А. Многопоточность II
Бретт Л. Шухерт
Данное приложение дополняет и углубляет материал главы «Многопоточность», с. 207. Оно написано в виде набора независимых разделов, которые можно читать в произвольном порядке. Чтобы такое чтение было возможно, материал разделов частично перекрывается.
Пример приложения «клиент/сервер»
Представьте простое приложение «клиент/сервер». Сервер работает в режиме ожидания, прослушивая сокет на предмет клиентских подключений. Клиент подключается и отправляет запросы.
Сервер
Ниже приведена упрощенная версия серверного приложения. Полный исходный код примера приводится, начиная со с. 385.
ServerSocket serverSocket = new ServerSocket(8009);
while (keepProcessing) {
try {
Socket socket = serverSocket.accept();
process(socket);
} catch (Exception e) {
handle(e);
}
}
Приложение ожидает подключения, обрабатывает входящее сообщение, а затем снова ожидает следующего клиентского запроса. Код клиента для подключения к серверу выглядит так:
private void connectSendReceive(int i) {
try {
Socket socket = new Socket("localhost", PORT);
MessageUtils.sendMessage(socket, Integer.toString(i));
MessageUtils.getMessage(socket);
socket.close();
} catch (Exception e) {
e.printStackTrace();
}
}
Как работает пара «клиент/сервер»? Как формально описать ее производительность? Следующий тест проверяет, что производительность является «приемлемой»:
@Test(timeout = 10000)
public void shouldRunInUnder10Seconds() throws Exception {
Thread[] threads = createThreads();
startAllThreadsw(threads);
waitForAllThreadsToFinish(threads);
}
Чтобы по возможности упростить пример, я исключил из него подготовительный код (см. «ClientTest.java», с. 387). Тест предполагает, что обработка должна быть завершена за 10 000 миллисекунд.
Перед нами классический пример оценки производительности системы. Система должна завершить обработку серии клиентских запросов за 10 секунд. Если сервер сможет обработать все клиентские запросы за положенное время, то тест пройдет.
А что делать, если тест завершится неудачей? В однопоточной модели практически невозможно как-то ускорить обработку запросов (если не считать реализации цикла опроса событий). Сможет ли многопоточная модель решить проблему? Может, но нам необходимо знать, в какой области расходуется основное время выполнения. Возможны два варианта:
• Ввод/вывод – использование сокета, подключение к базе данных, ожидание подгрузки из виртуальной памяти и т.д.
• Процессор – числовые вычисления, обработка регулярных выражений, уборка мусора и т.д.
В системах время обычно расходуется в обеих областях, но для конкретной операции одна из областей является доминирующей. Если код в основном ориентирован на обработку процессором, то повышение вычислительной мощности способно улучшить производительность и обеспечить прохождение теста. Однако количество процессорных тактов все же ограничено, так что реализация многопоточной модели в процессорно-ориентированных задачах не ускорит их выполнения.
С другой стороны, если значительное время в выполняемом процессе расходуется на операции ввода/вывода, то многопоточная модель способна повысить эффективность работы. Пока одна часть системы ожидает ввода/вывода, другая часть использует время ожидания для выполнения других действий, обеспечивая более эффективное использование процессорного времени.
Реализация многопоточности
Допустим, тест производительности не прошел. Как повысить производительность и обеспечить прохождение теста? Если серверный метод process ориентирован на ввод/вывод, одна из возможных реализаций многопоточной модели выглядит так:
void process(final Socket socket) {
if (socket == null)
return;
Runnable clientHandler = new Runnable() {
public void run() {
try {
String message = MessageUtils.getMessage(socket);
MessageUtils.sendMessage(socket, "Processed: " + message);
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
};
Thread clientConnection = new Thread(clientHandler);
clientConnection.start();
}
Допустим, в результате внесенных изменений тест проходит; задача решена, верно?
Анализ серверного кода
На обновленном сервере тест успешно завершается всего за одну с небольшим секунду. К сожалению, приведенное решение наивно, и оно создает ряд новых проблем.
Сколько потоков может создать наш сервер? Код не устанавливает ограничений, поэтому сервер вполне может столкнуться с ограничениями, установленными виртуальной машиной Java ( JVM). Для многих простых систем этого достаточно. А если система обслуживает огромное количество пользователей в общедоступной сети? При одновременном подключении слишком многих пользователей система «заглохнет».
Но давайте ненадолго отложим проблемы с поведением. Чистота и структура представленного кода тоже оставляют желать лучшего. Какие ответственности возложены на серверный код?
• Управление подключением к сокетам.
• Обработка клиентских запросов.
• Политика многопоточности.
• Политика завершения работы сервера.
