Глава 7
Управленческие практики при работе с ПО
Теория и практика управления в контексте доставки программного обеспечения претерпела значительные изменения за последние десятилетия вместе с несколькими основными парадигмами. В течение многих лет доминировала парадигма управления проектами и программами, и ее можно найти в таких структурах, как Институт управления проектами (Project Management Institute) и PRINCE2. После выпуска Манифеста Agile в 2001 году быстро набрали обороты методы Agile.
Между тем идеи бережливого движения в производстве стали применяться к программному обеспечению. Это движение происходит от подхода Toyota к производству, первоначально предназначенного для решения задачи создания широкого спектра различных автомобилей для относительно небольшого японского рынка. Стремление Toyota к неустанному совершенствованию позволило компании производить автомобили быстрее, дешевле и с более высоким качеством, чем у конкурентов. Такие компании, как Toyota и Honda, глубоко проникли в американскую автопромышленность, которая выжила только благодаря внедрению их идей и методов. Философия бережливого производства была впервые адаптирована для разработки программного обеспечения Мэри и Томом Поппендайками в их серии книг Lean Software Development («Бережливая разработка ПО»).
В этой главе мы обсудим практики управления, почерпнутые из движения бережливого производства, и то, как они влияют на эффективность доставки программного обеспечения.
Практики бережливого управления
В нашем исследовании мы смоделировали бережливое управление и его применение к доставке программного обеспечения с помощью трех компонентов (рис. 7.1 вместе с упрощенным управлением изменениями, рассмотренным далее в этой главе).
- Ограничение незавершенного производства (НЗП) и использование этих ограничений для улучшения процессов и увеличения производительности.
- Создание и поддержка визуальных дисплеев, показывающих ключевые показатели качества и производительности, а также текущий статус работы (включая ошибки), доступ к этим дисплеям для инженеров и руководителей и согласование данных показателей с операционными целями.
- Использование на ежедневной основе данных из инструментов мониторинга инфраструктуры и эффективности приложений для принятия бизнес-решений.
Использование ограничений НЗП и визуальных дисплеев хорошо известно в сообществе Lean. Они применяются для того, чтобы избежать перегрузок команды (что может привести к более длительным срокам выполнения) и не создавать препятствий для рабочего потока. Самое интересное, что ограничения НЗП сами по себе не сильно влияют на эффективность доставки. Мы наблюдаем сильный эффект только тогда, когда они объединены с использованием визуальных дисплеев и имеют цикл обратной связи от инструментов мониторинга производства до команд доставки или бизнеса. Когда команды используют эти инструменты вместе, мы видим гораздо более сильное положительное влияние на эффективность доставки ПО.

Также стоит немного подробнее остановиться на том, что именно мы измеряем. В случае НЗП мы не просто спрашиваем команды, хорошо ли они ограничивают НЗП и имеют ли налаженные процессы для этого. Мы также спрашиваем, делают ли их ограничения НЗП более заметными препятствия для более высокого рабочего потока и устраняют ли команды эти препятствия путем улучшения процесса, что приводило бы к повышению потока. Ограничения НЗП бесполезны, если они не приводят к улучшениям, увеличивающим рабочий поток.
В случае визуальных дисплеев мы спрашиваем, используются ли они или панели мониторинга для обмена информацией и используют ли команды такие инструменты, как метод канбан или раскадровки, для организации своей работы. Мы также спрашиваем, доступна ли информация о качестве и продуктивности, отображаются ли сбои или ошибки публично с помощью визуальных дисплеев и насколько легко эта информация доступна. Основными принципами при этом являются типы отображаемой информации, как широко она используется и насколько легко к ней получить доступ. Ключевые моменты — наглядность и высококачественная связь, которую она обеспечивает.
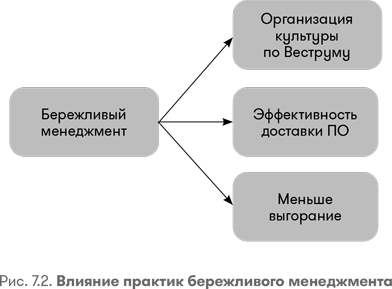
Мы предположили, что в сочетании эти методы повышают эффективность доставки, и это действительно так. На самом деле они также оказывают положительное влияние на культуру и производительность команды. Как показано на рис. 7.2, эти практики бережливого управления одновременно уменьшают выгорание (которое мы обсудим в Главе 9) и приводят к более производительной культуре (как описано в модели Веструма в Главе 3).
