ВЕРОЯТНОСТИ
Вы мне поверили, когда я сказал, что, вероятно, лишь немногие отдали почитать свой экземпляр книги A Brief History of Time? Я очень вольно использовал термин, как делают многие, но тема математической вероятности апеллирует к пределам наших сведений о мире и простирается от поведения субатомных частиц, например кварков и бозонов, до правдоподобности сообщений о скором конце света; от людей, участвующих в государственной лотерее, до тех, кто пытается предсказывать погоду (две вещи, которые могут иметь схожие шансы на успех).
Вероятности позволяют нам представить будущие события в цифрах и помогают принимать практические решения. Без них мы можем поддаться обаянию пустых анекдотов и забавных историй. Может, вы слышали, что кто-нибудь говорил: «Я не буду пристегиваться в машине, потому что слышал историю, когда парень погиб из-за того, что был пристегнут. Он оказался в собственной машине, как в ловушке, и не смог из нее выбраться. Если бы он не был пристегнут, то остался бы жив».
Да, конечно, но мы не можем делать выводы из одной или двух историй. Каковы относительные риски? Хотя есть несколько таких случаев, когда ремень безопасности стоил человеку жизни, все же без него вероятность смертельного исхода гораздо выше. Вероятность помогает нам взглянуть на ситуацию с помощью цифр.
Мы используем слово «вероятность» по-разному, чтобы обозначить разные вещи. Очень легко запутаться, считая, что человек имеет в виду одно, тогда как на самом деле он думает совсем другое. Подобное заблуждение может привести к тому, что сделанные нами выводы окажутся неверными.
В основе одного из видов вероятности — классической — лежит идея симметрии и равной вероятности: у игрового кубика шесть граней, у монеты — две стороны, у колеса рулетки — 38 слотов (это в США — в Европе 37). Если исключить производственный брак или жульничество, в результате которого можно фальсифицировать желаемый результат, то все исходы равновозможны. То есть вероятность выкинуть на кубике конкретное число равна одной шестой; вероятность выпадения решки при подбрасывании монеты равна одной второй; в случае с игрой в рулетку вероятность любого слота — 1/38 или 1/37.
Классическая вероятность ограничена подобного рода структурами, в которых уже все четко определено и задано. В классическом случае мы знаем точно параметры системы и поэтому можем подсчитать вероятность для каждого возможного случая. Второй вид вероятности возникает потому, что в повседневной жизни мы часто хотим знать вероятности событий, которые не включены в такую симметричную схему. Нам интересно, какова вероятность того, что лекарство поможет пациенту или что клиенты предпочтут один сорт пива другому. В этом случае нам нужно сначала оценить параметры системы, потому что изначально они не заданы.
Чтобы определить, что же собой представляет второй тип вероятности, мы делаем наблюдения или проводим эксперименты, а также считаем, сколько раз получился желаемый результат. Это так называемая частотная, или статистическая, вероятность. Мы назначаем лекарство группе пациентов и смотрим, скольким из них станет лучше, — это эксперимент, и вероятность того, что лекарство сработает, определяется как доля людей, которым оно помогло (мы основываемся на частоте случаев с желаемым результатом). Если провести такой эксперимент на большом количестве людей, результат будет очень близок к истинной вероятности, так же, как при опросах общественного мнения.
И классическая, и частотная вероятность имеют дело с повторяющимися, воспроизводимыми событиями, а также с долей случаев, которые приводят к определенному исходу в практически неизменных условиях (некоторые бескомпромиссные теоретики настаивают на том, что условия должны быть абсолютно идентичными, но я думаю, что они заходят слишком уж далеко, потому что в пределе Вселенная никогда не бывает абсолютно одинаковой, всегда есть случайные вариации). Когда вы проводите опрос общественного мнения среди случайных людей, то делаете это в идентичных условиях, даже если одних людей вы опрашиваете сегодня, а других завтра (конечно, при условии, что в этом промежутке не произойдет ничего такого, что могло бы изменить их точку зрения). Когда свидетельница в суде дает показания и говорит, что ДНК подозреваемого совпадает с ДНК крови, найденной на пистолете, она использует частотную вероятность, потому что скорее принимает в расчет те фрагменты ДНК, которые совпадают, нежели те, которые различаются. Когда вы вытягиваете карту из колоды, отсортировываете дефектную деталь на конвейере или спрашиваете участников опроса, любят ли они определенную марку кофе, — все это примеры классической или частотной вероятности повторяющегося, воспроизводимого события (в примере с картой — классическая вероятность, в примере с деталью на конвейере или кофе — частотная).
Третий вид вероятности отличается от описанных выше тем, что ее не получают экспериментально и определяют не для повторяющихся событий, — скорее она выражает мнение или степень уверенности в том, что какое-то событие произойдет. Она называется субъективной вероятностью (один из ее видов — байесовская вероятность, получившая свое название по имени статистика XVIII века Томаса Байеса). Когда подруга говорит, что на 50% уверена, что пойдет в эти выходные на вечеринку к Майклу и Джулии, она использует байесовскую вероятность, выражая некую степень уверенности в том, что так оно и будет. Каким будет уровень безработицы к следующему году? Мы не можем тут использовать частотную вероятность, потому что нельзя рассматривать безработицу следующего года как набор наблюдений, выполненных при идентичных или даже схожих обстоятельствах.