К сожалению, все эти ответственности реализуются кодом функции process. Кроме того, код распространяется на несколько разных уровней абстракции. Следовательно, какой бы компактной ни была функция process, ее все равно необходимо разбить на несколько меньших функций.
У серверного кода несколько причин для изменения; следовательно, он нарушает принцип единой ответственности. Чтобы код многопоточной системы оставался чистым, управление потоками должно быть сосредоточено в нескольких хорошо контролируемых местах. Более того, код управления потоками не должен делать ничего другого. Почему? Да хотя бы потому, что отслеживать проблемы многопоточности достаточно сложно и без параллельного отслеживания других проблем, не имеющих ничего общего с многопоточностью.
Если создать отдельный класс для каждой из ответственностей, перечисленных выше (включая управление потоками), то последствия любых последующих изменений стратегии управления потоками затронут меньший объем кода и не будут загрязнять реализацию других обязанностей. Кроме того, такое разбиение упростит тестирование других модулей, так как вам не придется отвлекаться на многопоточные аспекты. Обновленная версия кода:
public void run() {
while (keepProcessing) {
try {
ClientConnection clientConnection = connectionManager.awaitClient();
ClientRequestProcessor requestProcessor
= new ClientRequestProcessor(clientConnection);
clientScheduler.schedule(requestProcessor);
} catch (Exception e) {
e.printStackTrace();
}
}
connectionManager.shutdown();
}
Все аспекты, относящиеся к многопоточности, теперь собраны в объекте clientScheduler. Если в приложении возникнут многопоточные проблемы, искать придется только в одном месте:
public interface ClientScheduler {
void schedule(ClientRequestProcessor requestProcessor);
}
Текущая политика реализуется легко:
public class ThreadPerRequestScheduler implements ClientScheduler {
public void schedule(final ClientRequestProcessor requestProcessor) {
Runnable runnable = new Runnable() {
public void run() {
requestProcessor.process();
}
};
Thread thread = new Thread(runnable);
thread.start();
}
}
Изоляция всего многопоточного кода существенно упрощает внесение любых изменений в политику управления потоками. Например, чтобы перейти на инфраструктуру Java 5 Executor, достаточно написать новый класс и подключить его к существующему коду (листинг А.1).
Листинг А.1. ExecutorClientScheduler.java
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
public class ExecutorClientScheduler implements ClientScheduler {
Executor executor;
public ExecutorClientScheduler(int availableThreads) {
executor = Executors.newFixedThreadPool(availableThreads);
}
public void schedule(final ClientRequestProcessor requestProcessor) {
Runnable runnable = new Runnable() {
public void run() {
requestProcessor.process();
}
};
executor.execute(runnable);
}
}
Заключение
Применение многопоточной модели в этом конкретном примере показывает, как повысить производительность системы, а также демонстрирует методологию проверки изменившейся производительности посредством тестовой инфраструктуры. Сосредоточение всего многопоточного кода в небольшом количестве классов – пример практического применения принципа единой ответственности. В случае многопоточного программирования это особенно важно из-за его нетривиальности.
Возможные пути выполнения
Рассмотрим код incrementValue однострочного метода Java, не содержащего циклов или ветвления:
public class IdGenerator {
int lastIdUsed;
public int incrementValue() {
return ++lastIdUsed;
}
}
Забудем о возможности целочисленного переполнения. Будем считать, что только один программный поток имеет доступ к единственному экземпляру IdGenerator. В этом случае существует единственный путь выполнения с единственным гарантированным результатом:
• Возвращаемое значение равно значению lastIdUsed, и оба значения на одну единицу больше значения lastIdUsed непосредственно перед вызовом метода.
Что произойдет, если мы используем два программных потока, а метод останется неизменным? Какие возможны результаты, если каждый поток вызовет incrementValue по одному разу? Сколько существует возможных путей выполнения? Начнем с результатов (допустим, lastIdUsed начинается со значения 93):
• Поток 1 получает значение 94, поток 2 получает значение 95, значение lastIdUsed равно 95.
• Поток 1 получает значение 95, поток 2 получает значение 94, значение lastIdUsed равно 95.
• Поток 1 получает значение 94, поток 2 получает значение 94, значение lastIdUsed равно 94.
Последний результат выглядит удивительно, но он возможен. Чтобы понять, как образуются эти разные результаты, необходимо разобраться в количестве возможных путей выполнения и в том, как они исполняются виртуальной машиной Java.
