Книга: Ценность ваших данных
Назад: Глава 13. Управление основными данными: практика внедрения
Дальше: Глава 15. Базовая поддержка жизненного цикла данных
Глава 14. Обеспечение доступности и обслуживание данных: развитие
В главе 12 мы начали обсуждение группы областей знаний по управлению данными (или функций управления данными), которые отвечают за укрупненную фазу их жизненного цикла, связанную с обеспечением доступности и обслуживания (рис. 9.4). Мы уже рассмотрели первые три функции, закладывающие основу способностей организации по управлению данными на этой фазе. В этой главе мы обсудим оставшиеся функции, которые можно рассматривать как обеспечивающие дальнейшее развитие этих способностей:
● ведение хранилищ данных;
● управление документами и контентом;
● хранение больших данных.
В отношении функций «Ведение хранилищ данных» и «Хранение больших данных» нужно заметить следующее.
DMBOK2 рассматривает ведение хранилищ данных в рамках более широкой области знаний «Ведение хранилищ данных и бизнес-аналитика». Поэтому далее, чтобы не было разночтений со сводом знаний по управлению данными, мы будем придерживаться такого же подхода. В этой главе мы начнем обсуждать область «Ведение хранилищ данных и бизнес-аналитика», уделяя основное внимание вопросам ведения хранилищ данных. Далее, в главе 17, посвященной использованию данных, обсуждение будет продолжено в части бизнес-аналитики.
Аналогичным образом мы будем рассматривать и функцию «Хранение больших данных», которая в DMBOK2 разбирается в рамках общей темы «Большие данные и наука о данных». В этой главе мы начнем обсуждение данной темы, уделяя основное внимание вопросам хранения больших данных, а в главе 17 более подробно поговорим о науке о данных.
14.1. Ведение хранилищ данных и бизнес-аналитика
Понятие хранилище данных (Data Warehouse, DW) появилось в 1980-х годах для обозначения технологии, позволяющей организациям интегрировать данные из множества разнородных источников в рамках единой модели. С тех пор, особенно в связи с одновременным развитием бизнес-аналитики (Business Intelligence, BI) как основного драйвера принятия бизнес-решений, корпоративные хранилища данных успели стать обыденной вещью.
В главе 7, сопоставляя элементы референтной модели управления цепями поставок (SCOR-модель) с цепочкой поставок данных, мы отметили, что ведение хранилищ данных можно включить в группу процессов доставки, в частности складирования. При этом бизнес-аналитика больше соотносится с группой процессов «Делать», которая обеспечивает превращение материалов (данных) в различного рода информационные продукты.
14.1.1. Определение области знаний «Ведение хранилищ данных и бизнес-аналитика»
Хранилище данных (DW) включает два ключевых компонента – интегрированную базу данных, необходимых для принятия решений, и увязанное с ней программное обеспечение, используемое для сбора, очистки, преобразования и хранения данных из разнообразных внутренних и внешних источников. Кроме того, для поддержки функций ведения учета исторических данных, операционного и бизнес-анализа хранилище данных может включать вторичные витрины данных, т. е. выборочные копии данных из основного хранилища. В самом широком контексте под хранилищем данных может пониматься весь комплекс хранилищ, баз и витрин данных, используемых в организации в целях бизнес-аналитики.
Корпоративным хранилищем данных (Enterprise Data Warehouse, EDW) называют централизованное DW, предназначенное для информационного обеспечения BI-потребностей всей организации. EDW поддерживает корпоративную модель данных, что обеспечивает согласованность данных, используемых для принятия решений в масштабах организации.
Ведение хранилища данных включает осуществление текущих операций по извлечению, очистке, преобразованию, контролю и загрузке, обеспечивающих поддержку данных в хранилище в надлежащем состоянии. В процессе ведения DW первоочередное внимание уделяется обеспечению целостности и преемственности данных в историческом и бизнес-контекстах за счет применения к операционным данным адекватных бизнес-правил и реляционных связей. Кроме того, к сфере ведения DW относится также и поддержка процессов взаимодействия и согласования DW с репозиториями метаданных.
Понятие бизнес-аналитики (BI) имеет два смысловых значения. Во-первых, это вид анализа данных, который нацелен на изучение деятельности организации и выявление возможностей для развития бизнеса. Результаты такого анализа используются для совершенствования работы организации и достижения успехов в бизнесе. Во-вторых, под бизнес-аналитикой понимается еще и комплекс технологий, используемых для такого анализа данных. Являясь логическим развитием инструментов поддержки принятия решений, инструменты бизнес-аналитики предоставляют возможности по формированию и обработке запросов (querying), извлечению информации (data mining), проведению статистического анализа (statistical analysis), формированию отчетности (reporting), сценарному моделированию (scenario modeling), визуализации данных (data visualization), а также созданию и применению информационных панелей (dashboarding). Средства бизнес-аналитики сегодня находят применение во всех областях – от бюджетного планирования до расширенной аналитики (advanced analytics).
В традиционном понимании ведение DW относится только к структурированным данным (в этом разделе основное внимание будет уделено вопросам построения и ведения DW именно в части таких данных). Однако с появлением новейших прогрессивных технологий к области BI и DW стали относить и управление полуструктурированными и неструктурированными данными (специфика BI/DW для этих данных рассматривается в разделе 14.3).
14.1.2. Цели и бизнес-драйверы
Внедряя у себя хранилища данных, организации преследуют следующие основные цели:
● поддержка деятельности в области BI;
● повышение эффективности бизнес-анализа и принятия решений;
● изыскание инновационных возможностей по результатам углубленного анализа данных.
Наиболее действенные драйверы развития хранилищ данных – необходимость сопровождения операционных функций, выполнения требований нормативно-правового соответствия и обеспечения деятельности в области бизнес-аналитики.
Однако главный драйвер – поддержка BI. Бизнес-аналитика нужна для полного понимания устройства и работы организации, ее клиентов и продуктов. Организация, деятельность которой основана на знаниях, полученных посредством грамотного бизнес-анализа, способна к неуклонному повышению эффективности и получению конкурентных преимуществ. По мере нарастания темпов поступления возрастающих объемов данных BI все более переходит от ретроспективной оценки к предиктивной аналитике.
Кроме того, в процессе операционной деятельности современной организации все чаще требуется наличие доказательных подтверждений соблюдения нормативно-правовых требований, подкрепленных историческими данными. Следовательно, системы управления хранилищами должны уметь обрабатывать и подобные запросы.
14.1.3. Подходы к организации хранилища данных
Хранилища данных – это сравнительно новое технологическое решение, которое стало широко использоваться только в начале 1990-х годов, после того как Билл Инмон, опубликовал в 1991 году свою первую книгу по этой теме – «Построение хранилища данных». Хотя отдельные элементы этой концепции и их технические воплощения существовали и ранее начиная с 1970-х годов, только к концу 80-х была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления ею, а также появились технические возможности для создания соответствующих систем, первоначально названных хранилищами информации (information warehouse), а после выхода книги Инмона получивших свое нынешнее наименование хранилищ данных.
На сегодняшний день существует два основных подхода к архитектуре хранилищ данных. Это так называемая корпоративная информационная фабрика (Corporate Information Factory, CIF) Билла Инмона и многомерное хранилище данных Ральфа Кимбалла.
Подход Инмона отражает метод проектирования «сверху вниз» и рассматривает хранилище как централизованное место хранения всех данных организации. После реализации централизованной модели данных для этого хранилища организации могут создавать на ее основе витрины данных (Data Marts, DM) – специальные хранилища для отдельных бизнес-направлений.
Подход Кимбалла основан на методе проектирования «снизу вверх». При этом подходе основным способом хранения данных являются витрины данных. Хранилище данных в целом представляет собой набор витрин, которые позволяют выполнять унифицированные аналитические задания, отчеты и другие необходимые процессы бизнес-аналитики.
Рассмотрим эти подходы подробнее.
14.1.4. Корпоративная информационная фабрика (архитектура Инмона)
DW, согласно определению Инмона, представляет собой предметно-ориентированный, интегрированный, поддерживающий привязку ко времени, неизменяющийся набор сводных и детализированных исторических данных. Исходя из этого определения, можно выделить основные концептуальные компоненты, которые формируют отличия хранилища данных от операционных систем (систем поддержки операционной деятельности организации),.
● Предметная ориентированность: данные в хранилище организованы по признаку соотнесения их с крупными сущностными объектами бизнеса, а не функциями или приложениями.
● Интегрированность: данные в хранилище унифицированы и связаны. Используются единообразные для всех компонентов хранилища структуры ключей, кодов шифрования, определений данных и условных наименований. Поскольку данные в хранилище интегрированы, они не являются простой копией операционных данных. Вместо этого DW, по сути, система записи (system of record) данных:
● Неизменяемость: записи в DW обычно не обновляются, и этим хранилища принципиально отличаются от оперативных систем. Вместо обновления записи с новыми данными добавляются к уже имеющимися. А вот набор записей может отражать хронологию изменений состояния данных в процессе обработки одной и той же транзакции.
● Привязка ко времени: данные в записях DW сохраняются «как они есть» по состоянию на каждый заданный момент регистрации. По сути, записи в DW являются «моментальными снимками» состояния данных об описываемых объектах. Каждый снимок имеет метку времени. Как следствие, сколько бы вы ни запрашивали данные за один и тот же период времени, результаты выдачи будут неизменными вне зависимости от даты и времени обработки запроса.
● Агрегированные и детализированные данные: в DW сохраняются как записи о транзакциях на уровне мельчайших деталей, так и обобщенные данные. В операционных системах сводные данные обычно не учитываются. На заре создания DW необходимость обобщения данных диктовалась соображениями экономии вычислительных ресурсов и пространства памяти. В современных средах DW сводные данные могут иметься как на постоянном хранении (в табличной форме), так и формироваться по запросу (в режиме представления). Обычно решающим фактором при принятии решения о необходимости сохранения агрегированных таблиц является требуемая оперативность доступа к сводным данным.
● Исторические данные: операционные системы обрабатывают текущие данные, а в DW содержатся записи об истории операций, причем нередко в огромных объемах.
Хранилище на основе архитектуры Инмона построено в соответствии с реляционной моделью данных. Основные особенности реляционной модели были рассмотрены в главе 11 (см. раздел 11.2). Там мы, говоря о связях между сущностями и об атрибутах сущностей, выделили такие понятия, как первичный и внешний ключ. Прежде чем продолжить обсуждение особенностей корпоративной информационной фабрики, остановимся на понятии нормализации.
* Intersoft Lab. Основные подходы к архитектуре Хранилищ данных. Intersoft Lab: Журнал ВРМ World. 2005. – URL: .
Нормализация (normalization) заключается в применении к модели данных наборов правил, позволяющих упорядочить необходимые для поддержки деятельности организации сведения в стабильные структуры. Главная цель нормализации – сделать так, чтобы каждый атрибут содержался строго в одном месте во избежание избыточности и возможной противоречивости данных.
