ВОЗМОЖНЫЕ УЛОВКИ ПРИ СООБЩЕНИИ ДАННЫХ
Вы раздумываете, стоит ли покупать акции компании, производящей безалкогольные напитки, и вдруг натыкаетесь на график, представляющий годовой отчет компании по продажам:
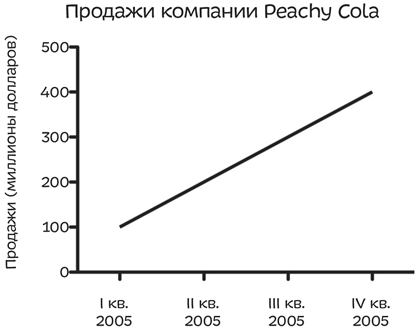
Выглядит многообещающе — продажи Peachy Cola постоянно растут. Пока что все идет хорошо. Но давайте припомним, как устроен наш мир, — и постараемся извлечь из этих знаний какую-нибудь пользу. Итак, мы знаем, что конкуренция на рынке безалкогольных напитков огромна. Продажи компании растут, но, возможно, не так быстро, как у конкурентов. Как потенциальному инвестору вам важно сравнить продажи Peachy Cola с продажами других компаний — ее продажи могут расти незначительно, в то время как рынок развивается особенно стремительно, а конкуренты зарабатывают больше, чем Peachy Cola. И как видно на этом графике с двойной осью Y, это, возможно, не сулит производителям ничего хорошего.
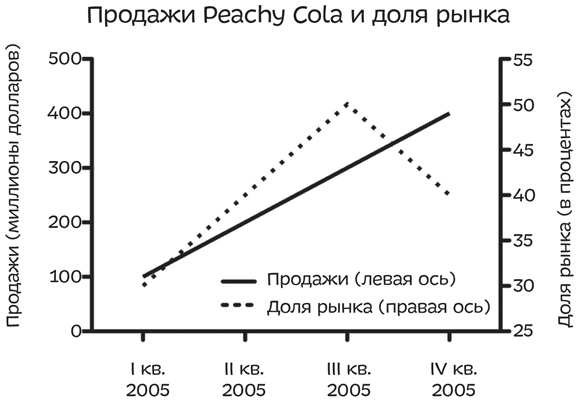
И хотя те, кто составляет недобросовестные графики, могут в корыстных целях как угодно менять шкалу на оси справа, сам по себе график с двойной осью Y нельзя считать предосудительным, потому что обе оси Y представляют разные вещи, которые не могут быть отображены на одной оси. В случае с организацией Planned Parenthood ситуация была иной: на том графике мы видели один показатель — количество проведенных процедур — на двух разных осях. И хотя они там отражали одно и то же, график был искажен, потому что шкалы на осях были разными. Сделано это было в целях манипуляции нашим восприятием.
Было бы также полезно посмотреть на прибыль от продаж Peachy Cola: вполне может оказаться, что благодаря производству и распространению компания зарабатывает больше на более низком объеме продаж. Тот факт, что кто-то предъявляет вам статистику или показывает график, еще не означает, что все это относится к делу. Наша всеобщая задача заключается в том, чтобы получить релевантную информацию и игнорировать те сведения, которые никакого значения не имеют.
Предположим, вы работаете в отделе по связям с общественностью в компании, производящей какого-то рода устройства — назовем их фрабезоиды. На протяжении последних нескольких лет эту продукцию охотно покупали, и продажи сильно выросли. Компания расширилась, построила новые объекты, увеличила штат сотрудников, и всем повысили зарплату. Однажды босс заходит в ваш кабинет с угрюмым выражением лица и говорит, что получил последние результаты продаж: количество проданных фрабезоидов упало на 12% по сравнению с предыдущим кварталом. Президент компании планирует провести большую пресс-конференцию и поговорить о будущем: как это всегда бывает, он намерен продемонстрировать большой график, отображающий положение дел. Если станет известно о снижении продаж, покупатели могут подумать, что фрабезоиды не так уж желанны, — и это приведет к дальнейшему снижению продаж.
Что вы делаете? Если вы честно отобразите данные по продажам за последние четыре года, ваш график будет выглядеть следующим образом:
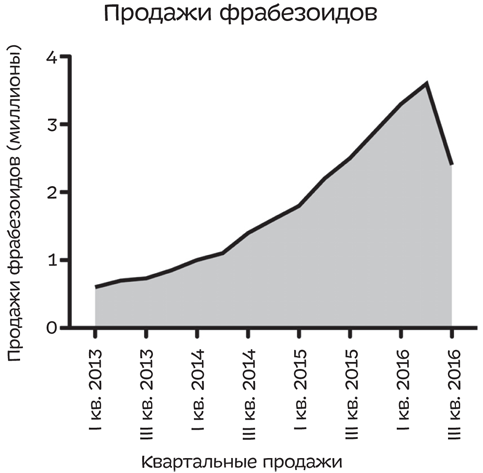
Кривая, идущая вниз, — это проблема. Если бы только был способ сделать так, чтобы она снова пошла вверх!
И такой способ есть — график кумулятивных продаж. Вместо графика квартальных продаж составьте график кумулятивных продаж — он отражает общее число продаж на текущий момент.
Как только продается хоть один фрабезоид, кривая идет вверх, как мы видим на этом графике:
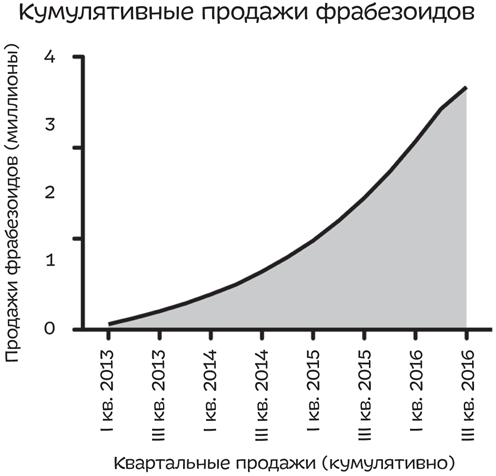
Если присмотреться, можно увидеть, что в последний квартал дела шли не так гладко: хотя в этот период кривая по-прежнему идет вверх, происходит это не так резко. Это-то и поможет вам понять, что продажи упали. Но нашему мозгу сложно уловить подобные нюансы (то, что в математике называется первой производной, — вычурное словечко для наклона линии). Итак, при взгляде на график кажется, что дела компании идут в гору, а вы меж тем заставили огромное количество потребителей поверить в то, что фрабезоиды — по-прежнему самая желанная покупка.
Так же поступил и Тим Кук, CEO компании Apple, во время своей последней презентации по продажам iPhone.
