5. Форматирование

Мы хотим, чтобы читатель, заглянувший «под капот» программы, был поражен увиденным — нашей аккуратностью, логичностью и вниманием к мелочам. Мы хотим, чтобы на него произвела впечатление стройность кода. Мы хотим, чтобы он уважительно поднял брови при просмотре модулей. Мы хотим, чтобы наша работа выглядела профессионально. Если вместо этого читатель видит беспорядочную массу кода, словно написанного шайкой пьяных матросов, то он заключит, что такое же неуважение к мелочам проникло и во все остальные аспекты проекта.
Вы должны позаботиться о том, чтобы ваш код был хорошо отформатирован. Выберите набор простых правил, определяющих формат кода, и последовательно применяйте их в своей работе. Если вы работаете в составе группы, то группа должна выработать согласованный набор правил форматирования, соблюдаемых всеми участниками. Также полезно иметь средства автоматизации, которые применяют правила форматирования за вас.
Цель форматирования
Прежде всего я твердо заявляю: форматирование кода важно. Оно слишком важно, чтобы не обращать на него внимания, и слишком важно, чтобы относиться к нему с религиозным пылом. Форматирование кода направлено на передачу информации, а передача информации является первоочередной задачей профессионального разработчика.
Возможно, вы думали, что первоочередная задача профессионального разработчика – «сделать так, чтобы программа заработала». Надеюсь, к этому моменту книга уже заставила вас отказаться от этих представлений. Функциональность, созданная сегодня, вполне может измениться в следующей версии, но удобочитаемость вашего кода окажет сильное воздействие на все изменения, которые когда-либо будут внесены. Стиль кодирования и удобочитаемость создают прецеденты, которые продолжают влиять на сопровождаемость и расширяемость кода уже после того, как исходный код изменился до неузнаваемости. Стиль и дисциплина программирования продолжают жить, даже если ваш код остался в прошлом. Так какие же аспекты форматирования помогают нам лучше передать свои мысли?
Вертикальное форматирование
Начнем с вертикальных размеров. Насколько большим должен быть исходный файл? В Java размер файла тесно связан с размером класса. Мы поговорим о размерах классов, когда речь пойдет о классах, а пока давайте займемся размером файлов.
Насколько большими должны быть исходные файлы Java? Оказывается, существует широчайший диапазон размеров и весьма заметные различия в стиле. Некоторые из этих различий показаны на рис. 5.1.
На рисунке изображены семь разных проектов: Junit, FitNesse, TestNG, Time and Money (Tam), JDepend, Ant и Tomcat. Отрезки, проходящие через прямоугольники, показывают минимальную и максимальную длину файла в каждом проекте. Прямоугольник изображает приблизительно одну треть (стандартное отклонение) от диапазона длин файлов. Середина прямоугольника соответствует среднему арифметическому. Таким образом, средний размер файла в проекте FitNesse составляет около 65 строк, а около трети файлов имеет размер от 40 до 100+ строк. Наибольший файл FitNesse занимает около 400 строк, а наименьший — всего 6 строк. Обратите внимание: на графике используется логарифмическая шкала, поэтому незначительные изменения в вертикальной координате подразумевают очень большие изменения в абсолютном размере.
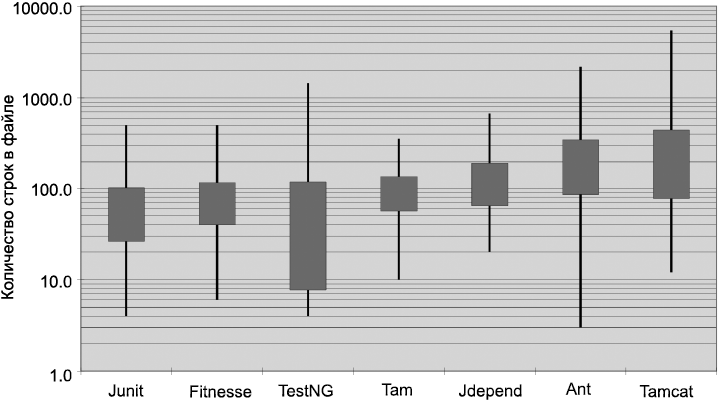
Рис. 5.1. Распределение длин файлов по логарифмической шкале (высота прямоугольника = сигма)
Junit, FitNesse и Time and Money состоят из относительно небольших файлов. Ни один размер файла не превышает 500 строк, а большинство файлов не превышает 200 строк. Напротив, в Tomcat и Ant встречаются файлы из нескольких тысяч строк, а около половины имеет длину более 200 строк.