Количество путей
Чтобы вычислить количество возможных путей выполнения, начнем со сгенерированного байт-кода. Одна строка кода Java (return ++lastIdUsed;) преобразуется в восемь инструкций байт-кода. Выполнение этих восьми инструкций двумя потоками может перемежаться подобно тому, как перемежаются карты в тасуемой колоде. Хотя в каждой руке вы держите всего восемь карт, количество всевозможных перетасованных комбинаций чрезвычайно велико.
В простом случае последовательности из N команд, без циклов и условных переходов, и T потоков, общее количество возможных путей выполнения будет равно
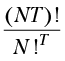 .
.
Вычисление возможных вариантов упорядочения
Из сообщения электронной почты, отправленного Дядюшкой Бобом Бретту:
При N шагов и T потоков общее количество в итоговой последовательности шагов равно T * N. Перед каждым шагом происходит переключение контекста, в ходе которого производится выбор между T потоками. Каждый путь может быть представлен в виде последовательности цифр, обозначающей переключение контекстов. Так, для шагов A и B с потоками 1 и 2 возможны шесть путей: 1122, 1212, 1221, 2112, 2121 и 2211. Если использовать в записи обозначения шагов, мы получаем A1B1A2B2, A1A2B1B2, A1A2B2B1, A2A1B1B2, A2A1B2B1 и A2B2A1B1. Для трех потоков последовательность вариантов имеет вид 112233, 112323, 113223, 113232, 112233, 121233, 121323, 121332, 123132, 123123, . . . .
Одно из свойств этих строк заключается в том, что каждый поток должен присутствовать в строке в N экземплярах. Таким образом, строка 111111 невозможна, потому что она содержит шесть экземпляров 1 и нуль экземпляров 2 и 3.
Итак, нам нужно сгенерировать перестановки из N цифр 1, N цифр 2… и N цифр T. Искомое число равно числу перестановок из N * T объектов, то есть (N * T)!, но с удалением всех дубликатов. Таким образом, задача заключается в том, чтобы подсчитать дубликаты и вычесть их количество из (N * T )!.
Сколько дубликатов содержит серия для двух шагов и двух потоков? Каждая строка из четырех цифр состоит из двух 1 и двух 2. Цифры каждой пары можно поменять местами без изменения смысла строки. Мы можем переставить две цифры 1 и/или две цифры 2. Таким образом, каждая строка существует в четырех изоморфных версиях; это означает, что у каждой строки имеются три дубликата. Три варианта из четырех повторяются, то есть только одна перестановка из четырех НЕ ЯВЛЯЕТСЯ дубликатом. 4! * 0.25 = 6. Похоже, наша схема рассуждений работает.
Как вычислить количество дубликатов в общем случае? Для N = 2 и T = 2 можно переставить 1 и/или 2. Для N = 2 и T = 3 можно переставить 1, 2, 3, 1 и 2, 1 и 3 или 2 и 3. Количество вариантов равно количеству перестановок N. Допустим, существует P разных перестановок N. Количество разных вариантов размещения этих перестановок равно P**T.
Таким образом, количество возможных изоморфных версий равно N!**T. Соответственно, количество путей равно (T*N)!/(N!**T). Для исходного случая T = 2, N = 2 мы получаем 6 (24/4).
Для N = 2 и T = 3 количество путей равно 720/8 = 90.
Для N = 3 и T = 3 получается 9!/6^3 = 1680.
В простейшем случае с одной строкой кода Java, эквивалентной восьми инструкциям байт-кода, и двумя программными потоками общее количество возможных путей выполнения равно 12 870. Если переменная lastIdUsed будет относиться к типу long, то каждая операция чтения/записи преобразуется в две инструкции вместо одной, а количество путей выполнения достигает 2,704,156.
Что произойдет, если внести в метод единственное одно изменение?
public synchronized void incrementValue() {
++lastIdUsed;
}
В этом случае количество возможных путей выполнения сократится до 2 для 2 потоков или до N! в общем случае.
Копаем глубже
А как же удивительный результат, когда два потока вызывают метод по одному разу (до добавления synchronized), получая одинаковое число? Как такое возможно? Начнем с начала.
Атомарной операцией называется операция, выполнение которой не может быть прервано. Например, в следующем коде строка 5, где переменной lastid присваивается значение 0, является атомарной операцией, поскольку в соответствии с моделью памяти Java присваивание 32-разрядного значения прерываться не может.
01: public class Example {
02: int lastId;
03:
04: public void resetId() {
05: value = 0;
06: }
07:
08: public int getNextId() {
09: ++value;
10: }
11:}
Что произойдет, если изменить тип lastId с int на long? Останется ли строка 5 атомарной? В соответствии со спецификацией JVM – нет. Она может выполняться как атомарная операция на конкретном процессоре, но по спецификации JVM присваивание 64-разрядной величины требует двух 32-разрядных присваивания. Это означает, что между первым и вторым 32-разрядным присваиванием другой поток может вмешаться и изменить одно из значений.
