ГЛАВА 2
ВЛАСТЕЛИН АЛГОРИТМОВ
Широта применения машинного обучения поразительна, но еще больше потрясает, что одни и те же алгоритмы умеют делать различные вещи. Во всех других областях для решения двух разных проблем приходится писать две разные программы. Они могут частично использовать одинаковую инфраструктуру, например те же языки программирования или ту же систему баз данных, но программа, скажем, для игры в шахматы совершенно бесполезна, если задача — обработать заявления о выдаче кредитных карт. В машинном обучении одни и те же алгоритмы могут делать и то и другое при условии, что вы дадите им соответствующие данные, на которых можно учиться. По сути, за огромным большинством приложений машинного обучения стоят всего несколько алгоритмов, с которыми мы познакомимся в следующих главах.
Посмотрите, например, на наивный байесовский классификатор — обучающийся алгоритм, который можно выразить в виде короткого уравнения. Если взять базу данных из историй болезни — симптомы, результаты анализов, наличие или отсутствие сопутствующих заболеваний, — этот алгоритм может научиться диагностировать болезнь в долю секунды, и часто лучше, чем врачи, которые много лет провели в медицинском институте. Он может победить и медицинские экспертные системы, на создание которых ушли тысячи человеко-часов. При этом тот же самый алгоритм широко используется для фильтрации спама, хотя на первый взгляд у спам-фильтров нет ничего общего с медицинской диагностикой. Другой простой обучающийся алгоритм, так называемый метод ближайших соседей, используют для массы задач — от распознавания почерка до управления манипуляторами в робототехнике и отбора книг и фильмов, которые могут понравиться клиенту. А обучающиеся алгоритмы дерева решений одинаково искусно определят, можно ли выдать вам кредитную карточку, найдут границы сплайсинга в ДНК и выберут следующий ход в шахматной партии.
Одни и те же обучающиеся алгоритмы не только способны выполнять бесконечно разнообразные задачи. По сравнению с алгоритмами, на смену которым они приходят, алгоритмы машинного обучения потрясающе просты. Большинство из них можно выразить в нескольких сотнях строк кода или, может быть, нескольких тысячах, если добавить много «примочек». В то же время программы, которые они вытесняют, иногда занимают сотни тысяч или даже миллионы строк кода, а ведь один обучающийся алгоритм способен породить неограниченное количество различных программ.
Если столь малый набор обучающихся алгоритмов может так много, возникает логичный вопрос: реально ли, чтобы один такой алгоритм делал вообще все? Другими словами, сможет ли единственный алгоритм научиться всему, что можно узнать из данных? Эта проблема — очень крепкий орешек, ведь сюда входит все, что знает взрослый человек, все, что создала эволюция, весь комплекс научных знаний. По правде говоря, все важнейшие алгоритмы машинного обучения, включая метод ближайших соседей, дерево принятия решений и байесовские сети (обобщение наивного байесовского классификатора), универсальны, то есть, если дать им достаточно соответствующих данных, они смогут аппроксимировать любую функцию сколь угодно точно: на языке математики это значит «научиться чему угодно». Ловушка в том, что «достаточно данных» может означать «бесконечный объем данных». Для обучения на основе конечных данных нужны допущения, и, как мы увидим, разные обучающиеся алгоритмы делают их по-разному, поэтому хорошо подходят для решения одних задач и не очень — для других.
А если не оставлять эти допущения внутри алгоритма, а делать их явными входными данными, наряду с собственно данными, и предоставлять пользователю право выбора, какие из них подключать и, возможно, даже задавать новые? Есть ли алгоритм, который может взять любые данные и предположения и на выходе дать скрытые в них знания? Я думаю, такой алгоритм существует. Конечно, нужно как-то ограничить эти допущения, иначе можно обмануть самого себя, дав алгоритму все искомое знание или что-то схожее в виде допущений. Однако есть много способов этого избежать — от ограничения объема вводных до требования, чтобы исходные допущения не были больше, чем допущения текущего алгоритма.
В таком случае вопрос сводится к следующему: насколько слабыми могут быть допущения, чтобы все еще позволять получать из конечных данных все полезное знание? Обратите внимание на слово «полезное»: нас интересует только знание о нашем мире, а не о несуществующих мирах, поэтому изобретение универсального обучающегося алгоритма сводится к открытию глубочайших закономерностей нашей Вселенной, общих для всех явлений, а затем — к нахождению эффективного с точки зрения вычислений способа соединить их с данными. Как мы увидим, требование вычислительной эффективности не позволяет использовать в качестве таких закономерностей законы физики, однако оно не подразумевает, что универсальный алгоритм машинного обучения должен быть столь же эффективным, как более специализированные. Как часто бывает в информатике, мы готовы пожертвовать эффективностью ради универсальности.
Это также касается количества данных, необходимого, чтобы получить искомое знание: универсальному обучающемуся алгоритму в целом потребуется больше данных, чем специализированному, однако это не беда, при условии, что эти данные есть в нашем распоряжении, а чем больше становится общий объем данных, тем больше вероятность, что их для наших целей окажется достаточно.
Итак, вот центральная гипотеза этой книги:
Все знание — прошлое, настоящее и будущее — можно извлечь из данных с помощью одного универсального обучающегося алгоритма.
Я называю этот алгоритм Верховным. Если его создание оказалось бы возможным, это стало бы одним из величайших научных достижений за всю историю человечества. Более того, Верховный алгоритм — последнее, что нам придется изобрести, потому что, как только мы «спустим его с цепи», он сам изобретет вообще все, что только можно придумать. Все, что нам нужно, — дать ему достаточно подходящих данных, и он откроет соответствующее знание. Дайте ему видеопоток, и он научится видеть. Дайте библиотеку — и он научится читать. Дайте результаты физических экспериментов, и он сформулирует законы физики. Дайте данные кристаллографии ДНК, и он откроет структуру этой молекулы.
Наверное, это звучит неправдоподобно. Разве может один алгоритм получить так много разных знаний, причем таких сложных? Но на самом деле на существование Верховного алгоритма указывает много свидетельств. Давайте с ними познакомимся.
Аргумент из области нейробиологии
В апреле 2000 года группа нейробиологов из Массачусетского технологического института сообщила в журнале Nature о результатах удивительного эксперимента: они изменили мозг хорька, перенаправив нервы из глаз в слуховую кору (часть мозга, отвечающую за обработку звуков), а из ушей — в зрительную. Казалось бы, в результате этих манипуляций хорек должен был стать тяжелым инвалидом, но этого не произошло: слуховая кора научилась видеть, зрительная — слышать. У нормальных млекопитающих в зрительной коре есть карта сетчатки: нейроны, соединенные с близлежащими областями сетчатки, в коре расположены по соседству. У подопытных хорьков такая же карта сетчатки сформировалась в слуховой коре. Если зрительные данные направить в соматосенсорную кору, отвечающую за осязание, научится видеть и она. Такая способность есть и у других млекопитающих.
У слепых от рождения зрительная кора может брать на себя другие функции головного мозга. У глухих то же самое делает слуховая кора. Слепые могут научиться «видеть» с помощью языка, если прикрепить к нему электроды и направить по ним зрительные образы от прикрепленной к голове камеры. Высокое напряжение будет соответствовать ярким пикселям, низкое — темным. Слепой ребенок по имени Бен Андервуд научился ориентироваться в пространстве с помощью эхолокации, как летучие мыши. Щелкая языком и слушая эхо, он мог ходить, не натыкаясь на препятствия, ездить на скейтборде и даже играть в баскетбол. Все это доказывает, что головной мозг везде использует один и тот же алгоритм обучения и области, выделенные для различных чувств, отличаются лишь поступающими в них входными данными (например, от глаз, ушей, носа). В свою очередь, ассоциативные зоны выполняют свои функции, потому что связаны с многочисленными сенсорными областями, а «исполнительные» свои — потому что соединяют ассоциативные зоны с двигательными нервами.
Изучение коры головного мозга под микроскопом подтверждает этот вывод. Везде повторяется тот же рисунок соединений: шестислойные колонны, петли обратной связи, ведущие в другую структуру мозга — зрительный бугор, а также повторяющиеся короткие тормозящие пути и более длинные возбуждающие. Имеется некоторое количество вариантов этой схемы, но они скорее похожи на разные параметры, настройки одного и того же алгоритма, чем на разные алгоритмы. Сенсорные зоны низкого уровня отличаются сильнее, но, как показали описанные выше эксперименты, и эти отличия не критичны. Мозжечок, самая древняя эволюционно часть головного мозга, которая отвечает за общую координацию движений, явно имеет другую, очень регулярную архитектуру, основанную на намного меньших нейронах, поэтому может показаться, что по крайней мере обучение движениям происходит по другим алгоритмам. Однако если у человека поврежден мозжечок, кора головного мозга берет на себя его функцию, то есть, вероятно, эволюция сохранила мозжечок не потому, что он делает то, чего не умеет кора, а просто потому, что так эффективнее.
Вычисления, происходящие внутри головного мозга, тоже единообразны. Вся информация представлена в виде электрических импульсов между определенными нейронами. Одинаков и механизм обучения: воспоминания формируются путем биохимического укрепления соединений между действующими вместе нейронами — так называемой долговременной потенциации. Все это верно и для животных: хотя мозг человека необычно велик, принципы его строения, по-видимому, те же самые.
