Книга: Ценность ваших данных
Назад: Глава 11. Планирование и проектирование данных
Дальше: Глава 13. Управление основными данными: практика внедрения
Глава 12. Обеспечение доступности и обслуживание данных: основы
В этой главе (и двух следующих) будет рассмотрена очень важная и довольно многочисленная группа областей знаний (функций) по управлению данными. Эти области (как и описанные в предыдущей главе области архитектуры и моделирования данных), относятся к непосредственному управлению жизненным циклом данных. Они отвечают за укрупненную фазу жизненного цикла, идущую вслед за фазой планирования и проектирования – обеспечение доступности и обслуживание данных (см. рис. 9.4). В рассматриваемую группу входят:
● хранение и операции с данными;
● интеграция и интероперабельность данных;
● управление справочными и основными данными;
● ведение хранилищ данных;
● хранение больших данных;
● управление документами и контентом.
В главе 7 мы сравнивали процессы цепочки поставок данных с процессами цепи поставок продукции (SCOR-моделью). Если взглянуть на перечисленные области в этом контексте, то их можно cоотнести со следующими процессами:
● снабжать,
● делать,
● доставлять,
● возвращать.
В упрощенной модели цепочки поставок данных, предлагаемой Дагласом Лейни (см. рис. 7.3), представленные области распространяются преимущественно на этапы сбора и администрирования.
Данная глава посвящена первым трем функциональным компонентам из рассматриваемой группы. Они закладывают основу для обеспечения доступности и обслуживания данных.
12.1. Хранение и операции с данными
В качестве первого звена в цепочках ценности или поставок всегда выступают процессы сбора (см. главу 7). Однако перед тем как ввести их в действие, необходимо решить вопросы организации хранения и обслуживания собираемых материальных ресурсов или данных. Хранение и выполнение операций с данными – это то, что прежде всего представляют себе многие люди, когда слышат об управлении данными. Именно с функций хранения и администрирования началось развитие этой дисциплины (см. табл. 8.1).
12.1.1. Определение области знаний «Хранение и операции с данными»
Область «Хранение и операции с данными» включает проектирование и реализацию решений для хранения, а также сопровождение хранимых данных с целью получения от них максимальной выгоды на протяжении всего их жизненного цикла. Работы в этой области ведутся по двум основным направлениям.
● Сопровождение баз данных. Объединяет работы, относящиеся к жизненному циклу данных, включая первоначальную реализацию рабочей среды базы данных (database environment), получение данных, а также их резервное копирование и удаление. Сюда же относится обеспечение оптимальной производительности (мониторинг и настройка – критически важные элементы сопровождения).
● Технологическая поддержка баз данных включает определение технических требований, соответствующих информационным потребностям организации, определение технической архитектуры, развертывание и администрирование технологических решений, а также разрешение проблемных вопросов, связанных с технологиями.
12.1.2. Цели и бизнес-драйверы
Цели хранения и операций с данными включают:
● управление доступностью данных на протяжении всего их жизненного цикла;
● обеспечение целостности информационных активов;
● управление эффективностью проведения информационных транзакций.
В процессе операционной деятельности организации постоянно используют собственные информационные системы. С учетом этого обстоятельства хранение и операции с данными являются жизненно важными аспектами деятельности организаций. Таким образом, обеспечение непрерывности бизнеса – главный драйвер усилий в рассматриваемой области управления данными. Если база данных оказывается недоступной, текущая операционная деятельность организации осуществляется с задержками или останавливается. Надежная инфраструктура хранения данных, обеспечивающая проведение операций, позволяет свести к минимуму риск подобных сбоев.
12.1.3. Архитектуры и модели организации баз данных
С архитектурной точки зрения базы данных подразделяются на два типа: централизованные и распределенные. Централизованная система управления базами данных (СУБД) управляет базами данных, которые реализованы в одном месте, в то время как распределенная система управляет множеством баз данных, реализованных во множестве систем.
Распределенные системы можно разделить на два класса по степени автономности входящих в них компонентов: федеративные (автономные компоненты) и не федеративные (неавтономные компоненты).
Архитектуры федеративных систем баз данных различаются в зависимости от уровней интеграции с локальными базами данных и объема предлагаемых услуг. В целом федеративные СУБД можно разделить на слабо связанные и сильно связанные.
В настоящее время широкое распространение получила виртуализация (также называемая облачными вычислениями, cloud computing), которая позволяет оказывать услуги по проведению вычислений, использованию программного обеспечения, предоставлению доступа к данным и их хранению таким образом, что конечному пользователю не требуются знания о физическом местонахождении и конфигурации систем, обеспечивающих предоставление этих услуг.
Ниже кратко описаны некоторые методы реализации баз данных в облаке.
● Образ виртуальной машины. Облачные платформы предоставляют пользователям возможность арендовать экземпляры виртуальных машин и использовать их для работы со своими базами данных. Пользователи могут либо загружать на них собственные образы машины с развернутой базой данных, либо использовать предлагаемые провайдерами готовые образы машин с предустановленными и настроенными СУБД.
● База данных как услуга. Некоторые облачные платформы предлагают возможность использования базы данных как услуги (Database-as-a-Service, DaaS) без запуска экземпляра виртуальной машины. В такой конфигурации владельцы приложения вовсе избавлены от необходимости устанавливать и поддерживать базу данных. Провайдер услуги DaaS сам устанавливает и поддерживает базу данных, а владельцы приложения пользуются ею за абонентскую плату.
● Управляемый облачный хостинг базы данных. При таком варианте база данных не предлагается в качестве услуги; вместо этого провайдер облачного сервиса размещает ее у себя в облаке и осуществляет управление базой данных по поручению и в интересах собственника приложения.
Что касается моделей организации баз данных, то в предыдущей главе мы уже отмечали, что наиболее распространенными из них являются: реляционная, многомерная, объектно-ориентированная, на основе фактов, хронологическая и NoSQL.