Что это означает для нас? То, что достаточно серьезную систему (объем FitNesse приближается к 50 000 строк) можно построить из файлов, типичная длина которых составляет 200 строк, с верхним пределом в 500 строк. Хотя это не должно считаться раз и навсегда установленным правилом, такие показатели весьма желательны. Маленькие файлы обычно более понятны, чем большие.
Газетная метафора
Представьте себе хорошо написанную газетную статью. Естественно, статья читается по вертикали. В самом начале обычно располагается заголовок с общей темой статьи; он помогает вам решить, представляет ли статья интерес для вас. В первом абзаце приводится краткое изложение сюжета на уровне общих концепций, без приведения каких-либо подробностей. По мере продвижения к концу статьи объем детализации непрерывно растет, пока вы не узнаете все даты, имена, цитаты и т.д.
Исходный файл должен выглядеть как газетная статья. Имя файла должно быть простым, но содержательным. Одного имени должно быть достаточно для того, чтобы читатель понял, открыл ли он нужный модуль или нет. Начальные блоки исходного файла описывают высокоуровневые концепции и алгоритмы. Степень детализации увеличивается при перемещении к концу файла, а в самом конце собираются все функции и подробности низшего уровня в исходном файле.
Газета состоит из множества статей, в большинстве своем очень коротких. Другие статьи чуть длиннее. И лишь немногие статьи занимают всю газетную страницу. Собственно, именно этим газеты так удобны. Если бы они состояли из одной длинной статьи с неупорядоченной подборкой фактов, дат и имен, то мы бы просто не смогли их читать.
Вертикальное разделение концепций
Практически весь код читается слева направо и сверху вниз. Каждая строка представляет выражение или условие, а каждая группа строк представляет законченную мысль. Эти мысли следует отделять друг от друга пустыми строками.
Для примера возьмем листинг 5.1. Объявление пакета, директива(-ы) импорта и все функции разделяются пустыми строками. Это чрезвычайно простое правило оказывает глубокое воздействие на визуальную структуру кода. Каждая пустая строка становится зрительной подсказкой, указывающей на начало новой самостоятельной концепции. В ходе просмотра листинга ваш взгляд привлекает первая строка, следующая за пустой строкой.
Листинг 5.1. BoldWidget.java
package fitnesse.wikitext.widgets;
import java.util.regex.*;
public class BoldWidget extends ParentWidget {
public static final String REGEXP = "'''.+?'''";
private static final Pattern pattern = Pattern.compile("'''(.+?)'''",
Pattern.MULTILINE + Pattern.DOTALL
};
public BoldWidget(ParentWidget parent, String text) throws Exception {
super(parent);
Matcher match = pattern.matcher(text);
match.find();
addChildWidgets(match.group(1));
}
Листинг 5.1 (продолжение)
public String render() throws Exception {
StringBuffer html = new StringBuffer("<b>");
html.append(childHtml()).append("</b>");
return html.toString();
}
}
Удаление пустых строк, как в листинге 5.2, имеет весьма тяжелые последствия для удобочитаемости кода.
Листинг 5.2. BoldWidget.java
package fitnesse.wikitext.widgets;
import java.util.regex.*;
public class BoldWidget extends ParentWidget {
public static final String REGEXP = "'''.+?'''";
private static final Pattern pattern = Pattern.compile("'''(.+?)'''",
Pattern.MULTILINE + Pattern.DOTALL);
public BoldWidget(ParentWidget parent, String text) throws Exception {
super(parent);
Matcher match = pattern.matcher(text);
match.find();
addChildWidgets(match.group(1));}
public String render() throws Exception {
StringBuffer html = new StringBuffer("<b>");
html.append(childHtml()).append("</b>");
return html.toString();
}
}
Эффект становится еще более заметным, если на секунду отвести глаза от листинга. В первом примере группировка строк сразу бросается в глаза, а второй пример выглядит как сплошная каша, притом что два листинга различаются только вертикальными разделителями.
