Книга: Приспособиться и выжить!
Назад: Глава 3 Бессмертные гены. Бег на месте в погоне за вечностью
Дальше: Судьбы генов. Бессмертное ядро
Изучаем ДНК и читаем генетический код
Известные нам сегодня последовательности ДНК составляют 40 тыс. томов, по миллиону знаков в каждом. Генетическое содержание некоторых видов, например человека, образует целую энциклопедию из 3000 томов, а других, таких как бактерии, укладывается всего в три или четыре тома. Вне зависимости оттого, какой том мы раскроем, мы увидим одинаковый с виду текст, примерно такой:
ACGGCTATGGGCTACCAAGGGCTACCAACTACCAAAGTTACGGCTAATCGACATAATTGGCTACCAAGACATAACCTGGCTACCAATTACTATGGACGGCCTACGGCGTCCGCTAATAATCGACATAACCTTTACTATGGCTACCAAAGTGACATAACCTTTACTCATAACCTGGCTACCAACCAAGGGCTACCAACTACCAAAATTACTATGGGACATTAATCGACATAACCTTTACTAACCTGGCTACCAATTACTATGGACGGCCAATGG.
И так многие сотни страниц.
Как такой монотонный текст, составленный всего из четырех знаков, может кодировать инструкции, необходимые для создания сложных существ? Более того, как вообще можно прочесть эту бессмыслицу?
Чтобы понять язык ДНК, нужно научиться расшифровывать гены и геномы с помощью генетического кода. Это позволит нам сравнивать виды организмов с разной степенью родства — от ближайших до очень дальних родственников, чьи пути разошлись на самых ранних этапах эволюции. Осознание того, как работает эволюция, возникает тогда, когда мы начинаем понимать значение общности и различий между организмами.
Чтобы летопись ДНК помогла понять ход естественной истории, нужно твердо овладеть языком ДНК и механизмом организации живых систем на основании заключенной в ДНК информации. Не волнуйтесь, научиться понимать язык ДНК не так уж трудно. У нее очень простой алфавит, весьма ограниченный набор слов и простые правила грамматики. Вознаграждение за ваши труды — способность видеть и понимать процесс эволюции на самом фундаментальном уровне. Я согласен, что в новых терминах порой трудно разобраться, поэтому советую отметить этот раздел закладкой и при необходимости к нему возвращаться.
Итак, начнем.
Белки — это молекулы, которые в каждом организме выполняют все виды работ: они переносят кислород, формируют ткани и копируют ДНК для передачи следующему поколению. ДНК каждого вида организма содержит в себе специфические инструкции (в виде кода), необходимые для построения этих белков.
ДНК состоит из двух нитей, образованных основаниями четырех типов. Основания, эти химические кирпичики ДНК, обозначают буквами A, C, G и T. Нити ДНК удерживаются между собой за счет прочных химических связей, образующихся между парами оснований на двух нитях: A всегда образует пару с T, а C — с G, как показано на рисунке:
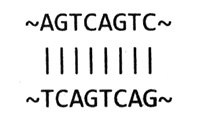
Если нам известна последовательность одной нити ДНК, по ней можно воссоздать последовательность противоположной нити. Инструкции для построения каждого белка задаются уникальной последовательностью оснований ДНК (TCGATAA и т. д.). Удивительно, но все разнообразие жизни на планете обеспечивается перестановками лишь этих четырех оснований. Таким образом, чтобы понять это разнообразие, мы должны расшифровать генетический код.
Как строятся белки и как они понимают, в чем заключается их функция? В роли строительных кирпичиков белков выступают аминокислоты. Каждая аминокислота кодируется последовательностью трех оснований ДНК, или триплетом (ACT, GAA и т. д.). Химические свойства этих аминокислот, соединенных в длинные цепи (средний белок состоит примерно из 400 аминокислотных остатков), определяют уникальное действие каждого белка. Фрагмент ДНК, кодирующий отдельный белок, называется геном.
