Глава 24. Эластичное масштабирование
Паттерн Elastic Scale (Эластичное масштабирование) охватывает масштабирование приложений в нескольких измерениях: горизонтальное масштабирование путем коррекции количества реплик пода; вертикальное масштабирование путем коррекции требований к ресурсам для подов; и масштабирование самого кластера путем изменения количества узлов. Все эти действия можно выполнить вручную, но в этой главе мы посмотрим, как то же самое может делать Kubernetes автоматически, в зависимости от нагрузки.
Задача
Kubernetes автоматизирует управление распределенными приложениями, состоящими из большого количества неизменяемых контейнеров, поддерживая желаемое их состояние, выраженное декларативно. Однако, учитывая непостоянный характер многих рабочих нагрузок, которые часто меняются со временем, непросто понять, как должно выглядеть желаемое состояние. Точное определение, сколько ресурсов потребуется контейнеру и сколько реплик службы должно быть запущено в данный момент для выполнения соглашений об уровне обслуживания, требует времени и усилий. К счастью, Kubernetes позволяет легко изменять объем ресурсов контейнера, число реплик службы или узлов в кластере. Такие изменения могут происходить вручную или автоматически, в соответствии с определенными правилами.
Kubernetes может не только следовать фиксированным настройкам подов и кластера, но также следить за уровнем нагрузки и событиями, связанными с изменением объемов ресурсов, анализировать текущее состояние и масштабироваться для достижения желаемой производительности. Эта способность наблюдать позволяет Kubernetes адаптироваться и обретать эластичность, опираясь на фактические показатели использования, а не на ожидаемые факторы. Давайте рассмотрим разные способы, которыми можно достичь такого поведения, и то, как объединить разные методы масштабирования.
Решение
Есть два основных подхода к масштабированию любых приложений: горизонтальное и вертикальное. Под горизонтальным масштабированием в мире Kubernetes подразумевается создание большего количества реплик пода. Под вертикальным масштабированием подразумевается увеличение объема ресурсов для контейнеров, управляемых подами. На бумаге все выглядит просто, но определить конфигурацию приложения для автоматического масштабирования на общей облачной платформе так, чтобы не повлиять на другие службы и на сам кластер, часто можно только методом проб и ошибок. Как всегда, Kubernetes предлагает множество средств и методов, помогающих найти лучшие настройки для приложений, и мы кратко рассмотрим их здесь.
Горизонтальное масштабирование вручную
Ручное масштабирование, как нетрудно догадаться, заключается в том, что оператор-человек посылает команды Kubernetes. Этот подход можно использовать в отсутствие автоматического масштабирования или для постепенного поиска оптимальной конфигурации приложения, соответствующей медленно меняющейся нагрузке, в течение длительных периодов. Преимущество ручного подхода заключается в том, что он допускает упреждающие, а не только реактивные изменения: зная периодичность и ожидаемую нагрузку на приложение, его можно масштабировать заранее, а не реагируя, например, на уже возросшую нагрузку с использованием средств автоматического масштабирования. Ручное масштабирование может выполняться в двух стилях.
Императивное масштабирование
Контроллер, такой как ReplicaSet, отвечает за постоянное выполнение заданного количества экземпляров пода. Благодаря этому, чтобы масштабировать под, достаточно изменить количество желаемых реплик. Масштабировать наше развертывание Deployment с именем random-generator до четырех экземпляров можно одной командой, как показано в листинге 24.1.
Листинг 24.1. Изменение числа реплик развертывания Deployment из командной строки
kubectl scale random-generator --replicas=4
После такого изменения контроллер ReplicaSet может запустить дополнительные поды или, если число действующих подов больше желаемого, остановить избыточные.
Декларативное масштабирование
Масштабирование с использованием команды scale выполняется тривиально просто и удобно для быстрого реагирования в чрезвычайных ситуациях, но этот подход не сохраняет настройки вне кластера. Обычно все приложения для Kubernetes хранят определения своих ресурсов в системе управления версиями, включая число реплик. Воссоздание ReplicaSet из исходного определения приведет к изменению числа реплик до прежнего уровня. Чтобы избежать такого отклонения конфигурации и обеспечить обратное распространение изменений, рекомендуется декларативно изменять желаемое количество реплик в ReplicaSet или некотором другом определении и применять изменения к Kubernetes, как показано в листинге 24.2.
Листинг 24.2. Использование развертывания Deployment для декларативной настройки числа реплик
kubectl apply -f random-generator-deployment.yaml
Мы можем масштабировать ресурсы, управляющие несколькими подами, такие как ReplicaSet, Deployment и StatefulSet. Обратите внимание на асимметричное поведение при масштабировании StatefulSet с постоянным хранилищем. Как рассказывалось в главе 11 «Служба с состоянием», если в StatefulSet имеется элемент .spec.volumeClaimTemplates, он будет создавать PVC при масштабировании вверх, но не будет удалять при масштабировании вниз, чтобы предотвратить удаление хранилища.
Еще одним ресурсом Kubernetes, доступным для масштабирования, но следующим другим соглашениям об именовании, является ресурс задания Job, который был описан в главе 7 «Пакетное задание». Масштабирование задания с целью параллельного выполнения нескольких экземпляров одного и того же пода осуществляется изменением поля .spec.parallelism, а не .spec.replicas. Однако это дает тот же семантический эффект: увеличение пропускной способности путем запуска дополнительных обрабатывающих подов, которые действуют как одна логическая единица.
 Для описания полей в этой книге используется формат определения путей JSON. Например, имя .spec.replicas соответствует полю replicas в разделе spec объявления ресурса.
