6. Сетевое взаимодействие в Linux и BPF
С точки зрения сетевого взаимодействия мы используем программы BPF для двух основных целей — захвата пакетов и фильтрации. Это означает, что программа пользовательского пространства может прикрепить фильтр к любому сокету, извлечь информацию о пакетах, проходящих через него, и разрешить, или запретить, или перенаправить определенные типы пакетов в зависимости от того, как они определены на этом уровне.
Цель этой главы — объяснить, как программы BPF могут взаимодействовать со структурой буфера сокетов на разных этапах пути к сетевым данным в сетевом стеке ядра Linux. Пока определим два наиболее общих случая:
• программы, связанные с сокетами;
• программы, написанные для основанного на BPF классификатора для управления трафиком.

Socket Buffer, также называемая SKB или sk_buff, — это структура ядра, которая создается и используется для каждого отправленного или полученного пакета. Читая SKB, вы можете передавать или отбрасывать пакеты и заполнять карты BPF для создания статистики и метрик потока, иллюстрирующих трафик.
Кроме того, некоторые программы BPF позволяют манипулировать SKB и, соответственно, преобразовывать конечные пакеты, чтобы перенаправить или изменить их. Например, в системе только с IPv6 вы можете написать программу, которая преобразует все полученные пакеты из IPv4 в IPv6 с помощью SKB.
Понимание различий между разными видами программ, которые мы можем написать, и того, как разные программы позволяют достичь одной и той же цели, является ключом к пониманию BPF и eBPF в сети. В следующем разделе рассмотрим первые два способа фильтрации на уровне сокетов: с помощью классических фильтров BPF и программ eBPF, подключенных к сокетам.
BPF и фильтрация пакетов
Как уже говорилось, фильтры BPF и программы eBPF являются основными вариантами применения программ BPF в контексте сетевого взаимодействия, однако изначально программы BPF были синонимом фильтрации пакетов.
Фильтрация пакетов по-прежнему является одним из наиболее важных участков. В свое время она была расширена от классического BPF (cBPF) до современного eBPF в Linux 3.19 добавлением функций, связанных с картами, к типу программы фильтра BPF_PROG_TYPE_SOCKET_FILTER.
Фильтры используются в основном в следующих трех сценариях высокого уровня.
• Отбрасывание трафика в реальном времени (например, разрешение только трафика протокола пользовательских дейтаграмм (UDP) и отбрасывание чего-либо еще).
• Наблюдение в реальном времени за отфильтрованным набором пакетов, поступающих в работающую систему.
• Ретроспективный анализ сетевого трафика, захваченного в работающей системе, например, в формате pcap.

Термин pcap происходит от соединения двух слов: packet («пакет») и capture («захват»). Формат pcap реализован как специфичный для домена API для захвата пакетов в библиотеке Packet Capture Library (libpcap). Этот формат полезен в сценариях отладки, когда нужно сохранить набор пакетов, захваченных в действующей системе, непосредственно в файл для последующего анализа с помощью инструмента, который может читать поток пакетов, экспортируемых в формате pcap.
В следующих разделах мы рассмотрим два способа применения концепции фильтрации пакетов в программах BPF. Сначала покажем, как обычный широко распространенный инструмент, такой как tcpdump, выступает в качестве высокоуровневого интерфейса для программ BPF, работающих как фильтры. Затем напишем и загрузим собственную программу, используя тип BPF-программы BPF_PROG_TYPE_SOCKET_FILTER.
Выражения tcpdump и BPF
Одним из инструментов командной строки для анализа и наблюдения трафика в реальном времени, о котором знают почти все, является tcpdump. По сути, это интерфейс для libpcap, который позволяет пользователю определять высокоуровневые выражения фильтрации. tcpdump выполняет чтение пакетов из выбранного вами сетевого (или любого другого) интерфейса, а затем записывает содержимое полученных пакетов в стандартный вывод или файл. Затем поток пакетов может быть отфильтрован с применением синтаксиса фильтра pcap. Синтаксис фильтра pcap — это предметно-ориентированный язык (DSL) для фильтрации пакетов с использованием высокоуровневого набора выражений, созданных с помощью набора примитивов, которые, как правило, легче для запоминания, чем ассемблер BPF. В этой главе не описываются все возможные примитивы и выражения в синтаксисе фильтра pcap, поскольку весь набор можно найти в man7pcap-filter, но мы рассмотрим некоторые примеры, чтобы вы могли почувствовать его мощь.
Представим, что мы работаем на машине Linux, на которой имеется веб-сервер на порте 8080. Этот веб-сервер не регистрирует запросы, и мы хотим узнать, получает ли он их на самом деле и как, потому что клиент обслуживаемого приложения жалуется на невозможность получить ответ при просмотре страницы продуктов. На данный момент мы знаем только, что он подключается к одной из наших страниц, где представлены продукты, используя веб-приложение, обслуживаемое этим веб-сервером. Но, как это обычно бывает, понятия не имеем, что может быть причиной проблемы, потому что конечные пользователи обычно не собираются отлаживать сервисы за нас. Вдобавок, к сожалению, мы не позаботились о какой-либо стратегии ведения журналов или отчетов об ошибках, поэтому совершенно не понимаем, в чем кроется проблема. К счастью, есть инструмент, способный прийти нам на помощь! Это tcpdump, который можно настроить для фильтрации только пакетов IPv4, проходящих в нашей системе и использующих протокол управления передачей (TCP) через порт 8080. Так мы сможем проанализировать трафик веб-сервера и выявить ошибочные запросы.
Отфильтровать пакеты с помощью tcpdump мы можем командой:
# tcpdump -n 'ip and tcp port 8080'
Рассмотрим, что здесь происходит:
• -n указывает tcpdump не преобразовывать адреса в соответствующие имена, так как мы хотим видеть именно адреса источника и получателя;
• ipandtcpport8080 — это выражение фильтра pcap, которое tcpdump будет использовать для фильтрации пакетов. ip означает IPv4, and является соединением для задания более сложного фильтра, что позволяет добавлять больше выражений для сопоставления. Затем мы указываем, что нас интересуют только пакеты TCP, поступающие в порт 8080 или из него, с помощью tcpport8080. В данном конкретном случае лучше было бы задействовать выражение tcpdstport8080, потому что нас интересуют только пакеты, чей порт назначения — 8080, а не те, что выходят из него.
