Книга: Код. Тайный язык информатики
Назад: Глава 19 Два классических микропроцессора
Дальше: Глава 21 Шины
Глава 20
Набор символов ASCII
В цифровой памяти компьютера хранятся только биты, поэтому все, с чем мы собираемся работать, должно быть в виде битов. Мы уже видели, как с помощью битов можно представить числа и машинный код. Следующая задача — представить текст. В конце концов, большая часть накопленной в мире информации выражена в виде текста, а наши библиотеки полны книг, журналов и газет. Наверняка нам захочется использовать компьютеры для хранения звуков, изображений и фильмов, а с текста гораздо проще начать.
Чтобы представить текст в цифровой форме, мы должны разработать некоторую систему, в которой каждая буква соответствует уникальному коду. Для чисел и знаков препинания также нужно предусмотреть коды. Короче, нам нужны коды для всех буквенно-цифровых символов. Такая система иногда называется набором кодированных символов, а отдельные коды — кодами символов.
Сначала сформулируем вопрос: «Сколько битов требуется для этих кодов?» Ответить на него непросто!
Когда мы думаем о представлении текста с помощью битов, давайте не будем забегать далеко вперед. Мы привыкли к красиво отформатированному тексту на страницах книги, журнала или газеты. Абзацы состоят из строк одинаковой ширины. Однако такое форматирование существенно не влияет на сам текст. Когда мы читаем короткий рассказ в журнале, а спустя годы встречаем его в книге, он не кажется нам другим только потому, что в книге столбец текста шире.
Другими словами, забудьте, что текст отформатирован в виде плоских столбцов на печатной странице. Считайте его одномерным потоком букв, цифр, знаков препинания с дополнительным символом, обозначающим конец одного абзаца и начало следующего.
Опять же, если вы читаете рассказ в журнале, а позднее видите его в книге, и при этом шрифт немного отличается, имеет ли это какое-либо значение? Если журнальная версия начинается так:
Зовите меня Ишмаэль..., а книжная — так: Зовите меня Ишмаэль...
стоит ли обращать на это внимание? Вероятно, нет. Да, шрифт слегка влияет на восприятие, однако от его замены рассказ не теряет смысла. Исходный шрифт всегда можно вернуть. Это не наносит вреда.
Вот еще один способ упростить задачу: давайте использовать простой текст без курсива, полужирного начертания, подчеркивания, цветов, обводки букв, подстрочных и надстрочных индексов, а также без диакритических значков. Никаких Å, é, ñ или ö. Только символы латинского алфавита, поскольку из них состоит 99% английских слов.
В ходе предыдущих исследований кодов Морзе и Брайля мы видели, как буквы алфавита могут быть представлены в двоичном формате. Несмотря на то что эти системы прекрасно справляются со стоящими перед ними задачами, они имеют недостатки, когда речь заходит о компьютерах. В азбуке Морзе коды имеют разную длину. Например, часто используемые буквы обозначаются короткими кодами, более редкие — длинными. Как видите, такой код подходит для телеграфа, однако не для компьютеров. Кроме того, код Морзе не делает различий между буквами в верхнем и нижнем регистре.
Коды Брайля имеют фиксированную длину, каждая буква представлена шестью битами, что предпочтительнее для компьютеров. Азбука Брайля также различает букву верхнего и нижнего регистра, хотя и использует для этого специальный escape-код, указывающий, что за ним следует символ в верхнем регистре. По сути, это означает, что для каждой заглавной буквы требуются два кода, а не один. Цифры отображаются с помощью кода переключения, который дает понять, что следующие далее коды представляют числа до тех пор, пока не встретится другой код переключения, сигнализирующий возврат к представлению букв.
Наша цель — разработка такого набора кодированных символов, чтобы нижеприведенное предложение можно было зашифровать с помощью серии кодов, каждый из которых — это определенное количество битов.
У меня 27 сестер.
Одни коды будут представлять буквы, другие — знаки препинания, третьи — числа. Еще нам необходим код, соответствующий пробелу между словами. Приведенное предложение состоит из 17 символов (включая пробелы). Последовательность кодов для шифрования подобных предложений часто называется текстовой строкой.
То, что нам нужны коды для чисел в текстовой строке, таких как «27», может показаться странным, поскольку мы представляли числа с помощью битов во многих предыдущих главах. Мы можем предположить, что кодами для цифр 2 и 7 в этом предложении являются просто двоичные числа 10 и 111. Однако это не обязательно так. В контексте такого предложения с символами 2 и 7 можно обращаться как с любыми другими символами в письменном языке. Им могут соответствовать коды, совершенно не связанные с фактическими значениями этих чисел.