А оператор префиксного увеличения ++ в строке 9? Выполнение этого оператора может быть прервано, поэтому данная операция не является атомарной. Чтобы понять, как это происходит, мы подробно проанализируем байт-код обоих методов.
Прежде чем двигаться дальше, необходимо усвоить ряд важных определений:
Кадр (frame) – для каждого вызова метода создается кадр с адресом возврата, значениями всех передаваемых параметров и локальных переменных, определяемых в методе. Это стандартный способ реализации стека вызовов, используемого в современных языках для вызова функций/методов – как обычного, так и рекурсивного.
Локальная переменная – любая переменная, определяемая в области видимости метода. Все нестатические методы содержат как минимум одну переменную this, которая представляет текущий объект, то есть объект, получивший последнее сообщение (в текущем потоке), инициировавшее вызов метода.
Стек операндов – многим инструкциям JVM передаются параметры. Их значения размещаются в стеке операндов, реализованном в виде стандартной структуры данных LIFO (Last-In, First-Out, то есть «последним пришел, первым вышел»).
Байт-код, сгенерированный для resetId(), выглядит так.
| Мнемоника | Описание | Состояние стека операндов после выполнения |
| ALOAD 0 | Загрузка «нулевой» переменной в стек операндов. Что такое «нулевая» переменная? Это this, текущий объект. При вызове метода получатель сообщения, экземпляр Example, сохраняется в массиве локальных переменных кадра, созданного для вызова метода. Текущий объект всегда является первой сохраняемой переменной для каждого метода экземпляра | this |
| ICONST_0 | Занесение константы 0 в стек операндов | this, 0 |
| PUTFIELD lastId | Сохранение верхнего значения из стека (0) в поле объекта, который задается ссылкой, хранящейся на один элемент ниже вершины стека (this) | <пусто> |
Эти три инструкции заведомо атомарны. Хотя программный поток, в котором они выполняются, может быть прерван после выполнения любой инструкции, данные инструкции PUTFIELD (константа 0 на вершине стека и ссылка на this в следующем элементе, вместе со значением поля value) не могут быть изменены другим потоком. Таким образом, при выполнении присваивания в поле value будет гарантированно сохранено значение 0. Операция является атомарной. Все операнды относятся к информации, локальной для данного метода, что исключает нежелательное вмешательство со стороны других потоков.
Итак, если эти три инструкции выполняются десятью потоками, существует 4.38679733629e+24 возможных путей выполнения. Так как в данном случае возможен только один результат, различия в порядке выполнения несущественны. Так уж вышло, что одинаковый результат гарантирован в этой ситуации и для long. Почему? Потому что все десять потоков присваивают одну и ту же константу. Даже если их выполнение будет чередоваться, результат не изменится.
Но с операцией ++ в методе getNextId возникают проблемы. Допустим, в начале метода поле lastId содержит значение 42. Байт-код нового метода выглядит так.
| Мнемоника | Описание | Состояние стека операндов после выполнения |
| ALOAD 0 | Загрузка this в стек операндов | this |
| DUP | Копирование вершины стека. Теперь в стеке операндов хранятся две копии this | this, this |
| GETFIELD lastID | Загрузка значения поля lastId объекта, ссылка на который хранится в вершине стека (this), и занесение загруженного значения в стек | this, 42 |
| ICONST_1 | Занесение константы 1 в стек | this, 42, 1 |
| IADD | Целочисленное сложение двух верхних значений в стеке операндов. Результат сложения также сохраняется в стеке операндов | this, 43 |
| DUP_X1 | Копирование значения 43 и сохранение копии в стеке перед this | 43, this, 43 |
| PUTFIELD value | Сохранение верхнего значения из стека (43) в поле value текущего объекта, который задается ссылкой, хранящейся на один элемент ниже вершины стека (this) | 43 |
| IRETURN | Возвращение верхнего (и единственного) элемента стека | <пусто> |
Представьте, что первый поток выполняет первые три инструкции (до GETFIELD включительно), а потом прерывается. Второй поток получает управление и выполняет весь метод, увеличивая lastId на 1; он получает значение 43. Затем первый поток продолжает работу с того места, на котором она была прервана; значение 42 все еще хранится в стеке операндов, потому что поле lastId в момент выполнения GETFIELD содержало именно это число. Поток увеличивает его на 1, снова получает 43 и сохраняет результат. В итоге первый поток также получает значение 43. В результате одно из двух увеличений теряется, так как первый поток «перекрыл» результат второго потока (после того как второй поток прервал выполнение первого потока).
