Книга: Магия таблиц. 100+ приемов ускорения работы в Excel (и немного в Google Таблицах)
Назад: Функция LET
Дальше: Отладка формул и ошибки
Функция LAMBDA и вспомогательные функции
 Файл с примером: LAMBDA.xlsx
Файл с примером: LAMBDA.xlsxЕсли раньше в Excel нужно было создавать собственные пользовательские функции с помощью макросов (VBA), то теперь можно делать это функцией, не залезая в код, если в вашей версии появилась новая (можно сказать, революционная) функция LAMBDA. А появилась она в Microsoft 365 в 2020–2021 годах (в зависимости от пакета обновлений), ее нет в «коробочной» версии Excel 2021.
Функция LAMBDA появилась и в Google Таблицах в 2022 году.
Синтаксис у нее такой:
=LAMBDA([переменная]; …; [переменная]; формула)
Переменных может и не быть (хотя тогда LAMBDA не имеет особого смысла, можно просто присвоить имени Excel формулу без аргументов и вызывать ее по этому имени), может быть одна или несколько. В конце последним аргументом всегда будет формула с этими переменными.
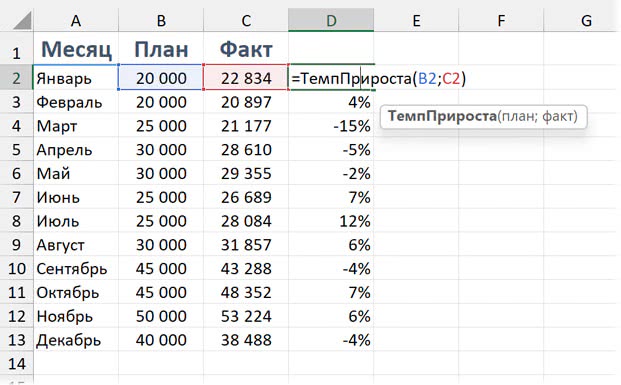
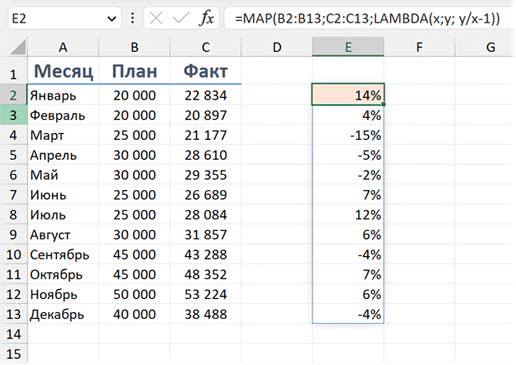
Рассмотрим на простом примере с отклонением «факт — план». Допустим, план в столбце B, факт в столбце C. Обычная формула будет выглядеть так:
=C2 / B2 — 1
А в случае с LAMBDA мы указываем переменные и формулу в общем случае:
=LAMBDA(план; факт; факт / план — 1)
После чего можно сохранить ее в диспетчере имен (Ctrl + F3) под любым именем, какое вы хотите присвоить этой функции, например “ТемпПрироста”. И дальше использовать эту функцию в пределах книги (а если хочется перенести ее в другую, можно создать пустой лист в книге и скопировать/переместить его в другую книгу — это приведет к переносу имен, а значит, и функции).
Вся мощь LAMBDA раскрывается с ее вспомогательными функциями, которые позволяют обрабатывать все значения в массиве или все строки/столбцы в массиве и применять к ним одно и то же вычисление. То есть теперь можно посчитать, например, среднее значение по каждой строке одной формулой. Или собирать данные с разных листов одной формулой, притом что этот список листов будет меняться. Давайте рассмотрим такие примеры применения LAMBDA со вспомогательными функциями.
ФУНКЦИЯ MAP: ОБРАБАТЫВАЕМ КАЖДЫЙ ЭЛЕМЕНТ МАССИВА
Файл с примером: LAMBDA.xlsxФункция MAP повторяет вычисление, описанное в функции LAMBDA, для каждого элемента в массиве. Соответственно, она возвращает массив того же размера, что и массив на входе:
=MAP(массив; LAMBDA(переменная для обозначения каждого элемента массива; вычисление))
Например, мы можем взять массив с суммами сделок (из таблицы) и умножить каждое значение на 10%. Первый аргумент функции MAP — массив с данными (здесь ссылка на столбец "Сумма" таблицы Сделки). Второй — функция LAMBDA, у которой первый аргумент — это переменная (произвольное имя, у нас — стоимость) для каждого элемента массива, а второй — вычисление с этой переменной (что мы делаем с каждым элементом из массива).