Результат работы этой команды будет примерно таким (без лишних частей, например полных TCP-рукопожатий):
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on wlp4s0, link-type EN10MB (Ethernet), capture size 262144 bytes
12:04:29.593703 IP 192.168.1.249.44206 > 192.168.1.63.8080: Flags [P.],
seq 1:325, ack 1, win 343,
options [nop,nop,TS val 25580829 ecr 595195678],
length 324: HTTP: GET / HTTP/1.1
12:04:29.596073 IP 192.168.1.63.8080 > 192.168.1.249.44206: Flags [.],
seq 1:1449, ack 325, win 507,
options [nop,nop,TS val 595195731 ecr 25580829],
length 1448: HTTP: HTTP/1.1 200 OK
12:04:29.596139 IP 192.168.1.63.8080 > 192.168.1.249.44206: Flags [P.],
seq 1449:2390, ack 325, win 507,
options [nop,nop,TS val 595195731 ecr 25580829],
length 941: HTTP
12:04:46.242924 IP 192.168.1.249.44206 > 192.168.1.63.8080: Flags [P.],
seq 660:996, ack 4779, win 388,
options [nop,nop,TS val 25584934 ecr 595204802],
length 336: HTTP: GET /api/products HTTP/1.1
12:04:46.243594 IP 192.168.1.63.8080 > 192.168.1.249.44206: Flags [P.],
seq 4779:4873, ack 996, win 503,
options [nop,nop,TS val 595212378 ecr 25584934],
length 94: HTTP: HTTP/1.1 500 Internal Server Error
12:04:46.329245 IP 192.168.1.249.44234 > 192.168.1.63.8080: Flags [P.],
seq 471:706, ack 4779, win 388,
options [nop,nop,TS val 25585013 ecr 595205622],
length 235: HTTP: GET /favicon.ico HTTP/1.1
12:04:46.331659 IP 192.168.1.63.8080 > 192.168.1.249.44234: Flags [.],
seq 4779:6227, ack 706, win 506,
options [nop,nop,TS val 595212466 ecr 25585013],
length 1448: HTTP: HTTP/1.1 200 OK
12:04:46.331739 IP 192.168.1.63.8080 > 192.168.1.249.44234: Flags [P.],
seq 6227:7168, ack 706, win 506,
options [nop,nop,TS val 595212466 ecr 25585013],
length 941: HTTP
Теперь ситуация во многом прояснилась! У нас есть множество запросов, которые возвращают код состояния 200OK, и еще один — с кодом внутренней ошибки 500InternalServerError в конечной точке /api/products. Клиент прав: у нас проблема с перечислением продуктов!
Вы можете спросить: какое отношение средства фильтрации pcap и tcpdump имеют к программам BPF, если у них собственный синтаксис? Фильтры pcap в Linux скомпилированы в программы BPF! И, поскольку tcpdump использует фильтры pcap для фильтрации, это означает, что каждый раз, выполняя tcpdump с применением фильтра, вы фактически компилируете и загружаете программу BPF для фильтрации пакетов. К счастью, передав tcpdump флаг -d, вы можете вывести инструкции BPF, которые будут загружены с помощью указанного фильтра:
tcpdump -d 'ip and tcp port 8080'
Фильтр такой же, как и в предыдущем примере, но благодаря флагу -d вывод представляет собой набор инструкций ассемблера BPF.
Вывод команды будет следующим:
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 12
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 12
(004) ldh [20]
(005) jset #0x1fff jt 12 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 14]
(008) jeq #0x1f90 jt 11 jf 9
(009) ldh [x + 16]
(010) jeq #0x1f90 jt 11 jf 12
(011) ret #262144
(012) ret #0
Проанализируем полученное.
• ldh[12]. Загрузить (ld) половинное слово (h) (16 бит) из аккумулятора со смещением 12, что является полем Ethertype (рис. 6.1).

Рис. 6.1. Структура кадра Ethernet канального уровня
• jeq#0x800jt2jf12. Выполнить условный переход: проверить, равно ли значение Ethertype из предыдущей инструкции 0x800, что является идентификатором для IPv4, и затем использовать пункты назначения перехода — 2, если истина (jt), и 12 — если ложь (jf). Так что обработка будет продолжена до следующей инструкции, если интернет-протокол — IPv4, в ином случае инструкция перейдет в конец и вернет ноль.
• ldb[23]. Эта инструкция загрузит поле протокола более высокого уровня из кадра IP, который может быть найден по смещению 23. Смещение 23 определяется суммированием 14 байт заголовков в кадре канального уровня Ethernet (см. рис. 6.1) и позиции протокола в заголовке IPv4, которая равна 9: 14 + 9 = 23.
• jeq#0x6jt4jf12. Снова условный переход. В данном случае убеждаемся, что предыдущий извлеченный протокол равен 0x6, что соответствует TCP. Если это так, переходим к следующей инструкции (4), если не так — переходим к концу (12) и отбрасываем пакет.
• ldh[20]. Еще одна инструкция загрузки половинного слова — в данном случае загрузка суммы значений смещения пакета и смещения фрагмента из заголовка IPv4.
• jset#0x1fffjt126. Инструкция jset перейдет на 12, если какие-либо данные, найденные в смещении фрагмента, верны, в ином случае перейдет на 6, что является следующей инструкцией. Смещение после инструкции jset0x1fff приказывает инструкции рассматривать только последние 13 байт данных (в расширенном виде 0001111111111111).
• ldxb4*([14]&0xf). В x загружается (ld) то, чем является b. Эта инструкция загрузит в x значение длины заголовка IP.
• ldh[x+14]. Еще одна инструкция загрузки полуслова, которая получит значение со смещением (x+14), то есть длину IP-заголовка + 14, что в пакете соответствует расположению порта источника.
