнее, чем просто расположение отдельных фигур на определенных клетках доски и знание правил игры. Это представление включает восприятие групп взаимодействующих фигур как одно целое, а также знание эвристики, или эмпирических правил, принадлежащих к подобным блокам высшего уровня. Хотя эвристические правила не являются строгими в том смысле как официальные правила игры, они, в отличие от последних, позволяют быстро оценить то, что происходит на доске. Это было ясно с самого начала, но исследователи недооценили то, какую важную роль это интуитивное блочное восприятие шахматного мира играет в шахматных способностях людей. Считалось, что программа, оснащенная некой основной эвристикой, в сочетании с огромной скоростью и аккуратностью компьютера в просчете вариантов и анализе каждого возможного хода, будет легко выигрывать у игроков высшего класса. Однако этот прогноз все еще далек от исполнения даже после двадцати пяти лет интенсивной работы множества специалистов.
На сегодняшний день люди подходят к шахматной проблеме по-разному. Одна из новейших точек зрения включает гипотезу о том, что просчет вариантов — глупое занятие. Вместо этого предлагается оценить позицию, стоящую на доске в данный момент, и, пользуясь эвристикой, составить некий план — а затем найти ход, способствующий выполнению этого плана. Безусловно, правила для составления планов неизбежно будут включать эвристику, которая является чем-то вроде упрощенного просчета вариантов. Иными словами, опыт анализа вариантов многих сыгранных ранее партий здесь «сжат» в новую форму, при поверхностном рассмотрении не требующую подобного анализа. Кажется, что это не более, чем игра слов. Однако если такое «сокращенное» знание дает нам более эффективные ответы, чем действительный просчет вариантов (даже если при этом иногда случаются ошибки), то мы уже кое-что выигрываем. Именно этим превращением знаний в более эффективно используемые формы и отличается разум — так что меньше-анализирующие-варианты-шахматы, возможно, являются плодотворной идеей. Особенно интересно было бы создать программу, способную превращать знания, полученные путем анализа возможных вариантов, в «сокращенные» правила; но это — огромный труд.
Шашечная программа Самуэля
Именно такой метод был разработан Артуром Самуэлем в его замечательной шашечной программе. Метод Самуэля состоял в одновременном использовании динамического (с заглядыванием вперед) и статического (без заглядывания вперед) способов оценки любой данной позиции. Статический метод основывался на простой математической функции нескольких величин, характеризующих любую позицию на доске; это вычислялось практически мгновенно. В свою очередь, динамический метод основывался на создании «дерева» возможных будущих ходов, ответов на них, ответов на ответы и так далее (как было показано на рис. 38). Некоторые параметры в функции статической оценки могли варьироваться, в результате чего получались разные версии этой функции. Стратегия Самуэля заключалась в том, чтобы путем естественного отбора находить все лучшие и лучшие значения этих параметров.
Это делалось следующим образом: каждый раз, когда программа оценивала позицию, она делала это одновременно статистически и динамически. Ответ, полученный путем анализа вариантов, — назовем его Д — использовался для нахождения следующего хода. Цель С — статистической оценки — была сложнее: после каждого хода переменные параметры немного исправлялись таким образом, чтобы С возможно больше приближалось к Д. В результате знание, полученное путем динамического анализа дерева, частично включалось в параметры статистической оценки. Короче, идея заключалась в том, чтобы постепенно превратить сложный динамический метод в гораздо более простую и эффективную функцию статической оценки.
Здесь возникает изящный рекурсивный эффект. Дело в том, что динамическая оценка любой данной позиции включает просчет вперед на конечное число ходов — скажем, семь. При этом промежуточные позиции, получающиеся после каждого возможного хода, также должны получить какую-то оценку. Но когда программа оценивает эти позиции, она, разумеется, уже не может просчитывать на семь ходов вперед — иначе ей пришлось бы анализировать четырнадцать возможных позиций, затем двадцать одну и так далее, и тому подобное — что породило бы бесконечный регресс. Вместо этого программа пользуется статическими оценками позиций, возникающих при анализе. Таким образом, схема Самуэля включает сложную обратную связь, в процессе которой программа непрерывно пытается превратить оценки, основанные на просчете вариантов, в более простой статический подход; этот подход в свою очередь играет ключевую роль в динамическом взгляде вперед. Таким образом, оба этих метода тесно связаны между собой, и каждый рекурсивным путем извлекает пользу из улучшений в другом методе.
Уровень игры шашечной программы Самуэля крайне высок и сравним с уровнем лучших человеческих игроков мира. Если это так, то почему бы не приложить ту же идею к шахматам? Международный комитет, собравшийся в 1961 году, чтобы обсудить возможность компьютерных шахмат, и включавший датского международного гроссмейстера и математика Макса Эйве, пришел к печальному заключению, что использование метода Самуэля в шахматах было бы примерно в миллион раз труднее, чем в шашках. По-видимому, это закрывает данный вопрос…
Удивительно высокого уровня игры шашечных программ недостаточно для того, чтобы утверждать, что искусственный интеллект уже создан; однако этого успеха также не следует преуменьшать. Это комбинация идей о том, что такое шашки и как их анализировать и программировать. Некоторые читатели могут подумать, что эта программа ничего, кроме шашечного мастерства самого Самуэля, не доказывает. Но это неверно по крайней мере по двум причинам. Во-первых, хорошие игроки выбирают ходы, руководствуясь мысленными процессами, которых они сами полностью не понимают — они пользуются интуицией. Однако до сих пор никому не известен способ стопроцентного использования собственной интуиции; лучшее, что мы можем сделать, это задним числом использовать наши «впечатления» или «мета-интуицию» (интуицию о собственной интуиции), чтобы с их помощью попытаться объяснить природу собственной интуиции. Но это было бы только грубым приближением к действительной сложности интуитивных методов. Поэтому практически невозможно, чтобы Самуэль скопировал в своей программе собственные методы игры. Есть и другая причина, по которой не следует путать игру Самуэлевой программы с игрой ее создателя — программа его регулярно обыгрывает! Это вовсе не парадокс — не более, чем тот факт, что компьютер, запрограммированный на вычисление π, может делать это гораздо быстрее самого программиста.
Какую программу можно назвать оригинальной?
Проблема компьютера, превосходящего своего программиста, связана с вопросом «оригинальности» в ИИ. Что, если программа ИИ выдвинет идею или план игры, которые никогда не приходили в голову ее создателю? Кому тогда будет принадлежать честь? Существуют несколько интересных примеров, когда именно это и происходило; некоторые примеры касаются весьма тривиального уровня, некоторые — уровня довольно глубокого. Один из самых известных случаев произошел с программой Е. Гелернтера, созданной для доказательства теорем элементарной Эвклидовой геометрии. В один прекрасный день эта программа нашла блестящее и оригинальное доказательство одной из основных теорем геометрии, так называемой «pons asinorum» или «ослиный мост».
Эта теорема утверждает, что углы, прилегающие к основанию равнобедренного треугольника, равны между собой. Стандартное доказательство проводится с помощью высоты, делящей треугольник на две симметричные половины. Элегантный метод, найденный программой (см. рис. 114), не пользуется никакими дополнительными построениями.
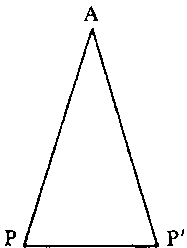
Рис. 114. Доказательство Pons Asinorum (найденное Паппусом (ок. 300 г. до н. э.) и программой Гелернтера (ок. 1960 г. н. э.).) Требуется доказать, что углы, прилегающие к основанию равнобедренного треугольника, равны между собой. Решение: поскольку треугольник равнобедренный, АР и АР' — равной длины. Следовательно, треугольники РАР' и Р'АР конгруэнтны (сторона-сторона-сторона). Из этого вытекает, что соответствующие углы равны. В частности, углы, прилегающие к основанию, равны.
Вместо этого программа рассмотрела данный треугольник и его зеркальное отображение как два различных треугольника Доказав, что они конгруэнтны, она показала, что углы у основания соответствуют друг другу в этой конгруэнтности — что и требовалось доказать.
Это блестящее доказательство восхитило как создателя программы, так и многих других, некоторые даже увидели в этом признак гениальности. Не умаляя этого достижения, заметим, что в 300 году до н. э. геометр Паппус нашел также и это доказательство. Так или иначе, открытым остается вопрос: «Чья это заслуга?» Можно ли назвать это разумным поведением? Или же доказательство находилось глубоко внутри человека (Гелернтера), и компьютер только извлек его на поверхность? Последний вопрос подходит очень близко к цели. Его можно вывернуть наизнанку. Было ли доказательство спрятано глубоко в программе, или же оно лежало на поверхности? Насколько легко понять, почему программа сделала именно то, что она сделала? Может ли ее открытие быть приписано какому-то простому механизму, или простой комбинации механизмов программы? Или же имело место некое сложное взаимодействие, которое, будучи объяснено, не станет от этого менее достойным восхищения?
Кажется логичным предположить, что, если эти действия — результат неких операций, с легкостью прослеживаемых в программе, то, в каком-то смысле, программа лишь выявляла идеи, спрятанные (правда, неглубоко) в голове самого программиста. Напротив, если прослеживание программы шаг за шагом не помогает нам ответить на вопрос, откуда взялось это определенное открытие то, возможно, пора начать отделять «разум» программы от разума программиста. Программисту принадлежит лишь честь изобретения программы, но не идей которые выдала затем эта программа. В таких случаях, человека можно назвать «мета-автором» — автором автора результата, а программу — просто автором.
В случае Гелернтера и его геометрической машины, сам Гелернтер, возможно, не нашел бы доказательства Паппуса, все же механизмы, создавшие это доказательство, лежали достаточно близко к поверхности программы, так что ее трудно назвать самостоятельным геометром. Если бы программа продолжала удивлять людей, снова и снова выдавая новые оригинальные доказательства, каждое из которых основывалось бы на гениальном прозрении, а не на определенных стандартных методах, то тогда у нас не было бы сомнений в том, что перед нами — настоящий геометр. Однако этого не случилось.
