Книга: Жизнь 3.0. Быть человеком в эпоху искусственного интеллекта
Назад: Глава 3 Ближайшее будущее: болезни, законы, оружие и работа
Дальше: Надежность искусственного интеллекта и глюки
Прорывы
Системы глубокого обучения с подкреплением и его агенты
В 2014 году, когда я смотрел видео, на котором разработанная DeepMind система с искусственным интеллектом училась играть в компьютерные игры, у меня отвисла челюсть. В особенности хорошо искусственному интеллекту удавалось играть в Breakout (см. рис. 3.1), классическую игру Atari, с нежностью вспоминаемую мной с подросткового возраста. Цель игры в том, чтобы, перемещая платформу, заставлять шарик биться о кирпичную стену. Всякий раз, когда удается выбить из стены кирпич, он пропадает, а счет увеличивается.
В тот день я написал несколько компьютерных игр, и хорошо знал, что написать программу, которая может сыграть в Breakout, совсем не трудно, но это было не то, что сделала команда DeepMind. Они сделали другое: создали девственно чистый AI, который ничего не знал об этой игре, как и о любых других играх, и вдобавок не имел никакого понятия о том, что такое игры, платформы, кирпичи или шарики. Их AI знал лишь одно: длинный список чисел, загружающихся через равные интервалы времени и представляющих текущий счет, и еще один длинный список, которые мы (но не AI) интерпретировали бы как описание цвета и освещенности разных частей экрана. AI просто велели максимизировать счет, выставляя с регулярными интервалами числа, которые мы (но не AI) будем распознавать как коды, соответствующие определенным нажатиям клавиш.
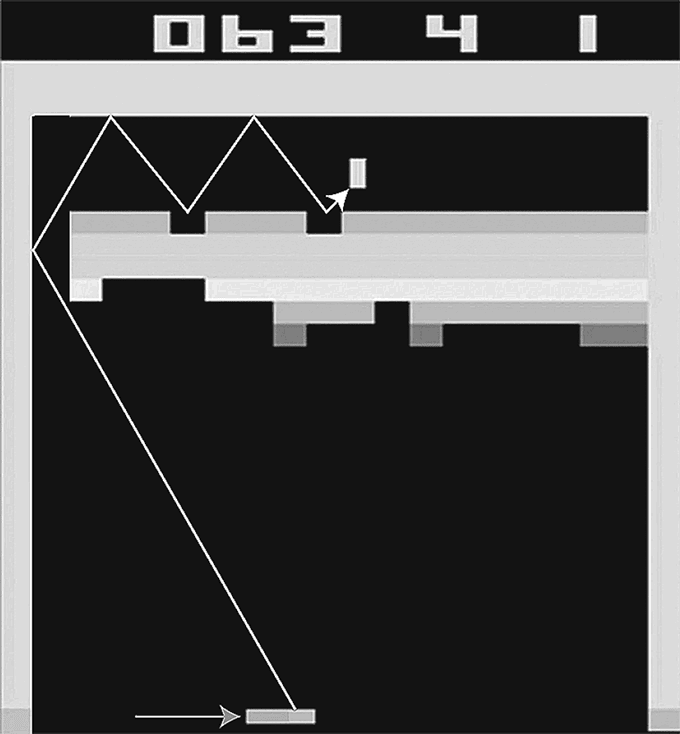
Рис. 3.1
Искусственный интеллект DeepMind учился проходить аркадную игру Breakout на платформе Atari с нуля, для чего использовались методы машинного обучения с подкреплением. Вскоре DeepMind самостоятельно открыл оптимальную стратегию: пробивать в левом краю кирпичной стены дыру и загонять в эту дыру игровой шарик, который, оказавшись в замкнутом пространстве, быстро увеличивает счет. Я добавил на этом рисунке стрелки, показывающие траектории платформы и шарика.
Поначалу AI играл ужасно: он бессмысленно толкал платформу влево и вправо, как слепой, почти каждый раз промахиваясь мимо шарика. В какой-то момент у него, казалось, возникла идея, что двигать платформу по направлению к шарику – это, наверное, правильно, но шарик все равно пролетал мимо. Мастерство AI, однако, продолжало расти с практикой, и вскоре он стал играть значительно лучше, чем я когда бы то ни было, безошибочно отбивая шарик, как бы быстро тот ни двигался. И тут-то и пришло время моей челюсти отвиснуть: AI непостижимым образом смог раскрыть знакомую мне стратегию максимизации очков: всегда целиться в верхний левый угол, чтобы, пробив дырку в кирпичной кладке, загонять шарик туда, позволяя ему там долго прыгать между тыльной стороной стены и границей игрового поля. Это действительно казалось разумным решением. Позже Демис Хассабис говорил мне, что программисты компании DeepMind не знали этого трюка, пока созданный ими искусственный интеллект не открыл им глаза. Я всем рекомендую посмотреть этот ролик, перейдя по ссылке, которую я здесь привожу.