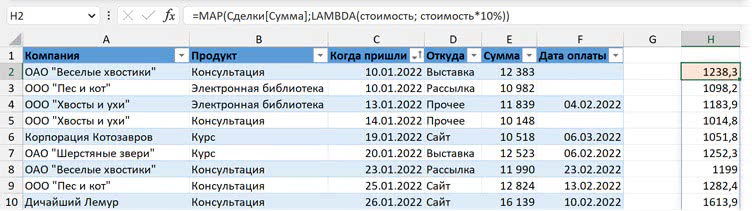
Конечно, такую задачу можно решить и обычной формулой, и формулой массива — это лишь пример, показывающий, что позволяет делать MAP.
Если массив двумерный, то и результат будет такого же размера. MAP применяет вычисление к каждому элементу массива.
Массивов может быть и несколько, тогда они перечисляются в MAP как отдельные аргументы, а последним аргументом всегда будет LAMBDA.
Пример применения MAP: собираем данные с разных листов (список листов динамический)
Файл с примером: Собираем данные с разных листов.xlsx

Google Таблица с примером: Собираем данные с разных листов
Наша задача — собирать данные с нескольких листов, причем список листов может меняться: листы могут меняться, могут удаляться из списка, могут добавляться новые.
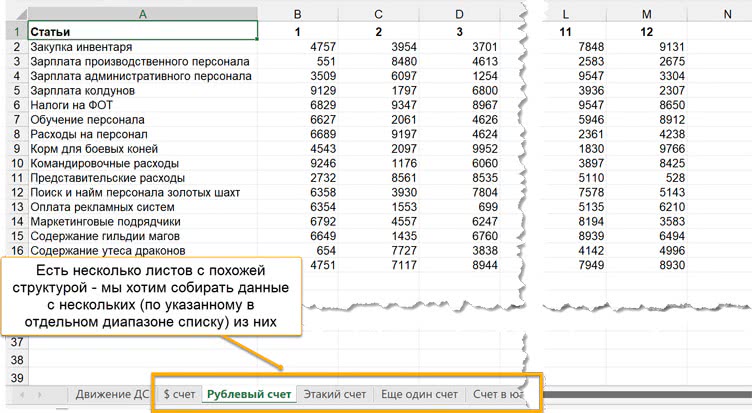
Пока на сводном листе, куда мы хотим собирать все данные (в примере он назван «Движение ДС»), — четыре счета, идущих не подряд в таблице. Могут добавиться новые, могут удалиться какие-то из этих.
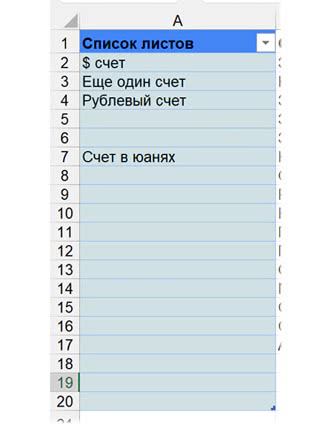
В Google Таблицах список листов можно сделать и открытым $A$2:$A, но это может сказаться на быстродействии.
В Excel разумно делать его таблицей и ссылаться на ее столбец в формуле.
Чтобы обработать несколько листов и с каждым проделывать какие-то манипуляции, будем забирать названия листов из массива с помощью функции MAP и передавать в LAMBDA, где будет нужное нам вычисление с каждым элементом из диапазона (первого аргумента MAP).
В общем виде для нашей задачи:
=MAP(список листов; LAMBDA(sh; вычисление))
где sh — просто имя переменной для имен листов, можно задать и другое.
А что будет за вычисление, какой алгоритм?
