Приложение А
Краткий очерк классической молекулярной биологии
Наследственный материал всех организмов в природе – нуклеиновые кислоты. Существуют два вида нуклеиновых кислот: ДНК (дезоксирибонуклеиновая кислота) и близкородственная ей РНК (рибонуклеиновая кислота). Некоторые мелкие вирусы используют в качестве наследственного материала РНК. Все прочие вирусы и организмы – ДНК. (Исключением могут быть «дремлющие вирусы».)
Молекулы как ДНК, так и РНК тонкие и длинные, порой необычайно длинные. ДНК – полимер с регулярным остовом, в котором чередуются группы фосфатов и сахаров (в данном случае сахар называется дезоксирибоза).
К каждой группе сахаров присоединена маленькая плоскостная молекулярная группа, называемая основанием, или нуклеотидом. Существует четыре основных типа нуклеотидов: аденин (А), гуанин (Г), тимин (Т) и цитозин (Ц). (А и Г относятся к пуринам, Т и Ц – к пиримидинам). Порядок оснований вдоль любого данного отрезка ДНК несет наследственную информацию. Около 1950 г. Эрвин Чаргафф открыл, что в ДНК самого разнообразного происхождения количество А равняется количеству Т, а количество Г – количеству Ц. Эти закономерности известны как правила Чаргаффа.
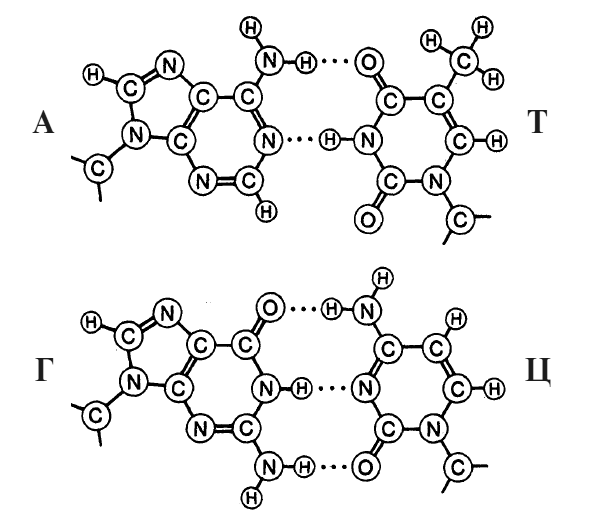
Рис. А-1. Две пары оснований: А = Т и Г = Ц. Обозначения оснований: А – аденин, Т – тимин, Г – гуанин, Ц – цитозин. Обозначения атомов: C – углерод, N – азот, O – кислород, H – водород.
РНК по структуре сходна с ДНК, только сахар в ней немного другой (рибоза вместо дезоксирибозы), а вместо Т у нее У (урацил). (Тимин и есть 5-метилурацил.) Таким образом, пара АТ замещается очень сходной парой АУ.
ДНК обычно существует в форме двойной спирали, состоящей из двух раздельных цепочек, навитых друг на друга вокруг общей оси. Как ни удивительно, две цепочки направлены в противоположные стороны. То есть если последовательность атомов в остове одной из цепочек читается снизу вверх, то у другой – сверху вниз.
На любом уровне основания соединены попарно – то есть основание в одной цепочке спарено с противолежащим основанием в другой цепочке. Пары возможны лишь в определенных сочетаниях. Вот они:
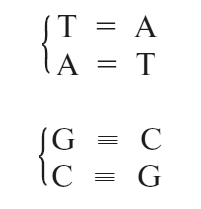
Их химические формулы даны на рис. А-1. Пары оснований удерживаются слабыми связями, которые называются водородными и обозначены здесь черточками. Следовательно, пара АТ образует две водородных связи, пара ГЦ – три. Это парное соединение оснований (нуклеотидов) – ключевая характеристика структуры.
Для репликации ДНК клетка расплетает цепочки и использует каждую цепочку по отдельности как инструкцию по созданию ее новой товарки. По завершении этого процесса получаются две двойные спирали, каждая из которых содержит одну старую цепочку и одну новую. Поскольку основания для новых цепочек надо подобрать так, чтобы выполнялись правила парности (А к Т, Г к Ц), у нас получается две двойные спирали, каждая из которых по последовательности оснований полностью тождественна исходной. Если вкратце, этот точный механизм попарного соединения и есть молекулярная основа наследственности. Реальность, конечно, намного сложнее, чем эта бегло набросанная схема.
Важнейшая функция нуклеиновых кислот – кодирование белков. Белковая молекула – тоже полимер с упорядоченным остовом (полипептидной цепочкой) и боковыми группами, расположенными на регулярных расстояниях. Как остов, так и боковые цепочки белка заметно отличаются по химической природе от остова и боковых цепочек нуклеиновой кислоты. К тому же у белков существует двадцать различных видов боковых цепочек, тогда как у нуклеиновых кислот – только четыре.
Общая химическая формула полипептидной цепи дана на рис. А-2. «Боковые цепочки» присоединены в точках, обозначенных R, R’, R» и т. д. Точная химическая формула каждой из двадцати различных боковых цепочек известна, и ее можно найти в любом учебнике по биохимии.