В том, как все это делалось, было что-то до такой степени человеческое, что мне стало не по себе: я видел AI, у которого была цель и который достиг совершенства на пути к ней, значительно обогнав своих создателей. В предыдущей главе мы определили интеллект просто как способность достигать сложных целей, и в этом смысле AI DeepMind становился все более умным в моих глазах (хотя бы и в очень узком смысле освоения премудростей единственной игры). В первой главе мы уже встречались с тем, что специалисты по информатике называют интеллектуальными агентами: это сущности, которые собирают информацию об окружающей среде от датчиков, а затем обрабатывают эту информацию, чтобы решить, как действовать в этой среде. Хотя игровой искусственный интеллект DeepMind жил в чрезвычайно простом виртуальном мире, состоящем из кирпичей, шариков и платформы, я не мог отрицать, что этот агент был разумным.
DeepMind вскоре опубликовала и свой метод, и использованный код, объяснив, что в основе лежала очень простая, но действенная идея, получившая название глубокого обучения с подкреплением. Обучение с подкреплением – классический метод машинного обучения, основанный на бихевиористской психологии, которая утверждает, что достижение положительного результата подкрепляет ваше стремление повторить выполненное действие, и наоборот. Словно собака, которая учится выполнять команды хозяина, опираясь на его поддержку и в надежде на угощение, искусственный интеллект DeepMind учился двигать платформу, ловя шарик, в надежде на увеличение счета. DeepMind объединила эту идею с глубоким обучением: там научили глубокую нейронную сеть, описанную в предыдущей главе, предсказывать, сколько очков в среднем заработает АI, нажимая ту или иную из доступных клавиш, и, исходя из этого и учитывая текущее состояние игры, он выбирал ту клавишу, которую нейронная сеть оценивала как наиболее перспективную.
Рассказывая о том, что поддерживает мою положительную самооценку, я включил в этот список и способность решать разнообразные не решенные до меня задачи. Интеллект, ограниченный лишь способностью научиться хорошо играть в Breakout и больше ни на что не годный, следует считать чрезвычайно узким. Для меня вся важность прорыва DeepMind заключалась в том, что глубокое обучение с подкреплением – исключительно универсальный метод. Нет сомнений, что они практиковали его же, когда их AI учился играть в сорок девять различных игр Atari и достиг уровня, при котором стал уверенно обыгрывать любых человеческих соперников в двадцать девять из них, от Pong до Boxing, Video Pinball и Space Invaders.
Не надо было долго ждать момента, когда эту идею начнут использовать для обучения AI более современным играм – с трехмерными, а не двухмерными мирами. Вскоре конкурент компании DeepMind, базирующийся в Сан-Франциско OpenAI, выпустил платформу под названием Universe, где DeepMind AI и другие интеллектуальные агенты могли совершенствоваться во взаимодействии с компьютером так же, как если бы это была игра, – орудуя мышкой, набирая что угодно на клавиатуре, открывая любое программное обеспечение, например запуская веб-браузер и роясь в интернете.
Охватывая взглядом будущее углубленного обучения с подкреплением, трудно предсказать, к чему оно может привести. Возможности метода явно не ограничиваются виртуальным миром компьютерных игр, поскольку, если вы робот, сама жизнь может рассматриваться как игра. Стюарт Рассел рассказывал мне о своем первом настоящем HS-моменте, когда он наблюдал, как его робот Big Dog поднимается по заснеженному лесному склону, изящно решая проблему координации движений конечностей, которую он сам не мог решить в течение многих лет. Для прохождения этого эпохального этапа в 2008 году потребовались усилия огромного количества первоклассных программистов. После описанного прорыва DeepMind не осталось причин, по которым робот не может рано или поздно воспользоваться каким-нибудь вариантом глубокого обучения с подкреплением, чтобы самостоятельно научиться ходить, без помощи людей-программистов: все, что для этого необходимо, – это система, начисляющая ему очки при достижении успеха. Роботы в реальном мире также без помощи людей-программистов могут научиться плавать, летать, играть в настольный теннис, драться и делать все остальное из почти бесконечного списка других двигательных задач. Для ускорения процесса и снижения риска где-нибудь застрять или повредить себя в процессе обучения прохождение его начальных этапов будет, вероятно, осуществляться в виртуальной реальности.