Для описания полей в этой книге используется формат определения путей JSON. Например, имя .spec.replicas соответствует полю replicas в разделе spec объявления ресурса.
Оба стиля масштабирования вручную (императивный и декларативный) предполагают, что человек будет наблюдать или предвидеть изменение нагрузки на приложение, принимать решение о направлении и величине масштабирования и применять это решение к кластеру. Однако эти стили не подходят для приложений с динамической нагрузкой, которая часто меняется и требует постоянной адаптации. Давайте посмотрим далее, как можно автоматизировать принятие решений о масштабировании.
Автоматическое горизонтальное масштабирование
Многие рабочие нагрузки имеют динамическую природу, меняясь со временем и затрудняя определение фиксированных настроек масштабирования. Но облачные технологии, такие как Kubernetes, позволяют создавать приложения, легко адаптирующиеся к изменяющимся нагрузкам. Поддержка автоматического масштабирования в Kubernetes позволяет определять переменную емкость приложения вместо фиксированной, которая обеспечивает достаточную пропускную способность для обслуживания другой нагрузки. Проще всего такое поведение реализовать с использованием HorizontalPodAutoscaler (HPA) для горизонтального масштабирования числа подов.
Определение HPA для развертывания Deployment random-generator можно создать с помощью команды в листинге 24.3. Чтобы это определение HPA имело какой-либо эффект, важно, чтобы при развертывании было объявлено ограничение .spec.resources.requests для процессора, как описано в главе 2 «Предсказуемые требования». Также важно, чтобы в кластере был включен сервер метрик, который собирает данные об использовании ресурсов.
Листинг 24.3. Создание определения HPA из командной строки
kubectl autoscale deployment random-generator --cpu-percent=50 --min=1 --max=5
Эта команда создаст определение HPA, показанное в листинге 24.4.
Листинг 24.4. Определение HPA
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: random-generator
spec:
minReplicas: 1
maxReplicas: 5
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: random-generator
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
Минимальное число всегда выполняющихся подов.
Максимальное число подов, которое может быть достигнуто при масштабировании вверх.
Ссылка на объект, связанный с этим определением HPA.
Уровень использования процессора в процентах от запрошенного в подах. Например, если в поде параметр .spec.resources.requests.cpu имеет значение 200m, масштабирование вверх произойдет, когда средняя величина использования процессора превысит 100m (= 50%).
 В листинге 24.4 для настройки HPA используется версия API ресурса v2beta2. Эта версия находится в активной разработке и является расширением версии v1. Версия v2 предлагает намного больше критериев, чем загрузка процессора: например, потребление памяти или нестандартные метрики для конкретного приложения. Командой kubectl get hpa.v2beta2.autoscaling -o yaml легко можно преобразовать ресурс HPA v1, созданный командой kubectl autoscale, в ресурс v2.
В листинге 24.4 для настройки HPA используется версия API ресурса v2beta2. Эта версия находится в активной разработке и является расширением версии v1. Версия v2 предлагает намного больше критериев, чем загрузка процессора: например, потребление памяти или нестандартные метрики для конкретного приложения. Командой kubectl get hpa.v2beta2.autoscaling -o yaml легко можно преобразовать ресурс HPA v1, созданный командой kubectl autoscale, в ресурс v2.
Следуя этому определению, контроллер HPA будет стремиться сохранить среднее потребление процессора на уровне 50% от значения, затребованного в .spec.resources.requests, изменяя количество запущенных экземпляров пода в диапазоне от одного до пяти. Такое определение HPA можно применить к любым ресурсам, которые поддерживают подресурс scale, такие как Deployment, ReplicaSet и StatefulSet, но вы должны учитывать побочные эффекты. Развертывания Deployment создают новые наборы реплик во время обновлений, но не копируют никаких определений HPA. Если применить определение HPA к ReplicaSet, который управляется развертыванием Deployment, оно не будет скопировано в новые ReplicaSet и просто потеряется. Лучше всего применять HPA к абстракции развертывания Deployment более высокого уровня, которая сохраняет и применяет HPA к новым версиям ReplicaSet.
Теперь посмотрим, как определение HPA может заменить оператора-человека и обеспечить автоматическое масштабирование. В общем случае контроллер HPA непрерывно выполняет следующие действия:
1. Извлекает метрики подов, которые подлежат масштабированию согласно определению HPA. Метрики извлекаются не напрямую из подов, а из Kubernetes Metrics API, возвращающего агрегированные метрики (и даже пользовательские и внешние метрики, если выполнены соответствующие настройки). Метрики уровня подов извлекаются из Metrics API, а все остальные — из Kubernetes Custom Metrics API.
2. Вычисляет необходимое количество реплик на основе текущего и целевого значения метрики. Вот упрощенная версия формулы:
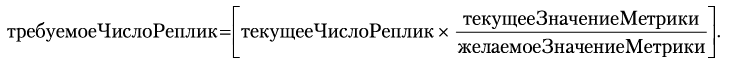
Например, если в настоящий момент выполняется единственный под с текущим значением метрики использования процессора, равным 90% от запрошенного, а желаемое значение составляет 50%, тогда количество реплик будет удвоено, так как 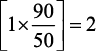 . В действительности используется более сложная реализация, потому что она должна учитывать несколько выполняющихся экземпляров пода, несколько типов метрик и множество крайних случаев и колеблющихся значений. Например, если задано несколько метрик, тогда контроллер HPA оценит каждую метрику отдельно и из всех результатов выберет наибольший. Конечный результат всех вычислений — это одно целое число, представляющее количество желаемых реплик, которое поможет удержать измеренное значение метрики ниже желаемого порогового значения.
