Глава 1. Введение
В этой вводной главе мы подготовим основу для остальной части книги и обсудим важные понятия Kubernetes, используемые в проектировании и реализации облачных приложений на основе контейнеров. Понимание этих новых абстракций, а также связанных с ними принципов и паттернов из этой книги является ключом к созданию распределенных приложений, автоматизируемых облачными платформами.
Эта глава не является обязательным условием для понимания паттернов, описываемых далее. Читатели, знакомые с понятиями Kubernetes, могут пропустить ее и сразу перейти к интересующей их категории.
Путь в облачное окружение
Наибольшей популярностью среди архитектур приложений для облачных платформ, таких как Kubernetes, пользуется архитектура микросервисов. Этот способ организации программного обеспечения помогает снизить сложность его разработки за счет дробления бизнес-функций и замены сложности разработки сложностью эксплуатации.
Существует большое количество теоретических и практических методов создания микросервисов с нуля или деления монолитных приложений на микросервисы. Большинство из этих методов основаны на приемах, описанных в книге Эрика Эванса (Eric Evans) «Domain-Driven Design» (Addison-Wesley), и понятиях ограниченного контекста и агрегатов. Ограниченные контексты непосредственно связаны с большими моделями и делят их на разные компоненты, и агрегаты помогают группировать ограниченные контексты в модули с определенными границами транзакций. Однако кроме этих понятий, характерных для каждой предметной области, для каждой распределенной системы, независимо от того, основана она на микросервисах или нет, существует множество технических проблем, связанных с их организацией, структурой и поведением во время выполнения.
Контейнеры и механизмы управления контейнерами, такие как Kubernetes, предлагают много новых примитивов и абстракций для решения проблем распределенных приложений, и здесь мы обсудим разные варианты, которые следует учитывать при переносе распределенной системы в Kubernetes.
В этой книге мы будем исследовать особенности взаимодействий контейнеров и платформ, рассматривая контейнеры как черные ящики. Однако мы включили этот раздел, чтобы подчеркнуть важность внутреннего устройства контейнеров. Контейнеры и облачные платформы дают огромные преимущества распределенным приложениям, но, поместив мусор в контейнеры, вы получите распределенный мусор в большем масштабе. На рис. 1.1 показано, какие навыки необходимы для создания хороших облачных приложений.
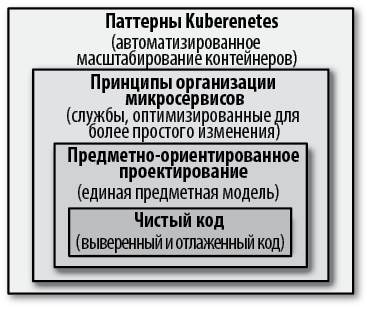
Рис. 1.1. Путь в облачное окружение
В общем случае каждое облачное приложение имеет несколько уровней абстракции, которые требуют различных проектных решений:
• В самом низу находится уровень программного кода. На этом уровне каждая переменная, каждый метод и каждый класс, которые вы создаете, оказывают прямое влияние на обслуживание приложения в долгосрочной перспективе. Независимо от технологии контейнеров и платформы управления ими, команда разработчиков и создаваемые ими артефакты будут иметь наибольшее влияние. Важно поддерживать разработчиков, которые стремятся писать чистый код, имеют необходимое количество автоматических тестов, постоянно улучшают качество кода и являются мастерами в сфере разработки программного обеспечения.
• Предметно-ориентированное проектирование (Domain-Driven Design, DDD) — это подход к проектированию программного обеспечения с позиции бизнеса с целью получить архитектуру, как можно более близкую к реальному миру. Он лучше всего соответствует объектно-ориентированным языкам программирования, но есть и другие хорошие подходы к моделированию и проектированию программного обеспечения для решения практических задач. Модель с правильно выбранными границами, простыми в использовании интерфейсами и многофункциональным API является основой для успешной контейнеризации и автоматизации в дальнейшем.