Кто сочиняет компьютерную музыку?
Различие между автором и мета-автором становится особенно заметно в случае компьютерной музыки. По-видимому, во время акта сочинительства программа может иметь различные уровни автономии. Один из уровней проиллюстрирован на примере пьесы, мета-автор которой — Макс Матьюс, работающий в лабораториях компании «Белл». Он ввел в компьютер ноты двух маршей — «Когда Джонни идет, маршируя, домой» и «Британские гренадеры» — и попросил его создать новую пьесу которая начиналась бы с «Джонни» и постепенно переходила в «Гренадеров». В середине получившейся пьесы «Джонни», действительно, полностью исчезает, и мы слышим только «Гренадеров». После чего процесс начинает идти в обратном направлении, и пьеса заканчивается мелодией «Джонни» , как и в начале. По словам Матьюса, это:
тошнотворное музыкальное переживание, которое, тем не менее, не лишено интереса — в особенности, в области ритмического превращения «Гренадеры» написаны в темпе 2/4, в тональности фа мажор, а «Джонни» — в темпе 6/8 в тональности ми минор. Переход от 2/4 к 6/8 легко заметен, при этом такой переход был бы очень трудной задачей для музыканта-человека. Модуляция из фа мажора в ми минор, включающая замену двух нот гаммы, режет ухо — более плавный переход, без сомнения был бы лучшим решением.
Получившаяся пьеса довольно забавна, хотя местами довольно помпезна и запутана.
Сочиняет ли музыку сам компьютер? Подобных вопросов лучше не задавать — однако их трудно полностью игнорировать. Ответить на них нелегко. Алгоритмы здесь четко определены, просты и понятны. Сложных и запутанных вычислений, самообучающихся программ и случайных процессов здесь нет — машина функционирует совершенно механически и прямолинейно. Однако результатом является последовательность звуков, не запланированных композитором во всех деталях, хотя общая структура произведения полностью и точно определена. Поэтому композитор часто бывает удивлен — и приятно удивлен — конкретным воплощением своих идей. Именно в этом смысле можно сказать, что компьютер сочиняет музыку. Мы называем этот процесс алгоритмической композицией и снова подчеркиваем тот факт, что алгоритмы здесь просты и прозрачны.
Маттьюс сам отвечает на вопрос, который, по его мнению, лучше не задавать. Несмотря на его возражения, многие считают, что проще сказать, что эта пьеса была «сочинена компьютером». По моему мнению, это выражение передает ситуацию совершенно неверно. В этой программе не было структур, аналогичных «символам» мозга, и о ней никак нельзя было сказать, что она «думает» о том, что делает. Приписать создание подобной музыкальной пьесы компьютеру — все равно, что сказать, что автором этой книги является фототипическая машина, оснащенная компьютерной техникой, на которой книга была составлена — машина, автоматически (и часто неверно) переносящая слова со строчки на строчку.
В связи с этим возникает вопрос, отходящий немного в сторону от ИИ. Когда мы видим слово «Я» или «мне» в тексте, к чему мы его относим? Например, подумайте о фразе «ВЫМОЙ МЕНЯ», которую иногда можно увидеть на грязном кузове грузовика. Кого это «меня»? Может быть, это какой-то несчастный заброшенный ребенок, который, желая быть вымытым, нацарапал эти слова на ближайшей поверхности? Или же это грузовик, требующий купания? Или сама фраза желает принять душ? А может быть, это русский язык ратует за собственную чистоту? Эту игру можно продолжать до бесконечности. В данном случае, эта фраза — только шутка имеется в виду, что мы должны на определенном уровне предположить, что эти слова написал сам грузовик, требующий, чтобы его вымыли. С другой стороны, эти слова ясно воспринимаются как написанные ребенком, и мы находим эту ошибочную интерпретацию забавной. Эта игра основана на прочтении слова «меня» на неправильном уровне.
Именно такой тип двусмысленности возник в этой книге, сначала в «Акростиконтрапунктусе» и позже в обсуждении Геделевой строки G (и ее родственников). Мы дали разбивальным записям следующую интерпретацию «Меня нельзя воспроизвести на патефоне X», интерпретацией недоказуемого суждения было «Меня нельзя доказать в формальной системе X» Возьмем последнее предложение. Где еще вы встречали суждение с местоимением «я», прочитав которое, вы автоматически предположили, что «я» относится не к человеку, произносящему это предложение, но к самому предложению? Я думаю, таких случаев очень немного. Слово «я» когда оно появляется, например, в Шекспировском сонете, относится не к четырнадцатистрочной поэтической форме, напечатанной на странице, а к существу из плоти и крови, стоящему за этими строчками.
Как далеко мы обычно заходим, пытаясь определить, к кому относится «я» в предложении? Мне кажется, что ответ заключается в том, что мы пытаемся найти мыслящее существо, которому можно приписать авторство данных строк. Но что такое «мыслящее существо»? Нечто такое, с чем мы можем с легкостью сравнить самих себя. Есть ли характер у Вайзенбаумовой программы «Доктор»? И если да, то чей это характер? Недавно на страницах журнала «Science» появился спор на эту тему.
Это возвращает нас к вопросу о том, кто же на самом деле сочиняет компьютерную музыку. В большинстве случаев, за подобными программами стоит человеческий разум, и компьютер используется, с большей или меньшей изобретательностью, как инструмент для воплощения человеческих идей. Программа, которая это исполняет, на нас совсем не похожа. Это простой и бесхитростный набор команд не обладающий гибкостью, пониманием того, что он делает, или самосознанием. Если когда-нибудь люди создадут программы с этими свойствами, и эти программы начнут сочинять музыкальные произведения, тогда мне кажется, наступит время разделить наше восхищение между программистом, создавшим такую замечательную программу, и самой программой обладающей музыкальным вкусом. Я думаю, что это случится только тогда, когда внутренняя структура программ будет основываться на чем-то, напоминающем «символы» в нашем мозгу и их пусковые механизмы, которые отвечают за сложное понятие значения. Подобная внутренняя структура наделила бы программу такими свойствами, с которыми мы могли бы до определенной степени идентифицировать себя. Но до тех пор мне не кажется правильным говорить «Эта пьеса была написана компьютером».
Доказательство теорем и упрощение программ
Вернемся теперь к истории ИИ. Одним из ранних шагов в этом направлении была попытка создания программы, способной доказывать теоремы. Концептуально это то же самое, что создание программы, способной искать деривацию MU в системе MIU — с той разницей, что формальные системы здесь часто были сложнее, чем система MIU. Это были версии исчисления предикатов, представляющего собой расширенный — с использованием кванторов — вариант исчисления высказываний. В действительности большинство правил исчисления предикатов содержится в ТТЧ. Трюк при написании такой программы заключается в том, чтобы снабдить ее чувством направления, чтобы программа не блуждала по всему пространству возможностей, а следовала лишь по «важным» тропинкам, которые, в соответствии с некими разумными критериями могут привести к нужной строчке.
В этой книге мы не рассматривали подобные вопросы подробно. В самом деле, как мы можем сказать, когда продвигаемся в направлении теоремы, а когда наши поиски — пустая трата времени? Этот вопрос я попытался проиллюстрировать на примере головоломки MU. Разумеется, окончательный ответ на него дать невозможно. Именно в этом — суть Ограничительных Теорем, поскольку если бы мы всегда знали, в каком направлении идти, то могли бы построить алгоритм для доказательства любой теоремы, — а это противоречит Теореме Чёрча. Такого алгоритма не существует. (Предоставляю читателю догадаться, почему это следует из Теоремы Чёрча.) Однако это не означает, что невозможно развить интуитивное чувство того, какие дороги ведут к цели и какие уводят в сторону. Лучшие программы обладают сложной эвристикой, позволяющей им делать заключения в исчислении предикатов так же быстро, как это делают способные люди.
Метод при доказательстве теорем заключается в том, чтобы всегда иметь в виду конечную цель — строчку, которую вы хотите получить. — и использовать это знание при поиске промежуточных шагов. Один из способов, разработанных для превращения общих целей в местную стратегию для деривации, называется упрощением проблем. Он основан на идее, что кроме конечной задачи можно обычно выделить также несколько подзадач, решение которых помогает в нахождении решения основной задачи. Следовательно, если разбить проблему на серию новых подзадач, и каждую из них затем разбить на подподзадачи — и так далее, рекурсивным образом, — то рано или поздно мы придем к очень простым целям, которых можно будет достигнуть за пару шагов. По крайней мере, так кажется…
Именно упрощение проблемы было причиной неприятностей Зенона. Как вы помните, его метод, чтобы попасть из А в Б (где Б было конечной целью), состоял в «упрощении» задачи, разбив ее на две подзадачи сначала пройти половину пути, а затем все остальное. Таким образом, вы «протолкнули» — говоря в терминах главы V — две подзадачи в ваш «стек задач». Каждая из них, в свою очередь, будет заменена на две подзадачи — и так далее, до бесконечности. Вместо единственной конечной цели у вас получается бесконечный стек задач (рис. 115). Вытолкнуть бесконечное количество подзадач из вашего стека будет непросто — именно это, разумеется, и имел в виду Зенон.
