8. Границы
Джеймс Гренинг

Редко когда весь программный код наших систем находится под нашим полным контролем. Иногда нам приходится покупать пакеты сторонних разработчиков или использовать открытый код. В других случаях мы зависим от других групп нашей компании, производящих компоненты или подсистемы для нашего проекта. И этот внешний код мы должны каким-то образом четко интегрировать со своим кодом. В этой главе рассматриваются приемы и методы «сохранения чистоты» границ нашего программного кода.
Использование стороннего кода
Между поставщиком и пользователем интерфейса существует естественная напряженность. Поставщики сторонних пакетов и инфраструктур стремятся к универсальности, чтобы их продукты работали в разных средах и были обращены к широкой аудитории. С другой стороны, пользователи желают получить интерфейс, специализирующийся на их конкретных потребностях. Эта напряженность приводит к появлению проблем на границах наших систем.
Для примера возьмем класс java.util.Map. Как видно из рис. 8.1, Map имеет очень широкий интерфейс с многочисленными возможностями. Конечно, мощь и гибкость контейнера полезны, но они также создают некоторые неудобства. Допустим, наше приложение строит объект Map и передает его другим сторонам. При этом мы не хотим, чтобы получатели Map удаляли данные из полученного контейнера. Но в самом начале списка стоит метод clear(), и любой пользователь Map может стереть текущее содержимое контейнера. А может быть, наша архитектура подразумевает, что в контейнере должны храниться объекты только определенного типа, но Map не обладает надежными средствами ограничения типов сохраняемых объектов. Любой настойчивый пользователь сможет разместить в Map элементы любого типа.
• clear() void – Map
• containsKey(Object key) boolean – Map
• containsValue(Object value) boolean – Map
• entrySet() Set – Map
• equals(Object o) boolean – Map
• get(Object key) Object – Map
• getClass() Class<? extends Object> – Object
• hashCode() int – Map
• isEmpty() boolean – Map
• keySet() Set – Map
• notify() void – Object
• notifyAll() void – Object
• put(Object key, Object value) Object – Map
• putAll(Map t) void – Map
• remove(Object key) Object – Map
• size() int – Map
• toString() String – Object
• values() Collection – Map
• wait() void – Object
• wait(long timeout) void – Object
• wait(long timeout, int nanos) void – Object
Рис. 8.1. Методы Map
Если в приложении требуется контейнер Map с элементами Sensor, его можно создать следующим образом:
Map sensors = new HashMap();
Когда другой части кода понадобится обратиться к элементу, мы видим код следующего вида:
Sensor s = (Sensor)sensors.get(sensorId );
Причем видим его не только в этом месте, но снова и снова по всему коду. Клиент кода несет ответственность за получение Object из Map и его приведение к правильному типу. Такое решение работает, но «чистым» его не назовешь. Кроме того, этот код не излагает свою историю, как ему положено. Удобочитаемость кода можно было бы заметно улучшить при помощи шаблонов (параметризованных контейнеров):
Map<Sensor> sensors = new HashMap<Sensor>();
...
Sensor s = sensors.get(sensorId );
Но и такая реализация не решает проблемы: Map<Sensor> предоставляет намного больше возможностей, чем нам хотелось бы.
Свободная передача Map<Sensor> по системе означает, что в случае изменения интерфейса Map исправления придется вносить во множестве мест. Казалось бы, такие изменения маловероятны, но вспомните, что интерфейс изменился при добавлении поддержки шаблонов в Java 5. В самом деле, мы видели системы, разработчики которых воздерживались от использования шаблонов из-за большого количества потенциальных изменений, связанных с частым использованием Map.
Ниже представлен другой, более чистый вариант использования Map. С точки зрения пользователя Sensors совершенно не важно, используются шаблоны или нет. Это решение стало (и всегда должно быть) подробностью реализации.
public class Sensors {
private Map sensors = new HashMap();
public Sensor getById(String id) {
return (Sensor) sensors.get(id);
}
//...