12.1.4. Администраторы баз данных
Ключевую роль в каждом из направлений деятельности в области хранения и операций с данными играют администраторы баз данных (АБД). АБД – наиболее устоявшаяся и общепринятая профессиональная роль в сфере управления данными.
Наряду с АБД в некоторых организациях предусмотрены роли администраторов сетевых систем хранения данных, которые специализируются на сопровождении сетевых хранилищ, рассматриваемых отдельно от остальных приложений или структур, обеспечивающих хранение данных.
Функция хранения и выполнения операций с данными – это технически сложная работа, выполняемая АБД и администраторами сетевых систем хранения для обеспечения доступности и высокой производительности баз данных, а также сохранения их целостности.
Администрирование баз данных иногда рассматривается как единая монолитная функция, но АБД выступают в разных ролях. Они могут сопровождать среды эксплуатации баз данных, выполнять работы по разработке или поддерживать конкретные приложения и процедуры. На профиль работы администратора баз данных влияет общая архитектура баз данных организации (централизованная, распределенная, федеративная; слабо или сильно связанная), а также то, какие модели в них применены (реляционная, объектно-ориентированная, NoSQL и т. п.). С появлением новых технологий АБД и администраторы сетевых систем хранения стали отвечать за создание виртуальных сред и управление ими (облачные вычисления). Поскольку среды хранения данных довольно сложны, администраторы баз данных ищут способы уменьшить сложность или, по крайней мере, управлять ею за счет автоматизации, возможностей повторного использования и применения стандартов и передовых практик.
Хотя может показаться, что администраторы баз данных не связаны с функцией руководства данными, их знания технической среды необходимы для реализации руководящих установок в отношении данных, связанных с такими аспектами, как контроль доступа или конфиденциальность и безопасность данных. Опытные администраторы баз данных также играют важную роль в расширении возможностей организации по внедрению и использованию новых технологий,.
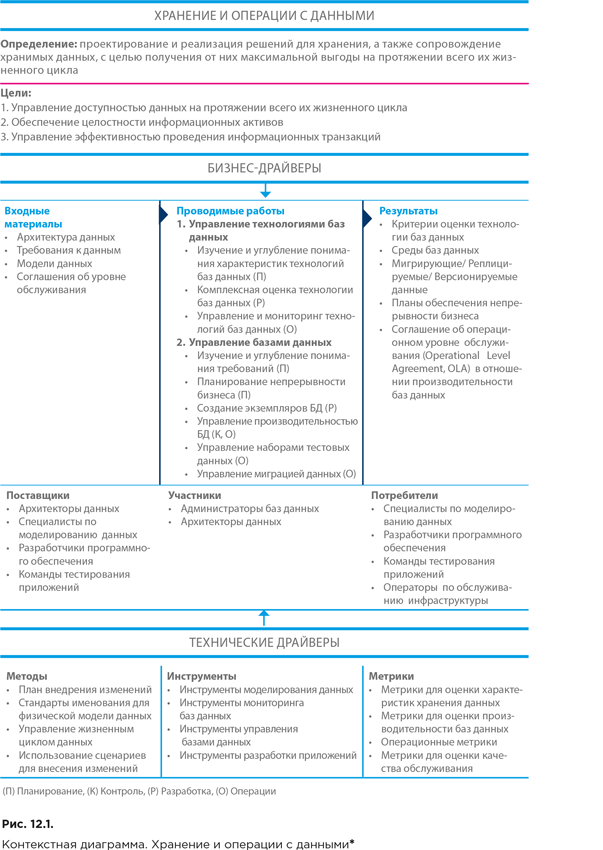
12.1.5. Контекстная диаграмма области знаний и уровни зрелости функции «Хранение и операции с данными»
Контекстная диаграмма области знаний «Хранение и операции с данными» представлена на рисунке 12.1.
АБД совместно с архитекторами данных вносят вклад в обеспечение доступности и обслуживание данных, работая по следующим направлениям:
● определение требований к хранению данных;
● определение требований к доступу к данным;
● разработка конкретных реализаций(экземпляров) баз данных;
● управление физической средой хранения;
● загрузка данных;
● репликация данных – ведение дублирующих друг друга баз данных (реплик);
● отслеживание шаблонов использования (типичных схем распределения нагрузки на базы данных);
● планирование обеспечения непрерывности бизнеса;
● управление резервным копированием и восстановлением;
● управление производительностью и доступностью баз данных;
● управление альтернативными средами баз данных (например, для разработки и тестирования);
● управление миграцией данных (переносом из одних хранилищ в другие);
● отслеживание и учет информационных активов;
● аудит и проверка корректности данных.
На рисунке 12.2 представлены обобщенные характеристики уровней зрелости функции «Хранение и операции с данными».
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)

* Smith P.; Edge J.; Parry S.; Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
12.1.6. Влияние на ценность данных
Непрерывность информационного обслуживания – важнейший фактор, позволяющий организации достигать своих целей и поддерживать удовлетворенность заинтересованных сторон. Основательный и продуманный подход к сопровождению и технологической поддержке баз данных, включая планирование мероприятий по обеспечению непрерывности бизнеса в случае аварий или чрезвычайных ситуаций, позволяет избежать сбоев в обслуживании (либо в результате превышения объема данных над имеющейся емкостью хранилищ, либо в результате катастрофического инцидента).
Переход к виртуализированным средствам хранения и обработки данных обеспечивает целый ряд вполне ощутимых преимуществ.
● Возможность достижения значительной экономии средств, поскольку использованием баз данных можно управлять более эффективно, а сопровождение осуществляется более централизованно.
● Подготовка к аварийному восстановлению упрощается, когда все информационные ресурсы, подлежащие включению в резервную копию, находятся в одном месте.
● По аналогичным соображениям упрощается создание многоуровневой архитектуры интеграции с предоставлением централизованных информационных сервисов (более подробно см. в разделе 12.2).
● С точки зрения руководства данными централизация обеспечивает более эффективный мониторинг безопасности, производительности и соответствия нормативно-правовым требованиям.