Во-первых, нам надо будет проверять каждое значение в списке: если там пусто, то никаких манипуляций производить не нужно, можно возвращать ноль. Это можно сделать с помощью функции ЕПУСТО / ISBLANK (она возвращает ИСТИНА, если ее аргумент пустой):
=MAP(список листов; LAMBDA(sh; ЕСЛИ(ЕПУСТО(sh); 0; вычисление))
Во-вторых, надо получить ссылку на лист и на нужный диапазон на каждом листе. Чтобы сделать действующую ссылку из текста (а у нас sh — текст, название листа), нужно использовать ДВССЫЛ / INDIRECT. Допустим, нам нужно будет использовать данные в столбцах A: N на каждом листе. Соберем ссылку следующим образом: апостроф (это вполне себе текст из одного символа, так что берем его в кавычки) & название листа (sh) & (апостроф & восклицательный знак & диапазон):
ДВССЫЛ("'" & sh & "'!A: N")
Наконец, надо с полученным диапазоном произвести манипуляции: подтянуть данные с помощью ВПР / VLOOKUP, или просуммировать, или сделать еще что-то. Или просто сослаться на нужные ячейки, если структура одинаковая везде и не будет меняться. В общем, функция может быть любая, в примере ВПР по названию статьи:
=MAP(список листов;
LAMBDA(sh;
ЕСЛИ(ЕПУСТО(sh); 0;
функция(ДВССЫЛ("'" & sh & "'!A: N")))
В нашем случае с VLOOKUP / ВПР в общем виде:
=MAP(список листов;
LAMBDA(sh;
ЕСЛИ(ЕПУСТО(sh);0;
ВПР(название статьи;ДВССЫЛ("'"&sh&"'!A: N");номер столбца;0))))
С конкретными ссылками:
=MAP($A$2:$A20;
LAMBDA(sh;
ЕСЛИ(ЕПУСТО(sh);0;
ВПР($B2;ДВССЫЛ("'"&sh&"'!A: N");СТОЛБЕЦ()-1;0))))
СТОЛБЕЦ()-1 — здесь мы просто берем номер столбца, в котором стоит формула, и уменьшаем на единицу, чтобы получить номера столбцов на листе с данными (у нас там на один столбец меньше; так как другая структура данных — нет списка листов в первом столбце; понятно, что у вас структура может быть какая-то еще).
Остается просуммировать (СУММ / SUM; если, конечно, вам нужна сумма, а не среднее или что-то еще) все полученные значения, которые ВПР / VLOOKUP нам принесет со всех листов:
=СУММ(MAP($A$2:$A20;
LAMBDA(sh;
ЕСЛИ(ЕПУСТО(sh);0;
ВПР($B2;ДВССЫЛ("'"&sh&"'!A: N");СТОЛБЕЦ()-1;0)))))
ФУНКЦИЯ BYROW: ОБРАБАТЫВАЕМ КАЖДУЮ СТРОКУ МАССИВА
Файл с примером: BYROW.xlsxФункция BYROW позволяет последовательно обращаться к каждой строке в массиве.
Ее синтаксис:
=BYROW(диапазон; LAMBDA (переменная для обращения к каждой строке); вычисление с этой переменной))
То есть мы можем производить вычисления не с отдельной ячейкой и не со всем массивом, а с каждой строкой последовательно (на выходе мы получим массив значений в один столбец и с таким же числом строк, сколько в исходном диапазоне, — это будет результат вычисления с каждой строкой). Де-факто получается цикл — мы обрабатываем каждую строку последовательно.
Аналогично работает функция BYCOL — там, соответственно, будет обрабатываться каждый столбец массива.
Давайте посмотрим на пример. У нас диапазон C2:N13, в котором есть продажи за 12 месяцев. Посчитаем средние продажи в каждой строке одной формулой:
=BYROW(C2:N13;LAMBDA(строка;СРЗНАЧ(строка)))
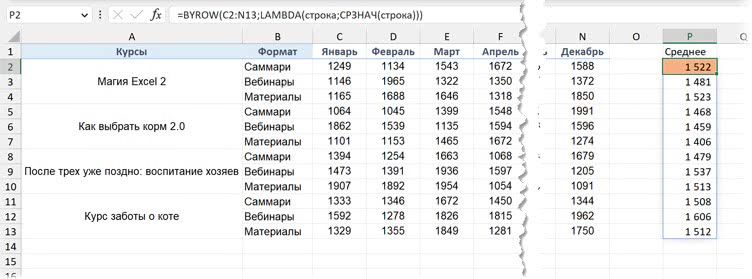
Конечно, мы могли бы просто протянуть функцию =СРЗНАЧ(C2:N2) на несколько строк. Но этот пример показывает нам, как работает BYROW
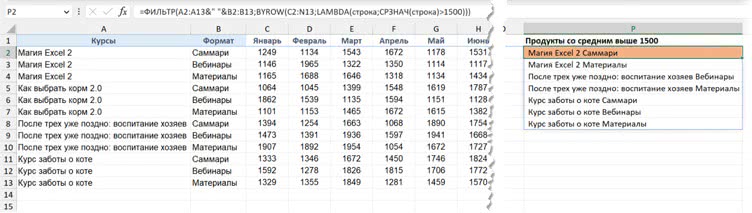
Теперь давайте решим другую задачу: нам нужно выводить те продукты (сочетание: какой курс и какой формат — вебинары или саммари), у которых средняя выручка за год — выше 1500. Например, Магия Excel 2 + саммари — нужно выводить (среднее — 1522), а Как выбрать корм 2.0 + вебинары — нет (среднее — 1459).