Правила нормализации разделяют и организуют атрибуты в соответствии с первичными и внешними ключами. Правила последовательно распределяются по уровням, и на каждом следующем уровне повышается степень детализации и добавляются новые требования по учету специфики сущностей при подборе корректных первичных и внешних ключей. Каждому уровню соответствует отдельная так называемая нормальная форма (normal form, NF). Всего выделяют пять нормальных форм (они обозначаются номерами в соответствии с уровнем), но на практике, как правило, достаточно третьей (3NF). Под нормализованной моделью обычно понимают данные, приведенные в форму 3NF.
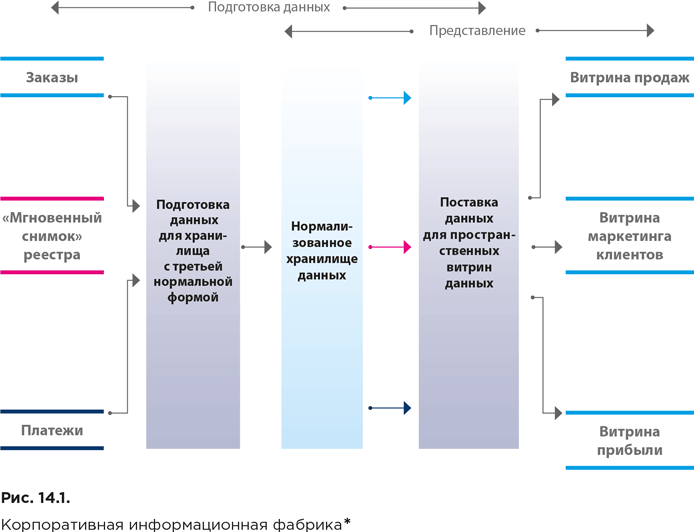
На рисунке 14.1 представлена укрупненная архитектура корпоративной информационной фабрики.
Подготовка данных начинается со скоординированного извлечения их из источников. После этого осуществляется загрузка реляционной базы данных, которая в итоге содержит детализированные (атомарные) данные в третьей нормальной форме. Наполненное нормализованное хранилище используется для того, чтобы снабжать информацией дополнительные репозитории презентационных данных (данных, подготовленных для анализа). Эти репозитории, в частности, включают специализированные хранилища для изучения и извлечения информации (data mining), а также витрины данных.
С целью представления создаются отдельные витрины агрегированных данных, предназначенные для обслуживания бизнес-подразделений или для реализации бизнес-функций. Для структурирования данных в них используется многомерная модель (о ней мы поговорим в следующем разделе). Детализированные данные при этом остаются доступными, что обеспечивается с помощью нормализованного хранилища. Таким образом, структура детализированных и агрегированных данных при такой архитектуре существенно различается.
Подводя итог вышесказанному, можно выделить следующие отличительные характеристики архитектурного подхода Инмона.
● Использование реляционной модели организации детализированных данных и многомерной – для организации агрегированных данных.
● Использование итеративного подхода при создании больших хранилищ данных, построение хранилища не сразу, а по частям. Это позволяет при необходимости вносить изменения в небольшие блоки данных или программных кодов и избавляет от необходимости реструктурировать значительные объемы данных или осуществлять сложное перепрограммирование. То же можно сказать и о потенциальных ошибках: они также будут локализованы в пределах сравнительно небольшого массива данных без риска испортить все хранилище.
● Использование третьей нормальной формы для организации детализированных данных обеспечит высокую степень детализации интегрированных данных и предоставит организации широкие возможности для манипулирования, изменения формата и способа представления данных по мере необходимости.
● Хранилище данных – это проект корпоративного масштаба, охватывающий все подразделения и обслуживающий нужды всех пользователей корпорации.
● Хранилище данных – это не механическая коллекция витрин данных, а физически целостный объект.
14.1.5. Многомерное хранилище данных (архитектура Кимбалла)
Архитектурный подход к представлению хранилища данных Кимбалла основан на многомерной структурной модели данных. Кимбалл определяет хранилище как копию транзакционных данных, особым образом структурированную для обработки запросов и анализа. «Копия» в данном контексте не означает точной копии оригинала. При переносе в хранилище данные подвергаются реструктуризации для обеспечения соответствия схеме многомерной модели, которая специально проектируется таким образом, чтобы сделать данные предельно понятными и полезными для потребителей, но при этом сохранить и достаточный для обработки запросов уровень формализации. Важнейшее отличие многомерных схем хранения данных от традиционных реляционных – отказ от нормализации,.
Многомерные модели, часто называемые также звездообразными схемами (star schema), представляют собой подборки фактов (facts), под которыми понимаются числовые данные или характеристики бизнес-процессов (например, объем продаж) в проекции на измерения (dimensions), которые используются для описания атрибутов, соответствующих фактам и позволяющих пользователям правильно интерпретировать фактические данные (например, с объемом продаж сопоставляются артикул продукта X и отчетный квартал). Таблица фактов связана со множественными таблицами измерений, и в графическом представлении такая схема организации данных имеет форму звезды, откуда и возникло название. При наличии в модели множественных таблиц фактов они проецируются на общие для различных таблиц так называемые конформные (conformed) измерения через шину (bus), подобную компьютерной шине. Множественные витрины данных на корпоративном уровне могут интегрироваться посредством подключения их к общей шине конформных измерений.
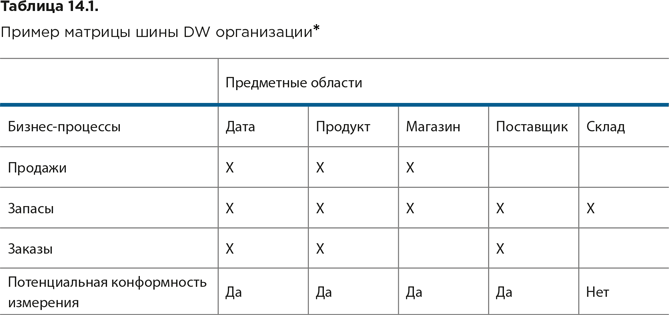
Матрица шины DW отражает доступные фактические данные на пересечениях строк бизнес-процессов (фактов) и столбцов предметных областей (измерений). Возможности для интеграции через конформные измерения появляются там, где множественные процессы используют одни и те же данные.
В таблице 14.1 приведен простейший пример матрицы шины DW.
К бизнес-процессам отнесены продажи, запасы и заказы. Данные обо всех трех бизнес-процессах могут интегрироваться через общие для них конформные измерения Дата и Продукт.
Данные о продажах и запасах могут интегрироваться через измерение Магазин, а данные о запасах и заказах – через измерение Поставщик. Таким образом, лишь четыре измерения из пяти – Дата, Продукт, Магазин и Поставщик – являются кандидатами на роль конформных. А вот измерение Склад общим для каких-либо бизнес-процессов не является и для интеграции данных непригодно, поскольку ему соответствует единственный бизнес-процесс – учет запасов.
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
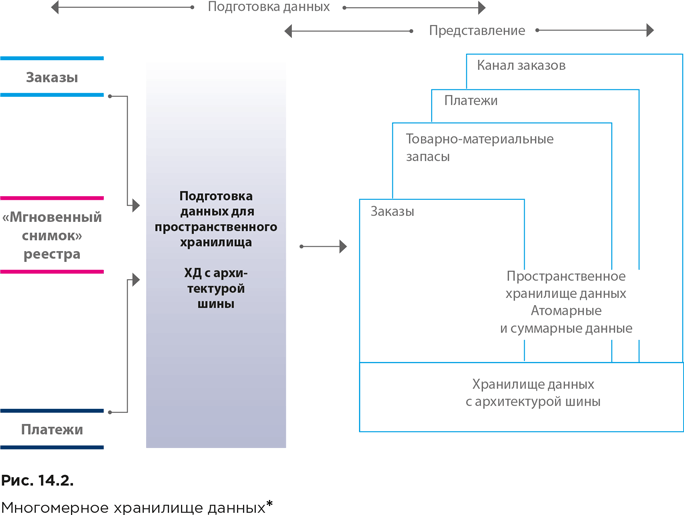
На рисунке 14.2 представлена укрупненная архитектура многомерного хранилища данных.
* Intersoft Lab. Основные подходы к архитектуре Хранилищ данных. Intersoft Lab: Журнал ВРМ World. 2005. – URL: .
Как и при архитектурном подходе Инмона, подготовка данных начинается со скоординированного извлечения их из источников. При этом уже на этапе подготовки первичные данные преобразуются в вид, пригодный для использования (с учетом требований к скорости обработки информации и качеству данных). Ряд операций совершается централизованно, например поддержание и хранение общих справочных данных, а другие операции могут выполняться распределенно.
В хранилище (области представления) содержатся такие же детализированные данные, как и в нормализованном хранилище Инмона, однако они структурированы в соответствии с многомерной моделью (что облегчает использование данных и выполнение запросов). При этом хранилище может быть централизованным или распределенным.
Хранилище содержит как детализированные, так и агрегированные данные, сформированные в соответствии требованиями в части производительности или пространственного распределения.
Запросы в процессе выполнения могут оперировать на различных уровнях детализации без дополнительного перепрограммирования со стороны пользователей или разработчиков приложений.
В отличие от архитектуры CIF, многомерные модели строятся для обслуживания бизнес-процессов (которые в свою очередь связаны с бизнес-показателями или бизнес-событиями), а не бизнес-подразделений. Например, данные о заказах, которые должны быть доступны для общекорпоративного использования, вносятся в многомерное хранилище только один раз (при подходе Инмона их пришлось бы трижды копировать в витрины данных отделов маркетинга, продаж и финансов). После формирования в хранилище сведений об основных бизнес-процессах консолидированные модели могут обеспечивать выдачу их кросс-процессных характеристик. С развитием матрицы корпоративного хранилища данных с архитектурой шины происходит расширение связей между показателями бизнес-процессов (фактами) и описательными атрибутами (измерениями).
На основе вышесказанного можно выделить следующие отличительные характеристики архитектурного подхода Кимбалла:
● использование многомерной модели данных;
● хранилище включает как детализированные данные о транзакциях, так и агрегированные.
● хранилище данных не служит единым физическим репозиторием (в отличие от подхода Инмона). Это виртуальное хранилище, представляющее собой набор витрин данных, каждая из которых имеет архитектуру «звезда».
14.1.6. Сравнение архитектурных подходов Инмона и Кимбалла
Сходства
Прежде всего, и тот и другой подход направлены на создание одного объекта – корпоративного хранилища данных. Единство конечного объекта означает общность требований, которым должен удовлетворять любой подход для достижения искомого конечного результата, а это, в свою очередь, указывает на то, что и в самой архитектуре должны быть общие черты.
Первое основное требование связано с тем, что для принятия и осуществления важных решений все организации нуждаются в средстве для обеспечения хранения, анализа и интерпретации данных, которые они накапливают. Именно для этого создаются хранилища данных.
Второе требование – это требование точности и своевременности предоставления данных. Каждый пользователь должен иметь возможность доступа к любым данным в соответствии со своими конкретными требованиями, и этот доступ должен осуществляться с помощью понятных и простых способов построения запросов.
Оба архитектурных подхода отвечают названным требованиям в полной мере. Они обеспечивают хранение как детализированных, так и агрегированных данных, которые доступны пользователям для анализа.
