What Happens When You Call a Method?
Where you learn that a humble method call requires a lot of work on Ruby’s part and you shed light on a twisted piece of code.
After some hours working on Bookworm, you and Bill already feel confident enough to fix some minor bugs here and there—but now, as your working day is drawing to a close, you find yourself stuck. Attempting to fix a long-standing bug, you’ve stumbled upon a tangle of classes, modules, and methods that you can’t make heads or tails of.
“Stop!” Bill shouts, startling you. “This code is too complicated. To understand it, you have to learn in detail what happens when you call a method.” And before you can react, he dives into yet another lecture.
When you call a method, Ruby does two things:
-
It finds the method. This is a process called method lookup.
-
It executes the method. To do that, Ruby needs something called self.
This process—find a method and then execute it—happens in every object-oriented language. In Ruby, however, you should understand the process in depth, because this knowledge will open the door to some powerful tricks. We’ll talk about method lookup first, and we’ll come around to self later.
Method Lookup
You already know about the simplest case of method lookup. Look back at Figure 1, . When you call a method, Ruby looks into the object’s class and finds the method there. Before you look at a more complicated example, though, you need to know about two new concepts: the receiver and the ancestors chain.
The receiver is the object that you call a method on. For example, if you write my_string.reverse(), then my_string is the receiver.
To understand the concept of an ancestors chain, look at any Ruby class. Then imagine moving from the class into its superclass, then into the superclass’s superclass, and so on, until you reach BasicObject, the root of the Ruby class hierarchy. The path of classes you just traversed is the ancestors chain of the class. (The ancestors chain also includes modules, but forget about them for now. We’ll get around to modules in a bit.)
Now that you know what a receiver is and what an ancestors chain is, you can sum up the process of method lookup in a single sentence: to find a method, Ruby goes in the receiver’s class, and from there it climbs the ancestors chain until it finds the method. Here’s an example:
| | class MyClass |
| | def my_method; 'my_method()'; end |
| | end |
| | |
| | class MySubclass < MyClass |
| | end |
| | |
| | obj = MySubclass.new |
| | obj.my_method() # => "my_method()" |
Bill draws this diagram:
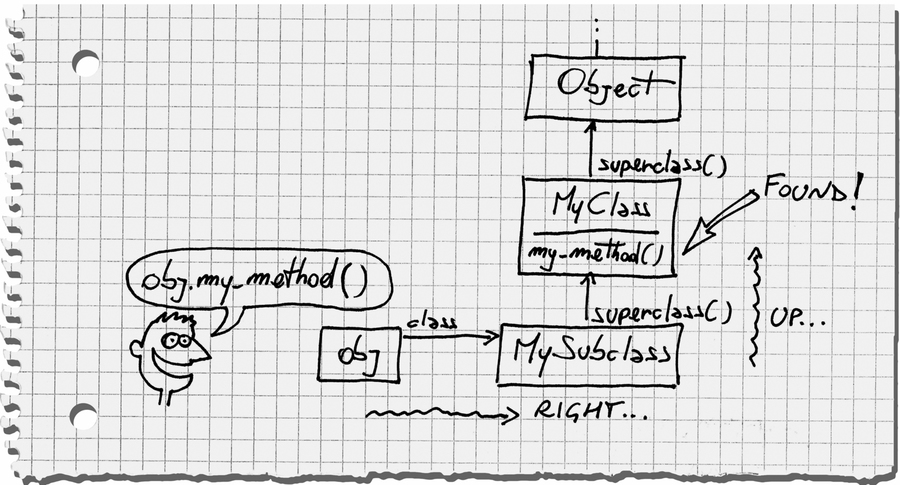
If you’re used to traditional class diagrams, this picture might look confusing to you. Why is obj, a humble object, hanging around in the same diagram with a class hierarchy? Don’t get confused—this is not a class diagram. Every box in the diagram is an object. It’s just that some of these objects happen to be classes, and classes are linked together through the superclass method.
When you call my_method, Ruby goes right from obj, the receiver, into MySubclass. Because it can’t find my_method there, Ruby continues its search by going up into MyClass, where it finally finds the method.
MyClass doesn’t specify a superclass, so it implicitly inherits from the default superclass: Object. If it hadn’t found the method in MyClass, Ruby would look for the method by climbing up the chain into Object and finally BasicObject.
Because of the way most people draw diagrams, this behavior is also called the “one step to the right, then up” rule: go one step to the right into the receiver’s class, and then go up the ancestors chain until you find the method. You can ask a class for its ancestors chain with the ancestors method:
| | MySubclass.ancestors # => [MySubclass, MyClass, Object, Kernel, BasicObject] |
“Hey, what’s Kernel doing there in the ancestors chain?” you ask. “You told me about a chain of superclasses, but I’m pretty sure that Kernel is a module, not a class.”