Давайте разберемся на примере. Когда ведущая прогноза погоды сообщает, что вероятность дождя завтра 30%, мы знаем, что она не проводила экспериментов в течение нескольких идентичных в плане погодных условий дней (даже если бы такое было возможно). Цифра в 30% выражает степень ее уверенности (по шкале от одного до 100) в том, что будет дождь, и своей целью она ставит доведение до вашего сведения некоей информации, которая может заставить вас призадуматься, нужны ли вам будут завтра галоши и зонтик.
Если ведущая прогноза погоды — хорошо проверенный источник, то дождь будет идти в 30% случаев, про которые она говорила, что вероятность дождя 30%. Если дождь будет идти в 60% случаев, то она ошиблась, и намного. Вопрос о том, насколько проверен источник, важен только в случае с субъективной вероятностью.
Кстати, давайте вернемся к вашей подруге, сказавшей, что ее шансы пойти на вечеринку равны 50%. Многие из тех, кто не привык мыслить критически, часто допускают подобную ошибку: они полагают, что если есть два варианта, то они должны быть равновероятны. Когнитивные психологи Амос Тверски и Дэниел Канеман описали вечеринки и иные возможные сценарии людям, участвовавшим в эксперименте. На конкретной вечеринке, например, гостям могут сказать, что в зале присутствуют 70% писателей и 30% инженеров. Если вы столкнетесь с кем-то, у кого будет татуировка с портретом Шекспира, то справедливо решите, что перед вами один из пишущей братии, но если вы наткнетесь на кого-то с уравнением Максвелла на футболке, то справедливо решите, что перед вами инженер. А что, если вы столкнетесь с человеком без опознавательных признаков — ни татуировки, ни математических формул на футболке, — какова вероятность того, что перед вами инженер? В опросах, проведенных Тверски и Канеманом, люди обычно говорили о вероятности «50 на 50», совершенно не видя разницы между двумя возможными исходами и двумя одинаково вероятными исходами.
Субъективная вероятность — единственная из всех возможных, находящихся в нашем распоряжении в тех ситуациях, где нет места эксперименту и симметрии условий. Когда судья дает присяжным указание вынести вердикт, указывает ли «перевес улик» на вину ответчика, то налицо субъективная вероятность — каждый из присяжных должен самостоятельно решить, есть ли перевес, взвешивая все улики на весах собственных внутренних (возможно, не объективных) принципов и убеждений.
Когда букмекер оценивает шансы на скачках, он пользуется субъективной вероятностью — хотя послужной список лошади, здоровье и история наездника тоже могут предоставить некую информацию, тут нет естественной симметрии (это не случай классической вероятности) и тут нет никакого эксперимента (что исключает возможность частотной вероятности). Тот же принцип действует и в бейсболе или любом ином виде спорта. Букмекер может сказать, что шансы «Роялс» выиграть следующий матч равны 80%, но это не вероятность в математическом смысле; просто таким образом он — и мы вместе с ним — использует язык, чтобы придать своим словам весомость, числовую точность. Букмекер не может повернуть стрелки часов вспять и просмотреть несколько раз один и тот же матч «Роялс», чтобы подсчитать, сколько раз они его выиграют. Он может, правда, подсчитать все математически или использовать компьютер, чтобы построить базу для оценки, но, в конце концов, его числа — всего лишь догадка, степень его уверенности в собственном предсказании. Субъективность оценок подтверждается тем, что у разных экспертов получаются разные числа.
Субъективные вероятности окружают нас, при том что мы в большинстве своем их не замечаем — мы встречаемся с ними в газетах, в залах заседания совета директоров, в спортзалах. Вероятность того, что какая-нибудь страна, не отличающаяся политической чистоплотностью, в ближайшие 12 месяцев взорвет атомную бомбу, что процентная ставка возрастет в следующем году, что Италия выиграет мировой кубок или что солдаты займут определенную высоту, — всегда субъективна, это не частотная вероятность.
Это все разовые, невоспроизводимые события. И репутация экспертов и предсказателей зависит от того, насколько правильны их прогнозы.
КОМБИНАЦИИ ВЕРОЯТНОСТЕЙ
Одно из самых важных правил теории вероятностей — правило умножения. Если два события независимы друг от друга — то есть одно из них никак не влияет на исход другого, — вы получите вероятность того, что они оба произойдут, перемножив вероятности каждого. Вероятность того, что при подбрасывании монеты выпадет орел, равна одной второй (потому что существует всего два возможных варианта: орел или решка). Вероятность того, что из колоды вы вытянете червовую карту, равна одной четвертой (потому что есть четыре возможных варианта: черви, пики, трефы и бубны). Если вы подкидываете монету и вытягиваете карту, то вероятность того, что у вас получатся и орел, и черви, высчитывается с помощью умножения двух отдельных вероятностей: 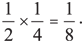
| Орел | Черви | Решка | Черви |
| Орел | Бубны | Решка | Бубны |
| Орел | Трефы | Решка | Трефы |
| Орел | Пики | Решка | Пики |
Я тут не говорю о тех редких случаях, когда вы кидаете монетку и она приземляется на ребро, или когда ее уносит чайка, пролетавшая мимо, или когда у вас в фальшивой колоде сплошь трефы.
