S ince its entry into the arena of business intelligence tools, Power BI has rapidly climbed positions within this segment of data analysis and decision-making systems development, to position itself as one of the most interesting options that They exist today thanks to a numerous set of qualities, among which a powerful capacity for graphical representation of the resident information in the data model, as well as the integration into the Power Query product, the extraction, transformation and loading engine (ETL) also included in Excel.
Precisely, the data mentioned above cleaning and debugging processes represent one of the main pillars of the phases that make up the development of an information system, so having a powerful and versatile tool to perform these operations is essential. Power Query, thanks to its rich user interface, which allows us to carry out the most varied operations of transformation and adaptation of the source data, gives Power BI a great power in the preparation of the data that we will later model using Power Pivot (DAX), to convert them into accessible information through dashboards, reports, etc.
In the following figure, we can see a broad graphical representation of the different phases that constitute the development of an information system using Power BI.

And if this were not enough, where we cannot reach the operations available in the user interface, Power Query also offers us the possibility to schedule tasks through M, its formula language, which considerably expands the range of options at our disposal.
The term self-service BI is usually associated with the ability of certain users of a DataWarehouse to connect to the system, obtain a subset of their information and analyze it independently to the main system, creating a smaller BI structure focused on certain aspects of the main.
These are users with an advanced profile and great knowledge of the nature of the data handled by the system, which, together with the appropriate tools, can analyze the information with a different degree of precision than is normally required by the bulk of end-users.
This type of user frequently works with the developers of the DataWarehouse responsible for the design and creation of databases, cubes (multidimensional or tabular), dashboards, etc., since it provides very valuable information for the proper optimization of processes involved in its creation, that is why having quality self-service BI tools such as Power BI helps to improve the final result of the information system.
Since its emergence in the BI market, Power Pivot, Power View, and ultimately, Power Query, all add-ins of Excel, have been presented as self-service tools BI, intended for advanced users mentioned above. However, the evolution and improvement in performance of this entire suite of add-ons, and the subsequent appearance of Power BI as an integrator of all of them (Power Pivot analytical engine, Power View display engine, and Power Query transformation engine) in a only product, they turn them not only into software for information systems analysts but also very useful tools for the developers of such systems.
The objective will be to approach the development of a Power BI model, focusing mainly on the extraction, transformation, and loading (ETL) operations that we will carry out through Power Query, but also paying attention to the important volume of data that we can handle through this application.
It is not about explaining Power Query in all its details but about making an introduction to it and M, its programming language, addressing some of the most common techniques in data processing, which serve the reader as an initiation, at the same time as we observe the management capacity you have working with datasets of several million records.
It is assumed that the reader has Power BI installed on your machine to follow the examples described; however, in the following , it is possible to download the installer.
As a source of the model that we are going to build, we will use imaginary data on the imaginary population registered in the Register of inhabitants of the Cities of a country.
The said registry is formed by the information related to the residents of the populations that make up the national territory, sent by the different cities to the authority, which offers an anonymous version of this information to the citizens through the so-called microdata files.
Each of these files, available in the Statistics of the Continuous Register, contains, in plain text format, information on the population registered in the country on January 1 of each year, where each row of the file represents an individual.
As we have just said, these data are adequately anonymized to comply with the data protection regulations, and among them, we can obtain the place of residence and birth by Province, city, and country, as well as the age, sex and size of the city by the number of inhabitants.
Also complying with the requirements of the authority regarding the use of these files, we must inform the reader that the degree of accuracy of the information elaborated from these files does not depend on the INE, but in this case, the processes and operations carried out with Power BI (Power Query) as software used to perform its operation.
For the example that we are going to develop, we will use the file corresponding to the statistics data as of January 1, 2016 (for example, 46 million records.)
