Implementing semantic search
Semantic search is when the search engine understands what the customer is searching for and provides results that are based on this understanding. Therefore, a search for the term shoes should display only items that are of type shoes instead of items with a description goes well with black shoes. We could argue that since we are boosting on the fields category, type, brand, color, and size, our results should match with what the customer is looking or searching for. However, this might not be the case. Let us take a more appropriate example to understand this situation.
Suppose a customer is searching for blue jeans where blue is intended to be the color and jeans is the type of apparel. What if there is a brand of products called blue jeans? The results coming from the search would not be as expected by the customer. As all the fields are being boosted by the same boost factor, the results will be a mix of the intended blue colored jeans and the products from the brand called blue jeans.
Now, how do we handle such a scenario? How would the search engine decide what products to show? We saw the same problem earlier with pink sweater and tried to solve it by proper boosting of fields. In this scenario, brand, type, and color are boosted by the same boost factor. The result is bound to be a mix of what is intended and what is not intended.
Semantic search could come to our rescue. We need the search engine to understand the meaning of blue jeans. Once the search engine understands that blue is the color and jeans is the type of clothing, it can boost the color and type fields only giving us exactly what we want.
The downside over here is that we have to take a call. We need to understand that blue jeans is a mix of color and type instead of brand or the other way around. The results that are returned will be heavily dependent on our call. The ideal way would be to give importance to different fields on the basis of the searches our site receives. Suppose that our site receives a lot of brand searches. We would then intend to make the search engine understand that blue jeans is a brand instead of type and color. On the other hand, if we analyze the searches happening on the site and find that the searches are mostly happening on type and color, we would have to make the search engine interpret blue jeans as type and color.
Let us try to implement the same.
To make the search engine understand the meaning of the terms, we need a dictionary that maps the terms to their meanings. This dictionary can be a separate index having just two fields, words and meanings. Let us create a separate core in our Solr installation that stores our dictionary:
cd<solr_installation>/example/solr mkdir -p dictionary/data mkdir -p dictionary/conf cp -r collection1/conf/* dictionary/conf
Define the Solr core in solr.xml file in the <solr_installation>/example/solr directory by adding the following snippet to the solr.xml file:
<solr sharedLib="lib"> <cores adminPath="/admin/cores"> <core name="collection1" instanceDir="/collection1"> <property name="dataDir" value="/collection1/data" /> </core> <core name="dictionary" instanceDir="/dictionary"> <property name="dataDir" value="/dictionary/data" /> </core> </cores> </solr>
The format of the solr.xml file will be changed in Solr 5.0. An optional parameter coreRootDirectory will be used to specify the directory from where the cores for the current Solr will be auto-discovered. The new format will be as follows:
<solr> <str name="adminHandler" >${adminHandler:org.apache.solr.handler.admin.CoreAdminHandler}< /str> <int name="coreLoadThreads">${coreLoadThreads:3}</int> <str name="coreRootDirectory">${coreRootDirectory:}</str> <str name="managementPath">${managementPath:}</str> <str name="sharedLib">${sharedLib:}</str> <str name="shareSchema">${shareSchema:false}</str> </solr>Also, as of Solr 5.0, the core discovery process will involve keeping a core.properties file in each Solr core folder. The format of the core.properties file will be as follows:
name=core1 shard=${shard:} collection=${collection:core1} config=${solrconfig:solrconfig.xml} schema=${schema:schema.xml} coreNodeName=${coreNodeName:}Solr parses all the directories inside the directory defined in coreRootDirectory parameter (which defaults to the Solr home), and if a core.properties file is found in any directory, the directory is considered to be a Solr core. Also, instanceDir is the directory in which the core.properties file was found. We can also have an empty core.properties file. In this case, the data directory will be in a directory called data directly below. The name of the core is assumed to be the name of the folder in which the core.properties file was discovered.
The Solr schema would contain only two fields, key and value. In this case, key would contain the field names and value would contain the bag of words that identify the field name in key:
<field name="key" type="lowercase" indexed="true" stored="true" required="true" /> <field name="value" type="wslc" indexed="true" stored="true" multiValued="true" />
Also, the key field needs to be marked as unique, as the key contains fields that are unique:
<uniqueKey>key</uniqueKey>
Also, we will need to change the default search field to value in the solrconfig.xml file for the dictionary core. For the request handler named /select, make the following change:
<str name="df">value</str>
Once the schema is defined, we need to restart Solr to see the new core on our Solr interface.