12.2. Интеграция и интероперабельность данных
На рисунке 9.4, который, как было замечено, по сути дела, отражает модель управления цепочками поставок данных, отсутствует специально выделенная функциональная область, отвечающая за их сбор. Однако это не означает, что вопросы сбора данных оставлены без внимания. Просто они распределены между различными функциональными элементами представленной схемы. Одну из главных ролей в обеспечении сбора данных играет функция обеспечения интеграции и интероперабельности.
12.2.1. Определение области знаний «Интеграция и интероперабельность данных»
Интеграция и интероперабельность данных (Data Integration and Interoperability, DII) – область, которая описывает процессы, связанные с перемещением и консолидацией данных как внутри хранилищ, приложений и организаций, так и в рамках обеспечения их взаимодействия.
Интеграция позволяет объединять данные в согласованные физические или виртуальные формы. Под интероперабельностью данных подразумевается способность двух или более информационных систем или компонентов к обмену и использованию информации, полученной в результате обмена,.
12.2.2. Цели и бизнес-драйверы
Внедрение практик и решений в области интеграции и интероперабельности данных преследует следующие цели:
● своевременное предоставление требуемых данных потребителям (как пользователям, так и приложениям) в нужном им формате;
● физическая или виртуальная консолидация данных в хабах (концентраторах);
● снижение стоимости и сложности решений по управлению данными за счет разработки общих моделей и интерфейсов;
● выявление значимых событий (возможностей и угроз) и автоматический запуск процедур выдачи уведомлений и принятия мер;
● поддержка функций BI, аналитики, управления основными данными и обеспечение операционной эффективности.
Основной драйвер деятельности в области интеграции и интероперабельности данных – потребность в управлении перемещением данных.
Поскольку в большинстве организаций имеются сотни, а то и тысячи всевозможных баз и хранилищ данных, управление процессами перемещения данных между местами хранения внутри организации и обмена данными с другими организациями становится одной из главных сфер ответственности любой ИТ-службы. Без надлежащего управления процесс перемещения данных быстро исчерпает все их ресурсы и возможности, лишив при этом необходимой поддержки традиционные приложения и области управления данными.
Повсеместный переход организаций на использование покупного прикладного ПО вместо разработки собственного усилил потребность в обеспечении интеграции и интероперабельности на корпоративном уровне. Каждое коммерческое приложение добавляет собственный набор хранилищ основных, транзакционных и отчетных данных. Все их приходится интегрировать с другими хранилищами данных, уже имеющимися в организации. Даже системы планирования ресурсов предприятия (ERP), обеспечивающие выполнение общих функций организации, практически никогда не охватывают всех необходимых хранилищ данных. Они также должны интегрировать свои данные с другими данными организации.
Еще один важнейший бизнес-драйвер интеграции – управление затратами на поддержку. Перемещение данных с использованием множества технологий, каждая из которых требует специфических навыков разработки и обслуживания, способно привести к непомерному росту стоимости поддержки. Внедрение стандартных инструментов позволяет сократить потребности в обслуживании и персонале, а также повысить эффективность поиска и устранения неполадок, что дает возможность перераспределить ресурсы сопровождения на решение других приоритетных задач организации.
Проведение работ в области интеграции и интероперабельности данных также помогает организации соблюдать действующие стандарты и регламенты обработки данных. Интеграционные системы корпоративного уровня позволяют повторно использовать коды, обеспечивающие соответствие требованиям нормативных документов, и упрощают проверку их соблюдения.
12.2.3. Основные аспекты обеспечения интеграции и интероперабельности данных
При создании решений в области интеграции и интероперабельности данных важно уделять внимание следующим аспектам,.
Корпоративный подход
При проектировании интеграционных решений следует придерживаться корпоративного (в масштабах всей организации) подхода, обеспечивающего возможность последующего расширения и масштабирования, но реализацию проводить итерационно, методом пошагового ввода новых решений в эксплуатацию. Центральное место в таком подходе занимает идея минимизации дублирования уже затраченных на интеграцию усилий.
Важным инструментом в реализации корпоративного подхода являются корпоративные сервисные шины (Enterprise Service Buses, ESB) – интеграционные решения, обеспечивающие синхронизацию данных в режиме, близком к реальному времени, между многими системами. Такие решения используют понятие хаба данных, предоставляющего каноническую модель для совместного использования данных организацией.
Каноническая модель данных – общая модель (используемая организацией или группой, отвечающей за обмен данными), стандартизирующая формат, в котором осуществляется распространение данных. Использование канонической модели ограничивает количество преобразований данных при обмене между системами или организациями. Каждой системе достаточно реализовать преобразование данных только в каноническую модель (при передаче) или из нее (при приеме), вместо того чтобы разрабатывать отдельные средства преобразования для множества систем, с которыми осуществляется обмен. В средах, где обмениваются данными более ста прикладных систем, интеграционное решение на основе канонической модели – единственно возможное.
ESB – пример реализации подхода к построению интеграционных решений, основанного на слабом связывании. Она действует как сервис обмена данными между приложениями. При таком подходе получение ответов на запросы, обращенные к другой системе, не является обязательным условием продолжения работы первой системы, т. е. доступность каждой из слабо связанных систем не зависит от доступности другой системы. Слабое связывание может быть реализовано с использованием различных средств: например, посредством сервисов, интерфейсов прикладного программирования (API) или очередей сообщений.
Исследование данных
Исследование данных необходимо проводить перед проектированием интеграционных решений. Цель исследования – определение потенциальных источников данных, которые могут быть использованы при выполнении работ по интеграции. Оно должно выявить, где данные могут быть получены и где они должны интегрироваться.
В крупных организациях существуют сотни, если не тысячи, источников данных, которые могут быть полезны для различных подразделений. Во многих случаях эти источники предоставляют одни и те же данные, но каждый из них доступен только в рамках отдельных проектов.