• jeq#0x1f90jt11jf9. Если значение в (x+14) равно 0x1f90 (8080 в десятичном виде), то есть исходный порт 8080, то инструкция перейдет к 11, а если это не так, проверит, находится ли пункт назначения на порте 8080, перейдя на 9.
• ldh[x+16]. Еще одна инструкция загрузки половинного слова, которая получает значение по смещению (x+16), что соответствует местоположению порта назначения в пакете.
• jeq#0x1f90jt11jf12. Еще один условный переход. На этот раз проверяется, равен ли пункт назначения 8080: если это так — перейти к 11, если нет — перейти к 12 и отбросить пакет.
• ret#262144. Когда эта инструкция достигнута, совпадение найдено и нужно вернуть соответствующую длину (по умолчанию 262 144 байта). Этот параметр можно настроить с помощью ключа -s в tcpdump.
Приведем «правильный» пример. Как мы говорили, для нашего веб-сервера нужно учитывать только пакеты, у которых 8080 — порт назначения, а не источник, поэтому в фильтре tcpdump следует указать это значение в поле dst:
tcpdump -d 'ip and tcp dst port 8080'
В этом случае дамп набора инструкций такой же, как в предыдущем примере, но, как видите, в нем отсутствует часть, которая отвечала за поиск пакетов, для которых порт 8080 — источник. Действительно, здесь нет ldh[x+14] и соответствующей инструкции jeq#0x1f90jt11jf9:
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 10
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 10
(004) ldh [20]
(005) jset #0x1fff jt 10 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 16]
(008) jeq #0x1f90 jt 9 jf 10
(009) ret #262144
(010) ret #0
Помимо простого анализа сгенерированного ассемблерного кода из tcpdump, как мы это делали, вы можете написать собственный код для фильтрации сетевых пакетов. Оказывается, самая большая проблема в этом случае — отладить выполнение кода, чтобы убедиться, что он соответствует вашим ожиданиям. Для этого в дереве исходников ядра в tools/bpf есть инструмент bpf_dbg.c, который, по сути, является отладчиком, позволяющим загрузить программу и файл .pcap для пошагового выполнения.

tcpdump может также читать напрямую из файла .pcap и применять к нему фильтры BPF.
Фильтрация пакетов для сырых сокетов
Тип программы BPF_PROG_TYPE_SOCKET_FILTER позволяет присоединить программу BPF к сокету. Все полученные сокетом пакеты будут переданы программе в виде структуры sk_buff, и затем программа сможет решить, следует их отбрасывать или разрешать. Программы такого вида также имеет возможность доступа к картам и работы в них.
Рассмотрим на примере, как можно использовать такую программу BPF.
Целью программы-примера является подсчет количества пакетов TCP, UDP и ICMP, передаваемых через интересующий нас интерфейс. Нам нужны:
• BPF-программа, которая может видеть потоки пакетов;
• код для загрузки программы и ее подключения к сетевому интерфейсу;
• сценарий для компиляции программы и запуска загрузчика.
На этом этапе можно написать программу BPF двумя способами: в виде кода C, который затем компилируется в файл ELF, или непосредственно в виде сборки BPF. Мы решили использовать код на C, чтобы показать абстракцию более высокого уровня и способ применения Clang для компиляции программы. Важно отметить, что для создания программы мы берем заголовки и помощники, доступные только в дереве исходных кодов ядра Linux, поэтому первое, что нужно сделать, — получить их копию с помощью Git. Чтобы избежать коллизий, воспользуйтесь тем же коммитом SHA, с помощью которого создан этот пример:
export KERNEL_SRCTREE=/tmp/linux-stable
git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux-stable.git
$KERNEL_SRCTREE
cd $KERNEL_SRCTREE
git checkout 4b3c31c8d4dda4d70f3f24a165f3be99499e0328

Для поддержки BPF вам потребуется clang> = 3.4.0 с llvm> = 3.7.1. Чтобы проверить, поддерживается ли BPF в вашей установке, используйте команду llc -version и посмотрите, есть ли у нее цель BPF.
Теперь, когда вы разбираетесь в фильтрации сокетов, можно приступить к BPF-программе типа socket.
Программа BPF
Основное, что должна сделать программа BPF, — получить доступ к пакету, который она получает. Проверьте тип протокола: TCP, UDP или ICMP, а затем увеличьте значение счетчика в массиве карты на конкретном ключе для найденного протокола.
Для этой программы мы собираемся воспользоваться механизмом загрузки, который анализирует ELF-файлы, задействуя помощники, находящиеся в samples/bpf/bpf_load.c в дереве исходного кода ядра. Функция загрузки load_bpf_file способна распознавать некоторые конкретные заголовки разделов ELF и связывать их с соответствующими типами программ. Вот как выглядит этот код:
bool is_socket = strncmp(event, "socket", 6) == 0;
bool is_kprobe = strncmp(event, "kprobe/", 7) == 0;
bool is_kretprobe = strncmp(event, "kretprobe/", 10) == 0;
bool is_tracepoint = strncmp(event, "tracepoint/", 11) == 0;
bool is_raw_tracepoint = strncmp(event, "raw_tracepoint/", 15) == 0;
bool is_xdp = strncmp(event, "xdp", 3) == 0;
bool is_perf_event = strncmp(event, "perf_event", 10) == 0;
bool is_cgroup_skb = strncmp(event, "cgroup/skb", 10) == 0;
bool is_cgroup_sk = strncmp(event, "cgroup/sock", 11) == 0;
bool is_sockops = strncmp(event, "sockops", 7) == 0;
bool is_sk_skb = strncmp(event, "sk_skb", 6) == 0;
bool is_sk_msg = strncmp(event, "sk_msg", 6) == 0;
Первое, что делает код, — это создает ассоциацию между заголовком раздела и внутренней переменной, например, как для SEC("socket"), в итоге получим boolis_socket=true.
