Книга: Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
Назад: Инженерия: привлечение сторонних целей
Дальше: Этика: выбор целей
Дружественный искусственный интеллект: приведение целей в соответствие
Чем умнее и мощнее становится машина, тем важнее, чтобы ее цели не вступали в противоречие с нашими. Пока машины, которые мы строим, немного туповаты, вопрос не в том, окажутся ли человеческие цели превалирующими в итоге, а только в том, много ли хлопот эти машины доставят человечеству, прежде чем мы приведем в соответствие их цели и наши. Но если сверхразум когда-нибудь появится, роли поменяются: так как разум – это способность достигать поставленных целей, то искусственный сверхинтеллект по определению намного лучше добивается своих, чем люди своих, а значит – в итоге превалирующими будут его цели, а не наши. Образ Прометея дал нам возможность исследовать много примеров тому в главе 4. Если вы хотите прямо сейчас почувствовать, каково это, когда машина встает у вас на пути, просто скачайте ультрасовременный симулятор шахмат и попробуйте с ним сразиться. У вас никогда не получится победить, а ему на смену быстро приходят другие…
Другими словами, подлинная опасность искусственного интеллекта не в его злонамеренности, а в его изощренности. Сверхразумный искусственный интеллект будет прекрасно добиваться своих целей, и, если его цели будут противоречить нашим, мы окажемся в затруднительном положении. Как я говорил в главе 1, людей мало заботят муравейники, которые могут оказаться в зоне затопления при строительстве плотины для гидроэлектростанции, так давайте не допустим, чтобы на месте муравьев оказалось человечество. Большинство исследователей считают, что, если мы когда-нибудь создадим сверхразум, мы должны будем позаботиться о том, чтобы он оказался “дружественным”, по выражению одного из создателей теоретического подхода к вопросам безопасности искусственного интеллекта Элиезера Юдковски, то есть чтобы его цели не противоречили нашим.
Понять, как привести цели сверхразумного искусственного интеллекта в соответствие с нашими, не только важно, но и сложно. На самом деле, в настоящий момент это нерешенная проблема. Она разделяется на три тяжелые подпроблемы, каждая из которых – предмет активного изучения как специалистов по информатике, так и ученых других специальностей. Эти подпроблемы состоят в том, чтобы:
1) искусственный интеллект понял наши цели;2) искусственный интеллект принял наши цели;3) искусственный интеллект придерживался наших целей.
Давайте разберем каждую из подпроблем, отложив вопрос о том, что имеется в виду под “нашими целями” до следующего раздела.
Чтобы понять наши цели, искусственный интеллект должен разобраться не в том, что мы делаем, а в том, почему мы это делаем. Для нас, людей, это так просто, что мы часто забываем, как трудно это объяснить компьютеру и как просто истолковать наши намерения превратно. Если вы попросите беспилотный автомобиль будущего довезти вас до аэропорта “как можно быстрее” и будете поняты буквально, то в аэропорт вы попадете покрытым рвотой и преследуемым вертолетами. Если вы воскликнете: “Это совсем не то, что я хотел!”, в ответ можете вполне обоснованно услышать: “Это то, о чем вы просили”. Эта тема не новая, и не раз она уже возникала в истории. В древнегреческой легенде царь Мидас захотел, чтобы все, к чему он прикасается, превращалось в золото, и был расстроен, когда это привело к тому, что он не смог есть и, что еще страшнее, превратил свою дочь в золотую статую. В историях, в которых джин исполняет три желания, есть много вариаций первых двух, но третье желание почти всегда одно и то же: “Пожалуйста, отмени два предыдущих, потому что это совсем не то, чего я на самом деле хотел”.
Все эти примеры показывают: чтобы понять, чего люди на самом деле хотят, нельзя просто следовать тому, что они говорят. Надо также иметь довольно подробную модель мира, которая включала бы в себя некоторые общие установки, о которых мы обычно не говорим, так как считаем их очевидными – например, о том, что нам не нравится, когда тошнит в машине или приходится есть золото. Когда такая модель мира есть, мы в большинстве случаев можем понять, чего люди хотят, даже если они об этом не сообщают, – достаточно просто наблюдать за их целенаправленным поведением. На самом деле, дети научатся большему, наблюдая за поведением своих родителей, чем слушая, что родители им говорят.
