Книга: Основы информационных технологий для неспециалистов: что происходит внутри машин
Назад: Часть IV Данные
Дальше: 12. Искусственный интеллект и машинное обучение
11. Данные и информация
Когда вы смотрите на интернет, интернет смотрит на вас.Приношу извинения Фридриху Ницше за искажение его слов из книги «По ту сторону добра и зла», 1886
Почти все, что вы делаете на компьютере, телефоне или с помощью кредитной карты, генерирует данные о вас. Эти сведения тщательно собирают, анализируют, хранят вечно и зачастую продают совершенно неизвестным вам организациям.
Представьте себе обычное взамодействие с Сетью. Вы ищете на компьютере или смартфоне какой-нибудь товар, место или информацию по теме, которую хотите изучить. Поисковые системы записывают, что и когда вас интересовало, куда вы заходили, на какие результаты нажимали – и, если у них получается, связывают все это конкретно с вами. Рекламодатели используют полученные данные, чтобы выводить для вас адресные уведомления о своих предложениях.
Мы все что-то ищем и приобретаем, развлекаем себя фильмами и телесериалами в Сети. Мы общаемся с друзьями и родственниками по электронной почте, через текстовые сообщения, а иногда даже голосовыми звонками. С помощью Facebook или Instagram мы не отдаляемся от товарищей и знакомых, LinkedIn помогает поддерживать связь с потенциальными работодателями, а сайты для свиданий – находить романтических партнеров (возможно). Мы читаем Reddit, Twitter и онлайн-новости, чтобы оставаться в курсе событий вокруг нас. Мы управляем нашими деньгами и оплачиваем счета онлайн. Мы повсюду ходим с телефоном, который точно знает, где мы находимся в любое время. Автомобили определяют наше местоположение и передают эту информацию другим. А вездесущие камеры, конечно же, в курсе, где сейчас наши машины. Домашние системы (например, сетевые термостаты, системы безопасности и умные приборы) отслеживают каждое наше движение, знают, когда мы дома и что мы там делаем.
Ни один бит этого потока персональных данных не пропадает зря. В 2018 году Cisco, ведущий производитель сетевого оборудования, выпустил прогноз, где говорилось, что годовой глобальный интернет-трафик превысит 3 зеттабайта в 2021-м115. Приставка «зетта» означает 1021, что по любым меркам целая куча байт. Откуда берутся все эти данные и что с ними делают? Ответы отрезвляют, ведь большинство сведений собирают не для нас, а о нас. Чем обширнее данные, тем больше информации о нас получают незнакомые люди, тем заметнее снижается уровень нашей безопасности и нарушается право на личную жизнь.
Я начну с веб-поиска, поскольку сбор огромного количества сведений начинается в поисковых системах. Отсюда мы перейдем к обсуждению отслеживания – наблюдения за тем, какие сайты вы посетили и что там делали. Далее я расскажу о персональной информации, которую люди непреднамеренно отдают или обменивают на развлечения или удобный сервис. Где ее всю хранят? Чтобы ответить, мы рассмотрим базы данных (БД) – коллекции данных, которые накапливают самые разные участники процесса. Здесь же мы обсудим агрегирование данных и интеллектуальный анализ, поскольку ценность сведений повышается, когда их комбинируют и получают новые выводы. Именно здесь возникает большинство проблем с конфиденциальностью: изучая сочетание информации о нас из разных источников, посторонние слишком легко выявляют то, что касается только нас. Наконец, я уделю внимание облачным вычислениям. В рамках этой услуги мы сами передаем все данные компаниям, которые обеспечивают их хранение и обработку на своих серверах, а не на наших компьютерах.
11.1. Поиск
Веб-поиск зародился в 1995 году, когда Всемирная паутина по сегодняшним меркам была еще крошечной. Количество веб-страниц и запросов быстро выросло в течение следующей пары лет, а в начале 1998-го вышла оригинальная статья Сергея Брина и Ларри Пейджа о Google – «Анатомия крупномасштабной гипертекстовой системы поиска в Сети». В ней говорилось, что AltaVista, одна из наиболее популярных поисковых систем, в конце 1997-го обрабатывала 20 миллионов запросов в день. Авторы точно предсказали, что к 2000 году сеть будет состоять из миллиарда страниц и сотен миллионов запросов в сутки116. По одной из оценок, в 2017 году подавалось уже 5 миллиардов запросов в день.
Поиск – это большой бизнес, который менее чем за 20 лет превратился из ничего в крупную индустрию. Например, компания Google, основанная в 1998 году, вышла на фондовую биржу в 2004-м, а к осени 2020-го ее рыночная капитализация составляла триллион долларов. Это меньше, чем у Apple (более 2 триллионов долларов), но намного больше, чем у таких давно известных компаний, как Exxon Mobil и AT&T, которые оценивались менее чем в 200 миллиардов долларов каждая. Google высокорентабелен, но существует высокая конкуренция, поэтому… кто знает, что может произойти дальше? (Здесь уместно кое-что раскрыть: я по совместительству работаю в Google, и у меня много друзей в этой корпорации. Но, естественно, ничто из написанного в этой книге не должно восприниматься как позиция Google по какому-либо вопросу.)
Как функционирует поисковая система (ПС)? С позиции пользователя – запрос печатается в форме на вебстранице и отправляется на сервер, который почти мгновенно возвращает список ссылок и фрагментов текста. На стороне сервера все сложнее. Он формирует список вебресурсов, содержащих одно или несколько слов из запроса, сортирует их по релевантности, «обертывает» фрагменты страниц в теги HTML и отправляет пользователю.
Однако Всемирная паутина слишком велика, чтобы каждый запрос пользователя инициировал поиск по всей Сети. Поэтому основная задача ПС – поддерживать готовность к запросам, сохраняя и сортируя на сервере информацию о страницах. Это делается с помощью индексирования Сети. В ходе него сканируются страницы, а релевантное содержимое заносится в БД, чтобы ответы на последующие запросы находились быстро. Индексирование – это широкомасштабный пример кэширования: результаты поиска основываются на предварительно вычисленном индексе кэшированной информации о странице, а не на просмотре интернет-страниц в реальном времени.
На рис. 11.1 примерно показана организация этого процесса, включая размещение рекламы на странице результатов.
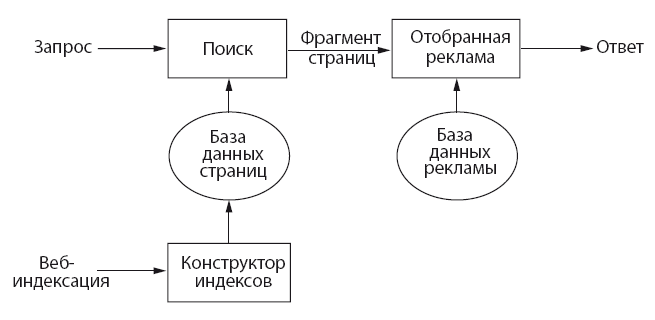
Рис. 11.1. Организация поисковой системы
Проблема в масштабе. Существуют миллиарды пользователей и много миллиардов веб-страниц. Поисковик Google раньше сообщал, сколько ресурсов он проиндексировал для создания индекса, но, когда их количество перевалило за 10 миллиардов, перестал это делать.
Допустим, размер обычной веб-страницы составляет 100 Кб, а для хранения ста миллиардов ресурсов требуется 10 петабайт дискового пространства. Некоторые из них статичны и не меняются месяцами или даже годами, но значительная часть ресурсов быстро обновляется (новостные сайты, блоги, ленты в Twitter), поэтому индексирование следует вести непрерывно и эффективно. Возможности отдохнуть не будет, ведь индексируемая информация не должна устаревать. Поисковые системы обрабатывают миллиарды запросов в день, причем для каждого из них требуется просканировать БД, найти релевантные страницы и отсортировать их в правильном порядке. Также необходимо выбрать рекламу, выводимую вместе с результами, и фоном записать в журналы все данные, которые помогут улучшить качество поиска, опередить конкурентов и продать больше рекламы117.
С нашей точки зрения, ПС – отличный пример алгоритмов в действии. Но при таком объеме трафика ни один простой алгоритм поиска или сортировки не будет работать достаточно быстро.
Для индексирования используется целое семейство алгоритмов: они решают, какую страницу просматривать следующей и какую индексируемую информацию брать из нее (слова, ссылки, изображения и т. д.), а также доставляют взятые данные в конструктор индексов. Они извлекают URL-адреса, устраняют дубликаты и нерелевантные записи, а оставшиеся добавляют в список для дальнейшей проверки. Процесс усложняется тем, что поисковый робот не может посещать конкретный сайт слишком часто, поскольку это значительно увеличит нагрузку и вызовет неудобство. Возможно, поисковику даже откажут в доступе. Так как скорость изменений на страницах широко варьируется, полезно задействовать алгоритмы, способные точно оценить ее. Тогда робот сможет чаще посещать те страницы, что меняются быстрее.