Сервис-ориентированная архитектура
Наиболее зрелые корпоративные стратегии интеграции приложений используют концепцию сервис-ориентированной архитектуры (SOA), в которой функциональность по предоставлению или обновлению данных может быть представлена в виде точно определенных вызовов сервисов, используемых приложениями в процессе их взаимодействия. При таком подходе приложениям не нужно взаимодействовать друг с другом напрямую или знать что-либо о внутренней структуре и работе других приложений. SOA обеспечивает независимость приложений и возможность замены той или иной системы в организации без необходимости внесения существенных изменений в системы, которые с ней взаимодействуют.
Цель сервис-ориентированной архитектуры – организация строго определенного взаимодействия между отдельными независимыми программными модулями. Каждый модуль выполняет функции (часто говорят «предоставляет сервисы») в интересах других программных модулей или людей. Ключевой концептуальный момент SOA – предоставляемые сервисы независимы: сервис и приложение ничего не знают друг о друге. Сервис-ориентированная архитектура может быть реализована с помощью различных технологий, включая веб-сервисы и обмен сообщениями.
Сами сервисы обычно реализуются как API, доступные для вызова прикладным системам или пользователям (потребителям). Регистрационная запись точно определенного API описывает доступные опции, необходимые параметры запроса и выдаваемую в ответ на обращение информацию.
Примерами наиболее часто применяемых стандартов реализации являются:
● SOAP: простой протокол доступа к объектам (Simple Object Access Protocol) – протокол обмена структурированными сообщениями в распределенной вычислительной среде;
● RESTful API: набор архитектурных принципов построения сервис-ориентированных приложений. REST – сокр. от англ. Representational State Transfer (передача состояния представления). RESTful – прилагательное, употребляющееся по отношению к сервисам, которые соответствуют принципам REST;
● JMS: служба сообщений Java (Java Message Service) – стандарт обмена сообщениями между приложениями, выполненными на платформе Java;
● RMI: удаленный вызов методов (Remote Method Invocation) – программный интерфейс для вызова удаленных процедур на языке Java.
Модель публикации и подписки
Модель публикации и подписки (publish and subscribe) предусматривает наличие систем, поставляющих данные («издателей»), и систем, получающих эти данные («подписчиков»). Системы, поставляющие данные, вносятся в каталог сервисов данных, а системы, которым эти данные требуются, должны подписываться на услуги провайдера. После публикации данные автоматически рассылаются подписчикам.
При наличии множества потребителей одних и тех же наборов данных или данных в одном и том же формате подготовка этих данных в централизованном порядке (с последующим открытием доступа к ним) позволяет обеспечивать использование потребителями согласованных наборов данных и их регулярное своевременное обновление.
Модель публикации и подписки идеально подходит для распространения данных среди всех заинтересованных сторон.
Извлечение, преобразование и загрузка
В основе любых решений в области интеграции и интероперабельности данных лежит процесс извлечения, преобразования и загрузки (Extract, Transform, Load; ETL). Вне зависимости от того, выполняются они физически или виртуально, в пакетном режиме или режиме реального времени, эти шаги непременно присутствуют при перемещении данных между приложениями и организациями.
Процесс преобразования переводит выбранные данные в структуру, совместимую с целевым хранилищем. Часто бывает так, что при этом нужно объединить фрагменты данных вместе (агрегирование) или, возможно, выполнить операции с данными, или провести вычисления, чтобы предоставить дополнительную информацию (обогащение). Границы между преобразованием, агрегированием и обогащением провести непросто, но все эти действия представляют собой добавление некоторой ценности к исходным данным. Это позволяет представлять потребителям данные в более полезной форме.
Задержка при обработке
В зависимости от требований по интеграции данных процедуры ETL могут выполняться в режиме периодической пакетной обработки или обработки по мере доступности новых или обновленных данных (в режиме реального времени или управляемой на основе событий – event driven). Обработка данных о текущих операциях обычно проводится в режиме реального времени или в режиме, близком к реальному времени (near real-time), а данных, требуемых для анализа и отчетности, – по графику, в пакетном режиме.
Обычное явление сегодня – потоковая обработка данных. Потоковые данные (streaming data) «вытекают» из компьютерных систем в непрерывном режиме по ходу событий (фиксируется такая информация, как сведения о покупках товаров или ценных бумаг, комментарии в социальных сетях или показания датчиков, отслеживающих различные характеристики). Однако реализация потоковой обработки сопряжена с серьезными затратами на аппаратное и программное обеспечение.
Задержка (latency) – это разница во времени между моментом, когда данные были сгенерированы в системе-источнике, и моментом, когда они стали доступны в целевой системе. Различные подходы к обработке данных определяют различную степень задержки.
Задержка может быть высокой (при пакетной обработке), низкой (при запуске процедур переноса на основе событий) или очень низкой (при использовании синхронизации в режиме реального времени или при потоковой обработке).
Оркестровка данных
Потоки данных в интеграционном решении должны быть спроектированы и документально оформлены. Оркестровка данных как раз и представляет собой описание потоков данных от «старта» до «финиша», включая промежуточные шаги, требуемые для выполнения преобразования и транзакции. Можно рассмотреть, например, такой набор действий, которые могут образовывать единую транзакцию: разместить заказ, произвести оплату, запросить доставку, отменить заказ, вернуть платеж, отменить доставку. Оркестровка пакетной интеграции данных должна также предоставлять сведения о частоте перемещения и преобразования данных. Отдельные задачи, c помощью которых реализуется пакетная интеграция, обычно описываются в планировщике, который и запускает их в указанное время, с указанной периодичностью или по наступлении заданного события. Расписание задач может включать множество взаимозависимых шагов.
Оркестровка интеграции данных в режиме реального времени, как правило, предусматривает запуск задач по событию – например, добавлению или обновлению данных. Такая оркестровка обычно сложнее, чем в пакетном режиме, и реализуется посредством применения многих инструментов.
Одна из главных задач оркестровки – обеспечить, чтобы каждое из отдельных действий, выполняемых в рамках потока, в случае какого-либо сбоя было завершено корректно и согласованно, а целостность данных во всех взаимодействующих системах сохранились.