Еще одна линия аргументов в пользу единообразия коры головного мозга — это, так сказать, бедность генома. Количество соединений в мозге человека более чем в миллион раз превышает количество «букв» в геноме, поэтому геном физически не в состоянии подробно закодировать строение мозга.
Однако самый важный аргумент в пользу того, что мозг — это Верховный алгоритм, заключается в том, что он отвечает за все, что мы способны воспринять и представить. Мы не узнаем о существовании того или иного явления, если мозг не сможет его постичь: либо просто не заметим, либо посчитаем случайностью. Так или иначе, если «встроить» головной мозг в компьютер в виде алгоритма, он сможет узнать все, что можем узнать мы, поэтому один из подходов к разработке Верховного алгоритма — и, пожалуй, самый популярный — обратный инжиниринг головного мозга. Джефф Хокинс затронул его в своей книге On Intelligence. С ним Рэймонд Курцвейл связывает свои надежды на сингулярность — появление искусственного интеллекта, который значительно превосходит человеческий. И даже пробует силы в этом подходе в своей книге How to Create a Mind. Тем не менее, как мы увидим, это лишь один из нескольких возможных подходов, причем не обязательно самый многообещающий, потому что головной мозг невероятно сложен, а мы все еще находимся на очень ранних стадиях его расшифровки. С другой стороны, если мы не сможем отыскать Верховный алгоритм, никакой сингулярности в обозримом будущем не предвидится.
С теорией единого строения коры согласны не все нейробиологи, и для прояснения этого вопроса потребуются дальнейшие исследования — ведь жаркие дебаты вызывает даже вопрос, где пределы способностей мозга. Но если есть то, что знаем мы, а мозг не может узнать, это должна была узнать эволюция.
Аргумент из области эволюции
Нескончаемое разнообразие форм жизни на Земле — результат действия единого механизма: естественного отбора. Что еще примечательнее, информатикам хорошо знаком механизм такого типа: это итеративный поиск, при котором проблему решают путем перебора множества кандидатов, выбора и модификации лучших и повторения этих шагов столько раз, сколько необходимо. Эволюция тоже алгоритм. Перефразируя Чарльза Бэббиджа, пионера вычислительных машин, жившего в Викторианскую эпоху, Бог создал не виды, а алгоритм создания видов. «Бесконечное число самых прекрасных и самых изумительных форм», о котором Дарвин пишет в заключении к «Происхождению видов», скрывает от нас самое прекрасное — единство. Все эти формы закодированы в цепочках ДНК, и все они возникают путем модификации и сочетания этих цепочек. Кто бы подумал, что такой алгоритм способен породить нас с вами? Если механизмы эволюции оказались способны создать человека, они, видимо, смогут узнать все, что только можно узнать, если ввести их в достаточно мощный компьютер. И действительно, эволюционное программирование, основанное на симуляции естественного отбора, — популярная отрасль машинного обучения. Таким образом, эволюция — еще одна многообещающая тропинка, которая может привести нас к Верховному алгоритму.
Эволюция — это высший пример того, на что способен единый алгоритм обучения, если дать ему достаточно данных. Входные данные для эволюции — это опыт и судьба всех когда-либо существовавших живых существ (вот это правда большие данные). Но с другой стороны, более трех миллиардов лет на самом большом компьютере на нашей планете — самой планете Земля — работает эволюция. Поэтому хотелось бы, чтобы ее компьютерная копия была быстрее и требовала меньше данных, чем оригинал. Какая модель лучше подходит для Верховного алгоритма: эволюция или мозг? Это похоже на старый спор о «наследственности или воспитании», и, как человека формирует и то и другое, возможно, истинный Верховный алгоритм будет содержать оба элемента.
Аргумент из области физики
В вышедшем в 1959 году знаменитом эссе физик и нобелевский лауреат Юджин Вигнер восхищался «необъяснимой эффективностью математики в естественных науках». Каким чудом законы, выведенные на основе немногочисленных наблюдений, применимы далеко за их пределами? И почему законы на много порядков точнее, чем данные, на которых они основаны? А самое главное, почему простой, абстрактный язык математики может так точно описывать столь многое в нашем бесконечно сложном мире? Вигнер считал это глубокой тайной, в равной степени радостной и непостижимой. Тем не менее все так и есть, и Верховный алгоритм — логическое продолжение этого феномена.
Если бы мир был просто цветущим и жужжащим хаосом, у нас был бы повод усомниться в существовании универсального обучающегося алгоритма. Однако если все вокруг нас — это следствие нескольких простых законов, вполне может оказаться, что единственный алгоритм может путем индукции сделать все возможные выводы. Все, что ему для этого потребуется, — срезать путь к следствиям законов, заменив невероятно длинные математические выкладки намного более короткими и основанными непосредственно на наблюдениях.
Например, мы полагаем, что законы физики породили эволюцию, но не знаем, как именно. Вместо поиска связывающей их цепочки следствий вывод о естественном отборе можно сделать непосредственно на основе наблюдений, как и поступил Дарвин. На основе тех же наблюдений можно было бы прийти к бесчисленному множеству неверных умозаключений, но большинство из них никогда не придут нам в голову, потому что на наши выводы влияют обширные познания о мире, и полученное знание согласуется с законами природы.
В какой мере характер физических законов распространяется на более высокие области знания, например биологию и социологию, нам еще предстоит узнать, но исследования хаоса дают много завораживающих примеров схожего поведения в очень разных системах, и теория универсальности это объясняет. Красивый пример того, как очень простая процедура итерации может породить неистощимое разнообразие форм, — множество Мандельброта. Если горы, реки, облака и деревья — результат аналогичных процессов, а фрактальная геометрия показывает, что так оно и есть, возможно, эти процессы — просто разная параметризация одной-единственной процедуры, которую мы можем вывести на их основе.
В физике те же уравнения, примененные к разным параметрам, часто описывают явления в совершенно разных областях, например квантовой механике, электромагнетизме и динамике жидкостей. Волновое уравнение, уравнение диффузии, уравнение Пуассона: если открыть что-то в одной отрасли, будет проще обнаружить аналоги в других, а если научиться решать одно из уравнений, это даст решение для всех сразу. Более того, эти уравнения довольно простые, и в них учитываются те же несколько производных параметров в отношении пространства и времени. Довольно вероятно, что они частные случаи некоего более общего уравнения, и все, что нужно сделать Верховному алгоритму, — выяснить, как конкретизировать его для частных наборов данных.
Еще одну линию доказательств можно найти в оптимизации — математической дисциплине, занимающейся нахождением аргумента, который дает максимальное значение функции. Например, поиск последовательности биржевых сделок, максимизирующей ваш совокупный доход, — это задача по оптимизации. В оптимизации простые функции часто дают удивительно сложные решения. Оптимизация играет выдающуюся роль практически во всех областях науки, технологии и бизнеса, включая машинное обучение. Каждая область оптимизируется в рамках, очерченных оптимизациями в других областях. Мы пытаемся максимизировать наше счастье в рамках экономических ограничений, которые, в свою очередь, становятся лучшими решениями для компаний в пределах доступных технологий, а те представляют собой лучшие решения, которые мы можем найти в рамках биологических и физических ограничений. Биология — результат оптимизации, произведенной эволюцией в рамках ограничений физики и химии, а сами законы физики — те же решения проблем оптимизации. Наверное, все, что существует, — это прогрессирующее решение всеобщей проблемы оптимизации, и Верховный алгоритм следует из формулировки этой проблемы.
Физики и математики — не единственные, кто находит неожиданные связи между разными областями. В своей книге Consilience («Непротиворечивость») видный биолог Эдвард Уилсон страстно отстаивает единство всего знания — от точных наук до гуманитарных дисциплин. Верховный алгоритм — высочайшее выражение этого единства: если знание объединено общей схемой, значит, Верховный алгоритм существует, и наоборот.
Тем не менее простота физики уникальна. За пределами физики и инженерии достижения математики не так бесспорны: иногда она представляет собой единственный разумный и эффективный путь, а иногда математические модели слишком грубы, чтобы быть полезными. Тенденция к излишнему упрощению вытекает, однако, из ограничений человеческого разума, а не только из ограничений математики как таковой. Жесткий (вернее, студенистый) диск в голове человека в основном занят восприятием и движениями, и для упражнений в математике нам приходится заимствовать области, предназначенные эволюцией для языка. У компьютеров таких ограничений нет, и они могут с легкостью превращать большие объемы данных в очень сложные модели. Машинное обучение — это то, что получается, когда необъяснимая эффективность математики сливается с необъяснимой эффективностью данных. Биология и социология никогда не будут такими простыми, как физика, однако метод, благодаря которому мы откроем их истины, может оказаться несложным.
Аргумент из области статистики
Согласно одной из школ статистики, в основе всего обучения лежит одна простая формула, а именно теорема Байеса, которая определяет, как корректировать предположения при появлении новых доказательств. Байесовский алгоритм начинает с набора гипотез о мире. Когда он видит новые данные, гипотезы, согласующиеся с ними, становятся более вероятными, а те, что с ним не согласуются, — менее вероятными (или даже невозможными). После того как было рассмотрено достаточно данных, начинает доминировать одна или несколько гипотез. Например, я ищу программу, которая точно предсказывает движение курсов акций, и, если акции, которым программа-кандидат предсказывала падение, пойдут вверх, эта программа потеряет доверие. После того как я рассмотрю некоторое число кандидатов, останутся лишь некоторые достоверные, и они будут воплощать мои знания о рынке акций.