Дальше в этом же файле мы увидим набор инструкций if, которые создают связь между заголовком и фактическим типом prog_type, поэтому для is_socket мы получаем BPF_PROG_TYPE_SOCKET_FILTER:
if (is_socket) {
prog_type = BPF_PROG_TYPE_SOCKET_FILTER;
} else if (is_kprobe || is_kretprobe) {
prog_type = BPF_PROG_TYPE_KPROBE;
} else if (is_tracepoint) {
prog_type = BPF_PROG_TYPE_TRACEPOINT;
} else if (is_raw_tracepoint) {
prog_type = BPF_PROG_TYPE_RAW_TRACEPOINT;
} else if (is_xdp) {
prog_type = BPF_PROG_TYPE_XDP;
} else if (is_perf_event) {
prog_type = BPF_PROG_TYPE_PERF_EVENT;
} else if (is_cgroup_skb) {
prog_type = BPF_PROG_TYPE_CGROUP_SKB;
} else if (is_cgroup_sk) {
prog_type = BPF_PROG_TYPE_CGROUP_SOCK;
} else if (is_sockops) {
prog_type = BPF_PROG_TYPE_SOCK_OPS;
} else if (is_sk_skb) {
prog_type = BPF_PROG_TYPE_SK_SKB;
} else if (is_sk_msg) {
prog_type = BPF_PROG_TYPE_SK_MSG;
} else {
printf("Unknown event '%s'\n", event);
return -1;
}
Теперь, поскольку мы хотим написать программу типа BPF_PROG_TYPE_SOCKET_FILTER, нужно указать SEC("socket") в качестве заголовка ELF для нашей функции, которая будет действовать как точка входа для программы BPF.
Как видно из этого списка, существует множество типов программ, связанных с сокетами и общими сетевыми операциями. В этой главе мы показываем примеры с BPF_PROG_TYPE_SOCKET_FILTER, а определение всех других типов программ приведено в главе 2. Более того, в главе 7 мы обсудим программы XDP с типом BPF_PROG_TYPE_XDP.
Поскольку мы хотим сохранять количество пакетов для каждого протокола, с которым сталкиваемся, нам необходимо создать карту «ключ/значение», где протокол является ключом, а пакеты считаются значениями. Для этой цели можем использовать BPF_MAP_TYPE_ARRAY:
struct bpf_map_def SEC("maps") countmap = {
.type = BPF_MAP_TYPE_ARRAY,
.key_size = sizeof(int),
.value_size = sizeof(int),
.max_entries = 256,
};
Карта определяется с помощью структуры bpf_map_def, для ссылок в программе она будет называться countmap.
На этом этапе можно написать какой-то код для подсчета пакетов. Мы знаем, что программы типа BPF_PROG_TYPE_SOCKET_FILTER для этого подходят, так как помогают увидеть все пакеты, проходящие через интерфейс. Поэтому мы прикрепляем программу к правильному заголовку с помощью SEC("socket"):
SEC("socket")
int socket_prog(struct __sk_buff *skb) {
int proto = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
int one = 1;
int *el = bpf_map_lookup_elem(&countmap, &proto);
if (el) {
(*el)++;
} else {
el = &one;
}
bpf_map_update_elem(&countmap, &proto, el, BPF_ANY);
return 0;
}
После присоединения заголовка ELF мы можем использовать функцию load_byte для извлечения раздела протокола из структуры sk_buff. Затем применяем идентификатор протокола в качестве ключа для выполнения операции bpf_map_lookup_elem, чтобы извлечь текущее значение счетчика из таблицы подсчетов и иметь возможность увеличить его или установить в 1, если это лишь первый пакет. Теперь можно обновить карту с увеличенным значением с помощью bpf_map_update_elem.
Чтобы скомпилировать программу в файл ELF, мы просто берем Clang с -targetbpf. Эта команда создает файл bpf_program.o, который будем загружать с помощью загрузчика:
clang -O2 -target bpf -c bpf_program.c -o bpf_program.o
Загрузка и подключение к сетевому интерфейсу
Загрузчик — это программа, которая фактически открывает наш скомпилированный двоичный файл BPF ELF bpf_program.o и связывает определенную программу BPF и ее карты с сокетом, который создается на основе наблюдаемого интерфейса (в нашем случае lo — локального петлевого интерфейса).
Наиболее важной частью работы загрузчика является сама загрузка файла ELF:
if (load_bpf_file(filename)) {
printf("%s", bpf_log_buf);
return 1;
}
sock = open_raw_sock("lo");
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, prog_fd,
sizeof(prog_fd[0]))) {
printf("setsockopt %s\n", strerror(errno));
return 0;
}
Это дополнит массив prog_fd еще одним элементом, то есть файловым дескриптором нашей загруженной программы, который мы теперь можем связать с дескриптором сокета петлевого интерфейса, открытого с помощью open_raw_sock.
Связывание выполняется установкой опции SO_ATTACH_BPF для необработанного сокета, открытого в интерфейсе. На этом этапе загрузчик пользовательского пространства может найти элементы карты по мере того, как ядро отправляет их:
for (i = 0; i < 10; i++) {
key = IPPROTO_TCP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &tcp_cnt) == 0);
key = IPPROTO_UDP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &udp_cnt) == 0);
key = IPPROTO_ICMP;
assert(bpf_map_lookup_elem(map_fd[0], &key, &icmp_cnt) == 0);
printf("TCP %d UDP %d ICMP %d packets\n", tcp_cnt, udp_cnt, icmp_cnt);
sleep(1);
}
Для выполнения поиска мы подсоединяемся к карте массива, используя цикл for и bpf_map_lookup_elem, чтобы прочитать и вывести значения для счетчиков пакетов TCP, UDP и ICMP.
Теперь осталось лишь скомпилировать программу!