Вертикальное сжатие
Если вертикальные пропуски разделяют концепции, то вертикальное сжатие подчеркивает тесные связи. Таким образом, строки кода, между которыми существует тесная связь, должны быть «сжаты» по вертикали. Обратите внимание на то, как бесполезные комментарии в листинге 5.3 нарушают группировку двух переменных экземпляров.
Листинг 5.3
public class ReporterConfig {
/**
* Имя класса слушателя
*/
private String m_className;
/**
* Свойства слушателя
*/
private List<Property> m_properties = new ArrayList<Property>();
public void addProperty(Property property) {
m_properties.add(property);
}
Листинг 5.4 читается гораздо проще. Он нормально воспринимается «с одного взгляда» — по крайней мере, для меня. Я смотрю на него и сразу вижу, что передо мной класс с двумя переменными и одним методом; для этого мне не приходится вертеть головой или бегать по строчкам глазами. В предыдущем листинге для достижения того же уровня понимания приходится потрудиться намного больше.
Листинг 5.4
public class ReporterConfig {
private String m_className;
private List<Property> m_properties = new ArrayList<Property>();
public void addProperty(Property property) {
m_properties.add(property);
}
Вертикальные расстояния
Вам когда-нибудь доводилось метаться по классу, прыгая от одной функции к другой, прокручивая исходный файл вверх-вниз, пытаясь разобраться, как функции связаны друг с другом и как они работают, — только для того, чтобы окончательно заблудиться в его запутанных нагромождениях? Когда-нибудь искали определение функции или переменной по цепочкам наследования? Все это крайне неприятно, потому что вы стараетесь понять, как работает система, а вместо этого вам приходится тратить время и интеллектуальные усилия на поиски и запоминание местонахождения отдельных фрагментов.
Концепции, тесно связанные друг с другом, должны находиться поблизости друг от друга по вертикали [G10]. Разумеется, это правило не работает для концепций, находящихся в разных файлах. Но тесно связанные концепции и не должны находиться в разных файлах, если только это не объясняется очень вескими доводами. Кстати, это одна из причин, по которой следует избегать защищенных переменных.
Если концепции связаны настолько тесно, что они находятся в одном исходном файле, их вертикальное разделение должно показывать, насколько они важны для понимания друг друга. Не заставляйте читателя прыгать туда-сюда по исходным файлам и классам.
Объявления переменных. Переменные следует объявлять как можно ближе к месту использования. Так как мы имеем дело с очень короткими функциями, локальные переменные должны перечисляться в начале каждой функции, как в следующем примере из Junit 4.3.
private static void readPreferences() {
InputStream is= null;
try {
is= new FileInputStream(getPreferencesFile());
setPreferences(new Properties(getPreferences()));
getPreferences().load(is);
} catch (IOException e) {
try {
if (is != null)
is.close();
} catch (IOException e1) {
}
}
}
Управляющие переменные циклов обычно объявляются внутри конструкции цикла, как в следующей симпатичной маленькой функции из того же источника.
public int countTestCases() {
int count= 0;
for (Test each : tests)
count += each.countTestCases();
return count;
}
В отдельных случаях переменная может объявляться в начале блока или непосредственно перед циклом в длинной функции. Пример такого объявления представлен в следующем фрагменте очень длинной функции из TestNG.
...
for (XmlTest test : m_suite.getTests()) {
TestRunner tr = m_runnerFactory.newTestRunner(this, test);
tr.addListener(m_textReporter);
m_testRunners.add(tr);
invoker = tr.getInvoker();
for (ITestNGMethod m : tr.getBeforeSuiteMethods()) {
beforeSuiteMethods.put(m.getMethod(), m);
}
for (ITestNGMethod m : tr.getAfterSuiteMethods()) {
afterSuiteMethods.put(m.getMethod(), m);
}
}
...
Переменные экземпляров, напротив, должны объявляться в начале класса. Это не увеличивает вертикальное расстояние между переменными, потому что в хорошо спроектированном классе они используются многими, если не всеми, методами класса.