Чтобы получать комбинацию «Курс — Формат», объединим два столбца амперсандом и добавим между ними разделитель, например пробел: A2:A13&" "&B2:B13
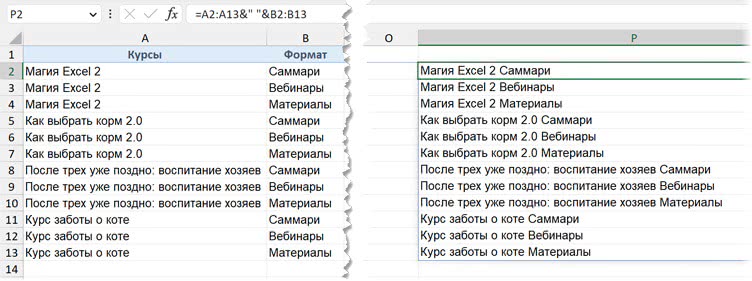
А чтобы вывести из этого виртуального (виртуального, потому что мы не будем, конечно, выводить его в ячейки отдельно в итоговой формуле, как выше, — это сделано лишь для того, чтобы мы посмотрели, как выглядит промежуточный результат) списка только те значения, которые соответствуют нашему условию (среднее выше 1500), применим функцию ФИЛЬТР. В общем виде так:
=ФИЛЬТР(A2:A13&" "&B2:B13; Среднее > 1500)
Ну а на деле, чтобы получить среднее по каждой строке, используем BYROW, как делали это выше:
=ФИЛЬТР(A2:A13&" " &B2:B13;
BYROW(C2:N13;LAMBDA(строка;СРЗНАЧ(строка)>1500)))
ФУНКЦИЯ REDUCE: ПОСЛЕДОВАТЕЛЬНО ОБРАБАТЫВАЕМ МАССИВ И ПОЛУЧАЕМ ОДНО ЗНАЧЕНИЕ В КАЧЕСТВЕ РЕЗУЛЬТАТА
Файл с примером: REDUCE.xlsxФункция REDUCE применяет вычисление к каждому значению в массиве, как и MAP. Но на выходе возвращает только одно значение — «накопленный» результат, а не массив того же размера:
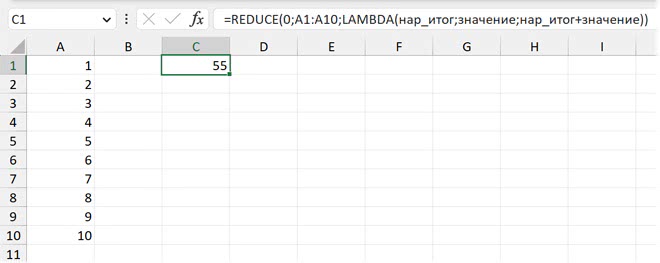
=REDUCE(начальное значение; массив; вычисление)
Вычисление — это функция LAMBDA, в которой первый аргумент — это нарастающий итог, накопленный результат, второй — это отдельное значение (на первом шаге — начальное значение, заданное в первом аргументе REDUCE, а далее — каждое очередное значение из массива), третий — вычисление:
=REDUCE(начальное значение; массив; LAMBDA(нарастающий итог; значение; вычисление))
В следующем примере мы обрабатываем десять ячеек с числами от 1 до 10 и на каждом шаге просто прибавляем к предыдущему шагу очередное значение. На выходе мы получаем одно значение (в отличие от SCAN, о которой ниже).
Пример применения REDUCE. Извлекаем из текстовой строки только цифры
Конечно, предыдущий пример не для практики, мы лишь рассмотрели синтаксис функции REDUCE, а на деле для решения задачи можно было просто использовать обычное суммирование.