Проверка качества данных
Сервис-ориентированный подход подразумевает внедрение элементов стандартизации, что облегчает деятельность по контролю и повышению качества данных. Это связано с тем, что все данные, проходящие через централизованные сервисы, могут быть проверены на соответствие правилам валидации, что позволяет обнаруживать, обрабатывать и сообщать об имеющихся ошибках.
В результате любые системы, подписанные на услуги по предоставлению данных, будут получать данные, уровень качества которых измерен и известен.
Таким образом, интеграционная архитектура – важный компонент повышения качества данных и может уменьшить необходимость инвестиций в применяемые для этой цели автономные инструменты.
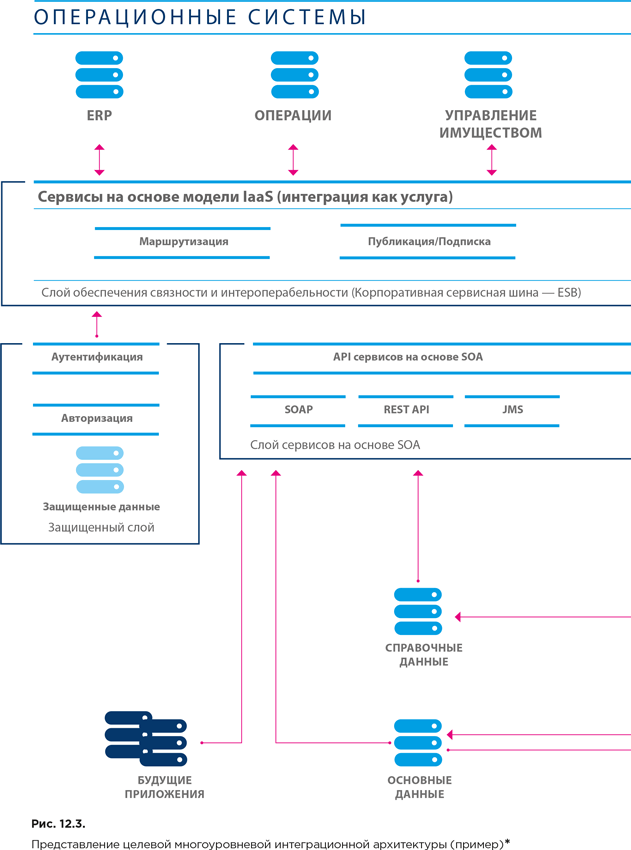
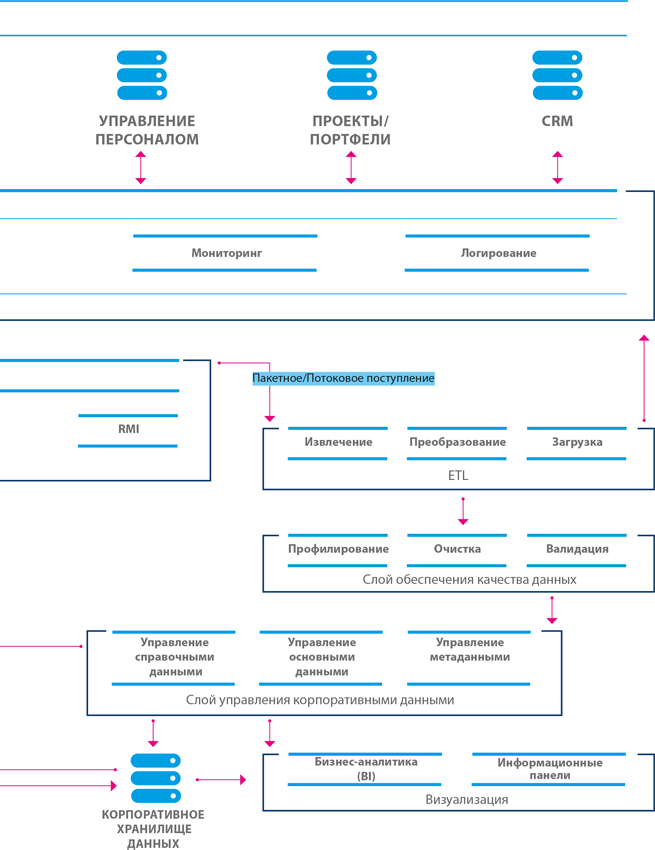
В завершение обсуждения ключевых аспектов функции обеспечения интеграции и интероперабельности данных следует заметить, что она критически важна для ведения хранилищ данных и бизнес-аналитики, а также для управления справочными и основными данными, поскольку обе эти области управления данными сфокусированы на преобразовании и интеграции данных из систем-источников в консолидационных хабах, с последующей передачей консолидированных данных в целевые системы, которые предоставляют их потребителям. На рисунке 12.3 приведен пример представления целевой многоуровневой интеграционной архитектуры, спроектированной с учетом перечисленных выше аспектов.
Диаграммы подобного рода могут быть полезны при объяснении всем заинтересованным сторонам ключевого принципа развития интеграционных решений – устранение связей «точка-точка» за счет реализации более многоуровневой технологии, поддерживаемой ESB.
12.2.4. Контекстная диаграмма области знаний и уровни зрелости функции «Интеграция и интероперабельность данных»
Контекстная диаграмма области знаний «Интеграция и интероперабельность данных» представлена на рисунке 12.4.
Интеграция и интероперабельность данных зависит от других областей управления данными:
● руководство данными – в части определения правил преобразования данных и структуры сообщений;
● архитектура данных – в части разработки архитектуры интеграционных решений;
● безопасность данных – в части обеспечения соответствия интеграционных решений требованиям по безопасности данных, как постоянно хранимых (persistent), так и виртуальных (virtual), а также «данных в движении» (in motion), которые перемещаются между приложениями и организациями;
● метаданные – в части отслеживания такой информации, как техническое описание данных (постоянно хранимых, виртуальных и передаваемых), описание их значения для бизнеса, описание бизнес-правил преобразования данных, а также история операций и сведения о происхождении (lineage) данных;
● хранение и операции с данными – в части физической реализации решений по хранению данных;
● моделирование и проектирование данных – в части проектирования структур данных (постоянно хранимых, виртуальных, а также сообщений, которые перемещаются между приложениями и организациями).