Once we have accessed the download page, we will click on the “Go” button to obtain the micro_2016.txt text file with the population data. We will also click on the link Registration design and valid values of the variables, which will provide us with the file Design and values of the variables of the Census_2016.xlsx Microdata File, containing the guide of the population file registration design, as well as the data to feed the search tables or catalogs that we will use in the model: list of Provinces, municipalities, countries, etc. From now on, we will refer to this file in an abbreviated form as an Excel source or Excel source file. Due to space issues, both files are downloaded compressed in zip format, and subsequent decompression is necessary.
As we have advanced previously, each row of the population file contains a string of digits with the data of an individual. In the following example, we see a random sample of one of these rows.
030141010021080840009
To extract each of the particles that identify the different properties of the person, we will use as a guide the Design sheet of the source Excel file, which shows us the meaning and positions that correspond to it within the total string of digits.
Using these indications, the following figure shows a brief scheme of the distribution of the values for the next process that we will implement with Power Query, to segment them so that they make sense in the subsequent modeling phase.
We finally arrived at the moment to start the fieldwork. First, we will run Power BI and select the Get Data option from the External Data group, which will show a list of the most common types of data sources, from which we will choose Text / CSV.

Next, a dialog box will open in which we will navigate to the path in which we have deposited the population data file micro_2016.txt. After selecting it, Power BI will display a preview of its first rows.
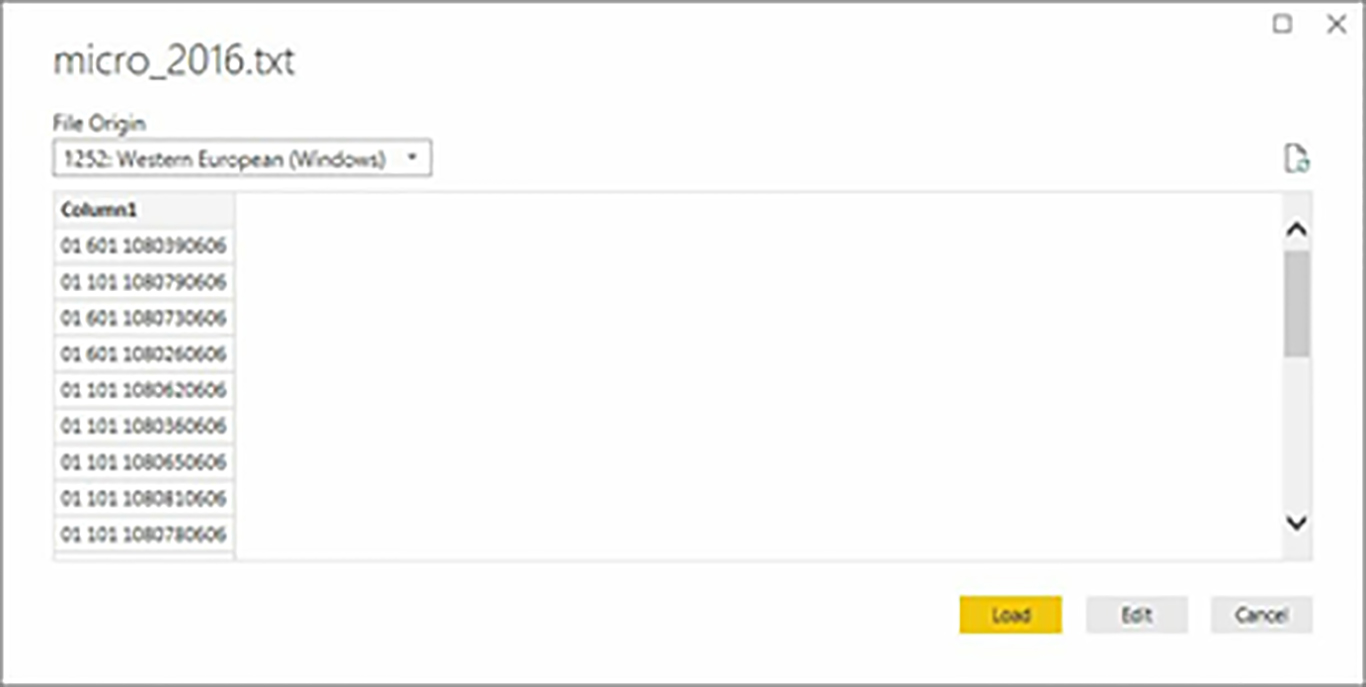
Next, we will click on Edit, and with that, Power BI will give way to the Power Query engine, represented by the query editor window or Query Editor, which will contain a query with the data of the file that we just incorporated.