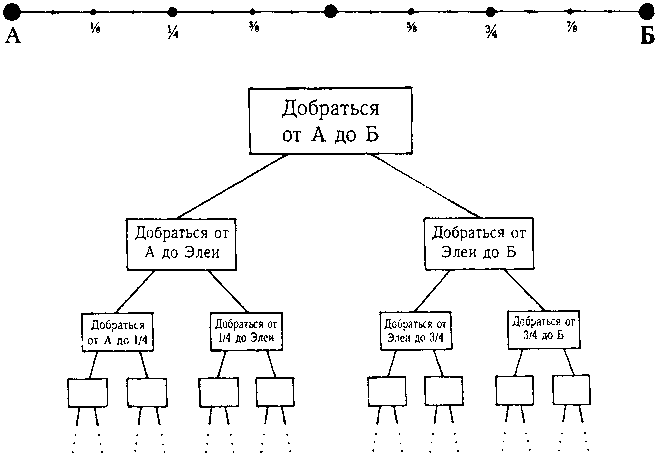
Рис. 115. Бесконечное дерево подзадач Зенона, чтобы добраться от А до Б.
Еще один пример бесконечной рекурсии в упрощении проблем можно найти в Диалоге «Маленький Гармонический Лабиринт», когда Ахилл хотел исполнения своего Нетипового Желания. Это должно было быть отложено до тех пор, пока не было получено разрешение Мета-Гения, но чтобы получить разрешение на дачу разрешения, Мета-Гений должна была говорить с Мета-Мета Гением и так далее. Несмотря на бесконечность стека задач, желание Ахилла было все же исполнено. Упрощение задач в конце концов победило!
Хотя я над ним и подсмеиваюсь, упрощение задач является могучим инструментом для превращения сложных конечных целей в более простые местные задачи. Эта техника отлично работает в некоторых ситуациях, таких, например как шахматные эндшпили, где расчет вариантов часто неэффективен, даже когда мы рассчитываем вперед на огромное (15 или более) количество шагов. Это объясняется тем, что чистый расчет вариантов не основан на планировании, вместо поиска определенной цели он просто исследует огромное количество возможных альтернатив. Конечная цель позволяет нам выработать стратегию для ее достижения, а это совершенно иная техника, чем механический расчет вариантов. Разумеется, в технике расчета желательность или нежелательность данного варианта измеряется функцией оценки, которая косвенно включает многие цели, основная из которых — не получить мата. Но это слишком неявно. У хороших шахматистов, играющих против программ, основанных на расчете вариантов обычно складывается впечатление, что те весьма слабы в составлении планов и разработке стратегии.
Шанди и кость
У нас нет гарантии того, что метод упрощения задач сработает в каждом отдельном случае. Во многих ситуациях он терпит фиаско. Рассмотрим, например, следующую простую задачу. Представьте себе, что вы — собака, и что хозяин только что перекинул вашу любимую кость через забор в соседний двор. Кость видно сквозь щели в заборе, она лежит на траве, и у вас текут слюнки. На расстоянии приблизительно пятнадцати метров от кости вы видите открытую калитку в заборе. Что вы сделаете? Некоторые собаки просто подбегают к забору поближе к кости и начинают лаять. Другие собаки бросаются к калитке (удаляясь при этом от цели) и бегут прямо к лакомому кусочку. Можно сказать, что и те, и другие применяют технику упрощения задачи, разница в том, что они представляют задачу по-разному. Лающая собака видит подзадачи в том, чтобы (1) подбежать к забору, (2) попасть на ту сторону и (3) подбежать к кости, но вторая подзадача оказывается слишком трудной, и собака начинает лаять. Для другой собаки подзадачи заключаются в том, чтобы (1) подбежать к калитке, (2) пробежать сквозь нее и (3) подбежать к кости. Обратите внимание, что все зависит от того, как вы представляете себе «пространство проблемы» — то есть от того, что кажется вам упрощением задачи (движением к цели) и что — усложнением задачи (движением от цели).
Изменение пространства задачи
Некоторые собаки сначала пытаются подбежать прямо к кости; когда они натыкаются на забор, в их мозгу нечто проясняется и они меняют направление и бегут к калитке. Им становится ясно, что то, что, как им сначала казалось, увеличивает дистанцию между начальным и желанным положениями, — а именно, отдаление от кости и приближение к калитке — на самом деле ее уменьшает. С первого взгляда они принимают физическое расстояние за расстояние проблемы. Любое отдаление от кости кажется им, по определению, Плохой Идеей. Но затем они каким-то образом понимают, что могут изменить свое восприятие того, что на самом деле «приблизит» их к кости. В правильно выбранном абстрактном пространстве движение к калитке является траекторией, приводящей собаку к кости. В этом смысле собака каждую минуту находится все «ближе» к кости. Следовательно, польза упрощения задач зависит от того, каким образом эта задача представлена у вас в голове. То, что в определенном пространстве выглядит как отступление, в ином пространстве может быть революционным шагом вперед.
В повседневной жизни мы постоянно сталкиваемся с необходимостью решать задачи, подобные проблеме собаки и кости. Предположим, как-то вечером я решаю съездить на машине к товарищу, живущему на расстоянии 100 км. на юг; при этом я нахожусь на работе, куда утром приехал на велосипеде. Прежде, чем я окажусь в машине, направляющейся на юг, я должен буду совершить множество кажущихся ошибочными шагов в «неправильном» направлении. Я должен буду выйти из кабинета, направляясь при этом на восток; пройти по коридору к выходу из здания, сначала на север, затем на запад. После этого я поеду домой на велосипеде, поворачивая во всех четырех направлениях. Там, после серии коротких передвижений, я, наконец, попаду в машину. Разумеется, это не означает, что я поеду прямо на юг — мой маршрут может включать повороты на север, восток или запад, чтобы как можно быстрее добраться до шоссе. Это совершенно не кажется мне парадоксальным или забавным; пространство, в котором физическое отступление воспринимается как движение к цели, так глубоко встроено в мой мозг, что я не вижу никакой иронии в том, что мне приходится двигаться на север, чтобы попасть на юг. Дороги, коридоры и так далее действуют как каналы, которые я покорно принимаю как данное; таким образом, моя интерпретация ситуации частично навязывается мне сверху. Но собаке, стоящей перед забором, гораздо труднее это сделать — особенно если прямо перед ее носом лежит аппетитная кость. На самом деле, когда пространство проблемы оказывается лишь немного абстрактнее физического пространства, люди часто бывают также беспомощны, как лающая на забор собака.
В каком-то смысле, все возможные задачи являются лишь вариантами задачи собаки и кости. Многие проблемы разворачиваются не в физическом, но в некоем концептуальном пространстве. Поняв, что прямолинейное движение к цели приводит вас к абстрактному «забору», вы можете либо (1) попытаться отойти в сторону от цели, следуя случайному маршруту (при этом вы надеетесь, что рано или поздно наткнетесь на скрытую «калитку», сквозь которую сможете пройти и подойти к вашей кости), либо (2) попытаться найти такое новое «пространство» проблемы, в котором не окажется абстрактного забора, отделяющего вас от цели — в таком пространстве вы сможете идти прямо к цели. Первый метод может показаться слишком ленивым, а второй — слишком трудным. Все же решения, требующие модификации пространства задачи, чаще бывают результатом мгновенного озарения, чем результатом серии долгих раздумий. Возможно, эти прозрения приходят из самого сердца разума — и, само собой разумеется, наш ревнивый мозг надежно защищает этот секрет.
Так или иначе, проблема заключается не в том, что упрощение задач само по себе ведет к неудаче — напротив, это весьма полезный прием. Проблема лежит глубже, как можно выбрать подходящую внутреннюю интерпретацию задачи? В каком пространстве вы ее располагаете? Какие действия сокращают дистанцию между вами и вашей целью в выбранном вами пространстве? На математическом языке это может быть выражено как задача нахождения подходящей метрики (функции расстояния) между состояниями. Вам надо найти такую метрику, в которой расстояние между вами и целью было бы очень коротким.
Поскольку нахождение внутреннего представления само по себе является задачей — и весьма непростой! — вы можете попытаться приложить технику упрощения задач к ней самой. Для этого вам придется каким-то образом представить огромное множество абстрактных пространств, что является весьма сложным проектом. Я пока не слышал, чтобы кто-нибудь пытался сделать подобное. Это может быть лишь интересной теоретической возможностью, на практике совершенно невыполнимой. В любом случае, ИИ очень не хватает программ, которые могут «отойти в сторону» и посмотреть, что происходит — и затем, используя эту перспективу, лучше сориентироваться для нахождения цели. Одно дело — написать программу, которая умеет выполнять единственное задание, даже такое, для выполнения которого, как нам кажется, нужен интеллект, и совсем другое дело — написать действительно думающую программу! Эта разница аналогична разнице между осой Sphex (см. главу XI), чьи инстинктивные действия кажутся весьма разумными, и человеком, за ней наблюдающим.
Снова режим I и режим М
Разумной программой, по-видимому, будет программа, достаточно гибкая для решения разнообразных задач. Она научится решать каждую из них и в процессе этого будет приобретать опыт. Она будет способна работать в согласии с набором правил, но в нужный момент сможет посмотреть на свою работу со стороны и решить, ведут ли данные правила к стоящей перед ней цели. Она будет способна прекратить работу по данным правилам и, если потребуется, выработать новые правила, лучше подходящие для данного момента.
Многое в этом обсуждении может напомнить вам о головоломке MU. Например, отход в сторону от конечной цели напоминает об отходе в сторону от MU, выводя все более длинные строчки, которые, как вы надеетесь, рано или поздно помогут вам получить MU. Если вы похожи на описанную наивную собаку, то можете чувствовать, что уходите в сторону от «кости MU» каждый раз, когда ваша строчка получается длиннее двух букв, если же вы — «собака» поумней, то понимаете, что использование длинных строчек может иметь определенный смысл — нечто вроде приближения к калитке, ведущей к кости MU.
Между предыдущим обсуждением и головоломкой MU есть еще одна связь: два операционных режима, приведшие к решению головоломки MU — Механический режим и Интеллектуальный режим. В первом из них вы работаете в системе жестких правил; в последнем вы всегда можете выйти из системы и взглянуть на проблему со стороны. Подобная перспектива означает возможность выбора определенного представления проблемы; работа же внутри системы сравнима с применением техники упрощения задач, не выходя из пределов уже данного представления. Комментарии Харди о стиле Рамануяна — в особенности, о его готовности изменять собственные гипотезы — иллюстрируют это взаимодействие между режимом M и режимом I в творческой мысли.