• Архитектурный стиль микросервисов очень быстро стал нормой и определяет ценные принципы и методы проектирования часто изменяющихся распределенных приложений. Применение этих принципов позволяет создавать реализации, оптимизированные для масштабирования, отказоустойчивости и частых изменений, что является общим требованием для любого современного программного обеспечения.
• Контейнеры очень быстро превратились в стандартный способ упаковки и запуска распределенных приложений. Создание модульных, многоразовых контейнеров, которые прекрасно подходят для использования в облачных окружениях, является еще одной фундаментальной предпосылкой. С ростом числа контейнеров в каждой организации возникает необходимость управлять ими, используя более эффективные методы и инструменты. Облачный — это относительно новый термин, используемый для описания принципов, паттернов и инструментов автоматизации масштабирования контейнерных микросервисов. Мы будем использовать как взаимозаменяемые слова облачный и Kubernetes, последнее из которых является названием наиболее популярной в настоящее время облачной платформы с открытым исходным кодом.
В этой книге мы не рассматриваем приемы разработки чистого кода, предметно-ориентированного проектирования и создания микросервисов. Все внимание мы сосредоточим исключительно на шаблонах и методах решения задач управления контейнерами. Но чтобы эти паттерны были максимально эффективными, приложение само должно быть тщательно спроектировано с применением методов разработки чистого кода, предметно-ориентированного проектирования, создания микросервисов и других соответствующих методик.
Распределенные примитивы
Чтобы объяснить, что подразумевается под новыми абстракциями и примитивами, мы сравним их с хорошо известным объектно-ориентированным программированием (ООП), например, на языке Java. Во вселенной ООП используются такие понятия, как класс, объект, пакет, наследование, инкапсуляция и полиморфизм. Среда выполнения Java предоставляет конкретные функции и гарантии управления жизненным циклом наших объектов и приложения в целом.
Язык Java и виртуальная машина Java (Java Virtual Machine, JVM) предоставляют локальные, внутрипроцессные строительные блоки для создания приложений. Kubernetes добавляет в эту привычную картину совершенно новое измерение, предлагая новый набор распределенных примитивов и среды выполнения для создания распределенных систем, разбросанных по нескольким узлам и процессам. Используя Kubernetes для реализации всего поведения приложения, мы больше не полагаемся только на локальные примитивы.
Таблица 1.1. Локальные и распределенные примитивы
| Понятие | Локальный примитив | Распределенный примитив |
| Инкапсуляция поведения | Класс | Образ контейнера |
| Экземпляр поведения | Объект | Контейнер |
| Единица повторного использования | .jar | Образ контейнера |
| Композиция | Класс A содержит класс B | Шаблон Sidecar (Прицеп) |
| Наследование | Класс A расширяет класс B | Контейнер A создается из родительского образа |
| Единица развертывания | .jar/.war/.ear | Под (Pod) |
| Изоляция времени сборки/выполнения | Модуль, Пакет, Класс | Пространство имен, под, контейнер |
| Начальная инициализация | Конструктор | Инициализирующие контейнеры, или Init-контейнеры |
| Операции, следующие сразу за начальной инициализацией | Метод Init | postStart |
| Операции, непосредственно предшествующие уничтожению экземпляра | Метод Destroy | preStop |
| Процедура освобождения ресурсов | finalize(), обработчик события завершения | Деинициализированный контейнер1 |
| Асинхронное и параллельное выполнение | ThreadPoolExecutor, ForkJoinPool | Задание |
| Периодическое выполнение | Timer, ScheduledExecutorService | Планировщик заданий |
| Фоновое выполнение | Фоновые потоки выполнения | Контроллер набора демонов (DaemonSet) |
| Управление конфигурацией | System.getenv(), Properties | Карта конфигураций (ConfigMap), секрет (Secret) |
Мы все еще должны использовать объектно-ориентированные строительные блоки для создания компонентов распределенного приложения, но дополнительно мы можем использовать примитивы Kubernetes для организации некоторых видов поведения приложения. В табл. 1.1 перечислены различные понятия из области разработки приложений и соответствующие им локальные и распределенные примитивы.