Размещение переменных экземпляров становилось причиной ожесточенных споров. В C++ обычно применялось так называемое правило ножниц, при котором все переменные экземпляров размещаются внизу. С другой стороны, в Java они обычно размещаются в начале класса. Я не вижу причин для использования каких-либо других конвенций. Здесь важно то, что переменные экземпляров должны объявляться в одном хорошо известном месте. Все должны знать, где следует искать объявления.
Для примера рассмотрим странный класс TestSuite из JUnit 4.3.1. Я основательно сократил этот класс, чтобы лучше выразить свою мысль. Где-то в середине листинга вдруг обнаруживаются объявления двух переменных экземпляров. Если бы автор сознательно хотел спрятать их, трудно найти более подходящее место. Читатель кода может наткнуться на эти объявления только случайно (как я).
public class TestSuite implements Test {
static public Test createTest(Class<? extends TestCase> theClass,
String name) {
...
}
public static Constructor<? extends TestCase>
getTestConstructor(Class<? extends TestCase> theClass)
throws NoSuchMethodException {
...
}
public static Test warning(final String message) {
...
}
private static String exceptionToString(Throwable t) {
...
}
private String fName;
private Vector<Test> fTests= new Vector<Test>(10);
public TestSuite() {
}
public TestSuite(final Class<? extends TestCase> theClass) {
...
}
public TestSuite(Class<? extends TestCase> theClass, String name) {
...
}
... ... ... ... ...
}
Зависимые функции. Если одна функция вызывает другую, то эти функции должны располагаться вблизи друг от друга по вертикали, а вызывающая функция должна находиться над вызываемой (если это возможно). Тем самым формируется естественная структура программного кода. Если это правило будет последовательно соблюдаться, читатели кода будут уверены в том, что определения функций следуют неподалеку от их вызовов. Для примера возьмем фрагмент FitNesse из листинга 5.5. Обратите внимание на то, как верхняя функция вызывает нижние, и как они, в свою очередь, вызывают функции более низкого уровня. Такая структура позволяет легко найти вызываемые функции и значительно улучшает удобочитаемость всего модуля.
Листинг 5.5. WikiPageResponder.java
public class WikiPageResponder implements SecureResponder {
protected WikiPage page;
protected PageData pageData;
protected String pageTitle;
protected Request request;
protected PageCrawler crawler;
public Response makeResponse(FitNesseContext context, Request request)
throws Exception {
String pageName = getPageNameOrDefault(request, "FrontPage");
loadPage(pageName, context);
if (page == null)
return notFoundResponse(context, request);
else
return makePageResponse(context);
}
private String getPageNameOrDefault(Request request, String defaultPageName)
{
String pageName = request.getResource();
if (StringUtil.isBlank(pageName))
pageName = defaultPageName;
return pageName;
}
protected void loadPage(String resource, FitNesseContext context)
throws Exception {
WikiPagePath path = PathParser.parse(resource);
crawler = context.root.getPageCrawler();
crawler.setDeadEndStrategy(new VirtualEnabledPageCrawler());
page = crawler.getPage(context.root, path);
if (page != null)
pageData = page.getData();
}
private Response notFoundResponse(FitNesseContext context, Request request)
throws Exception {
return new NotFoundResponder().makeResponse(context, request);
}
private SimpleResponse makePageResponse(FitNesseContext context)
throws Exception {
pageTitle = PathParser.render(crawler.getFullPath(page));
String html = makeHtml(context);
SimpleResponse response = new SimpleResponse();
response.setMaxAge(0);
response.setContent(html);
return response;
}
...
Заодно этот фрагмент дает хороший пример хранения констант на соответствующем уровне [G35]. Константу «FrontPage» можно было бы объявить в функции getPageNameOrDefault, но тогда хорошо известная и ожидаемая константа оказалась бы погребенной в функции неуместно низкого уровня. Лучше переместить эту константу вниз – от того места, где ее следовало бы ввести, к месту ее фактического использования.
Концептуальное родство. Некоторые фрагменты кода требуют, чтобы их разместили вблизи от других фрагментов. Такие фрагменты обладают определенным концептуальным родством. Чем сильнее родство, тем меньше должно быть вертикальное расстояние между ними.