Отличия
Первое существенное отличие между этими архитектурами – различные подходы к построению баз данных, составляющих основу хранилища. Если в архитектуре Кимбалла используется многомерная модель данных как на стадии подготовки, так и презентации данных, то архитектура Инмона комбинирует два подхода. В CIF детализированные данные организованы в виде нормализованной реляционной базы, а предназначенные для представления пользователям агрегированные данные организованы с помощью многомерных моделей, как и у Ральфа Кимбалла.
Таким образом, архитектуры отличаются, по сути, только способом организации детализированных данных.
Второе принципиальное отличие этих двух подходов, отчасти вытекающее из первого, – вопрос физической организации хранилища. Если у Инмона хранилище данных – это физически целостный реально существующий объект, то хранилище Кимбалла – скорее «виртуальный» объект. Это набор витрин данных, которые могут быть пространственно разобщенными.
Преимущества и недостатки
Преимущества и недостатки каждого из подходов напрямую вытекают из применяемых ими моделей данных.
С одной стороны, многомерная модель, на которую ориентирована архитектура Кимбалла, облегчает доступ к данным и требует меньше времени на выполнение запросов, а также упрощает работу с детализированными данными. С другой стороны, такая организация данных критикуется за отсутствие необходимой гибкости и чувствительности структуры к изменениям, поскольку в детализированные данные, представленные многомерной моделью, труднее вносить необходимые корректировки.
Реляционная модель детализированных данных, используемая в хранилище Инмона, замедляет доступ к данным и требует больше времени для выполнения запросов в силу различной организации детализированных и агрегированных данных. C другой стороны, она предоставляет широкие возможности для оперирования детализированными данными и изменения их формата и способа представления по мере необходимости.
В целом выбор того или иного архитектурного решения определяется нуждами бизнеса и его конкретными особенностями.
* Intersoft Lab. Сходство и различия двух подходов к архитектуре Хранилищ данных. Intersoft Lab: Журнал ВРМ World. 2005. – URL: .
14.1.7. Гибридный подход
Многие организации используют так называемый гибридный подход, стараясь совместить преимущества обоих описанных выше архитектурных концепций.
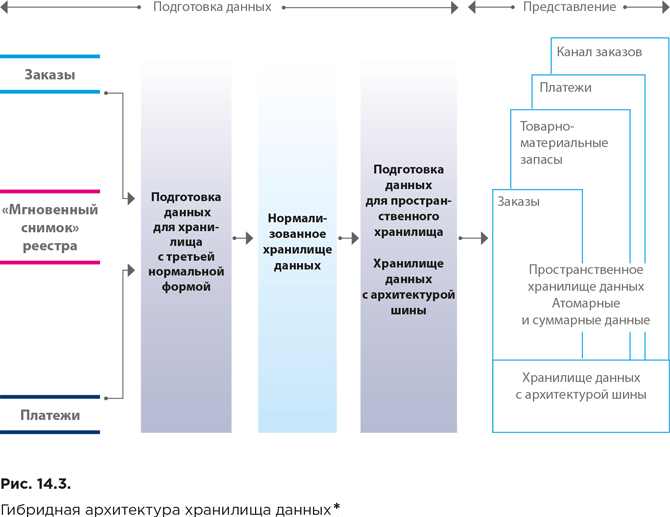
Гибридная архитектура хранилища данных представлена на рисунке 14.3.
Гибридное хранилище включает нормализованное хранилище CIF и многомерное хранилище детализированных и агрегированных данных на основе архитектуры шины.
Недостаток данного подхода в том, что двойная работа по подготовке и хранению детализированных данных сопровождается существенными дополнительными расходами и задержками.
14.1.8. Обобщенная архитектура аналитической рабочей среды организации
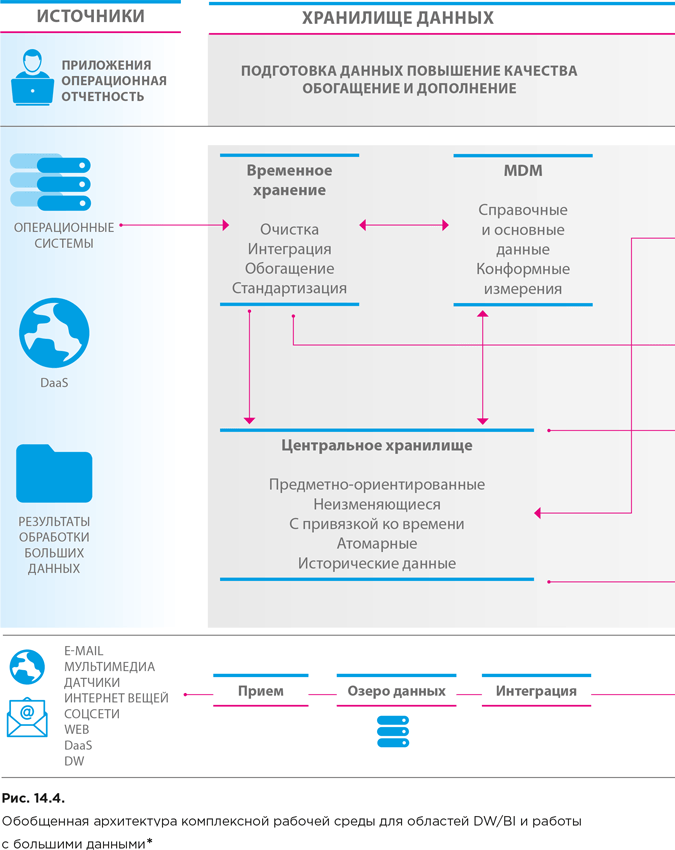
С развитием концепции больших данных представление об архитектуре аналитической рабочей среды организации несколько меняется, поскольку контур обработки больших данных стал дополнительным магистральным каналом притока новых сведений. Рисунок 14.4 описывает обобщенную архитектуру рабочих сред организации для областей бизнес-аналитики (на основе традиционного хранилища данных – DW) и науки о данных (на основе хранилища больших данных).
Работа с данными в среде DW/BI осуществляется следующим образом. Из систем-источников данные поступают в область временного хранения, где подвергаются очистке и обогащению, интегрируются и отправляются на хранение в центральное хранилище данных (DW) или хранилище операционных данных (operational data store, ODS). Доступ к данным из DW осуществляется через витрины или кубы (data cube).
Хранилище операционных данных представляет собой интегрированную базу операционных данных, поступающих от приложений или из других баз данных. В ODS обычно содержатся только текущие данные или данные за относительно небольшой отчетный период, в то время как в главном DW накапливаются еще и исторические данные. Главное же отличие ODS от DW заключается в том, что операционные данные динамически изменяются по мере поступления новых данных в отличие от статичных данных в главном хранилище. ODS используются далеко не во всех организациях, а только в тех, где требуется минимизировать время запаздывания.
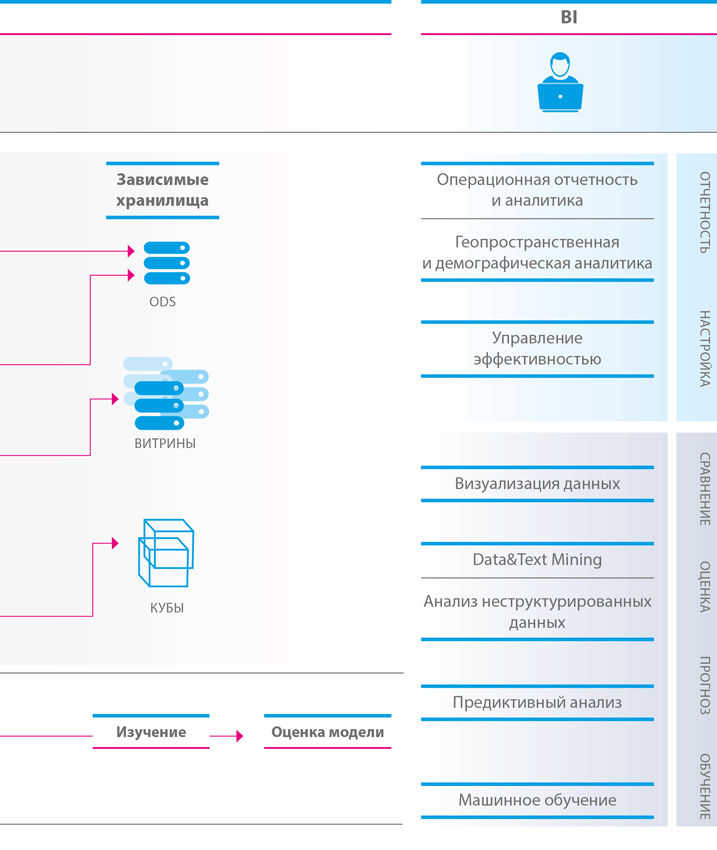
Для проведения бизнес-анализа в настоящее время предлагается широкий спектр BI-инструментов, которые можно разбить на следующие основные типы:
● операционная отчетность – позволяет выявлять и анализировать краткосрочные (помесячные) и среднесрочные (годовые) тенденции и закономерности;
● управление эффективностью бизнеса (Business Performance Management, BPM) – позволяет производить формальную оценку измеримых показателей, соответствующих целям организации;
● приложения для оперативного анализа – могут включать функции анализа клиентов, финансов, цепочек поставок, организации производства, управления персоналом и т. п.
Среди приложений для оперативного анализа особо выделяются инструменты онлайновой аналитической обработки (online analytical processing, OLAP), обеспечивающие высокопроизводительную обработку многомерных аналитических запросов. Выдача данных в ответ на запросы обычно происходит в матричном формате. Измерения определяются столбцами и строками матрицы, на пересечении которых выводятся факторы или значения. Концептуально такая модель может быть представлена как многомерный куб данных. Ниже перечислены три наиболее распространенные архитектуры OLAP-систем.
● Реляционная (ROLAP): функциональность OLAP реализуются посредством моделирования многомерности через определение связей между атрибутами стандартных двумерных таблиц систем управления реляционными базами данных. Стандартная схема модели данных в среде ROLAP – звездообразная.
● Многомерная (MOLAP): поддержка OLAP в составе или с использованием коммерческих и специализированных многомерных баз данных.
● Гибридная (HOLAP): сочетание ROLAP и MOLAP. Гибридные реализации позволяют хранить часть данных в MOLAP, а часть – в ROLAP. Реализации могут варьироваться в зависимости от имеющихся у проектировщика возможностей по контролю структуры разделов данных.
Важнейший принцип организации портфеля BI-приложений – самообслуживание (self-service) в части настроек представления и выдачи данных. Доступные пользователю действия обычно регулируются настройками профиля на портале доступа, где, в зависимости от привилегий, можно выбирать, подключать или отключать и конфигурировать различные функциональности, уведомления, сообщения и предупреждения, периодичность просмотра производственных отчетов, порядок взаимодействия с аналитическими отчетами, разрабатывать собственные отчеты и пользоваться настройками и функциями приборной панели и картами показателей.
