Глава 6. Автоматическое размещение
Автоматическое размещение является основной функцией планировщика Kubernetes, который распределяет новые поды между узлами в соответствии с требованиями контейнеров к ресурсам и с соблюдением правил планирования. Этот паттерн описывает принципы алгоритма планирования в Kubernetes и способы влияния на решения о размещении.
Задача
Типичная система на основе микросервисов состоит из десятков или даже сотен изолированных процессов. Контейнеры и поды служат хорошими абстракциями для упаковки и развертывания, но не решают проблему размещения этих процессов на подходящих узлах. При большом и постоянно растущем количестве микросервисов назначение и размещение их по отдельности начинает вызывать неуправляемое нарастание сложностей.
Контейнеры имеют зависимости друг от друга, зависимости от узлов и потребности в ресурсах, и все эти параметры меняются со временем. Ресурсы, доступные в кластере, также меняются со временем из-за сокращения или расширения кластера или из-за того, что часть ресурсов уже занята размещенными контейнерами. Порядок размещения контейнеров также влияет на доступность, производительность и емкость распределенных систем. Все это делает планирование контейнеров движущейся целью, в которую приходится стрелять на ходу.
Решение
В Kubernetes размещение подов на узлах осуществляется планировщиком. Это область, имеющая массу настроек, на момент написания этих строк все еще продолжала быстро развиваться и изменяться. В этой главе мы рассмотрим основные механизмы управления планированием, движущие силы, влияющие на размещение, а также причины и последствия выбора того или иного варианта. Планировщик Kubernetes является мощным инструментом, позволяющим экономить время. Он играет фундаментальную роль в платформе Kubernetes, но, как и другие компоненты Kubernetes (API Server, Kubelet), его можно использовать изолированно или вообще не использовать.
На самом верхнем уровне планировщик Kubernetes извлекает определение каждого вновь созданного пода, используя API Server, и связывает его с определенным узлом. Он отыскивает подходящий узел (если таковой имеется) для каждого пода, будь то первоначальное размещение приложения, масштабирование вверх или перемещение с вышедшего из строя узла на работоспособный узел. При этом учитываются зависимости времени выполнения, требования к ресурсам и высокой доступности, используются приемы горизонтального распределения подов и размещения подов поблизости друг от друга для уменьшения задержек при взаимодействиях. Однако чтобы планировщик правильно выполнял свою работу и допускал возможность декларативного размещения, ему нужны информация о емкости узлов и контейнеры с объявленными профилями ресурсов и действующими политиками. Давайте рассмотрим каждое из требований подробнее.
Доступные ресурсы на узле
Прежде всего, кластер Kubernetes должен иметь узлы с объемом ресурсов, достаточным для запуска новых подов. Каждый узел имеет определенную емкость для запуска подов, и планировщик гарантирует, что сумма ресурсов, запрашиваемых подом, не превысит доступную емкость узла. Емкость узла, выделенного только для нужд Kubernetes, рассчитывается по формуле в листинге 6.1.
Листинг 6.1. Емкость узла
Доступная емкость [для подов приложений] =
Полная емкость узла [весь объем ресурсов узла]
- Емкость для нужд Kubernetes [демонов Kubernetes, таких как
kubelet, среды выполнения контейнера]
- Емкость для нужд системы [демонов ОС, таких как sshd, udev]
Если не зарезервировать ресурсы для системных демонов, которые обеспечивают работу ОС и самого фреймворка Kubernetes, и отдать под нужды подов полную емкость узла, это может привести к тому, что поды и системные демоны будут конкурировать за ресурсы, что приведет к проблемам, связанным с нехваткой ресурсов. Также имейте в виду, что если запускать контейнеры на узле, который не управляется Kubernetes, это отразится на вычислениях емкости узла в Kubernetes.
Обойти это ограничение можно, запустив под-заглушку, который ничего не делает, а только имитирует потребление ресурсов в объемах, соответствующих неотслеживаемым контейнерам. Такой под создается только для представления и ресурсов, потребляемых неотслеживаемыми контейнерами, и чтобы помочь планировщику построить более полную модель ресурсов узла.