Связь между кодом ДНК и последовательностью белка была установлена примерно 40 лет назад, когда биологи расшифровали генетический код. Декодирование ДНК и построение белка осуществляются в два этапа. На первом этапе последовательность оснований одной нити ДНК транскрибируется в последовательность РНК, называемую матричной (или информационной) РНК (мРНК). Затем, на второй стадии, мРНК транслируется в аминокислотную последовательность, из которой формируется белок. В клетках генетический код считывается (с транскрипта мРНК) триплетами, каждый из которых определяет одну аминокислоту (короткий пример представлен в правой части рис. 3.2).
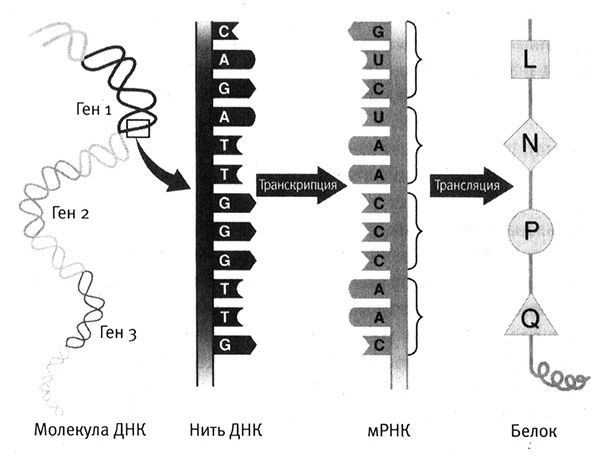
Рис. 3.2. Экспрессия ДНК. Схематичное изображение основных стадий превращения ДНК в функциональный белок. Слева изображена длинная последовательность ДНК, содержащая несколько генов. Далее — экспрессия части одного из генов, происходящая в две стадии. Сначала одна из нитей ДНК транскрибируется в последовательность мРНК. Затем последовательность мРНК транслируется в белок, причем последовательность трех оснований в мРНК (триплет) кодирует одну аминокислоту в белке (здесь аминокислоты обозначены буквами L, N, P и O). В молекуле мРНК вместо основания T используется основание U. Рисунок Лианн Олдс.
Существует 64 разных триплета, образуемых комбинациями оснований A, C, G и T в ДНК, но аминокислот в составе белков всего 20. Это означает, что одну и ту же аминокислоту кодирует несколько триплетов (три триплета не кодируют ничего, а обозначают окончание перевода мРНК в последовательность белковой цепи, как точка обозначает конец предложения). Для нас вами очень удобно (и имеет огромное эволюционное значение), что этот код, за несколькими небольшими исключениями, один и тот же для всех видов организмов (вот почему для получения человеческих белков, таких как инсулин, можно использовать бактерии).
Таким образом, зная специфическую последовательность ДНК, можно определить закодированную в ней последовательность белка. Однако не вся последовательность ДНК кодирует белки. Достаточно большая доля ДНК является «некодирующей». Первая проблема, с которой сталкиваются ученые при расшифровке длинной последовательности ДНК, состоит в определении начала и конца «кодирующей» области. К счастью, теперь эту задачу решают на компьютерах с помощью специальных алгоритмов, которые отлично ищут и находят «иголки» в «стогах» ДНК.
Кодирующая последовательность среднего гена состоит примерно из 1200 оснований. У некоторых видов организмов, в частности у бактерий или дрожжей, тысячи генов упакованы очень плотно и разделены сравнительно короткими промежутками некодирующей ДНК. У человека и многих других сложных существ гены составляют лишь небольшую долю всей ДНК и разделяются протяженными некодирующими участками. Какие-то из этих участков нужны для регуляции функций генов, а остальные называют мусорной ДНК. Эта мусорная ДНК накапливается в геноме в результате действия нескольких механизмов и часто содержит длинные повторяющиеся участки, не несущие информации. Эти участки не удаляются из ДНК естественным отбором, если только не оказывают вредного воздействия. Я не буду долго рассказывать об этой ДНК, но не упомянуть о ней нельзя, поскольку она составляет заметную часть нашего генома — как открытое море, разделяющее группы островов (гены).
Назад: Глава 3 Бессмертные гены. Бег на месте в погоне за вечностью
Дальше: Судьбы генов. Бессмертное ядро