Теорема Байеса — это машина, которая превращает данные в знания. Ее сторонники полагают, что это вообще единственно верный способ превращать данные в знания. Если они правы, Верховным алгоритмом будет либо сама теорема Байеса, либо он будет на ней основан. У других специалистов по статистике имеются серьезные сомнения в отношении того, как пользуются теоремой Байеса, и они предпочитают другие способы обучения на основе данных. До появления компьютеров теорему Байеса можно было применять только к очень простым проблемам, и предположение, что она может быть универсальным алгоритмом машинного обучения, казалось весьма натянутым. Однако при большом объеме данных и высокой эффективности вычислений теорема Байеса может найти применение в обширных областях гипотез и распространиться на все области знания, какие только можно себе представить. Если у байесовского обучения и есть какие-то границы, пока они неизвестны.
Аргумент из области информатики
На старших курсах колледжа я любил поиграть в тетрис. Игра очень затягивала: сверху падали разные фигуры, и их нужно было уместить как можно плотнее. Когда гора блоков достигала верхней границы экрана, игра заканчивалась. Тогда я и не подозревал, что это было мое введение в самую важную в теоретической информатике NP-полную задачу. Оказывается, овладеть тетрисом — по-настоящему его постичь — не пустяковое дело, а одна из самых полезных вещей, которую только можно сделать. Справившись с задачей тетриса, можно одним ударом решить тысячи сложнейших, невероятно важных проблем науки, технологии и менеджмента. Дело в том, что по сути они одна и та же проблема, и это один из самых захватывающих фактов во всей науке.
Как белки принимают характерную для них форму? Как воссоздавать историю эволюции видов по их ДНК? Как доказывать теоремы с помощью пропозициональной логики? Как выявлять возможности для скупки ценных бумаг с учетом транзакционных издержек? Как определять трехмерную форму по двухмерному изображению? Сжатие данных на дисках, формирование стабильных коалиций в политике, моделирование турбулентности в сдвиговых потоках, нахождение самого безопасного портфеля инвестиций с заданной выручкой и кратчайшего пути, чтобы посетить ряд городов, оптимальное расположение элементов на микросхемах, лучшая расстановка сенсоров в экосистеме, транспортные потоки, социальное обеспечение и (самое главное) как выиграть в тетрис — все это NP-полные задачи. Если получится решить одну из них, можно будет эффективно решать все задачи класса NP. Кто бы мог предположить, что все эти проблемы, такие разные на вид, — в действительности одно и то же? Но если это так, то вполне возможно, что их все (или, точнее, все частные случаи, имеющие эффективное решение) может научиться решать один алгоритм.
P и NP (к сожалению, названия не самые очевидные) — важнейшие классы проблем в информатике. Проблема относится к группе P, если ее можно эффективно решить, а к NP — если можно эффективно проверить ее решение. Знаменитый вопрос о равенстве классов P и NP — каждая ли эффективно проверяемая проблема эффективно решаема. Благодаря NP-полноте все, что нужно для ответа на этот вопрос, — доказать, что одна NP-полная задача эффективно решаема (или нет). NP — не самый сложный класс проблем в информатике, но, по-видимому, самый сложный из «реалистичных»: если нельзя даже проверить решение проблемы до скончания времен, какой смысл пытаться ее решить? Люди хорошо научились приблизительно решать NP-задачи, и, наоборот, проблемы, которые нам кажутся интересными (тетрис, например), имеют в себе что-то от NP-класса. Согласно одному из определений искусственного интеллекта, он заключается в нахождении эвристических решений для NP-полных задач. Часто мы решаем такие задачи, редуцируя их до выполнимости. Классическая NP-полная задача звучит так: может ли данная логическая формула в принципе быть истинной или она противоречит самой себе? Если бы мы изобрели обучающийся алгоритм, способный научиться решать проблему выполнимости, он стал бы хорошим кандидатом на звание Верховного.
Но и без NP-полных задач само наличие компьютеров — серьезнейший признак существования Верховного алгоритма. Если бы вы отправились в начало ХХ века и рассказали, что вскоре будет изобретена машина, которая сможет решать проблемы во всех сферах человеческой деятельности — одна и та же машина для всех проблем, — никто бы не поверил. Вам бы объяснили, что машины могут делать что-то одно: сеялки не печатают, а пишущие машинки не сеют. Затем, в 1936 году, Алан Тьюринг придумал любопытное устройство с лентой и головкой, которая читает и пишет символы. Сегодня оно известно как машина Тьюринга. С ее помощью может быть решена каждая проблема, какую только можно решить с помощью логической дедукции. Более того, так называемая универсальная машина Тьюринга может симулировать любую другую, прочтя с ленты ее спецификацию, — другими словами, ее можно запрограммировать делать что угодно.
Верховный алгоритм предназначен для индукции, то есть процесса обучения, точно так же как машина Тьюринга для дедукции. Он может научиться симулировать любые другие алгоритмы путем чтения примеров их поведения на входе и выходе. Равно как многие модели вычислений эквивалентны машине Тьюринга, вероятно, существует много эквивалентных формулировок универсального обучающегося алгоритма. Суть в том, чтобы найти первую такую формулировку, как Тьюринг в свое время нашел первый вариант многоцелевого компьютера.
Алгоритмы машинного обучения против инженерии знаний
Конечно, к Верховному алгоритму скептически относятся столько же людей, сколько испытывают по поводу его существования энтузиазм. Сомнения — это естественно, особенно когда речь идет о своего рода «серебряной пуле». Самое решительное сопротивление оказывает вековечный враг машинного обучения — инженерия знаний. Ее адепты считают, что знание нельзя получить автоматически: его должны вложить в компьютер эксперты. Конечно, обучающиеся алгоритмы тоже могут извлечь кое-что из данных, но это никоим образом не настоящее знание. Для инженеров знаний большие данные — не золотая жила, а обманка.
На заре искусственного интеллекта машинное обучение представлялось очевидным путем к компьютерам с разумом, подобным человеческому. Тьюринг и другие ученые думали, что это единственный приемлемый путь. Однако затем инженеры знаний нанесли ответный удар, и к 1970 году машинное обучение было жестко оттеснено на второй план. В какой-то момент, в 1980-х годах, казалось, что инженерия знаний вот-вот завоюет мир, а компании и целые государства вкладывали в нее огромные инвестиции. Но вскоре пришло разочарование, и машинное обучение начало свой неумолимый рост — сначала тихо, а потом на гребне растущего вала данных.
Тем не менее все успехи машинного обучения не убедили инженеров знаний. Они уверены, что вскоре ограничения этого подхода станут очевидными и маятник качнется в другую сторону. Эту точку зрения разделяет Марвин Минский, профессор Массачусетского технологического института и пионер в области искусственного интеллекта. Минский не просто скептически относится к машинному обучению как альтернативе инженерии знаний: он вообще не верит, что в науке об искусственном интеллекте можно что-то объединить. Теория интеллекта по Минскому изложена в его книге The Society of Mind («Общество разума»), где он замечает, что «разум — это одна вещь за другой и ничего больше». Вся книга — длинный перечень, сотни отдельных идей, к каждой из которых дается краткое описание. Проблема такого подхода к искусственному интеллекту — в том, что он не работает. Это как коллекционирование марок компьютером. Без машинного обучения количество идей, необходимых, чтобы построить интеллектуальный агент, бесконечно. Если у робота будут все человеческие умения, кроме способности учиться, человек вскоре оставит его позади.
Минский яро поддерживал проект «Cайк», самый известный провал в истории искусственного интеллекта. Целью «Cайка» было создание искусственного интеллекта путем ввода в компьютер всего необходимого знания. Когда в 1980-х годах проект стартовал, его руководитель Дуглас Ленат уверенно предрекал успех в течение десяти лет. Три десятилетия спустя «Cайк» продолжает расти, а здравый смысл и рассуждения все еще от него ускользают. По иронии, Ленат запоздало согласился заполнять «Cайк» данными, полученными из интернета, но не потому, что «Cайк» научился читать, а потому, что другого выхода не было.
Даже если каким-то чудом удастся закодировать все необходимое, проблемы только начнутся. Многие годы множество исследовательских групп пытались построить полные интеллектуальные агенты, складывая алгоритмы зрения, распознавания речи, понимания языка, рассуждения, планирования, навигации, манипуляций и так далее. Но без объединяющих рамок все эти попытки вскоре наталкивались на непреодолимую стену сложности: слишком много движущихся элементов, слишком много взаимодействий, слишком много ошибок, а разработчики программного обеспечения — всего лишь люди и не могут со всем этим совладать. Инженеры знаний убеждены, что искусственный интеллект — очередная инженерная проблема, однако человечество пока еще не достигло точки, в которой инженерия поможет нам дойти до финишной черты. В 1962 году, когда Кеннеди произнес свою знаменитую речь в честь запуска человека на Луну, этот полет был инженерной проблемой. В 1662 году — нет. В области искусственного интеллекта мы сегодня ближе к XVII веку.