Потребности контейнеров в ресурсах
Другим важным условием эффективного размещения подов является учет зависимостей контейнеров от среды времени выполнения и требований к ресурсам. Мы рассмотрели этот вопрос в главе 2 «Предсказуемые требования». Все сводится к тому, что контейнеры должны определять свои профили ресурсов (запросы и лимиты) и зависимости окружения, такие как наличие хранилищ или доступность портов. Только в этом случае поды могут разумно распределяться по узлам и работать, не влияя друг на друга в пиковые периоды.
Политики размещения
Последний элемент — наличие правильных политик фильтрации и приоритетов для конкретных потребностей приложений. Планировщик имеет набор предикатов и политик приоритетов по умолчанию, который подходит для большинства случаев. Его можно переопределить и запустить планировщик с другим набором политик, как показано в листинге 6.2.
 Политики и настройки планирования может определить только администратор в ходе конфигурации кластера. Как обычный пользователь вы можете лишь использовать предопределенные планировщики.
Политики и настройки планирования может определить только администратор в ходе конфигурации кластера. Как обычный пользователь вы можете лишь использовать предопределенные планировщики.
Листинг 6.2. Пример политики планирования
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 2},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 2},
{"name" : "EqualPriority", "weight" : 1}
]
}
Предикаты — это правила фильтрации неподходящих узлов. Например, PodFitsHostsPorts планирует поды, требующие наличия определенных фиксированных портов, только на узлах, где эти порты еще доступны.
Приоритеты — это правила, которые сортируют доступные узлы в соответствии с предпочтениями. Например, LeastRequestedPriority дает узлам с меньшим количеством запрашиваемых ресурсов более высокий приоритет.
Имейте в виду, что, кроме настройки политик планировщика по умолчанию, также можно запустить несколько планировщиков и позволить подам указывать, какой планировщик должен их размещать. Можно запустить другой экземпляр планировщика с другими настройками, дав ему уникальное имя. А затем просто добавить поле .spec.schedulerName с именем этого планировщика в настройки пода, после чего этот под будет выбираться для планирования только этим специализированным планировщиком.
Процесс планирования
Поды назначаются узлам, обладающим определенной емкостью, в соответствии с политиками размещения. Для полноты обсуждения на рис. 6.1 в общих чертах показано, как все необходимые элементы собираются вместе и какие основные этапы преодолевает под в процессе планирования.
Рис. 6.1. Процесс выбора узла для пода
Как только появляется под, который пока не назначен никакому узлу, он выбирается планировщиком вместе со всеми узлами, доступными для планирования, и набором политик фильтрации и приоритетов. На первом этапе планировщик применяет политики фильтрации и исключает из дальнейшего рассмотрения все узлы, которые не соответствуют критериям пода. На втором этапе оставшиеся узлы упорядочиваются по весу. На последнем этапе поду назначается узел, что является главным результатом процесса планирования.
В большинстве случаев лучше позволить планировщику самому назначить узел поду, а не пытаться реализовать свою логику размещения. Однако иногда может потребоваться принудительно связать под с конкретным узлом или группой узлов. Это назначение можно сделать с помощью селектора узла. .spec.nodeSelector — это поле в настройках пода, которое определяет массив пар ключ/значение, которые должны присутствовать в виде меток на узлах, пригодных для назначения данному поду. Например, предположим, что некоторый под должен выполняться на определенном узле, где имеется хранилище SSD или поддерживается ускорение вычислений на GPU. Тогда, если добавить в определение пода поле nodeSelector с содержимым disktype: ssd, как показано в листинге 6.3, только узлы с меткой disktype = ssd будут иметь право выполнять этот под.
Листинг 6.3. Селектор узла по типу доступного диска
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
nodeSelector:
disktype: ssd
Набор меток, которыми должен быть отмечен узел, пригодный для выполнения этого пода.
Помимо определения дополнительных меток узлов, можно использовать некоторые из меток которыми отмечен каждый узел по умолчанию. Например, каждый узел имеет уникальную метку kubernetes.io/hostname, которую можно использовать для размещения подов на узлах, исходя из имени хоста. Также можно использовать другие метки по умолчанию, которые определяют операционную систему, аппаратную архитектуру и типы экземпляров.