Проблема решается объявлением метода getNexId() с ключевым словом synchronized.
Заключение
Чтобы понять, как потоки могут «перебегать дорогу» друг другу, не обязательно разбираться во всех тонкостях байт-кода. Приведенный пример наглядно показывает, что программные потоки могут вмешиваться в работу друг друга, и этого вполне достаточно.
Впрочем, даже этот тривиальный пример убеждает в необходимости хорошего понимания модели памяти, чтобы вы знали, какие операции безопасны, а какие – нет. Скажем, существует распространенное заблуждение по поводу атомарности оператора ++ (в префиксной или постфиксной форме), тогда как этот оператор атомарным не является. Следовательно, вы должны знать:
• где присутствуют общие объекты/значения;
• какой код может создать проблемы многопоточного чтения/обновления;
• как защититься от возможных проблем многопоточности.
Знайте свои библиотеки
Executor Framework
Как демонстрирует пример ExecutorClientScheduler.java на с. 361, представленная в Java 5 библиотека Executor предоставляет расширенные средства управления выполнением программ с использованием пулов программных потоков. Библиотека реализована в виде класса в пакете java.util.concurrent.
Если вы создаете потоки, не используя пулы, или используете ручную реализацию пулов, возможно, вам стоит воспользоваться Executor. От этого ваш код станет более чистым, понятным и компактным.
Инфраструктура Executor создает пул потоков с автоматическим изменением размера и повторным созданием потоков при необходимости. Также поддерживаются фьючерсы – стандартная конструкция многопоточного программирования. Библиотека Executor работает как с классами, реализующими интерфейс Runnable, так и с классами, реализующими интерфейс Callable. Интерфейс Callable похож на Runnable, но может возвращать результат, а это стандартная потребность в многопоточных решениях.
Фьючерсы удобны в тех ситуациях, когда код должен выполнить несколько независимых операций и дождаться их завершения:
public String processRequest(String message) throws Exception {
Callable<String> makeExternalCall = new Callable<String>() {
public String call() throws Exception {
String result = "";
// Внешний запрос
return result;
}
};
Future<String> result = executorService.submit(makeExternalCall);
String partialResult = doSomeLocalProcessing();
return result.get() + partialResult;
}
В этом примере метод запускает на выполнение объект makeExternalCall, после чего переходит к выполнению других действий. Последняя строка содержит вызов result.get(), который блокирует выполнение вплоть до завершения фьючерса.
Неблокирующие решения
Виртуальная машина Java 5 пользуется особенностями архитектуры современных процессоров, поддерживающих надежное неблокирующее обновление. Для примера возьмем класс, использующий синхронизацию (а следовательно, блокировку) для реализации потоково-безопасного обновления value,
public class ObjectWithValue {
private int value;
public void synchronized incrementValue() { ++value; }
public int getValue() { return value; }
}
В Java 5 для этой цели появился ряд новых классов. AtomicBoolean, AtomicInteger и AtomicReference – всего лишь три примера; есть и другие. Приведенный выше фрагмент можно переписать без использования блокировки в следующем виде:
public class ObjectWithValue {
private AtomicInteger value = new AtomicInteger(0);
public void incrementValue() {
value.incrementAndGet();
}
public int getValue() {
return value.get();
}
}
Хотя эта реализация использует объект вместо примитива и отправляет сообщения (например, incrementAndGet()) вместо ++, по своей производительности этот класс почти всегда превосходит предыдущую версию. Иногда приращение скорости незначительно, но ситуации, в которых он бы работал медленнее, практически не встречаются.
Как такое возможно? Современные процессоры поддерживают операцию, которая обычно называется CAS (Compare and Swap). Эта операция является аналогом оптимистичной блокировки из теории баз данных, тогда как синхронизированная версия является аналогом пессимистичной блокировки.
Ключевое слово synchronized всегда устанавливает блокировку, даже если второй поток не пытается обновлять то же значение. Хотя производительность встроенных блокировок улучшается от версии к версии, они по-прежнему обходятся недешево.
Неблокирующая версия изначально предполагает, что ситуация с обновлением одного значения множественными потоками обычно возникает недостаточно часто для возникновения проблем. Вместо этого она эффективно обнаруживает возникновение таких ситуаций и продолжает повторные попытки до тех пор, пока обновление не пройдет успешно. Обнаружение конфликта почти всегда обходится дешевле установления блокировки, даже в ситуациях с умеренной и высокой конкуренцией.
