Прошлое без глубокого обучения
Инженер Лю Ян из команды по развитию распознавания речи Baidu отметил одну интересную вещь. Когда члены команды тестировали программу распознавания речи дома, они пропевали, а не произносили слова. При этом текст был точно идентифицирован. Удивительно, что ни одной другой компании не удалось обучить этому функцию распознавания речи. Команда Baidu не ставила перед собой цель научить машину узнавать песню. Они не знают, как это произошло. Напрашивается вывод, что возможности глубокого обучения достаточно велики, чтобы машина получила этот удивительный навык.
Люди, как правило, знают об изменениях в мире. В тот период, когда технология глубокого обучения еще не начала использоваться, казалось, что мир в полном порядке. Некоторые недостатки и проблемы воспринимались как должное. Чжоу Кехуа, серийный убийца, более десяти лет находился в розыске. Чтобы напасть на его след, отдел общественной безопасности мобилизовал почти все камеры видеонаблюдения. А как в то время обрабатывали видео? Невооруженным глазом! Некоторые полицейские даже падали в обморок, пока просматривали сотни или даже тысячи часов видео. Визуальное распознавание, основанное на методах глубокого обучения, изменит это. В настоящее время передовые системы мониторинга имеют сильную поддержку искусственного интеллекта. После обучения массивами данных машины смогут мгновенно распознавать лица, номерные знаки, модели автомобилей и т. д., чем существенно облегчат поиск людей. Нужно будет просто дать компьютеру несколько фотографий подозреваемого, и нейронная сеть быстро найдет материал, связанный с ним. Компания Yushi Technology, занимающаяся производством оборудования для обеспечения безопасности, разработала систему смарт-камер, которая в сочетании с картой Baidu может быстро определить траекторию движения подозреваемого или его транспортного средства.
Глубокое обучение изменило нашу жизнь там, где большинство этого даже не замечают. Чтобы поддерживать обновление картографической информации, сборочный автомобиль выезжает на дорогу. Обычно в нем работают два человека, а процесс сбора делится на две части – внутреннюю и внешнюю. Внешняя работа заключается в том, чтобы записывать информацию обо всех вещах на пути. Первый сотрудник несет ответственность за видеозапись с качественным звуком. Каждый раз, проходя мимо определенного места, необходимо отметить, например, что там есть светофор, четыре полосы движения, левый поворот, поворот вправо, дорога для продолжения движения прямо… Это традиционный способ сбора картографической информации. То есть необходимо просто записывать на видео все, что есть вокруг, а затем отправить данные в центр обработки. Персонал центра обработки данных зарегистрирует новые данные, сравнит со старыми и нанесет элементы на карту. Довольно трудоемкий рабочий процесс.
С умной технологией распознавания изображения мы можем обучить машину определять светофоры, повороты, разметку и другие элементы дороги. А после этого при записи очередного панорамного изображения получить все необходимые данные для того, чтобы была возможность сразу же внести их на карту. Это значительно экономит время и силы, а также повышает эффективность и точность данных.
Помимо алгоритмов программного обеспечения у глубокого обучения есть еще одно преимущество. В истории есть много примеров, когда изобретение находило применение в абсолютно неожиданных областях. Например, нитроглицерину, который сначала использовался в качестве взрывчатого вещества, нашли применение при оказании первой помощи при сердечных заболеваниях… В процессе глубокого обучения функция GPU тоже изменилась. Изначально графические процессоры были видеокартами для визуализации изображений и ускорения графических вычислений, а потом стали основным оборудованием для глубокого обучения. Графические чипы обладают более мощными вычислительными возможностями с плавающей точкой, чем CPU. Поэтому матричные данные, используемые для обработки изображений, идеально подходят для вычисления данных в области машинного обучения. Когда команда Ву Энда впервые использовала GPU для машинного обучения, немногие уловили суть. Сегодня это стало мейнстримом.
Но самое глубокое обучение все еще в поисковых системах.
Поисковик: судьба искусственного интеллекта на волоске
Для сегодняшних китайских интернет-пользователей Baidu стал привычкой. Но раньше его фокусировка на области искусственного интеллекта вызывала некоторое замешательство. Электроэнергия, игры, социальные сети, коммуникация… Все что угодно: от создания ПК до изобретения мобильных устройств и интернета. Почему Baidu занимается только искусственным интеллектом?
Многие люди думают, что компания Baidu выбрала сферу искусственного интеллекта. Но на самом деле, это искусственный интеллект выбрал Baidu. Если Baidu не будет следовать избранной миссии, то это будет не только потеря для компании, но и для Китая и даже мира.
Все начинается с поисковой системы
Поисковая система для пользователя – всего лишь инструмент, который может помочь им найти необходимую информацию. Для сайта, предоставляющего контент, поисковая система – это среда, которая помогает передавать контент нуждающимся пользователям. Во-первых, поисковая система должна «слышать» потребности пользователя, понимать из ключевых слов запроса, что именно он хочет найти. Во-вторых, она должна из огромного количества контента выбрать то, что лучше всего соответствует требованиям пользователя.