Выделенные на рисунке 14.4 архитектурные компоненты в различных организациях могут быть реализованы по-разному, в зависимости от выбранного архитектурного подхода. В частности, как мы уже говорили, архитектура Кимбалла подразумевает, что данные в хранилище структурно распределены по витринам данных подразделений, с помощью которых и обеспечивается их очистка, стандартизация и управление. В этом случае именно в витринах хранится история данных на максимально детализированном (атомарном) уровне.
Параллельно обработке данных в среде DW/BI во многих организациях осуществляется обработка входящих потоков больших данных. При этом данные сначала загружаются в специальное хранилище – озеро данных (data lake), а затем осуществляется их интеграция и исследование с построением моделей. Работа с большими данными будет рассмотрена более подробно далее (см. раздел 14.3).
14.1.9. Контекстная диаграмма области знаний и уровни зрелости функции «Ведение хранилищ данных и бизнес-аналитика»
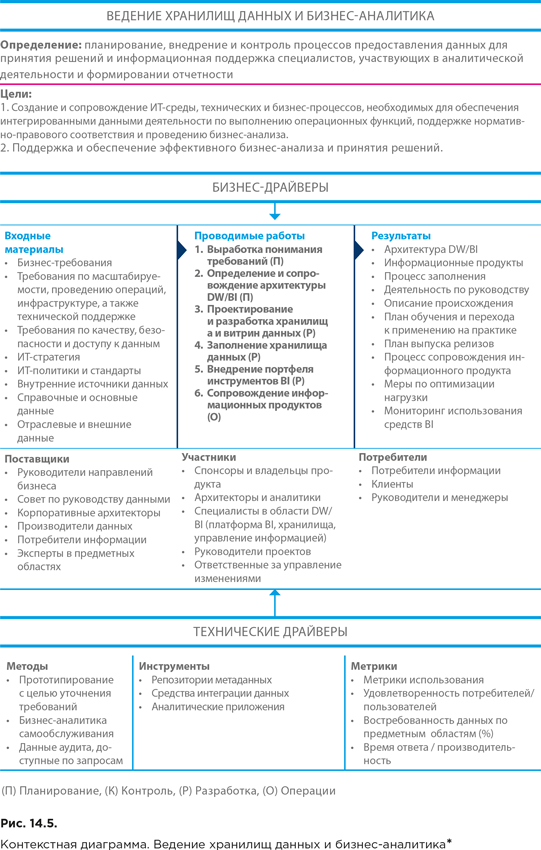
Контекстная диаграмма области знаний «Ведение хранилищ данных и бизнес-аналитика» представлена на рисунке 14.5.
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
При планировании и внедрении хранилища данных следует руководствоваться следующими принципами:
● фокусировка на целях бизнеса. Хранилище данных должно соответствовать приоритетам организации и способствовать решению бизнес-задач;
● ориентация на желаемые конечные результаты. Приоритеты и интересы бизнеса плюс потребности в данных BI-приложений должны от начала и до конца диктовать выбор содержания и структуры информационного наполнения хранилища данных;
● мыслить глобальными категориями при планировании архитектуры, но руководствоваться локальными соображениями при построении. Видение полной картины конечного результата воплощения архитектурного замысла – требование обязательное, но реализация этого замысла ведется итерационно-поступательными движениями – целевыми проектами или «спринтерскими рывками», обеспечивающими быструю окупаемость вложений;
● обобщение и оптимизация производятся на завершающих, а не начальных этапах реализации. Системную архитектуру необходимо выстраивать на основе максимально детализированных данных. Обобщение, сведение и интеграцию с целью приведения структуры данных к стандартным требованиям и повышения производительности систем нужно на время отложить, поскольку для восстановления утерянных деталей всю работу придется откатывать до точки дезинтеграции;
● ориентация на прозрачность и самообслуживание. Чем больше контекста (т. е. всевозможных метаданных), тем проще потребителям разобраться в смысле данных и найти им полезное и выгодное применение. Необходимо информировать заинтересованные стороны о происхождении данных и процессах их интеграции;
● параллельно с хранилищем необходимо выстраивать метаданные. Критический фактор успеха хранилища данных – способность объяснять смысл и происхождение данных. Структура метаданных должна формироваться на стадии проработки модели данных, а учет и управление – входить в состав рабочих процессов и текущих операций;
● сотрудничество с другими направлениями и проектами в области управления данными. Прежде всего необходимо осуществлять тесное взаимодействие с ответственными за руководство данными, обеспечением качества данных и ведением метаданных;
● нельзя подходить ко всем потребителям данных с едиными критериями. Различным группам потребителей требуются различные инструменты и продукты.
В начале раздела 14.1 мы уже отметили роли DW и BI в цепочке поставок данных. Внедренное хранилище данных и его ориентированная на потребителей данных часть, включающая клиентские приложения и инструменты BI, превращаются, по сути, в информационный продукт. Последующие усовершенствования платформы DW (дополнения, надстройки и/или модификации) следует проводить поэтапно, методом приращений.
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
На рисунке 14.6 представлены обобщенные характеристики уровней зрелости функции «Ведение хранилищ данных и бизнес-аналитика».

* Smith P., Edge J., Parry S., Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
14.1.10. Влияние на ценность данных
Довольно часто встречаются организации, у которых есть несколько хранилищ данных. Например, отдельные хранилища для подразделений финансов, продаж и маркетинга, обслуживания клиентов и т. п. Нередко одни и те же системы поддержки операционной деятельности загружают данные в несколько хранилищ, а иногда данные передаются между этими хранилищами.
Однако усилия по интеграции, стандартизации и обработке данных в хранилище обеспечивают наибольшую отдачу, если данные становятся доступными для всех, кто ими пользуется. Таким образом, максимальный эффект от внедрения технологий DW достигается только при создании корпоративного хранилища данных (EDW), собирающего данные от всех операционных систем и делающего их доступными для всей организации.
Можно выделить следующие преимущества внедрения в организации EDW, которые оказывают существенное влияние на повышение ценности ее данных.
Доступность данных для всей организации
Прежде чем кто-то в организации попытается инициировать реализацию нового отчета, процедуры по извлечению, преобразованию и загрузке (ETL), сервиса данных и т. п., он должен ознакомиться с возможностями, предоставляемыми EDW. Может оказаться, что нечто подобное уже доступно где-то в организации.
Необходимое условие обеспечения доступности данных – налаженное должным образом ведение и обеспечение доступности соответствующих метаданных. Все заинтересованные сотрудники организации должны знать, какие данные имеются в ее распоряжении (см. главу 15).
Возможность публикации данных в режиме, близком к реальному времени
В главе 11, обсуждая задержки при обработке данных, мы говорили о том, что обработка данных о текущих операциях обычно проводится в режиме реального времени или в режиме, близком к реальному времени (near real-time), а данных, требуемых для анализа и отчетности, – по графику, в пакетном режиме (см. главу 12, раздел 12.2.3). Однако с учетом постоянного ужесточения бизнес-требований пакетный режим во многих случаях становится все менее приемлемым.
Современные технологии позволяют обнаруживать и передавать изменения в данных почти в режиме реального времени (например, на основе модели публикации и подписки – см. главу 12, раздел 12.2.3).
Публикация данных в режиме, близком к реальному времени, не всегда проста и в значительной степени зависит от операционных систем, предоставляющих данные в хранилище данных. Поэтому при реализации таких возможностей важно обеспечить их доступность на корпоративном уровне максимально широкому кругу сотрудников.
Возможность отслеживания происхождения данных
Завоевание доверия к информации – важнейший аспект внедрения DW. По мере поступления данных в хранилище вместе с ними должны передаваться сведения о том, откуда они появились. Это достигается за счет описания происхождения данных (data lineage) (см. главы 8 и 11) и организации доступности соответствующих метаданных (см. главу 15). Понимая, кому принадлежат отдельные элементы данных и для каких целей они были получены, мы можем добиться соответствия нормативно-правовым требованиям и использовать данные эффективнее.
Роль EDW как корпоративной памяти
Хранилище данных должно выступать в качестве корпоративной памяти. Под этим подразумевается, что оно должно хранить с привязкой ко времени все данные, которые использует организация.
Когда руководство организации принимает решение, подкрепленное какими-либо доказательствами, хранилище данных и связанные с ним инструменты бизнес-аналитики должны обеспечивать предоставление исторической справки об этих доказательствах. Это не только усиливает поддержку выполнения требований нормативно-правового соответствия, но и позволяет в будущем развивать анализ тенденций.
Кроме того, существенная помощь обеспечивается с точки зрения извлечения уроков. Сравнение фактических результатов решения с результатами, предсказанными на основе данных, может быть использовано для повышения эффективности в будущем.
Эффективное использование опыта экспертов
Как правило, во многих подразделениях организации есть сотрудники – «источники знаний», которые хорошо разбираются в тонкостях информационных систем и данных. Объединив этих людей с теми, кто понимает, как применять инструменты анализа, можно получить много новых идей в отношении данных и их использования.
Целесообразно создать в организации центр компетенций в сфере бизнес-аналитики. Он должен играть роль центрального источника знаний для всех, у кого есть вопросы или предложения по поводу использования EDW. Деятельность центра также будет стимулировать инновации (что положительно скажется на итоговой прибыли) и может даже повысить привлекательность организации для потенциальных сотрудников.
14.2. Управление документами и контентом
Управление документами и контентом подразумевает наличие средств, позволяющих контролировать создание, регистрацию, хранение, защиту и использование самых разнородных сведений, доступ к которым невозможно организовать с помощью традиционных реляционных систем управления базами данных. Процессы в цепочках поставок таких данных имеют свою специфику, которую мы обсудим в этом разделе.
14.2.1. Определение области знаний «Управление документами и контентом»
Управление документами и контентом (Document and Content Management, DCM) распространяется на любые неструктурированные и полуструктурированные данные, т. е. данные, структура которых не описывается предопределенной моделью – будь то реляционная или любая другая модель данных (см. главу 8, раздел 8.2). Главная задача здесь – обеспечение сохранности и целостности обрабатываемых сведений, а также регулирование доступа к ним. В этом плане управление документами и контентом в общих чертах мало чем отличается от операционного управления реляционными базами данных (см. главу 12, раздел 12.1). Однако помимо текущих задач в этой области есть и стратегические. Во многих организациях неструктурированные данные имеют прямое отношение к структурированным. Соответственно, и управленческие решения должны приниматься согласованно и применяться последовательно. Кроме того, документы и неструктурированный контент требуют надежной защиты и контроля качества. А обеспечение информационной безопасности и качества таких данных невозможно без руководства, надежной архитектуры и налаженного управления метаданными.
14.2.2. Цели и бизнес-драйверы
Основными целями управления данными и контентом являются:
● обеспечение возможностей для эффективного накопления, получения и использования данных, сохраняемых в неструктурированных форматах;
● интеграция структурированных и неструктурированных данных;
● соблюдение действующего законодательства и обеспечение соответствия ожиданиям клиентов.