Следующий компонент – построение индекса. У робота поисковой системы берутся страницы, извлекаются релевантные части каждой из них, а затем все это индексируется вместе с URL-адресом и положением фрагмента на страничке. Детали процесса зависят от контента, который нужно проиндексировать. Текст, изображения, электронные таблицы, PDF-файлы, видео и так далее – все они требуют разной обработки. По сути, индексирование готовит список ресурсов и местоположений для каждого слова или индексируемого элемента, встретившегося на какой-либо веб-странице, и сохраняет эти данные в форме, позволяющей затем быстро извлекать перечень страниц для любого конкретного элемента.
Заключительная задача – формулирование ответа на запрос. Основная идея здесь в том, чтобы собрать все слова из запроса, использовать списки индексации для быстрого поиска релевантных URL-адресов, а затем выбрать самые подходящие из них (тоже быстро). Подробности данного процесса – драгоценные секреты операторов поисковых систем, поэтому в Сети вы найдете мало конкретных сведений о применяемых методах. И снова важное значение имеет масштаб: любое запрошенное слово может появиться на многих миллионах страниц, два – на одном миллионе, и все потенциальные ответы нужно стремительно просеять, чтобы оставить только десять лучших. Чем лучше ПС выводит точные попадания в топ и чем быстрее реагирует, тем чаще люди станут обращаться к ней, а не к ее конкурентам.
Первые поисковые системы просто отображали список ресурсов, где содержались слова из запроса, но по мере роста сети результаты стали походить на нагромождение нерелевантных страниц. Оригинальный алгоритм Google PageRank присваивал каждому ресурсу показатель качества. Он придавал больший вес страницам, на которые ссылались другие ресурсы или страницы, уже имеющие высокий рейтинг. Алгоритм «считал», что они с наибольшей вероятностью будут релевантны запросу. Как говорят Брин и Пейдж, «интуитивно понятно, что страницы, на которые обширно ссылаются из множества мест в интернете, заслуживают внимания». Естественно, для получения высококачественных результатов требуется не только это, поэтому поисковые компании постоянно ищут способы превзойти конкурентов по такому показателю.
Для обеспечения полномасштабного поиска требуются огромные вычислительные ресурсы: миллионы процессоров, терабайты оперативной памяти, петабайты внешней памяти и пропускная способность, измеряемая в Гб/с, гигаватты электроэнергии и, конечно, много людей. За все это нужно как-то платить, обычно за счет доходов от рекламы.
Попросту говоря, рекламодатели платят за размещение объявлений на веб-странице, причем тариф определяется тем, сколько людей (и из каких категорий) заходят на нее. Цена может зависеть от количества просмотров ресурса («показов», которые учитывают сам факт того, что объявление появилось на странице), кликов (пользователь щелкнул на рекламу) или «конвертации», когда человек в конечном счете что-то купил. Клиенты, которые изначально могут заинтересоваться тем, что рекламируется, явно ценнее прочих, поэтому в наиболее распространенной модели владелец поисковика проводит аукцион по поисковым запросам в режиме реального времени. Рекламодатели борются там за право размещать рекламу рядом с результатами поиска по конкретному запросу. Компания, в итоге выигравшая аукцион, получает прибыль, когда пользователь щелкает по ее объявлениям.
Google Ads (ранее AdWords) позволяет легко экспериментировать с предлагаемой рекламной кампанией. Например, их инструмент оценки (см. рис. 11.2) говорит, что ожидаемая стоимость поискового слова «керниган» и связанных с ним – например, unix и «программирование на С» – будет составлять 5 центов за клик, то есть каждый раз, когда кто-то ищет один из этих терминов и затем щелкает на мою рекламу, я буду платить Google 5 центов. Инструмент также подсчитал, что по выбранным мной поисковым запросам будет совершаться 194 клика в день при ежедневном бюджете в 10 долларов (в среднем за месяц) – хотя, конечно, никому неведомо, как много людей нажмут на мою рекламу и во сколько мне это обойдется. Я никогда не пытался проверить на опыте.
Могут ли рекламодатели платить за то, чтобы результаты поиска подправлялись в их пользу? Это беспокоило Брина и Пейджа, которые написали в той же статье: «Мы ожидаем, что поисковые системы, финансируемые за счет рекламы, будут изначально предвзято относиться к рекламодателям и не станут учитывать потребности потребителей». Google получает большую часть доходов от объявлений. И хотя он разделяет результаты поиска и рекламу, как и большинство других ПС, во множестве судебных дел истцы обвиняли компанию в предвзятости и несправедливости по отношению к своим продуктам. В Google отвечают, что результаты поиска не предвзяты по отношению к чьим-либо конкурентам, а целиком базируются на алгоритмах, которые отражают предпочтения людей.
Еще одна возможная форма пристрастности появляется, когда фокус условно нейтральной выводимой рекламы слегка смещается в сторону определенных групп населения. Это предположительно основывается на создании профиля клиента в разрезе расы, религии или этнической принадлежности. Например, по некоторым именам понятно, что их обладатель относится к определенной расе или этносу, поэтому при их поиске какие-либо объявления могут показываться или, напротив, скрываться, если реклама не нацелена на данные группы.
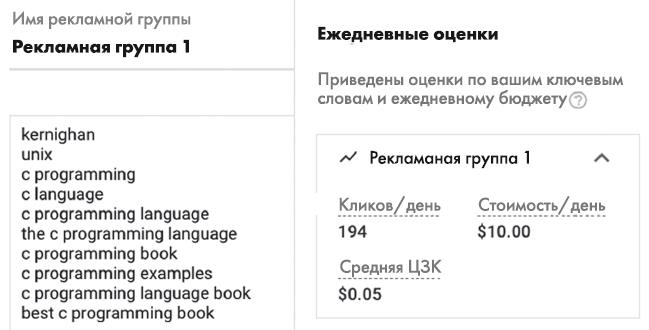
Рис. 11.2. Оценки Google Ads для «керниган» и связанных с ним слов
В США некоторые виды рекламы считаются незаконными, если в них отдается предпочтение какой-либо расе, религии или полу. Компания Facebook, которая тоже получает свой основной доход от объявлений, предоставляет своим клиентам инструменты для таргетированной рекламы с обширным набором критериев. Большинство из них вполне очевидны (доход, образование), но встречаются и такие, что явно незаконны или служат ширмой для возможной дискриминации. В 2019 году Facebook уладила миром тяжбу, где истец утверждал, что на ее платформе позволялось размещать рекламу, способствующую дискриминации118.
Возможно ли вообще искать что-то в сети так, чтобы ваши действия не отслеживали в таких подробностях? Поисковая система DuckDuckGo (DDG) утверждает, что не сохраняет вашу личную историю запросов и не выдает персонализированную рекламу. Поиск она отчасти выполняет самостоятельно, но в основном агрегирует результаты из большого числа ПС и других ресурсов. DDG все же получает прибыль от рекламы, но ее можно заблокировать через Adblock и другие расширения. Кроме того, этот поисковик предлагает несколько полезных руководств с советами о том, как просматривать веб-страницы и пользоваться смартфоном с меньшим риском для вашей безопасности и неприкосновенности частной жизни119.
11.2. Отслеживание
Обсуждение выше касалось поиска, но изложенные идеи применимы к любому виду рекламы. Чем точнее нацелить ее, тем значительнее вероятность, что она вызовет благоприятную реакцию зрителя, а значит, тем больше будет готов заплатить рекламодатель. Те, кто отслеживает вас онлайн – то есть наблюдает, что вы ищете, какие сайты посещаете, что делаете на них, – способны многое узнать о вас и о том, чем вы занимаетесь. В настоящее время отслеживание прежде всего ведется для того, чтобы более эффективно продавать вам что-либо, но несложно догадаться, что есть и другие способы применения столь подробных сведений. В данном разделе мы сосредоточимся в основном на механизмах отслеживания: куки-файлах, веб-жучках, JavaScript и браузерной идентификации.
Когда мы пользуемся интернетом, о нас неизбежно собирают информацию. Мы оставляем след практически при каждом действии. То же самое верно для других систем, особенно мобильников, которые во включенном состоянии всегда знают наше физическое местоположение. Когда вы не в помещении, любому аппарату с функцией GPS (а она есть во всех смартфонах) известно, где вы находитесь, с погрешностью в десять метров, и он способен в любое время передать ваши координаты. В некоторые цифровые камеры также встроена функция GPS, что позволяет им кодировать географическое положение в каждой фотографии. Это называется привязкой к местности (оно же геотегирование'). Также камеры применяют для выгрузки изображений Wi-Fi или Bluetooth. В общем, очевидно, что вас могут отслеживать и через них.
Если совместить подобные следы с нескольких устройств, удастся нарисовать подробную картину наших действий, интересов, финансов, окружения и многого другого. В самом безопасном случае эту информацию используют для более точного нацеливания рекламы, то есть нам будут показывать то, на что мы отреагируем с большей вероятностью. Но отслеживание может и не ограничиться этим, и тогда его результаты применят в менее невинных целях. Это способно привести к дискриминации, материальному убытку, краже личных данных, полицейскому надзору и даже ущербу для здоровья.