Нет никаких признаков, что инженерия знаний когда-либо будет в состоянии соревноваться с машинным обучением за пределами нескольких ниш. Зачем платить экспертам за медленное, муторное превращение знаний в понятную компьютерам форму, если компьютер сам может извлечь их из данных гораздо дешевле? А как насчет всего того, что эксперты просто не знают, но что можно открыть на основе данных? А если данные недоступны, стоимость инженерии знаний редко превышает пользу. Представьте, что фермерам приходилось бы проектировать каждый початок кукурузы, вместо того чтобы засеять семена и дать им вырасти: мы все умерли бы от голода.
Другой выдающийся ученый, не верящий в машинное обучение, — лингвист Ноам Хомский. Хомский уверен, что язык обязательно должен быть врожденным, потому что примеров грамматически правильных предложений, которые слышат дети, недостаточно, чтобы научиться грамматике. Однако это только перекладывает бремя обучения языку на эволюцию, и это аргумент не против Верховного алгоритма, а лишь против того, что он похож на головной мозг. Более того, если универсальная грамматика существует (как полагает Хомский), пролить на нее свет — значит сделать шаг к прояснению вопроса о Верховном алгоритме. Это было бы не так, лишь если бы язык не имел ничего общего с другими когнитивными способностями, но это неправдоподобно, учитывая, что в ходе эволюции он появился недавно.
В любом случае, если формализовать аргумент Хомского о «бедности стимула», мы обнаружим, что он очевидно ложен. В 1969 году Джим Хорнинг доказал, что стохастические контекстно-свободные грамматики можно выучить на одних положительных примерах, а затем последовали еще более сильные результаты. (Контекстно-свободная грамматика — хлеб насущный для лингвистов, а их стохастические версии моделируют, с какой вероятностью следует использовать каждое правило.) Кроме того, обучение языку не происходит в вакууме: дети получают от родителей и среды всевозможные подсказки. То, что язык можно выучить на примерах всего за несколько лет, отчасти возможно благодаря сходству между его структурой и структурой мира. Эта общая структура — именно то, что нас интересует, и от Хорнинга и других мы знаем, что ее будет достаточно.
Если говорить более обобщенно, Хомский критически относится к статистическому обучению любого рода. У него есть список того, что не могут делать статистические обучающиеся алгоритмы, однако этот список устарел полвека назад. Хомский, по-видимому, приравнивает машинное обучение к бихевиоризму, в котором поведение животных сводится к ассоциативным реакциям на награды. Но машинное обучение не бихевиоризм. Современные алгоритмы обучения могут научиться богатым внутренним представлениям, а не только парным ассоциациям между стимулами.
В конце концов, практика — критерий истины. Статистические алгоритмы обучения языку работают, а построенные вручную языковые системы — нет. Первое прозрение пришло в 1970-х годах, когда DARPA (Defense Advanced Research Projects Agency — Агентство передовых оборонных исследовательских проектов, научно-исследовательское крыло Пентагона) запустило первый широкомасштабный проект по распознаванию речи. Ко всеобщему удивлению, простой последовательный обучающийся алгоритм того типа, который высмеивал Хомский, ловко победил сложную систему, основанную на знаниях. Такие обучающиеся алгоритмы теперь используются практически во всех распознавателях речи, включая Siri. Фред Елинек, глава группы распознавания речи в IBM, как-то пошутил: «Всякий раз, когда я увольняю лингвиста, программа начинает работать эффективнее». Увязнув в трясине инженерии знаний, специалисты по компьютерной лингвистике чуть не вымерли в конце 1980-х годов. С тех пор в этой области безраздельно господствуют методы, основанные на машинном обучении: на конференциях по компьютерной лингвистике сложно найти доклад, в котором бы не было чего-нибудь на эту тему. Парсеры статистики анализируют язык с точностью, близкой к человеческой, оставляя далеко позади написанные вручную программы. Машинный перевод, исправление орфографии, определение частей речи, разрешение лексической многозначности, ответы на вопросы, диалоги, подведение итогов — все лучшие системы в этих областях используют машинное обучение. Watson — компьютер, выигравший в Jeopardy! — своим появлением обязан именно ему.
На это Хомский мог бы ответить, что инженерные успехи еще не доказательство научной обоснованности. Однако если ваши дома разваливаются, а двигатели не работают, видимо, с вашей физической теорией что-то не так. Хомский полагает, что лингвисты должны сосредоточиться на «идеальных», по его собственному определению, носителях языка, и это дает ему право игнорировать необходимость в статистике при обучении языку. Неудивительно, что лишь немногие экспериментаторы теперь принимают его теории всерьез.
Еще один потенциальный источник возражений против Верховного алгоритма — это мнение, популяризированное психологом Джерри Фодором: разум состоит из набора модулей, взаимодействие между которыми ограничено. Например, когда вы смотрите телевизор, ваш «высокоуровневый мозг» понимает, что это всего лишь световые вспышки на плоской поверхности, однако система восприятия зрения по-прежнему видит трехмерные формы. Но даже если сознание модулярно, это еще не значит, что в разных модулях используются разные алгоритмы обучения. Может быть, для работы, скажем, со зрительной и вербальной информацией достаточно одного алгоритма.
Критики вроде Минского, Хомского и Фодора когда-то торжествовали, но их влияние испарилось. Это хорошо, но тем не менее нельзя забывать об их аргументах, когда будем прокладывать путь к Верховному алгоритму. На то есть две причины. Первая — инженеры знаний сталкивались со многими проблемами, стоящими перед машинным обучением, и даже если они не преуспели в их решении, то извлекли много ценных уроков. Вторая — машинное обучение и инженерия знаний, как мы вскоре выясним, переплетены неожиданными и хитроумными связями. К сожалению, оба лагеря часто не слышат друг друга и говорят на разных языках: специалисты по машинному обучению мыслят в категориях вероятностей, а инженеры знаний — в категориях логики. Ниже мы посмотрим, что с этим сделать.
Лебедь кусает робота
«Как бы ни был умен алгоритм, всегда есть то, что он не может узнать». Это утверждение в разных формулировках — самое частое возражение против машинного обучения за пределами науки об искусственном интеллекте и когнитивистики. Нассим Талеб изо всех сил напирал на него в своей книге The Black Swan: The Impact of the Highly Improbable. Некоторые события просто непредсказуемы: если человек видел только белых лебедей, он будет считать, что вероятность когда-нибудь встретить черного равна нулю. Финансовый крах 2008 года оказался как раз таким «черным лебедем».
Действительно, некоторые вещи можно предсказать, а некоторые нельзя, и отличать одно от другого — первейшая задача алгоритма машинного обучения. Однако цель Верховного алгоритма — узнать все, что можно узнать, и этих знаний намного больше, чем может себе представить Талеб и не только он. Спад жилищного рынка совсем не был черным лебедем: его многократно предсказывали. Большинство банковских моделей не смогли его предвидеть исключительно из-за их довольно очевидных ограничений, а не в силу ограниченности машинного обучения как такового. Обучающиеся алгоритмы вполне способны точно предсказать редкие, никогда до этого не происходившие события: можно даже сказать, что в этом весь их смысл. Какова вероятность существования черного лебедя, если его никогда не видели? А как насчет доли известных науке видов, которые, как оказалось, имеют черных представителей? Это очень грубый пример — в этой книге мы увидим гораздо более глубокие.
Еще одно схожее и часто повторяемое возражение: «Данные не могут заменить человеческой интуиции». На самом деле это человеческая интуиция не может заменить данных. К интуиции мы прибегаем, когда не знаем фактов, а поскольку фактов часто не хватает, интуицией люди очень дорожат. Но если перед вами доказательства, разве вы станете их отрицать? Статистический анализ побеждает искателей талантов в бейсболе (это замечательно описано в книге Майкла Льюиса MoneyBall), он превосходит знатоков в дегустации вин, и каждый день мы видим все новые примеры его способностей. Вследствие наплыва данных граница между доказательствами и интуицией очень быстро смещается, и, как при любой революции, въевшиеся привычки надо преодолеть. Если я эксперт по теме X в компании Y, мне, конечно не понравится, когда меня обойдет какой-то парень с данными. Есть профессиональная поговорка: «Слушай своих клиентов, а не HiPPO». HiPPO — это «мнение самого высокооплачиваемого человека». Если вы хотите быть авторитетом и завтра, пользуйтесь данными, а не боритесь с ними.
«Ладно, — скажет кто-то. — Машинное обучение может находить статистические закономерности в данных, но оно никогда не откроет ничего серьезного, например законов Ньютона». Возможно, пока не откроет, но ручаюсь, в будущем все изменится. Если не брать истории про падающие яблоки, глубокие научные истины найти совсем не легко. Наука в своем развитии проходит через три этапа, которые можно назвать фазами Браге, Кеплера и Ньютона. В фазе Браге мы собираем много данных, как Тихо Браге, который ночь за ночью, год за годом кропотливо записывал положение планет. В фазе Кеплера мы подбираем к данным эмпирические законы: Кеплер это делал с движением планет. В фазе Ньютона мы открываем глубокие истины. Наука в значительной степени состоит из работы, подобной труду Браге и Кеплера, а ньютоновские проблески — редкость. Сегодня большие данные делают работу миллиардов Браге, а машинное обучение трудится, как миллионы Кеплеров. Если — будем надеяться — человечество еще ждут великие озарения, их с равной вероятностью могут породить и обучающиеся алгоритмы, и еще более занятые ученые будущего, и совместные усилия ученых и алгоритмов. (Конечно, Нобелевскую премию получат ученые, независимо от того, предложили они ключевые идеи или просто нажали на кнопку. У алгоритмов машинного обучения нет никаких амбиций.) В этой книге мы увидим, на что могут быть похожи эти алгоритмы, и порассуждаем о том, что они могут открыть — например, лекарство от рака.