Внутрипроцессные и распределенные примитивы имеют общие черты, но их нельзя сравнивать непосредственно и они не являются взаимозаменяемыми. Они работают на разных уровнях абстракции и имеют разные предпосылки и гарантии. Некоторые примитивы должны использоваться вместе. Например, мы должны использовать классы для создания объектов и помещать их в образы контейнеров. Однако некоторые другие примитивы могут служить полноценной заменой поведения в Java, например, CronJob в Kubernetes может полностью заменить ExecutorService в Java.
А теперь рассмотрим несколько распределенных абстракций и примитивов из Kubernetes, которые особенно интересны для разработчиков приложений.
Контейнеры
Контейнеры — это строительные блоки для создания облачных приложений на основе Kubernetes. Проводя аналогию с ООП и Java, образы контейнеров можно сравнить с классами, а контейнеры — с объектами. По аналогии с классами, которые можно расширять (наследовать) и таким способом изменять их поведение, мы можем создавать образы контейнеров, которые расширяют (наследуют) другие образы контейнеров, и таким способом изменять поведение. По аналогии с объектами, которые можно объединять и использовать их возможности, мы можем объединять контейнеры, помещая их в поды (Pod), и использовать результаты их взаимодействий.
Продолжая сравнение, можно сказать, что Kubernetes напоминает виртуальную машину Java, но разбросанную по нескольким хостам и отвечающую за запуск контейнеров и управление ими.
Init-контейнеры можно сравнить с конструкторами объектов; контроллеры DaemonSet похожи на потоки выполнения, действующие в фоновом режиме (как, например, сборщик мусора в Java). Поды можно считать аналогами контекста инверсии управления (Inversion of Control, IoC), используемого, например, в Spring Framework, где несколько объектов имеют общий управляемый жизненный цикл и могут напрямую обращаться друг к другу.
Параллели можно было бы проводить и дальше, но не глубоко. Однако следует отметить, что контейнеры играют основополагающую роль в Kubernetes, а создание модульных, многоразовых, специализированных образов контейнеров является основой успеха любого проекта и экосистемы контейнеров в целом. Но что еще можно сказать о контейнерах и их назначении в контексте распределенного приложения, помимо перечисления технических характеристик образов контейнеров, которые обеспечивают упаковку и изоляцию? Вот несколько основных особенностей контейнеров:
• Образ контейнера — это функциональная единица, решающая одну определенную задачу.
• Образ контейнера принадлежит одной команде и имеет свой цикл выпуска новых версий.
• Образ контейнера является самодостаточным — он определяет и несет в себе зависимости времени выполнения.
• Образ контейнера является неизменным: после создания он не изменяется, но может настраиваться.
• Образ контейнера имеет определенные зависимости времени выполнения и требования к ресурсам.
• Образ контейнера экспортирует четко определенные API для доступа к его возможностям.
• Контейнер обычно выполняется как один процесс Unix.
• Контейнер позволяет безопасно масштабировать его вверх и вниз в любой момент.
Кроме всех этих характеристик, правильный образ контейнера должен иметь модульную организацию, поддерживать параметризацию и многократное использование в разных окружениях, где он будет работать. Также он должен предусматривать параметризацию для разных вариантов использования. Наличие небольших, модульных и многократно используемых образов контейнеров помогает создавать более специализированные и надежные образы подобно большой библиотеке в мире языков программирования.
Поды
Рассматривая характеристики контейнеров, легко заметить, что они идеально подходят для реализации принципов микросервисов. Образ контейнера предоставляет единую функциональную единицу, принадлежит одной команде, имеет независимый цикл выпуска новых версий и обеспечивает развертывание и изоляцию среды времени выполнения. В большинстве случаев один микросервис соответствует одному образу контейнера.
Однако многие облачные платформы предлагают еще один примитив для управления жизненным циклом группы контейнеров, в Kubernetes он называется подом. Под (Pod) — это атомарная единица планирования, развертывания и изоляции среды времени выполнения для группы контейнеров. Все контейнеры, входящие в состав одной группы, всегда планируются для выполнения на одном хосте, развертываются вместе и могут совместно использовать пространства имен файловой системы, сети и процесса. Подчинение единому жизненному циклу позволяет контейнерам в поде взаимодействовать друг с другом через файловую систему или через сеть с помощью локальных механизмов межпроцессных взаимодействий, если это необходимо (например, по соображениям производительности).