. В действительности используется более сложная реализация, потому что она должна учитывать несколько выполняющихся экземпляров пода, несколько типов метрик и множество крайних случаев и колеблющихся значений. Например, если задано несколько метрик, тогда контроллер HPA оценит каждую метрику отдельно и из всех результатов выберет наибольший. Конечный результат всех вычислений — это одно целое число, представляющее количество желаемых реплик, которое поможет удержать измеренное значение метрики ниже желаемого порогового значения.
В поле replicas в определении ресурса, подлежащего автоматическому масштабированию, будет записано это вычисленное число, после чего другие контроллеры выполнят свою работу по достижению и поддержанию нового требуемого состояния. На рис. 24.1 показано, как работает HPA: осуществляет мониторинг метрик и изменяет число реплик соответственно.
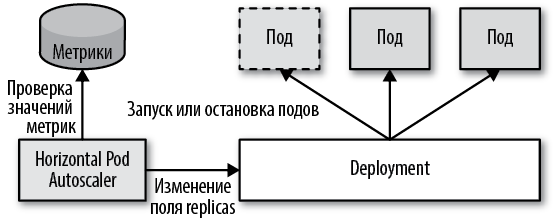
Рис. 24.1. Механизм автоматического горизонтального масштабирования подов
Автоматическое масштабирование — это область Kubernetes со множеством мелких деталей, которые продолжают быстро развиваться, и каждая из них может оказать существенное влияние на общее поведение механизма автоматического масштабирования. Поэтому здесь мы не будем подробно обсуждать все детали, но в разделе «Дополнительная информация» вы найдете ссылки на самую последнюю актуальную информацию по этому вопросу.
В целом поддерживаются следующие типы метрик:
Стандартные метрики
Эти метрики объявлены с параметром .spec.metrics.resource[:].type, содержащим значение Resource, и представляют метрики использования ресурсов, таких как процессор и память. Они доступны для любого контейнера в любом кластере под одними и теми же именами. Их значения можно определять в процентах, как это сделано в предыдущем примере, или в абсолютных значениях. В обоих случаях значения описывают гарантированный объем ресурса, то есть объем в поле requests контейнера, а не limits. Это самые простые в использовании типы метрик и обычно поддерживаются сервером метрик или компонентами Heapster, которые можно запускать как дополнения кластеров.
Нестандартные метрики
Эти метрики с параметром .spec.metrics.resource[:].type, содержащим значение Object или Pod, требуют расширенных настроек мониторинга кластера, которые могут отличаться для разных кластеров. Нестандартная метрика с типом Pod, как можно догадаться, описывает метрику, характерную для пода, тогда как метрика с типом Object может описывать любой другой объект. Нестандартные метрики обслуживаются агрегирующим API Server с точкой входа custom.metrics.k8s.io и поддерживаются различными адаптерами метрик, такими как Prometheus, Datadog, Microsoft Azure и Google Stackdriver.
Внешние метрики
К этой категории относятся метрики, которые описывают ресурсы, не являющиеся частью кластера Kubernetes. Например, у вас может быть под, принимающий сообщения от облачной службы очередей. Очень часто в таком сценарии бывает желательно масштабировать количество подов-потребителей в зависимости от глубины очереди. Такие метрики поддерживаются внешними плагинами метрик и имеют много общего с нестандартными метриками.
Правильно настроить автоматическое масштабирование очень непросто. Для этого придется немного поэкспериментировать с настройками. Ниже перечислены основные аспекты, которые следует учитывать при настройке HPA:
Выбор метрик
Одним из самых, пожалуй, важных решений, касающихся автоматического масштабирования, является выбор метрик. Чтобы добиться максимальной отдачи от HPA, между значением метрики и количеством реплик пода должна существовать прямая корреляция. Например, если выбранная метрика определяет количество запросов в секунду (например, HTTP-запросов в секунду), увеличение количества подов приведет к уменьшению среднего числа запросов, потому что запросы будут передаваться большему количеству подов. То же верно для метрики, определяющей использование процессора, потому что существует прямая корреляция между частотой запросов и использованием процессора (увеличение числа запросов ведет к увеличению использования процессора). Другие метрики, такие как потребление памяти, не имеют такой прямой корреляции. Проблема метрики потребления памяти заключается в том, что если служба потребляет определенный объем памяти, запуск большего числа экземпляров пода, скорее всего, не приведет к снижению потребления памяти, если приложение ничего не знает о других экземплярах и не имеет механизмов для перераспределения и освобождения своей памяти. Если память не освобождается и это отражается в метриках, HPA будет создавать все больше и больше подов, чтобы уменьшить объем потребляемой памяти, пока не достигнет верхнего порога на число реплик, что, вероятно, не является желаемым поведением. Поэтому выбирайте метрики, прямо (предпочтительно линейно) зависящие от количества подов.
Предотвращение частого изменения числа реплик
Механизм автоматического масштабирования HPA применяет разные методы, чтобы избежать быстрого выполнения противоречивых решений, которые могут приводить к изменению количества реплик при нестабильной нагрузке. Например, во время масштабирования вверх HPA игнорирует пиковые нагрузки на процессор, обусловленные инициализацией подов, обеспечивая гладкую реакцию на увеличение нагрузки. Во время масштабирования вниз, чтобы избежать неоправданного уменьшения числа реплик в короткие периоды провалов, контроллер учитывает все рекомендации по масштабированию в течение настраиваемого временного окна и выбирает самую высокую рекомендацию, имевшую место в течение этого окна. Все это улучшает устойчивость HPA к случайным колебаниям метрик.