Поскольку она использует библиотеку libbpf, нужно скомпилировать ее из дерева исходного кода ядра, которое мы только что клонировали:
$ cd $KERNEL_SRCTREE/tools/lib/bpf
$ make
Сейчас, когда у нас есть libbpf, можем скомпилировать загрузчик с помощью следующего сценария:
KERNEL_SRCTREE=$1
LIBBPF=${KERNEL_SRCTREE}/tools/lib/bpf/libbpf.a
clang -o loader-bin -I${KERNEL_SRCTREE}/tools/lib/bpf/ \
-I${KERNEL_SRCTREE}/tools/lib -I${KERNEL_SRCTREE}/tools/include \
-I${KERNEL_SRCTREE}/tools/perf -I${KERNEL_SRCTREE}/samples \
${KERNEL_SRCTREE}/samples/bpf/bpf_load.c \
loader.c "${LIBBPF}" -lelf
Как видите, сценарий включает в себя несколько заголовков и библиотеку libbpf из самого ядра, поэтому он должен знать, где найти исходный код ядра. Для этого вы можете заменить в нем $KERNEL_SRCTREE или просто записать этот сценарий в файл и использовать его:
$ ./build-loader.sh /tmp/linux-stable
На данном этапе загрузчик создаст файл loader-bin, который может быть наконец запущен вместе с файлом ELF программы BPF (требуются права root):
# ./loader-bin bpf_program.o
После загрузки и запуска программа сделает десять дампов, по одному за секунду, показывая количество пакетов для каждого из трех рассмотренных протоколов. Поскольку программа подключена к петлевому устройству lo, наряду с загрузчиком вы можете запустить ping и увидеть увеличение счетчика ICMP.
Выполните ping для генерации ICMP-трафика на localhost:
$ ping -c 100 127.0.0.1
При этом localhost пингуется 100 раз и получается что-то вроде следующего:
PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data.
64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.100 ms
64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.107 ms
64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.093 ms
64 bytes from 127.0.0.1: icmp_seq=4 ttl=64 time=0.102 ms
64 bytes from 127.0.0.1: icmp_seq=5 ttl=64 time=0.105 ms
64 bytes from 127.0.0.1: icmp_seq=6 ttl=64 time=0.093 ms
64 bytes from 127.0.0.1: icmp_seq=7 ttl=64 time=0.104 ms
64 bytes from 127.0.0.1: icmp_seq=8 ttl=64 time=0.142 ms
Затем в другом терминале мы, наконец, можем запустить программу BPF:
# ./loader-bin bpf_program.o
Начало вывода будет выглядеть так:
TCP 0 UDP 0 ICMP 0 packets
TCP 0 UDP 0 ICMP 4 packets
TCP 0 UDP 0 ICMP 8 packets
TCP 0 UDP 0 ICMP 12 packets
TCP 0 UDP 0 ICMP 16 packets
TCP 0 UDP 0 ICMP 20 packets
TCP 0 UDP 0 ICMP 24 packets
TCP 0 UDP 0 ICMP 28 packets
TCP 0 UDP 0 ICMP 32 packets
TCP 0 UDP 0 ICMP 36 packets
Теперь вы знаете достаточно о том, что нужно для фильтрации пакетов в Linux с помощью программы eBPF фильтра сокетов. Но это не единственный способ! Возможно, вы захотите подключить подсистему планирования пакетов с помощью ядра, а не непосредственно на сокетах. В следующем разделе рассмотрим эту возможность.
Классификатор управления трафиком на основе BPF
Управление трафиком относится к архитектуре подсистемы ядра для планирования пакетов. Она состоит из механизмов и систем очередей, которые могут определять, как пакеты передаются и принимаются.
Некоторые варианты управления трафиком включают следующие действия:
• определение приоритетов для пакетов конкретных типов;
• отбрасывание пакетов определенных типов;
• распределение пропускной способности,
но не ограничиваются ими.
Учитывая, что в общем случае управление трафиком — это способ перераспределить сетевые ресурсы в системе для того, чтобы извлечь максимальную выгоду, следует использовать конкретные специфические конфигурации управления трафиком в зависимости от типа приложений, которые вы собираетесь запустить. Управление трафиком предоставляет программируемый классификатор, называемый cls_bpf, позволяющий подключаться к различным уровням операций планирования, на которых они могут считывать и обновлять буфер сокета и метаданные пакета для таких процедур, как формирование трафика, трассировка, предварительная обработка и многое другое.
Поддержка eBPF в cls_bpf была реализована в ядре 4.1, что означает: программа такого типа имеет доступ к картам eBPF, способна поддерживать завершающие вызовы, может обращаться к метаданным туннеля IPv4/IPv6 и в общем случае использовать помощники и утилиты, поставляемые с eBPF.
Инструменты для взаимодействия с сетевой конфигурацией, связанной с управлением трафиком, являются частью пакета iproute2 (https://oreil.ly/SYGwI), в который включены ip и tc — инструменты для конфигурирования сетевых интерфейсов и параметров управления трафиком соответственно.
На этом этапе для изучения управления трафиком может потребоваться специальная терминология. Этому посвящен следующий раздел.
Терминология
Как уже упоминалось, между управлением трафиком и программами BPF существуют точки взаимодействия, поэтому вам необходимо понимать некоторые концепции управления трафиком. Если вы уже освоили управление трафиком, можете пропустить раздел терминологии и перейти непосредственно к примерам.
Организация очереди
При организации очереди (qdisc) определяются объекты планирования, используемые для постановки в очередь пакетов, отправленных на интерфейс, путем изменения способа их отправки. Эти объекты могут быть бесклассовыми или классифицированными.
По умолчанию qdisc — это pfifo_fast, который является бесклассовым и ставит в очередь пакеты в трех очередях FIFO («первым пришел — первым вышел»), взятые из очереди в зависимости от их приоритета. Этот qdisc не используется для виртуальных устройств, таких как loopback (lo) или устройства Virtual Ethernet (veth), которые вместо этого применяют noqueue. Помимо того что pfifo_fast является хорошим выбором по умолчанию для своего алгоритма планирования, он не требует никакого конфигурирования для работы.
