Книга: Много цифр. Анализ больших данных при помощи Excel
Назад: Переходим к кластеризации!
Дальше: Подытожим
Туда и обратно: история Gephi
Теперь, когда вы прошли через полный процесс кластеризации, я бы хотел вам показать, как выглядит то же самый процесс в Gephi. На рис. 5-20 мы рассматривали экспорт и визуализацию графа r-окрестности в Gephi, к которому я возвращаюсь в этом разделе.
Этот этап пробудит в вас зависть, и он уже близок. В Excel вы находили оптимальную модулярность графа с помощью разделительной кластеризации. В Gephi есть кнопка Modularity. Вы найдете ее с правой стороны окна раздела Network Overview вкладки Statistics.
При нажатии кнопки Modularity открывается окно настроек. Вам не нужно использовать веса ребер, так как вы импортировали матрицу смежности (окно настроек модулярности Gephi можно увидеть на рис. 5-41).
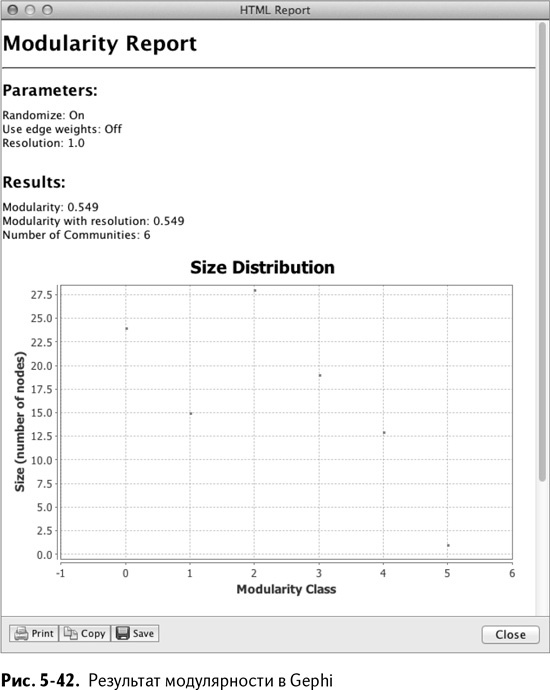
Нажмите ОК. Запустится оптимизация модулярности с использованием алгоритма приближения. Этот алгоритм выполняется практически со скоростью света. Отображается отчет – модулярность равна 0,549, как и размер каждого из кластеров (рис. 5-42). Обратите внимание: если вы запускаете этот алгоритм в Gephi, решение может оказаться другим, так как расчет рандомизирован.
Получив в Gephi кластеры, можно с ними позабавиться.
Перекрасьте граф в соответствии с модулярностью. Так же, как вы меняли размер графа «Друзей» с помощью степени вершины, зайдите в окно Ranking в верхнем левом углу экрана и откройте раздел Nodes (вершины). Выберите из выпадающего меню Modularity Class, подберите понравившуюся цветовую палитру и нажмите Apply, чтобы перекрасить граф (рис. 5-43).
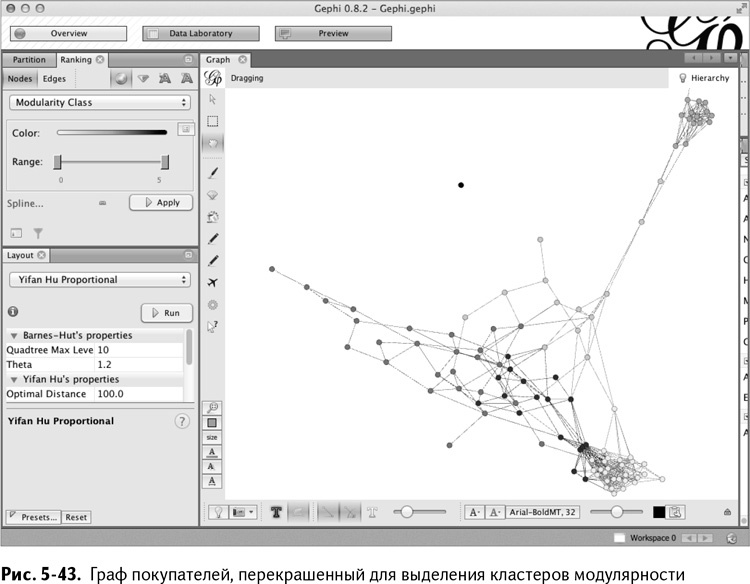
Отлично! Теперь вы видите, что эти два «гнезда» на графе – определенно группы. Рассеянная средняя часть графа разделена на три кластера. И бедного Паркера поместили в собственный кластер, не связанный ни с кем. Грустно и одиноко.
Второе, что вы можете сделать с информацией о модулярности, – это экспортировать ее обратно в Excel для изучения, как вы поступали с вашими собственными кластерами. Для этого зайдите во вкладку Data Laboratory, где вы уже были раньше. Вы заметите, что классы модулярности уже заполнены в столбце таблицы Nodes. Нажав кнопку Export Table, выберите ярлык и столбцы класса модулярности, чтобы перевести их в файл CSV (рис. 5-44).