Интуиция, творчество, стратегия
Еще одним поворотным моментом для меня стала победа созданного DeepMind искусственного интеллекта AlphaGo в матче из пяти партий в го против Ли Седоля, который на начало XXI века считался лучшим игроком в го в мире.
Тогда все ждали, что людей вот-вот лишат звания лучших игроков в го, как это случилось с шахматами десятилетиями раньше. И только настоящие знатоки го предсказывали, что на это потребуется еще одно десятилетие, и поэтому победа AlphaGo стала поворотным моментом для них так же, как и для меня. Ник Бострём и Рэй Курцвейл оба подчеркнули, что этот прорыв AI было очень трудно предвидеть, о чем свидетельствуют, в частности, интервью самого Ли Седоля до и после проигрыша в первых трех играх:
Октябрь 2015: “Оценивая нынешний уровень машины… я думаю, что выиграю почти все партии”.Февраль 2016 года: “Я слышал, что Google DeepMind AI стал на удивление силен и быстро учится, но я убежден, что смогу выиграть хотя бы в этот раз”.9 марта 2016 года: “Я был очень удивлен, так как совсем не ожидал, что могу проиграть”.10 марта 2016 года: “У меня нет слов… Я просто в шоке. Должен признать… что третья игра будет для меня нелегкой”.12 марта 2016 года: “Я чувствовал свое бессилие”.
В течение года после победы над Ли Седолем улучшенный вариант AlphaGo обыграл двадцать лучших игроков в го в мире, не проиграв ни одной партии.
Почему все это воспринималось мной так лично? Я признавался выше, что считаю интуицию и способность к творчеству основными своими человеческими качествами, и, как я сейчас понимаю, в тот момент я почувствовал, что AlphaGo обладает обоими.
Играющие в го по очереди ставят черные и белые камни на доске 19 на 19 (см. рис. 3.2). Возможных позиций в го больше, чем атомов в нашей Вселенной, а это означает, что просчитать все интересные последствия каждого хода – дело безнадежное. Поэтому игроки в значительной степени полагаются на подсознательную интуицию, которая дополняет их сознательные рассуждения в оценке сильных и слабых сторон той или иной позиции, и у экспертов эта интуиция развивается в почти сверхъестественное чувство. Как мы видели в предыдущей главе, в результате глубокого обучения иногда возникает нечто напоминающее интуицию: глубокая нейронная сеть может определить, что на картинке изображена кошка, не имея возможности объяснить почему. Поэтому команда DeepMind поставила на идею, что глубокое обучение может распознавать не только кошек, но и сильные позиции в го. Главное, к чему они стремились, создавая AlphaGo, – было поженить интуицию, присущую глубокому обучению, с логической силой классического GOFAI, каков он был до революции глубокого обучения. Они взяли обширную базу данных, где было много позиций го как из игр, сыгранных людьми, так и из игр, сыгранных AlphaGo с клоном самого себя, и тренировали глубокую нейронную сеть предсказывать для каждой позиции вероятность итоговой победы белых. Кроме того, они натренировали отдельную сеть предсказывать вероятные следующие ходы. Затем они объединили эти две сети, пользуясь “старыми добрыми методами” для быстрого просмотра сокращенного списка наиболее вероятных будущих позиций, чтобы определить следующий ход, для которого следующая позиция окажется самой сильной.

Рис. 3.2
Продолжение DeepMind – искусственный интеллект AlphaGo. Пренебрегая тысячелетним человеческим опытом игры в го, он сделал невероятно творческий ход на пятой линии, вся сила которого обнаружилась только 50 ходов спустя, в результате у легенды го Ли Седоля не оставалось никаких шансов.
Детьми, появившимися в браке интуиции и логики, оказались ходы, которые были не просто сильными, – в некоторых случаях их с полным основанием можно назвать креативными. Например, тысячелетняя мудрость го учит, что в начале игры надо стремиться захватить третью и четвертую линии от края. Тут есть возможность для торга: игра на третьей линии дает возможность быстро проводить краткосрочные захваты территории на краю доски, в то время как игра на четвертой линии способствует долгосрочному стратегическому влиянию на центр.