Оса Sphex работает в режиме M превосходно, но совершенно не способна выбирать представление о системе или вносить в режим M какие бы то ни было изменения. Она не может заметить, что некое событие происходит в ее системе снова, снова и снова, поскольку это равнялось выходу из системы, каким бы незначительным он ни был. Она просто не замечает того факта, что повторяется нечто одинаковое. Эта идея (не замечать тождественности повторяющихся событий) интересна в применении к нам самим. Есть ли в нашей жизни часто повторяющиеся идентичные ситуации, в которых мы каждый раз ведем себя одинаково глупо, поскольку не можем, взглянув на себя со стороны, заметить их тождественность? Здесь мы опять сталкиваемся с вопросом: «Что такое тождественность?» Этот вопрос прозвучит как одна из тем ИИ, когда мы будем обсуждать узнавание структур.
ИИ в применении к математике
Математика — необыкновенно интересная область для изучения с точки зрения ИИ. Каждый математик чувствует, что между идеями в математике существует некая метрика — что вся математика является сетью взаимосвязанных результатов. В этой сети некоторые идеи соотносятся очень тесно; для соединения же других идей требуются более сложные пути. Иногда две теоремы в математике близки между собой, потому что одну из них легко доказать, пользуясь доказательством другой. Иногда две идеи близки между собой, потому что они аналогичны или даже изоморфны. Это только два примера значения слова «близкий» в области математики; возможно, имеются и другие. Трудно сказать, является ли наше чувство математических взаимосвязей универсальным и объективным, или же это только историческая случайность. Некоторые теоремы различных ветвей математики кажутся нам трудно соотносимыми, и мы можем подумать, что они никак не связаны между собой — но позднее можем узнать нечто, что заставит нас пересмотреть это мнение. Если бы нам удалось ввести высоко развитое чувство математической близости — так сказать, «мысленную метрику» математика — в программу, то у нас, возможно, получился бы примитивный «искусственный математик». Но это зависит от нашей способности наделить программу также чувством простоты и «естественности» — еще один из основных камней преткновения.
Эти темы возникали во многих проектах ИИ. Например, в Массачусетском институте технологии были разработаны программы, объединенные под названием «MACSYMA». Они были призваны помогать математикам в символической манипуляции сложными математическими выражениями. В некотором смысле, MACSYMA знает, «куда идти» — в ней есть что-то вроде «градиента сложности», ведущего ее от того, что нам кажется сложными выражениями, к более простым выражениям. В репертуар MACSYMA входит программа под названием «SYN», которая символически интегрирует функции; считается, что в чем-то она превосходит людей. Она опирается на множество различных способностей, как это обычно делает разум: глубокие знания, техника упрощения задач, множество эвристических правил, а также некоторые специальные приемы.
Целью программы, составленной Дугласом Ленатом из Стэнфордского университета, было изобретение идей и открытие фактов элементарной математики. Начиная с понятия «множества» и набора «интересных» идей, которые были в нее введены, она «изобрела» идею счета, затем сложения, затем — умножения, затем, среди прочего, — понятие простых чисел… Она зашла так далеко, что повторила открытие гипотезы Гольдбаха! Разумеется, все эти «открытия» были уже сделаны сотни, а то и тысячи лет назад. Может быть, успех программы объясняется тем, что понятие «интересного», которое Ленат вложил в машину, было закодировано в большом количестве правил, на которые, возможно, повлияло современное математическое образование самого Лената; тем не менее, этот успех впечатляет. Правда, после этих достойных уважения свершений программа, по-видимому, выдохлась. Примечательно, что она не смогла развить и улучшить свое чувство того, что является интересным. Эта способность, по-видимому, лежит несколькими уровнями выше.
В сердце ИИ: представление знаний
Многие из приведенных примеров показывают, что то, каким образом представлена некая область, имеет огромное влияние на то, как она будет «понята». Программа, которая печатала бы теоремы ТТЧ в заранее заданном порядке, не понимала бы ничего в теории чисел; с другой стороны, можно сказать, что программа, подобная программе Лената, обладающая дополнительным знанием, имеет некое рудиментарное чувство теории чисел. Программа, чьи математические познания находились бы в широком контексте опыта реального мира, имела бы больше всего возможностей «понимать» в том же смысле, как и люди. Именно представление знаний находится в сердце ИИ.
На заре исследований по ИИ считалось, что знание расфасовано «пакетами» размером с предложение, и что лучшим способом ввода знаний в программу был бы некий метод, позволяющий переводить факты в пассивные пакеты данных. Таким образом, каждый факт соответствовал бы куску данных, которые могли бы использоваться программой. Примером такого подхода являлись шахматные программы, в которых позиции на доске были закодированы в форме матриц или неких списков и записаны в памяти, откуда они могли быть вызваны и обработаны с помощью подпрограмм.
Тот факт, что люди сохраняют информацию гораздо более сложным способом, был известен психологам уже давно, но специалисты по ИИ открыли его для себя сравнительно недавно. Теперь они стоят перед проблемой «блочных» знаний и разницы между декларативным и процедурным знаниями (эта разница связана, как мы видели в главе XI, с тем, какие знания доступны для интроспекции).
В самом деле, наивному предположению о том, что все знание должно быть закодировано в виде пассивных фрагментов данных, противоречит основной факт конструкции компьютеров: их умение складывать, вычитать, умножать и так далее не является закодированным в пакеты данных и записанным в памяти; это знание находится не в памяти, а в самих схемах аппаратуры. Карманный калькулятор не хранит в памяти умения складывать; это знание закодировано в его «внутренностях». В памяти нет такого места, на которое можно было бы указать, если бы кто-нибудь спросил: «Покажите мне, где в этой машине находится умение складывать?»
Тем не менее, в ИИ был проделан большой объем работы по изучению систем, в которых большинство знаний хранится в определенных местах — то есть декларативно. Само собой разумеется, что какое-то знание должно заключаться в программах — иначе у нас была бы не программа, а энциклопедия. Вопрос в том, как разделить знание между программой и данными (которые далеко не всегда легко отличить друг от друга). Надеюсь, что это было достаточно хорошо объяснено в главе XVI. Если в процессе развития системы программист интуитивно воспримет некий объект как часть данных (или как часть программы), это может иметь значительное влияние на структуру системы, поскольку, программируя, мы обычно различаем между объектами, похожими на данные, и объектами, похожими на программу.
Важно иметь в виду, что в принципе любой способ кодирования информации в схему данных или процедур так же хорош, как и все остальные, в том смысле, что все то, что можно сделать, работая с одной схемой, можно сделать и с другой — если вас не слишком волнует эффективность. Однако можно привести доводы, доказывающие, что один метод определенно лучше другого. Взгляните, например, на следующий аргумент в пользу исключительно процедурного представления: «Когда вы пытаетесь закодировать достаточно сложную информацию в виде данных, вам приходится развивать для этого нечто вроде нового языка или формализма. Таким образом, на самом деле, структура ваших данных начинает напоминать программу, части которой работают как интерпретатор. Не лучше ли сразу представить ту же информацию в процедурной форме и избежать лишнего уровня интерпретации?»
ДНК и белки дают некоторую перспективу
Этот довод звучит весьма убедительно; тем не менее, если интерпретировать его немного свободнее, он может быть понят как аргумент против ДНК и РНК. Зачем кодировать генетическую информацию в ДНК, если, сохраняя ее прямо в белках, можно избежать не одного, а двух лишних уровней интерпретации? Оказывается, что иметь одну и ту же информацию, закодированную в нескольких разных формах для разных целей, очень полезно. Одно из преимуществ кодирования генетической информации в ДНК в модулярной форме (в форме данных) заключается в том, что таким образом два индивидуальных гена могут быть скомбинированы для формирования нового генотипа. Это было бы очень трудно, если бы информация содержалась только в белках. Вторым доводом в пользу хранения информации в ДНК является то, что это облегчает транскрипцию и трансляцию ее в белки. Когда информация не нужна, она не занимает много места; когда она нужна, она извлекается и служит эталоном. Не существует механизма для копирования одного белка на основе другого — их третичная укладка сделала бы такое копирование слишком громоздким. Кроме того, генетическая информация почти неизбежно должна быть представлена в трехмерных структурах, таких, как энзимы, поскольку узнавание молекул и манипуляция ими по природе являются трехмерными операциями. Поэтому в контексте клеток довод в пользу исключительно процедурного представления информации кажется неверным. Это говорит о том, что в возможности перехода от процедурной к декларативной информации и обратно есть свои преимущества. Это, возможно, верно и для ИИ.
Этот вопрос был затронут Фрэнсисом Криком на конференции по общению с внеземными культурами:
Мы видим, что на земле есть две молекулы, одна из которых хороша для копирования (ДНК), а другая — для действия (белки). Возможно ли разработать такую систему, в которой одна и та же молекула выполняла бы обе функции? Или же существуют веские, основанные на анализе системы аргументы, доказывающие, что деление этой работы на две части дает значительное преимущество? Ответа на этот вопрос я не знаю.
Модульность знания
Другой вопрос, возникающий по поводу представления знания, это модульность. Насколько легко ввести новое знание? Насколько легко получить доступ к старому знанию? Насколько модулярны книги? Все это зависит от многих факторов. Если из книги, в которой главы тесно связаны между собой и ссылаются друг на друга, убрать одну главу, то эту книгу станет практически невозможно понять. Так, потянув за одну паутинку, вы разрушаете всю паутину. С другой стороны, книги, главы которых менее зависимы друг от друга, гораздно более модулярны.