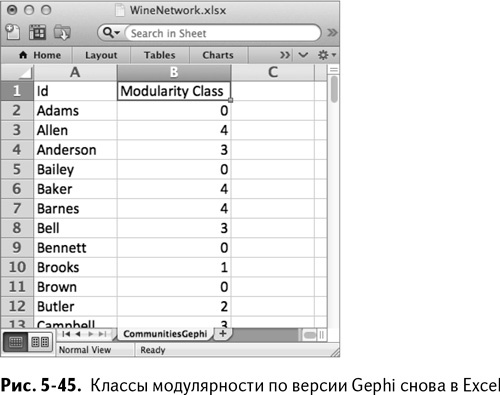
Нажмите «Выполнить» в окне экспорта, чтобы перенести ваши классы модулярностей в формат CSV, а затем откройте этот файл в Excel. Здесь, в основной рабочей тетради, создайте новую вкладку под названием CommunitiesGephi, куда затем вставьте те классы, которые нашел для вас Gephi (рис. 5-45). Также можно воспользоваться фильтром для сортировки покупателей по имени, как они и расположены в остальных таблицах рабочей тетради.
Просто для смеха докажем, что эта кластеризация лучше первоначальной по значению столбца С. Вы больше не связаны необходимостью строить только линейные модели, так что можно подсчитать итоговую модулярность для каждого покупателя с помощью следующей формулы (показанной здесь на примере Адамса, нашего любимого покупателя, в ячейке С2):
{=SUMPRODUCT(IF($B$2:$B$101=B2,1,0),
TRANSPOSE(Scores!B2:CW2))}
{=СУММПРОИЗВ(ЕСЛИ($B$2:$B$101=B2,1,0),
ТРАНСП(Scores!B2:CW2))}
Эта формула проверяет наличие покупателей в том же кластере, используя оператор IF/ЕСЛИ, раздает им значения 0 или 1, а затем использует SUMPRODUCT/СУММПРОИЗВ для сложения их модулярностей.
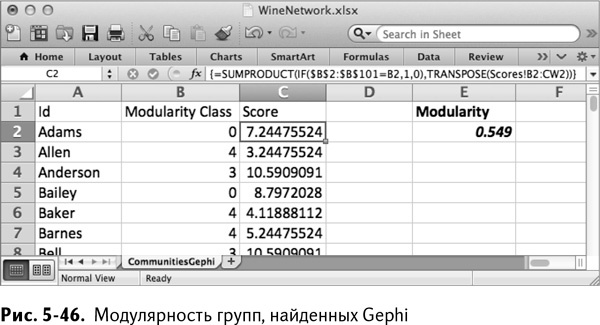
Вы можете кликнуть на этой формуле дважды, чтобы распространить ее на весь столбец С. Складывая значения в ячейке Е2 и деля их поочередно на общее число «пеньков» из r-NeighborhoodAdj'!CX102, вы, несомненно, получите общую модулярность, равную 0,549 (рис. 5-46). Так что эвристика Gephi выигрывает у эвристики разделительной кластеризации 0,003. О, да! Довольно близко. (Если вы использовали OpenSolver, то могли победить и Gephi.)
Давайте посмотрим, какие кластеры нам нашла Gephi. Сначала скопируйте вкладку TopDealsByCluster и переименуйте ее в TopDealsByClusterGephi. Теперь отсортируйте их обратно по столбцу А, пренебрегая предыдущей сортировкой. Теперь, по версии Gephi, у вас есть 6 кластеров, пронумерованных от 0 до 5 (ваш результат может отличаться, поскольку Gephi использует рандомизированный алгоритм), так что добавим 4 и 5 в нашу смесь в столбцы L и М, соответственно.
Нужно только немного подправить формулу в ячейке Н2, чтобы она обращалась к столбцу В вкладки CommunitiesGephi вместо столбца D вкладки Communities. А теперь можно растянуть формулу на весь лист, получая таблицу, изображенную на рис. 5-47.
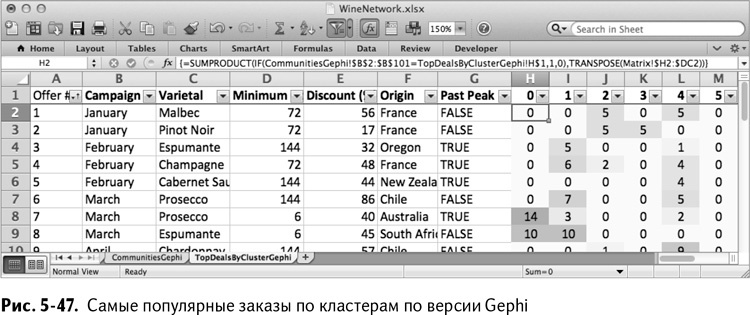
Еще раз отсортировав результаты по столбцам, вы увидите все те же знакомые кластеры – мелкий опт, игристое вино, франкофилы, любители пино, крупный опт и последняя, но не самая худшая – Паркер, собственной персоной.
Назад: Переходим к кластеризации!
Дальше: Подытожим