Вероятно, наиболее экономичным текстовым кодом является 5-битный код, созданный в 1874 году для печатающего телеграфа Эмилем Бодо, сотрудником французской телеграфной службы, которая начала использовать этот код в 1877 году. В дальнейшем код был усовершенствован Дональдом Мюрреем и стандартизирован в 1931 году Международным консультационным комитетом по телефонии и телеграфии (Comité Consultatif International Téléphonique et Télégraphique, CCITT; сейчас — Международный союз электросвязи — International Telecommunication Union, ITU). Официально этот код называется международным телеграфным алфавитом № 2 (International Telegraph Alphabet No 2, ITA-2); в Соединенных Штатах он более известен как код Бодо, хотя правильнее было бы называть его кодом Мюррея.
В XX веке код Бодо часто применялся в телетайпных аппаратах. Клавиатура телетайпа Бодо похожа на пишущую машинку, но у нее только 30 клавиш и пробел. Клавиши телетайпа — просто переключатели, использование которых приводит к генерации двоичного кода и его передаче по выходному кабелю аппарата, бит за битом. Кроме того, телетайп предусматривает печатный механизм. Коды, проходящие через входной кабель телетайпа, активируют электромагниты, которые печатают символы на бумаге.
Поскольку код Бодо 5-битный, он содержит всего 32 элемента. Шестнадцатеричные значения этих кодов находятся в диапазоне от 00h до 1Fh. В следующей таблице представлено соответствие этих 32 кодов буквам латинского алфавита.

Код 00h не присваивается ничему. Из оставшихся кодов двадцать шесть назначаются буквам алфавита, а остальные пять соответствуют вспомогательным действиям, выделенным в таблице курсивом.
Код 04h — это пробел, который создает пространство между словами, коды 02h и 08h — возврат каретки и перевод строки. Эти понятия применяются при использовании пишущей машинки. Когда достигаете конца строки, печатая, вы нажимаете на рычаг или кнопку, которая выполняет два действия. Во-первых, каретка перемещается вправо, благодаря чему следующая строка начинается с левого края листа (возврат каретки). Во-вторых, пишущая машинка прокручивает валик так, чтобы следующая строка находилась под той, которую вы только что напечатали (перевод строки). В системе Бодо эти два кода генерируются отдельными клавишами. Телетайпный аппарат Бодо реагирует на эти два кода при печати.
Для получения цифр и знаков препинания в системе Бодо используется код 1Bh, обозначенный в таблице фразой «Переключение на цифры». Все следующие за ним коды интерпретируются как цифры или знаки препинания, пока код «Переключение на буквы» (1Fh) не просигнализирует возврат к буквам. В следующей таблице представлены коды, соответствующие цифрам и знакам препинания.

В стандарте ITU коды 05h, 0Bh и 16h не определены: они зарезервированы «для национального использования». В таблице показано, как эти коды применялись в Соединенных Штатах. Эти же коды обычно подходят для букв с диакритическими знаками из некоторых европейских языков. Код «Сигнал» предназначен для подачи телетайпом слышимого звукового сигнала, «Кто это?» активирует механизм, посредством которого телетайп может идентифицировать себя.
Как и азбука Морзе, этот 5-битный код не предусматривает различий между прописными и строчными буквами. Предложение I spent $25 today («Сегодня я потратил 25 долларов») шифруется следующей последовательностью шестнадцатеричных значений.
I SPENT $25 TODAY.
0C 04 14 0D 10 06 01 04 1B 16 19 01 1F 04 01 03 12 18 15 1B 07 02 08
Обратите внимание на три кода переключения: 1Bh прямо перед числом, 1Fh после числа и 1Bh перед точкой в конце предложения. Строка завершается кодами возврата каретки и перевода строки.
К сожалению, если вы дважды отправите эту последовательность значений на печатающее устройство телетайпа, получите следующий результат.
I SPENT $25 TODAY.
8 ‘03,5 $25 TODAY.
Что случилось? Дело в том, что последний код переключения, полученный печатным аппаратом перед второй строкой, представлял код переключения на цифры, поэтому коды в начале второй строки были интерпретированы как цифры.
Подобные проблемы типичны при использовании кодов переключения. Несмотря на безусловную экономичность кода Бодо, предпочтительнее было бы остановиться на уникальных кодах для цифр и знаков препинания, а также отдельных кодах для строчных и прописных букв.
Если мы хотим выяснить, сколько бит нам необходимо для создания лучшей по сравнению с кодом Бодо системы кодирования символов, нужно просто сложить их: 52 кодовых слова — для прописных и строчных букв, десять кодовых слов — для цифр от 0 до 9. Это уже 62 кодовых слова. Если добавить несколько знаков препинания, получим 64 кодовых слова, а значит, нам нужно более шести бит. Однако мы еще не скоро превысим значение в 128 символов, при котором потребуются восемь бит.
Как видите, необходимы семь бит для представления символов английского текста, если мы хотим обойтись без переключения между буквами нижнего и верхнего регистра.
Что же это за коды? Фактически коды могут быть любыми. Если бы мы собирались создать собственный компьютер, собрать для этого все необходимые аппаратные средства, сами его запрограммировать и никогда не использовать для подключения к любой другой машине, мы могли бы придумать собственные коды. Все, что нужно, — это назначить уникальный код каждому символу, который мы собираемся использовать.