Близость узлов
Kubernetes поддерживает еще много весьма гибких способов настройки процесса планирования. Один такой способ — определение степени близости узлов, который является более общей формой способа на основе селектора узла, описанного выше, и позволяет задать правила, обязательные или предпочтительные. Обязательные правила должны выполняться всегда, чтобы узел мог быть выбран для запуска пода, тогда как предпочтительные правила подразумевают степень предпочтения, увеличивая вес соответствующих узлов, но не являются обязательными. Кроме того, поддержка понятия близости узлов позволяет выразить весьма широкий спектр ограничений, добавляя такие операторы, как In, NotIn, Exists, DoesNotExist, Gt и Lt. В листинге 6.4 показано, как определяется близость узлов.
Листинг 6.4. Определение пода с описанием близости узлов
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: numberCores
operator: Gt
values: [ "3" ]
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchFields:
- key: metadata.name
operator: NotIn
values: [ "master" ]
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
Жесткое требование: узел должен иметь больше трех ядер (обозначается меткой узла), чтобы участвовать в процессе планирования. Правило не пересматривается во время выполнения, если условия на узле изменятся.
Соответствие определяется меткой.
Нежесткое требование: список селекторов с весами. К весу каждого узла прибавляются веса совпавших селекторов, после чего выбирается узел с самым высоким весом, если он соответствует жестким требованиям.
Соответствие определяется полем (задается как jsonpath). Обратите внимание, что здесь допускается использовать только операторы In и NotIn, и в списке значений values может присутствовать только одно значение.
Близость и удаленность подов
Близость узлов является мощным инструментом планирования и следует выбирать именно его, когда возможностей селектора узла nodeSelector оказывается недостаточно. Этот механизм позволяет ограничить круг узлов, на которых может выполняться под, опираясь на соответствие меток или полей. Но он не позволяет выразить зависимости между подами и указать, как они должны размещаться относительно других подов. Для выражения требований к размещению подов с целью достижения высокой доступности или уменьшения задержек во взаимодействиях можно использовать оценку близости и удаленности подов.
Близость узлов помогает настроить выбор узлов, а близость подов не ограничивается узлами и позволяет выражать правила, затрагивающие несколько уровней топологии. Используя поле topologyKey и соответствующие метки, можно применять более детальные правила, которые комбинируют правила выбора домена, стойки, зоны облачного провайдера и региона, как показано в листинге 6.5.
Листинг 6.5. Определение пода с описанием близости узлов
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
confidential: high
topologyKey: security-zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
confidential: none
topologyKey: kubernetes.io/hostname
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
Обязательные правила, касающиеся размещения подов с учетом других подов, выполняющихся на целевом узле.
Метка-селектор для поиска подов, размещаемых вместе с данным.
Узлы, на которых выполняются поды с метками confidential=high, должны иметь метку security-zone. Для определяемого здесь пода будет выбран узел с той же меткой и значением.
Правила удаленности описывают узлы, на которых под не может быть размещен.
Правило говорит, что под не должен (но может) размещаться на любых узлах, где выполняются поды с меткой confidential=none.
Подобно близости узлов, существуют жесткие и мягкие требования к близости и удаленности подов, которые называются requiredDuringSchedulingIgnoredDuringExecution и preferredDuringSchedulingIgnoredDuringExecution соответственно. И так же как в случае близости узлов, в имени поля присутствует окончание IgnoredDuringExecution, которое добавлено для возможности расширения в будущем. В настоящий момент, если метки на узле изменятся и правила близости станут недействительными, поды продолжат выполняться, но в будущем такие изменения во время выполнения, возможно, будут учитываться.
Непригодность и допустимость
Еще одна возможность, помогающая управлять выбором узлов для выполнения пода, основана на понятиях непригодности и допустимости. Оценка близости узлов позволяет подам выбирать наиболее подходящие узлы, а непригодность и допустимость имеют противоположное назначение. Они позволяют узлам определять, какие поды должны или не должны планироваться на них. Непригодность — это характеристика узла, и если она определена, эта характеристика не позволяет планировать поды для выполнения на узле, если они непригодны для этого. В этом смысле непригодность и допустимость можно рассматривать как условие включения, позволяющее планировать на узлах, которые по умолчанию недоступны для планирования, тогда как правила близости являются условием исключения, явно определяющим, на каких узлах может выполняться под, и исключающим все невыбранные узлы.