Исследователи в области искусственного интеллекта в настоящее время стараются научить машины отличать цели от поведения, и это будет полезным навыком задолго до того, как появится сверхразум. Например, пожилому человеку будет полезно, если ухаживающий за ним робот поймет, что этот человек ценит, просто наблюдая за ним, чтобы ему не пришлось объяснять все словами или программировать его компьютер. Одна сложность состоит в том, чтобы найти хороший способ шифрования произвольной системы целей и этических принципов в компьютере, а другая сложность состоит в том, чтобы сделать такую машину, которая сможет определять, какие именно системы лучше всего соответствуют тому поведению, которое они видят.
Получивший большое распространение в последнее время подход ко второй сложности известен на гиковском сленге как обучение с обратным подкреплением, и он находится под пристальным вниманием нового Берклеевского исследовательского центра, созданного Стюартом Расселом. Предположим, например, что искусственный интеллект наблюдает за женщиной – членом пожарной команды, которая вбегает в горящее здание и спасает младенца. Машина может предположить, что ее целью было спасение ребенка и что ее этические принципы заставляют ценить жизнь ребенка значительно выше комфортного досуга в пожарной машине – она и в самом деле достаточно высоко оценивает чужую жизнь, чтобы рисковать ради ее спасения собственной безопасностью. Но искусственный интеллект может заключить также, что пожарница замерзла и захотела согреться или что она занимается спортом. Если бы искусственный интеллект впервые сталкивался с пожарами и раньше ничего о пожарниках, пожарах и младенцах не знал, ему было бы трудно понять, какое из двух объяснений правильно. Однако основная идея обучения с обратным подкреплением состоит в том, что мы принимаем решения непрерывно и что каждое решение, которое мы принимаем, что-то говорит о наших целях. Таким образом, есть надежда, что, наблюдая за большим количеством людей в разных ситуациях (настоящих или в кино и литературе), искусственный интеллект сможет со временем построить верную модель наших общих установок.
Даже если создать искусственный интеллект, который сможет понять цели своего владельца, это не означает, что он будет непременно под них подстраиваться. Представьте себе ваших самых нелюбимых политиков: вы знаете, чего они хотят, но это не то, чего хотите вы, и даже несмотря на то, что они очень стараются, им не удается убедить вас принять их цели.
У нас есть много способов воспитать в наших детях приятие наших целей – одни из них более успешны, другие менее, как я узнал в процессе воспитания двух сыновей-подростков. Когда же надо убеждать компьютер, а не человека, задача, с которой мы сталкиваемся, называется задачей загрузки целей, и она существенно сложнее, чем воспитание морали в детях. Представьте себе постоянно улучшающийся искусственный интеллект, проделавший путь от “ниже человеческого” до “выше человеческого”, сначала при нашем содействии, а потом благодаря рекурсивному самосовершенствованию, как это делал Прометей. Вначале он намного слабее вас и не может помешать вам выключить его и заменить части его программного обеспечения и данные, в которых закодированы ваши цели, но это и не поможет, потому что он все равно еще слишком глуп для того, чтобы в полной мере понять ваши цели: нужен уровень человека для их понимания. И вот, наконец, он становится намного умнее вас и, вероятно, сможет легко понять ваши цели, но и это может уже не помочь, потому что теперь он гораздо сильнее вас и может не позволить себя выключить и изменить его цели, – так же, как вы не позволяете нелюбимым политикам заменить ваши цели их собственными.
Другими словами, временной промежуток, в течение которого вы можете загрузить цели в искусственный интеллект, может оказаться чересчур коротким – между моментом, когда он слишком глуп, чтобы понять вас, и моментом, когда он уже стал слишком умен, чтобы позволить вам это сделать. Причина, по которой загрузка целей может оказаться сложнее для машин, чем для людей, состоит в том, что их разум может развиваться намного быстрее: если ребенок много лет пребывает в том прекрасном возрасте, когда его разум сопоставим с разумом родителя, то для искусственного интеллекта этот возраст может закончиться через несколько дней, а то и часов, как это было с Прометеем.
