Глава 4. Проверка работоспособности
Паттерн Health Probe (Проверка работоспособности) определяет порядок передачи информации о состоянии приложения в Kubernetes. Чтобы добиться максимальной автоматизации, облачное приложение должно постоянно сообщать о своем состоянии, чтобы фреймворк Kubernetes мог определить, работает ли приложение и готово ли оно обслуживать запросы. Доступность этой информации влияет на управление жизненным циклом подов и способом передачи трафика в приложение.
Задача
Kubernetes регулярно проверяет состояние процесса контейнера и перезапускает его при обнаружении проблемы. Однако из практики мы знаем, что простой проверки состояния процесса недостаточно для определения работоспособности приложения. Часто бывает так, что приложение зависает, а его процесс все еще работает. Например, приложение на Java может столкнуться с ошибкой OutOfMemoryError (нехватка памяти), но при этом процесс JVM будет продолжать выполняться. Также приложение может зависнуть, попав в бесконечный цикл или в состояние взаимоблокировки или когда система начинает активно использовать файл подкачки из-за нехватки памяти. Для выявления подобных ситуаций фреймворку Kubernetes нужен надежный способ проверки работоспособности приложений — не для того, чтобы понять внутреннюю работу приложения, а чтобы убедиться, что приложение работает как ожидается и способно обслуживать потребителей.
Решение
Индустрия программного обеспечения признает невозможность писать код без ошибок. Более того, в распределенных приложениях вероятность сбоев возрастает. В результате основное внимание сместилось с обнаружения и устранения неисправностей на обнаружение сбоев и восстановление работоспособности после них. Обнаружение сбоя — сложная задача. Она не имеет универсального решения, пригодного для всех приложений, потому что разные приложения имеют разное понятие сбоя. Кроме того, разные виды сбоев требуют разных корректирующих воздействий. Временные сбои могут устраняться самим приложением при наличии достаточного времени, а при некоторых других сбоях может потребоваться перезапустить приложение. Давайте посмотрим, какие проверки использует Kubernetes для обнаружения и исправления сбоев.
Проверка наличия процесса
Проверка наличия процесса — это самая простая проверка, которую Kubelet выполняет постоянно. Если процессы не запущены, они запускаются. То есть благодаря только одной этой простой проверке приложение становится немного более надежным. Если ваше приложение способно самостоятельно обнаружить сбой и завершиться, тогда вам вполне достаточно будет этой простой проверки работоспособности процесса. Однако для большинства случаев этого недостаточно и необходимы другие виды проверок.
Проверка работоспособности
Если ваше приложение попадает в ситуацию взаимоблокировки, процесс не останавливается сам по себе и продолжает действовать. Чтобы обнаружить подобные проблемы и любые другие нарушения в работе бизнес-логики приложения, Kubernetes использует проверки работоспособности — регулярные проверки, выполняемые агентом Kubelet, который запрашивает у контейнера подтверждение его работоспособности. Важно, чтобы проверка работоспособности выполнялась извне, а не внутри самого приложения, потому что некоторые сбои могут помешать сторожевому коду в приложении сообщить об ошибке. В отношении корректирующих воздействий проверка работоспособности аналогична проверке наличия процесса, поэтому при обнаружении сбоя контейнер перезапускается. Однако эти проверки обеспечивают большую гибкость в выборе методов проверки приложения, а именно:
• Проверка через HTTP заключается в отправке HTTP-запроса GET на IP-адрес контейнера и в ожидании HTTP-ответа с кодом от 200 до 399.
• Проверка через сокет TCP предполагает благополучный обмен через соединение TCP.
• Проверка через выполнение заключается в выполнении произвольной команды в ядре контейнера и в ожидании кода благополучного ее завершения (0).
Организация проверки работоспособности через HTTP показана в листинге 4.1.
Листинг 4.1. Контейнер с поддержкой проверки работоспособности
apiVersion: v1
kind: Pod
metadata:
name: pod-with-liveness-check
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
env:
- name: DELAY_STARTUP
value: "20"
ports:
- containerPort: 8080
protocol: TCP
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
Конечная точка для проверки через HTTP.
Ждать 30 секунд перед первой проверкой работоспособности, чтобы дать приложению время запуститься.
В зависимости от характера приложения, вы можете подобрать наиболее подходящий метод. Решение о признании или непризнании приложения работоспособным зависит от конкретной реализации. Но имейте в виду, что если приложение будет признано неработоспособным, произойдет перезапуск контейнера. Если перезапуск контейнера не помогает, продолжать проверку работоспособности бессмысленно, потому что перезапуск не устраняет основную проблему.
Проверка готовности
Проверку работоспособности удобно использовать для поддержания приложений в работоспособном состоянии, останавливая сбойные контейнеры и заменяя их новыми. Но иногда контейнер может действовать с ошибками и его повторный запуск не решает проблему. Наиболее распространенный пример — когда контейнер запускается, но по каким-то причинам не готов обрабатывать какие-либо запросы. Или, может быть, контейнер перегружен, задержка в обработке запросов увеличивается, и вы хотите, чтобы он временно предпринял меры защиты против высокой нагрузки.