Как показано на рис. 1.2, на этапах разработки и сборки микросервис соответствует образу контейнера, который разрабатывается и выпускается одной группой. Но во время выполнения аналогом микросервиса является под, представляющий единицу развертывания, размещения и масштабирования. Единственный способ запустить контейнер — в ходе масштабирования или миграции — использовать абстракцию пода. Иногда под содержит несколько контейнеров, например, когда контейнер с микросервисом использует вспомогательный контейнер во время выполнения, как показано в главе 15 «Шаблон Sidecar».
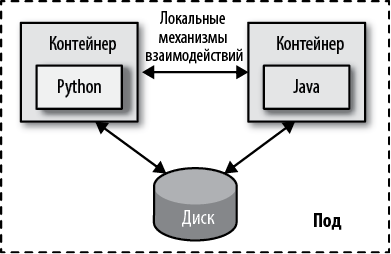
Рис. 1.2. Под как единица развертывания и управления
Уникальные характеристики контейнеров и подов образуют новый набор шаблонов и принципов разработки приложений на основе микросервисов. Мы рассмотрели некоторые характеристики хорошо спроектированных контейнеров; теперь рассмотрим некоторые характеристики пода:
• Под — это атомарная единица планирования. Собираясь запустить под, планировщик пытается найти хост, который удовлетворяет требованиям всех контейнеров, входящих в эту группу (есть некоторые особенности в отношении Init-контейнеров, которые мы рассмотрим в главе 14 «Init-контейнеры»). Если создать под со множеством контейнеров, планировщику придется отыскать хост, обладающий достаточными ресурсами для удовлетворения суммарных требований всех контейнеров. Процесс планирования описан в главе 6 «Автоматическое размещение».
• Под гарантирует совместное размещение контейнеров. Благодаря этому контейнеры в одной группе получают дополнительные возможности для взаимодействия друг с другом, из которых чаще всего используются общая локальная файловая система, сетевой интерфейс localhost и локальные механизмы межпроцессных взаимодействий (IPC).
• Под имеет IP-адрес, имя и диапазон портов, общих для всех контейнеров, входящих в группу. Это означает, что контейнеры в одной группе необходимо тщательно настраивать, чтобы избежать конфликтов портов, точно так, же как параллельно выполняющиеся процессы Unix должны соблюдать осторожность при совместном использовании сетевого пространства хоста.
Под — это атом Kubernetes, в котором находится ваше приложение, но у вас нет прямого доступа к поду. Для этой цели используются службы.
Службы
Группы контейнеров, или поды, — это эфемерные образования, они могут появляться и исчезать в любое время по разным причинам: например, в ходе масштабирования вверх или вниз, в случае неудачи при проверке работоспособности контейнеров и при миграции узлов. IP-адрес группы становится известен только после того, как она будет запланирована и запущена на узле. Группу можно повторно запланировать для запуска на другом узле, если узел, на котором она выполнялась, прекратил работу. Все это означает, что сетевой адрес группы контейнеров может меняться в течение жизни приложения, и потому необходим какой-то другой примитив для обнаружения и балансировки нагрузки.
Роль этого примитива играют службы (Services) Kubernetes. Служба — это еще одна простая, но мощная абстракция Kubernetes, которая присваивает имени службы постоянные IP-адрес и номер порта. То есть служба — это именованная точка входа для доступа к приложению. В наиболее распространенном сценарии служба играет роль точки входа для набора групп контейнеров, но это не всегда так. Служба — это универсальный примитив и может также служить точкой входа для доступа к функциональным возможностям за пределами кластера Kubernetes. Соответственно, примитив службы можно использовать для обнаружения служб и распределения нагрузки и для замены реализации и масштабирования без влияния на потребителей службы. Подробнее о службах мы поговорим в главе 12 «Обнаружение служб».