Поскольку компьютеры редко создаются и работают отдельно друг от друга, разумнее было бы договориться о применении одних и тех же кодов. Таким образом сконструированные нами компьютеры могут быть более совместимыми друг с другом и, вероятно, смогут даже обмениваться текстовой информацией.
Кроме того, не следует присваивать коды случайным образом. Так, когда мы работаем с текстом на компьютере, назначение последовательных кодов буквам алфавита дает некоторые преимущества. Например, этот метод упорядочивания упрощает сортировку по алфавиту.
К счастью, такой стандарт уже разработан: Американский стандартный код для обмена информацией (American Standard Code for Information Interchange, ASCII). Он был принят в 1967 году и остается одним из важнейших во всей компьютерной индустрии. Однако у него есть одно исключение (о котором расскажу позднее). Работая с текстом на компьютере, вы можете быть уверены, что стандарт ASCII каким-то образом задействован в этом процессе.
ASCII — это 7-битный код, использующий двоичные значения в диапазоне от 0000000 до 1111111, которые соответствуют шестнадцатеричным кодам от 00h до 7Fh. Давайте разберем коды ASCII. Начнем не с самого начала, поскольку первые 32 кода концептуально немного сложнее остальных, а со второй группы, состоящей из 32 кодов, которая включает знаки препинания и десять цифр. В следующей таблице перечислены шестнадцатеричные коды и соответствующие им символы.
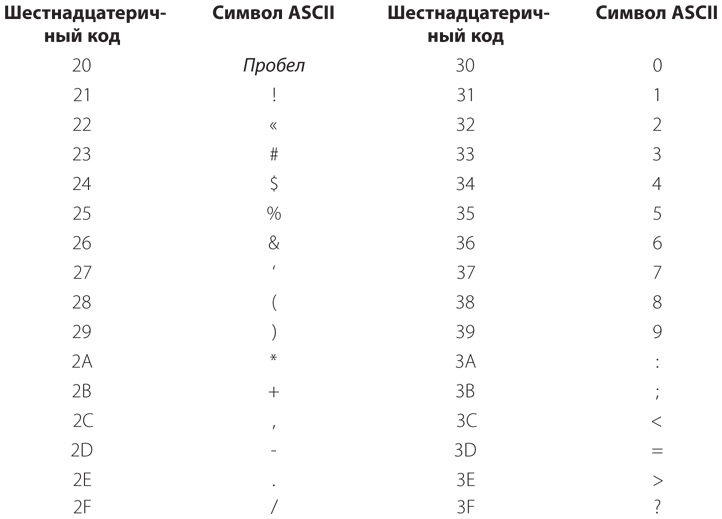
Обратите внимание: код 20h соответствует пробелу, отделяющему слова друг от друга.
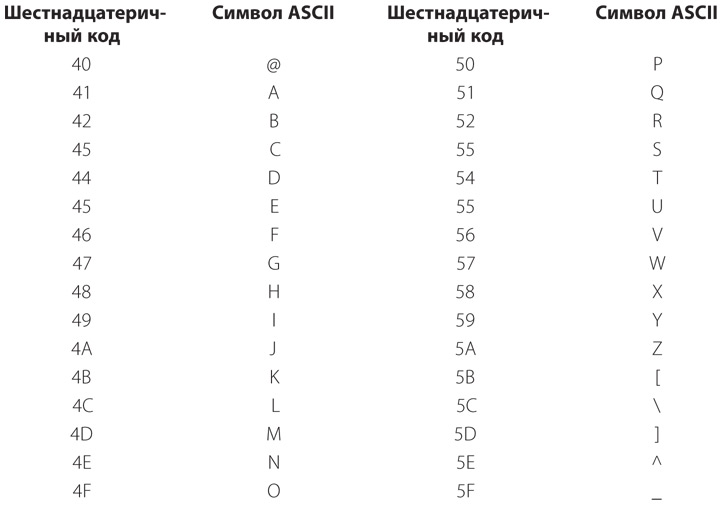
Следующие 32 кода — прописные буквы и некоторые дополнительные знаки препинания. Кроме значка @ и символа подчеркивания, эти знаки обычно отсутствуют на пишущих машинках, однако являются стандартными для компьютерных клавиатур.
Следующая группа из 32 символов: все строчные буквы и некоторые дополнительные знаки препинания, которые, опять же, редко встречаются на пишущих машинах.