}
Граничный интерфейс (Map) скрыт от пользователя. Он может развиваться независимо, практически не оказывая никакого влияния на остальные части приложения. Применение шаблонов уже не создает проблем, потому что все преобразования типов выполняются в классе Sensors.
Этот интерфейс также приспособлен и ограничен в соответствии с потребностями приложения. Код становится более понятным, а возможности злоупотреблений со стороны пользователя сокращаются. Класс Sensors может обеспечивать выполнение архитектурных требований и требований бизнес-логики.
Поймите правильно: мы не предлагаем инкапсулировать каждое применение Map в этой форме. Скорее, мы рекомендуем ограничить передачу Map (или любого другого граничного интерфейса) по системе. Если вы используете граничный интерфейс вроде Map, держите его внутри класса (или тесно связанного семейства классов), в которых он используется. Избегайте его возвращения или передачи в аргументах при вызовах методов общедоступных API.
Исследование и анализ границ
Сторонний код помогает нам реализовать больше функциональности за меньшее время. С чего начинать, если мы хотим использовать сторонний пакет? Тестирование чужого кода не входит в наши обязанности, но, возможно, написание тестов для стороннего кода, используемого в наших продуктах, в наших же интересах.
Допустим, вам не ясно, как использовать стороннюю библиотеку. Можно потратить день-два (или более) на чтение документации и принятие решений о том, как работать с библиотекой. Затем вы пишете код, использующий стороннюю библиотеку, и смотрите, делает ли он то, что ожидалось. Далее вы, скорее всего, погрязнете в долгих сеансах отладки, пытаясь разобраться, в чьем коде возникают ошибки – в стороннем или в вашем собственном.
Изучение чужого кода – непростая задача. Интеграция чужого кода тоже сложна. Одновременное решение обоих задач создает двойные сложности. А что, если пойти по другому пути? Вместо того чтобы экспериментировать и опробовать новую библиотеку в коде продукта, можно написать тесты, проверяющие наше понимание стороннего кода. Джим Ньюкирк ( Jim Newkirk) называет такие тесты «учебными тестами» [BeckTDD, pp. 136–137].
В учебных тестах мы вызываем методы стороннего API в том виде, в котором намереваемся использовать их в своем приложении. Фактически выполняется контролируемый эксперимент, проверяющий наше понимание стороннего API. Основное внимание в тестах направлено на то, чего мы хотим добиться при помощи API.
Изучение log4j
Допустим, вместо того чтобы писать специализированный журнальный модуль, мы хотим использовать пакет apache log4j. Мы загружаем пакет и открываем страницу вводной документации. Не особенно вчитываясь в нее, мы пишем свой первый тестовый сценарий, который, как предполагается, будет выводить на консоль строку «hello».
@Test
public void testLogCreate() {
Logger logger = Logger.getLogger("MyLogger");
logger.info("hello");
}
При запуске журнальный модуль выдает ошибку. В описании ошибки говорится, что нам понадобится нечто под названием Appender. После непродолжительных поисков в документации обнаруживается класс ConsoleAppender. Соответственно, мы создаем объект ConsoleAppender и проверяем, удалось ли нам раскрыть секреты вывода журнала на консоль:
@Test
public void testLogAddAppender() {
Logger logger = Logger.getLogger("MyLogger");
ConsoleAppender appender = new ConsoleAppender();
logger.addAppender(appender);
logger.info("hello");
}
На этот раз выясняется, что у объекта Appender нет выходного потока. Странно – логика подсказывает, что он должен быть. После небольшой помощи от Google опробуется следующее решение:
@Test
public void testLogAddAppender() {
Logger logger = Logger.getLogger("MyLogger");
logger.removeAllAppenders();
logger.addAppender(new ConsoleAppender(
new PatternLayout("%p %t %m%n"),
ConsoleAppender.SYSTEM_OUT));
logger.info("hello");
}
Заработало; на консоли выводится сообщение со словом «hello»! На первый взгляд происходящее выглядит немного странно: мы должны указывать ConsoleAppender, что данные выводятся на консоль.