Каждая полипептидная цепь образуется путем соединения «головой» к «хвосту» небольших молекул, называемых аминокислотами. Общая формула аминокислоты дана на рис. А-3, где R обозначает боковую цепочку – свою у каждой аминокислоты из волшебной двадцатки. В ходе этого процесса при каждом соединении теряется одна молекула воды. (Реальные этапы химических реакций несколько сложнее, чем это простое общее изложение.)
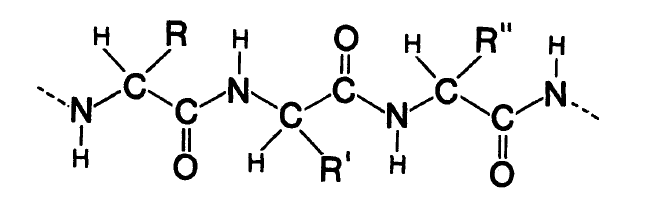
Рис. А-2. Базовая химическая формула полипептидной цепочки (на рисунке показано около трех звеньев). C – углерод, N – азот, O – кислород, H – водород. R, R’, R» – различные боковые цепочки (R означает «радикал»).
Все аминокислоты, встроенные в белки (кроме глицина), – это L-аминокислоты, тогда как их зеркальные отображения называются D-аминокислотами. Эта терминология относится к трехмерной конфигурации вокруг верхнего атома углерода на рис. А-3.
Синтез белка происходит на сложном биохимическом станке, который называется рибосомой. Ей помогают комплекс небольших молекул РНК, называемых тРНК (транспортная РНК), и ряд специальных ферментов. Информация о последовательности передается с помощью молекулы РНК, именуемой мРНК (матричной РНК). Чаще всего такая мРНК – она одноцепочечная – синтезируется в виде копии определенного участка ДНК по правилу парности оснований. Рибосома ползет вдоль матричной РНК, считывая ее последовательность оснований по три за один прием (см. приложение В). Общий процесс таков: ДНК ~~> РНК ~~> белок. Волнистые стрелки отображают направление, в котором передается информация о последовательности.
Дело еще больше усложняется тем, что каждая рибосома состоит не только из обширного комплекса белковых молекул, но и из ряда молекул РНК, две из которых довольно крупные. Эти молекулы РНК не являются матрицами. Они составляют элемент строения рибосомы.
По мере синтеза полипептидной цепи она сворачивается, укладываясь в хитроумную трехмерную структуру, необходимую белку, чтобы выполнять свою крайне специализированную функцию.
Белковые молекулы очень разнообразны по размерам. Типичная может состоять из нескольких сотен аминокислотных остатков. Поэтому ген обычно представляет собой отрезок ДНК в тысячу или более нуклеотидных пар, который кодирует одну полипептидную цепочку. Другие участки ДНК выполняют регуляторную роль, помогая включать и выключать определенные гены.
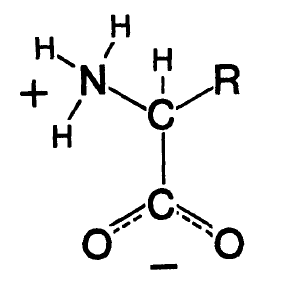
Рис. А-3. Общая формула аминокислоты. Аминогруппа – это NH3+. Кислотная группа – COO—. Боковая группа, различная у каждой аминокислоты, обозначена R. C – углерод, N – азот, O – кислород, H – водород.
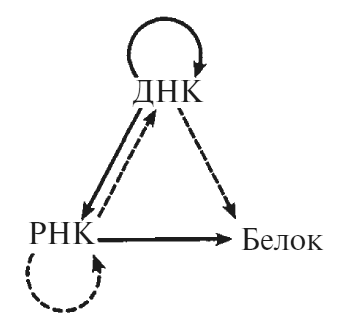
Рис. А-4. Схема, иллюстрирующая «центральную догму». Стрелками показаны разные направления передачи информации о последовательностях. Сплошными стрелками обозначены типичные виды передачи. Пунктирными – более редкие. Обратите внимание, что стрелок, направленных от белков, не существует.
Нуклеиновая кислота мелкого вируса может состоять примерно из 5000 оснований и кодировать лишь несколько белков. Бактериальная клетка, скорее всего, обладает ДНК из нескольких миллионов оснований, обычно собранных в кольцо, и они кодируют несколько тысяч различных белков. Ваша собственная клетка несет около трех миллиардов оснований, доставшихся вам от матери, и столько же – от отца; все они кодируют около ста тысяч белков. В 1970-е гг. обнаружили, что ДНК высших организмов может содержать длинные отрезки (некоторые из них находятся внутри генов и называются интронами) без явного смысла.
Так называемая центральная догма – широкая гипотеза, стремящаяся предсказать, какие способы передачи информации о последовательностях невозможны. Таковые соответствуют местам, где нет стрелок, на рис. А-4. Типичные виды передачи показаны сплошными стрелками, более редкие – пунктирными. Обратите внимание, что по направлению от белков ни одна стрелка не идет.
Обычные виды передачи описывались выше. Из более редких можно привести пример передачи РНК ~> РНК, используемой некоторыми РНК-вирусами, такими как вирус гриппа и полиомиелита. Передача РНК ~> ДНК (обратная транскрипция) встречается у так называемых РНК-ретровирусов. Примером может служить ВИЧ. Вариант ДНК ~> белок встречается лишь как курьез: при особых условиях в пробирке одноцепочечная ДНК может функционировать как матрица, но в природе этого, вероятно, не бывает вообще.