Верховный алгоритм — лиса или еж?
Нам надо рассмотреть еще одно потенциальное возражение против Верховного алгоритма. Наверное, самое серьезное. Его выдвигают не инженеры знаний и не рассерженные эксперты, а сами практики машинного обучения. На секунду поставив себя на их место, я мог бы сказать: «Послушайте, Верховный алгоритм совершенно не похож на мою повседневную работу! Я перепробовал сотни алгоритмов для каждой проблемы, и для разных задач лучше подходят разные алгоритмы. Разве может один заменить все это многообразие?»
На это я отвечу: вы правы. Но разве не лучше вместо сотен вариантов многих алгоритмов пробовать сотни вариантов одного-единственного? Если выяснить, что в каждом алгоритме важно, а что нет, найти у важных элементов общее и посмотреть, как они дополняют друг друга, можно сложить из них Верховный алгоритм. Именно этим мы и займемся на страницах этой книги или хотя бы попытаемся как можно ближе к этому подойти. Наверное, у вас, дорогой читатель, по мере чтения тоже возникнут какие-то идеи на этот счет.
Насколько сложен будет Верховный алгоритм? Тысячи строк кода? Миллионы? Мы пока не знаем, но в машинном обучении бывало, что простые алгоритмы чудесным образом побеждали очень замысловатые. В известном эпизоде книги The Sciences of the Artificial пионер искусственного интеллекта и нобелевский лауреат Герберт Саймон просит представить себе муравья, который упорно бежит по пляжу к себе домой. Путь муравьишки сложен не потому, что сложен он сам, а потому что вокруг полно маленьких дюн, на которые надо взбираться, и гальки, которую приходится обегать. Попытки смоделировать муравья, запрограммировав все возможные пути, будут обречены на провал. Аналогично самое сложное в машинном обучении — это данные. Все, что должен сделать Верховный алгоритм, — усвоить их, поэтому не надо удивляться, если сам он окажется несложным. Человеческая рука проста: четыре пальца вместе плюс отведенный в сторону большой. И несмотря на это, рука может делать и использовать бесконечное разнообразие инструментов. Верховный алгоритм по отношению к алгоритмам — то же, что рука по отношению к карандашам, мечам, отверткам и вилкам.
Как заметил Исайя Берлин, некоторые мыслители подобны лисам и знают много разного, а некоторые — ежам, которые знают что-то одно, но важное. То же самое с обучающимися алгоритмами. Я надеюсь, что Верховный алгоритм окажется ежом, но, даже если это лиса, ее все равно надо поскорее поймать. Самая большая проблема сегодняшних обучающихся алгоритмов не в том, что их много, а в том, что они, хоть и полезны, не делают всего, что мы от них хотим. И прежде чем начать открывать глубокие истины при помощи машинного обучения, надо как следует разобраться в самом машинном обучении.
Что на кону?
Предположим, человеку поставили диагноз «рак» и традиционные методы лечения — хирургия, химио- и лучевая терапия — не принесли желаемого эффекта. Дальнейший ход лечения станет для него вопросом жизни и смерти. Первый шаг — это секвенировать геном опухоли. Есть компании, например Foundation Medicine в Кембридже, которые этим занимаются: отправьте им образец опухоли, и они пришлют вам список мутаций в ее геноме, достоверно связанных с раком. Без этого не обойтись, потому что каждая раковая опухоль индивидуальна и нет лекарства, которое поможет во всех случаях. Распространяясь по организму человека, рак мутирует, и вследствие естественного отбора, скорее всего, будут выживать и размножаться клетки, наиболее стойкие к назначенным лекарствам. Возможно, нужный препарат помогает только пяти процентам пациентов, или необходимо сочетание лекарств, которое пока вообще не применяли. Может быть, придется разработать совершенно новое лекарство конкретно для данного случая или комплекс препаратов, чтобы подавить способность опухоли к адаптации. С другой стороны, у лекарств могут иметься побочные эффекты, смертельно опасные для данного пациента, но безвредные для большинства других людей. Ни один врач не может уследить за всей информацией, необходимой для выработки оптимальной терапии с учетом истории болезни и генома опухоли. Это идеальная работа для машинного обучения, и тем не менее на сегодняшний день обучающиеся алгоритмы не могут с ней справиться. У каждого из них есть какие-то из необходимых способностей, но не хватает других. У Верховного алгоритма будет все. Если применить его к большому объему данных о пациентах и лекарствах, а также информации, почерпнутой из литературы по биологии и медицине, мы сможем победить рак.
Универсальный алгоритм машинного обучения остро необходим во многих других областях и ситуациях — от невероятно важных до самых обыденных. Представьте себе, например, идеальную рекомендующую систему, которая посоветует именно те книги, фильмы и гаджеты, которые вы сами бы выбрали, будь у вас время проверить все варианты. Алгоритм Amazon очень далек от идеала. Отчасти дело в том, что у него просто недостаточно данных: в целом он знает только, какие предметы вы раньше покупали на этом сайте. Но если разойтись и предоставить ему полный доступ к потоку сознания человека начиная с рождения, он не будет знать, что с этим делать. Как преобразовать в связную картину мириады решений, калейдоскоп жизни? Как понять, кто этот человек и чего он хочет? Это выходит далеко за пределы кругозора сегодняшних обучающихся алгоритмов, но, если дать все эти данные Верховному алгоритму, он поймет вас примерно так же, как лучший друг.
В один прекрасный день в каждом доме появится робот. Он будет мыть посуду, заправлять кровать, даже присматривать за детьми, пока родители на работе. Как скоро это произойдет — зависит от того, как тяжело окажется отыскать Верховный алгоритм. Если лучшее, на что мы способны, — соединить много разных алгоритмов, каждый из которых решает лишь малую долю проблем искусственного интеллекта, вскоре мы наткнемся на стену сложности. Такой фрагментарный подход сработал в Jeopardy!, но лишь немногие верят, что домашние роботы будущего будут внуками компьютера Watson, победителя этой игры. Дело не в том, что Верховный алгоритм одной левой решит проблему искусственного интеллекта: нам по-прежнему понадобятся чудеса инженерии, и Watson в этом отношении — хороший пример. Однако здесь действует правило 80/20: Верховный алгоритм даст 80 процентов решения, и останется приложить 20 процентов труда, поэтому, несомненно, с него и надо начинать.
Влияние Верховного алгоритма на технологию не ограничится искусственным интеллектом. Универсальный обучающийся алгоритм — невероятно мощное оружие против Монстра Сложности. Нам поддадутся системы, которые сегодня слишком трудно построить. Компьютеры начнут делать больше и требовать меньше помощи с нашей стороны. Они не станут снова и снова повторять те же ошибки, а будут учиться на практике, как люди. Иногда, как старые дворецкие, они даже смогут угадывать, чего вы хотите, еще до того, как вы это выразите. Если компьютеры делают нас умнее, компьютеры с установленным Верховным алгоритмом заставят нас почувствовать себя настоящими гениями. Технологический прогресс заметно ускорится, причем не только в компьютерных науках, но и во многих других областях. Это, в свою очередь, будет способствовать экономическому росту и уменьшит нищету. С Верховным алгоритмом, помогающим синтезировать и распределять знания, интеллект организаций будет больше, а не меньше суммы интеллектов их подразделений. Типовые задачи станут автоматизированы, а люди найдут себе занятия поинтереснее. Все виды деятельности будут выполняться качественнее, чем сейчас: лучше обученными людьми, компьютерами или и теми и другими. Падения на рынках ценных бумаг будут происходить реже и без тяжелых последствий. Благодаря сети сенсоров, которые опутают нашу планету, и обученным моделям, которые станут моментально обрабатывать их данные, прогресс больше не будет идти вперед на ощупь: здоровье планеты пойдет на поправку. Модели начнут договариваться с миром от вашего имени, играя в замысловатые игры с моделями людей и организаций. А в результате всех этих улучшений мы окажемся счастливее, продуктивнее и долговечнее.