Главными бизнес-драйверами управления документами и контентом являются обеспечение соблюдения требований нормативно-правового регулирования, способность адекватно отвечать на запросы судебно-арбитражных и надзорных органов об электронном раскрытии информации (e-discovery), а также обеспечение непрерывности бизнеса. Составители DMBOK считают, что качественное управление рассматриваемым видом данных оказывает серьезное влияние на эффективность работы организаций. Прогресс в области технологий управления документами позволяет организациям автоматизировать и оптимизировать документооборот, устранять дублирующие друг друга ручные операции, нормализовать внутриорганизационное сотрудничество и внешние партнерские связи.
В свою очередь, дополнительным преимуществом этих технологий выступает упрощение и ускорение поиска, доступа и публикации нужных документов. Наконец, они же способствуют предотвращению утери важных документов. Все это крайне важно и для обеспечения электронного раскрытия информации, и для экономии денежных средств за счет высвобождения офисного пространства и снижения затрат на ведение и обработку документации.
Хорошо структурированные веб-сайты с мощными поисковыми возможностями позволяют эффективно управлять онтологиями и другими структурами, максимально упрощающими клиентам и сотрудникам поиск нужного контента, тем самым повышая уровень их удовлетворенности.
14.2.3. Основные понятия в области управления документами и контентом
Говоря об управлении документами и контентом, следует пояснить ряд исходных понятий.
Документы и записи
Документами называются электронные или бумажные (как печатные, так и рукописные) материалы с инструкциями, руководствами, требованиями и распоряжениями, которые касаются выполнения различных задач или функций, например, протоколами собраний и решений. Также документы могут использоваться для распространения информации или обмена знаниями и опытом. Примеры распространенных типов документов – акты, методики, правила, протоколы, процедуры руководства, спецификации, стандарты и технические задания.
В свою очередь, записи (records) – это подмножество документов определенного вида. То есть не всякий документ классифицируется как запись, но всякая запись относится к категории документов. Записи свидетельствуют, что действия, сведения о которых в них зафиксированы, были действительно произведены и сделано это было в установленном нормативными документами порядке; соответственно, записи могут использоваться для представления, например, в надзорные органы в качестве доказательства соблюдения организацией в ходе осуществления текущей деятельности установленных всевозможными регламентами требований. В современных условиях записи создаются или ведутся не только людьми, но и автоматическими средствами мониторинга и регистрации.
Документы и записи бывают физическими (документы, записки, договора, отчеты, квитанции, письма и микрофильмы) и электронными (письма и вложенные файлы e-mail, СМС, сообщения по мессенджерам и многие другие.). Отдельно стоит выделить контент веб-сайтов, документы на любых носителях и в любых аппаратных средах, а также записи в базах данных любого рода и типа.
Контент
Контент – это информационное наполнение документа. Документ можно рассматривать как некий контейнер, а вот контент – как то, что в этом контейнере содержится. Под контентом принято понимать данные и информацию, размещенную внутри файла, документа или на веб-сайте. Контентом часто управляют исходя из степени концептуальной важности документов, в которых он содержится, а также в зависимости от типа или статуса документов. Важно отметить, что у контента есть свой вполне конкретный жизненный цикл. В своей завершенной форме часть контента становится содержимым записей организации. Официальные записи требуют особого обращения по сравнению с прочим контентом.
Управление документами и записями
Управление документами (document management) – понятие, которое описывает весь спектр процессов, приемов и технологий распоряжения документами и записями на протяжении всего их жизненного цикла, включая хранение, учет и контроль как электронных, так и бумажных вариантов. Свыше 90 % документов в наши дни создаются в электронной форме.
В целом управление документами занимается их формой, а не содержанием, – иными словами, файлами и папками, а не контентом. Информационное наполнение может служить лишь подсказкой, как лучше этим файлом распоряжаться, но в рамках управления документами практическое обращение с этим файлом как с документом будет все так же строиться на основе его рассмотрения как единого и неделимого целого.
Управление записями (records management) – важнейший компонент управления документами. К управлению записями предъявляются особые требования. Согласно международному стандарту ISO 15489–1:2016 Information and documentation – Records management – Part 1: Concepts and principles управление записями включает:
a) создание записей и их ввод в систему с целью доказательства ведения деловых операций;
b) принятие надлежащих мер по защите их аутентичности, достоверности, целостности и пригодности для использования в условиях изменяющейся во времени деловой среды и требований к управлению записями.
Управление жизненным циклом документов и записей предполагает следующие виды работ:
● учет – идентификация и инвентаризация существующих и вновь создаваемых документов и записей;
● определение политик – разработка, утверждение и обеспечение соблюдения политик ведения, оборота, хранения и уничтожения документов и записей;
● классификация документов и записей;
● хранение физических и электронных документов и записей (текущее и архивное);
● получение и распространение – регулирование доступа к документам и записям, их тиражирования и распространения в соответствии с установленными политиками и правилами, стандартами информационной безопасности и защиты данных, распоряжениями руководства организации и нормативно-правовыми требованиями;
● сохранение и уничтожение – своевременное архивирование и уничтожение документов и записей в соответствии с нуждами организации, законами, нормами и правилами.
Управление контентом
Управление контентом (content management) включает процессы, методы и технологии упорядочения, классификации и структурирования информационных ресурсов с целью обеспечения возможности их хранения, публикации и многократного многоцелевого использования.
Жизненный цикл контента может быть высокоактивным и предусматривать ежедневные изменения посредством контролируемых процессов создания, добавления или изменения информации. Существует также статичный контент, вовсе не меняющийся или изменяемый крайне редко и в минимальных пределах. В свою очередь, управление контентом может варьироваться от строго формализованного (в соответствии с жесткими правилами хранения, доступа, обращения и аудита, контролем сроков хранения и ликвидации) до полностью неформального добавления и изменения контента пользователями.
Если управление контентом ведется в масштабах организации, такой подход называется управлением корпоративным контентом (Enterprise Content Management, ECM).
Контролируемые словари
Контролируемым словарем (controlled vocabulary) называют определенный перечень слов, которые допустимо использовать в индексах, названиях категорий, документов, файлов и иных объектов, а также тегах метаданных с целью обеспечения возможности поиска, извлечения и просмотра контента. Подобный регламентированный лексикон необходим также и для систематизации документов, записей и контента в каталогах библиотек. Сложность структуры словарей может варьироваться от простого списка или меню до более сложных кругов синонимов или нормативных словарей, еще более сложных таксономий и вплоть до сложнейших онтологий и тезаурусов.
Электронное раскрытие информации
Юрисдикции многих государств предусматривают действие специальных регламентов, дающих возможность организациям представлять суду доказательства в электронной форме. Электронные документы обычно маркированы метаданными (в отличие от многих бумажных, которые могут как иметь, так и не иметь данные об их происхождении), которые позволяют использовать их как важную часть доказательной базы. Процедура электронного раскрытия информации (e-discovery) позволяет выявлять электронные записи, которые могут быть предъявлены в судах различных инстанций и юрисдикций в качестве документальных доказательств.
14.2.4. Контекстная диаграмма области знаний и уровни зрелости функции «Управление документами и контентом»
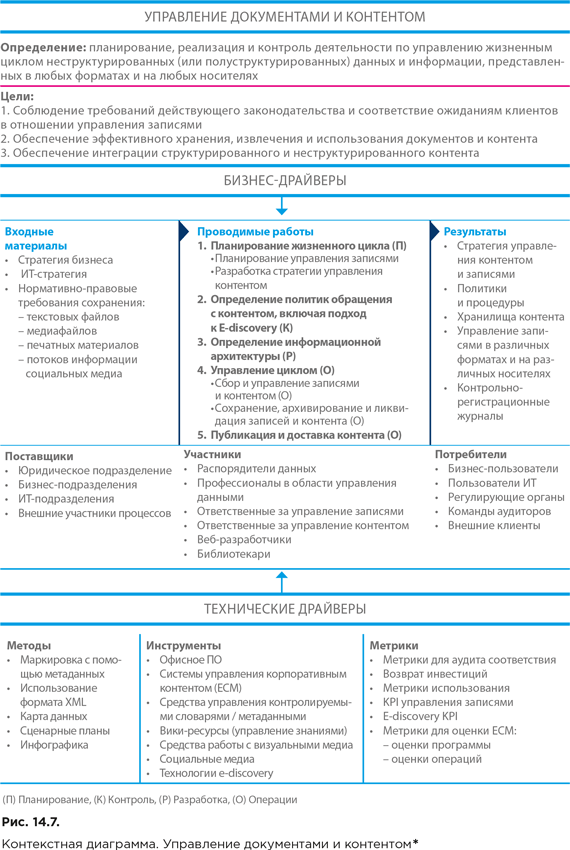
Контекстная диаграмма области знаний «Управление документами и контентом» представлена на рисунке 14.7.
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
Для успешного управления документами, записями и другими видами совместно используемого контента требуется:
1. Четкое планирование, включая формирование политик для различных видов доступа и обработки.
2. Обеспечение возможности управления терминологией, включая онтологии и таксономии, необходимой для организации, а также хранения и извлечения различных форм контента.
3. Определение информационной архитектуры и метаданных, необходимых для поддержки контент-стратегии.
4. Внедрение технологий, позволяющих управлять жизненным циклом контента – от создания или сбора контента до управления версиями и обеспечения безопасности.
5. Для записей решающее значение имеет политика хранения и удаления. Записи должны храниться в течение требуемого периода времени и быть уничтожены, как только будут выполнены требования к сроку их хранения. Пока записи существуют, они должны быть доступны соответствующим людям и процессам и должны доставляться по соответствующим каналам.
Для достижения этих целей организациям требуются системы управления контентом (Content Management System, CMS), а также инструменты для создания и управления метаданными, которые поддерживают работу с контентом. Кроме того, им необходимо внедрить функцию руководства для контроля за политиками и процедурами, которые обеспечивают эффективное использование контента и предотвращают его неправильное применение. Такое руководство позволяет организации последовательно и должным образом реагировать на судебные разбирательства.
Система управления корпоративным контентом (ECM) может представлять собой как единое платформенное решение, включающее все основные компоненты, так и набор приложений с различной степенью интеграции в единую систему (от полностью интегрированных до полностью самостоятельных). Компоненты или приложения могут находиться как по месту работы, так и в облачной среде.
На рисунке 14.8 представлены обобщенные характеристики уровней зрелости функции «Управление документами и контентом».
14.2.5. Влияние на ценность данных
По мере развития технологий создания, хранения и использования данных объемы информации, сохраняемой в электронном виде (Electronically Stored Information, ESI), стремительно растут. От того, насколько предусмотрительно и активно ведется управление накапливающимися документами и контентом, зависят такие способности организации, влияющие на повышение ценности ее данных, как:
● способность оперативно предоставлять пользователям актуальные версии документов и контента;
● способность проведения новых видов анализа деятельности организации за счет связывания различных видов контента с уже имеющимися структурированными данными (например анализ проблем в отношении эксплуатации конкретного продукта на основе разбора связанных с ним писем от клиентов);
● способность адекватно и оперативно откликаться на запросы в отношении электронного раскрытия информации.