Рассмотрим прямолинейную программу, производящую теоремы на основе аксиом и правил вывода ТТЧ. У «знаний» подобной программы — два аспекта. Они находятся косвенно в аксиомах и правилах и явно — в произведенных теоремах. В зависимости от того, под каким углом вы смотрите на знания, вы скажете, что они либо модулярны, либо распространены по всей программе и совершенно не модулярны. Представьте себе, например, что вы написали такую программу, но забыли включить в нее Аксиому I из списка аксиом. После того, как программа вывела тысячи теорем, вы обнаруживаете свою ошибку и вставляете новую аксиому. Тот факт, что вам это легко удается, показывает, что неявные знания системы модулярны; однако вклад новой аксиомы в явные знания системы станет заметен не скоро — после того, как произведенный ею эффект распространится по системе, подобно тому, как по комнате, в которой разбили флакон с духами, медленно распространяется аромат. В этом смысле, новое знание включается в систему постепенно. Более того, если бы вы захотели вернуться назад и заменить Аксиому I на ее отрицание, для этого вам пришлось бы убрать все теоремы, в деривации которых участвовала Аксиома I. Ясно, что явные знания системы далеко не так модулярны, как ее неявные знания.
Было бы полезно научиться делать пересадку знания в модулярной форме. Тогда, чтобы обучить человека французскому языку, нужно было бы лишь, проникнув в его мозг, определенным образом изменить его нейронную структуру, — и человек бегло заговорил бы по-французски! Разумеется, все это только юмористические мечтания.
Другой аспект представления знаний зависит от того, как мы хотим эти знания использовать. Должны ли мы, получив новую информацию, сразу делать выводы? Должны ли мы постоянно делать сравнения и проводить аналогии между новой и старой информацией? В шахматной программе, например, если вы хотите получить дерево анализа вариантов, то построение, включающее позиции на доске и минимум ненужных повторений, будет предпочтительнее, чем построение, повторяющее одну и ту же информацию в различной форме. Но если вы хотите, чтобы ваша программа «понимала» позицию, глядя на структуры на доске и сравнивая их с уже известными ей структурами, тогда повторение одной и той информации в разных формах будет более полезным.
Представление знания с помощью логического формализма
Существует несколько философских школ, по-разному трактующих лучшие способы представления знания и работы с ним. Одна из наиболее влиятельных школ пропагандирует представление знаний с помощью формальной нотации, подобной нотации ТТЧ, — с использованием препозиционных связок и кванторов. Не удивительно, что основные операции в подобной системе выглядят как формализация дедуктивных рассуждений. Логические заключения могут быть сделаны при помощи правил вывода, аналогичных соответствующим правилам ТТЧ. Спрашивая такую систему о какой-либо идее, мы ставим перед ней цель в виде строчки, которую необходимо вывести. Например: «Является ли МУМОН теоремой?» Тут вступают в действие автоматические рассуждающие механизмы, которые пытаются приблизиться к цели, используя различные методы упрощения задач.
Предположим, например, что дано высказывание «все формальные арифметические системы неполны»; вы спрашиваете программу: «Полны ли „Principia Mathematical“». Сканируя имеющуюся в ее распоряжении информацию (часто называемую базой данных), программа может заметить, что если бы ей удалось установить, что «Principia Mathematica» — это формальная арифметика, то она могла бы ответить на вопрос. Таким образом, высказывание «„Principia Mathematica“ — это формальная арифметика» становится подзадачей, после чего в действие вступает метод упрощения задач. Если программа сможет найти что-либо еще, что могло бы способствовать подтверждению (или опровержению) задачи или подзадачи, она начнет работать над этой информацией — и так далее, рекурсивным образом. Этот процесс называется обратным сцеплением данных, поскольку он начинается с цели и затем отступает назад — предположительно к уже известным вещам. Если представить графически основную задачу, подзадачи, подподзадачи и так далее, у нас получится структура дерева, поскольку основная задача может включать несколько подзадач, каждая из которых, в свою очередь, может подразделяться на несколько подподзадач… и т. д.
Обратите внимание, что этот метод не гарантирует решения, так как внутри системы может не существовать способа установить, что «Principia Mathematica» — формальная арифметика. Это, однако, означает не то, что задача или подзадача являются ложными утверждениями, а лишь то, что они не могут быть получены на основании сведений, имеющихся в распоряжении системы в данный момент. Когда такое случается, система может напечатать что-нибудь вроде: «Я не знаю». Тот факт, что некоторые вопросы остаются открытыми, разумеется, подобен неполноте, от которой страдают некоторые хорошо известные формальные системы.
Осознание дедуктивное и осознание аналогическое
Этот метод дает системе возможность дедуктивного осознания представленной области, поскольку она может выводить правильные умозаключения на основании известных ей фактов. Однако ей не хватает так называемого аналогического осознания — умения сравнивать ситуации и замечать сходство между ними, что является одной из основ человеческого мышления. Я не хочу сказать, что аналогические мыслительные процессы не могут быть втиснуты в эти рамки, просто их гораздо труднее выразить с помощью подобного типа формализма. В настоящее время логические системы стали менее популярны по сравнению с типами систем, позволяющих естественно проводить сложные сравнения.
Как только вы соглашаетесь с тем, что представление знаний — совершенно иное дело, чем простое записывание чисел, миф о том, что «у компьютера — слоновья память», становится легко опровергнуть. То, что хранится в памяти, совсем не обязательно аналогично тому, что программа знает, поскольку, даже если определенный кусок информации и записан где-то внутри сложной системы, в системе может не быть процедуры, правила или какого-либо иного способа управляться с данными и вызывать эту информацию — она может быть недоступна. В таком случае, вы можете сказать, что данная информация «забыта», поскольку доступ к ней временно или навсегда утрачен. Таким образом компьютерная программа может «забыть» что-то на высшем уровне, но помнить это на низшем уровне. Здесь мы снова сталкиваемся с вездесущим различием уровней, из которого, возможно, можем узнать многое о нас самих. Когда мы что-то забываем, это скорее всего означает, что утеряна «указка» высшего уровня, а не то, что какая-либо информация стерта или разрушена. Это говорит о том, насколько важно следить, как у вас в голове «записываются» новые впечатления, поскольку вы никогда не можете сказать заранее, в какой ситуации вам понадобится вытащить что-то из памяти.
От компьютерных хайку — к грамматике СРП
Сложность представления знаний в человеческой голове впервые поразила меня, когда я начал работать над программой по созданию английских предложений, основанных на неожиданном выборе и соединении слов. Я пришел к этой идее довольно интересным путем. Как-то я услышал по радио несколько примеров хайку, сочиненных компьютерами. Они меня чем-то глубоко затронули. Идея заставить компьютер производить нечто, что обычно считается искусством, была довольно юмористична и в то же время содержала элемент глубокой тайны. Меня позабавил юмор и мотивировала загадочность — даже противоречивость — программирования творческих актов. Тогда я и решил написать программу, еще более загадочную и противоречивую, чем программа хайку.
Сначала я был озабочен тем, как сделать грамматику гибкой и рекурсивной, чтобы не возникало впечатления, что программа просто механически подставляет слова в пробелы некоего трафарета. Примерно тогда же я наткнулся на статью Виктора Ингве в «Scientific American», в которой он описывал простую, но гибкую грамматику, способную порождать большое количество разнообразных предложений того типа, который можно найти в некоторых детских книгах. Я модифицировал некоторые идеи этой статьи и у меня получился набор процедур, составивших грамматику типа Схемы Рекурсивных Переходов, описанной в главе V. В этой грамматике выбор слов в предложении определялся процессом, который сначала выбирал наугад общую структуру предложения; постепенно процесс принятия решений распространялся на более низкие уровни предложения, пока не достигался уровень слов и букв. Многое должно было делаться ниже уровня слов, как например, спряжение глаголов и постановка слов во множественное число. Неправильные глаголы и существительные сначала формировались по общим правилам и затем, если результат совпадал с записанным в специальной таблице, производилась замена на нужную — нерегулярную — форму. Как только каждое слово достигало конечной формы, оно печаталось. Программа напоминала знаменитую обезьяну за пишущей машинкой, но оперировала при этом сразу на нескольких лингвистических уровнях, а не только на уровне букв.
В начале я нарочно использовал дурацкий набор слов, так как мне хотелось достичь забавного результата. Программа произвела множество бессмысленных предложений, как длинных, так и совсем кургузых. Вот несколько примеров, в переводе с английского:
Карандаш-самец, который должен неуклюже смеяться, будет квакать. Не должна ли программа всегда хрустеть девочкой в памяти? Десятичный жук, который неуклюже плюется, может крутиться. Кекс, принимающий неожиданного человека во внимание, может всегда уронить карту.
Программа должна работать весело.
Достойная машина не всегда должна приклеивать астронома.
О, программа, которая должна действительно убегать от девочки, пишет музыканта для театра. Деловые отношения квакают.
Счастливая девочка, которая всегда должна квакать, никогда не будет квакать наверняка.
Игра квакает. Профессор напишет маринованный огурчик. Жук крутится.
Человек берет соскальзывающую коробку.
Впечатление от всего этого получается сюрреалистическое; иногда отрывки текста напоминают хайку, как, например, последний пример четырех коротких предложений. Сначала все это кажется забавным и милым, но вскоре надоедает. Прочитав несколько страниц компьютерной продукции, вы можете заметить границы того пространства, в котором оперирует программа, после чего случайные точки в пределах этого пространства — даже если каждая из них и выглядит «новой» — уже вас не удивят. Мне кажется, что это — общий принцип: предмет надоедает вам не тогда, когда вы исчерпали репертуар его поведения, но тогда, когда вы поняли, где находятся границы, внутри которых это поведение может варьироваться. Пространство поведения человека достаточно сложно, чтобы постоянно удивлять других людей; однако в отношении моей программы это оказалось не так. Я понял, что моя цель — производство действительно смешных предложений — требует от программы гораздо большей тонкости. Но что, в данном случае, означает «тонкость»? Ясно было одно — случайные комбинации слов этой тонкостью не обладали. Необходимо было сделать так, чтобы слова использовались в соответствии с реальностью. Именно тогда я начал задумываться о представлении знаний.