Query Editor will be our main window of work throughout, and it is recommended that we familiarize ourselves with the elements.
You want Container panel of the queries used in the data transformation operations, which will later be used as a basis in the construction of the model from the Power BI designers. The term Query (query) serves the Query Editor to identify mainly tables, lists of values, or other types of objects that store data in a structured way. The work to be developed in this here will be focused mainly on the management of tables, so we will use both terms, query, and table to refer to the same type of object: a structure of data organized in rows and columns.
Data. This area shows the content of the query currently selected in the Queries panel.
Applied Steps Each of the operations we carry out on a query represents a step in the set of transformations performed, being registered with a name in this block of the Query Settings panel. This allows us to place ourselves in any of the steps to check the status of the query at that precise moment, modify it, delete it, etc., as if it were a macro recorder.
Formula Bar. Expression in M language corresponding to the currently selected step. If this element is not visible, we will activate it by checking the Form Bar box of the Layout group on the View tab.
Operations menu It is an impressive toolbox where we will find all kinds of debugging, cleaning, transformation, etc. We need to apply to the data. Let us also keep in mind that if we do not find the solution we are looking for, the possibility of entering our own code in M language is always available.
The file just imported generates a query called micro_2016, which contains a column named Column1, both automatically assigned in the import operation.
Although we can use these default names in the following transformation tasks, we will change them to others that are more meaningful for the rest of the operations to be performed, since Power Query assigns names to all the elements of the transformation procedures that your engine needs have identified. Therefore it is a good practice that in those on which we have to perform some special manipulation, such as its use in a formula, we assign custom descriptors.
In the case that currently concerns us, we will right-click both the name of the query and the column, selecting the Rename option and modifying their names respectively by PopulationCensus and Individual (by pressing F2, we will also achieve the same result). PopulationCensus will represent the future table of data of the model that we are going to develop.
At this point, we can update the work developed so far in the Query Editor window on the Power BI data model by clicking on the Close & Apply menu option, located in the Close group.
In our case, this operation may entail a significant process time penalty due to the high volume of data contained in PopulationCensus, since by default, all queries of the Query Editor are loaded into memory for later use in the data model of Power BI
As an alternative to be able to work with the data without actually loading it, we will right-click on the query and select the Properties option to open its properties window. Once located in it, we will uncheck the Enable load to report box and accept the changes; In this way, we maintain a reference to the data in its location of origin without incorporating them until it is necessary, thus reducing the process times. This by Reza Rad on performance issues in Power BI provides additional information about this particular.
After executing the Close & Apply option, the Query Editor window will close, and we will return to the main Power BI window, where we will click on the File | Save to save the work developed so far in a file that we will call PopulationCensus.pbix.
Preparation of the Data Table
The next task that we will deal with will be the division into columns of the identification data of each individual from the existing column in the PopulationCensus table, following the guidelines of the Design sheet of the source Excel file.
We will start with the Province's code of residence of the person, which corresponds to the first two digits of the Individual column.
First, we will click on the header of the Individual column. Next, in the Add Column menu tab, From the Text group, we will select the Extract option to obtain a substring of the column, choosing Range as the type of extraction.
As a result of this action, a dialog box will be opened wherein the Starting Index parameter we will enter 0. This parameter represents the index of the position from which the extraction of the substring will begin. On the other hand, in the Number of Characters parameter, we will enter 2 as the number of characters to obtain.
Accepting this dialogue will create a new column with the Province's code of residence of the individual, to which we will change the name to ProvinceResidantID.