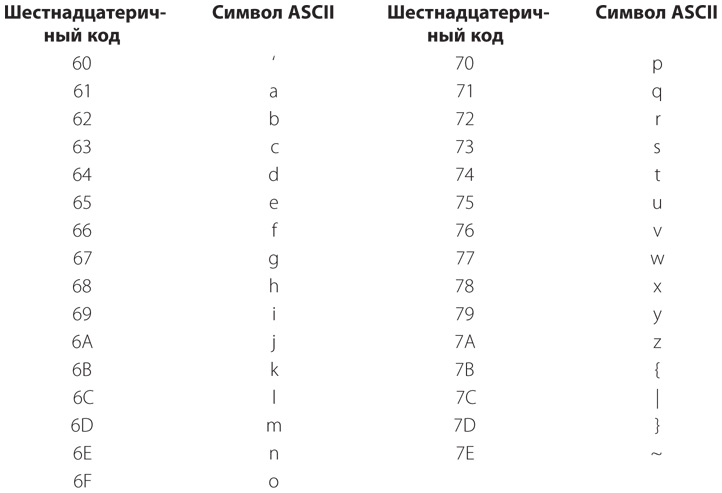
В этой таблице отсутствует последний символ, соответствующий коду 7Fh. Приведенные выше три таблицы содержат в общей сложности 95 символов. Поскольку код ASCII является 7-битным, он допускает использование 128 кодов, поэтому нам должно быть доступно еще 33 кода, до которых мы скоро и доберемся.
Текстовая строка Hello, you! («Привет тебе!») может быть представлена в кодировке ASCII с использованием следующих шестнадцатеричных кодов.
Hello, you!
48 65 6C 6C 6F 2C 20 79 6F 75 21
Обратите внимание на запятую (код 2C), пробел (код 20) и восклицательный знак (код 21), а также на коды, соответствующие буквам. Представление короткого предложения I am 12 years old («Мне 12 лет») в кодировке ASCII следующее.
I am 12 years old.
49 20 61 6D 20 31 32 20 79 65 61 72 73 20 6F 6C 64 2E
Число 12 в этом предложении отображено шестнадцатеричными числами 31h и 32h, то есть кодами ASCII для цифр 1 и 2. Когда число 12 — часть текста, его нельзя представлять с помощью шестнадцатеричных кодов 01h и 02h, BCD-кода 12h или шестнадцатеричного кода 0Ch. Все эти коды имеют в системе ASCII совершенно другие значения.
Конкретная прописная буква в системе ASCII отличается от своей строчной версии на 20h. Этот факт позволяет легко написать код, который, например, переводит текстовую строку в верхний регистр. Предположим, что определенная область памяти содержит текстовую строку, по одному символу на байт. Следующая подпрограмма для процессора 8080 предполагает, что адрес первого символа в текстовой строке хранится в регистре HL. Регистр C включает длину этой текстовой строки, то есть количество символов.

Оператор, который вычитает 20h из кода строчной буквы для ее преобразования в прописную, можно заменить следующим фрагментом.
ANI A, DFh
Инструкция ANI (AND Immediate) выполняет побитовую операцию И между значением в аккумуляторе и значением DFh, которое в двоичном формате равно 11011111. Под словом «побитовая» подразумеваю, что такая команда выполняет операцию И между каждой парой соответствующих битов, составляющих два числа. Эта операция И сохраняет все биты, содержащиеся в аккумуляторе (A), за исключением третьего слева, значение которого задается равным 0, что, в свою очередь, преобразует строчную букву ASCII в прописную.
Приведенные выше 95 кодов — это так называемые печатные символы, поскольку они имеют графическое представление. Кроме них в кодировке ASCII также предусмотрено 33 управляющих символа, которые не имеют графического представления, но выполняют определенные функции. Для полноты приведу эти 33 управляющих символа. Не беспокойтесь, если они покажутся вам непонятными. Кодировка ASCII изначально предназначалась для использования в телетайпах, поэтому многие из ее кодов в настоящее время потеряли свое значение.