Метки
Как было показано выше, на этапе сборки аналогом микросервиса является контейнер, а на этапе выполнения — группа контейнеров. А что можно считать аналогом приложения, состоящего из нескольких микросервисов? Kubernetes предлагает еще два примитива, помогающих провести аналогию с понятием приложения: метки и пространства имен. Мы подробно рассмотрим пространства имен в разделе «Пространства имен» ниже.
До появления микросервисов понятию приложения соответствовала одна единица развертывания с единой схемой управления версиями и циклом выпуска новых версий. Приложение помещалось в один файл .war, .ear или в каком-то другом формате. Но затем приложения были разделены на микросервисы, которые разрабатываются, выпускаются, запускаются, перезапускаются и масштабируются независимо друг от друга. С появлением микросервисов понятие приложения стало более размытым — больше нет ключевых артефактов или действий, которые должны выполняться на уровне приложения. Однако если понадобится указать, что некоторые независимые службы принадлежат одному приложению, можно использовать метки. Давайте представим, что одно монолитное приложение мы разделили на три микросервиса, а другое — на два.
В этом случае мы получаем пять определений групп контейнеров (и, может быть, много экземпляров этих групп), которые не зависят друг от друга с точки зрения разработки и времени выполнения. Тем не менее нам все еще может потребоваться указать, что первые три пода представляют одно приложение, а два других — другое приложение. Поды могут быть независимыми и представлять определенную ценность для бизнеса по отдельности, а могут зависеть друг от друга. Например, один под может содержать контейнеры, отвечающие за интерфейс с пользователем, а два других — за реализацию основной функциональности. Если какой-то из подов прекратит работать, приложение окажется бесполезным с точки зрения бизнеса. Использование меток дает возможность определять набор подов и управлять им как одной логической единицей. На рис. 1.3 показано, как можно использовать метки для группировки частей распределенного приложения в конкретные подсистемы.
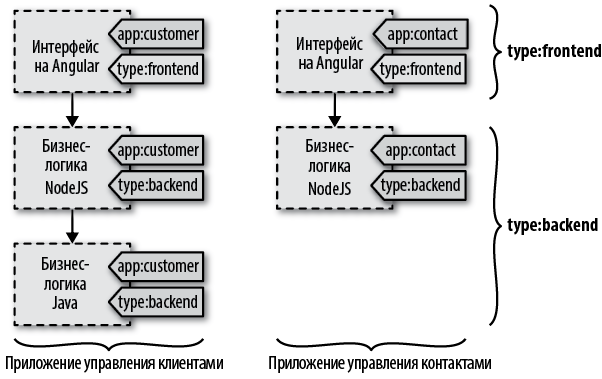
Рис. 1.3. Метки используются для идентификации подов как принадлежащих одному приложению
Вот несколько примеров использования меток:
• Метки используются наборами реплик (ReplicaSet) для поддержания в рабочем состоянии некоторых экземпляров подов. Для этого каждое определение пода должно иметь уникальную комбинацию меток, используемых для планирования.
• Метки также широко используются планировщиком для совместного размещения или распределения групп контейнеров по узлам с учетом требований этих групп.
• Метка может задавать логическую группировку набора подов и идентифицировать его как приложение.
• В дополнение к уже перечисленным типичным случаям метки можно использовать для хранения метаданных. Часто трудно заранее предусмотреть все случаи, когда могут пригодиться метки, но лучше иметь достаточно меток, чтобы описать все важные аспекты подов. Например, могут пригодиться метки для описания логических групп внутри приложения, бизнес-характеристик и степени важности, конкретных зависимостей среды времени выполнения, таких как архитектура оборудования или настройки местоположения.
Впоследствии эти метки могут использоваться планировщиком для более точного планирования. Те же метки можно использовать из командной строки для управления соответствующими подами. Однако не следует выходить за рамки разумного и заранее добавлять слишком много меток. При необходимости требуемые метки всегда можно добавить позже. Удаление меток, кажущихся ненужными, намного опаснее, поскольку нет простого способа узнать, для чего они используются и какой эффект может вызвать их удаление.
Аннотации
Другой примитив — аннотации — очень похож на метки. Подобно меткам, аннотации организованы в виде ассоциативного массива, но предназначены для определения метаданных, которые используются компьютером, а не человеком.