Еще интереснее, что при удалении аргумента ConsoleAppender.SystemOut сообщение «hello» все равно выводится. Но если убрать аргумент PatternLayout, снова начинаются жалобы на отсутствие выходного потока. Все это выглядит очень странно.
После более внимательного чтения документации мы видим, что конструктор ConsoleAppender по умолчанию «не имеет конфигурации» – весьма неочевидное и бесполезное решение. Похоже, это ошибка (или по крайней мере нелогичность) в log4j.
После некоторых поисков, чтения документации и тестирования мы приходим к листингу 8.1. Попутно мы получили много полезной информации о том, как работает log4j, и закодировали ее в наборе простых модульных тестов.
Листинг 8.1. LogTest.java
public class LogTest {
private Logger logger;
@Before
public void initialize() {
logger = Logger.getLogger("logger");
logger.removeAllAppenders();
Logger.getRootLogger().removeAllAppenders();
}
@Test
public void basicLogger() {
BasicConfigurator.configure();
logger.info("basicLogger");
}
@Test
public void addAppenderWithStream() {
logger.addAppender(new ConsoleAppender(
new PatternLayout("%p %t %m%n"),
ConsoleAppender.SYSTEM_OUT));
logger.info(“addAppenderWithStream”);
}
@Test
public void addAppenderWithoutStream() {
logger.addAppender(new ConsoleAppender(
new PatternLayout("%p %t %m%n")));
logger.info("addAppenderWithoutStream");
}
}
Теперь мы знаем, как инициализировать простейший консольный вывод и можем воплотить эти знания в специализированном журнальном классе, чтобы изолировать остальной код приложения от граничного интерфейса log4j.
Учебные тесты: выгоднее, чем бесплатно
Учебные тесты не стоят ничего. API все равно приходится изучать, а написание тестов является простым способом получения необходимой информации, в изоляции от рабочего кода. Учебные тесты были точно поставленными экспериментами, которые помогли нам расширить границы своего понимания.
Учебные тесты не просто бесплатны – они приносят дополнительную прибыль. При выходе новых версий сторонних пакетов вы сможете провести учебные тесты и выяснить, не изменилось ли поведение пакета.
Учебные тесты позволяют убедиться в том, что сторонние пакеты, используемые в коде, работают именно так, как мы ожидаем. Нет никаких гарантий, что сторонний код, интегрированный в наши приложения, всегда будет сохранять совместимость. Например, авторы могут изменить код в соответствии с какими-то новыми потребностями. Изменения также могут происходить из-за исправления ошибок и добавления новых возможностей. Выход каждой новой версии сопряжен с новым риском. Если в стороннем пакете появятся изменения, несовместимые с нашими тестами, мы сразу узнаем об этом.
Впрочем, независимо от того, нужна ли вам учебная информация, получаемая в ходе тестирования, в системе должна существовать четкая граница, которая поддерживается группой исходящих тестов, использующих интерфейс по аналогии с кодом продукта. Без граничных тестов, упрощающих процесс миграции, у нас появляются причины задержаться на старой версии дольше необходимого.
Использование несуществующего кода
Также существует еще одна разновидность границ, отделяющая известное от неизвестного. В коде часто встречаются места, в которых мы не располагаем полной информацией. Иногда то, что находится на другой стороне границы, остается неизвестным (по крайней мере в данный момент). Иногда мы намеренно не желаем заглядывать дальше границы.
Несколько лет назад я работал в группе, занимавшейся разработкой программного обеспечения для системы радиосвязи. В нашем продукте была подсистема «Передатчик», о которой мы почти ничего не знали, а люди, ответственные за разработку этой подсистемы, еще не дошли до определения своего интерфейса. Мы не хотели простаивать и поэтому начали работать подальше от неизвестной части кода.