На тридцать седьмом ходу второй партии AlphaGo потряс мир го, пойдя наперекор этой древней мудрости и начав играть на пятой линии (рис. 3.2), словно он больше доверял своей способности долгосрочного планирования, чем человек, и поэтому отдавал предпочтение стратегическому преимуществу, а не краткосрочной выгоде. Комментаторы были ошеломлены, Ли Седоль даже поднялся и на какое-то время покинул помещение, где шла игра. Они продолжали играть еще достаточно долго, было сделано еще примерно пятьдесят ходов, и только после этого основные события из нижнего левого угла доски переместились в центр, достигнув того самого камня, поставленного на тридцать седьмом ходу! И его присутствие здесь в конце концов сделало всю игру, навсегда внеся вторжение AlphaGo на пятую линию в анналы истории го как одно из самых важных открытий.
Именно из-за того, что игра в го требует интуиции и творчества, многие считают го в бо́льшей степени искусством, чем просто игрой. В Древнем Китае умение играть в го считалось одним из четырех “основных искусств” наряду с живописью, каллиграфией и игрой на цине, и оно остается чрезвычайно популярным в Азии: за первой партией между AlphaGo и Ли Седолем следили почти 300 миллионов человек. Результат матча глубоко потряс мир го, и победа AlphaGo стала для него важнейшей исторической вехой. Кэ Цзиэ, обладатель самого высокого рейтинга по го в то время, так прокомментировал это событие: “Человечество играло в го тысячи лет, и все же, как нам показал искусственный интеллект, мы всего лишь поцарапали его поверхность… Союз игроков-людей и игровых компьютеров открывает новую эру… Человек и искусственный интеллект смогут найти истину го вместе”. Плодотворное сотрудничество между человеком и машиной, и в самом деле, представляется очень многообещающим во многих сферах, включая науку, где искусственный интеллект, надеюсь, поможет нам, людям, углубить наше понимание мира и в значительно большей мере реализовать наш потенциал.
В конце 2017 года команда DeepMind запустила следующую модель – AlphaZero. Человеческому искусству игры в го тысячи лет, были сыграны миллионы партий, но все они не понадобились AlphaZero, которая училась с нуля, играя сама с собой. Она не только разгромила AlphaGo, но и стала сильнейшим в мире игроком в шахматы – и это тоже исключительно играя сама с собой. После двух часов практики она могла победить любого шахматиста-человека, а через четыре – обыграла Stockfish, лучшую в мире шахматную программу. Меня тут особенно впечатляет не только то, что она била любого человека-шахматиста, но и то, что она обошла любого человека, занимающегося программированием искусственного интеллекта, она сделала устаревшим весь созданный людьми AI-софт, который разрабатывался несколько десятилетий. Иначе говоря, мы теперь не можем отмахнуться от идеи, что искусственный интеллект создает лучший искусственный интеллект.
Урок, преподанный нам AlphaGo, для меня состоял еще и в другом: объединение интуиции глубокого обучения с логикой “старого доброго искусственного интеллекта” может создавать стратегии на грани возможного. Поскольку го – одна из самых сложных стратегических игр, AI-системы должны теперь использоваться для того, чтобы оценивать способности и развивать их у лучших стратегов среди людей, проявляющих себя далеко за пределами игровой доски. Например, речь можно вести об инвестиционной стратегии, стратегии во внешней политике или военных операциях. Решение стратегических задач в перечисленных областях реальной жизни, как правило, осложняется человеческой психологией, отсутствием информации и случайными факторами, но системы с искусственным интеллектом, успешно играющие в покер, уже продемонстрировали, что ни одна из этих проблем не может считаться непреодолимой.
Естественный язык
Есть еще одна сфера деятельности, где успехи искусственного интеллекта в последнее время потрясли меня. Это языки. Еще в раннем детстве я полюбил путешествовать, и мое любопытство в отношении других культур и других языков сыграло огромную роль в формировании моей идентичности. В нашей семье говорили по-шведски и по-английски, в школе я учил немецкий и испанский, в двух браках мне понадобилось изучать португальский и румынский, просто так, ради удовольствия, я изучал русский, французский и мандарин.
Но с искусственным интеллектом тягаться мне оказывается не под силу, и после важного открытия 2016 года больше нет таких “приятных” мне языков, в которых я могу переводить с одного на другой лучше, чем система AI, созданная мозгом Google.
