Implementing a text tagger using Solr
Let us see how we can implement the Solr text tagger. Let us get the latest code for the Solr text tagger from the GitHub repository by cloning the Git repository with the following command:
git clone https://github.com/OpenSextant/SolrTextTagger.git This will get the code inside a folder called SolrTextTagger.
Now inside the SolrTextTagger library, run the following command to create the JAR file:
mvn package Note
The mvn command is available in the Maven repository. This repository can be installed using the following command on Ubuntu machines:
sudo apt-get install maven2 We can also install and use the latest release of maven – maven3.
The mvn command fetches the dependencies required for compiling and creating the JAR file. If any dependencies are not satisfied or remain unavailable, you will need to debug the pom.xml file inside the SolrTextTagger folder and re-run the command.
Alternatively, you can use the solr-text-tagger.jar file available with this chapter.
On successful compilation, we will be able to see the following output on the screen:
[INFO] Building jar: /home/jayant/solrtag/SolrTextTagger/target/solr-text-tagger-2.1-SNAPSHOT.jar [INFO] ------------------------------------------------------------------ [INFO] BUILD SUCCESSFUL [INFO] ------------------------------------------------------------------ [INFO] Total time: 54 seconds [INFO] Finished at: Tue Feb 17 10:43:34 IST 2015 [INFO] Final Memory: 62M/322M [INFO] ------------------------------------------------------------------
The compiled file is available in the target folder inside the SolrTextTagger folder:
target/solr-text-tagger-2.1-SNAPSHOT.jar
This JAR file has to be copied into the <solr installation>/example/lib folder from where solrconfig.xml will pick it up.
To configure a text tagger with this instance of Solr, we will need to modify the solrconfig.xml and schema.xml files in our Solr installation. For a fresh installation of Solr, we can go to the <solr installation>/example/solr/collection1/conf folder and add or modify the following lines in our schema.xml:
<field name="name_tag" type="tag" stored="false" omitTermFreqAndPositions="true" omitNorms="true"/> <copyField source="name" dest="name_tag"/>
Here we are defining a new field name_tag, which is of the field type tag. In order to populate the field, we have copied the text from our existing field name to the new field name_tag.
Next, we will also need to define the behavior of tag. This is also done in schema.xml, as follows:
<fieldType name="tag" class="solr.TextField" positionIncrementGap="100" postingsFormat="Memory"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.ASCIIFoldingFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="org.opensextant.solrtexttagger.ConcatenateFilterFactory" /> </analyzer> <analyzer type="query"> <!-- 32 just for tests, bumps posInc --> <tokenizer class="solr.StandardTokenizerFactory" maxTokenLength="32"/> <!-- NOTE: This used the WordLengthTaggingFilterFactory to test the TaggingAttribute. The WordLengthTaggingFilter set the TaggingAttribute for words based on their length. The attribute is ignored at indexing time, but the Tagger will use it to only start tags for words that are equals or longer as the configured minLength. --> <filter class="org.opensextant.solrtexttagger.WordLengthTaggingFilterFactory" minLength="4"/> <filter class="solr.ASCIIFoldingFilterFactory"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType>
Here, we are defining the analysis happening on the tag field type during indexing and search or querying. The attribute postingsFormat="Memory" requires that we set codecFactory in our solrconfig.xml file to solr.SchemaCodecFactory. The postingsFormat class provides read and write access to all postings, fields, terms, documents, frequencies, positions, offsets, and payloads. These postings define the format of the index being stored. Here we are defining postingsFormat as memory, which keeps data in memory thus making the tagger work as fast as possible.
During indexing, we use standard tokenizer, which breaks our input into tokens. This is followed by ASCIIFoldingFilterFactory. This class converts alphabetic, numeric, and symbolic Unicode characters that are not on the 127-character list of ASCII into their ASCII equivalents (if the ASCII equivalent exists). We are converting our tokens to lowercase by using LowerCaseFilterFactory. Also, we are using ConcatenateFilterFactory provided by solrTextTagger, which concatenates all tokens into a final token with a space separator.
During querying, we once again use Standard Tokenizer followed by WordLengthTaggingFilterFactory. This defines the minimum length of a token to be looked up during the tagging process. We use ASCIIFoldingFilterFactory and LowerCaseFilterFactory as well.
Now, let us go through the changes we need to make in solrconfig.xml. We will first need to add solr-text-tagger-2.1-SNAPSHOT.jar to be loaded as a library when Solr starts. For this, add the following lines in solrconfig.xml:
<lib dir="../../lib/" regex="solr-text-tagger-2\.1-SNAPSHOT\.jar" />
Tip
You can also use the solr-text-tagger.jar file provided with this chapter. It has been properly compiled with some missing classes.