Поскольку потенциальная отдача так велика, нам стоит попробовать изобрести Верховный алгоритм, даже если шансы на успех невысоки. И даже если это займет много времени, поиски могут принести нам непосредственную пользу. Например, мы будем гораздо лучше понимать машинное обучение благодаря единому подходу к этой проблеме. Сегодня очень много деловых решений принимается на основе слабого понимания аналитики, но все может быть иначе. Чтобы пользоваться технологиями, не обязательно разбираться в механизмах их действия, однако нужно иметь хорошую концептуальную модель: это примерно то же, что уметь настроиться на радиостанцию и регулировать громкость. Сегодня люди, которые не занимаются машинным обучением, не имеют даже общего представления о том, что делают обучающиеся алгоритмы. Алгоритмы, которыми мы управляем, пользуясь Google, Facebook или современными аналитическими пакетами, немного похожи на загадочный черный лимузин с тонированными стеклами, который однажды вечером подъезжает к нашей двери. Стоит ли в него садиться? Куда он нас повезет? Настало время занять место водителя. Знание допущений, которые делают разные алгоритмы машинного обучения, поможет подобрать правильные инструменты для решения конкретной задачи, а не хвататься за первые попавшиеся и потом годами с ними мучиться, болезненно пытаясь открыть то, что надо было знать с самого начала. Понимая, что именно оптимизирует обучающийся алгоритм, можно гарантировать, что он будет оптимизировать важные вещи, а не что попадется под руку. Наверное, самое главное вот что: если знать, как именно пришел к выводам данный обучающийся алгоритм, легче понять, что делать с полученной информацией — чему верить, от чего отказываться, как получить в следующий раз лучший результат. А с универсальным обучающимся алгоритмом, который мы разработаем в этой книге в виде концептуальной модели, все это можно будет сделать без лишнего напряжения. Машинное обучение в своей основе — простая вещь. Надо всего лишь снять один за другим слои математики и научного жаргона и добраться до самой маленькой матрешки.
Все эти преимущества относятся и к личной, и к профессиональной жизни. Как лучше воспользоваться цепочкой данных, которые оставляет каждый наш шаг в современном мире? Любой поступок действует сразу на двух уровнях: дает нам непосредственный результат и учит систему, с которой мы взаимодействовали. Осознание этого — первый шаг к счастливой жизни в XXI веке. Научите алгоритмы, и они будут служить вам, но вначале их надо понять. Что в вашей работе можно сделать с помощью алгоритма, а что нет? И — самое важное — как воспользоваться машинным обучением, чтобы делать это еще лучше? Компьютер — инструмент, а не противник. Вооруженный машинным обучением менеджер становится сверхменеджером, ученый — сверхученым, инженер — сверхинженером. Будущее принадлежит тем, кто глубоко понимает, как сочетать свои уникальные знания и навыки с тем, что алгоритмы делают лучше всего.
Но, может быть, Верховный алгоритм — это ящик Пандоры, который лучше не открывать? Не поработят ли нас компьютеры и не захотят ли от нас избавиться? Не станет ли машинное обучение прислуживать тиранам и зловещим корпорациям? Благодаря пониманию, в каком направлении развивается машинное обучение, мы сможем разобраться, о чем надо волноваться, а о чем не стоит и как поступать в таких случаях. С теми видами обучающихся алгоритмов, которые мы встретим в этой книге, сценарий «Терминатора», где искусственный сверхинтеллект обретает разум и покоряет человечество с помощью армии роботов, просто невозможен. Если компьютеры умеют учиться, это еще не значит, что они волшебным образом обретут собственную волю. Обучающиеся алгоритмы учатся достигать целей, которые ставим им мы сами, и не могут эти цели менять. Скорее, нам надо позаботиться о том, чтобы они не оказали нам медвежью услугу, а для этого их надо лучше учить.
Прежде всего нам надо подумать, что будет, если Верховный алгоритм попадет в плохие руки. Первая линия защиты — позаботиться, чтобы хорошие ребята получили его раньше остальных, а если непонятно, кто хороший, а кто нет, обеспечить к нему открытый доступ. Вторая линия — осознать, что, как бы ни был совершенен обучающийся алгоритм, он хорош ровно настолько, насколько хороши предоставляемые ему данные. Тот, кто контролирует данные, контролирует и алгоритм. Реакцией на «датификацию» жизни должен стать не уход в джунгли — даже в лесу будет полно сенсоров, — а скорее активное стремление держать под контролем чувствительные для вас данные. Хорошо иметь советчиков, которые найдут и принесут вам то, что вы пожелаете. Без них можно потеряться. Однако они должны приносить вам то, что хотите вы сами, а не то, чем хочет снабдить вас кто-то посторонний. Вокруг контроля над данными и владения моделями, обучающимися на их основе, в XXI веке будет сломано немало копий: за них станут сражаться правительства, корпорации, организации и отдельные лица. Но с другой стороны, у вас будет и этическая обязанность делиться информацией ради общего блага. Машинное обучение само по себе не вылечит рак, поэтому больные раком люди принесут пользу будущим пациентам, поделившись информацией о себе.
Другая теория всего
Наука сегодня очень напоминает Балканский полуостров — настоящую Вавилонскую башню, где каждое сообщество говорит на собственном языке и способно видеть только несколько соседних мини-сообществ. Верховный алгоритм станет единым взглядом на науку в целом и даже, не исключено, приведет к созданию новой теории всего. Это может показаться странным заявлением — ведь машинное обучение просто строит теории на основе данных. Каким образом сам Верховный алгоритм может вырасти в теорию? Разве теория всего — это не теория струн? Верховный алгоритм совершенно на нее не похож!
Для ответа на эти вопросы сначала надо разобраться, что такое научная теория. Теория — это не полное описание мира, а набор ограничений в отношении того, каким он может быть. Чтобы получить полное описание, теорию нужно объединить с данными. Возьмем, например, второй закон Ньютона. Он гласит, что сила равна массе, умноженной на ускорение, то есть F = ma. Он не указывает, какова масса или ускорение какого-либо тела или каковы действующие на него силы, а только требует, чтобы в случае, когда масса объекта m, а его ускорение — a, равнодействующая сила составляла ma. Этот закон убирает некоторые степени свободы Вселенной, но не все. То же верно для любой другой физической теории, включая относительность, квантовую механику и теорию струн, которые, в сущности, уточнения законов Ньютона.
Сила теорий в том, что они значительно упрощают описание мира. Если мы вооружены законами Ньютона, достаточно знать только массу, положение и скорости всех предметов в определенный момент времени, чтобы вывести их положения и скорости во все другие моменты. Таким образом, законы Ньютона уменьшают наше описание мира на порядок, равный числу различимых случаев в истории Вселенной в прошлом и будущем. Поразительно! Конечно, законы Ньютона — лишь приближение истинных законов физики, поэтому давайте вместо них возьмем теорию струн, игнорируя все ее проблемы и вопрос, можно ли ее вообще когда-нибудь проверить эмпирически. Разве можно достичь большего? Да, можно. По двум причинам.
Первая заключается в том, что в реальности у нас никогда не будет достаточно данных, чтобы полностью описать наш мир. Даже игнорируя принцип неопределенности, точно знать положение и скорости всех частиц в мире в какой-то момент времени совершенно невозможно. А поскольку законы физики хаотичны, неопределенность со временем только накапливается, и очень скоро они определяют очень немного. Для точного описания мира нужны регулярные порции свежих данных. Это приводит к тому, что законы физики говорят нам только о локальных событиях, а это резко уменьшает их мощь.
Вторая проблема в следующем: даже если бы мы получили всю полноту знаний о мире в какой-то момент, законы физики по-прежнему не позволяли бы нам узнать его прошлое и будущее. Дело в том, что объем вычислений, необходимых для такого рода предсказаний, превышает способности любого компьютера, какой только можно себе представить, и для идеальной симуляции Вселенной потребовалась бы еще одна идентичная вселенная. Вот почему теория струн за пределами физики в основном неприменима, а теории биологии, психологии, социологии и экономики не выводятся из законов физики: их приходится создавать с нуля. Мы допускаем, что они приближение того, что предсказали бы законы физики в масштабе клеток, головного мозга и общества, но знать этого не можем.
В отличие от локальных теорий, которые имеют силу только в конкретных дисциплинах, Верховный алгоритм властен везде. В области X у него будет меньше возможностей, чем у превалирующей в ней теории, но в масштабе всей науки — когда мы рассматриваем мир в целом — он намного сильнее, чем любая другая теория. Верховный алгоритм — это зародыш всех теорий. Все, что нам нужно, чтобы получить теорию X, — это минимальное количество данных, необходимое для ее выведения путем индукции. (В случае физики это просто результаты, наверное, нескольких сотен ключевых экспериментов.) Достоинство Верховного алгоритма в том, что он вполне может оказаться лучшей отправной точкой для поиска теории всего, какую мы только можем получить. При всем уважении к Стивену Хокингу, Верховный алгоритм может в конце концов рассказать нам о Божественном замысле больше, чем теория струн.
Некоторые могут возразить, что поиски универсального обучающегося алгоритма — типичный пример научной гордыни. Но мечты не гордыня. Может быть, Верховный алгоритм займет свое место среди великих химер, рядом с философским камнем и вечным двигателем. А может быть, его поиск больше похож на попытки определить долготу в океане: такие расчеты долго считались слишком сложными, от них все отмахивались, а потом пришел одинокий гений и решил проблему. Скорее всего, создание Верховного алгоритма потребует усилий нескольких поколений, и величественный собор будет строиться камень за камнем. Единственный способ проверить — однажды утром встать пораньше и отправиться в путь.