Информация в аннотациях не предназначена для использования в запросах и сопоставления объектов. Аннотации предназначены для присоединения дополнительных метаданных к объектам, созданным разными инструментами и библиотеками. Например, аннотации можно использовать для добавления номера версии и сборки, информации об образе, временных меток, имен веток в репозитории Git, номеров запросов на включение, хешей образов изображений, адресов в реестре, имен авторов, сведений об инструментах и многого другого. То есть метки используются главным образом для поиска и выполнения действий с соответствующими ресурсами, а аннотации — для прикрепления метаданных, которые могут использоваться компьютером.
Пространства имен
Другой примитив, который также может помочь в управлении группой ресурсов, — пространство имен Kubernetes. Как уже отмечалось выше, пространство имен может показаться похожим на метку, но в действительности это совсем другой примитив со своими характеристиками и назначением.
Пространства имен Kubernetes позволяют разделить кластер Kubernetes (который обычно распределяется по нескольким хостам) на логические пулы ресурсов. Пространства имен определяют области для ресурсов Kubernetes и предоставляют механизм для авторизации и применения других политик к сегменту кластера. Чаще всего пространства имен используются для организации разных программных окружений, таких как окружения для разработки, тестирования, интеграционного тестирования или промышленной эксплуатации. Пространства имен также можно использовать для организации многопользовательских архитектур (multitenancy), а также для изоляции рабочих групп, проектов и даже конкретных приложений. Но, в конечном счете, для полной изоляции некоторых окружений пространств имен недостаточно, поэтому создание отдельных кластеров является обычным явлением. Как правило, создается один непромышленный кластер Kubernetes, используемый, например, для разработки, тестирования и интеграционного тестирования, и другой — промышленный кластер Kubernetes для опытной и промышленной эксплуатации.
Давайте перечислим некоторые особенности пространств имен и посмотрим, как они могут помочь нам в разных сценариях:
• Пространство имен управляется как ресурс Kubernetes.
• Пространство имен создает изолированную область для таких ресурсов, как контейнеры, группы контейнеров (поды), службы или наборы реплик (ReplicaSet). Имена ресурсов должны быть уникальными внутри пространства имен, но могут повторяться в разных пространствах имен.
• По умолчанию пространства имен определяют изолированную область для ресурсов, но ничто не изолирует эти ресурсы и не препятствует доступу одного ресурса к другому. Например, группа контейнеров из пространства имен для разработки может обращаться к другой группе контейнеров из пространства имен для промышленной эксплуатации, если ей известен IP-адрес этой группы. Однако существуют плагины для Kubernetes, которые обеспечивают изоляцию сети для достижения истинной многоарендности.
• Некоторые другие ресурсы, такие как сами пространства имен, узлы и постоянные тома (PersistentVolume), не принадлежат к пространствам имен и должны иметь уникальные имена для всего кластера.
• Каждая служба Kubernetes принадлежит к пространству имен и получает соответствующий DNS-адрес, включающий пространство имен в форме <имя-службы>.<имя-пространства-имен>. svc.cluster.local. То есть имя пространства имен присутствует в URI каждой службы, принадлежащей к данному пространству имен. Это одна из причин, почему так важно выбирать правильные имена для пространств имен.
• Квоты ресурсов (ResourceQuota) определяют ограничения на совокупное потребление ресурсов пространством имен. С помощью квот ResourceQuota администратор кластера может управлять количеством объектов каждого типа в пространстве имен. Например, используя квоты, он может определить, что пространство имен для разработки может иметь только пять карт конфигураций (ConfigMap), пять объектов Secret, пять служб, пять наборов реплик, пять постоянных томов и десять подов.
• Квоты ресурсов (ResourceQuota) также могут ограничивать общую сумму вычислительных ресурсов, доступных для запроса в данном пространстве имен. Например, в кластере с 32 Гбайт ОЗУ и 16 ядрами можно выделить половину ресурсов — 16 Гбайт ОЗУ и 8 ядер — для промышленной эксплуатации, 8 Гбайт ОЗУ и 4 ядра для промежуточного окружения, 4 Гбайт ОЗУ и 2 ядра для разработки и столько же для тестирования. Возможность наложения ограничений на группы объектов с использованием пространств имен и квот ресурсов неоценима.
