Разработка модели Стратегий
Модель ТОТЕ возникла как усовершенствованная версия старой модели «стимул-реакция» (С-Р), модели рефлекторной дуги, господствовавшей в психологии XX столетия. Она усовершенствовала модель С-Р, включив в нее два ключевых элемента моделирования человеческого опыта: обратную связь и результат. Роберт Дилтс и его коллеги (Dilts, Grinder, Bandler & DeLozier, 1980) пишут:
Существует обратная связь от результата действия к фазе тестирования, и мы сталкиваемся с рекурсивной петлей. Простейший тип диаграммы, графически представляющей эту концепцию рефлекторного действия, является альтернативой классической рефлекторной дуге. (р. 23).
Усовершенствованная модель ТОТЕ предлагает формат для описания последовательности внутренней переработки, инициируемой стимулом. Проверки этой модели соответствуют условиям, которым должна удовлетворять операция, прежде чем последует реакция. На фазе обратной связи система изменяет некоторый аспект стимула или внутреннего состояния индивида, чтобы реакция удовлетворяла проверке.
Дилтс и его коллеги иллюстрируют работу модели ТОТЕ на примере настройки радиоприемника:
Настраивая уровень громкости на радио или музыкальном центре, вы постоянно тестируете громкость звука, слушая его. Если звук слишком тихий, вы производите операцию, поворачивая ручку громкости по часовой стрелке. Если вы перестарались и звук оказался слишком громким, вы производите операцию, поворачивая ручку против часовой стрелки, чтобы уменьшить интенсивность звука. Настроив усилитель на нужный уровень громкости, вы выходите из ГОГЕ-программы «настройки громкости» и усаживаетесь в удобное кресло, чтобы продолжить чтение.
Что обозначают стрелки? Что может протекать по ним от одного блока к другому? Мы обсудим три возможных варианта: энергия, информация и контроль (р. 27).
Основатели когнитивного движения в психологии Миллер, Галлантер и Прибрам структурировали ТОТЕ так, чтобы идентифицировать потоки информации в системе. С этой целью они использовали метод измерения информации, лишь незадолго до этого разработанный Норбертом Винером и Клодом Шенноном. Позднее Дилтс и его коллеги рассмотрели концепцию «контроля» в системе: они описали информацию как «набор инструкций», контролирующих реакции или поведение:
Такая концепция чаще всего встречается при обсуждении вычислительных машин, где контроль операций, осуществляемых машиной, последовательно передается от одного набора инструкций к другому, по мере того как машина продолжает выполнять список инструкций, составляющих данную ей программу.
Представьте себе, что вы хотите найти определенную тему в книге. Вы открываете книгу на предметном указателе и находите тему. Когда вы просматриваете по очереди ссылки на номера страниц, ваше поведение может быть описано как находящееся под контролем этого списка чисел, причем контроль передается от одного числа к следующему по мере того, как вы просматриваете ссылки. Передачу контроля можно изобразить в виде стрелок, идущих от одного номера страницы к другому, однако стрелки будут иметь смысл, совершенно отличный от вышеописанных двух (р. 30).
Операции на стадии тестирования выявляют конгруэнтность или неконгруэнтность. Согласуется ли наша карта мира (представления, ожидания, желания и все остальное, что существует в нашем сознании) с опытом взаимодействия с этим миром? Если мы испытываем неконгруэнтность между первым и вторым, мы возвращаемся к рассмотрению первой проверки. Если мы обнаруживаем конгруэнтность между картой и опытом, мы выходим из программы.
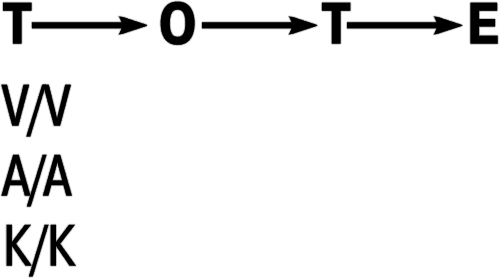
Рис. 16.1
Эта модель также картирует и демонстрирует важность постоянного приложения ресурсов к текущему состоянию, для того чтобы достичь нового результирующего состояния. Мы продолжаем совершать операции над различиями между картой и территорией. Успех приходит в результате многократного тестирования текущих состояний на соответствие желаемому состоянию, а затем доступа к ресурсам и их приложения, повторяемого до тех пор, пока мы не достигнем конгруэнтности между обоими состояниями.
Таким образом, модель ТОТЕ предполагает, что мы можем достичь совершенства в поведении благодаря:
• указанию цели или желаемого;
• сенсорным и поведенческим признакам или сигналам, свидетельствующим о достижении цели;
• совокупности операций, процедур и вариантов выбора, посредством которых мы можем достичь цели.
Бэндлер и Гриндер придумали модель Стратегий не на пустом месте. Они взяли за основу модель ТОТЕ и обогатили ее обнаруженными ими паттернами.