Схожим образом мы можем действовать в случае с вероятностью наступления сразу трех событий: получить орла при подбрасывании монетки, вытянуть карту червей из колоды или встретить случайного человека, у которого день рождения в один день с вами (вероятность последнего равна примерно 1/365,24 — хотя дни рождения не вполне равномерно распределены и некоторые даты рождения встречаются чаще, чем другие, это разумная цифра).
Вы, возможно, знаете такие сайты, где задают вопросы, на которые предполагается несколько ответов, например: «На какой из этих пяти улиц вы когда-то жили?» или «Кредитная карта какого из пяти представленных типов есть у вас?» Такие сайты пытаются установить вашу личность, чтобы убедиться, что вы тот, за кого они вас принимают. В таком случае применяется правило умножения. Вероятность того, что вы случайно ответите правильно на один вопрос, равна 0,2, а вероятность того, что вы угадаете ответ на шесть вопросов подряд, равна 0,2 × 0,2 × 0,2 × 0,2 × 0,2 × 0,2, или 0,000064. А это шесть шансов из 100 тысяч. Не так же точно, как результаты экспертизы ДНК в суде, но тоже неплохо. (А знаете, почему они не дают вопросы с выбором ответа из предложенных, а не предлагают вписывать краткий ответ? Потому что существует слишком много вариантов правильных ответов).
КОГДА ВЕРОЯТНОСТЬ ОДНИХ СОБЫТИЙ ОПРЕДЕЛЯЕТСЯ ДРУГИМИ СОБЫТИЯМИ
Правило умножения можно применять только к независимым событиям. А какие события не являются независимыми? Например, погода. Морозная погода сегодня вечером и морозная погода завтра не являются независимыми — такие явления часто сохраняются в течение нескольких дней. Конечно, морозы могут ударить совершенно внезапно, но все же, желая сделать прогноз на завтра, просто посмотрите на погоду сегодня.
Вы могли бы подсчитать количество вечеров в году, когда температура опускается сильно ниже нуля, — скажем, в вашем регионе 36 — и потом сказать, что вероятность заморозков сегодня вечером будет 36/365, приблизительно 10%, или 0,1, но при этом вы не учитываете зависимости. Если вы скажете, что вероятность того, что в течение зимы будет два морозных вечера подряд, равна 0,1 × 0,1 = 0,01 (согласно правилу умножения), то недооцените вероятность, потому что события двух вечеров подряд не независимы. На завтрашнюю погоду сильно влияет сегодняшняя.
Вероятность того, что какое-то событие произойдет, также может оказаться под влиянием конкретного факта, который вы сейчас изучаете. На вероятность того, что вечером будет морозно, очевидно влияет регион, о котором вы говорите. И эта вероятность выше на 44-й параллели, нежели на десятой. Шанс найти кого-то выше двух метров возрастает, если искать такого человека среди баскетболистов, а не в таверне, куда часто забегают жокеи. Таким образом, подгруппа людей или вещей, которую вы изучаете в данный момент, сильно влияет на вашу оценку вероятности.
УСЛОВНЫЕ ВЕРОЯТНОСТИ
Часто статистические данные вводят нас в заблуждение, потому что мы смотрим на показатели целой группы случайных людей, вместо того чтобы смотреть на подгруппу. Какова вероятность того, что у вас пневмония? Не очень высокая. Но если нам будет известно больше о вас и конкретно о вашем случае, вероятность может быть выше или ниже. Это называется «условные вероятности».
Рассмотрим два разных типа вопросов:
1. Какова вероятность того, что у случайно выбранного для опроса человека будет пневмония?
2. Какова вероятность того, что она будет у человека, не выбранного случайным образом для опроса, но проявляющего три симптома (температура, боль в мышцах, заложенность в груди)?
Второй вопрос предполагает условную вероятность. Она носит такое название, потому что мы рассматриваем не всю популяцию, а только тех людей, для которых выполняется определенное условие. Не прибегая к цифрам, мы можем угадать, что вероятность пневмонии выше во втором случае. Конечно, мы можем поставить вопрос таким образом, чтобы вероятность пневмонии была ниже у человека, которого выбрали не случайно:
Какова вероятность того, что мы найдем пневмонию у случайно выбранного человека, чьи анализы три раза подряд не подтвердили заболевание, у которого особенно крепкая иммунная система и который минуту назад финишировал первым в Нью-Йоркском марафоне?