Отложенная реакция
Масштабирование, инициируемое изменением значения метрики, — это многостадийный процесс, в который вовлечено несколько компонентов Kubernetes. Первый — это агент cAdvisor, действующий в каждом контейнере, и регулярно собирающий метрики для Kubelet. Второй — сервер метрик, извлекающий метрики из Kubelet через регулярные интервалы. Наконец, периодически запускается контроллер HPA, который анализирует собранные метрики. Формула масштабирования HPA вводит некоторую задержку, чтобы предотвратить частое применение противоречивых решений (как описано в предыдущем пункте). Вся эта деятельность накапливается в задержке между причиной и реакцией масштабирования. Увеличение задержки настройкой этих параметров делает HPA менее отзывчивым, а уменьшение увеличивает нагрузку на платформу. Настройка Kubernetes для балансировки ресурсов и производительности — это постоянный процесс обучения.
Knative Serving
Проект Knative Serving (с которым мы познакомимся в разделе «Knative Build» главы 25) предлагает еще более продвинутые методы горизонтального масштабирования. К их числу относится поддержка «масштабирования до нуля», когда число подов, поддерживающих службу Service, может быть уменьшено до нуля и увеличивается, только когда происходит определенное событие, например входящий запрос. В Knative эта возможность реализована поверх «сетки служб» Istio, которая, в свою очередь, предлагает прозрачные службы внутренней маршрутизации для подов. Knative Serving образует основу для бессерверной архитектуры, обладающей еще более гибкими и быстрыми средствами горизонтального масштабирования, превосходящими стандартные механизмы Kubernetes.
Подробное обсуждение Knative Serving выходит за рамки этой книги, так как это еще очень молодой проект, заслуживающий отдельной книги. Тем не менее в разделе «Дополнительная информация» вы найдете дополнительные ссылки на ресурсы Knative.
Автоматическое вертикальное масштабирование
Горизонтальное масштабирование предпочтительнее вертикального, потому что менее разрушительно, особенно для служб без состояния. Это не относится к службам с состоянием, для которых вертикальное масштабирование может оказаться предпочтительнее. В числе других сценариев применения вертикального масштабирования можно назвать настройку фактических потребностей службы в ресурсах на основе фактической нагрузки. Мы выяснили, почему определение правильного количества реплик пода может быть затруднено или даже невозможно, когда нагрузка меняется с течением времени. Вертикальное масштабирование тоже имеет подобные проблемы, связанные с определением правильных значений для параметров requests и limits контейнера. Механизм автоматического вертикального масштабирования подов в Kubernetes (Vertical Pod Autoscaler, VPA) решает эти проблемы за счет автоматизации процесса настройки и распределения ресурсов на основе информации о фактическом их потреблении.
Как мы видели в главе 2 «Предсказуемые требования», каждый контейнер в поде может определять свои параметры requests с требованиями к процессорному времени и памяти, что влияет на планирование подов. Параметры requests и limits в некотором смысле определяют контракт между подом и планировщиком, который обеспечивает гарантированный объем ресурсов или отказывается запланировать под. Слишком низкие требования к объему памяти могут привести к тому, что узлы будут плотно забиты подами, что, в свою очередь, может привести к ошибкам нехватки памяти или остановке действующих подов из-за нехватки памяти. Слишком низкие требования к процессорному времени могут привести к нехватке вычислительных ресурсов и низкой эффективности приложений. С другой стороны, если запросить избыточно большой объем ресурсов, это приводит к напрасному их расходованию. Важно определять параметры requests с требованиями к ресурсам как можно точнее, потому что это влияет на эффективность расходования ресурсов кластера и горизонтального масштабирования. Давайте посмотрим, как VPA помогает решить эту проблему.
Рассмотрим определение VPA из листинга 24.5, чтобы поближе познакомиться с автоматическим вертикальным масштабированием подов в кластере с поддержкой VPA и сервером метрик.
Листинг 24.5. VPA
apiVersion: poc.autoscaling.k8s.io/v1alpha1
kind: VerticalPodAutoscaler
metadata:
name: random-generator-vpa
spec:
selector:
matchLabels:
app: random-generator
updatePolicy:
updateMode: "Off"
Селектор меток для идентификации подов.
Политика обновления определяет, как механизм VPA будет применять изменения.
Определение VPA включает следующие важные элементы:
Селектор меток
Определяет поды, подлежащие масштабированию.
Политика обновления
Определяет, как механизм VPA будет применять изменения. Режим Initial позволяет выделять запрошенные ресурсы только во время создания пода, но не позже. Режим по умолчанию Auto позволяет выделять запрошенные ресурсы во время создания пода, а также вытеснять и снова планировать поды при изменении требований. Значение Off отключает автоматическое применение изменившихся требований подов, но позволяет определять предлагаемые значения. Это своего рода пробный прогон для определения нужного размера контейнера, но без непосредственного его применения.
Определение VPA также может иметь политику выделения ресурсов, которая влияет на то, как VPA вычисляет рекомендуемый объем ресурсов (например, путем установки для каждого контейнера нижней и верхней границ).