В 2019 и 2020 годах газета «Нью-Йорк тайме» опубликовала большую серию статей о конфиденциальности и отслеживании. Одна из наиболее показательных и тревожных частей – исследование БД о местоположении смартфонов на 50 миллиардов записей. База охватывала 12 миллионов человек в нескольких крупных городах США. Данные поставлялись из анонимного источника – вероятно, того, кто работал с брокером данных. Цитата из «Нью-Йорк тайме»120:
Компании, которые собирают всю информацию о ваших передвижениях, оправдывают свое занятие, выдвигая три утверждения: люди дают согласие на отслеживание, данные анонимны и находятся в безопасности.Ни одно из трех не выдерживает проверки.
«Нью-Йорк тайме» смогла точно определить значительное число личностей, сопоставив сведения о мероприятиях, домашних и рабочих адресах и тому подобном. Журналисты работали с 50 миллиардами записей, но сообщили, что компании, занимающиеся данными о местоположении, каждый день собирают на порядок больше информации, в том числе большой объем демографических сведений, что упрощает корреляцию и идентификацию121. В теории в «анонимных» данных не содержатся сведения, позволяющие установить личность, однако на практике легко выявить связи, четко определяющие человека, особенно при объединении информации из нескольких источников. Эта статья серьезно настораживает, как и серия материалов в целом.
Как собирают сведения? Какие-то данные автоматически отправляются браузером при каждом запросе. Среди них IP-адрес, страница, которую вы просматривали (ссылающийся домен, или «реферер»), тип и версия вашего браузера («агент пользователя») и ОС, ваши языковые предпочтения. Вы можете ограниченно этим управлять. На рис. 11.3 показана некоторая отсылаемая информация, отредактированная для краткости.
Кроме того, если есть куки-файлы из домена сервера, они тоже отправляются. Но, как обсуждалось в предыдущей главе, «печеньки» возвращаются только в тот домен, откуда их прислали. Так как же один сайт может использовать эти файлы, чтобы отслеживать посещение других ресурсов?
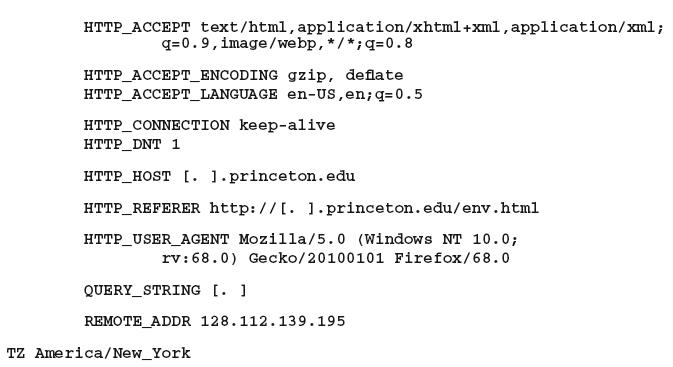
Рис. 11.3. Некоторая информация, отправляемая браузером
Ответ скрывается в работе ссылок. Одни веб-страницы содержат ссылки на другие, в чем и состоит суть связывания через гиперссылки. Мы знакомы со ссылками, на которые нужно обязательно нажимать, чтобы перейти по ним. Но по ссылкам на изображения и скрипты не нужно кликать: они автоматически передаются из источника по мере загрузки страницы. Если ресурс содержит ссылку на картинку, то она пересылается из указанного домена. Обычно в URL-адресе изображения закодированы сведения о странице, отправляющей запрос, поэтому, когда мой браузер извлекает картинку, ее домен узнаёт, на каком ресурсе я нахожусь, и тоже может сбросить куки-файлы на мой компьютер или телефон, а также получить информацию о моих предыдущих посещениях. То же самое относится к скриптам JavaScript.
Это самая суть отслеживания, поэтому давайте разберемся более подробно. В качестве эксперимента я выключил все мои средства защиты и зашел на сайт https:// toyota.com через браузер Safari. При первом посещении мне закачались куки-файлы с более чем 25 разных сайтов, а также 45 изображений со всевозможных ресурсов и более 50 программ JavaScript общим объемом более 10 Мб.
Страница продолжала отправлять сетевые запросы все время, пока я оставался на сайте, и вообще выполняла столько фоновых вычислений, что Safari предупредил меня об этом (рис. 11.4).
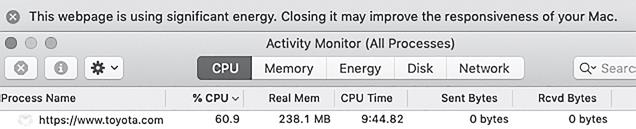
Рис. 11.4. Веб-страница, которая не устает вычислять
Теперь становится понятно, почему мои студенты, когда я прошу их посчитать куки-файлы, говорят, что у них уже набрались тысячи. Это также объясняет, почему подобные страницы порой медленно загружаются. (Если хотите, поставьте опыт сами: информацию можно найти в истории браузера и настройках конфиденциальности.) Я не проверял, что получится на смартфоне, поскольку расход трафика пробил бы крупную брешь в моем скромном тарифном плане.
Обычно, когда у меня включены средства защиты – Ghostery, Adblock Plus, uBlock Origin, NoScript, запрет на куки-файлы, «не использовать локальное хранилище данных», – я вообще не получаю ни «печенек», ни скриптов.
Значительное количество картинок на той веб-странице относились к тому же типу, что изображение, выделенное на рис. 11.5. То есть на ресурсе Toyota содержится ссылка на Facebook, которая извлекает картинку. Изображение прозрачно, а также имеет ширину и высоту в 1 пиксель, поэтому оно полностью невидимо.
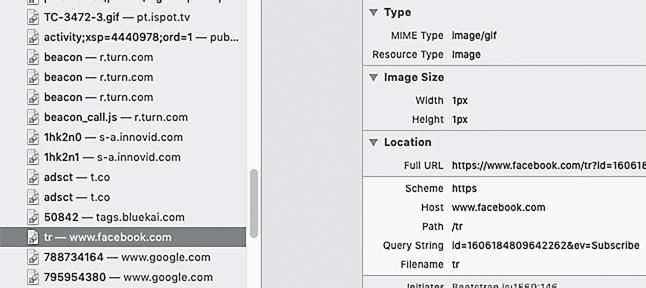
Рис. 11.5. Однопиксельное изображение для отслеживания
Такие однопиксельные изображения часто называют веб-жучками или веб-маяками. Создают их исключительно для отслеживания. Когда мой браузер запрашивает эту картинку с Facebook, тот ресурс узнаёт, что я смотрю на определенную страницу Toyota.com, и (если я разрешаю это) сбрасывает мне куки-файлы. Когда я посещаю другие сайты, каждая отслеживающая компания может составить представление о том, что я ищу. Если мои поиски в основном касаются машин, наблюдатели сообщают об этом потенциальным рекламодателям, и тогда мне начинают выводить объявления насчет автомобилей от дилеров, кредитов и аксессуаров. Если я заинтересуюсь несчастными случаями и купированием боли, мне будут показывать больше рекламы от ремонтных служб, юристов и терапевтов.
Компании вроде Google, Facebook и многих других собирают информацию о сайтах, на которые мы заходили, после чего используют ее, чтобы продавать рекламные места клиентам вроде Toyota. Те, в свою очередь, применяют данные для целенаправленной рекламы и (возможно) сопоставляют их с другими сведениями обо мне, помимо моего IP-адреса. По мере того как я посещаю все больше веб-страниц, отслеживающие компании создают все более детальную базу данных о моих предполагаемых характеристиках и интересах. Возможно, в итоге они определят, что я мужчина, женат, мне более 60 лет, у меня две машины, я живу в центральном районе штата Нью-Джерси и работаю в Принстонском университете. Чем больше они знают обо мне, тем точнее их клиенты сумеют подбирать для меня объявления. Конечно, таргетинг как таковой – это не идентификация личности, но в какой-то момент определить ее станет довольно просто (хотя многие компании говорят, что таким не занимаются). Однако если на какой-либо странице я указываю свое имя или адрес электронной почты, то нет никакой гарантии, что эти данные не передадут кому-то еще.
В 2016 году «Вашингтон пост» опубликовала серию материалов о конфиденциальности122. Одна статья вышла под заголовком «98 персональных элементов данных, с помощью которых Facebook подгоняет рекламу под вас». В этот список входят не только очевидные параметры вроде местоположения, возраста, пола, языка, уровня образования, размера доходов и капитала, но и более щекотливые, такие как «этническое сродство», что может применяться для незаконной дискриминации123.
Интернет-реклама – это продуманный рынок. Когда вы запрашиваете веб-страницу, ее публикатор уведомляет рекламную биржу (например, Google Ad Exchange или AppNexus), что есть доступное пространство на ресурсе, и сообщает информацию о вероятном посетителе: например, «одинокая женщина 25–40 лет из Сан-Франциско, которая любит технологии и хорошие рестораны». Рекламодатели предлагают цены за место, и объявление победителя размещается на странице. Весь процесс занимает пару сотен миллисекунд.