Тот же принцип будет и в следующем случае: вероятность того, что вы заработаете рак легких, не может не быть связана с историей вашей семьи. Вероятность того, что официант принесет вам кетчуп, не может не быть связана с вашим заказом. Можно подсчитать вероятность того, что любой случайно выбранный человек в ближайшие десять лет заболеет раком легких или что официант принесет кетчуп клиентам за определенным столиком, приняв в расчет остальные заказы. Но нам повезло, и мы знаем о том, как эти события связаны с другими. Это позволяет нам сузить рассматриваемую совокупность и получить более точную оценку. Например, если у обоих ваших родителей был рак легких, вы, возможно, захотите подсчитать вероятность заболеть тем же; тогда просто посмотрите на других людей в избранной группе — тех, у чьих родителей был рак. Если у ваших родителей его не было, вы захотите посмотреть на релевантную группу людей, у которых в анамнезе нет таких историй (и у вас, вероятно, получатся совсем иные результаты). Если вы хотите узнать вероятность, принесет ли официант вам кетчуп, вы можете посмотреть на столики, за которыми люди заказали гамбургеры и картошку фри, а не на те, за которыми люди едят тартар из тунца или яблочный пирог.
Нежелание видеть взаимосвязь событий (когда принимают предположение о независимости) может привести к серьезным юридическим последствиям. Рассмотрим дело Салли Кларк, британки из Эссекса, которая была привлечена к ответственности за убийство своего младшего ребенка. Ее первый ребенок умер еще в младенчестве, и его смерть связывали с СВДС (синдромом внезапной детской смерти, или «смертью в колыбели»). Обвинители уверяли, что вероятность смерти от СВДС обоих детей в одной семье очень мала, поэтому, скорее всего, имело место убийство. Свидетель со стороны обвинения, врач-педиатр, привел в качестве доказательства результаты исследования, в котором говорилось, что детская смертность в результате СВДС возникала в одном случае из 8543. (Компетентность доктора Мидоу в области педиатрии не делает его специалистом по статистике или эпидемиологии — такого рода путаница часто приводит к неверным суждениям. Об этом мы поговорим в части 3 этой книги. Эксперт в одной области не обязательно специалист в другой, даже если кажется, что эти области смежные.)
Углубившись в вопрос, мы можем усомниться и в числе 8543 — количестве смертей от СВДС. Откуда оно взялось? Диагноз СВДС ставится методом исключения — это значит, что ни один тест, проведенный медицинским персоналом, не может подтвердить, что смерть наступила в результате этого синдрома. Скорее бывает так что, если врачи затрудняются с диагнозом и уже исключили все другие возможные варианты, они диагностируют СВДС. Невозможность найти причину заболевания не может считаться доказательством того, что ее нет, поэтому весьма вероятно, что какие-то случаи со смертельным исходом, приписываемые СВДС, на самом деле были вызваны другими, менее мистическими причинами, например отравлением, удушением, пороком сердца и т. д.
Справедливости ради давайте предположим, что СВДС — действительно причина одной из 8543 смертей в младенчестве, как свидетельствовал доктор Мидоу, бывший экспертом в этом вопросе. Позже врач-педиатр заявил, что вероятность того, что в одной семье могут произойти два одинаковых случая — гибель ребенка в результате СВДС, — была 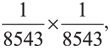 , или 1 из 73 миллионов. («Совпадение? Думаю, нет!» — мог воскликнуть обвинитель во время своей заключительной речи.) Глядя на эти подсчеты — использование правила умножения, — можно предположить, что случаи смертельного исхода независимы друг от друга, но это не обязательно так. Какие бы обстоятельства ни вызвали внезапную смерть первого ребенка миссис Кларк, нельзя забывать, что дети воспитывались в одной семье. Есть два сопутствующих фактора, связанных с СВДС: пассивное курение и сон на животе. Предположим также, что первый ребенок страдал от какого-нибудь врожденного порока. Это сильно повышает вероятность того, что нечто подобное проявится в геноме второго малыша (у детей, рожденных от одних и тех же родителей, 50% ДНК одинаковы). Рассуждая подобным образом, можно предположить, что вероятность смерти второго ребенка по какой-нибудь подобной причине равна 50%, — и вот миссис Кларк уже гораздо меньше похожа на убийцу.
, или 1 из 73 миллионов. («Совпадение? Думаю, нет!» — мог воскликнуть обвинитель во время своей заключительной речи.) Глядя на эти подсчеты — использование правила умножения, — можно предположить, что случаи смертельного исхода независимы друг от друга, но это не обязательно так. Какие бы обстоятельства ни вызвали внезапную смерть первого ребенка миссис Кларк, нельзя забывать, что дети воспитывались в одной семье. Есть два сопутствующих фактора, связанных с СВДС: пассивное курение и сон на животе. Предположим также, что первый ребенок страдал от какого-нибудь врожденного порока. Это сильно повышает вероятность того, что нечто подобное проявится в геноме второго малыша (у детей, рожденных от одних и тех же родителей, 50% ДНК одинаковы). Рассуждая подобным образом, можно предположить, что вероятность смерти второго ребенка по какой-нибудь подобной причине равна 50%, — и вот миссис Кларк уже гораздо меньше похожа на убийцу.