The reason for using 0 to indicate the starting position of the extraction is because Power Query works with zero-based indexes, which means that the index number or position of the first element is 0, the index of the second is 1 and so on. The following figure shows schematically the operation that we just performed.
If, for example, we wanted to obtain, from the string in the previous figure, a substring of 7 characters starting at position 12, the values to be used would be 11 for the index of the extraction start, and 7 for the number of characters to recover. Then we show the execution scheme for this operation again.
The function of the M language that internally executes the Extract-Range menu option is Text.Range, whose use we will discuss in later examples. In the following block of code, we see the extraction of the previous substrings, but using this function just mentioned.
Text.Range ([Individual], 0.2)
Text.Range ([Individual], 12.7)
Taking into account the considerations that we have just explained, for those operations related to the manipulation of character strings, it will be necessary to subtract 1 from the positions of the string with which we need to work, to make them coincide with the index that Power Query internally uses in Text processing functions.
Value Column Based on a Condition
The municipality code of residence is the next column that we are going to add to the table, finding its value located in positions 3, 4, and 5 of the Individual column.
Additionally, we must bear in mind that for those municipalities with a population of fewer than 10,000 inhabitants, this value is bleached (empty chain) due to data protection issues. Since, as we will see later, the way to identify a municipality is based on the union of Province codes plus municipality, for cases where the latter is not available, we will use a code that does not previously exist as 999, more appropriate in this circumstance that an empty chain, since it will provide more consistency to the data in the phase of creation of the post-transformation model that we are currently carrying out with Power Query.