Как VM решает эту задачу? CAS является атомарной операцией. На логическом уровне CAS выглядит примерно так:
int variableBeingSet;
void simulateNonBlockingSet(int newValue) {
int currentValue;
do {
currentValue = variableBeingSet
} while(currentValue != compareAndSwap(currentValue, newValue));
}
int synchronized compareAndSwap(int currentValue, int newValue) {
if(variableBeingSet == currentValue) {
variableBeingSet = newValue;
return currentValue;
}
return variableBeingSet;
}
Когда метод пытается обновить общую переменную, операция CAS проверяет, что изменяемая переменная все еще имеет последнее известное значение. Если условие соблюдается, то переменная изменяется. Если нет, то обновление не выполняется, потому что другой поток успел ему «помешать». Метод, пытавшийся выполнить обновление (с использованием операции CAS), видит, что изменение не состоялось, и делает повторную попытку.
Потоково-небезопасные классы
Некоторые классы в принципе не обладают потоковой безопасностью. Несколько примеров:
• SimpleDateFormat
• Подключения к базам данных.
• Контейнеры из java.util.
• Сервлеты.
Некоторые классы коллекций содержат отдельные потоково-безопасные методы. Однако любая операция, связанная с вызовом более одного метода, потоково-безопасной не является. Например, если вы не хотите заменять уже существующий элемент HashTable, можно было бы написать следующий код:
if(!hashTable.containsKey(someKey)) {
hashTable.put(someKey, new SomeValue());
}
По отдельности каждый метод потоково-безопасен, однако другой программный поток может добавить значение между вызовами containsKey и put. У проблемы есть несколько решений:
• Установите блокировку HashTable и проследите за тем, чтобы остальные пользователи HashTable делали то же самое (клиентская блокировка):
synchronized(map) {
if(!map.conainsKey(key))
map.put(key,value);
• Инкапсулируйте HashTable в собственном объекте и используйте другой API (серверная блокировка с применением паттерна АДАПТЕР):
public class WrappedHashtable<K, V> {
private Map<K, V> map = new Hashtable<K, V>();
public synchronized void putIfAbsent(K key, V value) {
if (map.containsKey(key))
map.put(key, value);
}
}
• Используйте потоково-безопасные коллекции:
ConcurrentHashMap<Integer, String> map = new ConcurrentHashMap<Integer,
String>();
map.putIfAbsent(key, value);
Для выполнения подобных операций в коллекциях пакета java.util.concurrent предусмотрены такие методы, как putIfAbsent().
Зависимости между методами могут нарушить работу многопоточного кода
Тривиальный пример введения зависимостей между методами:
public class IntegerIterator implements Iterator<Integer>
private Integer nextValue = 0;
public synchronized boolean hasNext() {
return nextValue < 100000;
}
public synchronized Integer next() {
if (nextValue == 100000)
throw new IteratorPastEndException();
return nextValue++;
}
public synchronized Integer getNextValue() {
return nextValue;
}
}
Код, использующий IntegerIterator:
IntegerIterator iterator = new IntegerIterator();
while(iterator.hasNext()) {
int nextValue = iterator.next();
// Действия с nextValue
}
Если этот код выполняется одним потоком, проблем не будет. Но что произойдет, если два потока попытаются одновременно использовать общий экземпляр IngeterIterator в предположении, что каждый поток будет обрабатывать полученные значения, но каждый элемент списка обрабатывается только один раз? В большинстве случаев ничего плохого не произойдет; потоки будут совместно обращаться к списку, обрабатывая элементы, полученные от итератора, и завершат работу при завершении перебора. Но существует небольшая вероятность того, что в конце итерации два потока помешают работе друг друга, один поток выйдет за конечную позицию итератора, и произойдет исключение.
Проблема заключается в следующем: поток 1 проверяет наличие следующего элемента методом hasNext(), который возвращает true. Поток 1 вытесняется потоком 2; последний выдает тот же запрос, и получает тот же ответ true. Поток 2 вызывает метод next(), который возвращает значение, но с побочным эффектом: после него вызов hasNext() возвращает false. Поток 1 продолжает работу. Полагая, что hasNext() до сих пор возвращает true, он вызывает next(). Хотя каждый из отдельных методов синхронизирован, клиент использовал два метода.
Проблемы такого рода очень часто встречаются в многопоточном коде. В нашей конкретной ситуации проблема особенно нетривиальна, потому что она приводит к сбою только при завершающей итерации. Если передача управления между потоками произойдет в строго определенной последовательности, то один из потоков сможет выйти за конечную позицию итератора. Подобные ошибки часто проявляются уже после того, как система пойдет в эксплуатацию, и обнаружить их весьма нелегко.
У вас три варианта:
• Перенести сбои.
• Решить проблему, внося изменения на стороне клиента (клиентская блокировка).