Для таких сценариев Kubernetes поддерживает проверки готовности. Для проверки готовности используют те же методы, что и для проверки работоспособности (через HTTP, TCP или выполнение команд), но корректирующие воздействия отличаются. Если проверка готовности потерпела неудачу, контейнер не перезапускается, а просто исключается из обработки входящего трафика. Проверка готовности помогает определить, когда контейнер будет готов к работе, чтобы дать ему некоторое время для инициализации перед получением запросов от службы. Также эти проверки могут использоваться для отключения службы от трафика на более поздних этапах, потому что проверки готовности выполняются регулярно, аналогично проверкам работоспособности. В листинге 4.2 показано, как организовать проверку готовности путем проверки наличия файла, который приложение создает по завершении подготовки к работе.
Листинг 4.2. Контейнер с поддержкой проверки готовности
apiVersion: v1
kind: Pod
metadata:
name: pod-with-readiness-check
spec:
containers:
- image: k8spatterns/random-generator:1.0
name: random-generator
readinessProbe:
exec:
command: [ "stat", "/var/run/random-generator-ready" ]
Проверка наличия файла, создаваемого приложением по завершении подготовки к обработке запросов. stat возвращает ошибку, если файл отсутствует, что обеспечивает отрицательный результат проверки.
И снова ваша реализация проверки работоспособности должна решать, когда приложение готово к выполнению своей работы, а когда его следует оставить в покое. В отличие от проверки наличия процесса и проверки работоспособности, которые предназначены для восстановления после сбоя путем перезапуска контейнера, проверка готовности требует дать приложению время на восстановление. Помните, что Kubernetes попытается оградить ваш контейнер от получения новых запросов (например, когда он выключается) независимо от того, проходит ли проверка готовности после получения сигнала SIGTERM.
Во многих случаях у вас будут одинаковые проверки работоспособности и готовности. Но проверка готовности дает контейнеру время для запуска. Только после благополучного прохождения проверки готовности развертывание считается успешным, и, например, поды с более старой версией могут быть остановлены в процессе непрерывного обновления.
Проверки работоспособности и готовности являются основополагающими строительными блоками для автоматизации облачных приложений. Прикладные фреймворки, такие как Spring, Wild-Fly Swarm, Karaf или MicroProfile для Java, предлагают свои реализации паттерна Health Probes (Проверка работоспособности).
Пояснение
Для полной автоматизации облачные приложения должны быть максимально открыты и предоставлять управляющей платформе средства чтения и интерпретации информации о работоспособности приложения и, при необходимости, для выполнения корректирующих воздействий. Проверка работоспособности играет важную роль в автоматизации таких действий, как развертывание, автоматическое восстановление, масштабирование и др. Однако существуют и другие средства, с помощью которых приложение может сообщить о себе больше информации.
Очевидный и старый метод решения этой задачи — журналирование. Желательно, чтобы контейнеры фиксировали в журналах все значимые события, связанные с ошибками, и хранили эти журналы в централизованном месте для дальнейшего анализа. Журналы, как правило, не используются для автоматизации действий, их задача — оповещение и помощь в дальнейшем расследовании. Более полезным аспектом журналов является возможность анализа причин сбоев и обнаружение незаметных ошибок.
Помимо вывода информации в стандартные потоки, также рекомендуется записывать причины завершения контейнера в /dev/termination-log. Это место, куда контейнер может записать свои последние слова, прежде чем окончательно исчезнуть. На рис. 4.1 показаны возможные варианты взаимодействия контейнера с платформой времени выполнения.
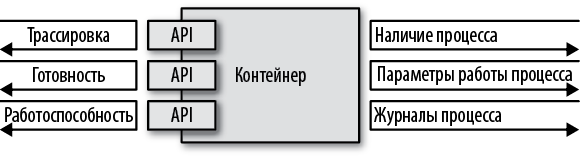
Рис. 4.1. Варианты наблюдения за контейнером
Контейнеры предоставляют универсальный способ упаковки и запуска приложений, интерпретируя их как черные ящики. Однако любой контейнер, предназначенный для выполнения в облачном окружении, должен предоставить API, с помощью которого среда выполнения сможет наблюдать за состоянием контейнера и предпринимать соответствующие действия. Это является главной предпосылкой для автоматизации обновления контейнеров и управления их жизненным циклом обобщенным способом, что, в свою очередь, повышает устойчивость системы и удобство работы пользователей. С практической точки зрения контейнерное приложение как минимум должно предоставлять API для различных видов проверок (работоспособности и готовности).
Еще более эффективные приложения должны также предоставлять управляющей платформе дополнительные средства для наблюдения за своим состоянием посредством интеграции с библиотеками трассировки и сбора метрик, такими как OpenTracing или Prometheus. Относитесь к своему приложению как к черному ящику, но реализуйте все необходимые API, чтобы упростить наблюдение и управление вашим приложением.
Следующий паттерн, Managed Lifecycle (Управляемый жизненный цикл), также основывается на обмене данными между приложениями и управляющим слоем в Kubernetes, но решает другую задачу — задачу получения приложением информации о важных событиях жизненного цикла пода.
Дополнительная информация
• Пример реализации проверки работоспособности (http://bit.ly/2Y6wCLG).
• Настройка проверок работоспособности и готовности (http://bit.ly/2r096A3).
• Настройка проверки наличия процесса с использованием проверок работоспособности и готовности (http://bit.ly/2HJkoDf).
• Ресурс качества обслуживания (Quality of Service) в Kubernetes (http://bit.ly/2HGimUq).
• Организация нормального завершения с Node.js и Kubernetes (http://bit.ly/2udUfo0).
• Дополнительные паттерны проверки работоспособности в Kubernetes (https://ahmet.im/blog/advanced-kubernetes-health-checks/).