Если вам не нравится такое отслеживание, то его можно значительно ограничить, хотя кое-чем придется пожертвовать. Браузеры позволяют вам полностью отказаться от куки-файлов или отключить только сторонние. Также вы можете напрямую удалить «печеньки» в любое время. Или же поручите браузеру, чтобы он автоматически очищался от них при каждом закрытии. Крупные компании, занимающиеся отслеживанием, предоставляют механизм отказа: если они обнаружат определенный куки-файл на вашем компьютере, то не станут наблюдать за вашими действиями в целях таргетирования (хотя высока вероятность, что они продолжать собирать информацию о вас на собственных сайтах).
Еще имеется полуофициальный механизм «Не отслеживать» (Do Not Track), который больше обещает, чем делает. В браузерах, обычно в меню конфиденциальности и безопасности, есть опция с таким названием. Если ее выбрать, вместе с запросами будет отправляться дополнительный HTTP-заголовок (см. пример на рис. 11.3). Вебсайт, который соблюдает этот механизм, не будет передавать данные о вас другим сайтам, хотя может свободно сохранять информацию для собственных нужд. В любом случае никого не обязывают уважать желания посетителей, и большинство ресуров игнорируют такие предпочтения. Например, Netflix сообщает: «В настоящее время мы не реагируем на сигналы веб-браузера „не отслеживать"»124.
Приватный просмотр, или режим инкогнито, – это механизм на стороне клиента, который предписывает браузеру очистить историю, куки-файлы и другие данные о просмотре, когда сеанс завершится. В таком случае другие пользователи вашего компьютера не смогут узнать, что вы делали (вот почему это неофициально называется «порнорежим»). Однако на то, что запоминают посещенные вами сайты, данная опция нисколько не влияет: с большой вероятностью они узнают вас при следующем входе. Впрочем, некоторые ресурсы все же отказываются предоставлять контент, если вы находитесь в режиме инкогнито.
Механизмы защиты не стандартизируются между браузерами (или даже разными версиями одного браузера), а настройки по умолчанию часто выставляются так, чтобы сделать вас уязвимым.
К сожалению, многие сайты не работают без куки-файлов, но большинство отлично загружается без сторонних «печенек», поэтому их всегда стоит выключать. Некоторые виды куки-файлов используются обоснованно: веб-сайту нужно знать, что вы уже вошли в систему, или записывать, что лежит у вас в корзине покупок. Но чаще всего «печеньки» применяются для отслеживания. Это раздражает меня настолько, что я предпочитаю не посещать такие места.
JavaScript – это основной инструмент отслеживания. Браузер запустит любой код JS, найденный в исходном HTML-файле или загруженный с URL с src="name. js" внутри тэга <script>. Это обширно используется для «аналитики», которая отслеживает просмотры определенного ресурса. Например, когда я посещаю Slashdot. org, сайт новостей о технологиях, мой браузер загружает 150 Кб для самой страницы и еще 115 Кб скриптов JS для аналитики с других трех сайтов, включая этот от Google:

(Отмечу, что, когда лично я захожу на Slashdot, ни один из этих аналитических скриптов не загружается, потому что их блокируют расширения Adblock и Ghostery.)
Код JavaScript может как присылать, так и извлекать куки-файлы сайта, с которого он пришел, и получать доступ к другой информации (например, истории посещения страниц в браузере). Он также способен непрерывно мониторить положение курсора и отправлять отчеты на сервер, что пригодится для расчетов того, какие части веб-страниц вас заинтересовали, а какие – нет. Он отслеживает места, где вы щелкаете мышкой или выделяете текст, даже если это не такие чувствительные области, как ссылки.
На рис. 11.6 показаны несколько строк кода JS, который отображает положение мышки при ее перемещении. Если добавить еще парочку, скрипт начнет передавать такую же информацию поставщику любой веб-страницы, просматриваемой вами. Туда же уйдут и сведения о других событиях – например, где вы печатаете, щелкаете или куда переносите блоки. Если хотите увидеть гораздо более отточенную и очень занимательную реализацию той же идеи, зайдите на сайт clickclickclick, click.

Рис. 11.6. JavaScript для отображения координат при перемещении мышки
При браузерной идентификации вас могут опознать (зачастую однозначно) без куки-файлов, при помощи индивидуальных особенностей вашего браузера. Сочетание сведений об ОС, браузере, его версии, языковых предпочтениях, установленных шрифтах и плагинах формирует очень характерный набор. Также на основе новых возможностей HTML5 можно увидеть, как конкретный браузер отображает определенную последовательность символов. Подобная методика называется снятием цифровых отпечатков125. Достаточно собрать несколько таких идентифицирующих сигналов, чтобы различать и определять отдельных пользователей независимо от настроек их куки-файлов. Конечно, рекламодатели и другие организации здорово обрадуются, если сумеют точно узнавать людей независимо от того, блокируют они «печеньки» или нет.
Electronic Frontier Foundation предлагает поучительный сервис Panopticlick. Он назван в честь «Паноптико-на» Иеремии Бентама – тюрьмы, спроектированной так, чтобы за арестантами там можно было постоянно наблюдать незаметно для них самих. Зайдя на coveryoutracks. eff.org, вы узнаете, насколько (примерно) вы уникальны среди других недавних посетителей. Даже если у вас хороший уровень защиты, вас, скорее всего, идентифицируют однозначно или хотя бы приблизительно. Когда вы откроете сайт в следующий раз, вас опознают с высокой вероятностью.
Сервис Blacklight, который можно найти на themarkup. org/blacklight, имитирует незащищенный браузер и сообщает вам о трекерах (включая те, которые пытаются обойти блокровщиков рекламы), сторонних куки-фай-лах, отслеживании мышки и клавиатуры и других коварных практиках. Иногда довольно страшно видеть, как активно за вами наблюдают, а вот искать самых злостных нарушителей скорее забавно. Например, кулинарный сайт epicurious.com загрузил 136 сторонних куки-файлов и 44 рекламных трекера, причем одновременно он мониторил нажатия клавиш и щелчки мыши, передавая данные о посещении в Facebook и Google.
Механизмы отслеживания не ограничиваются браузерами – они также применяются почтовыми и другими системами. Если ваш почтовик интерпретирует HTML, то он «отобразит» те самые однопиксельные картинки, с помощью которых кто-то будет наблюдать за вами. Apple TV, Chromecast, Roku, TiVo и Fire TV Stick от Amazon – все они в курсе, что вы смотрите. Так называемые «умные телевизоры» тоже это знают, а еще они способны отправлять своему производителю ваш голос и даже изображения с их камер. Устройства с поддержкой речи вроде Amazon Echo также пересылают для анализа то, что вы произносите126.
Как мы уже знаем, каждый IP-пакет на пути от вашего компьютера до места назначения проходит от 15 до 20 шлюзов. Это верно и для пакетов, которые отправляются обратно. Каждый шлюз на маршруте может заглянуть в содержимое пакета и даже изменить его неким образом. Это называется глубокой проверкой пакетов (ГПП), потому что просматриваются не только заголовки, но и само содержимое. Обычно все происходит на стороне вашего интернет-провайдера, поскольку именно здесь вас проще всего идентифицировать. И речь не только о просмотре веб-страниц, а обо всем трафике между вами и интернетом.
Иногда глубокая проверка пакетов ведется в законных целях – например, для исключения вредоносных программ. Но ее могут применять и для более точного таргетирования рекламы, а также для мониторинга или вмешательства в трафик, входящий в страну или исходящий из нее (вспомним «Великий Китайский брандмауэр» и жучков, поставленных на каналы связи американским АНБ).
Единственная защита от ГПП – сквозное шифрование в HTTPS. Оно не позволяет проверять и изменять содержимое во время его передачи, однако не скрывает метаданные – например, источник или точку назначения.
Правила, регулирующие, какую личную информацию можно собирать и как ее разрешено использовать, варьируются в зависимости от страны. Говоря по-простому, в США позволено все: любая компания или организация вправе безо всяких уведомлений собирать и распространять сведения о вас, не предоставляя вам возможность отказаться.
В Европейском союзе неприкосновенность частной жизни воспринимается более серьезно (опять же, если сильно упростить): компании не могут законно собирать или применять данные о человеке без его прямого разрешения. В соответствующей части GDPR (General Data Protection Regulation), который вступил в силу в середине 2018 года, сказано, что персональные данные недопустимо обрабатывать без прямого одобрения. Даже если в онлайн-форме по умолчанию выставлено «Отказываюсь», не считается, что пользователю дана возможность выразить информированное согласие. Также у людей есть право получить доступ к своей личной информации и следить, как ее используют. Согласие можно отозвать в любое время.