Copy the solr-text-tagger.jar file to your <solr installation>/example/lib folder and add the following line in your solrconfig.xml:
<lib dir="../../lib/" regex="solr-text-tagger\.jar" />
Also, add the following lines to support postingsFormat="Memory", as explained earlier in this section:
<!-- for postingsFormat="Memory" --> <codecFactory name="CodecFactory" class="solr.SchemaCodecFactory" /> <schemaFactory name="SchemaFactory" class="solr.ClassicIndexSchemaFactory" />
We will also have to define our own request handler, say /tag, which calls TaggerRequestHandler as provided by the Solr text tagger. Inside the /tag request handler, we have defined the field to be used for tagging as name_tag, which we added to our schema.xml earlier. The filter query is an optional parameter that can be used to match the subset of the documents (for name matching) in our case:
<requestHandler name="/tag" class="org.opensextant.solrtexttagger.TaggerRequestHandler"> <!-- top level params; legacy format just to test it still works --> <str name="field">name_tag</str> <str name="fq">NOT name:(of the)</str><!-- filter out --> </requestHandler>
Now, let us start the Solr server and watch the output to check whether any errors crop up while Solr loads the configuration and library changes that we made.
Note
If you get the following error in your Solr log stating that it is missing WorlLengthTaggingFilterFactory, this factory has to be compiled and added to the JAR file we had created:
2768 [coreLoadExecutor-4-thread-1] ERROR org.apache.solr.core.CoreContainer – Unable to create core: collection1 . . Caused by: java.lang.ClassNotFoundException: solr.WordLengthTaggingFilterFactory
The files that are required to be compiled, WordLengthTaggingFilterFactory.java and WordLengthTaggingFilter.java, are available in the following folder:
SolrTextTagger/src/test/java/org/opensextant/solrtexttagger
In order to compile the file, we will need the following JAR files from our Solr installation:
javac -d . -cp log4j-1.2.16.jar:slf4j-api-1.7.6.jar:slf4j-log4j12-1.7.6.jar:lucene-core-4.8.1.jar:solr-text-tagger-2.1-SNAPSHOT.jar WordLengthTaggingFilterFactory.java WordLengthTaggingFilter.java These jars could be found inside <solr installation>/example/lib/ext and webapps/solr.war file. The WAR file will need to be unzipped to obtain the required JAR files.
Once compiled, the class files can be found inside the org/opensextant/solrtexttagger folder. In order to add these files into our existing solr-text-tagger-2.1-SNAPSHOT.jar, simply unzip the JAR file and copy the files to the required folder org/opensextant/solrtexttagger/ and create the JAR file again using the following zip command:
zip -r solr-text-tagger.jar META-INF/ org/ In order to check whether the tag request handler is working, let us point our browser to http://localhost:8983/solr/collection1/tag.
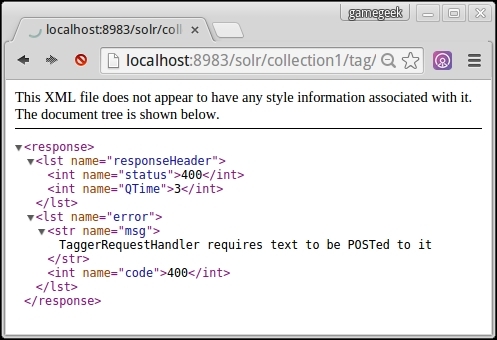
We can see a message stating that we need to post some text into TaggerRequestHandler. This means that the Solr text tagger is now plugged into our Solr installation and is ready to work.
Now that we have our Solr server running without any issues, let us add some files from the exampledocs folder to build the index and the tagging index along with it. Execute the following commands:
cd example/exampledocs java -jar post.jar *.xml java -Dtype=text/csv -jar post.jar books.csv
This will index all the xml documents and the books.csv file into the index.
Let us check whether the tagging works by checking the tags for the content inside the solr.xml file inside the exampledocs folder. Run the following command:
curl -XPOST 'http://localhost:8983/solr/tag?overlaps=ALL&tagsLimit=5000&fl=*&wt=json' -H 'Content-Type:text/xml' -d @solr.xml We can see the output on our command prompt:
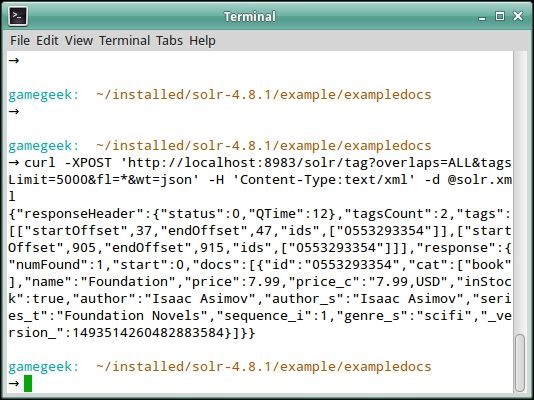
The tagcount is 2 in the output.