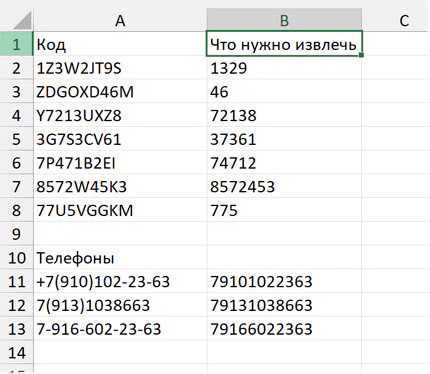
Но вот пример задачи, где может пригодиться «пробегание» по каждому элементу массива и вычисление с промежуточным итогом. Допустим, мы хотим извлечь из текстовой строки какие-то символы и соединить их в другую текстовую строку, например: только цифры из кода, состоящего из букв и цифр, или из номера телефона, где, помимо цифр, встречаются другие символы (скобки, дефисы, плюс и т. п.)
Нам нужно:
1. Сделать массив из отдельных символов текста
Чтобы извлечь один любой символ, нужна функция ПСТР / MID. Напомним ее аргументы:
=ПСТР (текст; позиция извлекаемого символа; число символов)
Нам необходимо последовательно извлекать все символы по одному (третий аргумент ПСТР) от первого до последнего. Чтобы получить последовательность чисел от единицы до последнего символа в тексте, нужна функция ПОСЛЕД / SEQUENCE и нужно знать, сколько в каждом тексте символов (длину текстовой строки можно определить с помощью ДЛСТР / LEN):
=ПСТР (текст; ПОСЛЕД(1;ДЛСТР(текст)))

Формула, формирующая массив из отдельных символов текста
2. Далее необходимо пройтись по каждому символу и проверить, является ли он цифрой (числом)
Будем превращать его из текста (мы обсуждали эту тему — см. ) в число с помощью ЗНАЧЕН / VALUE и проверять, будет ли полученное значение настоящим числом, с помощью ЕЧИСЛО / ISNUMBER.
ЕЧИСЛО(ЗНАЧЕН(символ))

Проверяем, является ли каждый символ (из массива с предыдущего скриншота) числом (де-факто цифрой) или нет.
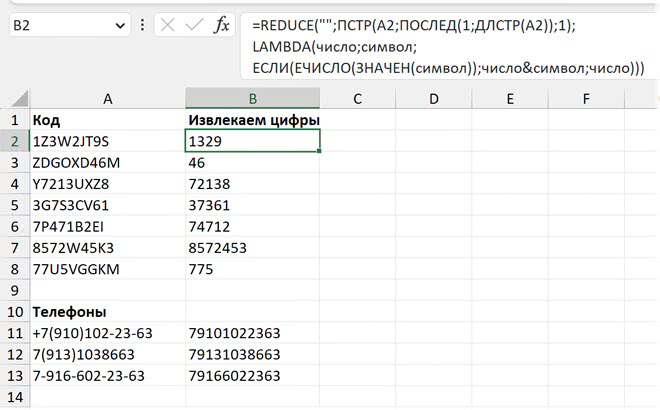
3. Далее нужно будет собирать текст из всех найденных цифр: начинаем мы с «нулевого» текста (пустые кавычки) как первого значения в REDUCE, берем массив из всех символов нашего текста (это ПСТР (ПОСЛЕД)), проверяем каждый и те, что являются числами, приклеиваем к уже собранным предыдущим. Получится такая формула в общем виде:
=REDUCE("";массив из символов;
LAMBDA(число; символ;
ЕСЛИ(ЕЧИСЛО(ЗНАЧЕН(символ)); число&символ; число)))
И со всеми функциями и ссылками:
=REDUCE("";ПСТР(A2;ПОСЛЕД(1;ДЛСТР(A2));1);
LAMBDA(число; символ;
ЕСЛИ(ЕЧИСЛО(ЗНАЧЕН(символ)); число&символ; число)))
Итак, наша формула «пробегается» по массиву из отдельных символов, проверяет каждый функцией ЕЧИСЛО, и если эта функция возвращает ИСТИНА, то мы склеиваем собранную на предыдущих шагах последовательность цифр с этим символом (операция объединения во втором аргументе функции ЕСЛИ). Иначе пропускаем его (оставляем собранную последовательность как есть — последний аргумент функции ЕСЛИ).