В конце концов ее муж нашел в архивах больницы доказательства того, что причина смерти второго малыша носила микробиологический характер. Миссис Кларк была оправдана, но к тому моменту она уже провела в тюрьме три года, отбывая наказание за преступление, которого не совершала.
Для условных вероятностей есть специальное обозначение. Вероятность того, что официант принесет вам кетчуп, при условии, что вы только что заказали гамбургер, выглядит так:
P (кетчуп | гамбургер),
где вертикальная прямая | читается как «при условии».
Обратите внимание: благодаря подобной записи исчезает необходимость в большом количестве слов, и математическая формула получается короткой.
Вероятность того, что официант принесет вам кетчуп, при условии, что вы только что заказали гамбургер и просили принести кетчуп, записывается так:
P (кетчуп | гамбургер ∧ попросил)
где ∧ читается как и.
ВИЗУАЛИЗАЦИЯ УСЛОВНЫХ ВЕРОЯТНОСТЕЙ
Относительная заболеваемость пневмонией на территории Соединенных Штатов в год составляет около 2% — 6 миллионов человек из 324 миллионов населения страны получают этот диагноз каждый год (безусловно, сюда не входят многочисленные случаи, когда диагноз поставить не удается, а также такие ситуации, когда человек в течение года болеет пневмонией не один раз, но мы пока не об этом). Получается, что вероятность того, что случайно выбранный для опроса человек болен пневмонией, равна приблизительно 2%. Но мы получим более точную оценку, если будем знать хоть что-то об этом конкретном человеке. Если вы пойдете к доктору и скажете, что у вас температура, кашель и заложена грудь, то уже не будете отобраны для опроса случайно — ведь вы пришли к доктору за помощью и жалуетесь на эти симптомы. Вы можете постепенно уточнить свою уверенность в чем-либо (например, что у вас пневмония), получая все новые и новые свидетельства. Мы используем правило Байеса для вычисления условной вероятности: какова вероятность того, что у меня пневмония, при условии наличия у меня симптома x? И чем большим количеством информации вы будете обладать, тем вернее будут уточнения такого рода. Какова вероятность того, что у меня пневмония, при условии, что: 1) у меня все эти симптомы; 2) в семейном анамнезе это не первый случай; 3) я только что провел три дня рядом с человеком, больным пневмонией? Вероятность увеличивается и увеличивается.
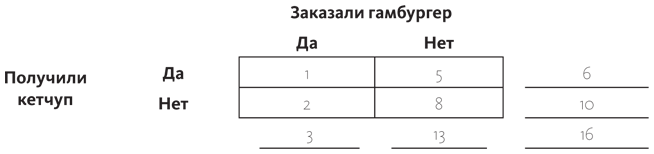
Вы можете подсчитать вероятности, используя формулу Байеса (см. ), но гораздо проще и нагляднее это сделать с помощью таблички, состоящей из четырех частей и описывающей все возможные сценарии: вы заказали или не заказали гамбургер и вы получили или не получили кетчуп:
На основании экспериментов и наблюдений вы вписываете различные значения — частоту каждого события. Из 16 посетителей ресторана, обедавших в тот момент, был только один, который заказал гамбургер, и ему принесли кетчуп, а также было два случая, когда кетчуп не принесли. Эти данные идут в левый столбец:
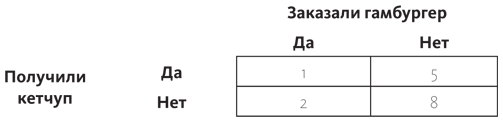
Аналогичным образом поступаем в ситуации, когда пятеро не заказывали гамбургер, но получили кетчуп, а восемь человек, которые не заказывали гамбургер, не получили кетчуп. Эти данные записываем в правый столбец:
А дальше вы просто складываете числа в строках и столбцах:
Теперь подсчет вероятностей стал делом простым. Если вы хотите узнать вероятность того, получите ли вы кетчуп при условии, что заказывали гамбургер, тогда начинайте с условия. Ему соответствует левый столбец.
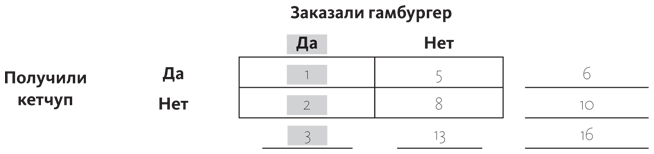
Трое посетителей заказали гамбургеры — это сумма, указанная в самом низу. Теперь попытаемся подсчитать вероятность того, что вы получите кетчуп при условии, что заказывали гамбургер. Теперь мы смотрим на клеточку «Да, получили кетчуп» в столбце «Да, заказали гамбургер», там стоит число 1. Условная вероятность P (кетчуп | гамбургер) тогда равна одной трети. И вы можете понимать это так: трое посетителей заказали гамбургер, один получил кетчуп, а двое нет. В данном виде подсчетов мы никак не задействуем правый столбец.