В зависимости от значения параметра .spec.updatePolicy.updateMode, VPA вовлекает в работу разные системные компоненты. Все три компонента VPA — механизмы рекомендаций, согласования требований и обновления — действуют независимо и могут заменяться альтернативными реализациями. Интеллектуальный механизм рекомендаций создавался с учетом опыта разработки системы Google Borg. Текущая реализация анализирует фактическое использование ресурсов контейнером под нагрузкой в течение определенного периода (по умолчанию восемь дней), создает гистограмму и выбирает значение, соответствующее наибольшему процентилю за этот период. Кроме метрик, он также учитывает события, связанные с ресурсами, в частности с памятью, такие как вытеснение и OutOfMemory.
В нашем примере мы выбрали значение Off для параметра .spec.updatePolicy.updateMode, но есть еще два значения, каждое из которых определяет свой уровень потенциальной дезорганизации работы масштабируемых подов. Давайте посмотрим, как работают разные значения updateMode, перечислив их в порядке увеличения разрушительного влияния:
updateMode: Off
Механизм рекомендаций VPA собирает метрики и события подов, а затем выдает рекомендации. Рекомендации всегда хранятся в разделе status ресурса VPA. Однако дальше этого механизм в режиме Off не идет. Он анализирует имеющуюся информацию и выдает рекомендации, но не применяет их. Этот режим можно использовать для получения информации о потреблении ресурсов подами без внесения каких-либо изменений и нарушения их работы. Принятие решения о применении рекомендаций оставлено на усмотрение пользователя.
updateMode: Initial
В этом режиме VPA делает еще шаг вперед. Кроме действий, выполняемых механизмом рекомендацией, дополнительно в работу вовлекается плагин согласования (admission plugin), который применяет рекомендации только ко вновь созданным подам. Например, если масштабирование пода осуществляется вручную, через механизм HPA, при изменении параметров развертывания Deployment или в случае остановки и повторного запуска пода по какой-либо причине, контроллер согласования VPA обновит значение запроса на ресурс.
Этот контроллер является изменяющим плагином согласования и переопределяет значения в поле requests новых подов, соответствующих селектору меток VPA. Данный режим не вызывает перезапуск действующих подов и является частично разрушительным, потому что изменяет требования к ресурсам для вновь создаваемых подов. Это может повлиять на выбор места для запуска нового пода. Более того, может так получиться, что после применения рекомендуемых требований к ресурсам под будет запланирован на другом узле, что может иметь неожиданные последствия. Или, что еще хуже, планировщик не сможет подобрать для пода подходящий узел, если ни на одном узле в кластере не окажется достаточного объема ресурсов.
updateMode: Auto
Кроме создания рекомендаций и их применения к вновь создаваемым подам, как описано выше, в этом режиме VPA вовлекает в работу свой компонент, выполняющий обновления. Этот компонент останавливает запущенные поды, которые соответствуют селектору меток, и запускает их вновь с помощью плагина согласования VPA, который обновляет требования к ресурсам. То есть этот режим является наиболее разрушительным, поскольку принудительно перезапускает все поды для применения рекомендаций, что может вызвать неожиданные проблемы с планированием, как описано выше.
Фреймворк Kubernetes предназначен для управления неизменяемыми контейнерами с неизменяемыми определениями spec в подах, как показано на рис. 24.2. Это упрощает горизонтальное масштабирование, но создает проблемы для вертикального масштабирования из-за необходимости останавливать и повторно запускать поды, что может повлиять на процесс планирования и вызвать сбои в работе. Это верно, даже когда под сокращает требуемый объем ресурсов и хочет освободить уже выделенные ресурсы.
Другая проблема связана с сосуществованием VPA и HPA. В настоящее время эти два механизма действуют независимо друг от друга, что может привести к нежелательному поведению. Например, если HPA использует метрики ресурсов, такие как процессорное время и объем памяти, и VPA влияет на эти же значения, это может привести к одновременному горизонтальному и вертикальному масштабированию подов (то есть произойдет двойное масштабирование).
Мы не будем еще дальше углубляться в детали, потому что механизм VPA все еще находится в состоянии бета-версии и его поведение может измениться. Но имейте в виду, что его применение может значительно улучшить потребление ресурсов.
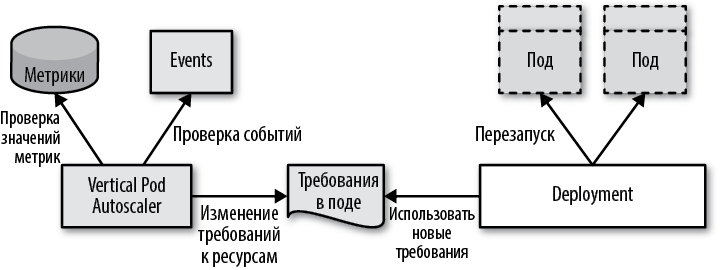
Рис. 24.2. Механизм автоматического вертикального масштабирования подов
Автоматическое масштабирование кластера
Паттерны, представленные в этой книге, используют в основном примитивы и ресурсы, предназначенные для разработчиков, использующих уже настроенный кластер Kubernetes. Поскольку эта тема связана с масштабированием рабочих нагрузок, в этом разделе мы познакомимся с механизмом автоматического масштабирования кластера Kubernetes Cluster Autoscaler (CA).
Одним из принципов облачных вычислений является оплата фактически потребленных ресурсов. Мы можем использовать облачные услуги, когда они необходимы, и ровно столько, сколько необходимо. Механизм автоматического масштабирования кластера может взаимодействовать с облачными провайдерами, где работает Kubernetes, и запрашивать выделение дополнительных узлов в периоды пиковых нагрузок и освобождать незанятые узлы в другие периоды, снижая затраты на инфраструктуру. Если HPA и VPA выполняют масштабирование на уровне подов и обеспечивают эластичное распределение ресурсов для служб внутри кластера, то CA обеспечивает масштабируемость на уровне узлов и эластичное распределение ресурсов для кластера в облачной инфраструктуре.