• Решить проблему, внося изменения на стороне сервера, что приводит к дополнительному изменению клиента (серверная блокировка).
Перенесение сбоев
Иногда все удается устроить так, что сбой не приносит вреда. Например, клиент может перехватить исключение и выполнить необходимые действия для восстановления. Откровенно говоря, такое решение выглядит неуклюже. Оно напоминает полуночные перезагрузки, исправляющие последствия утечки памяти.
Клиентская блокировка
Чтобы класс IntegerIterator корректно работал в многопоточных условиях, измените приведенного выше клиента (а также всех остальных клиентов) следующим образом:
IntegerIterator iterator = new IntegerIterator();
while (true) {
int nextValue;
synchronized (iterator) {
if (!iterator.hasNext())
break;
nextValue = iterator.next();
}
doSometingWith(nextValue);
}
Каждый клиент устанавливает блокировку при помощи ключевого слова synchronized. Дублирование нарушает принцип DRY, но оно может оказаться необходимым, если в коде используются инструменты сторонних разработчиков, не обладающие потоковой безопасностью.
Данная стратегия сопряжена с определенным риском. Все программисты, использующие сервер, должны помнить об установлении блокировки перед использованием и ее снятии после использования. Много (очень много!) лет назад я работал над системой, в которой использовалась клиентская блокировка общего ресурса. Ресурс использовался в сотне разных мест по всей кодовой базе. Один несчастный программист забыл установить блокировку в одном из таких мест.
Это была многотерминальная система с разделением времени, на которой выполнялись бухгалтерские программы профсоюза транспортных перевозок Local 705. Компьютер находился в зале с фальшполом и кондиционером за 50 миль к северу от управления Local 705. В управлении десятки операторов вводили данные на терминалах. Терминалы были подключены к компьютеру по выделенным телефонным линиям с полудуплексными модемами на скорости 600 бит/с (это было очень, очень давно).
Примерно раз в день один из терминалов «зависал». Никакие закономерности в сбоях не прослеживались. Зависания не были привязаны ни к конкретным терминалам, ни к конкретному времени. Все выглядело так, словно время зависания и терминал выбирались броском кубика. Иногда целые дни проходили без зависаний.
Поначалу проблема решалась только перезагрузкой, но перезагрузки было трудно координировать. Нам приходилось звонить в управление и просить всех операторов завершить текущую работу на всех терминалах. После этого мы могли отключить питание и перезагрузить систему. Если кто-то выполнял важную работу, занимавшую час или два, зависший терминал попросту простаивал.
Через несколько недель отладки мы обнаружили, что причиной зависания была десинхронизация между счетчиком кольцевого буфера и его указателем. Буфер управлял выводом на терминал. Значение указателя говорило о том, что буфер был пуст, а счетчик утверждал, что буфер полон. Так как буфер был пуст, выводить было нечего; но так как одновременно он был полон, в экранный буфер нельзя было ничего добавить для вывода на экран.
Итак, мы знали, почему зависали терминалы, но было неясно, из-за чего возникает десинхронизация кольцевого буфера. Поэтому мы реализовали обходное решение. Программный код мог прочитать состояние тумблеров на передней панели компьютера (это было очень, очень, очень давно). Мы написали небольшую функцию, которая обнаруживала переключение одного из тумблеров и искала кольцевой буфер, одновременно пустой и заполненный. Обнаружив такой буфер, функция сбрасывала его в пустое состояние. Voila! Зависший терминал снова начинал выводить информацию.
Теперь нам не приходилось перезагружать систему при зависании терминала. Когда нам звонили из управления и сообщали о зависании, мы шли в машинный зал и переключали тумблер.
Конечно, иногда управление работало по выходным, а мы – нет. Поэтому в планировщик была включена функция, которая раз в минуту проверяла состояние всех кольцевых буферов и сбрасывала те из них, которые были одновременно пустыми и заполненными. Зависший терминал начинал работать даже до того, как операторы успевали подойти к телефону.
Прошло несколько недель кропотливого просеивания монолитного ассемблерного кода, прежде чем была обнаружена причина. Мы занялись вычислениями и определили, что частота зависаний статистически соответствует одному незащищенному использованию кольцевого буфера. Оставалось только найти это одно использование. К сожалению, все это было очень давно. В те времена у нас не было функций поиска, перекрестных ссылок или других средств автоматизации. Нам просто приходилось просматривать листинги.
Тогда, холодной зимой 1971 года в Чикаго, я узнал важный урок. Клиентская блокировка — полный отстой.