Обогащенная модель ТОТЕ
Таким образом, основоположники НЛП открыли – или изобрели, или отшлифовали – модель Стратегий, исходя из модели ТОТЕ, которую когнитивные психологи разработали в качестве более полной и усовершенствованной старой модели «стимул-реакция». Такова «связь времен» между моделями. Кожибски объяснял, что мы связываем время, когда развиваем идеи и открытия своих предшественников-изобретателей, так что нам не приходится заново изобретать компьютер.
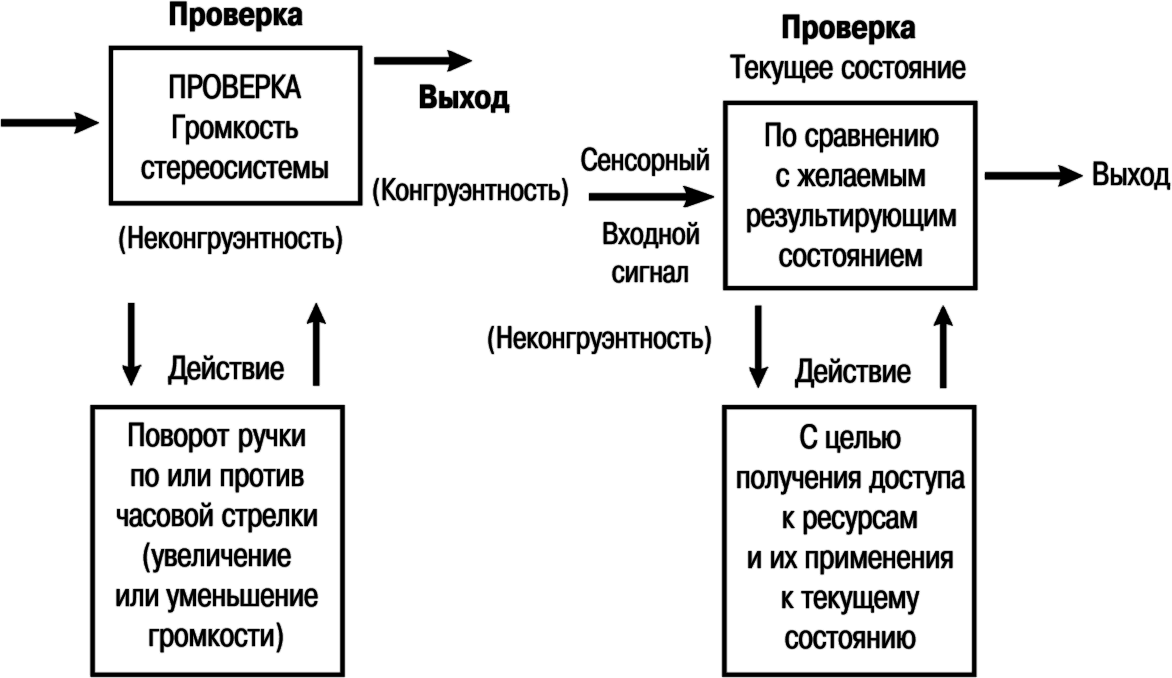
Рис. 16.2. Диаграмма модели ТОТЕ
ТОТЕ обеспечивает базовый формат для описания конкретных последовательностей форм поведения. Она описывает последовательность форм активности, которая консолидируется в функциональную единицу поведения, как правило, реализуемую на уровне, лежащем ниже порога осознания. Затем, обозначив этот процесс как ментальную стратегию, Дилтс, Бэндлер, Гриндер, Кэмерон-Бэндлер и Делозье (1980) интегрировали ТОТЕ в качестве шаблона в модель НЛП. Тем самым они обогатили и расширили модель ТОТЕ, так что она включила такие репрезентативные составляющие, как сенсорные репрезентативные системы, различения этих сенсорных модальностей («суб-модальности»), ключи зрительного доступа и лингвистические предикаты.
Результатом этого явилась модель, позволяющая нам распаковывать бессознательные стратегии, якорить элементы друг с другом, рефреймировать заключенные в них смыслы, а также проектировать, перепроектировать и/или встраивать стратегии. Эти нововведения сделали модель более приспособленной к моделированию опыта, позволяя заглянуть дальше и глубже в «черный ящик». В то же время эта модель обеспечила нам значительно более широкий и точный спектр языковых средств.
В этих отношениях НЛП еще более усовершенствовало модель ТОТЕ. Новая модель точно указывала, как мы осуществляем проверку и действия с точки зрения сенсорных систем, а также с точки зрения конкретных особенностей этих систем. Переформулировав Условия проверки и Действия как осуществляемые посредством репрезентативных систем, основоположники НЛП значительно усовершенствовали модели С-Р и ТОТЕ.