Непригодность добавляется в узел с помощью kubectl: kubectl taint nodes master noderole.kubernetes.io/master="true":NoSchedule, что оказывает эффект, представленный в листинге 6.6. Соответствующая допустимость добавляется в определение пода, как показано в листинге 6.7. Обратите внимание, что параметры key и effect в разделе taints в листинге 6.6 и в разделе tolerations в листинге 6.7 имеют одни и те же значения.
Листинг 6.6. Непригодность узла
apiVersion: v1
kind: Node
metadata:
name: master
spec:
taints:
- effect: NoSchedule
key: node-role.kubernetes.io/master
Отметить этот узел как непригодный для планирования, если только под не определяет эту непригодность допустимой.
Листинг 6.7. Определение пригодности недопустимого узла
apiVersion: v1
kind: Pod
metadata:
name: random-generator
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
Считать допустимыми (доступными для планирования) объявленные непригодными узлы с ключом node-role.kubernetes.io/master. В промышленных кластерах этот признак непригодности устанавливается на главном узле для предотвращения планирования подов на нем. Определение допустимости, как в этом поде, позволяет запустить данный под на главном узле.
Считать допустимым, только если определен эффект NoSchedule. Это поле может быть пустым, и тогда допустимыми будут считаться любые эффекты.
Условие непригодности может быть жестким, предотвращающим планирование на узле (effect = NoSchedule); нежестким, рекомендующим избегать планирования на узле (effect = PreferNoSchedule); и вытесняющим уже запущенные поды с узла (effect = NoExecute).
Условия непригодности и допустимости помогают определять сложные варианты использования, такие как создание выделенных узлов для ограниченного набора подов, или принудительно вытеснять поды с проблемных узлов, объявляя их непригодными.
Вы можете влиять на размещение подов, чтобы обеспечить высокую доступность и производительность приложения, но старайтесь не сильно ограничивать планировщик и не загоняйте себя в угол, когда планирование новых подов оказывается невозможным, хотя ресурсов более чем достаточно. Например, если требования ваших контейнеров к ресурсам слишком грубые или узлы слишком малы, у вас могут оказаться незаполненными ресурсы на узлах, которые не используются.
На рис. 6.2 можно видеть, что узел A имеет 4 Гбайт незанятой памяти, потому что не осталось свободных ядер процессора для размещения других контейнеров. Создание контейнеров с меньшими требованиями к ресурсам могло бы помочь исправить ситуацию. Другое решение состоит в том, чтобы использовать механизм перепланирования в Kubernetes, который помогает дефрагментировать узлы и повысить степень их использования.
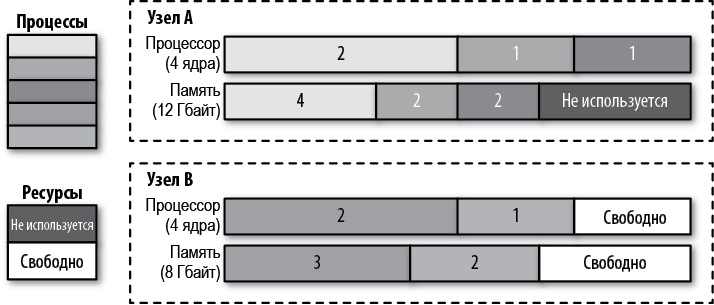
Рис. 6.2. Процессы, запланированные на узлах, и неизрасходованные ресурсы
После запуска пода на узле работа планировщика завершается, и местоположение пода больше не меняется, пока тот не будет удален и воссоздан без назначения узла. Как вы уже видели, со временем это может привести к фрагментации и недоиспользованию ресурсов кластера. Другая потенциальная проблема заключается в том, что решения планировщика основываются на его представлении о кластере в момент планирования нового пода. Если кластер меняется динамически, или меняются профили ресурсов узлов, или добавляются новые узлы, планировщик не будет перераспределять ранее запущенные поды. Кроме емкости узлов, также могут меняться их метки, влияющие на размещение, но это также никак не влияет на перераспределение уже запущенных подов.