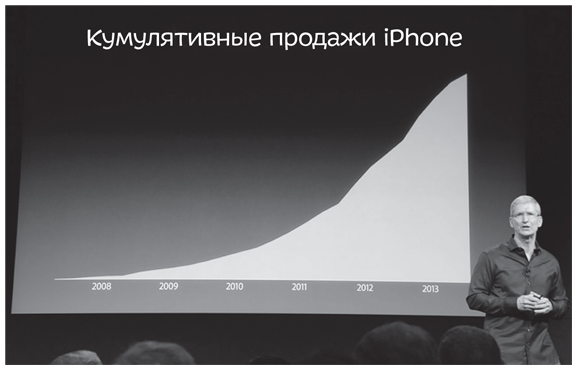
© 2013 Die Verge, Vox Media Inc. ()
ОТОБРАЖЕНИЕ НА ГРАФИКЕ НЕСУЩЕСТВЕННЫХ ДАННЫХ
В мире столько всего происходит, что всегда находится место совпадениям. Количество зеленых грузовиков на дороге может увеличиваться одновременно с вашей зарплатой; когда вы были ребенком, количество телешоу могло увеличиваться так же, как и ваш рост. Но это не означает, что одно есть причина другого. Статистики называют это корреляцией.
Известно, что корреляция не подразумевает причинность, однако об этом правиле часто забывают в рассуждениях. Для ошибок такого рода в формальной логике есть две формулировки.
1.-Post hoc, ergo propter hoc. Данное логическое заблуждение возникает из уверенности в том, что если один факт (Y) произошел после второго (X), значит, X стал причиной Y. Обычно люди чистят зубы до того, как пойти утром на работу. Но чистка зубов не есть причина, по которой они идут на работу. В данном случае все может быть наоборот.
2.-Cum hoc, ergo propter hoc. Это логическое заблуждение состоит в том, что из совпадения по времени двух фактов заключают, что один должен быть причиной второго. Тайлер Виджен, студент юридического факультета Гарвардского университета, написал книгу и создал сайт, где собрал примеры странных совпадений — корреляций, например таких:
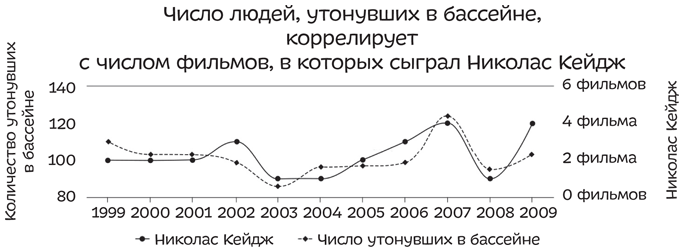
Эти данные можно интерпретировать четырьмя разными способами: 1) смерть в бассейне вызывает выход нового фильма с Николасом Кейджем; 2) выход фильмов с Николасом Кейджем становится причиной смерти в бассейне; 3) некий третий фактор (который еще не установлен) влияет на оба показателя; 4) показатели никак не связаны между собой, и корреляция — чистой воды совпадение. Если мы не отделим корреляцию от причинности, то сможем со всей уверенностью заявить, что график Виджена «доказывает» посильную помощь Ника Кейджа в предотвращении всех этих смертей в бассейне. И нам остается только поддерживать образовавшуюся тенденцию, чтобы актер и дальше развивал свою удивительную способность, которую он с блеском продемонстрировал в 2003 и 2008 годах.
В некоторых случаях между показателями, кажущимися взаимосвязанными, нет никакой настоящей связи: факт их корреляции — просто совпадение. В других же случаях можно найти между ними случайную связь, а то и состряпать более-менее разумную историю, которая подстегнула бы к поиску новых данных.
Мы можем исключить первое объяснение, так как на создание и выпуск фильма требуется время, поэтому пик смертности от утопления не мог вызвать пик популярности Ника Кейджа в том же году. Как насчет второго пункта? Возможно, люди настолько проникаются сюжетом остродраматических фильмов Кейджа, что не помнят себя и, как следствие, тонут. Возможно, по той же причине увеличивается и количество автомобильных аварий, а также травм, полученных в результате работы с тяжелым оборудованием. Мы не найдем ответов на эти вопросы, пока не проанализируем больше данных.
Что же насчет третьего фактора, который влияет на оба показателя? Можно предположить, что влияние оказывает экономика государства: чем более она развита, тем больше инвестиций идет в досуг — выпускается больше фильмов, люди чаще ездят в отпуск, ходят плавать. Если это так, то ни одна из ситуаций, частоту которых описывает график, — выход фильма Ника Кейджа и утопление — не бывает причиной другой. Свою роль тут сыграл третий фактор — экономика, — он и приводит к изменениям в обоих случаях. Статистики называют это третьим фактором x. И подобных случаев множество.
Вероятнее всего, эти две ситуации совсем никак не взаимосвязаны. А если присмотреться и хорошенько подумать, то мы обязательно обнаружим, что здесь одновременно изменяются два не связанных друг с другом показателя.
Продажи мороженого увеличиваются одновременно с ростом числа людей в шортах. Нельзя сказать, что один из фактов — причина второго. Третий фактор x, который на самом деле влияет на оба факта, — это повышение температуры летом. Количество телешоу, выпущенных в эфир в то время, когда вы были ребенком, возможно, коррелировало с вашим ростом, но несомненно, что причиной одинакового изменения обоих показателей стал общий период времени, когда: а) телевидение расширяло свой рынок и б) вы росли.
Как же тогда понять, в каких случаях корреляция указывает на причинность? Во-первых, можно провести контролируемый эксперимент. Во-вторых, включить логику. Но будьте внимательны — тут легко утонуть в трясине пустословия: это дождь вчера вынудил людей надеть дождевики? Или причиной стало желание не намокнуть, появляющееся, когда идет дождь?
Эту идею хорошо представил Рэнделл Манро в своем веб-комиксе xkcd: разговаривают две фигурки, очевидно, студенты колледжа. Один говорит, будто раньше думал, что корреляция подразумевает причинность. Потом, правда, походил на занятия по статистике и теперь уже так не думает. На что второй студент отвечает: «Кажется, занятия сделали свое дело». А первый ему на это: «Да, может быть».