CA — это расширение для Kubernetes, которое должно быть включено и настроено минимальным и максимальным количеством узлов. Оно может функционировать, только если кластер Kubernetes работает в облачных инфраструктурах, где узлы могут выделяться и выводиться из эксплуатации по требованию и имеется поддержка Kubernetes CA, таких как AWS, Microsoft Azure и Google Compute Engine.
Cluster API
Все крупные облачные провайдеры поддерживают Kubernetes CA. Однако плагины, реализующие эту поддержку, были написаны самими провайдерами, что вызывает привязку к одному провайдеру и несовместимость в поддержке CA. К счастью, появился проект Cluster API Kubernetes, целью которого является определение API для создания, настройки и управления кластером. Все крупные провайдеры облачных вычислений, такие как AWS, Azure, GCE, vSphere и OpenStack, поддержали эту инициативу. Он также предусматривает автоматическое масштабирование локально установленных экземпляров Kubernetes. Сердцем Cluster API является контроллер машины, действующий в фоновом режиме, для которого уже существует несколько независимых реализаций, таких как Kubermatic machine-controller или Open-Shift machine-api-operator. Проект Cluster API стоит того, чтобы внимательно следить за его развитием, так как в будущем он может стать основой для любого другого механизма автоматического масштабирования кластера.
CA выполняет две основные операции: добавление новых узлов в кластер и удаление узлов из кластера. Давайте посмотрим, как выполняются эти действия:
Добавление нового узла (масштабирование вверх)
Приложениям с переменной нагрузкой (с пиковыми периодами в течение дня, в выходные или праздничные дни и намного меньшей нагрузкой в другое время) необходима возможность увеличивать объем доступных ресурсов, когда это требуется. Можно, конечно, купить фиксированный объем ресурсов у облачного провайдера, чтобы покрыть потребности в пиковые периоды, но тогда высокая оплата за этот объем в периоды с небольшой нагрузкой уменьшит преимущества облачных вычислений. В таких случаях автоматическое масштабирование кластера становится по-настоящему полезным.
При горизонтальном или вертикальном масштабировании пода, вручную или посредством HPA или VPA, реплики должны размещаться на узлах, удовлетворяющих требованиям к процессору и памяти. Если в кластере не окажется узла с объемом ресурсов, удовлетворяющим требованиям пода, тогда этот под будет помечен как не подлежащий планированию и останется в состоянии ожидания, пока такой узел не будет найден. Механизм CA следит за такими подами, чтобы понять, когда следует добавить новый узел, удовлетворяющий их потребности. Обнаружив такой под, механизм CA изменит размер кластера согласно потребностям.
CA не может добавить в кластер случайный узел — он должен выбрать узел из доступных групп узлов, на которых работает кластер. Предполагается, что все машины в группе узлов имеют одинаковую емкость и одинаковые метки и на них выполняются одинаковые поды, указанные в локальных файлах манифеста или в наборах DaemonSet. Это предположение необходимо, чтобы CA мог оценить, какую дополнительную емкость добавит новый узел в кластер.
Если потребностям ожидающих подов соответствует несколько групп узлов, тогда CA можно настроить для выбора группы узлов с помощью разных стратегий, называемых механизмами расширения. Механизм расширения может расширить группу дополнительным узлом, используя критерий минимизации стоимости, минимизации избыточных ресурсов, максимизации числа подов, которые можно разместить на узле или просто случайным образом. Когда выбор будет сделан, облачный провайдер должен за несколько минут подготовить новую машину и зарегистрировать ее в API Server как новый узел Kubernetes, готовый для размещения ожидающих подов.
Удаление узла (масштабирование вниз)
Масштабирование вниз подов или узлов без прерывания обслуживания всегда сложнее и требует множества проверок. CA выполняет масштабирование вниз, когда нет необходимости выполнять масштабирование вверх, а узел идентифицируется как незанятый. Узел может быть удален, если выполняются следующие основные условия:
• Более половины его емкости не используется, то есть сумма всех требований к процессорному времени и памяти всех подов на этом узле составляет менее 50% от емкости его ресурсов.
• Все поды на узле, доступные для перемещения (которые не запускаются локально с помощью файлов манифеста или наборов DaemonSet), можно переместить на другие узлы. Чтобы убедиться в этом, CA имитирует процесс планирования и определяет будущее местоположение для каждого пода после его остановки на этом узле. Окончательное расположение подов по-прежнему определяется планировщиком и может отличаться, но успех моделирования гарантирует наличие резервных мощностей в кластере.
• Нет никаких других причин, препятствующих удалению узла, как, например, исключение узла из списка доступных для масштабирования вниз посредством аннотаций.
• На узле нет подов, которые нельзя переместить, таких как поды с требованиями PodDisruptionBudget, которые нельзя удовлетворить, поды с локальным хранилищем, поды с аннотациями, предотвращающими вытеснение, поды, созданные без контроллера, или системные поды.
Все эти проверки выполняются с целью гарантировать, что не будет остановлен ни один под, который нельзя запустить на другом узле. Если все предыдущие условия выполняются в течение некоторого времени (по умолчанию 10 минут), узел может быть удален. Для удаления узел помечается как непригодный для планирования и все поды, выполняющиеся на нем, перемещаются на другие узлы.
Схема на рис. 24.3 показывает, как CA взаимодействует с облачным провайдером и Kubernetes в процессе масштабирования кластера.