“You’re right.” Bill admits. “I forgot to tell you about modules. They’re easy….”
Modules and Lookup
You learned that the ancestors chain goes from class to superclass. Actually, the ancestors chain also includes modules. When you include a module in a class (or even in another module), Ruby inserts the module in the ancestors chain, right above the including class itself:
| | module M1 |
| | def my_method |
| | 'M1#my_method()' |
| | end |
| | end |
| | |
| | class C |
| | include M1 |
| | end |
| | |
| | class D < C; end |
| | |
| | D.ancestors # => [D, C, M1, Object, Kernel, BasicObject] |
Starting from Ruby 2.0, you also have a second way to insert a module in a class’s chain of ancestors: the prepend method. It works like include, but it inserts the module below the including class (sometimes called the includer), rather than above it:
| | class C2 |
| | prepend M2 |
| | end |
| | |
| | class D2 < C2; end |
| | |
| | D2.ancestors # => [D2, M2, C2, Object, Kernel, BasicObject] |
Bill draws the following flowchart to show how include and prepend work.
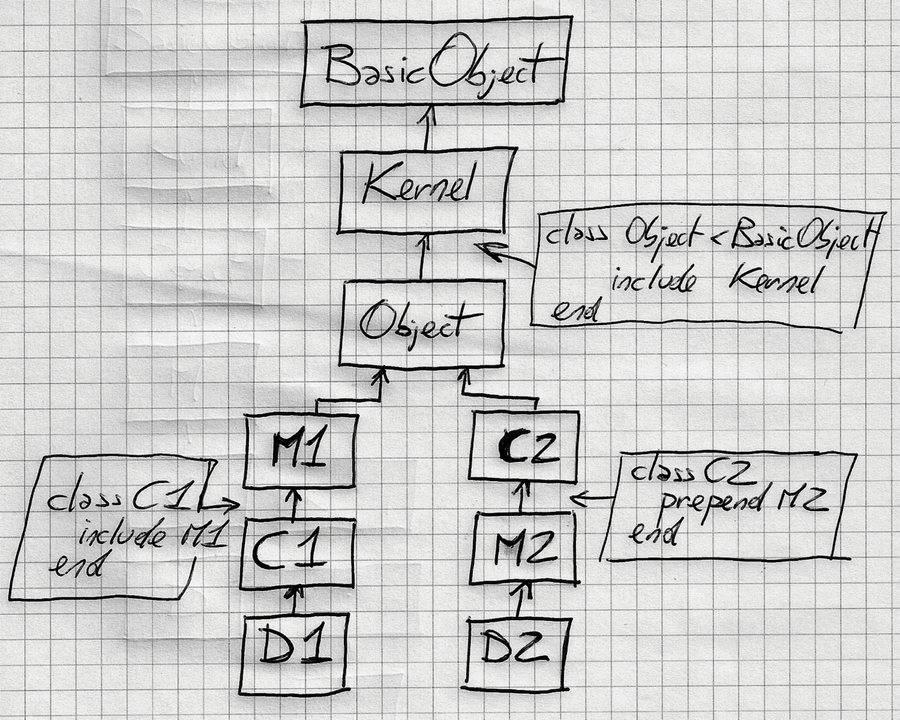
Figure 4. Method lookup with modules
Later in this book, you’ll see how to use prepend to your advantage. For now, it’s enough that you understand the previous diagram. There is one last corner case about include and prepend, however—one that is worth mentioning right away.
Multiple Inclusions
What happens if you try to include a module in the same chain of ancestors multiple times? Here is an example:
| | module M1; end |
| | |
| | module M2 |
| | include M1 |
| | end |
| | |
| | module M3 |
| | prepend M1 |
| | include M2 |
| | end |
| | |
| | M3.ancestors # => [M1, M3, M2] |
In the previous code, M3 prepends M1 and then includes M2. When M2 also includes M1, that include has no effect, because M1 is already in the chain of ancestors. This is true every time you include or prepend a module: if that module is already in the chain, Ruby silently ignores the second inclusion. As a result, a module can appear only once in the same chain of ancestors. This behavior might change in future Rubies—but don’t hold your breath.
While we’re talking about modules, it’s worth taking a look at that Kernel module that keeps popping up everywhere.