В 2016 году США и ЕС заключили соглашение, в котором регулировался порядок перемещения данных между двумя регионами и учитывалась защита прав граждан Евросоюза на неприкосновенность частной жизни. Однако в июле 2020 года высший суд ЕС постановил, что соглашение не соответствует нормам Евросоюза в данной области, поэтому сейчас ситуация в подвешенном состоянии127.
В начале 2020 года вступил в силу Закон о конфиденциальности потребителей в Калифорнии (ССРА), чьи цели и параметры аналогичны Общему регламенту ЕС. В нем прописано, что люди должны иметь возможность явно запретить продажу их данных. Хотя этот акт распространяется только на жителей одной территории, мы можем надеяться, что его влияние ощутят по всей стране. В Калифорнии живет более 10 % населения США, и она часто опережает другие штаты в решении социальных вопросов.
Однако пока еще слишком рано говорить о том, хорошо ли работают Общий регламент ЕС и ССРА.
11.3. Социальные сети
Информацию о нас собирают не только путем отслеживания при просмотре веб-сайтов. Пользователи социальных сетей, по сути, добровольно соглашаются поделиться внушительным объемом сведений о своей личной жизни в обмен на развлечения и поддержание связи с другими людьми.
Сколько-то лет назад я наткнулся на пост в Сети, где говорилось что-то вроде «На собеседовании меня спрашивали о том, что я не упоминал в резюме. Они просматривали мою страничку в Facebook, и это возмутительно, потому что она посвящена моей личной жизни, а их вообще не касается». Это трогательно наивно и невинно, но есть подозрение, что по крайней мере часть пользователей Facebook испытывала подобное чувство поругания – пусть даже хорошо известно, что работодатели и приемные комиссии колледжей регулярно используют поисковые системы, социальные сети и подобные ресурсы, чтобы получить более подробную информацию о кандидате. В США незаконно спрашивать соискателя о возрасте, этнической принадлежности, религии, сексуальной ориентации, семейном положении и о многом другом, относящемся к персональным сведениям, – но это можно легко и незаметно определить с помощью соцсетей.
Поисковые системы и социальные сети предоставляют полезные услуги, и они бесплатны, что же тут плохого? Но им нужно как-то зарабатывать. Помните: если вы не платите за продукт, то вы и есть продукт. Бизнес-модель соцсетей строится на том, что они собирают горы информации о своих пользователях и продают ее рекламодателям. Соответственно, у них чуть ли не по определению будут проблемы с конфиденциальностью.
За то недолгое время, что существуют соцсети, они резко выросли в размерах и влиянии. Facebook основали в 2004 году, а в 2020-м компания сообщала о более чем 2,5 миллиарда активных пользователей ежемесячно – около трети населения всего мира. (Facebook также владеет Instagram и WhatsApp, и сведения передаются между операторами.) Ежегодный доход в 70 миллиардов долларов практически полностью обеспечивается за счет рекламы. При таком стремительном росте у корпорации нет времени на то, чтобы тщательно продумывать политику и неторопливо разрабатывать надежные компьютерные программы. Каждый сайт социальных сетей сталкивался с проблемами разглашения личных данных из-за плохо продуманных функций, неясных для пользователей настроек конфиденциальности (которые часто меняются), ошибок в ПО и утечек информации, присущих системе в целом.
Проблемы Facebook как крупнейшей и самой успешной соцсети были наиболее заметны. Некоторые из них возникли из-за того, что корпорация предоставляет третьим лицам API для написания приложений, которые запускаются в пользовательском контексте, а они могут раскрывать личные данные вопреки политике конфиденциальности компании128. Опять же, такие проблемы есть и у других соцсетей129.
Сервисы геолокации отображают местоположение пользователей на мобильных телефонах, что упрощает личные встречи с друзьями или позволяет участвовать в играх, где учитываются ваши координаты. Адресная реклама становится особенно эффективной, если известно, где в реальности находится потенциальный клиент. Вы с большей вероятностью отреагируете на предложение от ресторана, если стоите около его двери, а не читаете о нем в газете. С другой стороны, дрожь пробирает, когда вы понимаете, что с помощью смартфона отслеживаются даже ваши действия в пределах магазина. Тем не менее продавцы начинают использовать внутримагазинные маячки. Если вы регистрируетесь в системе (обычно скачивая определенное приложение или неявно соглашаясь на отслеживание), маячки, применяя Bluetooth для общения с вашим телефоном, определяют, где именно в торговом зале вы находитесь, и делают вам предложение, посчитав, что вас привлечет какой-то определенный товар. Процитируем одну компанию, которая разрабатывает такие системы: «Маячки возвещают о революции мобильного маркетинга внутри помещений»130.
Конфиденциальность местоположения131– право на то, чтобы ваши координаты знали только вы сами, – нарушается такими системами, как кредитные карты, системы оплаты проезда на автомагистралях и общественном транспорте и, конечно же, смартфоны. Становится все сложнее не оставлять следов в каждом посещаемом месте. Приложения для мобильников – самые худшие нарушители: они часто запрашивают доступ практически ко всей информации, которую телефон о вас знает, включая данные звонков, физическое местоположение и так далее. Интересно, зачем программе-фонарику нужны мои координаты, контакты и журнал вызовов?
Разведывательным службам давно известно, что они могут многое выяснить, анализируя, кто с кем общается, даже если к содержанию разговоров нет доступа. Именно по этой причине АНБ собирало метаданные по всем телефонным звонкам в США: номера абонентов, время и длительность. Изначально Агентство получило разрешение на такую деятельность в ряду прочих необдуманных реакций на террористическую атаку 11 сентября 2001 года, но об истинных масштабах накапливания сведений никто не подозревал до публикации Сноудена в 2013-м. Если даже поверить заявлению, что там «просто метаданные, а не сами разговоры», то учтите, что и такая информация бывает исключительно показательной. Эд Фелтен из Принстонского университета, давая показания на слушаниях Судебного комитета Сената в октябре 2013 года, объяснил, как метаданные превращают частную историю в достояние гласности132:
Эти метаданные на первый взгляд могут показаться не более чем «информацией о набранных номерах». Но анализ метаданных телефона часто раскрывает информацию, которую традиционно удавалось получить лишь путем прослушивания самого разговора. То есть метаданные нередко замещают собой содержимое.Вот самый простой пример. Определенные номера телефонов используются для конкретной цели, так что, узнав о любом контакте, мы раскрываем основную (и часто конфиденциальную) информацию о том, кто звонил. Примерами могут служить горячие линии поддержки для жертв домашнего насилия и изнасилований. Также существует большое количество горячих линий для людей, задумавшихся о самоубийстве, – включая специальные сервисы для служб экстренного реагирования – для ветеранов, несовершеннолетних геев и лесбиянок. Для тех, кто страдает от зависимости в какой-либо форме – алкогольной, наркотической, игровой, – тоже имеются горячие линии.Схожим образом, у главных инспекторов практически в каждом федеральном агентстве, включая АНБ, есть горячие линии, на которые сообщается о неправомерных действиях, растратах, мошенничестве. Во многих государственных налоговых службах выделяется отдельная горячая линия для сообщений о налоговом мошенничестве. Также были созданы горячие линии для сообщений о преступлениях на почве ненависти, поджогах, незаконном обороте оружия и жестоком обращении с детьми. Во всех этих случаях метаданные сами по себе передают много информации о содержании звонка, даже без дополнительных сведений.Запись о звонке, указывающая, что кто-то воспользовался горячей линией по борьбе с сексуальным насилием или линией для сообщений о налоговом мошенничестве, конечно, не раскрывает фразы из самого разговора. Но данные о том, что звонок на один из этих номеров продолжался 30 минут, сообщают информацию, которую практически каждый счел бы крайне конфиденциальной.
Это же верно и в отношении явных и неявных взаимодействий в социальных сетях. Намного проще установить связи между людьми, когда они сами всё предоставляют в открытом виде. Например, «лайки» в Facebook можно использовать для точного определения таких характеристик, как пол, этническая принадлежность, сексуальная ориентация и политические взгляды. Это указывает на то, какие выводы можно сделать из информации, свободно выкладываемой пользователями социальных сетей133.
Кнопки для «лайков» в Facebook и аналогичные им в Twitter, LinkedIn, YouTube и других сетях значительно упрощают отслеживание и выявление связей. Щелкая на иконку социальной сети на какой-нибудь страничке, вы сообщаете, что просматриваете ее. По сути, это рекламное изображение, пусть даже видимое, а не скрытое, и оно дает поставщику шанс отправить вам куки-файлы.
Утечка личной информации через социальные сети и другие сайты возможна даже в том случае, если вы ими не пользуетесь. Например, если я получаю приглашение в электронном виде (e-vite) на вечеринку от благонамеренного друга, компания, которая предоставляет такую услугу, узнаёт действующий адрес моей почты, хотя я не отвечал на послание и не давал никаких разрешений на использование моего адреса.