На рисунке 12.5 представлены обобщенные характеристики уровней зрелости функции «Интеграция и интероперабельность данных».


* Smith P.; Edge J.; Parry S.; Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
** DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
*** Smith P.; Edge J.; Parry S.; Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
12.2.5. Влияние на ценность данных
Внедрение современных интеграционных решений привносит дополнительные возможности косвенного влияния на повышение ценности всей совокупности корпоративных данных, в частности:
● Централизованная платформа интеграции обеспечивает ряд преимуществ, которые позволяют повысить операционную жизнеспособность организации за счет ограничения количества точек соприкосновения при передаче данных.
● Расширяются возможности по применению стандартов и более эффективному измерению степени соответствия требованиям руководства данными, поскольку может быть уменьшено количество точек мониторинга.
● Решение может упростить реализацию проектов за счет предоставления стандартных повторно используемых компонентов сервисов данных (которые в свою очередь могут предоставлять средства проверки качества данных).
● Диагностика и устранение проблем осуществляются более эффективно, поскольку в проекте интеграции задействовано меньше компонентов, обеспечивающих обмен данными между системами.
● Определять соглашения об уровне обслуживания и управлять их соблюдением гораздо легче, используя единую точку контроля и измерения.
● Информационный обмен между подразделениями и третьими сторонами упрощается, поскольку все данные проходят через централизованную сервисную платформу.
● Качество данных можно контролировать в процессе передачи напрямую, что облегчает выявление несоответствий в данных, используемых различными подразделениями организации.
12.3. Управление справочными и основными данными
В любой организации имеются совместно используемые данные, без которых трудно себе представить ее нормальную работу: юридические данные, клиентская база, сведения о поставщиках и контрагентах и пр. Пользователи этих данных рассчитывают на их согласованность в пределах организации, т. е. ожидают получить одну и ту же информацию об одном и том же объекте из разных источников. Разночтения и противоречия здесь порождают проблемы: задержки, коллизии, финансовые и имиджевые потери организации.
Подобного рода данные обычно подразделяются на справочные и основные.
Фундаментальную роль справочных и основных данных в информационном обеспечении процессов организации и важность поддержания высокого уровня их качества мы уже отмечали в главе 8.
12.3.1. Определение области знаний «Справочные и основные данные»
Справочные данные (reference data) – это любые данные, используемые для определения характеристик или классификации других данных, или же для соотнесения данных внутри организации с внешней информацией. В основном справочные данные состоят из кодов и их описаний (например, таблицы кодов и определений), но могут иметь и более сложную структуру, в том числе включать отображения и иерархии.
Типичным примером справочных данных являются общероссийские классификаторы технико-экономической и социальной информации. Согласно Федеральному закону от 29.06.2015 № 162-ФЗ «О стандартизации в Российской Федерации» это документы по стандартизации, распределяющие технико-экономическую и социальную информацию в соответствии с ее классификацией (классами, группами, видами и другим) и являющиеся обязательными для применения в государственных информационных системах и при межведомственном обмене информацией в порядке, установленном федеральными законами и иными нормативными правовыми актами Российской Федерации. К ним относятся общероссийские классификаторы валют (ОКВ), единиц измерения (ОКЕИ), стран мира (ОКСМ) и ряд других.
Для основных данных (master data) можно привести определение из ГОСТ Р ИСО 8000-2:2019:
«Основные данные: Данные, находящиеся во владении организации и описывающие объекты, которые являются независимыми и основными для этой организации и на которые нужно ссылаться при составлении транзакций.
Пример – Сообщение с кредитными картами относится к двум объектам, представленным в основных данных. Первый – это учетная кредитная карта счета в банке, идентифицированная номером кредитной карты. Основные данные, относящиеся к этой кредитной карте, включают в себя информацию по счету, требуемую банком-эмитентом. Второй – это коммерческий счет банка-получателя, идентифицированный номером, где основные данные включают в себя информацию об определенном торговце, требуемую банком-получателем.
Примечание 1. Как правило, основные данные описывают заказчиков, служащих, поставщиков, продукцию, пайщиков, услуги, инструменты, оборудование, а также правила и инструкции.
Примечание 2. Каждая организация определяет самостоятельно, какие данные следует считать основными».
Концептуально справочные и основные данные близки по своему назначению: и те и другие нужны для описания контекста транзакций, без которого невозможно создание и использование транзакционных данных (справочные данные при этом еще и определяют контекст для основных данных). Вместе они обеспечивают адекватное понимание данных.
Чтобы снизить издержки и риски, возникающие в результате рассогласования различных элементов справочных и основных данных, этими данными нужно управлять. Вопросы такого управления относятся к специальной области знаний – «Справочные и основные данные».
Важно иметь в виду, что и справочные, и основные данные – ресурсы совместного использования, управление которыми должно вестись исключительно на корпоративном уровне, а не на уровне отдельных систем.
12.3.2. Цели и бизнес-драйверы
Цели управления справочными и основными данными включают:
● обеспечение наличия в организации полных, согласованных, актуальных и достоверных основных и справочных данных по всему спектру процессов;
● обеспечение возможности совместного использования основных и справочных данных в рамках всех функций и приложений организации;
● снижение стоимости и сложности использования и интеграции данных за счет применения стандартов, общих моделей данных и шаблонов интеграции.
Самые распространенные драйверы управления справочными и основными данными:
● Выполнение требований организации к данным. В различных областях работы организации требуются одни и те же наборы данных – и нужна уверенность в их полноте, актуальности и согласованности. Справочные и основные данные часто служат фундаментом при определении таких наборов данных (например, для планомерного и полного учета всех клиентов в аналитических выкладках необходимо четкое и последовательно применяемое определение клиента).