ОБМАНЧИВЫЕ ИЛЛЮСТРАЦИИ
Инфографика в большом почете у разных ловкачей и пройдох, которым нужно сформировать мнение аудитории, и полагаются они на то, что большинство людей не станут вникать в то, что выглядит убедительно. Вот, например, посмотрите на этот рисунок. Возможно, с его помощью кто-то хотел напугать вас и заставить думать, что быстро растущая инфляция съедает все ваши с таким трудом зарабатываемые деньги:

Выглядит страшновато, правда? Но присмотритесь. Ножницы отрезают не 4,2% от банкноты, а около 42%. Когда ваша визуальная система сталкивается с логической, первая всегда выходит победителем, если только вы не приложите усилий, чтобы переломить это предубеждение. Точная инфографика выглядела бы похоже, но производила бы менее сильный эмоциональный эффект:

ИНТЕРПРЕТАЦИЯ И ФРЕЙМИНГ
Иногда статистические данные собраны и описаны как следует, а вот переданы неверно, потому что тот, кто передавал, — не важно, будь то журналист или адвокат, — не специалист в этом вопросе. И ошибки он допускает либо потому, что сам не понял, либо потому, что не осознавал, что малейшее изменение в формулировке может привести к изменению в смысле.
Часто у тех, кому хочется использовать статистику, в штате нет статистиков, и в поиске ответов на свои вопросы они попадают к тем, у кого нет соответствующей компетенции. Корпорации, правительственные учреждения, некоммерческие организации, семейные бакалейные лавочки — все они пользуются статистическими данными о продажах, клиентах, тенденциях, сетях снабжения. Некомпетентность может проявиться на любой стадии: во время проведения эксперимента, сбора данных, анализа или интерпретации.
Иногда бывает так, что публикуемые статистические данные нерелевантны. Если вы пытаетесь убедить своих акционеров, что дела вашей компании идут в гору, то, возможно, стоит предложить статистические данные по годовым продажам и показать уверенно растущие цифры. Но если рынок, на котором представлен ваш продукт, растет и развивается, от вас будут ждать увеличивающихся продаж. Инвесторов и аналитиков волнует, изменилась ли ваша доля на рынке. Но как сделать отчет более привлекательным, если эта доля уменьшается, потому что налетели конкуренты и теперь уводят ваших клиентов? Ответ прост: не предоставлять релевантную статистику по доле на рынке — вместо этого покажите статистику продаж. Продажи-то растут! Значит, все хорошо!
Финансовые показатели из заявлений на ипотеку 25-летней давности, вероятно, не сильно помогут в построении модели риска сегодня. Любая модель поведения потребителей на сайте устаревает очень быстро. Статистические данные о прочности бетона, использованного для эстакад, возможно, уже не релевантны для мостов (отличия могут быть вызваны влажностью и иными факторами, даже в случае, если в обоих инженерных проектах использовался один и тот же бетон).
Все вы наверняка слышали фразы типа «Четверо стоматологов из пяти рекомендуют зубную пасту Colgate». И это правда. Рекламное агентство, стоящее за этим существующим на протяжении многих лет слоганом, хочет донести до вас мысль, что стоматологи предпочитают Colgate всем другим брендам. Но это не так. Комитет рекламных стандартов Великобритании изучил утверждение слогана и счел его нечестным. Выяснилось, что в ходе опроса стоматологи могли рекомендовать более одной зубной пасты. И, как оказалось, самого крупного конкурента Colgate рекомендовали почти так же часто, как и Colgate (деталь, которую вы никогда не найдете в рекламе этой пасты).
Мы говорили о фрейминге, обсуждая средние, еще раз мы его коснулись, говоря о графиках. Манипуляция фреймами предоставляет бесконечное количество способов заставить кого-нибудь верить в то, чего на самом деле нет. А нужно всего лишь остановиться и подумать о том, что вам говорят. Представители C-SPAN уверяют, что их сеть «доступна» в 100 миллионах домов. Но это не означает, что 100 миллионов людей смотрят C-SPAN. Это даже не означает, что его смотрит хотя бы один человек.
Манипуляции с фреймами могут оказывать влияние на общественный порядок. Изучение результатов переработки мусора на самых разных улицах Лос-Анджелеса показывает, что одна конкретная улица перерабатывает в 2,2 раза больше, чем любая другая. Но прежде чем городской совет даст жителям этой улицы награду за их старания в области сохранения города зеленым, давайте зададимся вопросом: что может так сильно влиять на это количество? Как вариант, на этой улице проживает в два раза больше человек, чем на других, — возможно, потому что она длиннее, возможно, потому что на ней больше многоквартирных домов. Измерение объемов переработки мусора на уровне улицы нельзя считать релевантным показателем, если только все улицы не идентичны. Наиболее точные статистические данные можно получить либо по квартирам (замерить объемы переработки для каждой семьи), либо по каждому жителю — что даже лучше, потому что большие семьи потребляют больше, чем те, где народу меньше. Поэтому, проводя эксперимент, нужно учитывать не только объем собранного материала для переработки, но и количество людей, живущих на улице. И именно это и будет настоящим фреймом для статистика.
В 2014 году Los Angeles Times сообщила об объемах воды, которая используется в городе Ранчо-Санта-Фе, расположенном в засушливой Калифорнии. «Ежедневное потребление воды домашними хозяйствами в этом районе вышло в среднем почти в пять раз больше, чем в прибрежных районах Южной Калифорнии в сентябре. Из-за этого Санта-Фе теперь называют самым большим насосом в штате». «Домашнее хозяйство» в данном случае — нерелевантный фрейм для этого статистического результата. Фрейм «на душу населения» подошел бы гораздо лучше. Возможно, у жителей Ранчо-Санта-Фе большие семьи, что автоматически означает большую потребность в воде для душа, туалета, мытья посуды. Другой подходящий фрейм — использование воды из расчета на акр. Дома, расположенные в Ранчо-Санта-Фе, как правило, обладают большими придомовыми территориями. Может, в целях пожарной безопасности, может, по каким-то иным причинам гораздо целесообразнее держать землю засаженной зеленой растительностью, а на земельных участках в Ранчо-Санта-Фе на один акр потребляют не больше воды, чем в любом другом месте штата.
На самом деле в материалах New York Times можно найти кое-какую информацию по этому вопросу: «Чиновники, отвечающие за государственные водные ресурсы, запретили сравнивать потребление воды на душу населения в разных районах. По их словам, они ожидают, что в более состоятельных районах с большими земельными участками потребление будет выше».
Проблема со статьей заключается в том, что в ней фреймят данные, чтобы те выглядели так, словно жители Ранчо-Санта-Фе используют воды больше, чем им положено. Но данные, которые приводит газета, — как и в случае с переработкой мусора в Лос-Анджелесе, описанном выше, — не говорят об этом ни слова.
Указание пропорций, а не фактических цифр часто помогает построить верный фрейм. Представим, что вы работаете в компании, занимающейся продажами потоковых конденсаторов, и отвечаете за реализацию товара в Северо-Западном регионе. Ваши продажи сильно увеличились, но все равно еще недотягивают до результатов вашего соперника Джека, отвечающего за Юго-Западный регион. Вряд ли это справедливо — его территория не только больше географически, на ней живет и больше народу. Бонусы в вашей компании зависят от того, покажете ли вы начальству, что успешны в продажах.