Если друг помечает меня на фотографии, опубликованной на Facebook, тайна моей личной жизни нарушается без моего согласия. Эта соцсеть обеспечивает функцию распознавания лиц, благодаря которой пользователям проще отмечать своих друзей, что по умолчанию позволено делать без их разрешения. И я, похоже, способен контролировать ситуацию лишь отчасти: можно запретить соцсети предлагать кому-то отмечать меня, но не сами отметки. Как пишет Facebook:
Когда вы включаете в настройках распознавание лиц, мы используем соответствующую технологию для анализа фотографий и видео, на которых вы предположительно можете присутствовать – например, на фотографии профиля или там, где вас уже отмечали, – чтобы создать шаблон вашего образа. Мы применяем данный шаблон для распознавания вашего изображения на других фотографиях, видео и прочих местах, где используется камера (например, в прямом эфире) в Facebook.Если вы отключаете эту функцию: <… > Мы не будем применять распознавание лиц, чтобы предлагать людям отмечать вас на фотографиях. Это означает, что вас по-прежнему могут отметить на фотографиях, но мы не будем предлагать ставить пометки, основываясь на шаблоне распознавания лиц134.
Я вообще не пользуюсь Facebook и поэтому удивился, обнаружив, что у меня «есть» страница в этой соцсети, очевидно, автоматически сгенерированная на основе статьи в «Википедии». Досадно, но тут я мало что могу поделать – только надеяться, что люди не подумают, будто я одобряю такое.
Любая система с большим числом пользователей способна легко создать «социальный граф» взаимодействий между ее непосредственными участниками, а также включить в него тех, кто вовлечен косвенно, – без их согласия или даже ведома. Во всех этих случаях у человека не будет возможности избежать проблем заблаговременно. А после того как информация уже создана, ее сложно удалить.
Хорошенько подумайте о том, что вы рассказываете миру о себе. Перед тем как отправить почту, написать пост или твит, сделайте паузу на пару секунд и задайте себе вопрос: понравится ли вам, если загруженные вами слова или изображения напечатают на первой странице «Нью-Йорк тайме» или покажут в главном сюжете в выпуске новостей на ТВ? Ваша письма, текстовые сообщения и твиты, скорее всего, будут храниться вечно и могут всплыть годы спустя в позорном для вас контексте.
11.4. Интеллектуальный анализ и агрегирование данных
Интернет и Всемирная паутина совершили революцию в том, как люди собирают, хранят и представляют информацию. Поисковые системы и базы данных имеют настолько огромную ценность для всех, что даже сложно вспомнить, как мы раньше обходились без интернета. Массивные объемы данных (так называемые большие данные) служат исходным материалом для распознавания речи, автоматического перевода, выявления мошенничества с кредитными картами, систем рекомендаций, информации о дорожном движении в реальном времени и многих других полезных услуг.
Вместе с тем распространение данных онлайн имеет крупные недостатки, особенно если речь идет об информации, способной поведать о нас что-нибудь лишнее.
Несомненно, есть различные публичные сведения, и некоторые их подборки предназначены для поиска и индексирования. Так, если я создам веб-страницу для этой книги, мне определенно будет выгодно, чтобы ее легко находили поисковые системы.
Но как насчет открытых архивов? Закон гласит, что данные определенных типов доступны по запросу каждому представителю общественности. В Соединенных Штатах это судебные разбирательства, документы по ипотеке, цены на жилье, местные налоги на недвижимость, записи о рождении и смерти, свидетельства о браке, списки избирателей, взносы на политические цели и тому подобное. (Обратите внимание, что из свидетельства о рождении можно узнать дату и порой – девичью фамилию матери, а ведь то и другое часто используют для проверки личности пользователя.)
В прежние времена, чтобы получить такую информацию, требовалось добраться до местного правительственного учреждения. Поэтому, хотя формально архивы считались «открытыми», ради доступа к ним приходилось постараться. Человеку, искавшему данные, следовало показаться лично, предъявить документы и, возможно, даже заплатить за каждую физическую копию. Сегодня сведения часто доступны онлайн, и я могу проверять публичные акты анонимно, не выходя из дома. Или даже организовать свое дело, собирая эту информацию и комбинируя ее с другой. Например, популярный сайт zillow.com отображает на карте цены на жилье, основываясь на планах местности, объявлениях агентств недвижимости, общественные данные о земельной собственности и сделках. Такой сервис сочтут полезным те, кто собирается продать или купить дом, однако в других ситуациях, вероятно, люди назвали бы его бесцеремонным. Подобные сайты добавляют сведения о нынешних и прошлых жильцах, данные об их регистрации на выборах и в качестве затравки намекают, что у них, возможно, криминальное прошлое. Из базы данных Федеральной избирательной комиссии (fec.gov), где записаны пожертвования на выборы, четко видно, каких кандидатов поддержали ваши друзья и известные люди. Также в ней возможно найти их домашние адреса. Это создает неустойчивое равновесие, которое больше склоняется в сторону права публики на осведомленность, нежели права отдельной личности на неприкосновенность частной жизни.
Трудно сказать, какую информацию следует делать настолько доступной. Политические взносы точно нужно показывать, а вот домашние адреса жертвователей лучше скрыть. Персональные идентификаторы, такие как номера социального страхования США, ни в коем случае нельзя выкладывать в Сеть – с их помощью легко завладеть личными данными. Записи об арестах и снимки задержанных иногда попадают в общий доступ, всё это размещают на некоторых сайтах – их бизнес-модель строится на том, что они берут деньги с людей за удаление фотографий! Существующие законы не всегда способны предотвратить раскрытие такой информации, а если данные попали во Всемирную паутину, значит, поезд ушел – они останутся там навсегда.
Опасения по поводу свободного доступа к сведениям становятся особенно серьезными, если учесть, что можно объединять данные из нескольких источников, на первый взгляд не связанных между собой. Например, компании, которые обеспечивают работу веб-сервисов, записывают огромный объем информации о своих пользователях. Поисковые системы регистрируют все запросы вместе с IP-адресом, с которого они поступили, и куки-файлами предыдущего посещения.
В августе 2006 года, исходя из лучших побуждений, AOL опубликовал большую выборку поисковых журналов для исследования. Перед этим компания анонимизировала логи, содержащие 20 миллионов запросов от 650 000 пользователей за три месяца, теоретически полностью удалив все данные, по которым удалось бы идентифицировать ее клиентов. Но, несмотря на благие намерения AOL, на практике быстро выяснилось, что логи не такие уж анонимные. Оказалось, что пользователям назначались случайные, но уникальные ID, по которым получилось найти последовательности запросов от одних и тех же личностей, а затем однозначно определить как минимум нескольких из них. Люди искали свои имена, адреса, номера социального страхования и другие персональные данные. Сопоставление поисковых запросов раскрыло больше сведений, чем предполагали в AOL, включая огромные объемы информации, которую сами пользователи явно не хотели бы делать общедоступной. Компания быстро удалила журналы запросов со своего веб-сайта, но, разумеется, опоздала: данные уже разошлись по всему миру.
Подобные логи содержат информацию, ценную для ведения бизнеса и улучшения качества обслуживания, но, очевидно, в них также находятся потенциально уязвимые персональные данные. Как долго поисковые системы должны сохранять такие сведения? В этом вопросе компании подвергаются внешнему давлению с разных сторон: с точки зрения конфиденциальности всё надо удалять как можно скорее, а с позиции правоохранительных органов – наоборот. До какой степени следует обрабатывать данные внутри системы, чтобы добиться большей обезличенности? Некоторые компании утверждают, что удаляют часть IP-адреса для каждого запроса (обычно крайний правый байт), но этого может не хватить для анонимизации клиента. Насколько обширный доступ к такой информации нужно давать правительственным учреждениям? А что раскрывать, если подадут гражданский иск? Ответы на эти вопросы далеко не очевидны.
В журналах AOL попадались пугающие запросы (например, «как убить своего супруга»), поэтому вполне уместна идея, что в определенных ситуациях стоит открывать правоохранительным органам доступ к этим записям. Но где провести черту – не совсем понятно. Между тем существует горстка поисковых систем, которые утверждают, что не хранят журналы запросов. Наиболее распространенная из них – DuckDuckGo.
История с AOL иллюстрирует общую проблему: по-настоящему анонимизировать данные трудно. Определяя, какую идентифицирующую информацию удалить, люди обычно мыслят узко: «Если в этих конкретных данных нет ничего, что позволило бы установить личность человека, значит, они безопасны». Однако в реальном мире также имеются другие источники сведений, и часто можно сделать выводы, комбинируя факты из нескольких ресурсов, о которых первоначальный поставщик данных ничего не знал. Возможно, тогда они еще даже не появились.
Описанный выше пример ярко высветил эту проблему повторной идентификации. В 1997 году Латанья Суини, тогда аспирант МТИ, изучила якобы анонимизированные медицинские карты 135 000 государственных служащих Массачусетса. Эти данные обнародовала государственная комиссия по страхованию: они предназначались для проведения исследований, и их даже продали одной частной компании. Каждая карта, помимо различной информации, включала в себя дату рождения, пол и текущий почтовый индекс. Суини нашла шесть человек, которые родились 31 июля 1945 года: трое из них были мужчинами, но только один жил в Кембридже. Сопоставив такие сведения с общедоступным списком регистрации избирателей, она смогла идентифицировать Уильяма Уэлда, на тот момент губернатора Массачусетса.