Как мы уже видели, родство может быть основано на прямой зависимости (когда одна функция вызывает другую) или на использовании переменных в функциях. Однако существуют и другие разновидности родства. Например, родство возникает в том случае, если группа функций выполняет аналогичные операции. Возьмем следующий фрагмент кода из Junit 4.3.1:
public class Assert {
static public void assertTrue(String message, boolean condition) {
if (!condition)
fail(message);
}
static public void assertTrue(boolean condition) {
assertTrue(null, condition);
}
static public void assertFalse(String message, boolean condition) {
assertTrue(message, !condition);
}
static public void assertFalse(boolean condition) {
assertFalse(null, condition);
}
...
Эти функции обладают сильным концептуальным родством, потому что они используют единую схему выбора имен и выполняют разные варианты одной базовой операции. Тот факт, что они вызывают друг друга, вторичен. Даже без него эти функции все равно следовало бы разместить поблизости друг от друга.
Вертикальное упорядочение
Как правило, взаимозависимые функции должны размещаться в нисходящем порядке. Иначе говоря, вызываемая функция должна располагаться ниже вызывающей функции. Так формируется логичная структура модуля исходного кода – от высокого уровня к более низкому.
Как и в газетных статьях, читатель ожидает, что самые важные концепции будут изложены сначала, причем с минимальным количеством второстепенных деталей. Низкоуровневые подробности естественно приводить в последнюю очередь. Это позволяет нам бегло просматривать исходные файлы, извлекая суть из нескольких начальных функций, без погружения в подробности. Листинг 5.5 имеет именно такую структуру. Возможно, еще лучшие примеры встречаются в листинге 15.5 на с. 299 и в листинге 3.7 на с. 75.
Горизонтальное форматирование
Насколько широкой должна быть строка? Чтобы ответить на этот вопрос, мы проанализируем ширину строк в типичных программах. Как и в предыдущем случае, будут проанализированы семь разных проектов. На рис. 5.2 показано распределение длин строк во всех семи проектах. Закономерность впечатляет, особенно около 45 символов. Фактически каждый размер от 20 до 60 соответствует примерно одному проценту от общего количества строк. Целых 40 процентов! Возможно, еще 30 процентов составляют строки с длиной менее 10 символов. Помните, что на графике используется логарифмическая шкала, поэтому разброс в области свыше 80 символов очень важен. Программисты явно предпочитают более короткие строки.
Это наводит на мысль, что строки лучше делать по возможности короткими. Установленное Холлеритом старое ограничение в 80 символов выглядит излишне жестким; я ничего не имеют против строк длиной в 100 и даже 120 символов. Но более длинные строки, вероятно, вызваны небрежностью программиста.
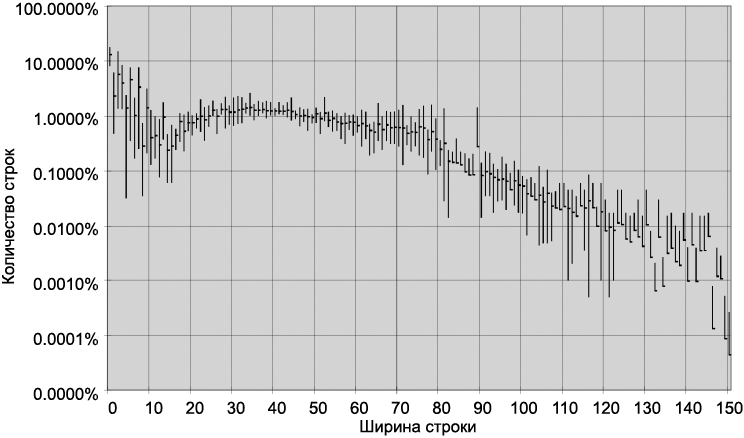
Рис. 5.2. Распределение ширины строк в Java
Прежде я использовал это правило, чтобы мне не приходилось прокручивать программный код вправо. Но современные мониторы стали настолько широкими, а молодые программисты выбирают настолько мелкие шрифты, что на экране помещается до 200 символов. Не делайте этого. Лично я установил себе «верхнюю планку» в 120 символов.