Кандидаты, которые не оправдали надежд
Итак, если Верховный алгоритм существует, на что он похож? На первый взгляд, очевидный ответ — на запоминание. Просто запоминай все, что видишь, и через некоторое время увидишь все, что только можно увидеть, и таким образом узнаешь все, что только можно узнать. Проблема в том, что, как сказал Гераклит, в ту же реку нельзя войти дважды. В мире куда больше вещей, чем мы в состоянии увидеть. Неважно, сколько снежинок вы исследуете: следующая будет другой. Даже если бы вы присутствовали при Большом взрыве и после этого везде и всюду, вы все равно увидели бы лишь крохотную долю того, что могли бы увидеть в будущем. Если бы вы десять тысяч лет наблюдали за жизнью на Земле, это не подготовило бы вас к тому, что еще предстоит. Человек, выросший в одном городе, не впадает в ступор, когда переезжает в другой, однако робот, способный только запоминать, впал бы. Кроме того, знание — это не просто длинный список фактов. Знание бывает обобщенным и структурированным. «Все люди смертны» — намного более емкое утверждение, чем семь миллиардов свидетельств о смерти, по одному на каждого человека. Запоминание же не даст нам ни обобщенности, ни структуры.
Другой кандидат в Верховные алгоритмы — микропроцессор. В принципе, процессор в вашем компьютере можно рассматривать как единый алгоритм, работа которого — выполнять другие алгоритмы, подобно универсальной машине Тьюринга, и он может выполнять любые мыслимые алгоритмы до границ своей памяти и производительности. Для микропроцессора алгоритм — просто еще один вид данных. Проблема в том, что сам по себе микропроцессор ничего делать не умеет: он просто сидит весь день без дела. Откуда берутся алгоритмы, которые он выполняет? Если они были закодированы программистом-человеком, никакого обучения нет. Тем не менее в каком-то отношении микропроцессор — удачный аналог Верховного алгоритма. Микропроцессор — не самое оптимальное оборудование для запуска отдельных алгоритмов, для этого гораздо больше подходят разработанные для конкретной задачи интегральные схемы специального назначения (application-specific integrated circuit, ASIC). Однако почти для всех приложений мы используем именно микропроцессоры, потому что их гибкость с лихвой компенсирует относительную неэффективность. Если бы нам приходилось разрабатывать ASIC для каждого нового приложения, информационная революция никогда бы не состоялась. Верховный алгоритм — тоже не лучший алгоритм для изучения конкретного элемента знаний. Эффективнее был бы алгоритм, в который уже заложена большая часть этого знания (или знание целиком: тогда данные будут избыточны). Однако вся суть в том, чтобы вывести знание из данных путем индукции. Это легче и дешевле, поэтому чем более обобщен алгоритм машинного обучения, тем лучше.
Еще более радикальный кандидат — скромный вентиль ИЛИ-НЕ, логический переключатель, который на выходе дает единицу, если на входе два нуля. Не забывайте, что все компьютеры построены из логических вентилей в виде транзисторов и все вычисления можно свести к комбинациям элементов И, ИЛИ и НЕ. Вентиль ИЛИ-НЕ — это просто элемент ИЛИ, за которым следует элемент НЕ: отрицание дизъюнкции, как в предложении «Я счастлив, если не голоден и не болен». Элементы И, ИЛИ и НЕ можно реализовать с использованием вентилей ИЛИ-НЕ, поэтому этот вентиль может делать все. Вообще говоря, некоторые микропроцессоры только его и используют. Так почему же он не может стать Верховным алгоритмом? Ведь он, безусловно, непревзойден в своей простоте. К сожалению, вентиль ИЛИ-НЕ — Верховный алгоритм не в большей степени, чем кубик лего — универсальная игрушка. Конечно, детали конструктора как кирпичики и из них многое можно построить, но гора элементов самопроизвольно ни во что не сложится. То же относится к другим простым вычислительным схемам, например сетям Петри и клеточным автоматам.
Перейдем к более сложным кандидатам. Например, к запросам, на которые может ответить любой хороший движок базы данных, или простых алгоритмов в статистическом пакете. Разве их недостаточно? Это более крупные детали лего, но по-прежнему всего лишь кирпичики. Движок базы данных никогда не откроет ничего нового: он просто сообщает то, что знает. Даже если все люди в базе данных смертны, ему не придет в голову экстраполировать эту черту на других людей (проектировщики баз данных побледнели бы от самой этой мысли). Статистика в основном заключается в проверке гипотез, которые кто-то сначала должен сформулировать. Статистические пакеты умеют выполнять линейную регрессию и другие простые процедуры, но они мало чему могут научиться, сколько бы данных им ни предоставили. Качественные пакеты входят в серую зону между статистикой и машинным обучением, но все равно остается множество видов знания, которое они не могут открыть.
Ладно, давайте начистоту. Верховный алгоритм — это уравнение U(X) = 0. Он уместится не то что на футболке, а даже на почтовой марке! Уравнение U(X) = 0 говорит, что определенная (возможно, очень сложная) функция U какой-то (возможно, очень сложной) переменной X равна нулю. К этой форме можно свести любое уравнение. Например, F = ma можно записать в виде F – ma = 0, поэтому, если считать F – ma функцией U переменной F — вуаля: U(F) = 0. В целом X может быть любыми вводными данными, а U — любым алгоритмом, поэтому, конечно, Верховный алгоритм не может быть более общим, чем это уравнение, а поскольку мы ищем самый общий алгоритм из всех возможных, это должен быть он. Конечно, я шучу, но конкретно этот неудачный кандидат указывает на одну из реальных опасностей в машинном обучении: создание настолько общего обучающегося алгоритма, что он окажется недостаточно содержательным, чтобы быть полезным.
Так какое же минимальное содержание может иметь обучающийся алгоритм, чтобы оставаться полезным? Законы физики? В конце концов, все в этом мире им подчиняется (по крайней мере, мы так думаем), они породили эволюцию, а в ходе эволюции — головной мозг. Может быть, Верховный алгоритм и правда скрыт в законах физики, но, если это так, нам надо выразить его явно. Если просто подбрасывать законам физики данные, новых законов не получишь. На это можно посмотреть следующим образом: возможно, основная теория какой-то дисциплины — просто законы физики, облеченные в удобную для этой дисциплины форму. Но если это действительно так, нам нужен алгоритм, который найдет кратчайший путь из данных этой дисциплины к ее теории, и непонятно, смогут ли законы физики в этом помочь. Еще один аспект заключается в следующем: если бы законы физики были иными, Верховный алгоритм все равно во многих случаях смог бы их открыть. Математики любят говорить, что Бог может нарушать законы физики, но даже он не бросает вызов законам логики. Возможно, это так, но законы логики предназначены для дедукции, а нам нужно что-то подобное для индукции.
Пять «племен» машинного обучения
Конечно, охоту за Верховным алгоритмом не надо начинать с нуля. У нас за плечами несколько десятилетий исследований машинного обучения, на которые можно опереться. Лучшие умы планеты посвятили свои жизни разработке обучающихся алгоритмов, а кто-то даже утверждает, что универсальный алгоритм уже у него в руках. Хотя мы стоим на плечах гигантов, такие заявления надо принимать с долей скептицизма, и тогда возникает вопрос: как понять, что Верховный алгоритм найден? Мы поймем это тогда, когда один и тот же обучающийся алгоритм, в котором допустимо только менять параметры, на основе минимальных исходных данных сможет научиться понимать видео и текст так же хорошо, как человек, сделает важные открытия в биологии, социологии и других науках. Очевидно, что по этим стандартам ни один алгоритм машинного обучения пока нельзя признать Верховным, даже в том маловероятном случае, что он уже найден.
Крайне важно понимать, что от Верховного алгоритма не требуется уметь с чистого листа решать новую задачу. Это, наверное, была бы слишком высокая планка для любого обучающегося алгоритма, и это, разумеется, совершенно не похоже на то, как работают сами люди. Например, язык не существует в вакууме, и мы не поймем фразу без знания мира, к которому она относится. Таким образом, когда Верховный алгоритм будет учиться читать, он может опираться на то, что до этого он уже научился видеть, слышать и управлять роботами. Точно так же ученый не просто вслепую подбирает модели к данным — чтобы решить проблему, он оперирует всеми знаниями в данной области. Делая открытия в биологии, Верховный алгоритм тоже сначала может прочитать всю литературу по предмету, какую пожелает, полагаясь на уже освоенный навык чтения. Верховный алгоритм — не просто пассивный потребитель данных. Он может взаимодействовать с окружающей средой и активно искать данные, которые ему нужны, как робот-ученый Адам, о котором мы упоминали выше, или просто ребенок, исследующий окружающий мир.
Поиски Верховного алгоритма сложны, но их оживляет соперничество разных научных школ, действующих в области машинного обучения. Важнейшие из них — символисты, коннекционисты, эволюционисты, байесовцы и аналогисты. У каждого «племени» есть набор фундаментальных постулатов и конкретная проблема, которая больше всего его волнует. «Племя» находит решение для этой проблемы в идеях союзных научных дисциплин, и у него есть верховный алгоритм, который воплощает это решение.
Для символистов интеллект сводится к манипулированию символами — так математики решают уравнения, заменяя одни выражения другими. Символисты понимают, что нельзя учиться с нуля: данные должны сопровождаться исходными знаниями. Они научились встраивать уже имеющееся знание в машинное обучение и на лету соединять фрагменты знания, чтобы решать новые задачи. Их верховный алгоритм — это обратная дедукция: она определяет недостающее для дедукции знание, а затем как можно в большей степени его обобщает.