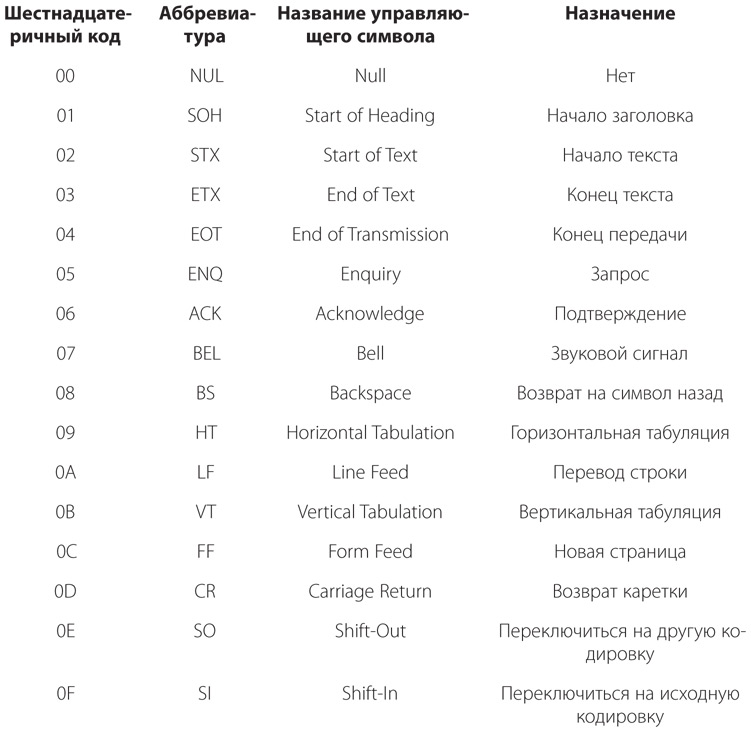
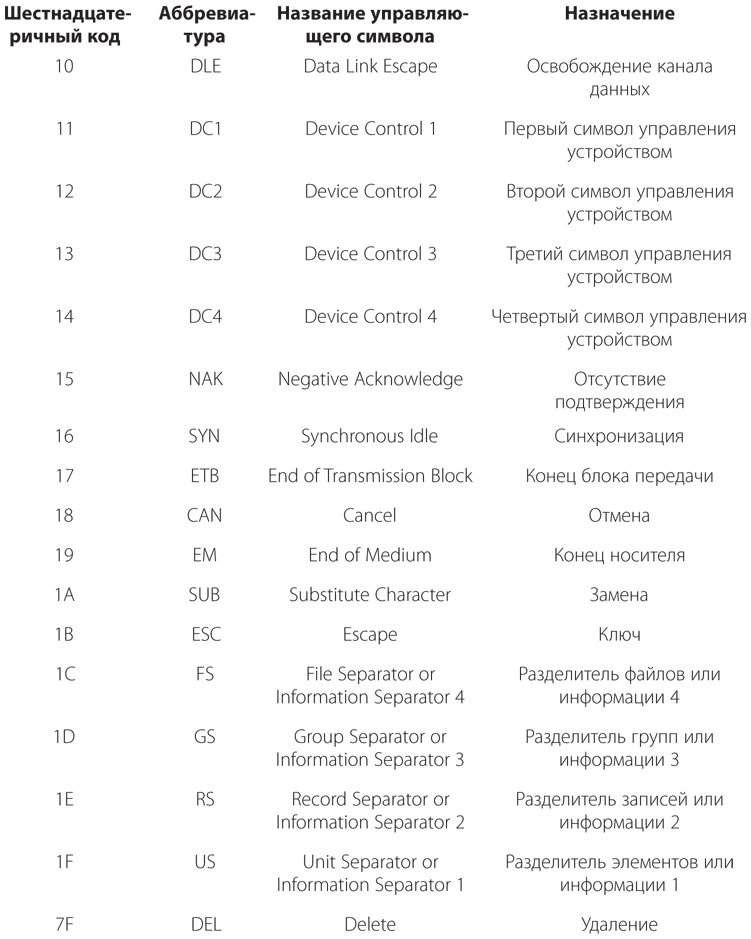
Управляющие символы в данном случае могут использоваться наряду с печатными для элементарного форматирования текста. Это проще всего понять, если вы подумаете о таком устройстве, как телетайп или простой принтер, который отпечатывает на странице символы под воздействием потока кодов ASCII. Получив код символа, печатающая головка устройства наносит символ и перемещается на одну позицию вправо. Наиболее важные управляющие символы изменяют это нормальное поведение.
Рассмотрим следующую строку шестнадцатеричных значений.
41 09 42 09 43 09
Символ 09 — это код горизонтальной табуляции, или табулятор. Если представить, что все горизонтальные позиции символа на странице принтера нумеруются начиная с 0, то код табуляции дает команду напечатать следующий символ на следующей горизонтальной позиции, номер которой кратен восьми, например так.
Это удобный способ для расположения текста столбцами.
Даже сегодня многие компьютерные принтеры реагируют на код перехода к новой странице (12h), извлекая текущую страницу и начиная печатать на новой.
Код для возврата на один символ назад (backspace) может использоваться для печати составных символов на некоторых старых принтерах. Предположим, вам нужно, чтобы телетайпный аппарат отобразил строчную букву e с обратным апострофом: è. Эту задачу можно решить с помощью шестнадцатеричных кодов 65 08 60.
Сегодня наиболее важными являются управляющие коды для возврата каретки и перевода строки, которые имеют то же значение, что и аналогичные коды Бодо. В ответ на код возврата каретки печатающая головка принтера перемещается к левому краю страницы, а в ответ на код перевода строки — на одну строку вниз. Обычно для перехода на новую строку требуются оба кода. Код возврата каретки может использоваться сам по себе для печати поверх существующей строки, а код перевода строки — для того, чтобы перейти к следующей, при этом не перемещаясь к левому краю страницы.
Несмотря на то что кодировка ASCII — доминирующий стандарт в компьютерном мире, она не используется во многих крупных компьютерных системах IBM. Для мейнфреймов System/360 компания разработала собственный 8-битный код EBCDIC (Extended BCD Interchange Code — расширенный двоично-десятичный код обмена информацией) — расширенный вариант более раннего 6-битного кода BCDIC, полученного из кодов, используемых на перфокартах IBM. Эти перфокарты, позволяющие хранить по 80 текстовых символов, были созданы IBM в 1928 году и использовались на протяжении более 50 лет.