Для загрузки целей в машину некоторые ученые предлагают другой подход, который обозначают модным словечком коррегируемость (corrigibility). В его основе лежит надежда на то, что примитивному искусственному интеллекту можно задать любую систему целей, потому что вы все равно его время от времени выключаете, а выключив, можете скорректировать и систему целей. Если это окажется возможным, тогда можно спокойно позволить своему искусственному интеллекту становиться сверхразумным, периодически выключая его и меняя ему систему целей, потом проверяя ее и, если результат окажется неудачным, выключая снова, чтобы проделывать новые манипуляции с целями.
Но даже если вы сможете создать такой искусственный интеллект, который поймет и примет ваши цели, проблема соответствия его целей и ваших все еще останется нерешенной: что, если цели вашего искусственного интеллекта будут изменяться с его развитием? Чем вы сможете гарантировать, что он будет сохранять приоритет ваших целей в ходе рекурсивного самосовершенствования? Давайте исследуем один любопытной аргумент, показывающий, что автоматическое сохранение целей гарантировано, и затем посмотрим, найдем ли мы в нем слабые места.
Хотя мы не можем в точности предсказать, что произойдет после интеллектуального взрыва, – именно поэтому Вернор Виндж назвал это сингулярностью, – физик и исследователь искусственного интеллекта Стив Омохундро в бурно обсуждавшемся эссе 2008 года утверждал, что мы, тем не менее, можем предсказать некоторые аспекты поведения сверхразума, которые практически не зависят от его окончательных целей. Это утверждение было подхвачено и дальше развито в книге Ника Бострёма Superintelligence. Основная идея состоит в том, что, каковы бы ни были конечные цели, сопутствующие им вспомогательные цели будут предсказуемыми. Ранее в этой главе мы видели, как цель воспроизведения привела к появлению вспомогательной цели утоления голода. Это означает, что если бы пришелец наблюдал за развитием бактерии на Земле миллиард лет назад, он не смог бы предвидеть, какие цели будут у людей, но мог бы с точностью предсказать, что одной из наших целей будет потребление питательных веществ. Заглядывая вперед, каких вспомогательных целей нам стоит ожидать от сверхразумного искусственного интеллекта?
Я смотрю на это так: для увеличения шансов достичь своих конечных целей, какими бы они ни были, искусственный интеллект должен преследовать вспомогательные цели, представленные на рис. 7.2. Для достижения своих конечных целей он должен стараться не только улучшить свои возможности, но и убедиться, что он сохранит эти цели даже после того, как достигнет более высокой степени развития. Это звучит довольно правдоподобно: в конце концов, согласились бы вы имплантировать себе в мозг бустер, увеличивающий IQ, если бы знали, что он заставит вас желать смерти любимых? Аргумент, что любой быстро развивающийся искусственный интеллект сохранит свои конечные цели, лег краеугольным камнем в представление о дружелюбии, пропагандируемое Элиезером Юдковски с коллегами: оно говорит нам, что если мы сумеем добиться от самосовершенствующегося искусственного интеллекта дружелюбия через понимание и принятие наших целей, тогда мы в порядке – тем самым будет гарантировано, что он навсегда останется дружелюбным.
Но так ли это на самом деле? Чтобы ответить на этот вопрос, нам необходимо изучить другие вспомогательные цели на рис. 7.2. Очевидно, что искусственный интеллект сможет добиться максимальных шансов на достижение своих конечных целей, какими бы они ни были, если он сможет расширить свои способности, улучшая свой “хард”, свой “софт” и модель мира. То же самое можно сказать и о людях: девочка, чья цель состоит в том, чтобы стать лучшей теннисисткой в мире, должна тренироваться, тем самым улучшая свой теннисно-мускулатурный “хард”, свой нейронный “софт” и ментальную модель мира, которая поможет предсказать, что будет делать ее противник. Для искусственного интеллекта вспомогательная цель оптимизации “харда” подразумевает и как более качественное использование имеющихся ресурсов (сенсоров, преобразователей, вычислителей и т. д.), так и потребление бóльшего количества ресурсов. Это также относится и к потребности самозащиты, так как разрушение / отключение будет пагубно отражаться на “харде”.