Мы можем использовать этот метод, когда нужно подсчитать любую условную вероятность, даже вероятность того, получите ли вы кетчуп при условии, что не заказывали гамбургер: 13 посетителей ресторана не заказывали гамбургер, пять из них при этом получили кетчуп — это значит, что вероятность равна 5/13, или около 38%. В этом конкретном ресторане вероятность того, что вы получите кетчуп, даже не заказывая гамбургер, гораздо выше, чем если бы вы его заказывали. (А теперь давайте включим критическое мышление. Как такое могло случиться? Может, данные взяты в ситуации, когда посетители заказывали картофель фри? Или, может, все гамбургеры изначально подавались с кетчупом?)
ПРИНЯТИЕ РЕШЕНИЙ В МЕДИЦИНЕ
Этот способ визуализации условных вероятностей очень полезен для принятия решений в медицине. Если вы сдаете медицинский анализ и его результат указывает на заболевание, какова вероятность того, что у вас оно и правда есть? Это не 100%, потому что сами способы проведения анализов неидеальны — они дают ложные положительные результаты (сообщают, что у вас выявлено заболевание, когда его нет) и ложные отрицательные (сообщают, что у вас нет заболевания, когда на самом деле оно есть).
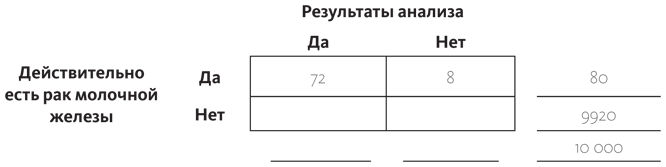
Вероятность того, что у женщины есть рак молочной железы, равна 0,8%. Если рак молочной железы есть, то вероятность того, что маммография его покажет, равна только 90%, так как сам аппарат неидеален и, бывает, идентифицирует не все случаи заболевания. Если же у женщины нет рака молочной железы, вероятность положительного результата равна 7%. А теперь предположим, что у женщины, выбранной для опроса случайно, тест показал положительный результат, — какова вероятность того, что у нее и правда рак молочной железы?
Для начала нарисуем нашу табличку, состоящую из четырех частей, и впишем все данные: женщина, у которой на самом деле есть рак молочной железы, и женщина, у которой его нет. И результаты анализа: что рак есть или что его нет. Чтобы нам было легче считать, давайте возьмем круглое число: предположим, речь идет о 10 тысячах женщин.
Это размер генеральной совокупности, поэтому записываем это число внизу справа, вне нашей таблицы.
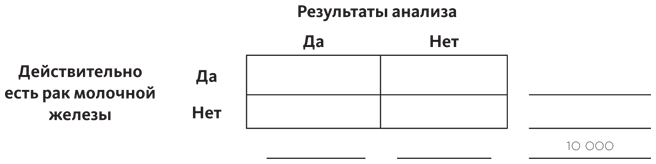
В отличие от примера с гамбургером и кетчупом, сначала мы записываем данные на полях, потому что именно этой информацией располагаем. Вероятность того, что у женщины рак, равна 0,8%, иными словами, он у 80 женщин из 10 тысяч. Записываем эти данные на полях справа вверху (мы еще не знаем, как заполнять ячейки таблицы, но скоро узнаем). А так как нам известно, что общая сумма равна 10 тысячам, получается такая сумма по второй строке:
10 000 – 80 = 9920.
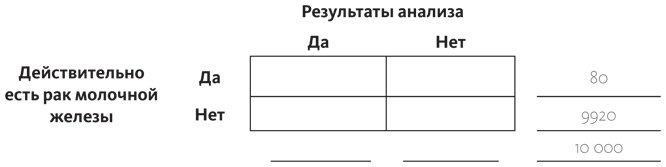
Нам сказали, что вероятность положительного результата анализа, если рак все-таки есть, равна 90%. А так как всего процентов 100, вероятность того, что анализы не покажут положительный результат при наличии рака, высчитывается так: 100% – 90% и, выходит, равна 10%.
Что касается 80 женщин, у которых действительно есть рак молочной железы (запись на полях справа вверху), мы можем сказать, что теперь нам известно, что у 90% из их общего числа результаты будут положительными (90% от 80 равно 72), а у 10% результат будет отрицательным (10% от 80 равно 8). Это все, что нам нужно знать, чтобы заполнить клеточки таблицы в верхней строке.
Мы пока еще не готовы сделать все необходимые вычисления для ответа на вопрос «Какова вероятность того, что у пациентки рак молочной железы при условии, что анализ дал положительный результат?», потому что нам еще нужно узнать, у какого количества людей результаты анализов положительны. А недостающая часть этого пазла кроется в изначальном описании ситуации: у 7% женщин, у которых нет рака молочной железы, анализы все равно покажут положительный результат. Число на полях возле нижней строки говорит о том, что у 9920 женщин рака нет; 7% от этого числа составляет 694,4 (округлим до 694). А это значит, что в нижнюю правую ячейку таблицы нужно занести число 9920 – 694 = 9226.