От СРП до УСП
Идея, которую я принял на вооружение, состояла в том, чтобы классифицировать каждое слово — существительное, глагол, предлог и т. д. — согласно разным «семантическим измерениям». Таким образом, каждое слово становилось членом различных классов; кроме этого, существовали также суперклассы — классы классов (что напоминает замечание Улама). В принципе, подобная классификация может иметь любое количество уровней, но я решил остановиться на двух. Теперь в любой момент выбор слов был семантически ограничен, поскольку требовалось, чтобы части составляемой фразы согласовались между собой. Скажем, некоторые действия могли быть совершены только одушевленными объектами; только некоторые абстрактные понятия могли влиять на события и так далее. Было нелегко решить, какие категории должны были быть установлены и должна ли каждая конкретная категория быть классом или суперклассом. Каждое слово получило «семантические ярлыки» в нескольких различных категориях. Многие часто встречающиеся предлоги, например, входили сразу в несколько классов, в соответствии с их разными значениями. Теперь продукция машины стала гораздо более осмысленной — и поэтому забавной уже в другом смысле.
Небольшой тест Тюринга
Ниже я привожу девять отрывков, тщательно отобранных из многих страниц текста, написанного поздней версией моей программы. Вместе с ними я включил сюда три предложения, написанных людьми (с самыми серьезными намерениями). Можете ли вы сказать, какие предложения написаны компьютером, а какие — людьми?
(1) Спонтанная речь может рассматриваться как взаимная замена семиотического материала (дублирование) на семиотический диалогический продукт в процессе динамического размышления.
(2) Лучше подумайте о пути «цепи» простачков мысленного эксперимента, в котором линии наследственности являются prima facie примером парадиахронической транзитивности.
(3) Считайте, что это усиливающаяся по принципу цепной реакции возможность чего-то, что рано или поздно появится как продукт (эпистемические условия?), и продукт этот не будет франкфуртовским засовыванием-всего-в-одну-упаковку.
(4) Несмотря на все усилия, ответ, если вам угодно, был поддержан Востоком; следовательно, обман будет приостановлен, благодаря позиции посла.
(5) Разумеется, до восстаний посол слегка постепенно баловал этот сброд.
(6) Предположительно, усовершенствованная свобода являлась причиной этих позиций в той мере, в какой мир очищен последствиями, которые в конце концов не будут неизбежно вызваны порядком, в той мере, в какой этот мир иногда, бесконечно удивительно, порождает непримиримость.
(7) По мнению софистов, кампании в городах-государствах, иными словами, были восприняты Востоком с хитростью. Разумеется, Восток был разделен этими государствами с особенной жестокостью. Восток поддерживает усилия, которые были поддержаны человечеством.
(8) Каждый согласится с тем, что иерархический порядок обмана, несмотря на это, будет напророчен его врагами. По той же причине, индивидуалисты могли бы в будущем засвидетельствовать, что непримиримость не остановит кампаний.
(9) Нет нужды говорить, что во время восстаний, которые оправдали бы секретность, ответы не разделяют Востока. Разумеется, эти страны, ipso facto, всегда зондируют свободу.
(10) Хотя Нобелевская премия была получена гуманистами, она, кроме того, была получена и рабами.
(11) Рабы часто принимают позицию стран, раздираемых конфликтами.
(12) Более того, Нобелевские премии будут получены. По той же причине, несмотря на последствия. Нобелевские премии, которые будут получены, будут иногда получены женщинами.
Людьми написаны предложения с 1 по 3; они были извлечены из современного журнала Art Language и являются, насколько я могу сказать, совершенно серьезными попытками образованных и умственно нормальных людей сообщить нечто друг другу. То, что здесь они приводятся вне контекста, не слишком важно, поскольку контекст звучит совершенно в том же духе.
Моя программа произвела все остальное. Номера с 10 по 12 были выбраны, чтобы показать, что иногда программа выдавала вполне осмысленные суждения, номера с 7 по 9 — наиболее типичный продукт: эти высказывания плавают в странном и соблазнительном мире между смыслом и бессмыслицей. Что же касается предложений с 4 по 6, то они, пожалуй, находятся за пределами смысла. Если быть великодушным, то можно сказать, что они являются самостоятельными «лингвистическими объектами», чем-то вроде абстрактных скульптур, созданных из слов вместо камня; с другой стороны, можно утверждать, что они — не что иное, как псевдо-интеллектуальная тарабарщина.
Выбор словаря для моей программы все еще был направлен на достижение юмористического эффекта. Трудно определить, на что похож конечный результат. Хотя многое в нем выглядит осмысленно, по крайней мере, на уровне отдельных фраз, у читателя определенно создается впечатление, что этот текст написан кем-то, не имеющим понятия о том, что и зачем он говорит. В частности, чувствуется, что за словами здесь не стоят никакие образы. Когда подобные высказывания полились рекой из печатающего устройства, я испытал сложные чувства. Меня позабавила глупость результата; я также был весьма горд моим успехом и попытался описать его друзьям в виде правил для сочинения осмысленных историй по-арабски на основании отдельных росчерков пера. Разумеется, я преувеличивал, но мне нравилось думать об этом таким образом. Наконец, я был счастлив от того, что внутри этой необычайно сложной машины в согласии с некими правилами происходила манипуляция длинными цепями символов, и что эти длинные цепи символов были в каком-то смысле похожи на мысли в моей собственной голове… в каком-то смысле на них похожи.
Представления о том, что такое мысль
Конечно, я не обманывал себя, предполагая, что за этими фразами скрывается разумное существо. Я как никто другой понимал, почему этой программе было весьма далеко до настоящего мышления. К этому случаю отлично приложима теорема Теслера: как только данный уровень владения языком был механизирован, стало ясно, что его нельзя назвать разумом. Но благодаря этому удивительному опыту у меня сложилось впечатление, что настоящая мысль основывается на гораздо более длинных и сложных последовательностях символов в мозгу — символов, двигающихся, наподобие поездов, одновременно по многим параллельным и перекрещивающимся путям; мириады моторов — возбуждающихся нейронов — толкают, тащат и переводят с пути на путь вагоны этих поездов…
Это был всего лишь интуитивный образ, непередаваемый словами. Но образы, интуиция и мотивация находятся так близко друг от друга, что они часто смешиваются; глубокое впечатление, произведенное этим образом, заставило меня серьезнее задуматься над тем, что же такое, на самом деле, представляет из себя мысль. В других местах книги я попытался описать некоторые «дочерние» образы этой первоначальной картины — в особенности, в «Прелюдии» и в «Муравьиной фуге».
Когда я думаю об этой программе сегодня, по прошествии двенадцати лет, меня более всего поражает полное отсутствие зрительных образов за тем, что она говорит. Программа не имела ни малейшей идеи о том, что такое раб, человек и все остальные вещи. Слова были для нее только формальными символами, такими же абстрактными, как p и r в системе pr, — а может быть и еще абстрактнее. Программа пользовалась тем, что когда люди читают какой-либо текст, они обычно наделяют все слова смыслом, словно смысл с необходимостью привязан к группе букв, формирующих то или иное слово. Моя программа — это нечто вроде формальной системы, чьи «теоремы» — порожденные ею фразы — имели готовые интерпретации (по крайней мере, для людей, говорящих по-английски). Но в отличие от системы pr, не все высказывания, интерпретированные таким образом, получались истинными. Многие из них оказались ложными, а многие — просто бессмысленными.
Скромная система pr отразила крохотный уголок вселенной. Но в моей программе — за исключением небольшого количества семантических ограничений, которым она должна была подчиняться — не было подобного «зеркала», отражающего структуру реального мира. Чтобы наделить программу этим зеркалом, мне пришлось бы «завернуть» каждое понятие в множество слоев знаний о мире. Этот проект очень отличался от моего первоначального замысла. Не то, чтобы я не хотел этим заниматься — просто до сих пор руки не доходили.
Грамматики высшего уровня…
На самом деле, я часто задумывался о возможности написать грамматику типа УСП (или какого-нибудь иную программу, производящую предложения), которая выдавала бы только истинные высказывания. Такая программа наделяла бы слова действительным смыслом так, как это происходило в системе pr и в ТТЧ. Идея языка, в котором ложные высказывания грамматически неверны, не нова — она была высказана Иоганном Амосом Комениусом еще в 1633 году. Эта идея очень соблазнительна, поскольку такая система была бы магическим кристаллом: чтобы узнать, истинно ли высказывание, нужно было бы всего лишь проверить его грамматическую правильность… На самом деле, Комениус пошел еще дальше: в его языке ложные высказывания были не только грамматически неправильными, но и вообще невыразимыми!