Reviewing in the Query Editor window the menu options of the Add Column tab, we will notice the existence of the Conditional Column option, through which we can create a column based on one or more conditions. However, among the available operators, none allows us to extract a substring by positions.
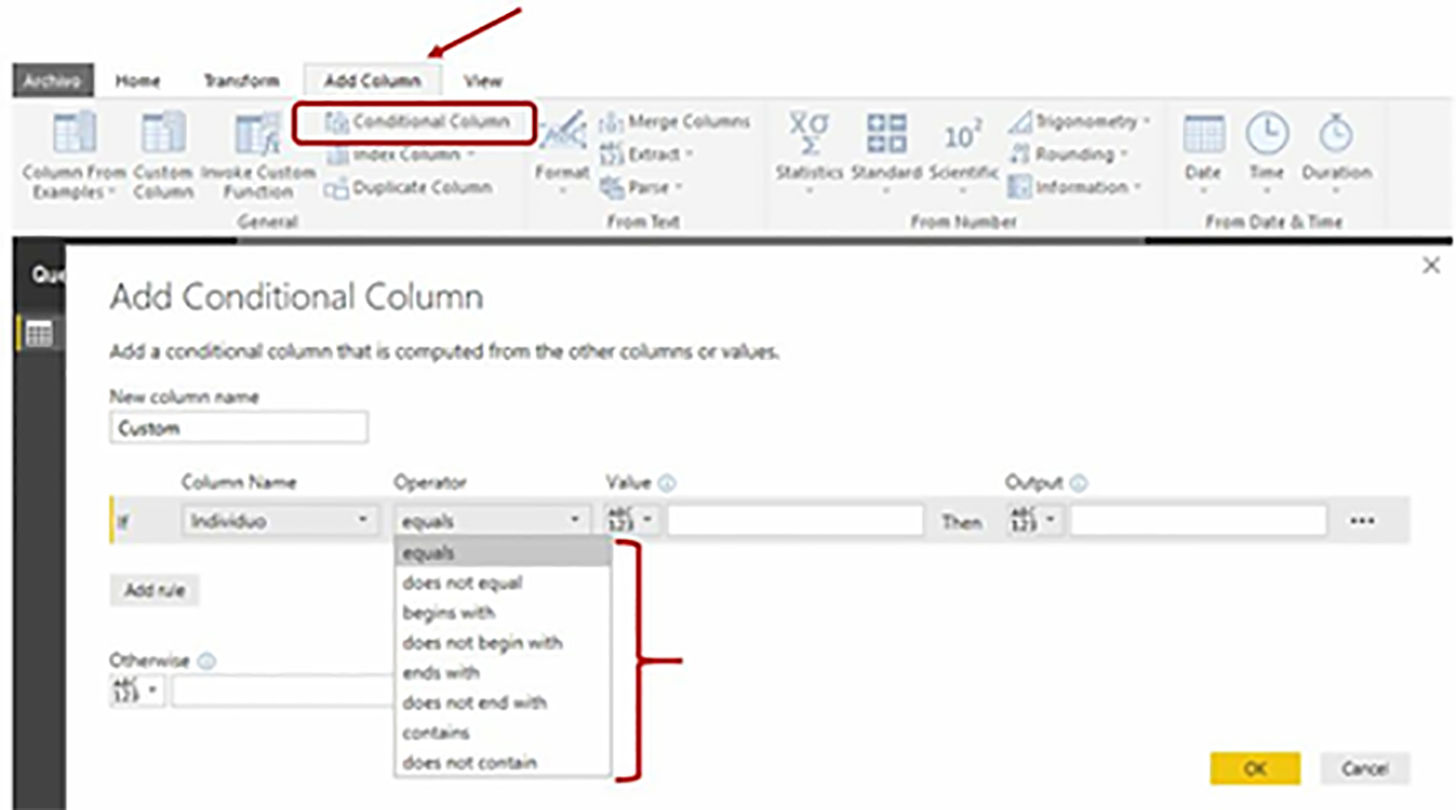
This leads us to look for the solution in the Custom Column option, also located in the Add Column menu tab, which, as the name implies, enables the creation of a custom column by entering an expression written in M language.
if Text.Length (Text.Trim (Text.Range ([Individual], 2,3))) = 0 then
"999"
else
Text.Range ([Individual], 2,3)
In the previous block of code, we use the decision structure if… then… else and functions belonging to the Text category to check if there is value in the 3-character substring that starts at index 2. Note that in a case like the current one, where we perform several functions in a nested way, the order of evaluation of the same begins with the one that is located in the innermost position continuing outwards, as explained below.
First, we extract the substring using the Text.Range function, then we eliminate the blank spaces that could be with the Text.Trim function, and check the resulting length with the Text.Length function; if this is 0 (empty string) it is one of the bleached municipalities, so we return the 999 string as a result (the double-quote character is used as a string delimiter); otherwise, it is a municipality with value, and we return the substring corresponding to its code through Text.Range.

For the remaining columns to be created, we will continue to use the Custom Column menu option, since in all cases, we will need to extract a substring from the Individual column.
Attention to Upper and Lower Case in M
Now that we have begun to write M code, we must be cautious when creating our expressions, due to the distinction between upper and lower case letters that this language makes between its elements, such as reserved words, function names, etc.
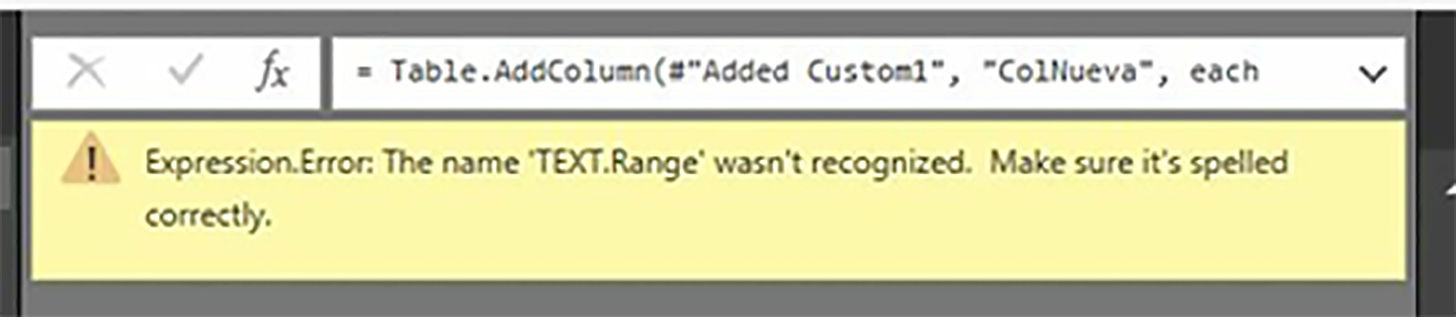
If for example, we try to create a new column with the following expression.