Все эти сценарии относятся к ведению механизма перепланирования. Механизм перепланирования в Kubernetes относится к разряду вспомогательных и обычно запускается как задание, когда администратор кластера решает, что пришло время привести дефрагментацию кластера, перераспределив поды. Механизм перепланирования поддерживает некоторые предопределенные политики, которые можно включать, настраивать или отключать. Политики определяются в файле с настройками пода механизма перепланирования и в настоящее время включают:
RemoveDuplicates
Стратегия удаления дубликатов гарантирует выполнение на одном узле только одного пода, связанного с набором реплик ReplicaSet или развертыванием Deployment. Если обнаружится большее число подов, лишние поды будут вытеснены. Эта стратегия может пригодиться в сценариях, когда узел вышел из строя и управляющие контроллеры запустили новые поды на других, исправных узлах. Когда неисправный узел восстановится и вернется в кластер, количество запущенных модулей окажется больше желаемого, и тогда перепланировщик сможет помочь вернуть их число к нужному количеству реплик. Удаление дубликатов на узлах также может помочь равномерно распределить поды между несколькими узлами, если политики планирования и топология кластера изменятся после первоначального размещения.
LowNodeUtilization
Эта стратегия выявляет узлы с низким коэффициентом использования ресурсов и переносит на них поды с других, перегруженных узлов, в надежде добиться более удачного распределения и равномерного использования ресурсов. Под узлами с недоиспользованными ресурсами подразумеваются узлы, на которых количество ядер, объем памяти или число подов меньше настроенных пороговых значений thresholds. Аналогично, под перегруженными узлами подразумеваются узлы, на которых эти значения превышают настроенные значения targetThresholds. Любой узел, использование ресурсов которого находится между этими значениями, считается оптимально используемым и не подвергается действию этой стратегии.
RemovePodsViolatingInterPodAntiAffinity
Эта стратегия исключает блоки, нарушающие правила удаленности между подами, что может произойти при добавлении правил определения удаленности уже после размещения подов на узлах.
RemovePodsViolatingNodeAffinity
Эта стратегия предназначена для вытеснения подов, нарушающих правила близости.
Независимо от используемой политики, перепланировщик старается избежать вытеснения:
• критически важных подов, отмеченных аннотацией scheduler.alpha.kubernetes.io/critical-pod;
• подов, не управляемых набором реплик ReplicaSet, развертыванием Deployment или заданием Job;
• подов, управляемых контроллером DaemonSet;
• подов, имеющих локальное хранилище;
• подов с параметром PodDisruptionBudget, если вытеснение может нарушить установленные правила;
• пода самого перепланировщика (с этой целью под перепланировщика маркируется как критически важный).
Конечно, все операции вытеснения производятся с учетом уровня качества обслуживания подов, то есть первыми вытесняются поды с негарантированным качеством обслуживания, затем поды с переменным качеством обслуживания и, наконец, поды с гарантированным качеством обслуживания. Подробнее об уровнях качества обслуживания рассказывается в главе 2 «Предсказуемые требования».
Пояснение
Размещение — это область, в которую вмешательство нежелательно. Если вы будете следовать рекомендациям из главы 2 «Предсказуемые требования» и объявите все потребности контейнера в ресурсах, планировщик выполнит свою работу и поместит под на наиболее подходящий узел. Однако если этого недостаточно, у вас в запасе есть несколько способов помочь планировщику прийти к желаемой топологии развертывания. В заключение перечислим подходы к управлению планированием (имейте в виду, что на момент написания этой книги данный список менялся с каждой новой версией Kubernetes), в порядке возрастания их сложности:
nodeName
Простейшая форма связывания пода с узлом. В идеале это поле должно заполняться планировщиком, который руководствуется политиками, а не вручную. Связывание пода с конкретным узлом значительно сужает область для планирования этого пода. Это возвращает нас к эпохе, предшествовавшей Kubernetes, когда мы явно указывали узлы для запуска наших приложений.
nodeSelector
Массив пар ключ/значение. Чтобы под можно было запустить на узле, указанные пары ключ/значение должны присутствовать на нем в виде меток. Селектор узла — один из самых простых механизмов управления выбором планировщика, требующий всего лишь добавить несколько значимых меток в определение пода и узла (что приходится делать в любом случае).