Представьте начальству свой отчет о продажах в зависимости от площади или населения региона, в котором работаете. Иными словами, вместо того чтобы рисовать график продаж потоковых конденсаторов, покажите количество, приходящееся на душу населения в этом регионе или на квадратную милю. В обоих случаях, возможно, вы обойдете своего соперника.
Судя по сообщениям в новостях, 2014 год принес наибольшее количество смертей в результате авиакатастроф: 22 падения самолета и 992 человеческие жертвы. Но сегодня путешествия на самолете стали безопаснее, чем когда-либо. А так как и летают теперь намного чаще, это число, 992 погибших, говорит о значительном уменьшении числа смертей на миллион пассажиров (или миллион миль). На рейсе крупной авиакомпании вероятность погибнуть составляет один на пять миллионов. Гораздо выше риск погибнуть при других обстоятельствах: переходя дорогу или жуя бутерброд (смерть от того, что человек поперхнулся или отравился, вероятнее в тысячу раз). Здесь очень важны базовые показатели сравнения. Эти статистические данные растянуты во времени на целый год — год авиаперелетов, год перекусов бутербродами (в результате чего можно либо поперхнуться, либо отравиться). Поменяв базовый показатель, можно рассматривать каждый отдельный вид деятельности (перелет, жевание) на часовом промежутке времени — и это изменит статистику.
РАЗНИЦА, КОТОРАЯ НЕ ИГРАЕТ РОЛИ
К статистике часто прибегают, когда хотят понять, есть ли разница между двумя вещами: двумя разными удобрениями, лекарствами, манерами преподавания, суммами зарплат (например, сравниваются мужчины и женщины, выполняющие один и тот же вид работ). Сравниваемые показатели могут отличаться друг от друга по-разному. Между ними может быть фактическая разница. На вашу выборку могут влиять мешающие факторы, не имеющие ничего общего с исследуемым вопросом. В ваших измерениях могут быть ошибки. А может и быть случайное отклонение — оно возникает то в одной, то в другой части уравнения, в зависимости от того, когда вы с ним работаете. Задача исследователя — найти стабильные, воспроизводимые разницы, и мы пытаемся отделить их от экспериментальных ошибок.
Будьте, однако, осторожны с тем, каким образом новостные СМИ используют слово «значимый», потому что для статистиков это не означает «заслуживающий внимания». В статистике это слово связано с тем, что данные были получены в результате статистических процедур, например проверки по критерию Стьюдента и критерию хи-квадрат, регрессионного анализа и метода главных компонент (их сотни). Статистический уровень значимости представляет в количественной форме, насколько легко результаты объясняются чистой случайностью. При большом количестве наблюдений даже самые незначительные отклонения бывает сложно объяснить в рамках используемой статистической модели. Не критерии определяют, что заслуживает внимания, а что нет, — тут нужны человек и его оценка.
Чем больше у вас наблюдений в двух группах, тем вероятнее вы найдете между ними разницу. Допустим, мы изучаем ежегодные эксплуатационные расходы на два разных автомобиля, Ford и Toyota, располагая данными о содержание десяти машин каждой марки. Давайте предположим, что средние расходы на Ford на восемь центов в год больше. Возможно, статистически это будет незначительно, и, понятное дело, разница в восемь центов в год не станет учитываться при выборе машины — она слишком мала, чтобы из-за этого еще переживать. Но если посмотреть на содержание 500 тысяч автомобилей, эта разница уже станет статистически значимой. При этом она не будет иметь никакого значения в реальной жизни. Еще один пример: новое средство от головной боли может быть статистически лучше, поскольку быстрее решает проблему, но если всего на 2,5 секунды, то кому какая разница?
ИНТЕРПОЛЯЦИЯ И ЭКСТРАПОЛЯЦИЯ
Вы входите в свой сад и видите 10-сантиметровый одуванчик. Сегодня вторник. Через пару дней, в четверг, вы снова смотрите на него — его высота 15 сантиметров. Какой была его высота в среду? Наверняка мы не знаем, потому что не замеряли в этот день (в среду вы застряли в пробке, возвращаясь домой из питомника, где купили средство от сорняков). Но вы можете предположить: возможно, в среду высота одуванчика была 12,5 сантиметра. Это чистой воды интерполяция: вы берете два крайних значения и оцениваете величину между ними.
Какого размера будет этот одуванчик через шесть месяцев? Если он вырастает на 2,5 сантиметра в день, то можно сказать, что через полгода (примерно 180 дней) его высота составит 450 сантиметров, или четыре с половиной метра. В данном случае вы прибегли к экстраполяции. Но скажите, видели ли вы когда-нибудь такой большой одуванчик? Вероятно, нет: они ломаются под собственным весом, погибают от других естественных причин, их вытаптывают или обрабатывают средством от сорняков. Интерполяция — не идеальная техника, но если сравнить два этих способа, то она даст более точную оценку. Экстраполяция предполагает больше риска, потому что вы оцениваете величину, выходящую за диапазон наблюденных значений.
Время, необходимое, чтобы кофе в чашке остыл до комнатной температуры, определяется по законам физики (на него влияют многие факторы, например атмосферное давление, форма чашки). Если изначально температура чашки была 63 °C, со временем она опустится следующим образом:
| Время, прошедшее с начала эксперимента, мин. | Температура, °C |
| 0 | 63 |
| 1 | 60 |
| 2 | 57 |
| 3 | 54 |
Каждую минуту ваш кофе теряет три градуса. Если бы вы включили промежуточные члены в ряд известных вам величин — скажем, захотели узнать температуру кофе ровно посредине между двумя замерами, — интерполяция оказалась бы довольно точной. Но если вы будете экстраполировать, есть вероятность получить абсурдный ответ, например что ваш кофе через полчаса замерзнет.