Давайте разберем этот процесс так же, как концептуальную модель глубокого обучения. Вход, выход и даже каждое изменение в поиске можно рассматривать как обучение для поисковых систем. Итак, кто скажет поисковой системе, хорош или плох результат? Пользователь. Клик – это ответ. Если пользователь не воспользовался результатами, отображенными на первой странице, и перешел ко второй, значит система допустила ошибку.
Поисковая система не только повышает точность результатов поиска, ориентируясь на предпочтения пользователей, но и учится отличать «плохие» веб-страницы от «хороших». Привыкает выбирать страницы, как это делают люди. Изначально поисковик анализировал только заголовки, ключевые слова, описания и некоторые другие элементы страницы. Теперь такие поисковые системы, как Baidu, могут определять степень правдивости информации, количество рекламы и выбирают страницы, которые действительно обладают ценностью для пользователя.
Получение информации через поисковую систему – это процесс диалога между человеком и машиной. В отличие от предыдущих человеко-компьютерных взаимодействий, этот процесс основан на «естественном языке». Распознавание изображений, распознавание речи, обработка естественного языка являются основными технологиями поисковых систем.
Ван Хайфэн считает, что нам необходимы новые возможности и способы мышления, чтобы расширить способность мыслить и приобретать знания. Это уже выходит за рамки наших способностей видеть, слышать, говорить и действовать. Язык является одной из самых важных характеристик, которая отличает человека от других живых существ. Видеть, слышать и действовать могут почти все животные. И у некоторых из них эти способности развиты сильнее, чем у людей. Но язык уникален. Знание, основанное на языке, также уникально.
Во все времена человечество фиксировало свои знания. Они записывались и передавались в виде языка. А инструменты, используемые для записей, постоянно совершенствовались: от оракула, бумаги до современного интернета. Таким образом, как Baidu, так и Google считают, что обработка естественного языка является очень сложной задачей для будущего искусственного интеллекта. Распознавание речи, например преобразование голоса в текст или слова в звук, решает только проблему преобразования одного сигнала в другой. Это не является языком. А именно язык неразрывно связан с человеческим мышлением и знанием.
Такие проекты, как AlphaGo, стали потрясающим изобретением для обычных людей. И мы считаем, что это настоящий успех. Но мы не можем игнорировать его особенности: пространство закрыто и специфично, а система работает только на основе полной информации и ясных правил. Игра в шахматы может использоваться в системах с искусственным интеллектом, обученных ходам. Обработка естественного языка – более сложная задача. Для Go нет никаких сложностей, пока данные и вычислительная мощность имеются в достаточном количестве. В языке неопределенностей слишком много, например семантическое разнообразие.
Для того, чтобы компьютеры могли «понимать» и генерировать человеческий язык, ученые проделали большую работу. В Baidu на основе массивов данных, машинном обучении и лингвистике была создана карта знаний, построена система вопросов и ответов машинного перевода и конструирования диалога, а также проанализирована способность распознавать эмоции.
Только в «Сети знаний» (Knowledge Graph) можно выделить три категории функций: граф сущностей, граф внимания и граф намерений.
В «Сети знаний» каждый узел является сущностью, каждый объект имеет несколько атрибутов, связь между узлами – это связь между объектами. В настоящее время физическая карта Baidu содержит сотни миллионов объектов, десятки миллиардов атрибутов и сотни миллиардов связей, которые были извлечены из большого количества структурированных и неструктурированных данных.
Теперь давайте рассмотрим пример, если кто-то ищет: «Бывший муж бывшей жены отца папы».
Отношения между персонажами, содержащиеся в этой фразе, очень сложны, но наша система рассуждений может легко проанализировать отношения между сущностями и в конечном итоге получить правильный ответ.
Технология обработки естественного языка Baidu может анализировать грамматически сложные конструкции и определять неоднозначность предложений, а не только искать буквальное соответствие.
Бывший муж бывшей жены отца Цзинтун Доу опубликовал новость на сайте FayeWong.
Бывший муж Вэй Доу, родившийся 14 октября 1969 года в Пекине, Китай, певец, экспериментальный музыкант. В 1988 году он присоединился к Черной пантере.
Япэн Ли Ли Япэн и родился 27 сентября 1971 года в округе Шуймогоу, Урумчи, Синьцзян. Окончил Центральную академию драмы в 1994 году.