Виртуальные интерфейсы можно отличить от физических интерфейсов (устройств) с помощью псевдофайловой системы /sys:
ls -la /sys/class/net
total 0
drwxr-xr-x 2 root root 0 Feb 13 21:52 .
drwxr-xr-x 64 root root 0 Feb 13 18:38 ..
lrwxrwxrwx 1 root root 0 Feb 13 23:26 docker0 ->
../../devices/virtual/net/docker0
Lrwxrwxrwx 1 root root 0 Feb 13 23:26 enp0s31f6 ->
../../devices/pci0000:00/0000:00:1f.6/net/enp0s31f6
Lrwxrwxrwx 1 root root 0 Feb 13 23:26 lo -> ../../devices/virtual/net/lo
Если пока не все ясно, не расстраивайтесь. Если вы никогда не слышали о qdisc, можете использовать команду ipa для отображения списка сетевых интерфейсов, настроенных в текущей системе:
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue
state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp0s31f6: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc
fq_codel stateDOWN group default
qlen 1000
link/ether 8c:16:45:00:a7:7e brd ff:ff:ff:ff:ff:ff
6: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc
noqueue state DOWN group default
link/ether 02:42:38:54:3c:98 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:38ff:fe54:3c98/64 scope link
valid_lft forever preferred_lft forever
Этот список уже о чем-то говорит. Можете ли вы найти в нем слово qdisc? Проанализируем ситуацию.
• В этой системе три сетевых интерфейса — lo, enp0s31f6 и docker0.
• Интерфейс lo — виртуальный, поэтому у него есть qdiscnoqueue.
• enp0s31f6 — это физический интерфейс. А почему здесь имеется qdisc с fq_codel (честная задержка в очереди)? Разве pfifo_fast не должен быть установлен по умолчанию? Оказывается, система, на которой мы тестируем команды, работает под управлением Systemd, которая по-разному устанавливает qdisc по умолчанию, используя параметр ядра net.core.default_qdisc.
• Интерфейс docker0 является интерфейсом моста, поэтому он задействует виртуальное устройство, а для него применяется noqueue qdisc.
noqueue qdisc не имеет классов, планировщика или классификатора. Все, что он делает, — пытается отправить пакеты немедленно. Как уже говорилось, noqueue по умолчанию используется виртуальными устройствами, но это также qdisc, который вступает в силу для любого интерфейса, если вы удаляете qdisc, связанный с этим интерфейсом в настоящий момент.
fq_codel — это бесклассовый qdisc, который классифицирует входящие пакеты с помощью стохастической модели, чтобы иметь возможность честно ставить в очередь потоки трафика.
Теперь ситуация должна быть более понятной: мы задействовали команду ip, чтобы найти информацию о qdisc, но оказалось, что среди инструментов iproute2 есть инструмент под названием tc, имеющий специальную подкоманду, которую вы можете использовать для вывода списка всех qdisc:
tc qdisc ls
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev enp0s31f6 root refcnt 2 limit 10240p flows 1024
quantum 1514
target 5.0ms interval 100.0ms memory_limit 32Mb ecn
qdisc noqueue 0: dev docker0 root refcnt 2
Здесь гораздо больше информации! Для docker0 и lo мы в основном видим ту же информацию, что и для ipa, но для enp0s31f6, например, получаем следующее:
• количество входящих пакетов, которые он может обработать, ограничено — 10 240;
• стохастическая модель, используемая fq_codel, хочет направить трафик в разные потоки, и этот вывод содержит информацию о том, сколько их существует, — 1024.
Теперь, когда ключевые понятия qdisc описаны, в следующем разделе можем подробнее рассмотреть классовые и бесклассовые qdisc, чтобы понять, в чем их различия и какие из них подходят для программ BPF.
Классовые qdisc, фильтры и классы
Классовые qdisc позволяют определять классы для разных типов трафика, поэтому к ним можно применять разные правила. Наличие класса для qdisc означает, что он способен содержать дополнительные qdisc. При таком типе иерархии мы можем использовать фильтр (классификатор) для классификации трафика путем определения следующего класса, в который должен быть помещен пакет.
С помощью фильтров пакеты назначают определенному классу в зависимости от их типа. Их задействуют внутри классовых qdisc, чтобы определить, в каком классе следует поместить пакет в очередь (два или более фильтра могут отражать один и тот же класс) (рис. 6.2). Каждый фильтр применяет классификатор для сортировки пакетов на основе содержащейся в них информации.
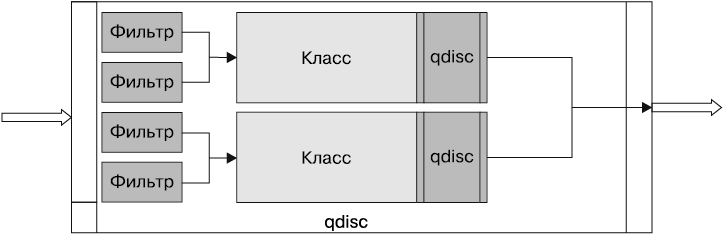
Рис. 6.2. Классовый qdisc с фильтрами
Как уже упоминалось, cls_bpf — это классификатор, который мы хотим использовать при написании BPF-программ для управления трафиком. В следующих разделах будет приведен конкретный пример того, как это делается.
Классы — это объекты, которые могут существовать только в классовом qdisc, с их помощью управляют трафиком для создания иерархий. Сложные иерархии возможны благодаря тому, что к классу могут быть прикреплены фильтры, которые в дальнейшем можно применять в качестве точки входа для другого класса или qdisc.
Бесклассовые qdisc
Бесклассовый qdisc — это qdisc, у которого не может быть дочерних элементов, потому что ему не разрешено иметь связанные классы. Это означает, что к бесклассовому qdisc невозможно прикрепить фильтры. Поскольку бесклассовые qdisc не могут иметь дочерних элементов, мы не можем добавлять к ним фильтры и классификаторы, так что они неинтересны с точки зрения BPF, но все же полезны для решения простых задач управления трафиком.
Получив определенные знания о qdisc, фильтрах и классах, рассмотрим, как писать программы BPF для классификатора cls_bpf.
Программа классификатора управления трафиком с использованием cls_bpf
Как уже говорилось, управление трафиком — это мощный механизм, который стал еще более мощным благодаря классификаторам. Среди классификаторов есть такой, который позволяет запрограммировать путь сетевых данных, — классификатор cls_bpf. Это особенный классификатор, потому что он может запускать программы BPF. Это означает, что cls_bpf позволит вам внедряться в свои программы BPF непосредственно на входном и выходном уровнях, а запуск программ BPF, подключенных к этим уровням, означает, что они смогут получить доступ к структуре sk_buff для соответствующих пакетов.