Горизонтальное разделение и сжатие
Горизонтальные пропуски используются для группировки взаимосвязанных элементов и разделения разнородных элементов. Рассмотрим следующую функцию:
private void measureLine(String line) {
lineCount++;
int lineSize = line.length();
totalChars += lineSize;
lineWidthHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
Знаки присваивания окружены пробелами, обеспечивающими их визуальное выделение. Операторы присваивания состоят из двух основных элементов: левой и правой частей. Пробелы наглядно подчеркивают это разделение.
С другой стороны, я не стал отделять имена функций от открывающих скобок. Это обусловлено тем, что имя функции тесно связано с ее аргументами. Пробелы изолируют их вместо того, чтобы объединять. Я также разделил аргументы в скобках пробелами, чтобы выделить запятые и подчеркнуть, что аргументы не зависят друг от друга.
Пробелы также применяются для визуального обозначения приоритета операторов:
public class Quadratic {
public static double root1(double a, double b, double c) {
double determinant = determinant(a, b, c);
return (-b + Math.sqrt(determinant)) / (2*a);
}
public static double root2(int a, int b, int c) {
double determinant = determinant(a, b, c);
return (-b - Math.sqrt(determinant)) / (2*a);
}
private static double determinant(double a, double b, double c) {
return b*b - 4*a*c;
}
}
Обратите внимание, как хорошо читаются формулы. Между множителями нет пробелов, потому что они обладают высоким приоритетом. Слагаемые разделяются пробелами, так как сложение и вычитание имеют более низкий приоритет.
К сожалению, в большинстве программ форматирования кода приоритет операторов не учитывается, и во всех случаях применяются одинаковые пропуски. Нетривиальные изменения расстояний, как в приведенном примере, теряются после переформатирования кода.
Горизонтальное выравнивание
Когда я был ассемблерным программистом, горизонтальное выравнивание использовалось для визуального выделения некоторых структур. Когда я перешел на C, C++, а в конце концов и на Java, я продолжал выравнивать все имена переменных в группах объявлений или все правосторонние значения в группах команд присваивания. Мой код выглядел примерно так:
public class FitNesseExpediter implements ResponseSender
{
private Socket socket;
private InputStream input;
private OutputStream output;
private Request request;
private Response response;
private FitNesseContext context;
protected long requestParsingTimeLimit;
private long requestProgress;
private long requestParsingDeadline;
private boolean hasError;
public FitNesseExpediter(Socket s,
FitNesseContext context) throws Exception
{
this.context = context;
socket = s;
input = s.getInputStream();
output = s.getOutputStream();
requestParsingTimeLimit = 10000;
}
Однако потом я обнаружил, что такое выравнивание не приносит пользы. Оно визуально выделяет совсем не то, что требуется, и отвлекает читателя от моих истинных намерений. Например, в приведенном выше списке объявлений читатель просматривает имена переменных, не обращая внимания на их типы. Аналогичным образом в списке команд присваивания возникает соблазн просмотреть правосторонние значения, не замечая оператора присваивания. Ситуация усугубляется тем, что средства автоматического форматирования обычно удаляют подобное выравнивание.
Поэтому в итоге я отказался от этого стиля форматирования. Сейчас я отдаю предпочтение невыровненным объявлениям и присваиваниям, как в следующем фрагменте, потому что они помогают выявить один важный дефект. Если в программе встречаются длинные списки, нуждающиеся в выравнивании, то проблема кроется в длине списка, а не в отсутствии выравнивания. Длина списков объявлений в классе FitNesseExpediter наводит на мысль, что этот класс необходимо разделить.
public class FitNesseExpediter implements ResponseSender
{
private Socket socket;
private InputStream input;
private OutputStream output;
private Request request;
private Response response;
private FitNesseContext context;
protected long requestParsingTimeLimit;
private long requestProgress;
private long requestParsingDeadline;
private boolean hasError;
public FitNesseExpediter(Socket s, FitNesseContext context) throws Exception
{
this.context = context;
socket = s;
input = s.getInputStream();
output = s.getOutputStream();
requestParsingTimeLimit = 10000;
}
Отступы
Исходный файл имеет иерархическую структуру. В нем присутствует информация, относящаяся к файлу в целом; к отдельным классам в файле; к методам внутри классов; к блокам внутри методов и рекурсивно – к блокам внутри блоков. Каждый уровень этой иерархии образует область видимости, в которой могут объявляться имена и в которой интерпретируются исполняемые команды.