The Kernel
Ruby includes some methods, such as print, that you can call from anywhere in your code. It looks like each and every object has the print method. Methods such as print are actually private instance methods of module Kernel:
| | Kernel.private_instance_methods.grep(/^pr/) # => [:printf, :print, :proc] |
The trick here is that class Object includes Kernel, so Kernel gets into every object’s ancestors chain. Every line of Ruby is always executed inside an object, so you can call the instance methods in Kernel from anywhere. This gives you the illusion that print is a language keyword, when it’s actually a method. Neat, isn’t it?
You can take advantage of this mechanism yourself: if you add a method to Kernel, this Spell: will be available to all objects. To prove that Kernel Methods are actually useful, you can look at the way some Ruby libraries use them.
The Awesome Print Example
The awesome_print gem prints Ruby objects on the screen with indentation, color, and other niceties:
| | require "awesome_print" |
| | |
| | local_time = {:city => "Rome", :now => Time.now } |
| | ap local_time, :indent => 2 |
This produces:
| <= | { |
| | :city => "Rome", |
| | :now => 2013-11-30 12:51:03 +0100 |
| | } |
You can call ap from anywhere because it’s a Kernel Method (), which you can verify by peeking into Awesome Print’s source code:
| | module Kernel |
| | def ap(object, options = {}) |
| | # ... |
| | end |
| | end |
After this foray into Ruby modules and the Kernel, you can finally learn how Ruby executes methods after finding them.
Method Execution
When you call a method, Ruby does two things: first, it finds the method, and second, it executes the method. Up to now, you focused on the finding part. Now you can finally look at the execution part.
Imagine being the Ruby interpreter. Somebody called a method named, say, my_method. You found the method by going one step to the right, then up, and it looks like this:
| | def my_method |
| | temp = @x + 1 |
| | my_other_method(temp) |
| | end |
To execute this method, you need to answer two questions. First, what object does the instance variable @x belong to? And second, what object should you call my_other_method on?
Being a smart human being (as opposed to a dumb computer program), you can probably answer both questions intuitively: both @x and my_other_method belong to the receiver—the object that my_method was originally called upon. However, Ruby doesn’t have the luxury of intuition. When you call a method, it needs to tuck away a reference to the receiver. Thanks to this reference, it can remember who the receiver is as it executes the method.
That reference to the receiver can be useful for you as well—so it is worth exploring further.
The self Keyword
Every line of Ruby code is executed inside an object—the so-called current object. The current object is also known as self, because you can access it with the self keyword.
Only one object can take the role of self at a given time, but no object holds that role for a long time. In particular, when you call a method, the receiver becomes self. From that moment on, all instance variables are instance variables of self, and all methods called without an explicit receiver are called on self. As soon as your code explicitly calls a method on some other object, that other object becomes self.
Here is an artfully complicated example to show you self in action:
| | class MyClass |
| | def testing_self |
| | @var = 10 # An instance variable of self |
| | my_method() # Same as self.my_method() |
| | self |
| | end |
| | |
| | def my_method |
| | @var = @var + 1 |
| | end |
| | end |
| | |
| | obj = MyClass.new |
| | obj.testing_self # => #<MyClass:0x007f93ab08a728 @var=11> |
As soon as you call testing_self, the receiver obj becomes self. Because of that, the instance variable @var is an instance variable of obj, and the method my_method is called on obj. As my_method is executed, obj is still self, so @var is still an instance variable of obj. Finally, testing_self returns a reference to self. (You can also check the output to verify that @var is now 11.)
If you want to become a master of Ruby, you should always know which object has the role self at any given moment. In most cases, that’s easy: just track which object was the last method receiver. However, there are two important special cases that you should be aware of. Let’s look at them.
The Top Level
You just learned that every time you call a method on an object, that object becomes self. But then, who’s self if you haven’t called any method yet? You can run irb and ask Ruby itself for an answer:
| | self # => main |
| | self.class # => Object |
As soon as you start a Ruby program, you’re sitting within an object named main that the Ruby interpreter created for you. This object is sometimes called the top-level context, because it’s the object you’re in when you’re at the top level of the call stack: either you haven’t called any method yet or all the methods that you called have returned. (Oh, and in case you’re wondering, Ruby’s main has nothing to do with the main() functions in C and Java.)
Class Definitions and self
In a class or module definition (and outside of any method), the role of self is taken by the class or module itself.
| | class MyClass |
| | self # => MyClass |
| | end |
This last detail is not going to be useful right now, but it will become a central concept later in this book. For now, we can set it aside and go back to the main topic.