Чтобы лучше понять взаимосвязь между управлением трафиком и программами BPF, посмотрите на рис. 6.3, где показано, как программы BPF загружаются в классификатор cls_bpf. Отметьте, что такие программы подключены к входным и выходным qdisc. Все другие взаимодействия в контексте также описаны. Считая сетевой интерфейс точкой входа для сетевого трафика, вы увидите следующее.
• Сначала трафик направляется на вход управления трафиком.
• Затем ядро выполняет программу BFP, загруженную из пространства пользователя для каждого входящего запроса.
• После выполнения входной программы управление передается сетевому стеку, который информирует приложение пользователя о сетевом событии.
• После того как приложение дает ответ, управление передается на выход управления трафиком с использованием другой программы BPF, которая после завершения возвращает управление ядру.
• Клиенту дается ответ.
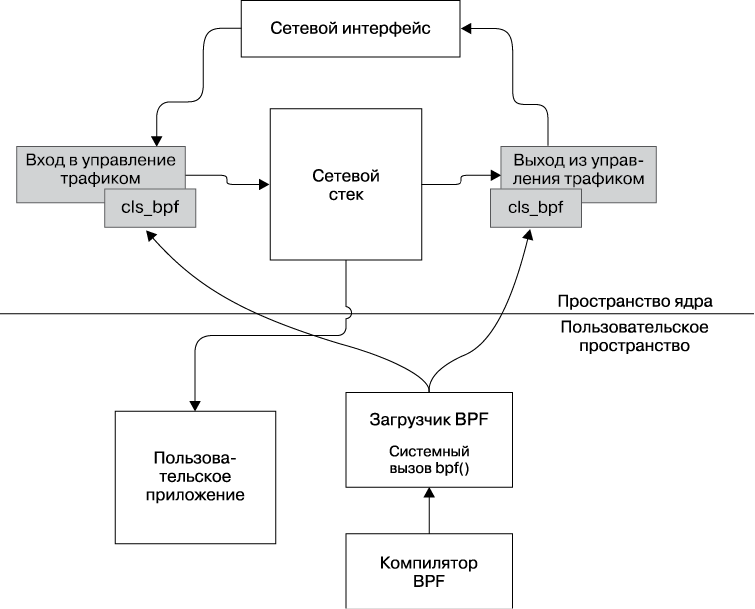
Рис. 6.3. Загрузка BPF-программ и управление трафиком
Вы можете писать программы BPF для управления трафиком на C и компилировать их, используя LLVM/Clang с бэкендом BPF.

Входящие и исходящие qdisc позволяют подключать управление трафиком к входящему (входному) и исходящему (выходному) трафику соответственно.
Чтобы этот пример работал, нужно запустить его в ядре, которое было скомпилировано с cls_bpf напрямую или в виде модуля. Чтобы убедиться, что у вас есть все необходимое, сделайте следующее:
cat /proc/config.gz| zcat | grep -i BPF
Убедитесь, что видите примерно такой вывод с y или m:
CONFIG_BPF=y
CONFIG_BPF_SYSCALL=y
CONFIG_NET_CLS_BPF=m
CONFIG_BPF_JIT=y
CONFIG_HAVE_EBPF_JIT=y
CONFIG_BPF_EVENTS=y
Теперь посмотрим, как написать классификатор:
SEC("classifier")
static inline int classification(struct __sk_buff *skb) {
void *data_end = (void *)(long)skb->data_end;
void *data = (void *)(long)skb->data;
struct ethhdr *eth = data;
__u16 h_proto;
__u64 nh_off = 0;
nh_off = sizeof(*eth);
if (data + nh_off > data_end) {
return TC_ACT_OK;
}
Роль функции main нашего классификатора выполняет функция classification. Она аннотирована заголовком раздела под названием classifier, так что tc знает, что использовать нужно этот классификатор.
В данный момент нам нужно извлечь некоторую информацию из skb. Член data содержит все данные для текущего пакета и все его детали протокола. Чтобы программа знала, что внутри, нужно перевести данные в кадр Ethernet (в данном случае с переменной *eth). Чтобы удовлетворить статический верификатор, следует убедиться, что данные, суммируемые с размером указателя eth, не превышают объем пространства, в котором находится data_end. После этого мы можем перейти на один уровень глубже и получить тип протокола из члена h_proto в *eth:
if (h_proto == bpf_htons(ETH_P_IP)) {
if (is_http(skb, nh_off) == 1) {
trace_printk("Yes! It is HTTP!\n");
}
}
return TC_ACT_OK;
}
Получив протокол, нам нужно преобразовать его с хоста, чтобы проверить, действительно ли это IPv4, который нас интересует. Если это так, мы проверяем, является ли внутренний пакет пакетом HTTP, используя нашу собственную функцию is_http. Если все правильно, печатаем отладочное сообщение о том, что нашли HTTP-пакет:
void *data_end = (void *)(long)skb->data_end;
void *data = (void *)(long)skb->data;
struct iphdr *iph = data + nh_off;
if (iph + 1 > data_end) {
return 0;
}
if (iph->protocol != IPPROTO_TCP) {
return 0;
}
__u32 tcp_hlen = 0;
Функция is_http аналогична нашей функции классификатора, но мы запускаем ее из skb, уже зная начальное смещение для данных протокола IPv4. Как и ранее, мы должны выполнить проверку перед получением доступа к данным протокола IP с помощью переменной *iph, чтобы статический верификатор узнал о наших намерениях.
После того как это сделано, для продолжения работы мы просто проверяем, содержит ли заголовок IPv4 пакет TCP. Если протокол пакета относится к типу IPPROTO_TCP, нужно сделать еще несколько проверок, чтобы получить фактический заголовок TCP в переменной *tcph:
plength = ip_total_length - ip_hlen - tcp_hlen;
if (plength >= 7) {
unsigned long p[7];
int i = 0;
for (i = 0; i < 7; i++) {
p[i] = load_byte(skb, poffset + i);
}
int *value;
if ((p[0] == 'H') && (p[1] == 'T') && (p[2] == 'T') && (p[3] == 'P')) {
return 1;
}
}
return 0;
}
Теперь, когда заголовок TCP известен, мы можем загрузить первые 7 байт из структуры skb со смещением poffset полезной нагрузки TCP. На этом этапе можно проверить, является ли массив байтов последовательностью, означающей HTTP. Зная, что это протокол уровня 7 и это HTTP, можем вернуть 1, в противном случае возвращаем 0.