Изменение правил планирования по умолчанию
Планировщик по умолчанию отвечает за размещение новых подов на узлах в кластере и справляется с этой задачей достаточно хорошо. Однако при необходимости можно изменить список политик фильтрации и приоритетов планировщика.
Близость и удаленность пода
Эти правила позволяют выражать зависимости одних подов от других, например, для уменьшения задержек в приложении, увеличения доступности, удовлетворения ограничений безопасности и т.д.
Близость узла
Это правило позволяет выразить зависимость пода от узлов. Например, учесть наличие оборудования, местоположение и т.д.
Непригодность и допустимость
Непригодность и допустимость позволяют узлу контролировать, какие поды могут или не могут планироваться на них, например, чтобы выделить узел для группы подов или даже вытеснить поды во время выполнения. Другое преимущество настроек непригодности и допустимости состоит в том, что при расширении кластера Kubernetes путем добавления новых узлов с новыми метками вам не придется добавлять новые метки во все поды — это нужно будет сделать только для подов, которые должны быть размещены на новых узлах.
Нестандартный планировщик
Если ни один из предыдущих подходов не является достаточно хорошим или ваши требования к планированию слишком сложны, вы можете реализовать свой планировщик. Такой планировщик может работать вместо стандартного планировщика Kubernetes или одновременно с ним. Можно использовать гибридный подход, когда запускается процесс «расширения планировщика», к которому обращается стандартный планировщик Kubernetes на последнем этапе перед принятием решения о планировании. При таком подходе не требуется реализовывать полный планировщик и достаточно лишь предоставить HTTP API для фильтрации и определения приоритетов узлов. Преимущество создания своего планировщика состоит в том, что при этом можно учитывать факторы, внешние по отношению к кластеру Kubernetes, такие как стоимость оборудования, сетевые задержки и оптимизация использования ресурсов при распределении подов между узлами. Также есть возможность задействовать несколько своих планировщиков вместе с планировщиком по умолчанию и выбирать, какой планировщик использовать для каждого пода. Каждый планировщик может иметь свой набор политик для своего подмножества подов.
Как видите, есть много способов управлять размещением подов, и выбор правильного подхода или комбинирование нескольких подходов могут оказаться сложной задачей. Основная мысль этой главы: определите и объявите профили ресурсов контейнера, снабдите поды и узлы соответствующими метками, наконец, старайтесь поменьше вмешиваться в работу планировщика Kubernetes.
Дополнительная информация
• Пример автоматизированного размещения (http://bit.ly/2TTJUMh).
• Связывание подов с узлами (https://kubernetes.io/docs/user-guide/node-selection/).
• Описание планирования и размещения узлов (https://red.ht/2TP1ceB).
• Бюджет неработоспособности пода (https://kubernetes.io/docs/admin/disruptions/).
• Гарантии планирования критически важных подов (https://kubernetes.io/docs/admin/rescheduler/).
• Планировщик Kubernetes (http://bit.ly/2Hrq8lJ).
• Алгоритм планирования (http://bit.ly/2F9Vfi2).
• Настройка нескольких планировщиков (http://bit.ly/2HLv5Fk).
• Перепланировщик для Kubernetes (http://bit.ly/2YMQzYn).
• Статья «Keep Your Kubernetes Cluster Balanced: The Secret to High Availability» (http://bit.ly/2zuecKk).
• Видеоролик «Everything You Ever Wanted to Know About Resource Scheduling, but Were Afraid to Ask» (http://bit.ly/2FNkBT9).
Игнорировать в процессе выполнения. — Примеч. пер.
Если метки узла изменятся и поды, прежде несовместимые с этим узлом в соответствии с селектором близости, окажутся совместимыми, они будут планироваться для выполнения на этом узле.