Чтобы создать наглядное представление этой иерархии, мы снабжаем строки исходного кода отступами, размер которых соответствует их позиции в иерархии. Команды уровня файла (такие, как большинство объявлений классов) отступов не имеют. Методы в классах сдвигаются на один уровень вправо от уровня класса. Реализации этих методов сдвигаются на один уровень вправо от объявления класса. Реализации блоков сдвигаются на один уровень вправо от своих внишних блоков и т.д.
Программисты широко используют эту схему расстановки отступов в своей работе. Чтобы определить, к какой области видимости принадлежат строки кода, они визуально группируют строки по левому краю. Это позволяет им быстро пропускать области видимости, не относящиеся к текущей ситуации (например, реализации команд if и while). У левого края ищутся объявления новых методов, новые переменные и даже новые классы. Без отступов программа становится практически нечитаемой для людей. Следующие программы идентичны с синтаксической и семантической точки зрения:
public class FitNesseServer implements SocketServer { private FitNesseContext
context; public FitNesseServer(FitNesseContext context) { this.context =
context; } public void serve(Socket s) { serve(s, 10000); } public void
serve(Socket s, long requestTimeout) { try { FitNesseExpediter sender = new
FitNesseExpediter(s, context);
sender.setRequestParsingTimeLimit(requestTimeout); sender.start(); }
catch(Exception e) { e.printStackTrace(); } } }
-----
public class FitNesseServer implements SocketServer {
private FitNesseContext context;
public FitNesseServer(FitNesseContext context) {
this.context = context;
}
public void serve(Socket s) {
serve(s, 10000);
}
public void serve(Socket s, long requestTimeout) {
try {
FitNesseExpediter sender = new FitNesseExpediter(s, context);
sender.setRequestParsingTimeLimit(requestTimeout);
sender.start();
}
catch (Exception e) {
e.printStackTrace();
}
}
}
Наше зрение быстро охватывает структуру файла с отступами. Мы почти мгновенно находим переменные, конструкторы и методы. Всего за несколько секунд можно понять, что класс предоставляет простой интерфейс для работы с сокетом, с поддержкой тайм-аута. С другой стороны, разобраться в версии без отступов без тщательного анализа практически невозможно.
Нарушения отступов. Иногда возникает соблазн нарушить правила расстановки отступов в коротких командах if, коротких циклах while или коротких функциях. Но каждый раз, когда я поддавался этому искушению, я почти всегда возвращался и расставлял отступы, как положено. Таким образом, я стараюсь не сворачивать блоки в одну строку, как в этом фрагменте:
public class CommentWidget extends TextWidget
{
public static final String REGEXP = "^#[^\r\n]*(?:(?:\r\n)|\n|\r)?";
public CommentWidget(ParentWidget parent, String text){super(parent, text);}
public String render() throws Exception {return ""; }
}
Вместо этого я предпочитаю развернутые блоки с правильными отступами:
public class CommentWidget extends TextWidget {
public static final String REGEXP = "^#[^\r\n]*(?:(?:\r\n)|\n|\r)?";
public CommentWidget(ParentWidget parent, String text) {
super(parent, text);
}
public String render() throws Exception {
return "";
}
}
Вырожденные области видимости
Иногда тело цикла while или команды for не содержит команд, то есть является вырожденным, как в следующем фрагменте. Я не люблю такие структуры и стараюсь избегать их. А когда это невозможно, я по крайней мере слежу за тем, чтобы пустое тело имело правильные отступы и было заключено в фигурные скобки. Вы не представляете, как часто меня обманывала точка с запятой, молчаливо прячущаяся в конце цикла while в той же строке. Если не сделать эту точку хорошо заметной, разместив ее в отдельной строке, ее попросту слишком сложно разглядеть:
while (dis.read(buf, 0, readBufferSize) != -1)
;
Правила форматирования в группах
У каждого программиста есть свои любимые правила форматирования, но если он работает в группе, то должен руководствоваться групповыми правилами.