TEXT.Range ([Individual], 2, 3)
Having written the name of the TEXT function category in capital letters instead of Text, which would be the correct form, we would get the error we see in the following figure.
How do I find the most appropriate function for each moment? The answer is inside
M is a language composed of functions, which organized into categories (Table, Text, Number, List, etc.) offer a wide spectrum of possibilities for handling tables, lists, character strings, etc.
But in the face of such an offer, we need some type of documentation to find the one that best suits our requirements in each situation.
As resources on the Internet, we have the official Microsoft reference page, from which we can download a document with the language specifications. For the functions, there is also a page where they are grouped by category, and we can also find many sites dedicated not only to Power Query, but also to Power BI, Power Pivot and other Microsoft BI technologies, of which in the end some featured links are provided.
However, all of the above resources are based on our availability of an Internet connection, but what happens if, under certain circumstances, we cannot connect to the Network?
This situation should not worry us since from the Power Query itself, and we can access information about the functions of the M language through a small trick.
First, we will create a new query using the New Source | Blank Query, located in the Home menu, New Query group.

A new query with the default name Query1 will be created. In the formula bar, we will write the following expression.
= #shared
After pressing Enter, a result set consisting of records (Record objects) containing the language functions, as well as types, constant values, etc. will be generated. To be able to handle this list more comfortably, we will click on the Into Table menu option of the Convert group, belonging to the Record Tools | Convert, to convert it into a table type query.
Once the table is obtained, we can find information about the functions by applying a filter on the Name column. For example, if we want to see only the functions of the Text category, we will click on the filter/order button of that column, we will enter the Text value. (including the point to narrow the search better), and we will click, OK.
As a result, the table will show the names of the filtered functions. We can reopen this filter box and apply it for ascending order.
But if the aid remained only in a list of functions, this utility would be impractical. We are going to look for in this list one of the functions that we have previously used: Text.Range, and in the Value column, we will click but not on the Function value but in an empty space within that box. A panel will open at the bottom of the window with detailed information about the selected function: signature (parameters and return with their corresponding types), description of the operation performed, and examples of use.
If we click again, this time on the Function value, the information on the function will be expanded, covering the entire window and opening the user interaction dialog box so that we can evaluate its operation.

We can also use other filter variants, such as the search for functions that contain a specific substring within their name. First of all, we will remove the last steps created in the Applied Steps panel until we remain in Converted to Table. Deleting a step is very simple, just select it and press Delete or click on the delete icon next to its name.
Then we will open the filter box again, and in the Text Filters option, we will select Contains, entering the ToText value in the filter box. After accepting this dialog box, we will obtain it. As a result, all the functions whose name contains the introduced particle.