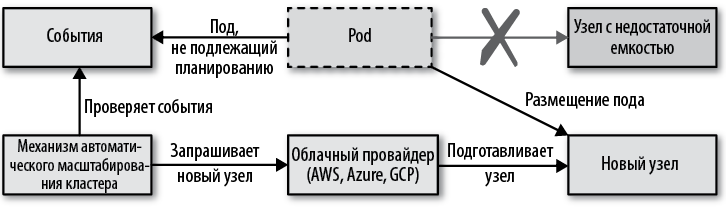
Рис. 24.3. Механизм автоматического масштабирования кластера
Как вы, наверное, уже поняли, масштабирование подов и масштабирование узлов не связаны между собой, а выполняются независимо. HPA или VPA могут анализировать метрики, события и масштабировать поды. Если в какой-то момент емкости кластера оказывается недостаточно, в работу вступает CA и увеличивает ее. Также механизм CA может пригодиться, когда имеются существенные колебания нагрузки на кластер из-за выполнения пакетных заданий, повторяющихся задач, тестов непрерывной интеграции или других пиковых нагрузок, требующих временно увеличить емкость. Он может увеличить и уменьшить емкость кластера и значительно сэкономить затраты на облачную инфраструктуру.
Уровни масштабирования
В этой главе мы рассмотрели различные способы масштабирования развернутых рабочих нагрузок для удовлетворения меняющихся потребностей в ресурсах. Большинство из перечисленных здесь действий вполне может выполнить оператор-человек, но это не соответствует облачному мышлению. Для крупномасштабного управления распределенными системами необходима автоматизация повторяющихся действий. Лучше автоматизировать масштабирование и позволить операторам-людям сосредоточиться на задачах, которые пока нельзя автоматизировать с помощью операторов Kubernetes.
Давайте еще раз окинем взглядом приемы масштабирования, в порядке от более тонких к более грубым, как показано на рис. 24.4.
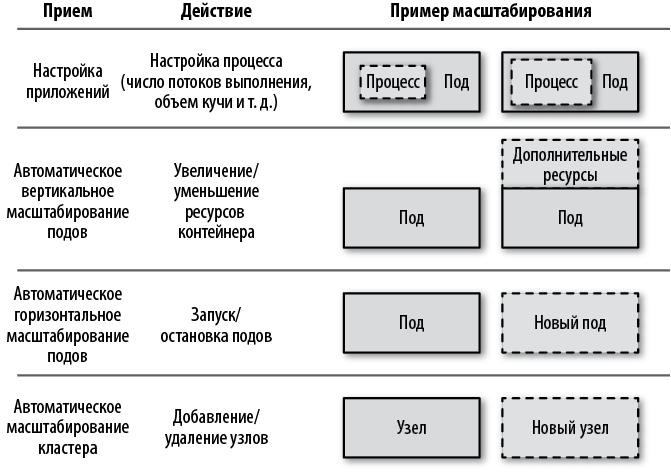
Рис. 24.4. Уровни масштабирования приложений
Настройка приложений
На самом детальном уровне находится метод, заключающийся в настройке приложений, который мы не рассматривали в этой главе, поскольку он не связан с Kubernetes. Тем не менее самое первое, что можно предпринять, — настроить приложение, выполняющееся в контейнере, чтобы оно оптимально использовало выделенные ресурсы. Это действие не требуется выполнять при каждом масштабировании службы, оно должно быть выполнено изначально, перед выпуском приложения в эксплуатацию. Например, для среды выполнения Java можно настроить размер пула потоков выполнения, обеспечивающий оптимальное использование ресурсов процессорного времени, которые получает контейнер. Также можно настроить объемы различных областей памяти, например размеры кучи, обычной памяти и памяти для стека потоков выполнения. Корректировка этих значений обычно выполняется с помощью изменений конфигурации, а не кода.
В контейнерных приложениях используются запускающие сценарии, которые могут вычислять оптимальные значения по умолчанию для количества потоков и размеров областей памяти приложения, опираясь на ресурсы, выделенные контейнеру, а не на общую емкость узла. Использование таких сценариев может стать отличным первым шагом. Можно пойти еще дальше и использовать методы и библиотеки, такие как Netflix Adaptive Concurrency Limits, с помощью которых приложение может динамически вычислять свои ограничения путем самопрофилирования и адаптироваться к ним. Это — своеобразное автоматическое масштабирование на уровне приложения, которое устраняет необходимость настройки служб вручную.
Настройка приложений может вызвать регрессию, подобно изменениям в коде, и должна сопровождаться тестированием. Например, изменение размера кучи приложения может привести к его краху из-за ошибки OutOfMemory, и горизонтальное масштабирование в этом случае не поможет. С другой стороны, масштабирование подов по вертикали или по горизонтали или выделение большего количества узлов не даст ожидаемого эффекта, если приложение не использует должным образом ресурсы, выделенные для контейнера. То есть настройка на этом уровне масштабирования может повлиять на все другие методы и оказаться разрушительной, но ее необходимо выполнить хотя бы один раз, чтобы добиться оптимального поведения приложения.
Автоматическое вертикальное масштабирование подов
В предположении, что приложение эффективно использует ресурсы контейнера, следующим шагом является установка правильных запросов и лимитов ресурсов в контейнерах. Выше мы видели, как VPA может автоматизировать процесс определения и применения оптимальных значений, основанных на реальном потреблении. Существенная проблема в данном случае заключается в том, что Kubernetes требует остановки подов и их повторного запуска, что оставляет возможность для коротких или неожиданных периодов прерывания обслуживания. Выделение большего количества ресурсов для контейнера, испытывающего недостаток ресурсов, может сделать под не подлежащим планированию и еще больше увеличить нагрузку на другие экземпляры. Увеличение ресурсов контейнера также может потребовать дополнительной настройки приложения, чтобы обеспечить оптимальное их использование.