ФУНКЦИЯ SCAN: ПОЛУЧАЕМ ПРОМЕЖУТОЧНЫЕ ИТОГИ ДЛЯ КАЖДОГО ЗНАЧЕНИЯ ИЗ МАССИВА
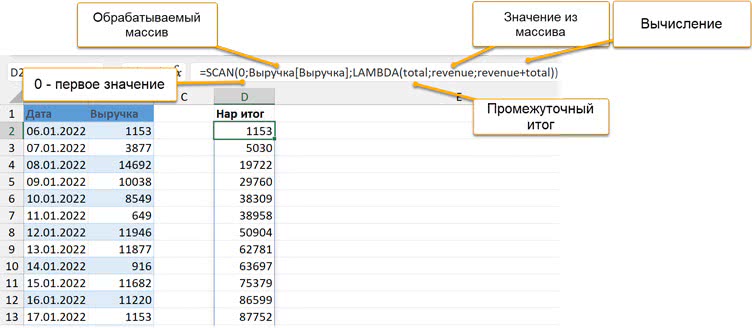
Файл с примером: Нарастающий итог SCAN.xlsxФункция SCAN работает как REDUCE, но возвращает массив, показывая все промежуточные значения, а не только итоговое.
REDUCE и SCAN могут принимать только один массив, а MAP — и несколько тоже.
Синтаксис функции похожий:
=SCAN(начальное значение; массив; вычисление)
В следующем примере мы вычисляем нарастающий итог: первое значение — ноль, обрабатываем мы столбец с выручкой из одноименной таблицы и на каждом шаге прибавляем (вычисление задано в третьем аргументе LAMBDA) к накопленному итогу (это первый аргумент LAMBDA, у нас — total) очередное значение из массива (второй аргумент LAMBDA, у нас — revenue):
=SCAN(0; Выручка[Выручка]; LAMBDA(total; revenue; revenue + total))
Что, если мы хотим нарастающий итог по условию? Например, суммировать только те дни, в которые у нас работал Лемур.
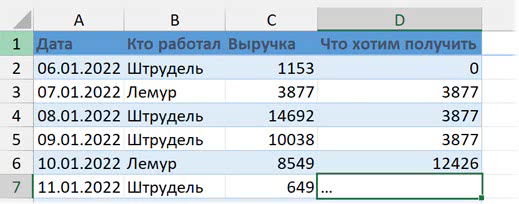
Здесь нужна функция ЕСЛИ / IF, ведь мы будем проверять условие и либо прибавлять число, если в столбце B — «Лемур», либо оставлять накопленный итог без изменений.
В общем виде:
ЕСЛИ(Кто работал = "Лемур"; промежуточный итог + выручка; промежуточный итог)
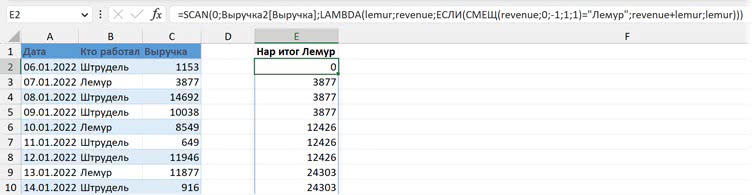
Так как у нас в качестве обрабатываемого массива выступает столбец «Выручка», мы не можем напрямую в LAMBDA ссылаться на столбец «Кто работал»: его в SCAN нет. Но мы можем ссылаться на другие ячейки относительно ячеек обрабатываемого массива — тут пригодится функция СМЕЩ / OFFSET. Чтобы ссылаться на ячейку слева от заданной (в нашем случае это очередная ячейка массива), нам нужна такая конструкция (смещение на один столбец влево, «минус один» в аргументе СМЕЩ):
СМЕЩ(ячейка из массива;0;-1;1;1)
Вся формула будет выглядеть так. Здесь 0 — начальное значение; Выручка2[Выручка] — ссылка на столбец с данными; lemur — накопленный итог; revenue — очередное значение из массива (выручка за конкретную дату); СМЕЩ(…) — ссылка на ячейку слева от ячейки с выручкой:
=SCAN(0;Выручка2[Выручка];
LAMBDA(lemur;revenue;
ЕСЛИ(СМЕЩ(revenue;0;-1;1;1)="Лемур";revenue + lemur;lemur)))
Назад: Функция LET
Дальше: Отладка формул и ошибки

