Chapter 9. SolrCloud
In this chapter, we will learn about SolrCloud. We will look at the architecture of SolrCloud and understand the problems it addresses. We will look at how it can be used to address scalability issues. We will also set up SolrCloud along with a separate setup for central configuration management known as ZooKeeper. We will look at the advanced sharding options available with SolrCloud, memory management issues, and monitoring options. We will also evaluate SolrCloud as a NoSQL storage system.
The major topics that will be covered in this chapter are:
- The SolrCloud architecture
- Centralized configuration
- Setting up SolrCloud
- Distributed indexing and search
- Advanced sharding with SolrCloud
- Memory management
- Monitoring
- Using SolrCloud as a NoSQL database
The SolrCloud architecture
Scaling proceeds in two ways when it comes to handling large amounts of data, horizontally or vertically. Vertical scaling deals with the problems of handling large data by adding bigger and bigger machines. Suppose a single machine which has 4 GB of RAM and 4 CPU can handle a concurrency of 100 queries per second on a data size of say 8 GB. As the amount of data increases, the amount of processing required for serving the queries also increases. Therefore, if the data size goes to 16 GB, the query concurrency that the same machine can handle will be 75 queries instead of 100. For vertical scaling, we would replace the current 4 GB + 4 CPU machine with an 8 GB + 8 CPU machine, which should again be able to serve a concurrency of 100 queries per second on a data size of 16 GB. Horizontal scaling would mean that we add another machine of the same configuration 4 GB RAM + 4 CPU to the system and divide 16 GB of data into two parts of 8 GB each. Each machine now hosts 8 GB of data and can support a concurrency of 100 queries per second. That is, a combined concurrency of 200 queries per second is obtained.
There is a limit to which a system can be scaled vertically. The largest machine available on Amazon as of now has 32 vCPUs and 244 GB of RAM. While it may be possible to scale a system in a vertical fashion by adding more hardware, horizontal scaling is still preferable. Maybe a year down the line, Amazon will be able to offer 64 vCPUs with 488 GB of RAM. What if your data grows exponentially during the one-year period? The larger machine may not be able to satisfy your queries per second requirements. Horizontal scaling is cost-effective as it is possible to retain the existing hardware and add new instead of discarding the existing hardware for an upgraded or better machine. Horizontal scaling not only adds new machines providing additional computing power and memory, but it also provides additional storage. It can be made to act as a distributed system taking care of failover and high availability scenarios wherever required.
Scaling with Solr is as complex. It is possible to add hardware and scale a single Solr or a Solr setup in master-slave architecture in a vertical fashion. For vertical scaling, we will need to continually add more memory and increase the computing power and, if possible, move to SSD drives, which are expensive but a lot more efficient than normal drives. This will improve the disk IO multiple times. Since we need a master-slave architecture for high-availability and failover scenarios, we will need to retain at least two machines, one acting as the master and the other acting as a slave and replicating Solr index data from the master.
However, horizontal scaling is preferable. SolrCloud provides easy scaling in a horizontal fashion.
With SolrCloud, the complete index can be divided into shards and replicas. A shard is a part of the complete index. A replica is basically a Solr slave that reads data from the master and replicates it. A shard can have more than one replica. SolrCloud has the capability to set up a cluster of Solr servers that also provides fault tolerance and high availability in addition to distributed search and indexing.
SolrCloud offers a centralized configuration, automatic load balancing and failover for queries, and ZooKeeper integration for cluster coordination and configuration. ZooKeeper is a centralized service for maintaining configuration information for a distributed system. It is possible to have a cluster of ZooKeeper services providing high availability and failover. SolrCloud does not have a master node to allocate nodes, shards, and replicas. Instead, it uses ZooKeeper to manage these components.
With SolrCloud, we can add documents to our distributed index via any server in the cluster. The document is automatically routed to the proper shard in the cluster and indexed there. In case of a server or Solr instance going down, another shard will be elected as a leader. The searches are available near real time after indexing.
A full-scale SolrCloud setup is explained by the following architecture:
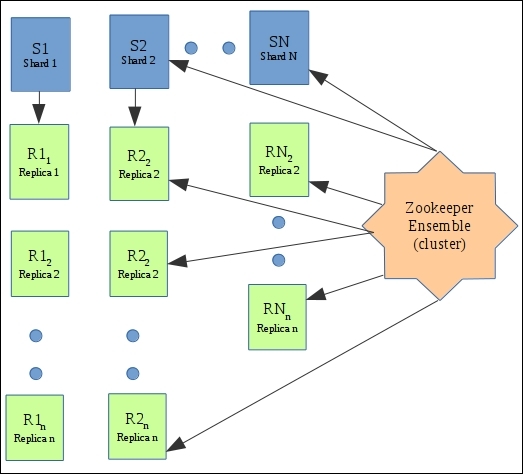
The SolrCloud architecture
The cloud consists of N shards, each of which can be on a different machine. Each shard can have n replicas, again on different machines. The configuration is managed by a separate cluster of ZooKeeper servers known as Zookeeper ensemble. The ZooKeeper ensemble will interact with each machine in SolrCloud, namely shard leaders and replicas.