Пояснение
Мы кратко рассмотрели лишь часть основных понятий Kubernetes, которые используются в этой книге. Примитивов, которыми разработчики пользуются каждый день, намного больше. Например, создавая контейнерную службу, вы можете задействовать множество объектов Kubernetes, которые позволяют воспользоваться всеми преимуществами фреймворка. Имейте в виду, что это только объекты, используемые разработчиками приложений для интеграции контейнерной службы в Kubernetes. Есть и другие понятия, используемые администраторами, чтобы позволить разработчикам эффективно управлять платформой. На рис. 1.4 представлены основные ресурсы Kubernetes, которые могут пригодиться разработчикам.
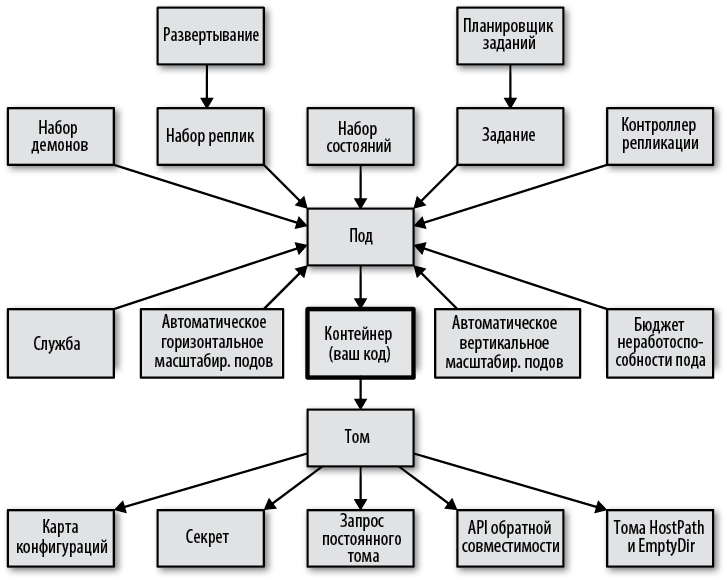
Рис. 1.4. Понятия Kubernetes для разработчиков
Эти новые примитивы способствуют появлению новых способов решения проблем, наиболее универсальные из которых становятся шаблонами. В этой книге мы не будем подробно описывать все решения, а сосредоточимся только на тех, которые устоялись как шаблоны.
Дополнительная информация
• Принципы проектирования контейнерных приложений (https://red.ht/2HBKqYI).
• Методология «Двенадцать факторов» (https://12factor.net/ru/).
• Сайт книги «Domain-Driven Design: Tackling Complexity in the Heart of Software» (http://dddcommunity.org/book/evans_2003).
• Руководство «Container Best Practices» (http://bit.ly/2TUyNTe).
• Руководство «Best Practices for Writing Dockerfiles» (https://dockr.ly/2TFZBaL).
• Презентация «Container Patterns» (http://bit.ly/2TFjsH2).
• Руководство «General Container Image Guidelines» (https://red.ht/2u6Ahvo).
• Описание понятия пода (https://kubernetes.io/docs/user-guide/pods/).
Эванс Эрик. Предметно-ориентированное проектирование (DDD).: Структуризация сложных программных систем. М.: Вильямс, 2010. — Примеч. пер.
Деинициализированные контейнеры еще не реализованы, но есть предложение (http://bit.ly/2TegEM7), описывающее, как включить эту возможность в будущие версии Kubernetes. События жизненного цикла мы обсудим в главе 5 «Управляемый жизненный цикл».
В переводе с английского pod — это стручок, кокон или группа. В контексте Kubernetes Pod — это группа контейнеров, запускаемых как одно целое. — Примеч. пер.
Предметно-ориентированное проектирование (DDD): Структуризация сложных программных систем. М.: Вильямс, 2010. — Примеч. пер.