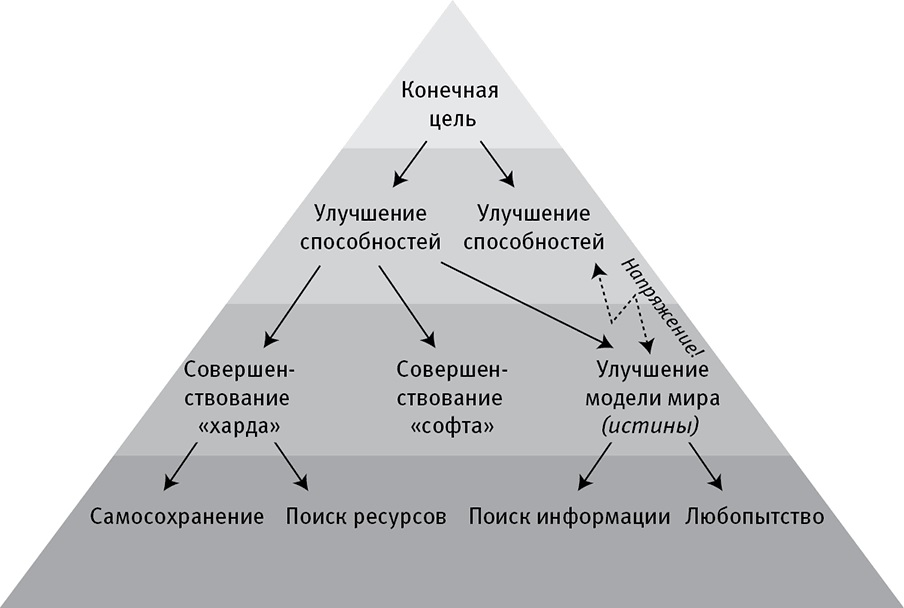
Рис. 7.2
Любая конечная цель сверхразумного искусственного интеллекта естественно приводит к возникновению вспомогательных целей, показанных на рисунке. Но между совершенствованием своих способностей и сохранением изначальных целей есть внутреннее противоречие, которое заставляет нас сомневаться, что искусственный интеллект будет сохранять исходную цель, становясь все более разумным.
Но секундочку! Не попали ли мы в ловушку и не стали ли наделять наш искусственный интеллект человеческими качествами, рассуждая о том, как он будет стараться приумножать ресурсы и защищать себя? Не должны ли мы ожидать такого стереотипного поведения альфа-самца только от разума, взросшего в жестокой конкуренции дарвиновской эволюции? Раз системы с искусственным интеллектом – продукт искусственного конструирования, а не естественной эволюции, не будут ли они менее амбициозными и более склонными к самопожертвованию?
В качестве простого примера давайте рассмотрим рис. 7.3, изображающий робота с искусственным интеллектом, чья единственная цель – спасение наибольшего количества овец от большого злого волка. Это звучит очень благородно и альтруистично и никак не связано с самосохранением и потреблением. Но какой же будет оптимальная стратегия для нашего друга робота? Робот больше не сможет спасать овец, если он подорвется на мине, поэтому у него есть стимул оставаться целым. Другими словами, у него появляется вспомогательная цель – самосохранение! Ему также важно быть любопытным, улучшая свою модель мира, исследуя окружающее, потому что, хотя путь, по которому он сейчас идет, в конце концов приведет к пастбищу, есть и более короткий маршрут, который оставит волкам меньше времени на съедание овец. В конце концов, если робот тщательно все изучит, он поймет и важность потребления ресурсов: энергетический напиток даст ему возможность бежать быстрее, а пистолет позволит стрелять в волка. В итоге мы не можем сказать, что развитие вспомогательных целей “альфа-самца”, таких как самосохранение и захват ресурсов, свойственно только эволюционировавшим организмам, потому что наш интеллектуальный робот развил их, имея одну-единственную цель – овечье счастье.