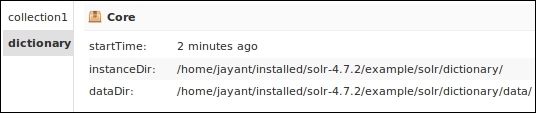
New core in Solr
In order to populate the dictionary index, we will need to upload the data_dictionary.csv file onto our index. The following command performs this function. Windows users can use the Solr admin interface to upload the CSV file:
curl "http://localhost:8983/solr/dictionary/update/csv?commit=true&f.value.split=true" --data-binary @data_dictionary.csv -H 'Content-type:application/csv; charset=utf-8' In order to check the dictionary index, just run a query q=*:*:
http://localhost:8983/solr/dictionary/select/?q=*:*
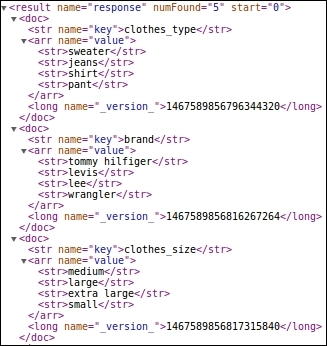
Query on the dictionary index
We can see each key has multiple strings as its values. For example, brand is defined by values tommy hilfiger, levis, lee, and wrangler.
Now that we have the dictionary index, we can query our input string and figure out what the customer is looking for. Let us input our search query blue jeans against the index and see the output:
http://localhost:8983/solr/dictionary/select/?q=blue%20jeans
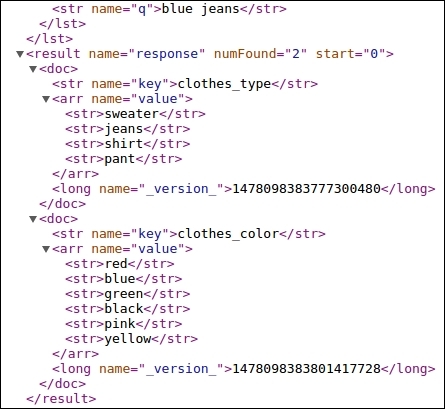
Query on the dictionary index
We can see that the output contains keys clothes_type and clothes_color. Now using this information, we will need to create our actual search query. In this case, the boost will be higher on these two fields than that on the remaining fields. Our query would now become:
q=blue%20jeans&qf=text%20cat^2%20name^2%20brand^2%20clothes_type^4%20clothes_color^4%20clothes_occassion^2&pf=text%20cat^3%20name^3%20brand^3%20clothes_type^5%20clothes_color^5%20clothes_occassion^3&fl=name,brand,clothes_type,clothes_color,score
We have two pairs of jeans in our index, one is blue and the other is black in color. The black pair is identified by the brand blue jeans. Earlier, if we had not incorporated dynamic boosting, the brand blue jeans would have been boosted higher as it is part of pf in the query. Now that we have identified that the customer is searching for clothes_type and clothes_color fields, we increase the boost for these fields in both qf and pf. Therefore, even though the keywords blue and jeans occur separately in fields clothes_type and clothes_color, we get them above the item where brand is blue jeans.
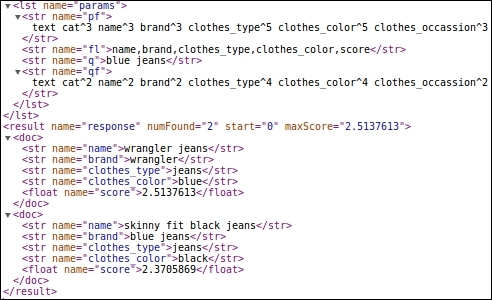
Search with dynamic boosting
This is one way of implementing semantic search. Note that we are performing two searches over here, the first identifies the input fields of the customer's interest and the second is our actual search where the boosting happens dynamically on the basis of the results of the first search.