Например, чтобы протестировать нечто, можно сравнить внешние/внутренние визуально запоминаемые образы (Ve/Vi): «Выглядит ли написание этого слова так, как оно должно выглядеть согласно моим воспоминаниям?»
Можно проделать то же самое с кинестетической (Kе/Кi) или аудиальной системой (Ае/Аi). Опыт конгруэнтности (который заставляет нас ходить по замкнутой петле в пределах программы) также проявляется в виде репрезентаций, относящихся к той или иной репрезентативной системе.
Эта модель также позволяет провести проверку на сравнение двух внутренних сохраняемых или генерируемых репрезентаций. Такая проверка может касаться, скажем, интенсивности, размеров или цвета репрезентаций. Может потребоваться, чтобы интенсивность некоторого ощущения, звукового или зрительного образа достигла определенного порогового значения, прежде чем будет получен достаточно сильный сигнал, чтобы можно было выйти из программы.
Поскольку большинство людей, как правило, предпочитают использовать одну репрезентативную систему (PC) намного чаще, чем другие, очередность использования PC описывает то, как мы используем наиболее высоко ценимую нами PC при проведении Проверок и выполнении Действий. Мы часто используем предпочитаемую нами PC даже тогда, когда она функционирует не лучшим образом, а порой даже порождает проблемы и ограничения.
В усовершенствованной модели Стратегий НЛП эффективность моделирования часто предполагает сопоставление адекватной PC с задачей (например, визуальной PC с правописанием или аудиальной – с музыкой). Именно это и является одной из целей ТОТЕ и PC-анализа – нахождение PC, наиболее адекватной для шагов ТОТЕ, что позволяет нам получить желаемый результат за наименьшее число шагов. Если нам это удается, мы говорим, что наша модель элегантна. Модель Стратегий придает нашим PC новый смысл и мотивацию. Она показывает, что все наши PC представляют собой ресурсы, способствующие обучению и выполнению заданий.
Рассмотрим, к примеру, стратегии обучения правописанию. Фонетическая стратегия обучения правописанию предполагает последовательность: Ае’Аi/Ае. Однако поскольку визуальное кодирование английского языка не следует фонетическим правилам, люди, использующие визуальные стратегии правописания, систематически показывают лучшие результаты, чем те, кто использует аудиальные стратегии. Стратегия произнесения вслух работает очень эффективно для устных выступлений с чтением по бумажке. В то же время она не столь эффективна для правописания. Типичная визуальная стратегия обучения правописанию содержит последовательность шагов, показанную на рис. 16.3.
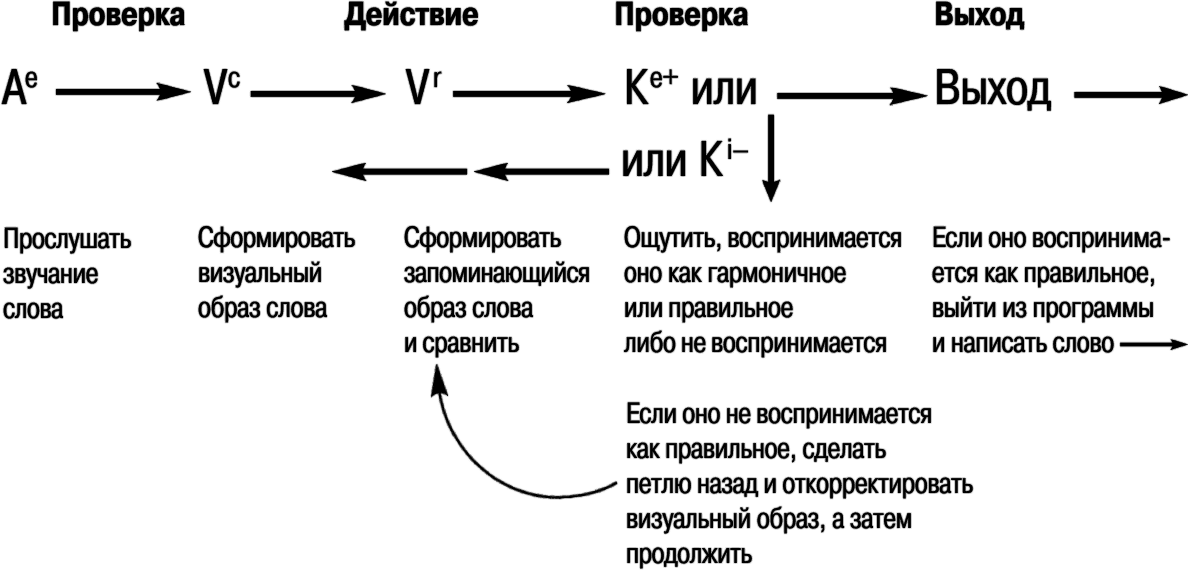
Рис. 16.3. ТОТЕ для правописания