Для коннекционистов обучение — то, чем занимается головной мозг, и поэтому они считают, что этот орган надо воспроизвести путем обратной инженерии. Мозг учится, корректируя силу соединений между нейронами, поэтому ключевая проблема — понять, какие соединения за какие ошибки отвечают, и соответствующим образом их изменить. Верховный алгоритм коннекционистов — метод обратного распространения ошибки, который сравнивает выходные данные системы с желаемыми, а потом последовательно, слой за слоем, меняет соединения между нейронами, чтобы сделать результат ближе к тому, что требуется.
Эволюционисты верят, что мать учения — естественный отбор. Если он создал нас самих, значит, он может все, и нам остается только симулировать его на компьютере. Ключевая проблема, которую решает эта научная школа, — обучающаяся структура: требуется не просто подобрать параметры, как при обратном распространении ошибки, а создать мозг, который эти уточнения будет тонко настраивать. Верховный алгоритм эволюционистов — это генетическое программирование, соединяющее и развивающее компьютерные программы точно так же, как природа сводит и развивает живые организмы.
Байесовцы озабочены прежде всего неопределенностью. Все усвоенное знание неопределенно, и само обучение — это форма недостоверного вывода. Проблема, таким образом, заключается в следующем: как работать с зашумленной, неполной, даже противоречивой информацией и не потерять голову? Выходом становится вероятностный вывод, а верховным алгоритмом — теорема Байеса и ее производные. Теорема Байеса объясняет, как встраивать в наши убеждения новые доказательства, а алгоритмы вероятностного вывода делают это с максимальной эффективностью.
Для аналогистов ключ к обучению — находить сходства между разными ситуациями и тем самым логически выводить другие сходства. Если у двух пациентов схожие симптомы, вероятно, у них одинаковое заболевание. Ключевая проблема — оценить, насколько похожи два случая. Верховный алгоритм аналогистов — это метод опорных векторов, который определяет, какой опыт надо запомнить и как соединить опыт, чтобы делать новые прогнозы.
Решения центральных проблем каждого из «племен» — блестящие, с трудом завоеванные успехи. Но подлинный Верховный алгоритм должен решить все пять проблем, а не одну. Например, чтобы лечить рак, необходимо разобраться в метаболических путях в клетке: каковы механизмы регуляции генов, за какие химические реакции отвечают кодируемые этими генами белки, как добавление новой молекулы повлияет на эти цепочки реакций. Было бы глупо пытаться узнать все это с нуля, игнорируя знания, которые биологи накапливали десятилетиями. Символисты знают, как объединить эти знания с данными секвенсоров ДНК, микрочипами экспрессии генов и так далее и получить результаты, которые нельзя иметь из каждого источника по отдельности. Однако знание, полученное путем обратной дедукции, — качественное, а не количественное, поэтому нам придется не просто разобраться, что с чем взаимодействует, но и понять степень этого взаимодействия, и здесь может пригодиться метод обратного распространения ошибки. Тем не менее и обратная дедукция, и обратное распространение будут подвешены в пространстве без какой-то базовой структуры, к которой можно привязать найденные ими взаимодействия и параметры. Такую структуру может открыть генетическое программирование. С этого момента, если у нас будет полное знание метаболизма и все данные пациента, можно попробовать найти лечение. Однако в реальности имеющаяся информация всегда неполная, а местами и ошибочная. Приходится прокладывать путь к цели, несмотря на эти препятствия, и именно для этого пригодится вероятностное заключение. В самых сложных случаях рак у пациента будет очень сильно отличаться от того, что было описано, и полученное знание не поможет. Спасти положение смогут алгоритмы, основанные на сходстве: они заметят аналогии между очень разными на первый взгляд ситуациями, потому что сосредоточатся на существенных моментах и проигнорируют остальное.
В этой книге мы создадим единый алгоритм со всеми этими возможностями.
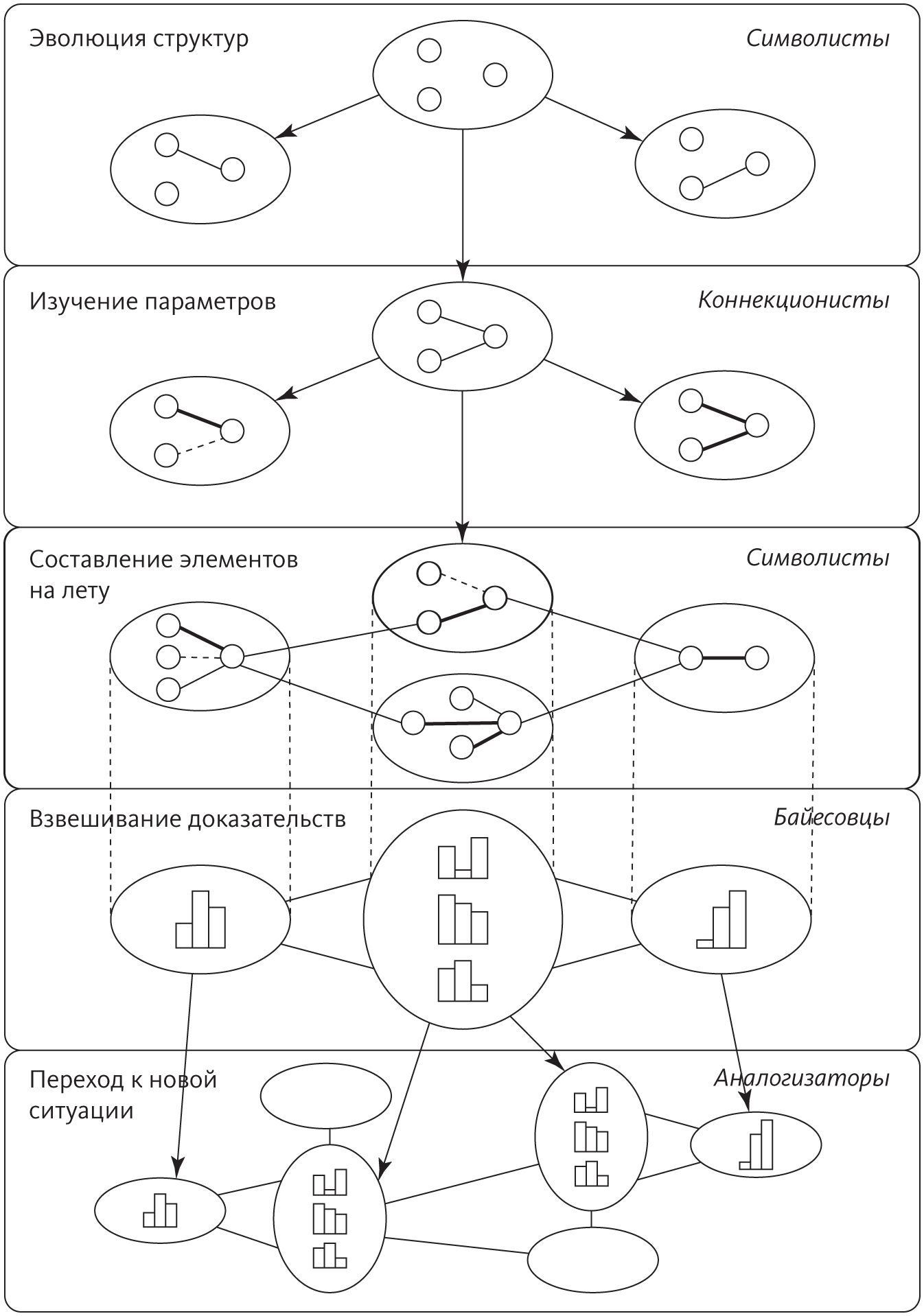
В наших поисках мы пройдем по землям каждого из пяти «племен». Пограничные переходы, где они встречаются, ведут переговоры и вступают в схватки, будут самыми непростыми отрезками пути. У каждого «племени» есть свой кусочек мозаики, которую мы обязаны собрать. Специалисты по машинному обучению, как и все ученые, напоминают слепцов рядом со слоном: один щупает хобот и думает, что это змея. Другой прислонился к ноге и считает, что это дерево. Еще один потрогал бивень и решил, что это бык. Наша цель — дотронуться до всех элементов, не спеша с выводами. Прикоснувшись ко всему, мы попытаемся нарисовать в воображении слона целиком. Соединить все фрагменты в одно решение — далеко не банальная задача. Некоторые полагают, что это вообще невозможно. Но именно это мы сделаем.
Алгоритм, к которому мы придем, пока не будет Верховным (мы увидим почему), но так далеко еще никто не заходил. А в пути нас ждет столько сокровищ, что позавидовал бы сам Крез. Тем не менее эта книга — лишь первая часть саги о Верховном алгоритме. Героем второй части станете вы, дорогой читатель. Ваша миссия, если вы решитесь взять ее на себя, — пройти остаток пути и вернуться с наградой. Я буду вашим скромным проводником по первой части, отсюда и до границы известного мира. Что? Вы говорите, что знаете слишком мало и не сильны в алгоритмах? Не пугайтесь. Информатика еще молода, и здесь, в отличие от физики или биологии, вам не надо быть доктором наук, чтобы совершить в ней революцию. (Не верите — спросите Билла Гейтса, а еще Сергея Брина, Ларри Пейджа и Марка Цукерберга.) Важны идеи и упорство.
Итак, вы готовы? Наш путь начнется с визита к символистам, «племени» с самой солидной родословной.