Everything that you’ve learned so far about method execution can be summed up in a few short sentences. When you call a method, Ruby looks up the method by following the “one step to the right, then up” rule and then executes the method with the receiver as self. There are some special cases in this procedure (for example, when you include a module), but there are no exceptions…except for one.
Refinements
Remember the first refactoring you coded today, in ? You and Bill used an Open Class () to add a method to Strings:
| | class String |
| | def to_alphanumeric |
| | gsub(/[^\w\s]/, '') |
| | end |
| | end |
The problem with modifying classes this way is that the changes are global: from the moment the previous code is executed, every String in the system gets the changes. If the change is an incompatible Monkeypatch (), you might break some unrelated code—as happened to you and Bill when you inadvertently redefined Array#replace.
Starting with Ruby 2.0, you can deal with this problem using a Spell: . Begin by writing a module and calling refine inside the module definition:
| | module StringExtensions |
| | refine String do |
| | def to_alphanumeric |
| | gsub(/[^\w\s]/, '') |
| | end |
| | end |
| | end |
This code refines the String class with a new to_alphanumeric method. Differently from a regular Open Class, however, a Refinement is not active by default. If you try to call String#to_alphanumeric, you’ll get an error:
| | "my *1st* refinement!".to_alphanumeric |
| <= | NoMethodError: undefined method `to_alphanumeric' [...] |
To activate the changes, you have to do so explicitly, with the using method:
| | using StringExtensions |
From the moment you call using, all the code in that Ruby source file will see the changes:
| | "my *1st* refinement!".to_alphanumeric # => "my 1st refinement" |
Starting from Ruby 2.1, you can even call using inside a module definition. The Refinement will be active until the end of the module definition. The code below patches the String#reverse method—but only for the code inside the definition of StringStuff:
| | module StringExtensions |
| | refine String do |
| | def reverse |
| | "esrever" |
| | end |
| | end |
| | end |
| | |
| | module StringStuff |
| | using StringExtensions |
| | "my_string".reverse # => "esrever" |
| | end |
| | |
| | "my_string".reverse # => "gnirts_ym" |
Refinements are similar to Monkeypatches, but they’re not global. A Refinement is active in only two places: the refine block itself and the code starting from the place where you call using until the end of the module (if you’re in a module definition) or the end of the file (if you’re at the top level)
In the limited scope where it’s active, a Refinement is just as good as an Open Class or a Monkeypatch. It can define new methods, redefine existing methods, include or prepend modules, and generally do anything that a regular Open Class can do. Code in an active Refinement takes precedence over code in the refined class, and also over code in modules that are included or prepended by the class. Refining a class is like slapping a patch right onto the original code of the class.
On the other hand, because they’re not global, Refinements don’t have the issues that you experienced in . You can apply a Refinement to a few selected areas of your code, and the rest of your code will stick with the original unrefined class—so there aren’t many chances that you’ll break your system by inadvertently impacting unrelated code. However, this local quality of Refinements has the potential to surprise you, as you’re about to find out.
Refinement Gotchas
Look at this code:
| | class MyClass |
| | def my_method |
| | "original my_method()" |
| | end |
| | |
| | def another_method |
| | my_method |
| | end |
| | end |
| | |
| | module MyClassRefinement |
| | refine MyClass do |
| | def my_method |
| | "refined my_method()" |
| | end |
| | end |
| | end |
| | |
| | using MyClassRefinement |
| | MyClass.new.my_method # => "refined my_method()" |
| | MyClass.new.another_method # => "original my_method()" |
The call to my_method happens after the call to using, so you get the refined version of the method, just like you expect. However, the call to another_method could catch you off guard: even if you call another_method after using, the call to my_method itself happens before using—so it calls the original, unrefined version of the method.
Some people find the result above counterintuitive. The lesson here is to double-check your method calls when you use Refinements (). Also keep in mind that Refinements are still an evolving feature—so much so that Ruby 2.0 issues a scary warning when your program uses Refinements for the first time:
| <= | warning: Refinements are experimental, and the |
| | behavior may change in future versions of Ruby! |
This warning has been removed in Ruby 2.1, but there are still a few corner cases where Refinements might not behave as you expect—and some of those corner cases might change in future Rubies. For example, you can call refine in a regular module, but you cannot call it in a class, even if a class is itself a module. Also, metaprogramming methods such as methods and ancestors ignore Refinements altogether. Behaviors such as these have sound technical justifications, but they could trip you up nonetheless. Refinements have the potential to eliminate dangerous Monkeypatches, but it will take some time for the Ruby community to understand how to use them best.
You’re still considering the power and responsibility of using Refinements when Bill decides to throw a quiz at you.