Группа разработчиков согласует единый стиль форматирования, который в дальнейшем применяется всеми участниками. Код программного продукта должен быть оформлен в едином стиле. Он не должен выглядеть так, словно был написан несколькими личностями, расходящимися во мнениях по поводу оформления.
В начале работы над проектом FitNesse в 2002 году я провел встречу с группой для выработки общего стиля программирования. На это потребовалось около 10 минут. Мы решили, где будем расставлять фигурные скобки, каким будет размер отступов, по какой схеме будут присваиваться имена классов, переменных и методов и т.д. Затем эти правила были закодированы в системе форматирования кода нашей рабочей среды, и в дальнейшем мы неуклонно придерживались их. Это были не те правила, которые предпочитаю лично я; это были правила, выбранные группой. И я, как участник группы, неуклонно соблюдал их при написании кода в проекте FitNesse.
Хорошая программная система состоит из набора удобочитаемых документов, оформленных в едином, согласованном стиле. Читатель должен быть уверен в том, что форматные атрибуты, встречающиеся в одном исходном файле, будут иметь точно такой же смысл в других файлах. Ни в коем случае не усложняйте исходный код, допуская его оформление в нескольких разных стилях.
Правила форматирования от дядюшки Боба
Правила, которые использую лично я, очень просты; они представлены в коде листинга 5.6. Перед вами пример того, как сам код становится лучшим документом, описывающим стандарты кодирования.
Листинг 5.6. CodeAnalyzer.java
public class CodeAnalyzer implements JavaFileAnalysis {
private int lineCount;
private int maxLineWidth;
private int widestLineNumber;
private LineWidthHistogram lineWidthHistogram;
private int totalChars;
public CodeAnalyzer() {
lineWidthHistogram = new LineWidthHistogram();
}
public static List<File> findJavaFiles(File parentDirectory) {
List<File> files = new ArrayList<File>();
findJavaFiles(parentDirectory, files);
return files;
}
private static void findJavaFiles(File parentDirectory, List<File> files) {
for (File file : parentDirectory.listFiles()) {
if (file.getName().endsWith(".java"))
files.add(file);
else if (file.isDirectory())
findJavaFiles(file, files);
}
}
public void analyzeFile(File javaFile) throws Exception {
BufferedReader br = new BufferedReader(new FileReader(javaFile));
String line;
while ((line = br.readLine()) != null)
measureLine(line);
}
private void measureLine(String line) {
lineCount++;
int lineSize = line.length();
totalChars += lineSize;
lineWidthHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
private void recordWidestLine(int lineSize) {
if (lineSize > maxLineWidth) {
maxLineWidth = lineSize;
widestLineNumber = lineCount;
}
}
public int getLineCount() {
return lineCount;
}
public int getMaxLineWidth() {
return maxLineWidth;
}
public int getWidestLineNumber() {
return widestLineNumber;
}
public LineWidthHistogram getLineWidthHistogram() {
return lineWidthHistogram;
}
Листинг 5.6 (продолжение)
public double getMeanLineWidth() {
return (double)totalChars/lineCount;
}
public int getMedianLineWidth() {
Integer[] sortedWidths = getSortedWidths();
int cumulativeLineCount = 0;
for (int width : sortedWidths) {
cumulativeLineCount += lineCountForWidth(width);
if (cumulativeLineCount > lineCount/2)
return width;
}
throw new Error("Cannot get here");
}
private int lineCountForWidth(int width) {
return lineWidthHistogram.getLinesforWidth(width).size();
}
private Integer[] getSortedWidths() {
Set<Integer> widths = lineWidthHistogram.getWidths();
Integer[] sortedWidths = (widths.toArray(new Integer[0]));
Arrays.sort(sortedWidths);
return sortedWidths;
}
}
1 Прямоугольник представляет диапазон «сигма/2» выше и ниже среднего значения. Да, я знаю, что распределение длин файлов не является нормальным, поэтому стандартное отклонение не может считаться математически точным. Но я и не стремлюсь к точности. Я хочу лишь дать представление о происходящем.
Кого я пытаюсь обмануть? Я так и остался ассемблерным программистом. Парня можно разлучить с «металлом», но в душе «металл» все равно живет!