* Smith P., Edge J., Parry S., Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
14.3. Большие данные и наука о данных
За понятиями «большие данные» и «наука о данных» стоят значительные технологические изменения, благодаря которым появилась возможность генерировать, хранить и анализировать колоссальные объемы данных, и эти объемы продолжают неуклонно расти. Специалисты научились использовать такие данные для моделирования, прогнозирования и влияния на поведение людей, а также получения углубленных представлений о широком спектре важнейших предметов, включая статистику здравоохранения, управления природными ресурсами и экономического развития
Хотя значительная часть больших данных относится к категории неструктурированных и полуструктурированных, процессы в цепочках их поставок имеют существенно более сложную специфику, чем рассмотренные нами в предыдущем разделе особенности управления документами и контентом.
14.3.1. Определение функциональной области «Большие данные и наука о данных»
Чтобы охарактеризовать рассматриваемую область, приведем некоторые определения из ГОСТ Р ИСО/МЭК 20546-2021 «Информационные технологии. Большие данные. Обзор и словарь».
Под большими данными (big data) понимаются большие массивы данных, отличающиеся главным образом такими характеристиками, как объем, разнообразие, скорость обработки и вариативность, которые требуют использования технологии масштабирования для эффективного хранения, обработки, управления и анализа (кроме того, термин «большие данные» широко применяется в различных значениях, например в качестве наименования технологии масштабирования, используемой для обработки больших массивов данных).
Таким образом, определение больших данных опирается на следующие ключевые понятия:
● массив данных (dataset) – идентифицируемая совокупность данных, к которой можно получить доступ или скачать в одном или нескольких форматах;
● объем данных (data volume) – количественная характеристика данных, влияющая на выбор ресурсов для вычислений и хранения, а также на управление данными в процессе обработки (объем данных становится важным при работе с большими массивами данных);
● разнообразие данных (data variety) – диапазон форматов, логических моделей, временных шкал и семантики массива данных (данное понятие отражает нерегулярность и разнородность структур данных, навигации по структурам, запросов и типов данных);
● скорость обработки данных (data velocity) – скорость потока, с которой данные создаются, передаются, сохраняются, анализируются или визуализируются;
● вариативность данных (data variability) – изменения в скорости передачи, формате или структуре, семантике или качестве массива данных.
Под наукой о данных (data science) понимается извлечение практических знаний из данных посредством исследования или создания и проверки гипотез.
Наука о данных изучает полный жизненный цикл аналитики данных. Аналитика данных (data analytics) – это составное понятие, охватывающее получение, сбор, проверку и обработку данных, включая их количественную оценку, визуализацию и интерпретацию.
Аналитика данных используется для представления объектов, описываемых данными, с целью прогнозирования конкретных ситуаций и формирования пошаговых рекомендаций при решении задач. Закономерности, полученные посредством аналитики, используются в различных целях, таких как принятие решений, проведение исследований, обеспечение устойчивого развития, проектирование, планирование и т. д.
В принципе, понятие «наука о данных» используется для обозначения хорошо известной дисциплины – прикладной статистики (applied statistics). Отличия обуславливаются тем, что вычислительные мощности, необходимые для выявления статистических закономерностей, сегодня выросли настолько, что способствовали появлению больших данных и реализации технологий их статистико-аналитической обработки.
До недавнего времени углубленный анализ колоссальных массивов данных был невозможен по технологическим причинам, и аналитикам приходилось полагаться на ограниченные по размерам статистические выборки или иные средства приблизительной оценки. С ростом вычислительных мощностей ученые научились накапливать и обрабатывать более объемные массивы данных и применять к ним комплексные методы анализа, позаимствованные из прикладной математики, статистики, информатики, обработки и преобразования сигналов, теории вероятностей, распознавания образов, машинного обучения, моделирования неопределенности, визуализации данных и других прикладных областей знания с целью углубленного изучения и предсказания поведения систем на основе массивов больших данных. Иными словами, наука о данных нашла новые способы анализа данных и извлечения из них ценности.
Специалистов, которые исследуют данные, строят предиктивные (predictive) и предписывающие (prescriptive) модели, а также модели машинного обучения (machine learning), проводят на их основе анализ и осуществляют внедрение полученных результатов в интересах заинтересованных сторон, стали теперь называть «учеными в области данных» или «учеными по данным» (data scientists).
Важно понимать, что рассмотренные нами отличительные характеристики больших данных предъявляют новые требования к методам управления данными. Для использования преимуществ больших данных необходимо изменить привычные методические подходы. Большинство хранилищ данных используют традиционную реляционную модель. Большие данные, как правило, в виде такой модели не представлены. В большинстве хранилищ данных обработка тесно связана с процедурами ETL (извлечение, преобразование, загрузка). В решениях для обработки больших данных (в частности, в так называемых «озерах данных») используется концепция ELT, т. е. загрузка и последующее преобразование. Не менее важно и другое: скорость и потоки загрузки в случае сбора больших данных столь велики, что стандартные подходы к критически важным аспектам управления данными – интеграции, управлению метаданными, обеспечению качества данных – становятся неприемлемыми, и возникает необходимость в выработке и реализации принципиально новых решений еще и в этих областях.
14.3.2 Цели и бизнес-драйверы
Организации осуществляют деятельность в области больших данных и науки о данных со следующими целями:
● раскрытие связей между данными и бизнесом;
● итеративное включение источников данных в среду организации;
● выявление и анализ новых факторов, которые могут оказывать влияние на бизнес;
● публикация и визуализация достоверных данных в подходящей и этичной форме.
В своей основе цели деятельности в области больших данных и науки о данных достаточно близки к целям деятельности в области ведения хранилищ данных и бизнес-аналитики (см. раздел 14.1.2). При этом имеется существенное отличие.
Традиционная бизнес-аналитика (BI) подобна «зеркалу заднего вида», поскольку описывает тенденции, выявленные по результатам изучения структурированных ретроспективных данных. Иногда выявленные закономерности бизнес-аналитики используются и для прогнозирования, но уверенности в надежности таких прогнозов нет, поскольку это всего лишь экстраполяции в будущее прошлых тенденций, которые в любой момент могут измениться.
С развитием технологий обработки больших данных и методов науки о данных организации приобретают способность смотреть вперед – «через лобовое стекло». Возможность прогнозирования на основе моделей, в том числе в режиме, близком к реальному времени, с использованием разнородных данных из множества различных источников помогает организациям лучше понимать направления своего развития.
Главный драйвер развития в организации работ в области сбора и исследования больших данных – стремление к обнаружению скрытых бизнес-возможностей посредством всесторонней аналитической проработки массивов данных с использованием широкого спектра диверсифицированных алгоритмов. Большие данные стимулируют инновации, поскольку объемы и разнообразие массивов, доступных для исследования, безостановочно растут и все эти данные можно использовать для определения моделей прогнозирования нужд потребителей и создания персонализированных презентаций продуктов и услуг. Наука о данных способствует повышению производительности и результативности обработки больших данных. Алгоритмы машинного обучения помогают автоматизировать сложные по структуре и ресурсоемкие комплексы рабочих процессов, способствуя повышению эффективности работы организации, снижая затраты и минимизируя риски.
14.3.3. Дата-инжиниринг и экосистема больших данных
В разделе 14.1.8 мы рассматривали архитектуру комплексной рабочей среды для областей DW/BI и работы с большими данными (см. рис. 14.4). В процессе обработки входящих потоков больших данных сначала осуществляется их загрузка в специальное хранилище – озеро данных (data lake), а затем проводятся работы по интеграции и исследованию данных с построением моделей.
Поскольку сведения в озере данных могут быть необработанными (сырыми) и поступать из источников, не относящихся к операционным информационным системам организаций, они не подходят для рядового бизнес-пользователя; скорее, озера данных предоставляют материал для работы ученых по данным и различного рода экспертов, проводящих подробный анализ данных.
В связи с этим возникает необходимость в такой важной области деятельности, как дата-инжиниринг.
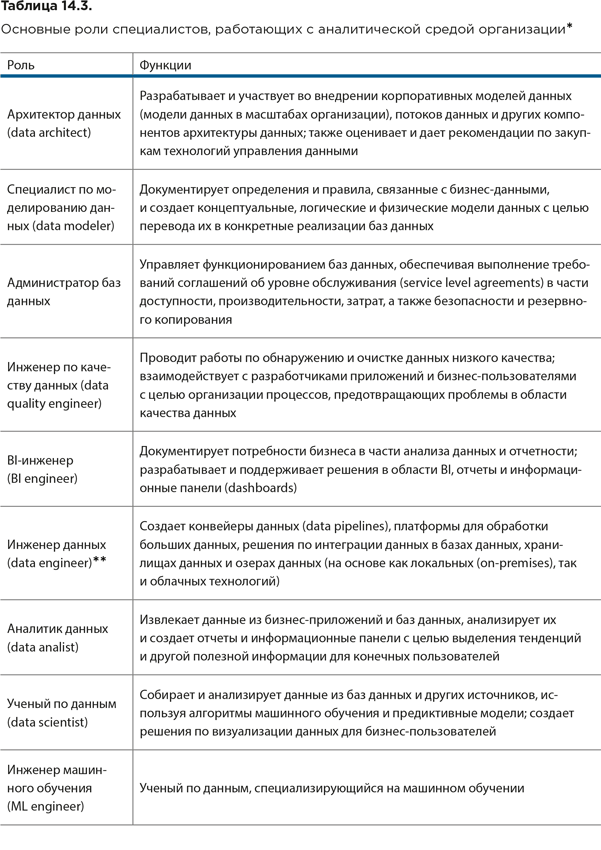
Дата-инжиниринг (data engineering) – это комплексная деятельность по обеспечению возможности использования необработанных данных. Без подготовительных работ им было бы невозможно разобраться в огромных объемах больших данных. За выполнение таких работ отвечает отдельная группа специалистов – инженеры данных (data engineers).
Инженеры данных – это инженеры-программисты (software engineers), которые, как правило, отвечают за построение конвейеров данных (data pipelines) для объединения информации из разных систем-источников. Они интегрируют, консолидируют и очищают данные и структурируют их для использования в аналитических приложениях.
Инженеры данных работают совместно с учеными по данным, повышая прозрачность данных и позволяя организациям принимать более надежные бизнес-решения.
Объем данных, с которыми работает инженер данных, зависит от организации и особенно от ее размера. Чем крупнее организация, тем сложнее архитектура аналитики и тем за большее количество данных он будет отвечать. Некоторые отрасли обрабатывают данные более интенсивно, в том числе здравоохранение, розничная торговля и финансовые услуги.