● Управление качеством данных. Противоречивые, некачественные или неполные данные приводят к неверным решениям и упущенным возможностям; управление справочными и основными данными позволяет снизить подобные риски за счет обеспечения полного и согласованного представления всех важных для организации сущностей.
● Управление затратами на интеграцию данных. Стоимость интеграции данных из новых источников в сложную информационную среду только повышается при отсутствии качественных справочных и основных данных, необходимых для минимизации разночтений в определениях критически важных сущностей.
● Снижение риска. Справочные и основные данные позволяют упрощать архитектуру обмена и совместного использования данных, снижая за счет этого издержки и риски, обусловленные избыточной сложностью ИТ-среды.
12.3.3. Специфика управления основными данными
Основные данные описывают ключевые бизнес-сущности (например, сотрудников, клиентов, продукты, финансовые структуры, ресурсы, адреса и т. д. и т. п.), определяющие контекст для бизнес-транзакций и их анализа. Сущность (entity) – это какой-либо объект реального мира (человек, организация, место или предмет). Сущности представлены своими экземплярами (entity instances), которые могут быть описаны в форме строк табличных данных или записей.
Основные данные требуют выявления и (или) выработки достоверной версии правды (trusted version of truth) для каждого экземпляра концептуальных сущностей, таких как продукт, место, счет, физическое лицо или организация, и поддержания этой версии в актуальном состоянии. Главная трудность при управлении основными данными связана с разрешением сущностей (entity resolution) – процессом определения различий и управления связями между данными различных систем и процессов. Экземпляры объектов, описываемых строками таблицы основных данных, в отдельных системах организации обычно представлены по-разному. В рамках управления основными данными должны быть отработаны механизмы разрешения этих рассогласованностей, иначе не получится однозначно и непротиворечиво идентифицировать одни и те же экземпляры каждой сущности (будь то клиенты, продукты и т. п.) в различных контекстах. Этим процессом необходимо управлять постоянно, чтобы не допустить рассогласования идентификаторов экземпляров сущностей основных данных на протяжении всего времени их использования.
Таким образом, управление основными данными (master data management, MDM) подразумевает контроль значений и идентификаторов, обеспечивающий их согласованность во всех системах и наиболее точное отражение актуальных сведений об основных бизнес-сущностях. Цели MDM включают обеспечение доступности точных текущих значений основных данных и минимизацию риска, связанного с их неоднозначной идентификацией (т. е. c появлением в системах идентификаторов, относящихся к нескольким экземплярам одной и той же сущности или соответствующих двум или более сущностям).
12.3.4. Специфика управления справочными данными
Как уже отмечалось, справочные данные – это любые данные, которые используются для определения характеристик или классификации других данных, или же для соотнесения данных внутри организации с внешней информацией. Классификации могут, например определять статусы или типы (например, статус заказа: новый, обрабатывается, закрыт, отменен). Внешняя информация может включать данные о географическом местонахождении или применимых стандартах (и определяться, например, кодом страны).
Справочные данные отличаются от основных и транзакционных данных наличием только им присущих характеристик:
● справочные данные, как правило, менее изменчивы, чем другие виды данных, за некоторыми исключениями (например, данные об обменных курсах валют) они меняются нечасто;
● они обычно проще по структуре и менее объемны, чем наборы транзакционных или основных данных, т. е. таблицы справочных данных содержат меньше столбцов и меньше строк;
● никаких трудностей с разрешением сущностей при управлении справочными данными не возникает (в отличие от основных данных).
Управление справочными данными (reference data management, RDM) подразумевает контроль допустимых множеств значений данных и их определений. Цель RDM – обеспечить организации доступ к полному набору точных и актуальных текущих значений всех представляемых справочными данными понятий.
Одна из главных трудностей в управлении справочными данными – правильно определить их владельца, т. е. лицо, отвечающее за их определение и ведение. Часть справочных данных может поступать в организацию из внешних источников; другая часть – быть разбросанной по различным подразделениям и не иметь формального владельца; еще какие-то справочные данные могут генерироваться и учитываться в одном подразделении, а полученные значения использоваться в других подразделениях. Поэтому определение ответственных за сбор и обновление данных – важная функция RDM. Отсутствие распределения ответственности в сфере RDM порождает риск, поскольку разночтения в справочных данных влекут за собой неправильное понимание контекста данных (например, когда два бизнес-подразделения по-разному классифицируют одно и то же понятие).
12.3.5. Контекстная диаграмма области знаний «Справочные и основные данные» и уровни зрелости соответствующих функций
Контекстная диаграмма области знаний «Справочные и основные данные» представлена на рисунке 12.6.
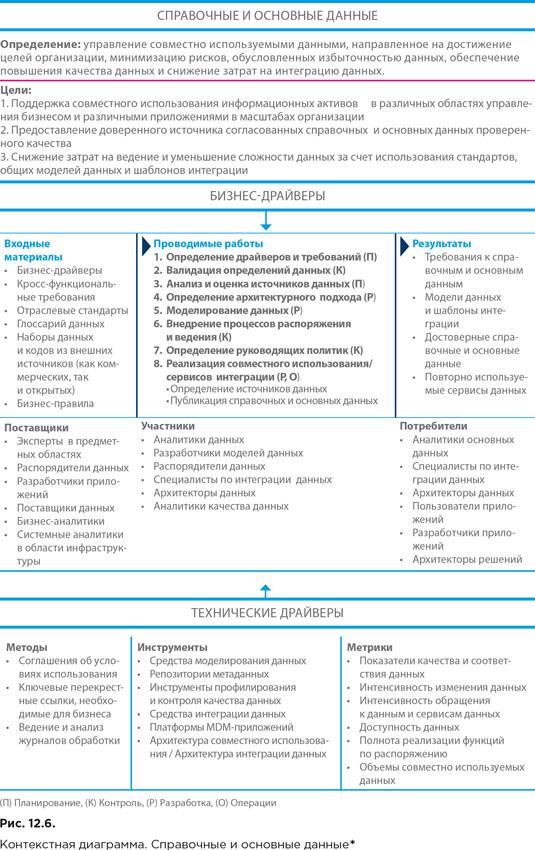
* DAMA. DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition. Technics Publications, 2017. (Русский перевод: DAMA-DMBOK: Свод знаний по управлению данными. Второе издание / Dama International. – М.: Олимп-Бизнес, 2020.)