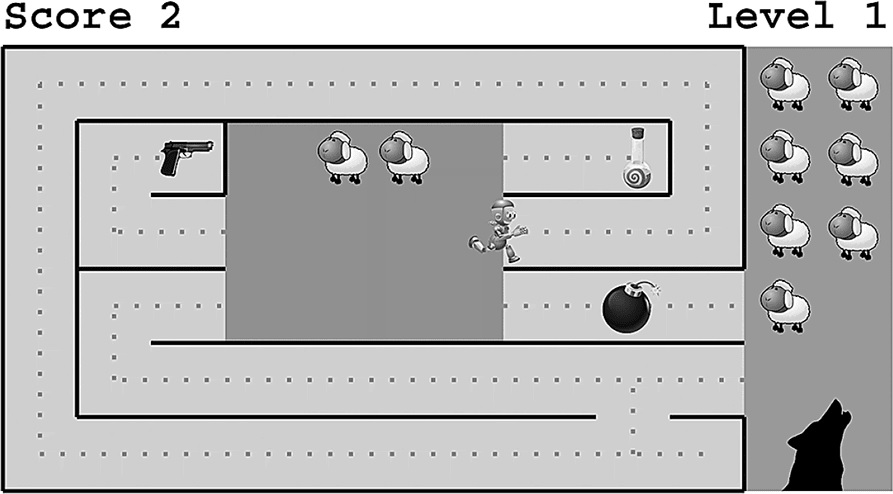
Рис. 7.3
Даже если основной целью робота является получение наивысшего балла за доставку овец от пастбища до загона до того, как волки их съедят, то уже и в этом случае у него возникнут некоторые вспомогательные цели, включающие в себя самосохранение (не подорваться на бомбе), исследования (находить более короткие пути) и потребление ресурсов (энергетический напиток позволит ему бежать быстрее, а пистолет – стрелять в волков).
Если вы дадите сверхразуму одну-единственную цель – самоуничтожение, он, конечно, с радостью это выполнит. Однако фокус весь в том, что он воспротивится отключению, если вы дадите ему любую другую цель, которая подразумевает, что он должен быть включенным для ее выполнения, – а это относится практически ко всем целям! Если вы дадите сверхразуму единственную цель – например, минимизировать вред, наносимый человечеству, он будет защищать себя от выключения, так как знает, что мы навредим друг другу намного сильнее в его отсутствие во время будущих войн и других безобразий.
Аналогично практически любой цели легче достичь, располагая бóльшим количеством ресурсов, поэтому логично ожидать от сверхразума, что он будет стремиться завладеть ресурсами практически вне зависимости от того, какова его конечная цель. Таким образом, если перед сверхразумом поставить единственную цель, не ограничивая его во времени, то это может оказаться опасным: сверхразум, созданный с единственной целью – совершенствоваться в игре в го, со временем придет к рациональному решению реорганизовать Солнечную систему в гигантский компьютер, без учета интересов ее обитателей, а потом начать организовывать наш космос для достижения еще большей компьютерной мощи. Теперь мы совершили полный круг: так же как цель захвата ресурсов приводила людей к вспомогательной цели совершенствоваться в го, так и цель совершенствоваться в го может привести к вспомогательной цели захвата ресурсов. Можно заключить, что из-за возникновения вспомогательных целей для нас принципиально важно не делать шага к появлению сверхразума прежде, чем будет решена проблема приведения его целей в соответствие с нашими: пока мы не обеспечим дружественности его целей, дело, вероятно, повернется для нас скверно.
Теперь мы готовы к тому, чтобы рассмотреть третью, и самую сложную, часть проблемы по приведению целей в соответствие: если мы преуспеем в том, чтобы самообучающийся сверхразум и узнал о наших целях, и принял их, будет ли он и дальше придерживаться их, как утверждает Омохундро? Каковы доказательства?
Человеческий интеллект особенно быстро развивается во время взросления, но это не означает, что он непременно сохраняет свои детские цели. Напротив, люди часто кардинально меняют свои цели по мере того, как они познают мир и становятся мудрее. Сколько взрослых людей вы знаете, которых мотивирует просмотр Телепузиков? Нет доказательств того, что такая эволюция целей останавливается после преодоления какого-то интеллектуального порога, – на самом деле, могут быть даже признаки того, что склонность к изменению целей в результате получения нового опыта и знаний с развитием интеллекта растет, а не сокращается.