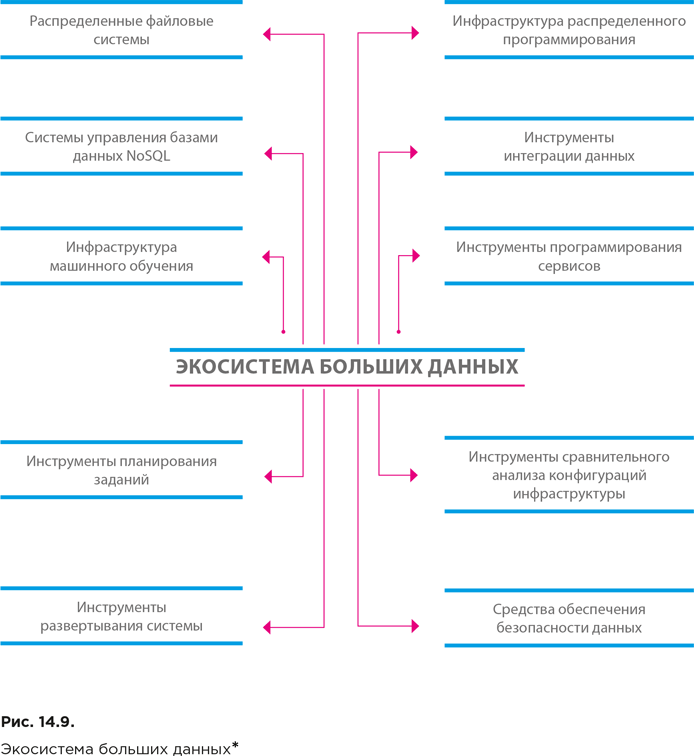
Основная цель инженера данных – сделать данные легко доступными и оптимизировать экосистему больших данных своей организации. Поэтому инженер данных должен иметь обширные знания в области современных технологий хранения и обработки данных, поскольку экосистема больших данных может включать самые разнообразные компоненты (рис. 14.9).
В первую очередь следует выделить распределенные файловые системы. Они работают на нескольких серверах сразу, способны хранить файлы, превышающие по объему размер диска отдельного компьютера, ориентированы на параллельную обработку файлов (одновременно на нескольких компьютерах) и легко масштабируются.
* Силен Д., Мейсман А., Али М. Основы Data Science и Big Data. Python и наука о данных. – СПб.: Питер, 2018.
Для работы с данными в распределенной файловой системе должна быть использована специальная инфраструктура распределенного программирования.
Хранение огромных объемов данных предполагает использование систем управления базами данных, специализирующихся на работе с такими данными и формировании запросов к ним. Традиционные реляционные СУБД, использующие язык запросов SQL (такие как Oracle или MySQL), плохо справляются с большими объемами. Кроме того, в них отсутствуют средства обработки потоковых, неструктурированных и графовых (ориентированных на представление в виде графа) данных. Поэтому появились новые типы СУБД на основе нереляционных технологий, объединенные в категорию NoSQL (см. главы 11 и 12).
Данные в распределенной файловой системе перемещаются от источников к потребителям с помощью специальной инфраструктуры интеграции данных.
Когда данные доходят до потребителя, начинается их обработка с целью извлечения из них скрытой полезной информации и знаний. На этой стадии используются методы из области машинного обучения, статистики и прикладной математики. Необходимые для работы алгоритмы предоставляются инструментами, входящими в среду инфраструктуры машинного обучения.
С целью обеспечения всем заинтересованным системам (вне зависимости от их внутренней организации) унифицированный доступ к создаваемым приложениям, их реализуют в виде сервисов. Для этого используют специальные инструменты программирования и стандарты реализации (см. главу 12).
Для автоматизации повторяющихся операций и запуска заданий по событиям используются инструменты планирования заданий, созданные специально для работы с большими данными.
Инфраструктуру, обрабатывающую большие объемы данных, необходимо оптимизировать (это может принести существенную экономию). Оптимизация осуществляется с помощью инструментов сравнительного анализа конфигураций.
Развертывание новых приложений в кластерах больших данных можно облегчить с помощью инструментов, обеспечивающих автоматизацию установки и настройки.
Наконец, средства обеспечения безопасности, поддерживают функционирование приложения в рамках единой централизованной системы управления доступом.
14.3.4. Архитектурные компоненты аналитической среды организации и роли работающих с ними специалистов
Схема на рисунке 14.10 отражает архитектуру аналитической среды организации в более упрощенном виде, чем схема на рисунке 14.4. На ней выделено пять слоев.
Слой источников данных включает системы оперативной обработка транзакций (OLTP), поддерживающие операционную деятельность организации. Кроме того, в него могут входить различные приложения, подключаемые по API, а также датчики, внешние устройства и другие источники данных, подключаемые напрямую или с помощью сетевых протоколов.

* Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Слой обработки данных выделен для обозначения операций, осуществляемых в пакетном режиме (с перерывами): ETL (извлечение – преобразование – загрузка) и ELT (извлечение – загрузка – преобразование), либо в потоковом (непрерывно).
Слой хранения может включать традиционное хранилище данных – Data Warehouse (DW), хранилище больших данных – озеро данных, либо современное хранилище, объединяющее DW и озеро данных, – платформу данных.
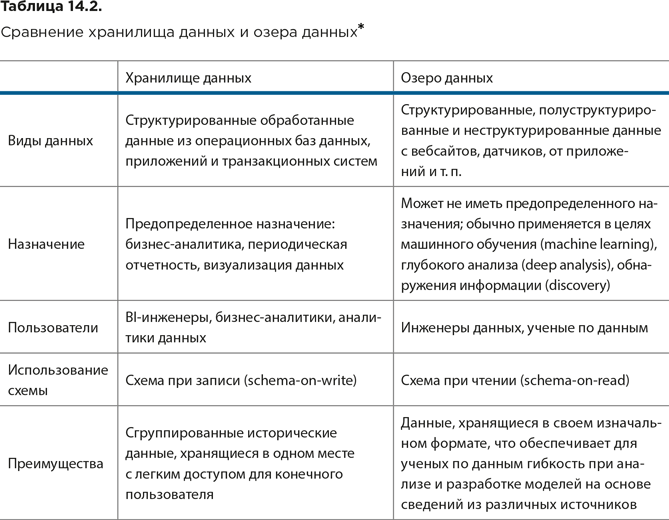
DW и озеро данных имеют схожую основную функцию (хранение данных для анализа), но различаются по своему назначению, структуре, видам хранящихся данных, а также их источникам и пользователям (см. табл. 14.2).
В DW собираются данные из бизнес-приложений для использования с конкретными целями. Перед хранением они должны быть очищены и упорядочены. При записи данные структурируют по предопределенной схеме (schema-on-write), что облегчает в дальнейшем доступ у ним.
Поскольку сведения, хранящиеся в DW, уже обработаны, их легче использовать для высокоуровневого анализа. Инструменты BI могут с ними легко оперировать, что упрощает использование хранилищ специалистами, не являющимися профессионалами в области работы с данными.
* Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Озеро данных – это обширное хранилище, в котором собираются необработанные данные в изначальном собственном формате. Одно из преимуществ озера данных – то, что оно может хранить данные различной структуры. Каждый сохраненный элемент данных помечен уникальным идентификатором и снабжен метаданными, чтобы при необходимости его можно было легко запросить. Данные в озере хранятся без предопределенной схемы – аналитики структурируют их только в момент чтения для конкретной задачи (schema-on-read). При построении озер данных целесообразно следовать существующим на сегодня передовым практикам.
Сравнительная характеристика хранилища данных и озера данных представлена в таблице 14.2.
Для наполнения хранилища применяются процессы ETL или ELT, тогда как для озера данных – преимущественно ELT или потоковая обработка данных (стриминг).
* Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Если говорить о построении современной платформы данных, то в настоящее время известно несколько перспективных архитектурных концепций. В частности, выделяются подходы Modern Data Architecture, Lambda Architecture и Data Mesh Architecture.
Modern Data Architecture объединяет преимущества DW и озера данных. При этом следует заметить, что у Modern Data Architecture отсутствует четкий дизайн с точки зрения внедрения тех или иных решений. Концепция реализации во многом зависит от видения главного инженера проекта.
Lambda Architecture – решение, построенное в том числе на концепции озера данных, которое позволяет решать задачи, связанные с обработкой в режиме реального времени, обрабатывая данные за миллисекунды.
Data Mesh Architecture активно использует стриминг-технологии, объединяет пакетную и потоковую обработки данных, а хранит данные в облаке. Благодаря этому у организаций появляется возможность анализировать данные в режиме реального времени, снизив при этом затраты на управление инфраструктурой хранилища.
Два последних слоя на рисунке 14.10 выделены для обозначения деятельности в области науки о данных (ее осуществляют ученые по данным и инженеры машинного обучения) и деятельности в области BI (ей занимаются BI-инженеры).
В таблице 14.3 описаны основные роли специалистов, работающих с аналитической средой организации.
Деятельность в рамках слоев обработки и хранения данных обычно осуществляется инженером данных. Коротко рассмотрим ее на примере операций, выполняемых в ходе процесса ETL.
Извлечение данных
На этом этапе данные извлекаются из одного или нескольких источников и подготавливаются к преобразованию. Отметим, что для корректного представления данных после их загрузки в хранилище из источников должны извлекаться не только сами данные, но и информация, описывающая их структуру, из которой будут сформированы метаданные для хранилища,
Преобразование данных
Чаще всего преобразование включает следующие шаги:
● Преобразование структуры данных
Данные из различных источников могут отличаться своей структурной организацией: соглашениями о назначении имен полей и таблиц, порядком их описания, форматами, типами и кодировкой данных. Перед передачей в хранилище их нужно свести к единой структуре.
● Агрегирование данных
Наибольший интерес для анализа представляют данные, обобщенные по некоторому интервалу времени, по группе клиентов или товаров. Такие обобщенные данные называются агрегированными (иногда агрегатами), а сам процесс их вычисления – агрегированием.
● Перевод значений
Часто данные в источниках хранятся с использованием специальных кодировок, которые позволяют сократить избыточность данных и тем самым уменьшить объем памяти, требуемой для их хранения. Так, наименования объектов, их свойств и признаков могут храниться в сокращенном виде. В этом случае перед загрузкой данных в хранилище требуется выполнить перевод сокращенных значений в более полные и понятные.
● Создание новых данных
В процессе загрузки в хранилище может понадобиться вычисление некоторых новых данных на основе существующих, что обычно сопровождается созданием новых полей.
● Очистка данных
Наличие «грязных» данных – одна из важнейших и трудно формализуемых проблем аналитических технологий. Очистка данных – это процедура корректировки данных, которые в каком-либо смысле не удовлетворяют определенным критериям качества, т. е. содержат нарушения структуры данных, противоречия, пропуски, дубликаты или неправильные форматы.
Загрузка данных
Процесс загрузки заключается в переносе данных из промежуточных таблиц в структуры хранилища данных. От продуманности и оптимальности процесса загрузки данных во многом зависит время, требуемое для полного цикла обновления данных в хранилище, а также их полнота и корректность.
Следует заметить, что описанный здесь спектр операций, выполняемых на этапе преобразования данных, часто расширяется. Особенно при работе с большими объемами быстро поступающих данных, когда процесс ETL заменяется на ELT (сначала данные извлекаются и загружаются в конечную систему, и лишь после этого происходит их преобразование).
В частности, в ходе преобразования может возникнуть необходимость в группировке или разгруппировке данных (объединение или разъединение данных по какому-либо признаку), нормализации (преобразование диапазона изменений числового признака в другой, более удобный для применения в процессе анализа) и квантовании (разбиение диапазона возможных значений числового признака на заданное количество интервалов и присвоение попавшим в них значениям номеров интервалов или иных меток).