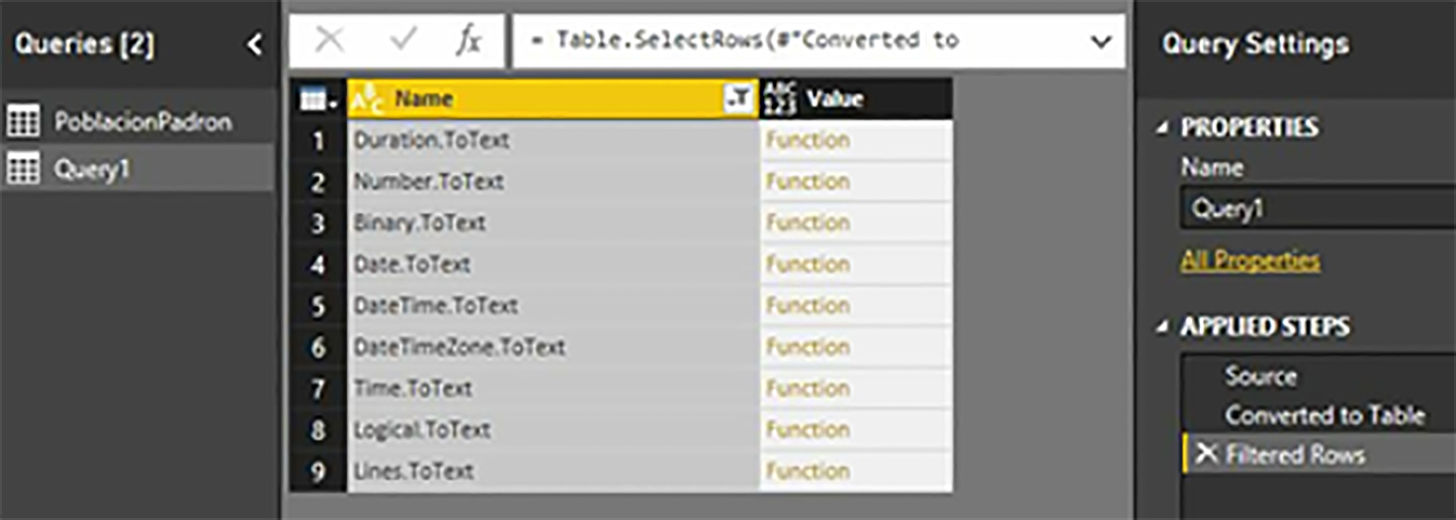
Once we finish consulting the documentation using these techniques, we can select the Query1 table in the Queries pane and delete it by pressing the Delete key.
Column to Identify the Sex of the Individual
The digit located in position 6 of the Individual column identifies the sex of the person, the value being 1 for men and 6 for women. We will transfer this value to the new column SexID, where in addition to the Text.Range function we will use Number to from text, to convert the result to a type of numerical data.
Number.FromText (Text.Range ([Individual], 5.1))
Data Types in Power Query. Choose Between Any or a Specific Type
When creating the SexID column in the previous section, despite having used the Number.FromText function to convert its content to a number, the data type of the generated column is Any (any or generic type) instead of Whole Number (number integer) as was our intention, which explicitly obliges us to change the data type of the column by clicking on its name, and then, in the Home menu, Transform group, Data Type option, select the Whole Number value.
Whenever we are faced with a situation of these characteristics, in which Power Query has assigned the default Any type to a column, but we know what is the appropriate type of data that it should have, the recommendation is that we change its type to which it really corresponds, so that operations with it can be carried out with greater precision and reliability.
To quickly know the type of data that a column has, we will look at the icon located on the left side of its title.
Another technique that we can also use to change the type of data is to click on the icon in the column header and choose the new type in the list that appears.
From here, in those operations that involve the creation of a column, we will specify next to its name the type of data that should have
Place of Birth. Province
The next column, which will have the name Province BirthBirth (Text), is obtained from positions 7 and 8 of the Individual column, and represents, as its name indicates, the Province of birth of the person. For the population born outside the country, value 66 will be used, and in the case of those born in former American territories, code 53 is used.
ProvinceBirthID
=====================
Text.Range ([Individual], 6.2
Place of Birth. City or Country
The municipality or country of birth is obtained from positions 9, 10, and 11, moving to the column CityPaisBirthID (Text). For people who were not born in the country, the value will correspond to the code of the country of birth. As was the case with the place of residence, in municipalities with fewer than 10,000 inhabitants, this value is bleached for data protection, so that for these cases, we will use code 999.
Municipality Country Birth ID
=====================
if Text.Length (Text.Trim (Text.Range ([Individual], 8.3))) = 0 then
"999"
else
Text.Range ([Individual], 8.3)
Nationality
The nationality code data, which we will transfer to a column with the name NationalityID (Text), is in positions 12, 13, and 14.