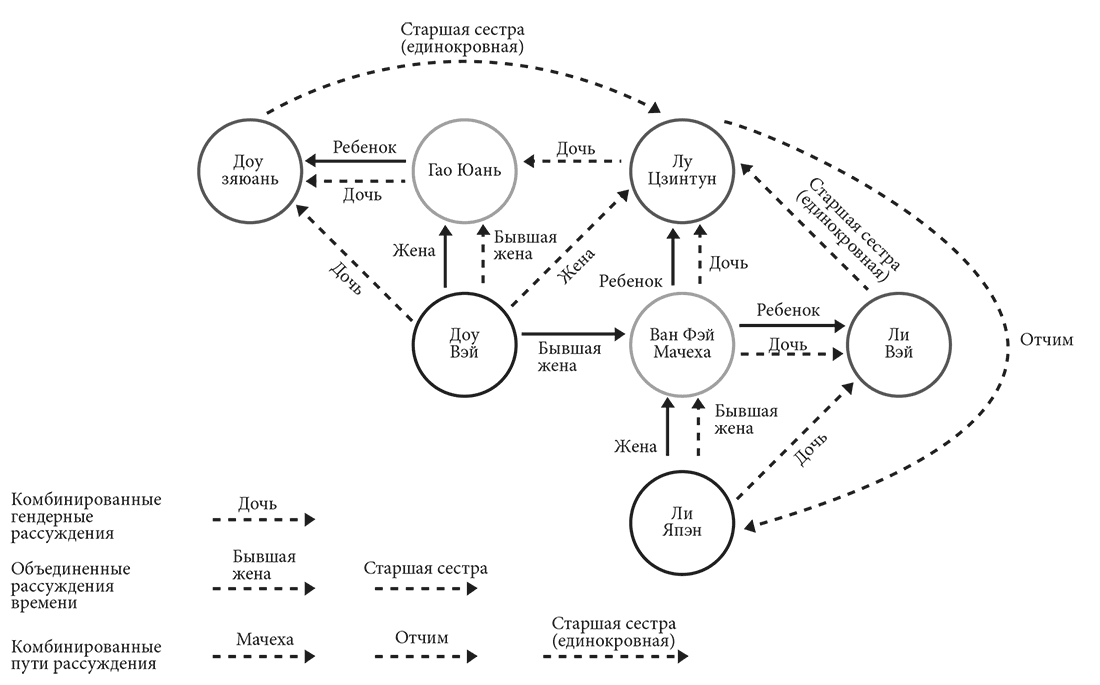
Рис. 3-5. Диаграмма взаимоотношений 1
Еще один пример: кто сын Лин Сычэна; Лин Сычэн чей сын.
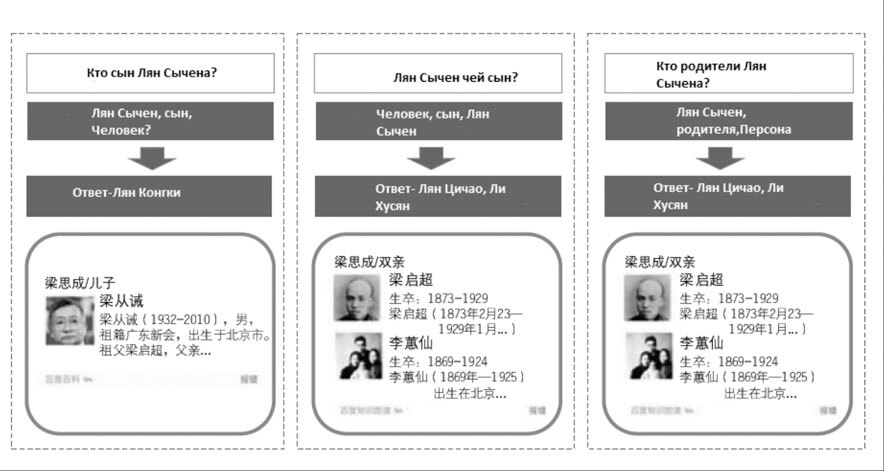
Рис. 3-6. Диаграмма взаимоотношений 2
Если мы используем традиционные методы поиска по ключевым словам, то получим почти идентичные результаты. Однако после семантического анализа машина может обнаружить, что семантика этих двух предложений совершенно разная, и, соответственно, из «Сети знаний» может быть извлечен совершенно другой ответ.
Существует также третье предложение: кто родители Лян Цичэн. Буквально это отличается от второго предложения, но после семантического анализа машина обнаружит, что два предложения ищут один и тот же объект.
Глубокая технология обучения еще больше повышает способность к обработке естественного языка. С 2013 года Baidu использует модель DNN в поисковых системах. Эта модель пережила несколько десятков обновлений и сейчас использует семантический анализ для поиска. Это очень важная особенность. Не только результаты поиска стали более релевантными. Улучшилось положение и с пониманием, восприятием проблем и запросов, и с машинным переводом.
Техническая основа для поиска – техническая основа и для искусственного интеллекта. Например, Чжан Якин, который отвечает за облачную работу Baidu, считает, что поиск – это самое крупное приложение для облачных вычислений. Без облака нет возможностей получить хороший результат. Baidu рождается в облаке.