Рассматривая взаимосвязь между перфокартами и соответствующими им 8-битными кодами символов EBCDIC, имейте в виду, что эти коды разрабатывались на протяжении многих десятилетий под влиянием различных технологий. По этой причине не стоит ожидать от них излишней логичности или согласованности.
На перфокарте символ кодируется комбинацией из одного или нескольких прямоугольных отверстий, пробитых в одном столбце. Сам символ часто печатается в верхней части карты. Нижние десять строк пронумерованы от 0 до 9. Ненумерованная строка над нулевой строкой считается одиннадцатой, а верхняя — двенадцатой; десятая строка отсутствует.
Вот еще несколько терминов из области применения перфокарт IBM: строки с нулевой по девятую называются цифровыми строками, или цифровой пробивкой. Одиннадцатая и двенадцатая строки — зонные строки, или зонная пробивка. Иногда нулевая и девятая строки считались не цифровыми, а зонными, что вызывало путаницу.
Восьмибитный код символа EBCDIC состоит из старшей и младшей тетрад (четыре бита). Младшая тетрада — код BCD, соответствующий цифровой пробивке символа; старшая тетрада — код, который произвольно можно поставить в соответствие зонной пробивке символа. Из главы 19 вы помните, что BCD означает двоично-десятичный код — 4-битный код для цифр от 0 до 9.
Для цифр от 0 до 9 не существует никакой зонной пробивки. Отсутствие пробивки соответствует старшей тетраде 1111. Младшая тетрада — код BCD цифровой пробивки. В следующей таблице приведены коды EBCDIC для цифр от 0 до 9.
Шестнадцатеричный код
Символ EBCDIC
F0
0
F1
1
F2
2
F3
3
F4
4
F5
5
F6
6
F7
7
F8
8
F9
9
Для прописных букв тетрада 1100 соответствует зонной пробивке только двенадцатой строки, тетрада 1101 — зонной пробивке только одиннадцатой строки, тетрада 1110 — зонной пробивке только нулевой строки. Приведем коды EBCDIC для прописных букв.
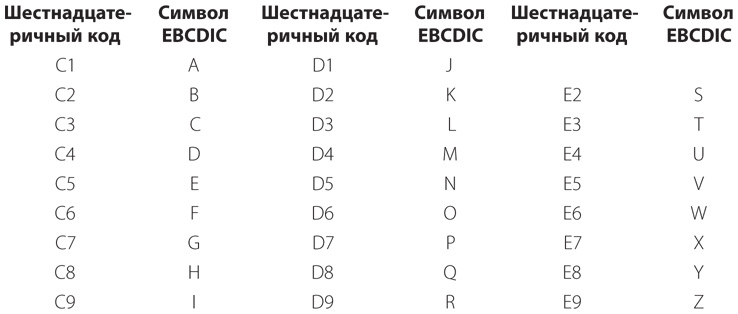
Обратите внимание на зазоры в нумерации этих кодов. Если вы используете текст EBCDIC при написании программ, эти зазоры могут мешать.
Строчные буквы соответствуют той же цифровой пробивке, что и прописные, но другой зонной пробивке. Для строчных букв от a до i пробиваются двенадцатая и нулевая строки, что соответствует коду 1000, для букв от j до r — двенадцатая и одиннадцатая строки, что соответствует коду 1001, для букв от s до z — одиннадцатая и нулевая строки, что соответствует коду 1010. Коды EBCDIC для строчных букв следующие.
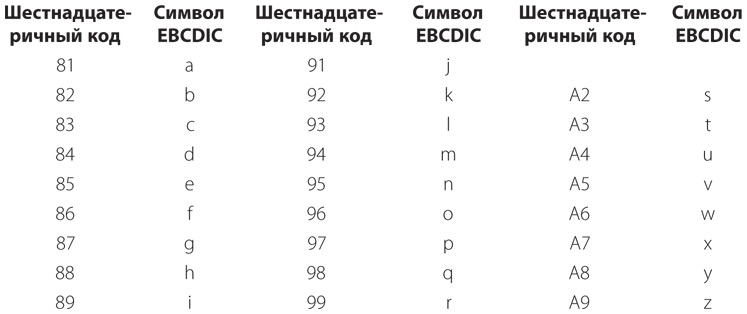
Разумеется, существуют и другие коды EBCDIC — для знаков препинания и управляющих символов, однако мы едва ли нуждаемся в проведении полномасштабного исследования этой системы.
На первый взгляд может показаться, что одного столбца перфокарты IBM достаточно для кодирования 12 бит информации. Каждое отверстие соответствует одному биту, не так ли? По идее, для кодирования символа ASCII должно быть достаточно семи из 12 позиций в каждом столбце. Однако на практике это не очень хорошо работает, поскольку при этом пробивается слишком много отверстий, из-за чего карта становится хрупкой.