Как видите, наша программа проста. Разрешено почти все, а получив HTTP-пакет, программа скажет нам об этом в отладочном сообщении.
Вы можете скомпилировать программу с помощью Clang, используя цель bpf, как мы делали ранее с примером фильтра сокетов. Мы не можем скомпилировать эту программу для управления трафиком подобным образом — это сгенерирует файл ELF classifier.o, который будет на этот раз загружен tc, а не нашим пользовательским загрузчиком:
clang -O2 -target bpf -c classifier.c -o classifier.o
| Коды возврата управления трафиком Из man 8 tc-bpf: TC_ACT_OK (0) — завершает конвейер обработки пакетов и позволяет пакету продвигаться дальше; TC_ACT_SHOT (2) — завершает конвейер обработки пакетов и отбрасывает пакет; TC_ACT_UNSPEC (-1) — использует действие по умолчанию, настроенное из tc (аналогично возвращению -1 из классификатора); TC_ACT_PIPE (3) — переходит к следующему действию, если оно доступно; TC_ACT_RECLASSIFY (1) — завершает конвейер обработки пакетов и начинает классификацию с начального else. Все остальное — неопределенный код возврата. |
Теперь мы можем установить программу на интересующий нас интерфейс. В нашем случае это был eth0.
Первая команда заменит qdisc по умолчанию для устройства eth0, а вторая фактически загрузит наш классификатор cls_bpf в этот классовый планировщик входящего трафика (ingress). Это означает, что наша программа будет обрабатывать весь трафик, поступающий в данный интерфейс. Для обработки исходящего трафика нужно использовать вместо этого egress.
# tc qdisc add dev eth0 handle 0: ingress
# tc filter add dev eth0 ingress bpf obj classifier.o flowid 0:
Программа загружена, теперь все, что нам нужно, — отправить HTTP-трафик в интерфейс. Для этого можно задействовать любой HTTP-сервер в этом интерфейсе. Тогда вы сможете обратиться к IP-адресу интерфейса с помощью curl.
Если у вас нет HTTP-сервера, можете использовать тестовый вариант с Python 3 и модулем http.server. Откроется порт 8000 со списком каталогов текущего рабочего каталога:
python3 -m http.server
Сейчас можно вызвать сервер с помощью curl:
$ curl http://192.168.1.63:8080
После этого вы должны увидеть ответ от HTTP-сервера. Теперь можете получить сообщения отладки, созданные с помощью trace_printk, подтвердив это специальной командой tc:
# tc exec bpf dbg
Вывод будет примерно таким:
Running! Hang up with ^C!
python3-18456 [000] ..s1 283544.114997: 0: Yes! It is HTTP!
python3-18754 [002] ..s1 283566.008163: 0: Yes! It is HTTP!
Поздравляем! Вы только что создали свой первый классификатор управления трафиком BPF.

Вместо сообщения отладки, как в этом примере, вы можете применить карту, чтобы сообщить пространству пользователя, что интерфейс только что получил пакет HTTP. Поупражняйтесь в этом самостоятельно. Посмотрите на classifier.c в предыдущем примере, чтобы получить представление о том, как это сделать, — например, так, как мы использовали карту countmap.
Возможно, теперь вам понадобится выгрузить классификатор. Можете сделать это, удалив входящий qdisc, который только что подключили к интерфейсу:
# tc qdisc del dev eth0 ingress
Примечания к act_bpf и отличия cls_bpf
Вы могли заметить, что существует другой объект для BPF-программ, называемый act_bpf. На самом деле act_bpf — это действие, а не классификатор. Это означает другую функциональность, потому что действия являются объектами, прикрепленными к фильтрам. Из-за этого они не могут выполнять фильтрацию напрямую, требуя, чтобы управление трафиком сначала рассмотрело все пакеты. Поэтому обычно предпочтительно использовать классификатор cls_bpf вместо прямого действия act_bpf.
Но, поскольку act_bpf может быть присоединен к любому классификатору, могут возникнуть случаи, когда вам покажется полезным повторно применить уже имеющийся классификатор и присоединить к нему программу BPF.
Различия между управлением трафиком и XDP
Хотя программы управления трафиком cls_bpf и XDP выглядят очень похожими, они во многом разнятся. Программы XDP выполняются раньше по ходу движения входных данных, прежде чем те поступят в основной сетевой стек ядра, поэтому данные программы не имеют доступа к структуре буфера сокетов sk_buff, как в случае с tc. Вместо этого они принимают другую структуру, называемую xdp_buff, которая является урезанным представлением пакета без метаданных. Все это имеет свои преимущества и недостатки. Например, будучи выполненными еще до кода ядра, программы XDP могут эффективно отбрасывать пакеты. По сравнению с программами управления трафиком программы XDP могут быть подключены только к трафику, входящему в систему.
Вы можете задаться вопросом: когда выгодно использовать одни и другие? Ответ таков: из-за того что XDP-программы не содержат обогащенные ядром структуры данных и метаданные, они лучше подходят для случаев, охватывающих уровни OSI вплоть до 4-го. Но оставим это до следующей главы!
Резюме
Теперь вам должно быть совершенно ясно, что программы BPF полезны для обеспечения видимости и контроля на разных уровнях пути передачи сетевых данных. Вы видели, как использовать их для фильтрации пакетов с помощью высокоуровневых инструментов, которые генерируют сборку BPF. Мы загрузили программу в сетевой сокет и в конце подключили наши программы к входному qdisc управления трафиком, чтобы классифицировать его с помощью программ BPF. В этой главе мы также кратко обсудили XDP, а в главе 7 полностью раскроем данную тему. Например, расскажем, как создаются программы XDP, какие программы XDP существуют и как их писать и тестировать.