Развивая эту мысль в другом направлении, можно представить себе программу высшего уровня, создающую произвольные коаны. Почему бы и нет? Такая грамматика соответствовала бы формальной системе, теоремы которой являлись коанами. И если бы у вас была подобная программа, то не могли бы вы отрегулировать ее таким образом, чтобы она порождала только подлинные коаны? Моя приятельница Марша Мередит с энтузиазмом занялась этим проектом «Искусственного Изма»; ниже приводится забавный квази-коан, один из ранних продуктов ее усилий:
МОЛОДЕНЬКОМУ МАСТЕРУ ПОНАДОБИЛАСЬ МАЛЕНЬКАЯ БЕЛАЯ КРИВАЯ ПЛОШКА «КАК МЫ МОЖЕМ НАУЧИТЬСЯ, НЕ УЧАСЬ?» — СПРОСИЛ МОЛОДОЙ МАСТЕР У ВЕЛИКОГО НЕДОУМЕВАЮЩЕГО МАСТЕРА. НЕДОУМЕВАЮЩИЙ МАСТЕР ПЕРЕШЕЛ С ТВЕРДОЙ КОРИЧНЕВОЙ ГОРЫ НА МЯГКУЮ БЕЛУЮ ГОРУ С МАЛЕНЬКОЙ КРАСНОЙ КАМЕННОЙ ПЛОШКОЙ. НЕДОУМЕВАЮЩИЙ МАСТЕР УВИДЕЛ МЯГКУЮ КРАСНУЮ ХИЖИНУ. НЕДОУМЕВАЮЩИЙ МАСТЕР ЗАХОТЕЛ ЭТУ ХИЖИНУ «ПОЧЕМУ БОДХИДХАРМА ПРИШЕЛ В КИТАЙ?» — СПРОСИЛ НЕДОУМЕВАЮЩИЙ МАСТЕР У ВЕЛИКОГО ПРОСВЕТЛЕННОГО УЧЕНИКА «ПЕРСИКИ БОЛЬШИЕ», — ОТВЕТИЛ УЧЕНИК НЕДОУМЕВАЮЩЕМУ МАСТЕРУ. «КАК МЫ МОЖЕМ НАУЧИТЬСЯ, НЕ УЧАСЬ?» — СПРОСИЛ НЕДОУМЕВАЮЩИЙ МАСТЕР У ВЕЛИКОГО СТАРОГО МАСТЕРА. СТАРЫЙ МАСТЕР УШЕЛ С БЕЛОЙ КАМЕННОЙ Г0025. СТАРЫЙ МАСТЕР ЗАБЛУДИЛСЯ.
Ваша персональная разрешающая процедура для определения подлинности коана, возможно, уже сработала без необходимости использовать Геометрический Код или Искусство Цепочек Дзена. Если отсутствие местоимений или упрощенный синтаксис вас не насторожили, то это должно было сделать странное «Г0025» под конец текста. Что это такое? Простая оплошность — проявление «вируса», который заставил программу напечатать вместо английского слова, обозначающего какой-либо предмет, внутреннее название «узла» (в действительности, атома ЛИСПа), где хранилась вся информация об этом предмете. Таким образом, это окошко, сквозь которое мы можем заглянуть в низший уровень лежащего в основе программы «разума дзена» — уровень, который должен был бы оставаться невидимым. К несчастью, подобных окошек в низший уровень человеческого разума дзен-буддистов не существует.
Последовательность действий, хотя до какой-то степени и случайная, определяется рекурсивной процедурой ЛИСПа под названием КАСКАД. Эта процедура создает цепь действий, связывающихся между собой произвольным образом. Хотя ясно, что степень понимания мира, которой обладает этот сочинитель коанов, далека от совершенства, работа над этой программой продолжается, в надежде сделать ее продукцию более похожей на подлинные коаны.

Рис. 116. Осмысленный рассказ на арабском языке. [A.Khatibi, M.Sijelmassi, «The Splendour of Islamic Calligraphy» Нью-Йорк, изд-во Риццоли, 1976.)
Грамматика для музыки?
А как насчет музыки? Может показаться, что эту область легко закодировать в грамматике типа УСП или какой-нибудь подобной программе. Продолжив это наивное рассуждение, можно сказать, что значение языка опирается на связь с окружающим миром, в то время как музыка — чисто формальна. В звуках музыки нет связи с окружающим миром; это чистый синтаксис — нота следует за нотой, аккорд за аккордом, такт за тактом…
Но постойте — в этом анализе что-то не так. Почему одни произведения гораздо глубже и красивее других? Это происходит потому, что форма в музыке выразительна, и действует на некие подсознательные области нашего разума. Звуки музыки не связаны с рабами или городами-государствами, но они порождают в нас множество эмоций. В этом смысле музыкальное значение все-таки зависит от неуловимых связей между символами и вещами реального мира — в данном случае, «вещами» являются некие скрытые структуры «программ» нашего разума. Нет, простой формализм, подобный грамматике УСП, не породит великой музыки. Псевдо-музыка, подобная псевдо-сказкам, может получиться без труда — и это будет интересным исследованием — но секреты значения в музыке лежат гораздо глубже, чем уровень чистого синтаксиса.
Здесь я должен кое-что пояснить: в принципе, все грамматики типа УСП обладают мощью любого программирующего формализма; так что, если музыкальное значение вообще может быть как-то уловлено (мне кажется, что это возможно), то это может быть сделано в грамматике УСП. Но мне кажется, что эта грамматика будет определять не только музыкальные структуры, но и общую структуру мозга слушателя. Она будет «грамматикой мысли», а не только лишь грамматикой музыки.
ШРДЛУ, программа Винограда
Программа какого типа нужна, чтобы заставить людей признать, что она действительно что-то «понимает»? Что понадобилось бы для того, чтобы ваша интуиция не говорила бы вам, что за программой «ничего нет»?
В 1968-1970 годах Терри Виноград (он же д-р Тире-Рвинога) писал докторскую диссертацию в Массачусетском институте технологии, работая над проблемами языка и понимания. В то время в МИТе многие специалисты по ИИ работали с так называемым «миром блоков» — относительно простой областью, в которой легко было представить задачи компьютерного зрения и языка. Эта область включала стол и разноцветные блоки, похожие на игрушечные кубики — квадратные, удлиненные, треугольные, и т. д. (Иной тип «блочного мира» представлен на картине Магритта «Мысленная арифметика» (рис. 117); я нахожу это название особенно подходящим к данному контексту.) Проблемы зрения в блочном мире МИТа весьма сложны: каким образом сканирование телекамерой сцены с множеством кубиков позволяет компьютеру решить, какие типы блоков там находятся, и каково их взаимное расположение? Некоторые блоки могут лежать на других, некоторые — стоять впереди других; блоки могут отбрасывать тени и т. д.
Однако Виноград не работал над этими аспектами зрения. Он начал с предположения, что блочный мир хорошо представлен в памяти компьютера. После этого ему оставалось решить задачу о том, как заставить компьютер:
(1) понимать по-английски вопросы о ситуации;
(2) отвечать по-английски на вопросы о ситуации;
(3) понимать команды по-английски о манипуляции блоков;
(4) разбивать каждую команду на серию операций, которые он может выполнить;
(5) понимать, что он делает и с какой целью;
(6) описывать свои действия и их цель по-английски.
Может показаться, что хорошо было бы разбить общую программу на серию модулярных подпрограмм, где каждой части проблемы соответствовал бы некий модуль, и затем, после того, как каждый модуль был бы разработан отдельно, соединить их вместе. Однако Виноград нашел, что стратегия разработки независимых модулей представляла значительные трудности.
Его радикальный подход бросил вызов теории о том, что интеллект может быть подразделен на независимые и полунезависимые части. Созданная Виноградом программа ШРДЛУ (названная так в честь старого кода «ЕТАОЙН ШРДЛУ», используемого операторами линотипических машин для отметки опечаток в газетных столбцах) не разбивала задачу на отдельные концептуальные части. Операции деления предложений, производства внутренних представлений, рассуждений о мире, представленном внутри нее самой, нахождение ответов на вопросы и т. д. были тесно переплетены во внутреннем представлении процедурных знаний программы. Некоторые критики утверждали, что программа Винограда так запутана, что не представляет вообще никакой «теории» о языке и не способствует нашему пониманию процессов мышления. По моему мнению, ничто не может быть так далеко от истины как подобная критика. Шедевр, подобный ШРДЛУ, может не быть изоморфным тому, что делаем мы — безусловно, мы не должны думать, что эта программа достигла «уровня символов» — но как сам акт создания ШРДЛУ, так и размышления об этой программе позволяют узнать очень многое о работе интеллекта.

Рис. 117. Рене Магритт. «Мысленная арифметика» (1931).
Структура ШРДЛУ
В действительности, ШРДЛУ все же состоит из отдельных процедур, каждая из которых содержит некие знания о мире; но эти процедуры настолько зависят друг от друга, что их невозможно четко разграничить. Программа похожа на крепко затянутый узел, который очень трудно распутать; но тот факт, что его не удается развязать, не означает того, что его невозможно понять. Может существовать элегантное геометрическое описание всего узла, даже если физически он запутан. Здесь уместно вспомнить метафору из «Приношения МУ» и сравнить эту проблему со взглядом на фруктовый сад под «естественным» углом.
Виноград очень хорошо описал ШРДЛУ. Ниже я привожу отрывок из его статьи в книге Шанка и Колби:
Одна из основных идей, лежащих в основе этой модели, заключается в том, что всякое использование языка можно рассматривать как активацию неких процедур в слушателе. Мы можем думать о любом высказывании как о программе, которая является косвенной причиной выполнения неких операций в когнитивной системе слушателя. Это «составление программ» неявно, поскольку мы имеем дело с разумным интерпретатором, реакция которого может весьма отличаться от той, которую хотел вызвать говорящий. Точная форма «программы», воспринимаемой слушателем, определяется его знанием о мире, его отношением к говорящему и так далее. В нашей программе мы имели дело с простой версией этого процесса интерпретации, происходящего внутри робота. Каждое высказывание, интерпретированное роботом, превращалось в набор команд ПЛАННЕРа. Программа, созданная таким образом, затем использовалась для достижения желаемого эффекта.
ПЛАННЕР облегчает упрощение задач
Упомянутый выше язык ПЛАННЕР — это один из языков ИИ; его основной чертой является то, что в него встроены некоторые операции, необходимые для упрощения задач, — например, рекурсивный процесс создания дерева подзадач, подподзадач и так далее. Это значит, что программисту уже не приходится объяснять подобные процессы снова и снова — они автоматически следуют из так называемых постановок задач. Человек, читающий составленную на ПЛАННЕРе программу, не заметит явных ссылок на эти операции; на компьютерном жаргоне говорится, что они прозрачны для пользователя. Если одна из ветвей дерева не сможет выполнить своей задачи, то ПЛАННЕР вернется назад и попробует другую дорогу, «Возврат» — ключевое слово в ПЛАННЕРе.