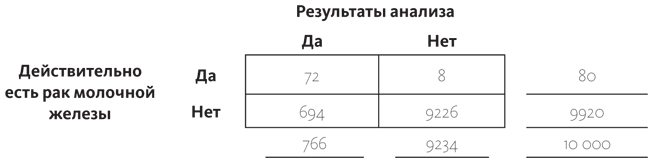
И, наконец, подсчитываем суммы по столбцам.
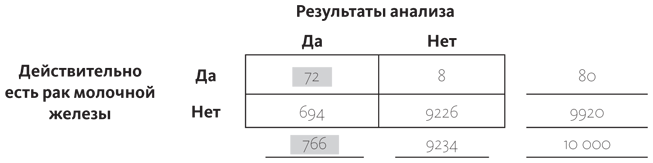
Если вы относитесь к тем миллионам людей, которые полагают, что наличие положительного результата анализов означает, что они точно больны, то вы ошибаетесь. Условная вероятность того, что у человека рак молочной железы, при условии, что результаты анализов были положительны, подсчитывается так: делим показатель левой верхней ячейки на итог под левым столбцом, это 72/766. Хорошая новость в том, что даже с положительной маммографией вероятность того, что у вас на самом деле есть рак молочной железы, равна 9,4%. Все объясняется тем, что заболевание достаточно редкое (оно встречается менее чем в одном случае из тысячи), а аппараты, с помощью которых проводят диагностирование, неидеальны.
УСЛОВНЫЕ ВЕРОЯТНОСТИ НЕ РАБОТАЮТ В ОБРАТНОМ НАПРАВЛЕНИИ
Мы со школы привыкли к тому, что в математике существует определенная симметрия: если x = y, то y = x. 5 + 7 = 7 + 5. Но так бывает не всегда, как мы убедились ранее на примере дискуссии о значениях вероятности (если вероятность ложной тревоги равна 10%, это не значит, что вероятность того, что беда все же произойдет, равна 90%). Посмотрите на статистику:
В супермаркетах продают яблок в десять раз больше, чем на придорожных развалах.
Если немного подумать, то станет очевидно, что вы не обязательно найдете яблоко в супермаркете в тот день, когда вам его захотелось: в магазине может быть в десять раз больше посетителей, чем на придорожном развале, и он может не справляться с возросшим спросом на данный товар. Если вы заметите случайно проходящего по улице человека с яблоком и у вас нет никакой информации о том, где он его взял, то вероятность того, что яблоко было куплено в супермаркете, нежели на развале, выше.
Может возникнуть вопрос: какова вероятность того, что человек купил это яблоко именно в супермаркете, при условии, что у него вообще есть яблоко?
P (был в супермаркете | нашел яблоко, которое хочет купить).
Это не то же самое, как в случае, если бы вам страшно хотелось яблоко сорта медуница:
P (нашел яблоко, которое хочет купить | был в супермаркете).
Такого рода асимметрия неожиданно возникает в ситуациях, когда имеет место обман с помощью статистических данных. Если вы прочтете где-то, что гораздо больше автомобильных аварий происходит в 19:00, нежели в 7:00, то какой вывод вы сделаете? Тут даже сама формулировка утверждения весьма неоднозначна. То ли речь идет о вероятности того, что во время аварии было 19 часов, то ли о вероятности того, что в 19 часов произошла авария. Во втором случае вы смотрите на количество автомобилей на дороге в 19:00 и подсчитываете, сколько из них попадают в аварии.
Возможно, в 19:00 на дороге гораздо больше машин, чем в любое другое время суток, а также случается гораздо меньше аварий на тысячу автомобилей. Это приведет к большему количеству аварий в 19:00, чем в любое другое время суток, просто потому, что на дороге в это время находится больше транспортных средств. Сведения об уровне аварийности на дороге помогут вам определить самое безопасное время для поездки.
Есть и другой пример. Вы все, должно быть, слышали, что большинство несчастных случаев на дороге происходит на расстоянии примерно 5 километров от дома. Причина не в том, что это расстояние опасно само по себе, а в том, что в большинстве случаев люди отъезжают не очень далеко от дома, чаще всего ездят куда-то по делам в округе. Как правило, эти две интерпретации одного и того же утверждения не равносильны:
P (19:00 | авария) ≠ P (авария | 19:00).
Путаница в интерпретациях подобного рода имеет не только теоретическое значение: множество судебных дел стали результатом неправильного использования условных вероятностей, которое внесло путаницу в ранее установленные факты. Судебный эксперт может правильно подсчитать, что вероятность случайного совпадения крови с места преступления с кровью подсудимого составляет 1%. И это совсем не то же самое, что сказать, что вероятность невиновности подсудимого равна 1%. Видите? Интуиция снова нас подвела. Судебный эксперт говорит о вероятности совпадения группы крови при условии, что подсудимый невиновен.
P (совпадение крови | невиновность).