Внедрение упрощенного процесса управления изменениями
У каждой организации есть какой-то собственный процесс для внесения изменений в свою производственную среду. В стартапах этот процесс управления изменениями может быть настолько простым, как попросить другого разработчика проверить ваш код перед запуском изменения в жизнь. В крупных организациях мы часто видим процессы управления изменениями, которые занимают дни или недели, требуя, чтобы каждое изменение было рассмотрено консультативным советом по изменениям (CAB — change advisory board), внешним по отношению к команде, в дополнение к экспертизам на уровне команды, таким как формальный процесс проверки кода.
Мы хотели изучить влияние процессов утверждения изменений на эффективность доставки программного обеспечения. С этой целью мы задали вопрос о четырех возможных сценариях.
- Все изменения в производстве должны быть утверждены внешним органом (менеджером или CAB).
- Только изменения с высоким риском, такие как изменения базы данных, требуют утверждения.
- Мы полагаемся на внутреннюю экспертную оценку при управлении изменениями.
- У нас нет процесса утверждения изменений.
Результаты оказались удивительными. Мы обнаружили, что утверждение только изменений с высоким риском не коррелирует с эффективностью доставки программного обеспечения. Команды, которые сообщили об отсутствии процесса утверждения или использовали внутреннюю экспертную оценку, достигали более высокой эффективности доставки ПО. Наконец, команды, которым требовалось утверждение со стороны внешнего органа, продемонстрировали более низкую эффективность.
Далее мы исследовали случай утверждения внешним органом, чтобы посмотреть, коррелирует ли эта практика со стабильностью. Мы обнаружили, что внешние утверждения отрицательно коррелировали со временем выполнения, частотой развертывания и временем восстановления и не имели корреляции с частотой сбоев изменений. Короче говоря, утверждение внешним органом (менеджером или САВ) просто не работает на повышение стабильности производственных систем, измеряемой временем восстановления обслуживания и частотой сбоев изменений. Однако это, безусловно, замедляет работу, что на самом деле хуже, чем вообще не иметь процесса утверждения изменений.
Наша рекомендация, основанная на этих результатах, заключается в использовании упрощенного процесса утверждения изменений, основанного на экспертной оценке, такой как парное программирование или проверка кода внутри команды, в сочетании с конвейером развертывания для обнаружения и отклонения плохих изменений. Этот процесс можно использовать для всех видов изменений, включая изменения кода, инфраструктуры и базы данных.
А как насчет разделения ответственности?
В регулируемых отраслях разделение ответственности часто требуется либо буквально в формулировках регламента (например, в случае PCI DSS), либо аудиторами. Однако реализация этого контроля не требует САВ или отдельной рабочей группы. Существуют два механизма, которые могут быть эффективно использованы для того, чтобы соответствовать букве и духу этого контроля.
Во-первых, когда какое-либо изменение зафиксировано, кто-то, кто не участвовал в создании изменения, должен просмотреть его либо до, либо сразу после фиксации в системе управления версиями. Это может быть кто-то из той же команды. Этот человек должен утвердить изменение, записав свое одобрение в систему записи, такую как GitHub (путем утверждения запроса на принятие изменений) или инструмент конвейера развертывания (утвердив ручной этап сразу после фиксации изменения).
Во-вторых, изменения должны применяться только к производству с использованием полностью автоматизированного процесса, который является частью конвейера развертывания. То есть никакие изменения не могут быть внесены в производство, если они не были зафиксированы в системе управлении версиями, проверены стандартным процессом сборки и тестирования, а затем развернуты с помощью автоматизированного процесса, запускаемого через конвейер развертывания. В результате применения конвейера развертывания аудиторы будут иметь полную запись о том, какие изменения были применены к каким средам, откуда они берутся в системе управления версиями, какие тесты и проверки были для них выполнены и кто и когда их одобрил. Таким образом, конвейер развертывания особенно ценен в контексте строго регулируемых отраслей или отраслей, для которых безопасность критически важна.
Логически понятно, почему утверждение со стороны внешних органов является проблематичным. Ведь системы программного обеспечения сложны. Каждый разработчик сделал, казалось бы, безобидное изменение, которое подвесило часть системы. Какова вероятность того, что внешний орган, не очень хорошо знакомый с внутренними компонентами системы, может просмотреть десятки тысяч строк изменения кода, внесенные, возможно, сотнями инженеров, и точно определить их влияние на сложную производственную систему? Эта идея является своего рода театром управления рисками: мы устанавливаем флажки, чтобы когда что-то пойдет не так, мы могли сказать, что по крайней мере мы следили за процессом. В лучшем случае этот процесс приведет только к временным задержкам и перебрасыванию ответственности.
Мы считаем, что есть ситуации, когда люди вне команды могут осуществить эффективное управление рисками изменений. Однако это скорее роль руководства, чем собственно проверка изменений. Такие команды должны контролировать эффективность доставки и помогать командам улучшать ее, внедряя практики, которые повышают стабильность, качество и скорость, такие как непрерывная доставка и методы бережливого управления, описанные в этой книге.