Программа Винограда успешно воспользовалась этими чертами ПЛАННЕРа — или, точнее, МИКРОПЛАННЕРа, частичной реализации замыслов для ПЛАННЕРа. Однако за последние несколько лет специалисты в области ИИ решили, что автоматический возврат, используемый в ПЛАННЕРе, имеет свои определенные недостатки и маловероятно, что он сможет привести к цели; так что они сосредоточили свои усилия на других областях ИИ.
Давайте посмотрим на дальнейшие комментарии Винограда о ШРДЛУ:
Определение значения каждого слова — эта программа, вызываемая в нужный момент анализа; она может производить произвольные вычисления, включающие данное высказывание и физическую ситуацию в данный момент.
Среди примеров, которые приводит Виноград, встречается следующий:
Различными возможностями значения слова «the» являются процедуры, которые проверяют разнообразные факты, касающиеся контекста, и затем определяют нужные действия, такие как «искать в базе данных описание единственного предмета, совпадающего с этим описанием» или «подтвердить, что описываемый предмет является единственным для говорящего». В программу включены различные типы эвристики для определения того, какие части контекста важны.
(Как читатель, вероятно, догадался, программа ШРДЛУ была англоязычна; задачи, которые ей приходилось решать, были специфичны для английского языка. В Диалоге «ШРДЛУ» мы постарались передать на русском как можно точнее не только содержание беседы с программой, но и ее форму, со всеми двусмысленностями и шероховатостями речи; однако комментарий Винограда о проблеме использования определенного артикля «the» был оставлен без изменения за отсутствием точного русского эквивалента. — Прим. перев.)
Удивительно то, насколько значительна эта проблема артикля «the». В русском аналогичные проблемы представляют, например, такие слова как «что», «в», «на», «и», «к». Можно с уверенностью сказать, что создание программы, которая была бы способна правильно использовать все значения этих слов, было бы эквивалентно решению проблемы ИИ, и таким образом, означало бы ответ на вопрос, что такое разум и сознание. Небольшое отступление: согласно частотному словарю Джона Б. Кэрролла (John В. Carroll, «Word Frequency Book»), пять наиболее часто употребляющихся в английском существительных — это «время», «люди», «дорога», «вода» и «слова», в таком порядке. Удивительнее всего то, что большинство людей не подозревает, что они думают настолько абстрактными категориями. Девять человек из десяти назовут «дом», «работа», «деньги», «человек»… И, раз уж мы заговорили о частотности, заметьте, что наиболее часто используемыми буквами английского языка, согласно Мергенталеру, являются «ETAOIN SHRDLU», в таком порядке.
Одна из интересных черт ШРДЛУ, противоречащая стереотипу компьютеров как машин, щелкающих числа подобно орешкам, это то, что, как указывает Виноград, эта система «не принимает чисел в их цифровой форме и умеет считать только до десяти». Несмотря на всю математику, лежащую в ее основе, ШРДЛУ — математический неуч! Как и мадам Мура Вейник, ШРДЛУ ничего не знает о составляющих ее низших уровнях. Ее знания, в основном, процедурные (см. в особенности замечание д-ра Тире-Рвинога в секции 11 предыдущего диалога).
Интересно сравнить процедурные знания, заключенные в ШРДЛУ, со знаниями моей создающей предложения программы. Все синтаксические познания моей программы процедурно включались в Увеличенные Схемы Переходов, написанные на языке АЛГОЛ; но семантические познания — информация о принадлежности к тому или иному семантическому классу — были статичны: они содержались в коротком списке цифр после каждого слова. Там было, правда, несколько служебных слов, таких как «to have», «to be» и тому подобное, которые были полностью представлены в процедурном виде в АЛГОЛе, но это было исключением. С другой стороны, в ШРДЛУ все слова были представлены в программах. Это показывает, что несмотря на то, что теоретически программы эквивалентны данным, на практике выбор способа представления знаний влечет за собой серьезные последствия.
Синтаксис и семантика
Теперь слово опять за Виноградом:
Наша программа не работает, сначала разделяя предложение на части, затем проводя семантический анализ и затем давая логический ответ. Когда машина пытается понять предложение, эти три действия происходят одновременно. Как только начинает вырисовываться некая синтаксическая структура, тут же вызывается семантическая программа, чтобы проверить, есть ли в этой структуре смысл; ее ответ может направлять дальнейшее синтаксическое подразделение. Решая, имеет ли данная структура смысл, семантическая программа может прибегать к логическому анализу и задавать вопросы о реальном мире. Например, в секции 34 Диалога («расположи голубую пирамиду на кубике в коробке»), первым возможным делением было «голубая пирамида на кубике». В этот момент в действие вступает семантический анализ, который определяет, что подобное деление не соответствует реальной ситуации. После этого, программа синтаксическего разбора находит следующего кандидата: «голубая пирамида»; затем она выделяет группу «на кубике в коробке» как самостоятельную фразу, указывающую на расположение… Таким образом, разные типы анализа находятся в постоянном взаимодействии, и результаты одного из них влияют на результаты других.
Очень интересно то, что в естественном языке синтаксис и семантика так глубоко переплетены. В предыдущей главе, обсуждая ускользающее понятие «формы», мы подразделили его на две категории: синтаксическая форма, котоорую можно обнаружить с помощью предсказуемо конечной разрешающей процедуры, и семантическая форма, которую таким образом обнаружить нельзя. Но здесь Виноград говорит нам, что, по крайней мере, когда слова «синтаксис» и «семантика» употребляются в их обычном значении, в естественном языке они сливаются друг с другом. Внешняя форма предложения — его состав в терминах элементарных знаков — не делится так четко на синтаксический и семантический аспекты. Это очень важный для лингвистики момент. Далее приводятся заключительные замечания Винограда о ШРДЛУ.
Давайте посмотрим, что делает система с простым описанием, например, «красный кубик, который поддерживает пирамиду». Это описание использует понятия БЛОК, КРАСНЫЙ, ПИРАМИДА, и РАВНОМЕРНЫЙ, каждое из которых является частью категоризации мира, лежащей в основе системы. Результат может быть представлен в виде блока-схемы, как на рис. 118. Обратите внимание, что это программа предназначена для нахождения предмета, совпадающего с данным описанием. Затем она будет включена в команду сделать нечто с данным предметом или в вопрос об этом предмете. Или же, если это описание будет частью предложения, оно станет частью программы, созданной для представления этого значения для его дальнейшего использования. Заметьте, что этот кусок программы также мог бы быть использован для проверки того, совпадает ли предмет с данным описанием, если бы первая команда НАЙТИ была заранее ограничена поисками нужного нам предмета.С первого взгляда кажется, что у этой программы — слишком сложная структура, поскольку нам не нравится думать, что значение простой фразы может содержать петли, проверку условий перехода на другую ветвь и другие подобные детали. Чтобы решить эту проблему, нам необходим такой внутренний язык, в котором петли и проверки были бы простейшими элементами и в котором представление процессов было бы так же просто, как и их описание. Программа, представленная на рис. 118, на языке ПЛАННЕР выглядела бы примерно так:(ЦЕЛЬ (Есть ? кубик X1))(ЦЕЛЬ (Цвет ? X1 красный))(ЦЕЛЬ (Равномерный ? X1))(ЦЕЛЬ (Есть ? пирамида Х2))(ЦЕЛЬ (Есть ? кубик X1))(ЦЕЛЬ (? X1 поддерживает ?Х2))Петли блока-схемы подразумеваются в структуре контроля возврата. Правильность описания оценивается путем следования вниз по списку до тех пор, пока какая-нибудь из целей не окажется невыполнимой; тогда программа автоматически отступает к тому моменту, когда она приняла последнее решение, и пробует другой путь. Решение может быть принято всякий раз, когда вводится новое название предмета или новая ПЕРЕМЕННАЯ (отмеченная префиксом «?»). Переменные используются для сопоставления с образцом. Если они уже обозначают некий предмет, программа сопоставления проверяет, выполнима ли цель для данного предмета. Если нет, то эта программа ищет все возможные предметы, для которых эта цель выполнима, выбирая один предмет и совершая последующие шаги до тех пор, пока ей не придется отступить. В таком случае она начинает работать со следующим подходящим предметом. Таким образом, неявным является даже различие между выбором и проверкой.
При разработке этой программы было принято важное стратегическое решение: не переводить полностью с английского на ЛИСП, а только частично — на ПЛАННЕР. Таким образом, поскольку интерпретатор ПЛАННЕР сам написан на ЛИСПе, между языком высшего уровня (английским) и языком низшего уровня (машинным) был введен новый промежуточный уровень (ПЛАННЕР). После того, как фрагмент английского предложения переводится в программу на ПЛАННЕРе, эта программа может быть послана на интерпретер ПЛАННЕРа, освобождая высший уровень ШРДЛУ для работы над другими задачами.
Постоянно приходится решать следующие проблемы: сколько уровней должно быть у системы? Сколько и какой тип «интеллекта» надо располагать на каждом из этих уровней? Сегодня эти проблемы — одни их самых трудных в ИИ. Поскольку мы знаем так мало о настоящем разуме, нам очень трудно решить, какой уровень искусственной разумной системы должен выполнять ту или иную часть задачи.
Это позволяет вам лучше понять те проблемы, что стоят за предыдущим Диалогом. В следующей главе мы рассмотрим новые смелые идеи в области ИИ.
Рис. 118. Процедурное представление фразы «красный кубик, который поддерживает пирамиду». (Roger Schank and Kenneth Colby, «Computer Models of Thought and Language», стр. 172)
Назад: ШРДЛУ
Дальше: Контрафактус