Автоматическое горизонтальное масштабирование подов
Предыдущие два метода являются формой вертикального масштабирования; применяя их, мы надеемся улучшить производительность существующих подов путем их настройки, но без изменения их количества. Следующие два метода являются формой горизонтального масштабирования: в этом случае мы не касаемся определений, но меняем количество подов и узлов. Такой подход снижает вероятность появления любых регрессий и сбоев и упрощает автоматизацию. В настоящее время HPA является наиболее популярной формой масштабирования. Первоначально он предлагал лишь минимальные возможности, опираясь только на метрики потребления процессора и памяти, но ныне появилась возможность использовать нестандартные и внешние метрики, помогающие организовать более сложные схемы масштабирования.
Если предположить, что вы выполнили два предыдущих метода и определили правильные значения настроек для самого приложения и потребности в ресурсах контейнера, после этого можно включить HPA и обеспечить адаптацию приложения к изменениям потребностей в ресурсах.
Автоматическое масштабирование кластера
Методы масштабирования с использованием HPA и VPA обеспечивают эластичность только в пределах емкости кластера. Их можно применять, только если кластер Kubernetes обладает достаточной емкостью. Автоматическое масштабирование кластера обеспечивает гибкость на уровне емкости кластера. Механизм CA дополняет другие методы масштабирования, но действует независимо. Он не заботится о причинах появления дополнительного спроса на ресурсы или о том, почему появилась неиспользуемая емкость, является ли это следствием действий человека-оператора или механизма автоматического масштабирования, меняющих профили рабочей нагрузки. Он может расширить кластер, чтобы добавить дополнительную емкость, или сократить его, чтобы сэкономить на затратах на неиспользуемые ресурсы.
Пояснение
Эластичность и различные методы масштабирования — это область Kubernetes, которая продолжает активно развиваться. Поддержка метрик лишь недавно была добавлена в HPA, а VPA все еще находится на стадии экспериментальной разработки. Кроме того, благодаря популяризации модели бессерверных вычислений наибольшим спросом стали пользоваться возможности масштабирования до нуля и быстрого масштабирования вверх. Knative serving — это расширение для Kubernetes, которое как раз решает эту проблему, обеспечивая основу для масштабирования до нуля, как кратко описывается во врезке «Knative Serving» выше и во врезке «Knative Build» в главе 25. Проект Knative и лежащие в его основе сетки служб продолжают быстро развиваться и представляют новые и очень интересные облачные примитивы. Мы внимательно следим за этой областью облачных вычислений и рекомендуем вам присмотреться к Knative.
Опираясь на описание желаемого состояния распределенной системы, Kubernetes может создавать и поддерживать его. Он также обеспечивает надежность и устойчивость к сбоям, постоянно выполняя мониторинг и автоматически восстанавливая и обеспечивая соответствие текущего состояния желаемому. Гибкость и надежность системы находятся на достаточно высоком уровне для многих нынешних приложений, но Kubernetes не останавливается на достигнутом. Небольшая, но правильно настроенная система Kubernetes сможет надежно функционировать даже при большой нагрузке, масштабируя поды и узлы. То есть под влиянием внешних факторов такая система будет становиться больше и сильнее, пользуясь мощными возможностями Kubernetes.
Дополнительная информация
• Пример эластичного масштабирования (http://bit.ly/2HwQa6V).
• Правильный выбор размеров пода для использования механизма автоматического вертикального масштабирования подов (http://bit.ly/2WInN9l).
• Основы автоматического масштабирования в Kubernetes (http://bit.ly/2U0XoGa).
• Автоматическое горизонтальное масштабирование подов (http://bit.ly/2r08Row).
• Алгоритм HPA (http://bit.ly/2Fh35Xb).
• Обзор механизма автоматического горизонтального масштабирования подов (http://bit.ly/2FlUSRH).
• Kubernetes Metrics API и клиенты (https://github.com/kubernetes/metrics/).
• Автоматическое вертикальное масштабирование подов (http://bit.ly/2Fixzbn).
• Настройка автоматического вертикального масштабирования подов (http://bit.ly/2HyI0eb).
• Предложение по автоматическому вертикальному масштабированию подов (http://bit.ly/2OfAOnW).
• Репозиторий GitHub с реализацией механизма автоматического вертикального масштабирования подов (http://bit.ly/2BDnAMZ).
• Автоматическое масштабирование кластеров в Kubernetes (http://bit.ly/2TkNQl9).
• Обзор библиотеки Netfix Adaptive Concurrency Limits (http://bit.ly/2JuXxxx).
• Часто задаваемые вопросы по автоматическому масштабированию кластеров (http://bit.ly/2Cum0NH).
• Cluster API (http://bit.ly/2D133T9).
• Kubermatic Machine-Controller (http://bit.ly/2VeTqae).
• OpenShift Machine API Operator (http://bit.ly/2uI7TzP).
• Knative (https://cloud.google.com/knative/).
• Knative: организация бессерверных служб (https://red.ht/2HvenKZ).
• Учебник по Knative (http://bit.ly/2HT70x9).
В случае с несколькими подами в качестве текущегоЗначенияМетрики используется среднее значение использования процессора.