Многие из 8-битных кодов EBCDIC не определены. Это говорит о том, что использование 7-битной кодировки ASCII имеет больше смысла. Во времена разработки системы ASCII память была дорогостоящей. Некоторые люди полагали, что кодировка ASCII должна быть 6-битной и предусматривать символ переключения между строчными и прописными буквами для экономии.
Как только эта идея была отвергнута, другие стали полагать, что кодировка ASCII должна быть 8-битной, поскольку даже в то время считалось, что в компьютерах будет применяться скорее 8-битная архитектура, чем 7-битная. Конечно, современным стандартом являются 8-битные байты. Несмотря на то что технически ASCII — это 7-битная кодировка, почти всегда ее коды хранятся как 8-битные значения.
Эквивалентность байтов и символов, безусловно, удобна, поскольку мы можем приблизительно представить, какой объем компьютерной памяти занимает конкретный текстовый документ, просто подсчитав количество символов. Некоторым людям гораздо легче понять, что такое килобайт и мегабайт памяти, когда этот объем ставится в соответствие объему текста.
Например, обычная машинописная страница формата А4 с полями 2,5 сантиметра и двойным междустрочным интервалом содержит примерно 27 строк текста. На каждой строке шириной 16 сантиметров содержится 65 символов. Содержимое такой страницы занимает в общей сложности около 1750 байт. Текст, содержащийся на машинописной странице с одинарным междустрочным интервалом, занимает примерно вдвое больше — 3,5 килобайта.
Страница в журнале New Yorker включает три столбца текста, в каждом из которых содержатся 60 строк по 40 символов. Это 7200 символов (байтов) на страницу.
Страница газеты New York Times содержит шесть столбцов текста. Если бы вся она была занята текстом без заголовков или изображений (что было бы необычно), то каждый столбец состоял бы из 155 строк по 35 символов. Тогда на всей странице было бы 32 550 символов, или 32 килобайта.
На странице обычной книги насчитывается около 500 слов. В среднем слово состоит примерно из семи букв, хотя скорее из восьми, если учитывать пробел. Таким образом, на странице книги около 3000 символов. Предположим, что средняя книга состоит из 333 страниц. Это значение, каким бы странным оно ни казалось, позволяет сказать, что объем текста средней книги составляет около одного миллиона байт, или один мегабайт.
Разумеется, объем текста книг варьируется в большом диапазоне:
«Великий Гэтсби» Фрэнсиса Скотта Фицджеральда — около 300 килобайт;
«Над пропастью во ржи» Джерома Сэлинджера — около 400 килобайт;
«Приключения Гекльберри Финна» Марка Твена — около 540 килобайт;
«Гроздья гнева» Джона Стейнбека — около одного мегабайта;
«Моби Дик, или Белый кит» Германа Мелвилла — 1,3 мегабайта;
«История Тома Джонса, найденыша» Генри Филдинга — 2,25 мегабайта;
«Унесенные ветром» Маргарет Митчелл — 2,5 мегабайта;
«Противостояние» Стивена Кинга — 2,7 мегабайта;
«Война и мир» Льва Толстого — 3,9 мегабайта;
«В поисках утраченного времени» Марселя Пруста — 7,7 мегабайта.
В Библиотеке Конгресса Соединенных Штатов насчитывается около 20 миллионов книг, в которых содержится в общей сложности 20 триллионов символов, что соответствует 20 терабайтам текстовых данных. (Кроме текста, там находится множество фотографий и аудиозаписей.)
Несмотря на то что ASCII, безусловно, является основным стандартом в компьютерной индустрии, он не идеален. Проблема в том, что этот стандарт слишком американский! Действительно, ASCII не вполне подходит даже для тех стран, в которых основным языком является английский. Кодировка ASCII включает символ доллара, но где же символ британского фунта? А как насчет букв с диакритическими значками, используемыми во многих западноевропейских языках? Я уже не говорю о нелатинских алфавитах, таких как греческий, арабский, иврит и кириллица. А что насчет символов слогового письма брахми, применяемого в Индии и Юго-Восточной Азии, на котором основаны такие виды письменности, как деванагари, бенгали, тайская и тибетская? Как с помощью 7-битного кода в принципе можно представить десятки тысяч идеограмм китайского, японского и корейского языков, а также десять с лишним тысяч хангыльских слогов?
В период разработки системы ASCII потребностям некоторых других стран уделяли внимание, хотя нелатинские алфавиты при этом особо не учитывались. Согласно опубликованному стандарту ASCII, десять его кодов (40h, 5Bh, 5Ch, 5Dh, 5Eh, 60h, 7Bh, 7Ch, 7Dh и 7Eh) можно переопределить в соответствии с национальными потребностями. Кроме того, при необходимости символ решетки (#) можно заменить символом британского фунта (£), а символ доллара ($) — обобщенным для валюты символом (¤). Очевидно, что замена символов имеет смысл только тогда, когда все пользователи конкретного текстового документа, содержащего эти переопределенные коды, знают об этом изменении.