Мы неплохо представляли себе, где заканчивалась наша зона ответственности и начиналась чужая территория. В ходе работы мы иногда наталкивались на границу. Хотя туманы и облака незнания скрывали пейзаж за границей, в ходе работы мы начали понимать, каким должен быть граничный интерфейс. Передатчику должны были отдаваться распоряжения следующего вида:
Настроить передатчик на заданную частоту и отправить аналоговое представление данных, поступающих из следующего потока.
Мы тогда понятия не имели, как это будет делаться, потому что API еще не был спроектирован. Поэтому подробности было решено отложить на будущее.
Чтобы не останавливать работу, мы определили собственный интерфейс с броским именем Transmitter. Интерфейс содержал метод transmit, которому при вызове передавались частота и поток данных. Это был тот интерфейс, который нам хотелось бы иметь.
У этого интерфейса было одно важное достоинство: он находился под нашим контролем. В результате клиентский код лучше читался, а мы в своей работе могли сосредоточиться на том, чего стремились добиться.
На рис. 8.2 мы видим, что классы CommunicationsController отделены от API передатчика (который находился вне нашего контроля и оставался неопределенным). Использование конкретного интерфейса нашего приложения позволило сохранить чистоту и выразительность кода CommunicationsController. После того как другая группа определила API передатчика, мы написали класс TransmitterAdapter для «наведения мостов». АДАПТЕР инкапсулировал взаимодействие с API и создавал единое место для внесения изменений в случае развития API.
Такая архитектура также создает в коде очень удобный «стык» для тестирования. Используя подходящий FakeTransmitter, мы можем тестировать классы CommunicationsController. Кроме того, сразу же после появления TransmitterAPI можно создать граничные тесты для проверки правильности использования API.
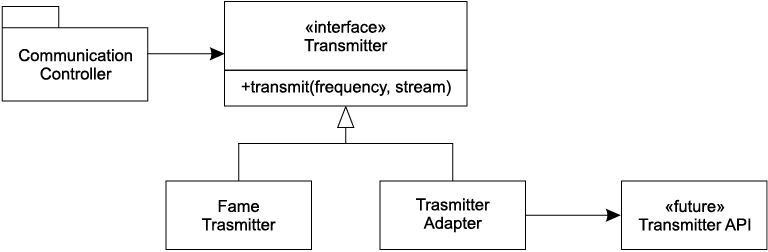
Рис. 8.2. Прогнозирование интерфейса передатчика
Чистые границы
На границах происходит много интересного. В частности, стоит уделить особое внимание изменениям. В хорошей программной архитектуре внесение изменений обходится без значительных затрат и усилий по переработке. Если в продукте используется код, находящийся вне нашего контроля, примите особые меры по защите капиталовложений и позаботьтесь о том, чтобы будущие изменения обходились не слишком дорого.
Для граничного кода необходимо четкое разделение сторон и тесты, определяющие ожидания пользователя. Постарайтесь, чтобы ваш код поменьше знал о специфических подробностях реализации стороннего кода. Лучше зависеть от того, что находится под вашим контролем, чем от тех факторов, которые вы не контролируете (а то, чего доброго, они начнут контролировать вас).
Чтобы границы со сторонним кодом не создавали проблем в наших проектах, мы сводим к минимуму количество обращений к ним. Для этого можно воспользоваться обертками, как в примере с Map, или реализовать паттерн АДАПТЕР для согласования нашего идеального интерфейса с реальным, полученным от разработчиков. В обоих вариантах код становится более выразительным, обеспечивается внутренняя согласованность обращений через границы, а изменение стороннего кода требует меньших затрат на сопровождение.
Литература
[BeckTDD]: Test Driven Development, Kent Beck, Addison-Wesley, 2003.
[GOF]: Design Patterns: Elements of Reusable Object Oriented Software, Gamma et al., Addison-Wesley, 1996.
[WELC]: Working Effectively with Legacy Code, Addison-Wesley, 2004.
1 См. описание паттерна АДАПТЕР в [GOF].