Я достаточно прозрачно выразился? Я действительно пытался это сказать:
Но AI догоняет меня, и после крупного прорыва в 2016 году не осталось почти никаких языков, между которыми я могу переводить лучше, чем искусственный интеллект, разработанный командой Google Brain для Google-переводчика.
Я сначала перевел эту фразу на испанский и обратно, используя приложение, которое я установил на своем ноутбуке несколько лет назад. В 2016 году команда Google Brain обновила свою бесплатную услугу Google Translate, включив в нее использование рекурсивных глубоких нейронный сетей, и в сравнении со “старыми добрыми” системами GOFAI это оказалось принципиальным:
Но AI догонял меня, и после прорыва в 2016 году практически не осталось языков, которые могут перевестись лучше, чем система AI, разработанная командой Google Brain.
Как вы можете видеть, местоимение “Я” потерялось во время захода в испанский язык, что, к сожалению, изменило смысл предложения. Близко, да мимо! Однако в защиту искусственного интеллекта от Google должен признать, что меня часто критикуют за пристрастие к избыточно длинным предложениям, которые трудно разобрать, и я выбрал для этого примера одно из самых замысловато закрученных. Типичные предложения часто переводятся безукоризненно. Появление этой системы вызвало в результате изрядный переполох, и сейчас к ее помощи прибегают сотни миллионов человек ежедневно. Кроме того, благодаря использованию глубокого обучения для развития систем преобразования речи в текст или текста в речь их пользователи теперь могут проговаривать текст своему смартфону на одном языке и выслушивать его перевод на другой.
Преобразования текстов на естественных языках – сейчас одна из наиболее быстро развивающихся областей применения искусственного интеллекта, и я думаю, что ее успешное развитие повлечет важные последствия, поскольку именно благодаря языку человек становится человеком. Чем сильнее становится искусственный интеллект в лингвистических предсказаниях, тем точнее он сможет ответить на электронное письмо или поддержать беседу. Благодаря этому, по крайней мере, у постороннего может сложиться впечатление, что он общается с человеком. Системы глубокого обучения делают сейчас первые шаги к тому, чтобы пройти знаменитый тест Тьюринга, научившись достаточно хорошо отвечать на вопросы в письменной форме, создавая у задающего их человека впечатление, что отвечает ему тоже человек.
И все же в работе с языком у искусственного интеллекта впереди еще долгий путь. Я должен признаться, что хотя меня задевает, когда искусственный интеллект обходит меня в точности перевода, я напоминаю себе, что искусственный интеллект совсем не понимает, о чем говорится в переводимом им тексте, и от этого мне сразу становится лучше. Его натренировали на массивном объеме данных искать соответствующие грамматические конструкции в языках и устойчивые отношения между словами, но он не умеет обнаруживать связь этих слов с чем бы то ни было в реальном мире. Например, он может представлять каждое слово в виде списка из тысяч чисел, показывающих, насколько оно близко по значению некоторым другим словам. Он может заключить, что разница между “королем” и “королевой” аналогична разнице между “мужем” и “женой”, но он все равно не знает, что значит быть мужчиной или женщиной, или даже что существует такая вещь, как физическая реальность, с пространством, временем и материей.
Тест Тьюринга, коль скоро в нем речь об обмане, не раз критиковали за то, что он проверяет скорее человеческое занудство, чем разумность компьютера. Конкурирующая система получила название Winograd Schema Challenge и была нацелена именно на то, чтобы выявить уровень общего здравомыслия, которого современным системам глубокого обучения как раз и недостает. Мы, люди, по старинке пользуемся нашим знанием о реальном мире, пытаясь понять предложение, угадывая, к чему относится то или иное местоимение. Например, вот типичное задание Винограда: определить, к кому относится местоимение “они” в предложениях:
1. Члены городского совета отказали демонстрантам в разрешении, потому что они боялись проявлений насилия.2. Члены городского совета отказали демонстрантам в разрешении, потому что они выступали в защиту насилия.
Каждый год между различными AI-системами проводятся соревнования, где ставятся такие вопросы, и пока эти системы показывают невысокую сообразительность. Именно эта задача – понимать, что относится к чему – сразила даже Google-переводчик, когда я в своем примере заменил испанский на китайский:
Но ИИ преследовал меня. После прорыва в 2016 году почти ни один язык не может быть переведен лучше, чем система искусственного интеллекта, разработанная командой Google Brain.