Говоря простым языком, о «вероятности того, что мы бы нашли совпадение, если бы подсудимый был на самом деле невиновен». Но это не та же самая цифра, которую вы хотите узнать, — какова вероятность того, что подсудимый невиновен при условии, что кровь совпала:
P (совпадение крови | невиновность) ≠ P (невиновность | совпадение крови).
Многие невиновные люди были в свое время отправлены в тюрьму по ошибке. Равно как и многие пациенты приняли неверное решение, касающееся медицинского обслуживания, исходя из ошибочного предположения:
P (положительный результат анализов | рак) = P (рак | положительный результат анализов).
И дело не только в пациентах — врачи постоянно допускают ошибки (одно исследование показало, что 90% врачей одинаково интерпретировали две разные вероятности). И результаты, соответственно, могут быть просто пугающими.
Один хирург, например, уговорил 90 женщин на операцию по удалению груди, так как они оказались в группе повышенного риска. Он как-то заметил, что в 93% случаев рак молочной железы возникал у женщин, находившихся в группе повышенного риска. При условии, что у женщины диагностирован рак молочной железы, вероятность того, что она будет в этой группе, равна 93%: P (группа повышенного риска | рак молочной железы) = 0,93. Используя четырехчастную таблицу для тысячи типичных женщин и добавляя дополнительную информацию о том, что 57% женщин попадают в эту группу высокого риска, а также учитывая, что вероятность того, что у женщины будет рак, равна 0,8% (как говорилось ранее), можно подсчитать условную вероятность P (рак молочной железы | группа повышенного риска). Это тот вид статистики, с которым женщине хорошо бы ознакомиться, прежде чем ложиться под нож хирурга (все цифры округлены).
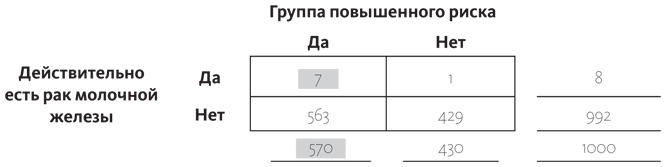
Вероятность того, что у женщины рак, при условии, что она находится в группе повышенного риска, равна не 93%, как ошибочно полагал хирург, а только 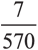 , или 1%. Хирург переоценил риск возникновения рака примерно в 100 раз. А последствия оказались необратимыми.
, или 1%. Хирург переоценил риск возникновения рака примерно в 100 раз. А последствия оказались необратимыми.
Составление четырехчастных таблиц может показаться странным занятием. Но составляя их, вы обращаетесь к научному, критическому мышлению и классифицируете данные визуально, чтобы облегчить себе подсчеты. А результаты последних помогают вам выразить проблему в цифрах и принять более рациональное решение, основанное на фактах.
Такие таблицы очень эффективны, и мне удивительно, что нас всех не учат составлять их в школе.
КАК ГОВОРИТЬ О СТАТИСТИКЕ И ГРАФИКАХ
Большинству из нас сложно подсчитать вероятности и статистические показатели в уме, равно как и распознать тонкие закономерности, глядя на сложные таблицы, полные цифр. Мы предпочитаем живые картинки, четкие изображения и истории. Однако, принимая решение, мы придаем подобным материалам слишком большое значение по сравнению со статистическими данными. А также часто недопонимаем или неверно интерпретируем графики.
Многие боятся цифр — а значит, принимают на веру те данные, которые получают от кого-то. Подобное поведение может привести к неверным выводам и решениям. У нас есть тенденция мыслить критически только в отношении тех вещей, с которыми мы не согласны. В нашу эпоху информации псевдофакты часто маскируются под факты, дезинформация прячется под личиной информации, а цифры лежат в основе любого важного утверждения или решения. Статистические искажения встречаются повсеместно. Как говорит социолог Джоэл Бест, обман в статистике возникает не просто потому, что все вокруг — пронырливые лгуны. За плохой статистикой стоят живые люди — часто искренние, не имеющие в виду ничего дурного, — просто порой они не думают критически о том, что говорят.
Тот же страх цифр, мешающий многим анализировать статистику, не дает порой возможности внимательно изучить цифры в графиках, названия осей и ту историю, которая за ними кроется. В мире полным-полно совпадений и могут происходить самые странные вещи — но тот факт, что с двумя вещами происходят изменения в одно и то же время, не означает, что одна из них вызвала другую или что они как-то взаимосвязаны скрытым третьим фактором х. Те, кто думает подобным образом и верит в такие ассоциации и совпадения, часто имеют в корне неверное представление о том, что такое вероятность, причина и результат, а также какую роль играет случай в том, как разворачиваются события. Вы можете, конечно, выдумать историю о том, что уменьшение количества пиратов за последние 300 лет и совпавшее с этим глобальное потепление непременно говорят о том, что пираты были просто необходимы для поддержания температурного баланса в мире. Но это результат недисциплинированного мышления и неверного истолкования фактов. Иногда бывает так, что распространители подобного рода ложных умозаключений знают больше вас и скрывают факты, надеясь, что вы ничего не заметите. Иногда они и сами попадают в ловушку собственных умозаключений. Но теперь-то вы знаете, что к чему.