Tip
Windows users can download curl from the following location and install it: .
The commands can then be run from the command prompt.
Linux users can pretty print the JSON output from the previous query by using Python's pretty-print tool for JSON and piping it with the curl command. The command will then be:
curl -XPOST 'http://localhost:8983/solr/tag?overlaps=ALL&tagsLimit=5000&fl=*&wt=json' -H 'Content-Type:text/xml' -d @solr.xml | python -m json.tool The output will be similar to the following image:
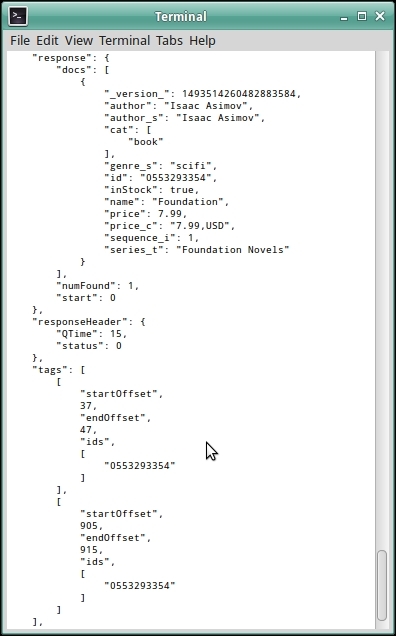
The output contains two sections, tags and docs. The tags section contains an array of tags with the ids of the documents in which they are found. The docs section contains Solr documents referenced by those tags.
We take up another findtags.txt file and find the tags in this file. Let us run the following command:
curl -XPOST 'http://localhost:8983/solr/tag?overlaps=ALL&tagsLimit=5000&fl=*' -H 'Content-Type:text/plain' -d @findtags.txt | xmllint --format - This will give us the output in the XML format, as follows:
<?xml version="1.0" encoding="UTF-8"?> <response> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">54</int> </lst> <int name="tagsCount">3</int> <arr name="tags"> <lst> <int name="startOffset">905</int> <int name="endOffset">915</int> <arr name="ids"> <str>0553293354</str> </arr> </lst> <lst> <int name="startOffset">1246</int> <int name="endOffset">1256</int> <arr name="ids"> <str>0553293354</str> </arr> </lst> <lst> <int name="startOffset">1358</int> <int name="endOffset">1368</int> <arr name="ids"> <str>0553293354</str> </arr> </lst> </arr> <result name="response" numFound="1" start="0"> <doc> <str name="id">0553293354</str> <arr name="cat"> <str>book</str> </arr> <str name="name">Foundation</str> <float name="price">7.99</float> <str name="price_c">7.99,USD</str> <bool name="inStock">true</bool> <str name="author">Isaac Asimov</str> <str name="author_s">Isaac Asimov</str> <str name="series_t">Foundation Novels</str> <int name="sequence_i">1</int> <str name="genre_s">scifi</str> <long name="_version_">1493514260482883584</long> </doc> </result> </response>
Here, we can see that three tags were found in our text. All of them refer to the same document ID in the index.
For the index to be useful, we will need to index many documents. As the number of documents increases so will the accuracy of the tags found in our input text.
Now let us look at some of the request time parameters passed to the Solr text tagger:
overlaps: This allows us to choose an algorithm that will be used to determine which overlapping tags should be retained versus which should be pruned away:ALL: We have usedALLin our Solr queries. This means all tags should be emitted.NO_SUB: Do not emit a sub tag, that is, a tag within another tag.LONGEST_DOMINANT_RIGHT: Compare the character lengths of the tags and emit the longest one. In the case of a tie, pick the right-most tag. Remove tags that overlap with this identified tag and then repeat the algorithm to find other tags that can be emitted.
matchText: This is a Boolean flag that indicates whether the matched text should be returned in the tag response. In this case, the tagger will fully buffer the input before tagging.tagsLimit: This indicates the maximum number of tags to return in the response. By default, this is1000. In our examples, we have mentioned it as5000. Tagging is stopped once this limit is reached.skipAltTokens: This is a Boolean flag used to suppress errors that can occur if, for example, you enable synonym expansion at query time in the analyzer, which you normally shouldn't do. The default value isfalse.ignoreStopwords: This is a Boolean flag that causes stop words to be ignored. Otherwise, the behavior is to treat them as breaks in tagging on the presumption that our indexed text-analysis configuration doesn't have aStopWordFilterclass. By default, the indexed analysis chain is checked for the presence of aStopWordFilterclass and, if found, thenignoreStopWordsistrueif unspecified. If we do not haveStopWordFilterconfigured, we can safely ignore this parameter.
Most of the standard parameters that work with Solr also work here. For example, we have used wt=json here. We can also use echoParams, rows, fl, and other parameters during tagging.