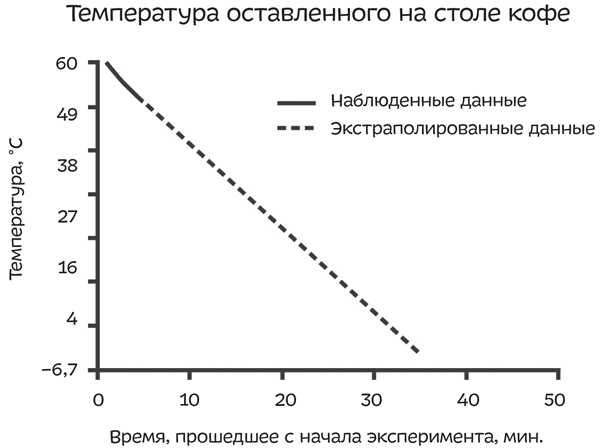
При экстраполяции не берут в расчет ограничения, накладываемые физикой: температура кофе не может упасть ниже температуры комнаты. Также не учитывается тот факт, что скорость, с которой кофе остывает, уменьшается тем быстрее, чем ближе температура кофе к комнатной. В дальнейшем график охлаждения выглядит следующим образом:
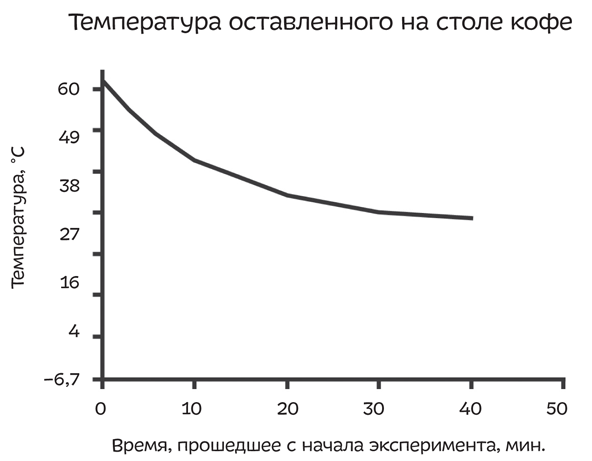
Обратите внимание, что крутизна кривой, соответствующая первым десяти минутам, не сохраняется — кривая становится все более пологой. Для экстраполяции особенно важны две вещи: наличие большого количества наблюдений, охватывающих большой промежуток, и понимание самой сути процесса.
ТОЧНЫЕ И ВЕРНЫЕ ЦИФРЫ
Когда мы сталкиваемся с точными цифрами, то обычно полагаем, что они к тому же еще и верны, но это не одно и то же. Если я скажу: «Сегодня многие люди покупают электромобили», — вы подумаете, что я строю догадки. Если я скажу: «16,39% продаж новых автомобилей составляют электрокары», — вы решите, что я точно знаю, о чем говорю. И в этот момент вы спутаете два таких понятия, как «точные» и «верные» цифры. Возможно, я все выдумал. Может, я опросил только небольшую группу людей возле дилерского центра электрокаров.
Вспомните упомянутый мною ранее заголовок Time, в котором говорилось, что на свете гораздо больше людей, у которых есть телефоны, нежели тех, у кого есть туалеты. Нельзя сказать, что это неправдоподобно, но это явное искажение того, что было обнаружено в результате исследования ООН. На самом деле в докладе ООН говорилось, что людей, у которых имелся доступ к мобильным телефонам, больше, нежели тех, у кого был доступ к туалетам, что существенно меняет картину. Одним мобильным телефоном могут пользоваться десятки людей. Отсутствие санитарных условий, конечно, огорчительно, но заголовок построен таким образом, что вы начинаете думать, будто в мире больше мобильных телефонов, нежели туалетов. А ведь эта информация не подтверждается данными.
Доступ — одно из тех слов, которые вас должны насторожить, когда вы встречаете их в статистике. Люди, имеющие доступ к медицинскому обслуживанию, возможно, просто живут рядом с медцентром, но это не означает, что им дадут там консультацию или что они имеют достаточно денег, чтобы заплатить за лечение. Как вы уже знаете, телевизионный канал C-SPAN доступен в 100 миллионах домов, но это не означает, что во всех 100 миллионах его смотрят. Я бы мог заявить, что 90% людей в мире имеют «доступ» к «Путеводителю по лжи», потому что 90% населения земного шара живут на расстоянии не больше 40 километров от интернета, железных или автомобильных дорог, взлетно-посадочных полос, портов или маршрутов собачьих упряжек.
МУХИ ОТДЕЛЬНО, КОТЛЕТЫ ОТДЕЛЬНО
Отличный способ жульничать с помощью статистики — сравнивать отличающиеся друг от друга вещи (данные, совокупности, типы продуктов) и при этом делать вид, что разницы между ними нет. Но, как гласит известное выражение, «мухи отдельно, котлеты отдельно».
Если использовать этот сомнительный метод, то можно прийти к такому заявлению: «Находиться на военной службе во время открытого конфликта (например, во время войны в Афганистане) гораздо безопаснее, нежели в тылу». Ход рассуждения будет таким: в 2010 году погибло 3482 американских военнослужащих. Исходя из общего числа военнослужащих — а их 1 431 000 человек, — получим 2,4 смертельных случая на тысячу человек. На территории Соединенных Штатов количество смертей в 2010 году составило 8,2 на тысячу человек. Иными словами, находиться на службе в военной зоне в три с лишним раза безопаснее, чем жить в Соединенных Штатах.
Давайте разберемся. Выборки очень разные, поэтому их нельзя сравнивать «в лоб». В действующей армии служат молодые здоровые солдаты, в их распоряжении питательные обеды и хорошее медицинское обслуживание. Население Соединенных Штатов весьма разнообразно: здесь проживают и старики, и больные, и гангстеры, и наркоманы, и любители погонять на мотоциклах, и любители игры в «ножички», а также огромное количество тех, у кого нет ни питательных обедов, ни медицинского обслуживания. Смертность среди этих людей высока, где бы они ни находились. А действующие военнослужащие не все находятся в зоне военных действий — некоторые проходят службу на безопасных базах, сидят в офисах Пентагона или же на призывных пунктах в торговых центрах районного масштаба.
Новостной журнал U.S. News & World Report как-то опубликовал статью, в которой приводилось соотношение демократов и республиканцев начиная с 1930-х годов. Проблема в том, что за это время принципиально поменялась сама процедура формирования выборки. В 1930-х и 1940-х респондентов отбирали в личном разговоре, а также с помощью адресных списков, созданных на основе телефонных справочников. К 1970-м опросы стали делать исключительно по телефону. В начале XX века при формировании выборки скорее учитывали тех, у кого был стационарный телефон, то есть людей с достатком, а они — во всяком случае, в то время — имели обыкновение голосовать за республиканцев. К 2000-м перешли на мобильные телефоны, из-за чего произошел явный перекос в сторону молодежи, отдававшей свои голоса, как правило, за демократов. Мы на самом деле не знаем, изменилась ли пропорция демократов и республиканцев с 1930-х годов, так как выборки не поддаются никакому сравнению. Нам кажется, мы изучаем одно, а на самом деле — другое.
Похожая проблема возникает, когда говорят о снижении уровня смертности в результате мотоциклетных аварий по сравнению с тем, что было три десятилетия назад. Сейчас в сводках упоминается больше трехколесных мотоциклов, а в прошлом столетии доминировали двухколесные модели; можно вспомнить тот факт, что когда-то шлемы были не обязательны, сейчас же их наличие в большинстве штатов оговаривается законом.