И это не единичный случай. В 2014 году Комиссия по такси и лимузинам Нью-Йорка опубликовала анонимизированный набор данных обо всех 173 миллионах поездок на такси в городе в 2013 году. Но обработку выполнили некачественно, что позволило определить ход процесса, обратить его и заново привязать информацию о каждой машине к поездкам на основании номера «бляхи» – лицензии такси135. Предприимчивый стажер по аналитике данных тогда же обнаружил, что можно найти фотографии знаменитых людей, садящихся в такси, где виден номер лицензии. Этого хватило для воссоздания подробностей о десятке поездок, вплоть до суммы чаевых.
Приятно верить, что разгадать какой-нибудь секрет не сумеет никто, потому что непосвященные знают слишком мало. Но приведенные выше примеры показывают, что возможно получать важные сведения, объединяя наборы данных, которые никогда не предполагалось изучать в совокупности136. Вероятно, недругам уже известно о вас больше, чем вы думаете. А если еще нет, то со временем им станет доступно больше информации.
11.5. Облачные вычисления
Вспомните модель вычислений, описанную в главе 6. У вас есть персональный компьютер – один или несколько. Вы запускаете отдельные приложения для выполнения разных задач – например, Word для работы с документами, Quicken или Excel для расчета личных финансов и iPhoto для обработки фотографий. Программы работают на вашем компьютере, но при этом могут связываться через интернет с некоторыми службами. Время от времени вы закачиваете новую версию с исправленными ошибками, а иногда покупаете обновления, чтобы получить новые функции.
Суть этой модели заключается в том, что программы и их данные обитают на ваших компьютерах. Если вы измените файл на одной машине, а затем он понадобится вам на другой, то придется переносить его самому. Если окажется, что вам нужен файл, который хранится на компьютере дома, а вы сейчас в офисе или в путешествии, то вам не повезло. Если вам требуется работать с Excel или PowerPoint и на ПК с Windows, и на Мас, то придется купить программу для каждого. И ваш телефон не будет никак с ними связан.
В настоящее время нормой стала другая модель: использование браузера или смартфона для доступа и обработки информации, хранящейся на интернет-серверах. Самые распространенные примеры здесь – почтовые сервисы, например Gmail или Outlook. Вы можете зайти в почту с любого компьютера или телефона. Хотя вы вправе выгрузить туда послание, написанное локально, или скачать письмо в локальную файловую систему, в большинстве случаев вы просто оставляете всю информацию «лежать» у поставщика услуги. Вы не получаете уведомлений об обновлениях программы, однако в ней иногда появляются новые функции. Мы часто поддерживаем связь с друзьями и просматриваем их фотографии через Facebook – так вот, сообщения и изображения сохраняются на этой платформе, а не на вашем компьютере. Подобные сервисы бесплатны. Единственная «видимая» стоимость заключается в том, что порой вам показывают рекламу, пока вы читаете письмо или просматриваете ленту друзей.
Эту модель обычно называют облачными вычислениями, потому что интернет метафорически именуют «облаком» (рис. 11.7) без определенного физического местоположения, а про информацию говорят, что она хранится где-то «в облаке».
Почта и социальные сети – наиболее распространенные облачные сервисы, но существует множество других, таких как Dropbox, Twitter, LinkedIn, YouTube и онлайн-календари. Данные размещаются не локально, а в облаке, то есть на оборудовании поставщика услуг: почта и календарь находятся на серверах Google, фотографии – на серверах Dropbox или Facebook, резюме – на LinkedIn и так далее.

Рис. 11.7. Облако137
Облачные вычисления возможны благодаря сочетанию ряда факторов. ПК стали более мощными, то же самое произошло с браузерами: они теперь способны эффективно запускать большие программы с высокими требованиями к отображению, пусть даже ЯП – интерпретируемый JavaScript. Пропускная способность намного выросла, а время ожидания между клиентом и сервером уменьшилось по сравнению с тем, что наблюдалось десять лет назад. Соответственно, стало возможно быстро отправлять или получать данные, даже реагировать на нажатие клавиши и предлагать варианты окончания слов в процессе печати. В результате браузер может производить большинство операций пользовательского интерфейса, для которых в прошлом потребовалась бы автономная программа. При этом он полагается на сервер для хранения основной массы данных и выполнения любых тяжелых вычислений. Такая организация хорошо подходит и для телефонов: теперь не требуется скачивать те или иные приложения.
Браузерная система бывает почти такой же отзывчивой, как и настольная, причем обеспечивает доступ к данным практически из любого места. Взгляните на облачные «офисные» инструменты от Google, которые предоставляют текстовый редактор, электронные таблицы и программу для презентаций. Кроме того, они обеспечивают одновременный доступ и обновление данных несколькими пользователями.
Возникает интересный вопрос: заработают ли когда-нибудь облачные инструменты настолько хорошо, что вытеснят настольные версии? Несложно представить, как обеспокоена Microsoft – она ведь получает значительную часть доходов от Office, и к тому же эти программы работают в основном на Windows, на которую приходится большая часть остального заработка компании. Текстовым редакторам и электронным таблицам на базе браузера не нужна платформа от Microsoft, поэтому они угрожают обоим ключевым направлениям ее бизнеса. На данный момент Google Docs и подобные системы не предоставляют всех возможностей Word, Excel и PowerPoint, однако история технологического прогресса изобилует примерами, когда появлялась явно худшая система, набирала новых пользователей, которым хватало и ее возможностей, и постепенно съедала действующего лидера. Очевидно, Microsoft хорошо осведомлена об этой проблеме, поэтому теперь предлагает облачную версию пакета, названную Office 365.
Веб-сервисы нравятся Microsoft и другим поставщикам, поскольку в них легко вводить модель подписки, то есть заставлять пользователей регулярно оплачивать доступ. Но возможно, что потребители предпочтут один раз приобрести ПО и при необходимости покупать обновления. На своих старых Mac я до сих пор использую версию Microsoft Office 2008 года. Она работает прекрасно и (к чести Microsoft) все еще иногда получает «заплатки» безопасности, поэтому я не спешу ничего менять.
Облачные вычисления полагаются на высокую скорость обработки и большой объем памяти у клиента, а также на значительную пропускную способность сервера. Код на стороне клиента пишется на JavaScript и часто замысловат. Он предъявляет высокие требования к браузеру: тот должен быстро обновлять и отображать графические материалы, реагируя на действия как пользователя (в частности, перетаскивание), так и сервера (например, обновления контента). Это достаточно сложно и усугубляется несовместимостью между браузерами и разными версиями JavaScript, вследствие чего поставщик обязан определять, каким способом лучше всего отправить клиенту правильный код. Однако процесс совершенствуется по мере того, как компьютеры становятся быстрее, а стандарты соблюдаются более строго.
В облачных вычислениях могут применяться разные компромиссные решения в плане того, где выполняются вычисления, и тем, где находится информация во время обработки. Один из способов сделать код JavaScript независимым от типа браузера – включить проверку условия в сам код, например «если браузер – Firefox версии 75, то сделайте это, если Safari 12, сделайте то, иначе сделайте что-то третье». Такой код очень громоздкий, следовательно, для того чтобы переслать программу JavaScript клиенту, потребуется большая пропускная способность, а дополнительные проверки замедлят работу браузера. В качестве альтернативы сервер может запросить у клиента, какой браузер используется, а затем отправить код, адаптированный к данной версии. Возможно, такой код будет более компактным и запустится быстрее, хотя для небольшой программы разница окажется незначительной.
Содержимое веб-страницы можно отправлять, не сжимая. В таком случае потребуется меньше обработки на обоих концах, но более высокая пропускная способность. Другой вариант – сжать контент. Тогда требования к пропускной способности снизятся, но нужно будет провести больше вычислений на обоих сторонах. Иногда компрессия выполняется только на одном конце. Так, чтобы сжать большие программы JavaScript, обычно удаляют все ненужные пробелы, а также дают переменным и функциям имена из одной-двух букв. Результаты получаются трудночитаемыми для человека, но для клиентского компьютера это не помеха.
Несмотря на технические сложности, облачные вычисления могут предложить вам много полезного – если у вас всегда есть доступ к интернету. ПО постоянно обновляется, информация хранится на профессионально обслуживаемом сервере с огромной емкостью, и клиентские данные регулярно копируются, поэтому риск потерять что-либо невелик. К тому же теперь у вас только одна копия документа, а не несколько вариантов (возможно, несовместимых) на разных компьютерах. Становится проще делиться файлами и совместно работать над ними в реальном времени. Цены очень выгодные: для индивидуальных пользователей сервис часто бесплатный, хотя бизнес-клиентам иногда приходится платить.
