The SolrCloud solution
SolrCloud provides the high availability and failover solution for an index spanning over multiple Solr servers. If we go ahead with the traditional master-slave model and try implementing a sharded Solr cluster, we will need to create multiple master Solr servers, one for each shard and then slaves for these master servers. We need to take care of the sharding algorithm so that data is distributed across multiple shards. A search has to happen across these shards. Also, we need to take care of any shard that goes down and create a failover setup for the same. Load balancing of search queries is manual. We need to figure out how to distribute the search queries across multiple shards.
SolrCloud handles the scalability challenge for large indexes. It is a cluster of Solr servers or cores that can be bound together as a single Solr (cloud) server. SolrCloud is used when there is a need for highly scalable, fault-tolerant, distributed indexing and search capabilities. With SolrCloud, a single index can span across multiple Solr cores that can be on different Solr servers. Let us go through some of the concepts of SolrCloud:
- Collection: A logical index that spans across multiple Solr cores is called a collection. Thus, if we have a two-core Solr index on a single Solr server, it will create two collections with multiple cores in each collection. The cores can reside on multiple Solr servers.
- Shard: In SolrCloud, a collection can be sliced into multiple shards. A shard in SolrCloud will consist of multiple copies of the slice residing on different Solr cores. Therefore, in SolrCloud, a collection can have multiple shards. Each shard will have multiple Solr cores that are copies of each other.
- Leader: One of the cores within a shard will act as a leader. The leader is responsible for making sure that all the replicas within a shard are up to date.
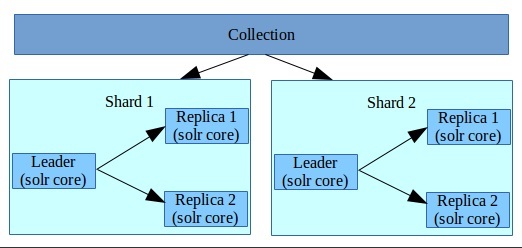
SolrCloud concepts – collection, shard, leader, replicas, core
SolrCloud has a central configuration that can be replicated automatically across all the nodes that are part of the SolrCloud cluster. The central configuration is maintained using a configuration management and coordination system known as Zookeeper. Zookeeper provides reliable coordination across a huge cluster of distributed systems. Solr does not have a master node. It uses Zookeeper to maintain node, shard, and replica information based on configuration files and schemas. Documents can be sent to any server, and Zookeeper will be able to figure out where to index them. If a leader for a shard goes down, another replica is automatically elected as the new leader using Zookeeper.
If a document is sent to a replica during indexing, it is forwarded to the leader. On receiving the document at a leader node, the SolrCloud determines whether the document should go to another shard and forwards it to the leader of that shard. The leader indexes the document and forwards the index notification to its replicas.
SolrCloud provides automatic failover. If a node goes down, indexing and search can happen over another node. Also, search queries are load balanced across multiple shards in the Solr cluster. Near Real Time Indexing is a feature where, as soon as a document is added to the index, the same is available for search. The latest Solr server contains commands for soft commit, which makes documents added to the index available for search immediately without going through the traditional commit process. We would still need to make a hard commit to make changes onto a stable data store. A soft commit can be carried out within a few seconds, while a hard commit takes a few minutes. SolrCloud exploits this feature to provide near real time search across the complete cluster of Solr servers.
It can be difficult to determine the number of shards in a Solr collection in the first go. Moreover, creating more shards or splitting a shard into two can be tedious task if done manually. Solr provides inbuilt commands for splitting a shard. The previous shard is maintained and can be deleted at a later date.
SolrCloud also provides the ability to search the complete collection of one or more particular shards if needed.
SolrCloud removes all the hassles of maintaining a cluster of Solr servers manually and provides an easy interface to handle distributed search and indexing over a cluster of Solr servers with automatic failover. We will be discussing SolrCloud in , SolrCloud.