Остерегайтесь меняющихся выборок, когда делаете выводы! Журнал U.S. News & World Report (да, снова он) сообщил, что за прошедший 20-летний период увеличилось число врачей, при этом средняя зарплата значительно снизилась. Что же из этого следует? Вы можете сделать вывод, что сейчас не лучшее время, чтобы обучаться профессии врача, потому что их теперь пруд пруди (а избыточное предложение на рынке стало причиной снижения зарплаты). Возможно, это и так, но в защиту этого утверждения нет ни одного доказательства.
Вполне правдоподобно звучит заявление, что благодаря сужению специализации и росту технологий, наблюдаемым на протяжении последних 20 лет, у врачей появилось больше профессиональных возможностей — как следствие, на рынке стало больше доступных вакансий, особенно на фоне увеличения общего числа врачей. Так что же насчет снижения зарплаты? Возможно, дело в увольнении пожилых специалистов, которых заменили более молодые, согласные — в силу отсутствия опыта — на более низкую зарплату. Но и таких доказательств тоже нет. Важная составляющая статистической грамотности — понимать, что некоторые данные, подобно тем, что мы рассмотрели в этом примере, просто нельзя интерпретировать.
Иногда вот такая путаница с котлетами и мухами происходит от сравнения противоречивых подвыборок — потому что вы проигнорировали какую-то деталь, сочтя ее неважной. Например, отбирая пробы кукурузы на поле, обработанном новым удобрением, вы можете не обратить внимания на то, что некоторые початки получали больше солнца, а некоторые — больше воды. Или при исследовании влияния потока машин на частоту проведения ремонтных работ от вашего внимания может ускользнуть тот факт, что на определенных улицах больше водостоков, чем на других, и потому там чаще возникает необходимость ремонтировать асфальтовое покрытие.
Говорят, что происходит объединение выборок, когда данные о разнородных объектах соединяют в одну категорию, как в случае с яблоками и грушами. Если вас интересует количество шестеренок, выпущенных с дефектом, можно объединить данные по разным их видам и получить необходимые вам цифры в зависимости от того, какую цель вы преследуете.
Допустим, вам интересно сравнить сексуальное поведение детей в возрасте 10–12 лет и подростков постарше. То, каким образом вы объедините данные, может существенно повлиять на то, как люди их потом воспримут. Если перед вами стоит задача найти деньги на создание образовательных и консультационных центров, можно заявить нечто вроде: «70% школьников в возрасте от 10 до 18 лет ведут половую жизнь». Нас не удивляет, что в этой категории 17- или 18-летние школьники, — но десятилетки! Такие заявления могут повергнуть в шок их бабушек и дедушек, которых придется отпаивать валерьянкой. Но ведь понятно же, что в общей категории, к которой отнесли и десятилетних детей, и 18-летних подростков, оказались и те, кто ведет половую жизнь, и те, кто нет. Гораздо правильнее было разбить всех участников исследовании на группы, объединив по возрасту и имеющемуся у них жизненному опыту: например, 10–11 лет, 12–13, 14–15, 16–18.
Но и это не единственная проблема. Что вообще имеется в виду под словосочетанием «вести половую жизнь»? Какой конкретно вопрос задавали школьникам?
И вообще, действительно ли опрашивали школьников? Может статься, на все эти вопросы отвечали родители. На полученные данные могли повлиять разные факторы. Слова «вести половую жизнь» можно понимать по-разному. И ответы могут разниться в зависимости от того, как понимать вопрос. Ну и, конечно, респонденты не обязательно говорили правду.
Или вот еще пример: допустим, вы захотели поговорить о безработице как об общей проблеме, но тут возникает риск объединения в одной выборке людей с самым разным жизненным опытом. Некоторые безработные физически недееспособны; другие были уволены по объективной причине, например потому что были пойманы с поличным во время кражи или потому что пришли на работу в нетрезвом виде. Кто-то хотел бы работать, но ему не хватает квалификации; кто-то отбывает срок; кто-то больше не хочет работать, потому что снова начал учиться, ушел в монастырь или находится на иждивении. Когда статистику используют, чтобы повлиять на государственную политику, собрать деньги на какое-то дело или чтобы выпустить газету с заголовком поярче, нюансы часто опускают. А ведь именно они порой кардинально меняют дело.
Эти нюансы часто говорят сами за себя. Люди теряют работу по разным причинам. Вероятность того, что алкоголик или вор станет безработным, может быть в четыре раза выше, чем в случае с любым другим человеком. И подобные детали часто теряются при объединении выборок. Учитывая эти факторы в своем анализе данных, вы четко увидите, кто безработный и почему, а это, в свою очередь, может привести к разработке более качественных обучающих программ или к открытию дополнительных центров анонимных алкоголиков в том городе, где эти организации необходимы.
Если в разных центрах, изучающих поведение людей, используют для вещей разные определения, а для их измерения разные методы, то статистические данные будут очень разнородными, несравнимыми. Например, вы хотите определить количество пар, живущих вместе, но не зарегистрировавших свои отношения, — тогда в вашем распоряжении данные, уже собранные разными государственными агентствами. Но варьирующиеся определения могут привести к проблеме с категоризацией: что означает «жить вместе»? Определяется ли это количеством проведенных вместе ночей в неделю? Или тем, где находятся личные вещи живущих вместе людей? А может, тем, где они получают почту? Некоторые органы государственной власти юридически признают однополые пары, другие — нет. Если вы соберете данные в разных местах и разными методами, ваша статистика окажется почти бессмысленной. Если методология записи, сбора и замера данных сильно варьируется в отношении ключевых моментов, то в итоге статистические данные будут отражать не то, что видится в них вам.
Последние исследования показали, что уровень безработицы среди молодежи в Испании составил 23%, — и это поразительно. В отчете в одну группу были объединены люди, которые при других обстоятельствах оказались бы в разных: тут были и студенты, не заинтересованные в поиске работы, и те, кого только что уволили, и те, кто находился в поисках работы.
Для отслеживания безработицы в Соединенных Штатах существует шесть разных индексов (обозначенных U1–U6), которые отражают разные интерпретации понятия «безработный». Сюда относятся те, кто ищет работу, и те, кто еще учится и не ищет, и те, кому интересна работа на полный рабочий день, при том что они работают только неполный, и т. д.
В газете USA Today за июль 2015 года сообщалось, что уровень безработицы упал до 5,3% и что это был «самый низкий уровень начиная с апреля 2008 года». Более компетентные источники, включающие агентство Associated Press, журнал Forbes и газету New York Times, называли свою причину очевидного снижения: многие безработные просто бросили попытки найти работу и потому чисто технически уже не могли считаться рабочей силой.