14.3.5. Контекстная диаграмма функциональной области «Большие данные и наука о данных» и уровни зрелости работы с большими данными
Контекстная диаграмма функциональной области «Большие данные и наука о данных» представлена на рисунке 14.11. Процесс осуществления деятельности в области науки о данных представляет собой последовательность итераций. Результаты предыдущей итерации служат исходными данными для следующей. Каждая итерация включает следующие работы.
● Определение стратегии и потребностей бизнеса в области изучения больших данных. Формулировка требования к желаемым результатам с указанием измеримых материальных выгод от их выполнения.
● Выбор источников данных. Идентификация пробелов в имеющейся базе информационных ресурсов и поиск источников данных, которые позволят заполнить эти пробелы.
● Получение и освоение источников данных. Получение всех необходимых наборов данных или доступа к их источникам с целью загрузки.
● Проработка гипотез и методов их проверки средствами науки о данных. Исследование источников данных с помощью средств профилирования, визуализации, статистического анализа с целью уточнения требований. Определение алгоритма модели и необходимых типов входных и выходных данных или моделирование нескольких альтернативных гипотез и методов анализа (например, сравнительный анализ группировок данных, выявленных посредством кластеризации, и т. п.).
● Интеграция и согласование данных для анализа. Годность модели зависит еще и от качества источников данных. Следует использовать данные из надежных и достоверных источников. При необходимости, c целью повышения качества и полезности вводимых наборов, нужно применять средства интеграции, очистки и доработки данных.
● Исследование данных с использованием моделей. Использование средств статистического анализа и алгоритмов машинного обучения для выявления закономерностей на основе интегрированных данных. Регулярная проверка валидности модели и при необходимости внесение корректив в параметры модели и настройки алгоритмов самообучения. По мере накопления статистики – доработка самой модели. Машинное обучение подразумевает многократные прогоны через модель больших массивов реальных данных с целью проверки гипотез и внесения корректив в настройки алгоритмов (например, выявления выпадающих из общего статистического ряда значений). Также в процессе такой проработки окончательно уточняются требования. Эволюция модели выверяется по изначально определенным метрикам пригодности или реалистичности результатов. С появлением новых гипотез могут потребоваться дополнительные наборы данных, а по результатам их проверки – новые модели, выходные данные и даже требования.
● Внедрение и мониторинг. Модели, которые выдают полезную информацию, можно переносить в производственную среду и использовать для текущего мониторинга ситуации с целью получения данных или, напротив, появления нежелательных тенденций, ставящих под угрозу эффективность текущей бизнес-модели. На этой стадии проекты по изучению данных превращаются в обычные рабочие проекты DW/BI и в среде DW обрастают всеми необходимыми техническими доработками и компонентами (процедурами ETL, правилами качества, основными данными).
На рисунке 14.12 приведены обобщенные характеристики уровней зрелости в соответствии с моделью зрелости использования цифровых технологий работы с большими данными в организации для достижения социальных и экономических эффектов (модель BD4DE-MM). Модель построена с учетом концептуальных положений методологии DECA для оценки развития цифровой экономики.
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
Модель BD4DE-MM предусматривает семь областей оценки зрелости, которые называются размерностями (dimensions) или ключевыми факторами успеха (key success factors):
1. Стратегия и регулирование.
2. Кадры и лидерство.
3. Данные.
4. Инструменты и аналитика.
5. Инфраструктура и безопасность.
6. Организация работы.
7. Воздействие.

* Ершов П. С., Катин А. В., Хохлов Ю. Е., Шапошник С. Б. Модель BD4DE-MM зрелости работы с большими данными в организации // Информационное общество. 2021, 4–5: 259–277. – URL: .
Для каждой из размерностей предусмотрен набор индикаторов оценки (assessment indicators). Например, для размерности «Стратегия и регулирование» в модель включены следующие индикаторы:
1. Наличие в организации стратегии работы с большими данными.
2. Соответствие стратегии работы с большими данными положениям стратегии развития организации.
3. Наличие в организации плана реализации стратегии работы с большими данными.
4. Наличие в организации необходимых ресурсов (например, кадровых или финансовых) для реализации стратегии работы с большими данными.
5. Наличие в стратегии работы с большими данными мероприятий, ориентированных на эксперименты с перспективными технологиями.
6. Соответствие деятельности организации требованиям нормативного правового регулирования работы с большими данными.
7. Соответствие деятельности организации международным стандартам работы с большими данными.
8. Соответствие деятельности организации принципам саморегулирования работы с большими данными.
14.3.6. Влияние на ценность данных
Согласно второму «закону» информации ее ценность возрастает с увеличением использования (см. главу 5). Таким образом, ценность данных не ограничивается одним конкретным случаем использования, их можно употребить многократно как с одной и той же целью, так и с разными. Применительно к большим данным особенно важен второй вариант.
В конечном счете ценность данных заключается в том, что можно получить от их всестороннего использования. Различные возможности использования служат альтернативами. Ценность данных определяется суммой таких вариантов – можно назвать это «альтернативной ценностью» данных. Раньше, после использования данных по основному назначению, было принято считать, что они свою миссию уже выполнили и их можно удалить. С появлением больших данных ситуация изменилась: данные обеспечивают отдачу еще долго после того, как их номинальная ценность уже извлечена. Можно выделить четыре эффективных способа раскрыть альтернативную ценность данных.
Простое повторное использование
Некоторые организации накапливают огромное количество данных, даже если не имеют в этом существенной необходимости или не практикуют их повторное использование. Так, например, операторы мобильной связи собирают информацию о местоположении своих абонентов, чтобы маршрутизировать их вызовы. Эти компании видят лишь узкое техническое назначение таких данных. Но их ценность значительно повышается при повторном использовании компаниями, которые распространяют персонализированную рекламу на основе местоположения.
Слияние наборов данных (искусственно созданные данные)
Согласно пятому «закону» информации ее ценность повышается при объединении с другой информацией (см. главу 5). Иногда скрытую ценность можно раскрыть, только объединив один набор данных с другим, возможно, совершенно непохожим. При анализе больших данных совокупность важнее отдельных частей, а при перекомпоновке совокупностей нескольких наборов данных получается еще более удачная совокупность.
Поиск массивов данных «2 в 1» (расширяемые данные)
Некоторые фирмы розничной продажи устанавливают в магазинах камеры наблюдения таким образом, чтобы не только обнаруживать злоумышленников, но и отслеживать передвижение клиентов по магазину и места, где они останавливаются, чтобы присмотреться. Такая информация полезна для разработки лучшей выкладки товаров в магазине, а также для оценки эффективности маркетинговых кампаний. Ранее камеры видеонаблюдения служили только для обеспечения безопасности и рассматривались не более чем статьей расходов. Теперь они рассматриваются как инвестиции, которые могут увеличить доход.
Дополнительные расходы на сбор нескольких потоков данных или намного большего числа точек данных в каждом потоке, как правило, невелики, поэтому имеет смысл собирать как можно больше данных, а также делать их расширяемыми, изначально рассматривая потенциальные варианты вторичного использования. Благодаря этому увеличивается альтернативная ценность информации. Суть в том, чтобы искать наборы «2 в 1», когда один и тот же массив данных, собранных определенным образом, можно применять в различных целях. Так эти сведения приобретают двойное назначение.
Учет амортизации ценности данных
Согласно третьему закону информации ее пригодность со временем снижается (см. главу 5). Информация с течением времени теряет часть своей первичной полезности. В таких условиях дальнейшее использование старых данных может не только не добавить ценности, но и фактически нивелировать пользу более новых данных. Разработка и применение моделей, которые позволяют выявить бесполезные сведения, чтобы своевременно их удалить, помогает повысить ценность имеющихся в распоряжении организации данных.
ПРАКТИЧЕСКИЙ ПРИМЕРВ рамках расширения задач по обеспечению доступности и обслуживанию данных «Телеком Дубль»:● совершенствует архитектуру хранилищ данных;● внедряет единую систему управления корпоративным контентом;● развивает аналитическую среду компании, проводя работы по внедрению и развитию озера данных.Большая работа проделана по оптимизации хранения профиля клиента. Та его часть, которая нужна онлайн (так называемый операционный профиль), перенесена на ИТ-инфраструктуру, которая держит высокие нагрузки по количеству выполняемых операций в секунду. Остальная часть остается в хранилище данных (аналитический профиль), где данные обновляются и пересчитываются в офлайне.Важный аспект любого бизнеса – соответствие законам и нормативным актам, принятым в государстве, где юридическое лицо осуществляет свою деятельность. Документы компании описывают весь юридический процесс совершаемых операций – от транзакций по оплате пользования сервисами до работы с учредительными документами, – определяющих функционирование всех подразделений. Ведя централизованное управление документами и контентом, «Телеком Дубль» существенно повысила свою прозрачность.Постепенно добавляя в описанный процесс все больше звеньев и детализируя его, мы можем проследить, каким образом каждый сотрудник влияет на достижение целей и задач компании. Это позволяет ему понять и визуально отследить собственный вклад в развитие бизнеса, а значит, дает возможность руководству ставить цели перед департаментами и отделами с любым уровнем детализации.
Литература к главе 14
• ГОСТ Р ИСО 15489-1-2019. Система стандартов по информации, библиотечному и издательскому делу. Информация и документация. Управление документами. Часть 1. Понятия и принципы.
• ГОСТ Р ИСО/МЭК 20546-2021. Информационные технологии. Большие данные. Обзор и словарь.
• Барсегян А. А., Куприянов М. С., Холод И. И., Тесс М. Д., Елизаров С. И. Анализ данных и процессов: Учеб. пособие. 3-е изд., перераб. и доп. – СПб.: БХВ-Петербург, 2009.
• Силен Д., Мейсман А., Али М. Основы Data Science и Big Data. Python и наука о данных. – СПб.: Питер, 2018.
• Хохлов Ю. Е. Национальная политика работы с данными в Российской Федерации. Международные и национальные стандарты в сфере данных. Институт развития информационного общества, 2021. – URL: .
• Bentley D. Business Intelligence and Analytics. Library Press, 2017.
• . Представлены 36 проектов национальных стандартов в области ИИ // , 2021. – URL:
• Inmon W., Imhoff С., Sousa, R. Corporate Information Factory: 2nd Edition. Wiley Publishing, Inc., 2001.
• Loshin D. Business Intelligence: The Savvy Manager’s Guide: 2nd Edition. Morgan Kaufmann, 2012.
• Loshin D. Big Data Analytics: From Strategic Planning to Enterprise Integration with Tools, Techniques, NoSQL, and Graph: 1st Edition. Morgan Kaufmann, 2013.
• Sebastian-Coleman L. Navigating the Labyrinth: An Executive Guide to Data Management, First Edition. Technics Publications, 2018.
• Van Gils B. Data Management: a Gentle Introduction: Balancing Theory and Practice. Van Haren Publishing, 2020.
• Управление данными в госсекторе. Навигатор для начинающих / под ред. О. М. Гиацинтова, В. А. Сазонова, М. С. Шклярук. – М.: РАНХиГС, 2022.
Назад: Глава 13. Управление основными данными: практика внедрения
Дальше: Глава 15. Базовая поддержка жизненного цикла данных