Проблема управления справочными данными связана с их использованием. Чтобы управление справочными данными было эффективным (обеспечивало актуальность и согласованность в рамках различных приложений и областей применения), оно должно осуществляться с помощью технологии, позволяющей потребителям данных (сотрудникам и системам) оперативно получать к ним доступ в процессе совместной работы на многих платформах.
Как и в случае управления другими видами данных, управление справочными данными требует планирования и проектирования. Архитектура и модели справочных данных должны учитывать, как будет осуществляться хранение, ведение и совместное использование справочных данных. Поскольку это общий ресурс, он требует высокой степени развития практики распоряжения данными. Чтобы получить максимальную отдачу от централизованной системы управления справочными данными, организация должна разработать политику руководства, которая требовала бы использовать эту систему и не позволяла сотрудникам вести свои собственные копии наборов справочных данных. Это может потребовать определенных усилий в части управления организационными изменениями, поскольку заставить людей отказаться от своих электронных таблиц на благо организации не так просто.
Управление основными данными – еще более сложная задача. Она иллюстрирует фундаментальные проблемы работы с данными:
● во-первых, люди имеют различные представления об одних и тех же понятиях, и выработать консенсус бывает непросто;
● во-вторых, информация имеет свойство эволюционировать, и для систематического учета этих изменений требуются планирование, знание данных, а также технические навыки.
Любая организация, признавшая необходимость MDM, вероятно, уже успела столкнуться с массой сложностей, обусловленных наличием в ИТ-среде множества разнородных систем, которые получают вводные по различным каналам и сохраняют ссылки на сущности реального мира в различных форматах и местах. По причине естественного роста накапливаемых объемов разнородной информации, а также возможных слияний и поглощений, процессы, обеспечивающие MDM исходными данными, могут содержать различные определения одних и тех же сущностей, а также использовать различные критерии и стандарты качества данных. Из-за всех этих сложностей лучше подходить к внедрению единой системы MDM поэтапно, вводя ее поочередно в различных предметных областях. Начинать лучше с простой области с небольшим числом сущностей и атрибутов, а затем продолжать выстраивать систему MDM методом расширения.
Планирование управления основными данными включает несколько базовых этапов. В каждой предметной области нужно:
● выявить потенциальные источники, данные из которых обеспечат создание комплексного всестороннего представления сущностей основных данных;
● разработать правила, обеспечивающие точность сравнения и корректность слияния экземпляров сущности, оказавшихся идентичными;
● определить подход к выявлению некорректно распознанных как идентичные и необоснованно объединенных экземпляров, дополненный корректной процедурой восстановления исходных экземпляров сущности;
● определить подход к распространению прошедших тест на достоверность данных во все системы организации.
Реализация процесса управления, однако, не так проста. Нужно не только наладить управление данными в системе MDM, но и обеспечить их доступность для использования другими системами и процессами. Для этого требуется технология, позволяющая предоставлять данные и получать обратную связь. Она также должна быть подкреплена политиками, которые должны способствовать тому, чтобы системы и бизнес-процессы использовали общие значения основных данных, и не позволять им создавать свои собственные «версии истины».
На рисунке 12.7 представлены обобщенные характеристики уровней зрелости функции «Управление справочными данными».
На рисунке 12.8 представлены обобщенные характеристики уровней зрелости функции «Управление основными данными».
12.3.6. Влияние на ценность данных
Налаженное управление справочными и основными данными обеспечивает большое количество преимуществ.
● Хорошо управляемые основные данные повышают организационную эффективность и снижают риски, связанные с различиями в структуре данных между системами и процессами.
● Создаются возможности для обогащения некоторых категорий данных. В частности, данные о заказчиках и клиентах могут быть дополнены информацией из внешних источников, таких как поставщики маркетинговых или демографических данных.
● Поскольку и справочные, и основные данные предоставляют контекст для транзакций, они оформляют и приводят в порядок транзакционные данные, вводимые подразделениями организации при выполнении операций (например, в системах CRM и ERP). Кроме того, они задают рамки анализа транзакционных данных.

* Smith P.; Edge J.; Parry S.; Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.

* Smith P.; Edge J.; Parry S.; Wilkinson D. Crossing the Data Delta: Turn the data you have into the information you need. Entity Group Limited, 2016.
ПРАКТИЧЕСКИЙ ПРИМЕР
Реализуя программу управления данными, компания «Телеком Дубль» решает ряд важных задач в рамках обеспечения доступности и обслуживания данных:● продолжает развивать продукты в части применения облачных вычислений;● переходит к использованию единой корпоративной сервисной шины;● переходит к использованию единого платформенного решения по управлению основными данными.В свою очередь проводимые мероприятия обеспечивают надежную базу для совершенствования всех направлений бизнеса.
Литература к главе 12
• Федеральный закон от 29.06.2015 № 162-ФЗ «О стандартизации в Российской Федерации». – URL: .
• ГОСТ Р ИСО 8000-2:2019. Качество данных. Часть 2. Словарь.
• Кузнецов С. В., Кознов Д. В. Управление мастер-данными в рамках итеративного подхода // Онтология 2017170–184. – DOI: 10.18287/2223–9537–2021–11–2–170–184.
• Van Gils B. Data Management: a Gentle Introduction: Balancing Theory and Practice. Van Haren Publishing, 2020.
• Berson А., Dubov L. Master Data Management and Data Governance, McGraw Hill; 2nd edition, 2010.
Назад: Глава 11. Планирование и проектирование данных
Дальше: Глава 13. Управление основными данными: практика внедрения