Объединение выборок, однако, не всегда приводит к неверным выводам. Вы можете объединить результаты учеников школы обоих полов, особенно если нет никаких доказательств того, что эти результаты на самом деле разные. Таким образом вы можете увеличить размер выборки (и получить более устойчивую оценку того, что изучаете). Интерпретацию затрудняют только слишком широкое определение категории (как в случае с сексуальной активностью школьников, о которой мы говорили ранее) или противоречивые определения (как с парами, живущими вместе). Если объединить выборки правильно, это поможет сделать правильный анализ данных.
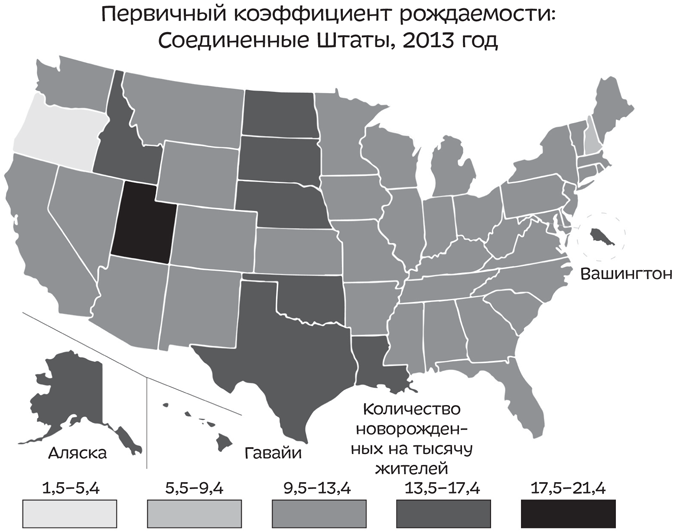
Предположим, вы работаете в штате Юта. Один крупный производитель детской одежды подумывает о том, чтобы переехать в ваш штат. И вам в голову приходит мысль указать ему на высокий уровень рождаемости в Юте. Таким образом вы рассчитываете привлечь его внимание. Для этого вы заходите на сайт и размещаете сведения о рождаемости:
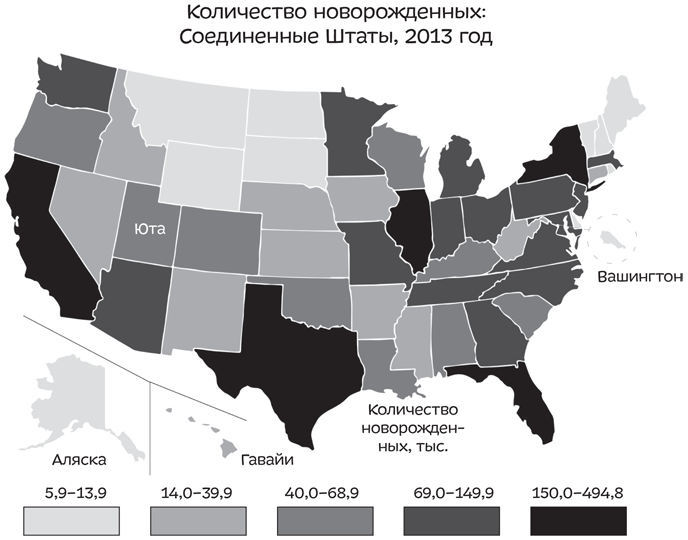
Юта выглядит лучше, чем Аляска, Вашингтон, Монтана, Вайоминг, Северная и Южная Дакота и небольшие штаты Северо-Востока. Но вряд ли можно сказать, что количество рождений там зашкаливает, особенно по сравнению с Калифорнией, Техасом, Флоридой и Нью-Йорком. Но погодите-ка, та карта, которую вы составили, показывает общее число рождений, а оно обязательно тем больше, чем больше население штата. Вместо этого вы могли бы составить карту с количеством новорожденных на тысячу жителей:
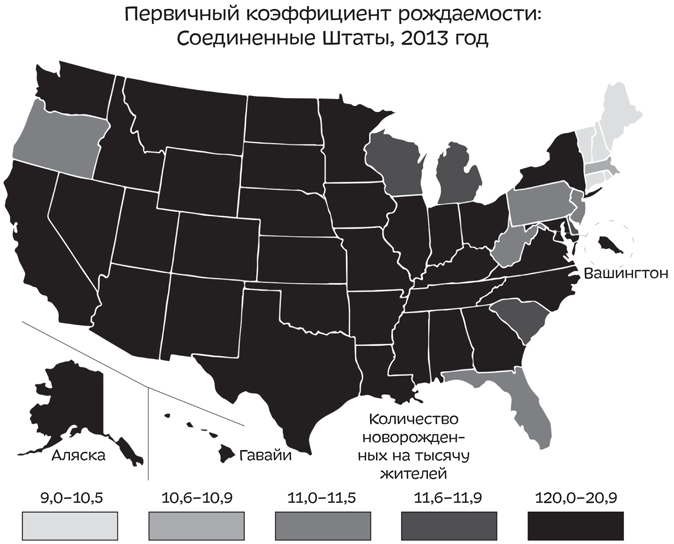
Это не помогает. Юта выглядит так же, как и остальные штаты. Что же делать? Поменяйте цвет! Вы можете поиграть с количеством величин в каждой категории — я имею в виду те полоски в самом низу, от серого до совсем черного. Удостоверившись, что уровень рождаемости Юты отображен отдельной категорией, вы заставите эти данные выделяться на фоне остальных.
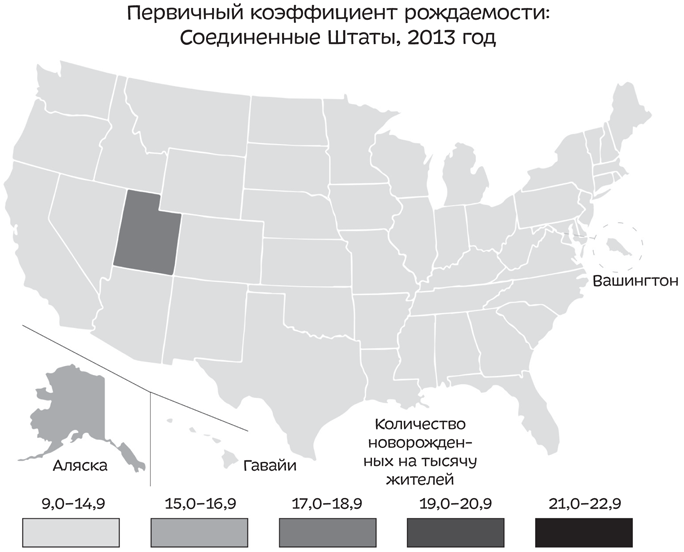
Конечно, это стало возможно только потому, что у штата Юта действительно самый высокий уровень рождаемости — ненамного, но все же. Выбрав для него «корзину» отдельного цвета, вы заставили его выделяться.