Поскольку многие компьютерные системы хранят символы в виде 8-битных значений, можно расширить их набор со 128 до 256. В таком наборе коды с 00h по 7Fh определяются так же, как и в обычной системе ASCII, а коды с 80h по FFh могут представлять что-то совершенно иное. Этот метод использовался для определения дополнительных кодов для букв с диакритическими значками и нелатинских алфавитов. В качестве примера приведу набор кодов для букв кириллицы. В представленной таблице старшая тетрада шестнадцатеричного кода символа указана в верхней строке, а младшая — в левом столбце.
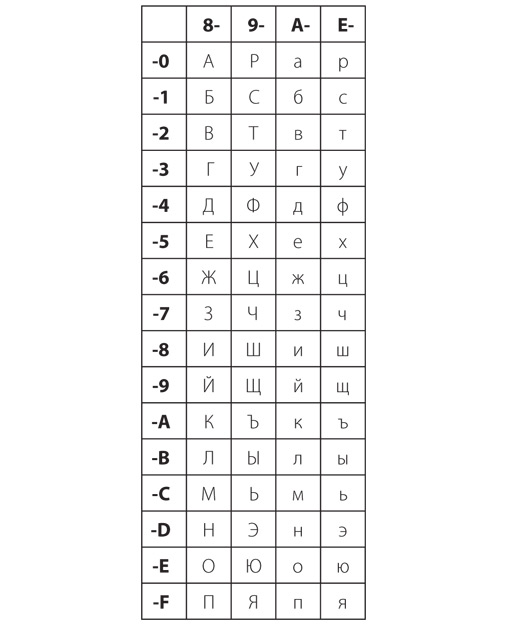
Символом кода A0h назначен неразрывный пробел. Обычно когда компьютерная программа форматирует текст в строки и абзацы, то разрыв строки равен пробелу, код ASCII которого 20h. Код A0h должен отображаться как пробел, но не может использоваться для разрыва строк. Неразрывный пробел может понадобиться, например, в фразе «WW II». Символ кода ADh — мягкий перенос. Его используют для разделения гласных в середине слова. На печатаемой странице он появляется, только когда необходимо перенести слово с одной строки на другую.
К сожалению, за минувшие десятилетия было создано много разных расширений кодировки ASCII, что привело к большой путанице и негативно отразилось на совместимости. Набор ASCII был расширен более радикальным образом для кодирования идеограмм китайского, японского и корейского языков. В одной популярной кодировке под названием Shift-JIS (Japan Industrial Standard — японский промышленный стандарт) коды с 81h по 9Fh фактически представляют первый байт двухбайтового кода символа. Таким образом, система Shift-JIS позволяет кодировать около 6000 дополнительных символов. К сожалению, Shift-JIS — не единственная система, которая использует такой подход. В Азии широко распространены еще три стандартных набора двухбайтовых символов (Double-byte character sets, DBCS).
Существование нескольких несовместимых наборов двухбайтовых символов — лишь одна из проблем. Печально, что некоторые символы, в частности обычные символы ASCII, представлены однобайтовыми кодами, а тысячи идеограмм — 2-байтовыми. Это затрудняет работу с такими наборами.
Считая предпочтительным наличие единой однозначной системы кодирования символов, подходящей для всех языков мира, в 1988 году несколько крупных компьютерных компаний объединились для разработки альтернативы ASCII, получившей название Unicode. В отличие от 7-битного кода ASCII, Unicode — 16-битный. Для каждого символа в кодировке Unicode требуется два байта. Значит, Unicode предусматривает коды символов от 0000h до FFFFh, то есть может представлять 65 536 различных символов. Этого достаточно для охвата всех языков мира, которые с большой долей вероятности будут использоваться в компьютерной индустрии, даже с возможностью расширения.
Кодировка Unicode создавалась не с нуля. Первые 128 символов Unicode, коды которых находятся в диапазоне от 0000h до 007Fh, соответствуют тем же символам в системе ASCII. Кроме того, коды Unicode с 00A0h по 00FFh — это коды описанного выше расширения ASCII для латинского алфавита Latin Alphabet No 1. В Unicode также включены другие мировые стандарты.
Несмотря на то что Unicode — очевидное улучшение систем кодировки, это не гарантирует его мгновенного принятия. Система ASCII и множество несовершенных расширений настолько укоренились в мире компьютерных технологий, что вытеснить их будет сложно.
Единственная настоящая проблема системы Unicode в том, что она делает недействительным прежнее соответствие между одним текстовым символом и одним байтом памяти. Закодированный с помощью стандарта ASCII роман «Гроздья гнева» занимает один мегабайт, а в кодировке Unicode — два мегабайта. Однако это небольшая плата за универсальную и однозначную систему кодирования.
Назад: Глава 19 Два классических микропроцессора
Дальше: Глава 21 Шины