Пожалуйста, сходите сами на https://translate.google.com, пока читаете эту книгу, и проверьте, не улучшился ли искусственный интеллект Google. Велика вероятность, что с ним это случилось, так как существуют весьма многообещающие подходы, как поженить рекуррентную глубокую нейронную сеть со “старым добрым искусственным интеллектом”, чтобы построить лингвистическую AI-систему, включающую в себя и модель мира.
Возможности и вызовы
Все эти три примера тут, разумеется, случайны, так как искусственный интеллект сейчас быстро распространяется на многие виды деятельности. Более того, хотя выше я упоминал только две компании в двух примерах, конкурирующие группы исследователей в университетах и из других компаний не сильно от них отстали. Громкий вой работающего пылесоса раздается во всех департаментах информатики по всему миру – он сопровождает старания Apple, Baidu, DeepMind, Facebook, Google, Microsoft соблазнительными предложениями отсосать оттуда студентов, аспирантов, профессоров.
Очень важно, чтобы приведенные мной выше примеры не создали неправильного представления, будто история AI состоит в основном из периодов стагнации, прерываемых редкими удачами. У меня привилегированное положение: я вижу длительный и неуклонный рост, который преподносится прессой как прорыв, свидетельствующий лишь о том, что преодолен очередной порог и стало возможным новое, поражающее воображение приложение либо полезный продукт. И поэтому мне кажется совершенно ожидаемым длительный и непрерывный прогресс. Более того, как мы видели в предыдущей главе, нет никаких оснований думать, что этот прогресс не сможет длиться до тех пор, пока искусственный интеллект не достигнет человеческих способностей в большинстве дел.
Отсюда вопрос: а как это все повлияет на нас? Как новые возможности искусственного интеллекта изменят смысл человеческого существования? Мы уже видели, что становится все труднее отрицать способность искусственного интеллекта ставить цели, опираться на интуицию, проявлять креативность, понимать человеческий язык, – то есть обладать качествами, которые многие из нас считают определяющими нашу человеческую сущность. Это означает, что даже в короткой перспективе, задолго до того, как универсальный искусственный интеллект сможет тягаться с нами в решении большей части задач, наша самооценка уже будет поколеблена, у нас уже появятся серьезные причины задуматься над тем, а что мы можем совершить, если наш человеческий разум будет дополнен искусственным, или над тем, как мы будем зарабатывать деньги, когда нам придется с ним конкурировать? Наша жизнь – изменится она к лучшему или к худшему? Какие сиюминутные возможности он нам откроет, какие новые проблемы создаст?
Все, что нам нравится в истории нашей цивилизации, создано человеческим разумом, и если мы сможем усилить его с помощью искусственного интеллекта, то у нас, очевидно, появятся хорошие шансы для улучшения своей жизни. Даже самый небольшой прогресс в области искусственного интеллекта может быть конвертирован в ключевые достижения в науке и технике и связанные с ними сокращения числа несчастных случаев, опасных заболеваний, проявлений несправедливости, войн, наркомании, нищеты. Но для того, чтобы воспользоваться этими преимуществами AI, не создавая себе новых проблем, нам нужно ответить на многие важные вопросы. Например:
1. Как нам сделать будущие системы искусственного интеллекта более надежными, чем те, что у нас есть сегодня? Как добиться, чтобы они делали то, что мы хотим, не ломаясь и не раскрывая посторонним наших секретов?2. Как нам обновить наши законодательные системы, сделав их более справедливыми и действенными в условиях постоянно меняющегося цифрового пейзажа?3. Как мы можем сделать оружие “умнее” и менее склонным убивать ни в чем не повинных мирных жителей, и как нам при этом не спровоцировать неконтролируемой гонки автономных видов летального оружия?4. Как мы можем двигаться по пути процветания благодаря автоматизации и не оставлять при этом людей без средств к существованию и без цели в жизни?
Давайте посвятим остаток главы рассмотрению каждого из этих вопросов по очереди. Эти четыре насущных вопроса касаются прежде всего специалистов по информатике, юристов, военных стратегов и экономистов. Однако для того чтобы получить ответ на каждый из них к тому времени, когда он будет нам нужен, мы все должны уже сейчас поучаствовать в их обсуждении, потому что, как мы скоро увидим, риски уходят далеко за привычные нам границы – как между профессиями, так и между нациями.
Назад: Глава 3 Ближайшее будущее: болезни, законы, оружие и работа
Дальше: Надежность искусственного интеллекта и глюки