Nationality ID
=====================
Text.Range ([Individual], 11.3)
Age
The age of the individual will be transferred to a column called AgeID (Whole Number) obtained from positions 15, 16, and 17.
Age ID
=====================
Text.Range ([Individual], 14,3)
Municipality Size According to Inhabitants
And we finish with the creation of the columns that indicate the size of the municipality of residence and birth according to its number of inhabitants: TamMunicipleResidantID (Text) and TamMunicipalBirthID (Text). Both have a length of 2 digits and are respectively in positions 18 and 19 as well as in 20 and 21.
For reasons of statistical confidentiality, in municipalities with less than 10,000 inhabitants, if for a Province, there is only one municipality in a population section, it has been added to the next or previous section, maintaining the code of the latter.
As was the case with the Province of birth, for column TamMunicipalBirthID, in those people born abroad, code 66 is assigned, while those born in former American territories are coded with the value 53. The following code block shows the expressions to use to build these columns.
TamMunicipalityResidenceID
======================
Text.Range ([Individual], 17,2)
TamMunnoverBirthID
=======================
Text.Range ([Individual], 19,2)
Composition of the Place of Residence Identifier
CityResidantID is not a column that can be used autonomously to select the place of residence of the individual. The most palpable sample of this is in the fact that if we review the CMUN sheet of the source Excel file, code 004, for example, corresponds to municipalities in 5 different Provinces, so to refer uniquely to one locality, we need both codes: Province and municipality.
For this reason, we will create a new column called Resident Place (Text), in which we will concatenate the values of ProvinceResidantID and CityResidantID. This will allow us to later build a query with an identifier of the same characteristics, which we will use as a search table when implementing the data model in Power BI.
PlaceResidenceID
================
[ProvinceResidantID] & [MunicipalityResidantID]
Composition of the Birthplace Identifier
Suppose that in the phase of creating the data model, we want to design the information of the place of birth as a hierarchy formed by the country, Province, and municipality levels. One way to solve this problem would be the creation, in the current table, of a new column that acts as an identifier, which we will call Birth PlaceID (Text), formed by three different codes corresponding to the levels just mentioned. The way to compose this identifier will vary depending on whether the individual was born in the country or abroad, data that we will find out by consulting the column ProvinceBirthID.
If the value of ProvinceBirthID is 66, it is a foreigner, which means that the column MunicipalityPaisBirthID contains the code of the country of birth instead of a municipality. Of course, in this case, we lack the municipality code, so we assign the value 999 to indicate that it is an unknown or unavailable location.
[Municipality CountryBirthID] & [ProvinceBirthID] & "999"
If the value of ProvinceBirthID is not 66, we will begin to construct the identifier with the value 101, which corresponds to the country code of USA, for example, followed by ProvinceBirthID and CityPaisBirthID.
"108" & [ProvinceBirthID] & [MunicipalityPaisBirthID]
The entire expression to create the column is shown in the following block of code.
if [Birth ProvinceID] = "66" then
// if he was born abroad
[Municipality CountryBirthID] & [ProvinceBirthID] & "999"
else
// if he was born in the USA
"108" & [ProvinceBirthID] & [MunicipalityPaisBirthID]
After the creation of CityBirthID, we will eliminate those other columns used as support in the preparation of this table, which we will not need to use from now on for the development of the data model. The columns in question will be: Individual, ProvinceResidantID, CityResidantID, ProvinceBirthID and CityCountryBirthID.
Next, we will execute the Close & Apply menu option again in the Query Editor, and in the Power BI window, we will save the changes in the .pbix file.
At this point we conclude this chapter in which we have made an introduction to Power BI from an ETL tool perspective, making use of the data transformation operations belonging to the Power Query engine integrated in this tool, with the aim of put together the data table for a model that we will build with Power BI designers.
In the next chapter, we will continue with the development of this information system, addressing the creation, also with the Query Editor, of the search tables, which once related to the data table, allow users to perform their analysis tasks through the application of filters and the creation of metrics.