С другой стороны, с облачными вычислениями связаны непростые вопросы конфиденциальности и безопасности. Кому принадлежат данные, хранящиеся в облаке? Кто имеет к ним доступ и на каких условиях? Существует ли какая-либо ответственность в случае неумышленного разглашения информации? Как поступают с аккаунтами умерших людей? Кто может принудить раскрыть данные? Например, в каких ситуациях ваш поставщик почтовых услуг (добровольно или под угрозой иска) может передать вашу переписку в государственное учреждение или суд в рамках какой-нибудь тяжбы? Сообщат ли вам об этом? (В так называемых «письмах-требованиях касательно национальной безопасности» компаниям на территории США иногда запрещают уведомлять клиентов, что в их отношении подан правительственный запрос о предоставлении информации.) Как ответ на эти вопросы зависит от того, где вы живете? Что делать, если вы сами из Европейского союза, где приняты относительно строгие правила о конфиденциальности персональных сведений, но ваши облачные данные хранятся на сервере в Штатах и подчиняются актам вроде Закона о борьбе с терроризмом в США?
Это не гипотетические вопросы. Будучи университетским профессором, я по необходимости обладаю доступом к персональной информации студентов: прежде всего к оценкам, конечно, но порой и к важным данным личного и семейного толка. Все это приходит по почте и хранится в компьютере университета. Не нарушу ли я закон, если буду держать мои файлы с оценками и переписку в «облаке» от Microsoft? Если по какой-либо моей оплошности эта информация станет достоянием всего мира, что произойдет? А если некое правительственное учреждение потребует от Microsoft предоставить сведения об одном или нескольких студентах?138 Я не юрист и не знаю ответов, но беспокоюсь из-за всего этого и стараюсь не пользоваться облачными сервисами ни при работе с данными об учениках, ни при общении с ними. Я храню такие материалы на компьютерах университета, поэтому, если из-за небрежности или ошибки сотрудников наружу просочится что-то конфиденциальное, у меня будет хоть какая-то защита от обвинений в ответственности. Конечно, если я сам совершу оплошность, то уже неважно, где именно содержались сведения.
Кто может ознакомиться с вашей корреспонденцией и при каких обстоятельствах? Это не только технический вопрос, но и правовой, а потому ответ зависит от того, в какой юрисдикции вы проживаете. В США, насколько я понимаю, ваш работодатель вправе читать ваши письма в корпоративном ящике по своему желанию и не уведомляя вас. И точка. Причем это относится как к деловым, так и к личным посланиям. Основанием здесь служит то, что работодатель предоставляет свои материально-технические средства, поэтому имеет право удостовериться, что их применяют в деловых целях и в соответствии с требованиями компании и закона.
Мои письма обычно неинтересны, но мне будет очень неприятно, если мой работодатель станет заглядывать в них без особой на то причины, пусть даже закон разрешает ему так поступать. Если вы студент, то знайте: в большинстве университетов считается, что электронные письма учеников настолько же личные, как бумажные. По моему опыту, студенты применяют созданный для них аккаунт только как передаточное звено и отправляют все в Gmail. Многие университеты, включая мой, молчаливо признают это и нанимают для соответствующих услуг стороннюю фирму. Предполагается, что эти учетные записи отделены от стандартного сервиса, подпадают под действие правил о конфиденциальности учащихся и не содержат рекламы, однако данные все же хранятся у поставщика.
Если для личной корреспонденции вы, как и большинство людей, используете интернет-провайдера или облачные службы (например, Gmail, Outlook, Yahoo и многие другие), они обещают вам защиту персональных данных. Как правило, такие сервисы публично заявляют, что электронная почта их клиентов не подлежит оглашению и ни один человек не будет ее просматривать или раскрывать, разве что в случае запроса от судебного органа. При этом они обычно не затрагивают тему того, насколько решительно будут сопротивляться тем требованиям о предоставлении информации, которые кажутся слишком абстрактными, или неофициальным просьбам в обертке «интересов национальной безопасности». Вы зависите от того, готов ли ваш провайдер выдержать мощное давление. В США правительство стремится облегчить доступ к почте: до 11 сентября их стремление объяснялось борьбой с организованной преступностью, а после – войной с терроризмом. Натиск подобного рода возрастает равномерно, а после каждого теракта резко усиливается.
Например, в 2013 году небольшой компании Lavabit, которая предоставляла клиентам защищенную электронную почту, приказали установить на ее сети систему наблюдения, чтобы правительство США получило доступ к корреспонденции. Власти также распорядились передать им ключи шифрования и велели владельцу фирмы Ладару Левисону ничего не сообщать абонентам. Левисон отказывался, утверждая, что не соблюдена надлежащая правовая процедура. В итоге он предпочел закрыть компанию, а не открывать доступ к письмам своих клиентов139. Со временем стало очевидно, что правительство интересовали сведения лишь об одном аккаунте – Эдварда Сноудена140.
Сегодня в качестве альтернативы можно пользоваться ProtonMail. Этот поставщик услуг базируется в Швейцарии, обещает конфиденциальность и определенно находится в положении, позволяющем ему успешно игнорировать запросы других стран на получение информации. Но любая компания, независимо от того, где она зарегистрирована, может оказаться в тисках между правительственными агентствами и коммерческими структурами с их финансовым давлением.
Если не затрагивать вопросы конфиденциальности и безопасности, то какую ответственность несет Amazon или другие облачные провайдеры? Предположим, какая-то ошибка конфигурации приводит к тому, что работа сервиса AWS недопустимо замедляется в течение всего дня. Какое возмещение убытков может получить клиент AWS? Как правило, в контрактах это прописывают через соглашения об уровне обслуживания, но они не гарантируют хороший сервис – только дают основание для подачи судебного иска, если случится что-то серьезное.
Какие обязанности перед клиентами берет на себя поставщик услуги? Когда он будет стоять на своем и бороться, а когда уступит угрозам привлечения к ответственности или негласным просьбам «властей»? Таких вопросов возникает множество, а четких ответов совсем мало. Государство и частные лица всегда хотят получать больше сведений о других, но при этом стараются ограничить доступ к данным о себе. Ряд крупных игроков, включая Amazon, Facebook и Google, теперь публикуют «отчеты о прозрачности»: там указывается приблизительное количество запросов правительства, в которых оно требует удалить информацию, предоставить данные о пользователях, устранить нарушения авторских прав или произвести схожие действия. Помимо прочего, в этих докладах имеются заманчивые намеки на то, как часто крупные коммерческие организации дают отпор и на каких основаниях. Например, в 2019 году Google получил от правительств разных стран более 160 000 запросов о предоставлении сведений, касающихся примерно 350 000 аккаунтов пользователей. Примерно в 70 % из них компания раскрыла «некоторые данные». Facebook сообщает о примерно таком же количестве запросов и разглашений141.
11.6. Краткие выводы
При помощи технических средств мы создаем объемные потоки детализированных данных – гораздо более крупные, чем нам кажется. Все эти сведения перехватывают для коммерческого использования: передают, комбинируют, изучают и продают с гигантским размахом. Такой «взаимовыгодный обмен» позволяет нам пользоваться ценными услугами вроде веб-поиска, социальных сетей, приложений на телефоне и безлимитных хранилищ в Сети, бесплатный доступ к которым мы принимаем как должное. Общественность становится все более осведомленной (хотя и недостаточно) о масштабах сбора данных. Рекламодатели уже стали обращать внимание, что многие сейчас применяют блокировщики рекламы. Это вполне разумно, поскольку рекламные сети часто, пусть и непреднамеренно, становятся источниками вредоносных программ. Но не совсем понятно, что произойдет, если все подключат Ghostery и Adblock Plus. Перестанет ли Сеть в ее нынешнем виде работать, или кто-нибудь изобретет альтернативные бизнес-модели для поддержки Google, Facebook и Twitter?
Данные также собирают в интересах правительства, что в долгосрочной перспективе выглядит более пагубным. Государственные органы наделены полномочиями, которых нет у коммерческих предприятий, и им труднее противостоять. В каждой стране люди по-разному пытаются влиять на поведение своих властей, но в любом случае для начала неплохо узнать, что к чему.
Очень эффективный рекламный слоган AT&T из начала 1980-х гласил: «Протяни руку и коснись кого-нибудь». Интернет, электронная почта, текстовые сообщения, социальные сети и облачные вычисления – все это упрощает задачу. Иногда все работает просто замечательно: вы можете находить друзей, общаться по интересам в гораздо более обширных сообществах, чем при личных встречах. Однако же, протягивая руку, вы становитесь видимым и доступным для всего мира, где далеко не каждый желает вам добра. Так вы открываете двери для спама, мошенничества, шпионских программ, вирусов, отслеживания, полицейского надзора, кражи персональных данных, утраты конфиденциальности и даже денег. Будьте осторожны – это разумно.
Назад: Часть IV Данные
Дальше: 12. Искусственный интеллект и машинное обучение

