Advanced concepts
As discussed earlier, RPT is based on a model where the world is divided into grid squares or cells. This is done recursively to get almost any amount of accuracy required. Each cell is indexed in Lucene with a byte string that has the parent cell's byte string as a prefix. Therefore, it is named PrefixTree. The PrefixTreeStrategy class for indexing and search uses a SpatialPrefixTree abstraction that decides how to divide the world into grid squares and what the byte encoding looks like to represent each grid square. It has two implementations, namely geohash and quadtrees. Let us look at both implementations in detail.
Quadtree
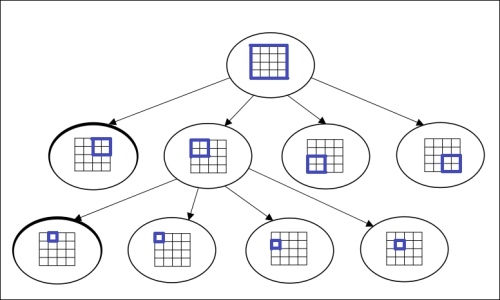
A quadtree is a simple and effective spatial indexing technique wherein each of the nodes represents a bounding box covering the parts of the space that has been indexed. Each node is either a leaf-node that contains one or more indexed points with no child, or an internal node with four children, one for each quadrant. The index structure of a quadtree is shown in the following image:
Indexing data
Data can be inserted into a quadtree as follows:
- Start with the root that determines the quadrant the point in question occupies.
- Go deeper into the tree till you find a leaf node.
- Add the point to the list of points in that node.
- While performing the preceding steps, if you come across a scenario wherein this list exceeds a pre-defined maximum allowed element count, proceed to the next step; else, it can be ignored.
- Split the node further and push the points into the appropriate sub-nodes
Searching data
A search on the indexed quadtree involves the following steps:
- Investigate each child node starting from the root and check whether it intersects the area it is being queried.
- If the point intersects the area, dig deeper into that child node until a leaf node is found.
- Once you encounter a leaf node, investigate each entry to see whether it intersects the query area. If so, return the leaf node.
A quadtree follows a Trie structure () as the values of the nodes are independent of the data that are being inserted. Thus, each of our nodes can be assigned a unique number. We simply assign a binary code to each of the quadrants (00 for top left, 10 for top right, and so on), and the node number of its ancestor gets concatenated in the case of a multi-level tree. For instance, in the preceding diagram, the bottom right node would be numbered as 00 11.
In geohash, which we will discuss next, each cell is divided into 32 smaller cells. On the other hand, in a quadtree, each cell is divided into four smaller cells in a 2x2 grid. So, with each additional level, there will be 32/2 = 16 times as many cells as those in the previous level for geohash. For a quadtree, the factor is 4/2 = 2 times. Therefore, there are fewer hierarchical levels in geohash than in a quadtree, which has certain performance gain during search.
Geohash
Geohash is a system for encoding geographical coordinates into a single field as a string. There is a web service that provides a geocode class, which is based on the latitude and longitude of any location. Geocode is represented as a hierarchy of spatial data that subdivides the overall space into a grid. Let us first understand how works before looking at the indexing- and search-related features provided by Solr for geohash.
Let us go to and enter our location (28.642815,77.368413), which points to Swarna Jayanti Park, Indirapuram, Ghaziabad, India, in the search bar. After executing the search, we zoom in to see the exact location on the map. The output would be as displayed in the following image:
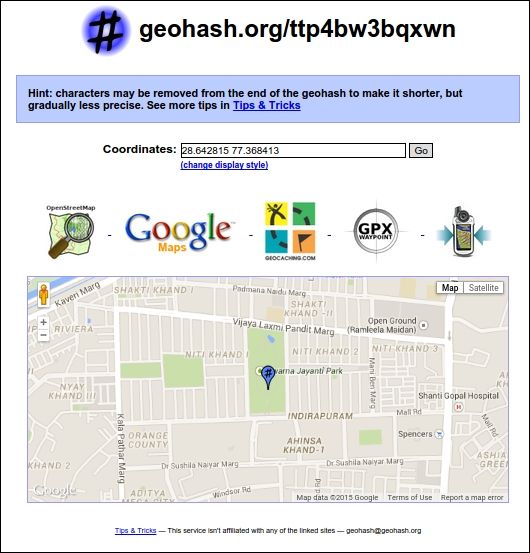
The hash generated for our latitude and longitude coordinates is ttp4bw3bqxwn. This hash is unique and can be used with to refer to our lat-lon coordinate.
Note
There are some basics required for using a geohash such as:
- Naming geohashes
- Geohash format
- Google map tools to generate geohash using Google Maps
- Quering geohash
These details can be obtained from the following URL: .
Let us also get a brief idea on how a point is indexed in geohash's SpatialPrefixTree grid. The geohash that we generated, ttp4bw3bqxwn, is a 12 character string. This is indexed in Solr and the underlying Lucene as 12 terms, as follows:
t, tt, ttp, ttp4, ttp4b, ttp4bw, ttp4bw3, ttp4bw3b, ttp4bw3bq, ttp4bw3bqx, ttp4bw3bqxw, ttp4bw3bqxwn
These 12 characters lead to an accurate point inside Swarn Jayanti Park, Indirapuram. Now, change the last digit of the longitude coordinate from 3 to 4. The lat-lon coordinate now becomes 28.642815-77.368414, and in the geohash, only the last character changed from n to y.
The new geohash is now ttp4bw3bqxwy, which is inside Swarn Jayanti Park, Indirapuram, Ghaziabad, as shown in the following image:
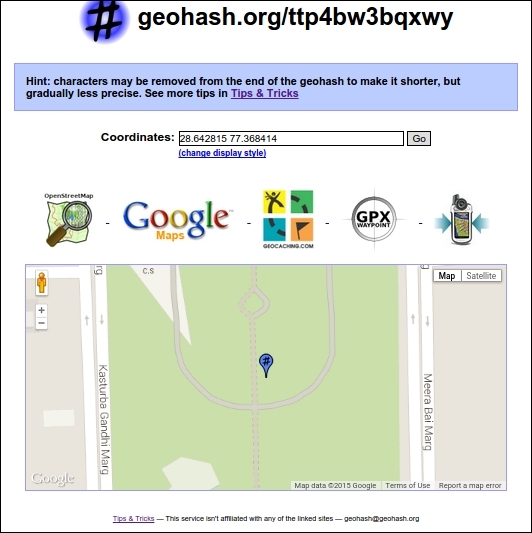
This shows us the concept of how the geohash is being indexed as 12 terms. A search on the first 11 characters would lead to a location that is defined by a 1 m grid. The accuracy of our search in this case would be 1 m. If we reduce the search characters further, our accuracy will decrease.
In order to index the geohash into our index, we need to define a fieldType class, namely solr.GeoHashField:
<fieldtype name="geohash" class="solr.GeoHashField"/>
Also, we need to define a field for indexing or storage:
<field name="store_hash" type="geohash" indexed="true" stored="true"/>
Further operations such as indexing and querying are similar to those available with RPT, which we saw earlier.