Если бы вы захотели сделать то же самое с остальными штатами, вам пришлось бы прибегнуть к трюкам иного рода, например показать, сколько детей рождается на квадратную милю или на магазин сети Walmart, — и таким образом получить функцию от чистого дохода. Дайте волю фантазии, прикиньте разные варианты — и вы cможете привести аргументы в пользу любого из 50 штатов.
А как же правильно изобразить такие данные? Это вопрос спорный, но, пожалуй, одним из нейтральных способов будет объединение данных так, чтобы по 20% штатов попали в одну из пяти категорий, каждая из которых отмечена своим цветом:
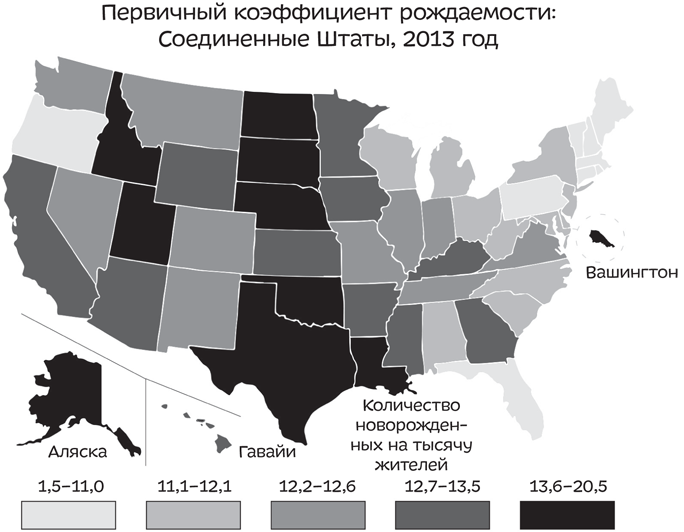
Другой вариант — сделать «корзины» одинакового размера:
Такой вид статистического обмана — использование категорий разных размеров на всех картограммах, кроме последней, — часто появляется в гистограммах. На приведенной ниже диаграмме показан средний процент числа подач 50 лучших игроков Главной лиги бейсбола в сезоне 2015 года:
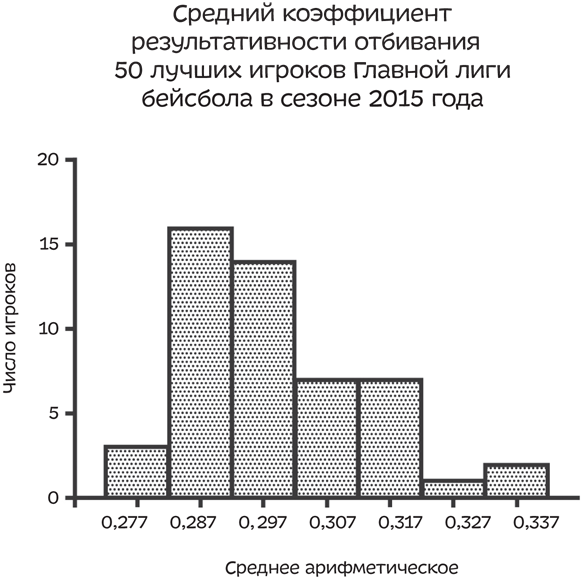
Итак, предположим, что вы игрок, средний коэффициент результативности отбивания которого равен 0,330, — и этот факт определяет вас во вторую по высоте категорию. Настало время раздачи бонусов, и вы не хотите, чтобы у вашего руководства нашлись хоть какие-нибудь причины отказать вам в премии в этом году, — вы уже купили Tesla. Поэтому просто измените ширину «корзин», объединив свои результаты с результатами двух игроков, чей коэффициент результативности равен 0,337, — и вот вы уже среди лучших игроков. Сомкните строй столбцов (в «корзине» 0,327 больше нет бэттеров), сделав разрыв оси X, который могут заметить лишь немногие.
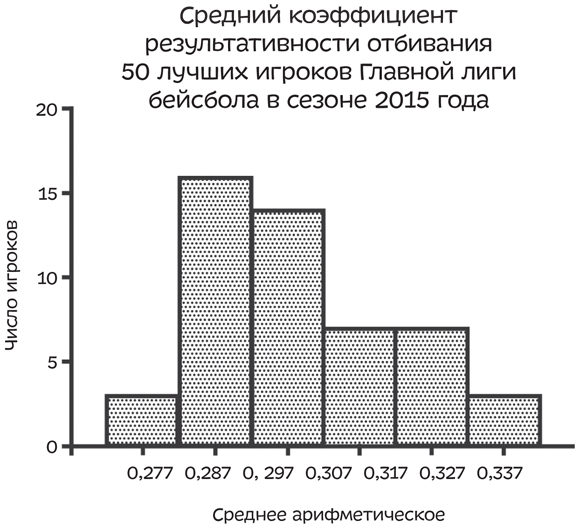
ОБМАНЧИВОЕ РАЗДЕЛЕНИЕ НА ГРУППЫ
В противоположность объединению выборок можно использовать разделение на группы, чтобы заставить кого-то поверить в то, чего на самом деле нет. Чтобы, например, заявить, что X — это главная причина Y, мне нужно просто разделить все остальные причины на более мелкие подгруппы.
Предположим, вы производите очистители воздуха и проводите кампанию, чтобы доказать, что респираторные заболевания — основная причина смерти в Соединенных Штатах, значительно превосходящая по частоте, например, заболевания сердечно-сосудистой системы или рак. Если говорить честно, то на сегодняшний день основная причина смерти в США — болезни сердца. По данным Центров по контролю и профилактике заболеваний в стране в 2013 году смерть в основном наступала по следующим причинам:
болезни сердца: 611 105;
рак: 584 881;
хронические заболевания нижних дыхательных путей: 149 205.
Даже если отбросить тот неприятный факт, что домашние очистители воздуха не сильно защищают от хронических респираторных заболеваний, эти данные не станут убедительным доводом для вашей компании. Вам бы, конечно, хотелось спасать более 100 тысяч жизней в год, но тот факт, что вы сумели справиться с третьей по важности причиной смерти, не сильно поможет вашей рекламной кампании. Хотя постойте! Ведь болезнь сердца — это не одно заболевание, их несколько:
острая ревматическая лихорадка и хроническое ревматическое заболевание сердца: 3260
гипертоническая болезнь сердца: 37 144
острый инфаркт миокарда: 116 793
сердечная недостаточность: 65 120
И так далее. Подобным же образом разбейте на подгруппы виды рака — и дело в шляпе! Заболевания нижних дыхательных путей становятся причиной смерти номер один. И вот вы уже заработали свой бонус. Некоторые производители продуктов питания использовали эту стратегию, чтобы скрыть количество жиров и сахаров, содержащихся в их продуктах.