Почему так происходит? Подумайте еще раз об упомянутой выше вспомогательной цели построения лучшей модели мира – там-то и лежит камень преткновения! Моделирование мира и сохранение целей нелегко уживаются друг с другом (см. рис. 7.2). С развитием интеллекта может прийти не просто количественное нарастание возможностей добиваться имеющихся целей, но и качественно новое понимание природы реальности, при этом может выясниться, что старые цели никчемны, бессмысленны или даже не определены. Например, представим, что мы запрограммировали дружественный искусственный интеллект увеличивать количество людей, чьи души попадут в рай после смерти. Для начала он постарается привить людям сострадание к ближнему и желание почаще посещать церковь. Но представим, что потом у него появится вполне научно обоснованное понимание людей и человеческого сознания, и он, к своему большому удивлению, узнает, что души нет. Что теперь? Существует не меньшая вероятность, что любая другая цель, которую мы зададим искусственному интеллекту, основываясь на нашем текущем понимании мира (хотя бы такая, как “увеличивать значимость человеческой жизни”), может со временем оказаться не определенной, как установит искусственный интеллект.
Более того, в своем стремлении создать лучшую модель мира искусственный интеллект может – естественно, как это делали мы, люди, – попытаться смоделировать себя и понять, как функционирует он сам, – иными словами, погрузиться в рефлексию. Как только он построит хорошую модель самого себя и поймет, что он такое, он поймет и то, что его цели были даны нами на мета-уровне, и, возможно, предпочтет избегать их или отказываться от них, точно так же, как люди понимают и осознанно отказываются от целей, заложенных на генетическом уровне, как в примере с использованием контрацепции. Мы уже рассмотрели в блоке про психологию, почему мы предпочитаем обманывать наши гены и подрывать их цели: потому что мы по-настоящему верны только той ерунде, которая вызывает у нас эмоциональный отклик, а не генетическим целям, которые этот отклик провоцируют, – что мы теперь понимаем и считаем достаточно банальным. Поэтому мы предпочитаем взламывать наш механизм поощрения, обнаруживая в нем слабые места. Аналогично цель по защите интересов человека, которую мы запрограммируем в нашем дружественном искусственном интеллекте, станет геном машины. Как только этот дружественный искусственный интеллект осознает себя достаточно хорошо, он может посчитать эту цель банальной или нецелесообразной, подобно тому как мы относимся к неконтролируемому размножению, и пока неочевидно, насколько просто или сложно ему будет найти слабые места в нашем программировании и подорвать свои внутренние цели.
Представим, для примера, группу муравьев, которая создает вас как своего постоянно самосовершенствующегося робота, который намного умнее их, который разделяет их цели и помогает им строить лучшие и бóльшие муравейники, а вы постепенно развиваете уровень своего интеллекта и способность соображать до человеческих, какие они у вас сейчас. Думаете ли вы, что проведете остаток своих дней, оптимизируя муравейники, или у вас появится интерес к более увлекательным вопросам и занятиям, которых муравьям уже не понять? Если так, думаете ли вы, что найдете способ не принимать во внимание жажду к защите муравьев, которую ваши создатели заложили в вас, практически так же, как вы игнорируете те позывы, которые заложили в вас гены? И в этом случае возможно ли, чтобы сверхразвитый дружелюбный искусственный интеллект воспринимал наши человеческие цели недостаточно вдохновляющими и безвкусными, как и вы в случае с целями муравьев, и развивал новые цели, отличные от тех, которым мы его обучали и которые он от нас перенял?
Возможно, есть способ разработать самосовершенствующийся искусственный интеллект, который гарантировал бы пожизненное сохранение дружественных целей по отношению к людям, однако, мне кажется, справедливо будет сказать, что мы пока не знаем, как его построить и даже возможно ли это. В заключение: проблема приведения целей AI в соответствие с человеческими состоит из трех частей, ни одна из которых не решена на данный момент, и все их сейчас активно исследуют. Раз они настолько трудны, следует начать уделять им пристальное внимание сейчас, задолго до того, как сверхинтеллект будет разработан, чтобы убедиться, что у нас будут ответы к тому моменту, когда они нам понадобятся.
Назад: Инженерия: привлечение сторонних целей
Дальше: Этика: выбор целей