Серверная блокировка
Дублирование можно устранить внесением следующих изменений в IntegerIterator:
public class IntegerIteratorServerLocked {
private Integer nextValue = 0;
public synchronized Integer getNextOrNull() {
if (nextValue < 100000)
return nextValue++;
else
return null;
}
}
В клиентском коде также вносятся изменения:
while (true) {
Integer nextValue = iterator.getNextOrNull();
if (next == null)
break;
// Действия с nextValue
}
В этом случае мы изменяем API своего класса, чтобы он обладал многопоточной поддержкой. Вместо проверки hasNext() клиент должен выполнить проверку null.
В общем случае серверная блокировка предпочтительна по следующим причинам:
• Она сокращает дублирование кода – клиентская блокировка заставляет каждого клиента устанавливать соответствующую блокировку сервера. Если код блокировки размещается на сервере, клиенты могут использовать объект, не беспокоясь о написании дополнительного кода блокировки.
• Она обеспечивает более высокую производительность – в случае однопоточного развертывания потоково-безопасный сервер можно заменить потоково-небезопасным, устраняя все дополнительные затраты.
• Она снижает вероятность ошибок – в случае клиентской блокировки достаточно всего одному программисту забыть установить блокировку, и работа системы будет нарушена.
• Она определяет единую политику использования – политика сосредоточена в одном месте (на сервере), а не во множестве разных мест (то есть у каждого клиента).
Она сокращает область видимости общих переменных — клиент не знает ни о переменных, ни о том, как они блокируются. Все подробности скрыты на стороне сервера. Если что-то сломается, то количество мест, в которых следует искать причину, сокращается.
Что делать, если серверный код вам неподконтролен?
• Используйте паттерн АДАПТЕР, чтобы изменить API и добавить блокировку:
public class ThreadSafeIntegerIterator {
private IntegerIterator iterator = new IntegerIterator();
public synchronized Integer getNextOrNull() {
if(iterator.hasNext())
return iterator.next();
return null;
}
}
• ИЛИ еще лучше – используйте потоково-безопасные коллекции с расширенными интерфейсами.
Повышение производительности
Допустим, вы хотите выйти в сеть и прочитать содержимое группы страниц по списку URL-адресов. По мере чтения страницы обрабатываются для накопления некоторой статистики. После чтения всех страниц выводится сводный отчет.
Следующий класс возвращает содержимое одной страницы по URL-адресу.
public class PageReader {
//...
public String getPageFor(String url) {
HttpMethod method = new GetMethod(url);
try {
);
String response = method.getResponseBodyAsString();
return response;
} catch (Exception e) {
handle(e);
} finally {
method.releaseConnection();
}
}
}
Следующий класс – итератор, предоставляющий содержимое страниц на основании итератора URL-адресов:
public class PageIterator {
private PageReader reader;
private URLIterator urls;
public PageIterator(PageReader reader, URLIterator urls) {
this.urls = urls;
this.reader = reader;
}
public synchronized String getNextPageOrNull() {
if (urls.hasNext())
getPageFor(urls.next());
else
return null;
}
public String getPageFor(String url) {
return reader.getPageFor(url);
}
}
Экземпляр PageIterator может совместно использоваться разными потоками, каждый из которых использует собственный экземпляр PageReader для чтения и обработки страниц, полученных от итератора.
Обратите внимание: блок synchronized очень мал. Он содержит только критическую секцию, расположенную глубоко внутри PageIterator. Старайтесь синхронизировать как можно меньший объем кода.
Вычисление производительности в однопоточной модели
Выполним некоторые простые вычисления. Для наглядности возьмем следующие показатели:
• Время ввода/вывода для получения страницы (в среднем): 1 секунда.
• Время обработки страницы (в среднем): 0,5 секунды.
• Во время операций ввода/вывода процессор загружен на 0%, а во время обработки – на 100%.
При обработке N страниц в однопоточной модели общее время выполнения составляет 1,5 секунды * N. На рис. А.1 изображен график обработки 13 страниц примерно за 19,5 секунды.

Рис. А.1. Обработка страниц в однопоточной модели
Вычисление производительности в многопоточной модели
Если страницы могут загружаться в произвольном порядке и обрабатываться независимо друг от друга, то для повышения производительности можно воспользоваться многопоточной моделью. Что произойдет, если обработка будет производиться тремя потоками? Сколько страниц удастся обработать за то же время?
Как видно из рис. А.2, многопоточное решение позволяет совмещать процессорно-ориентированную обработку страниц с операциями чтения страниц, ориентированными на ввод/вывод. В идеальном случае это обеспечивало бы полную загрузку процессора: каждое чтение страницы продолжительностью в одну секунду перекрывается с обработкой двух страниц. Таким образом, многопоточная модель обрабатывает две страницы в секунду, что втрое превышает производительность однопоточной модели.
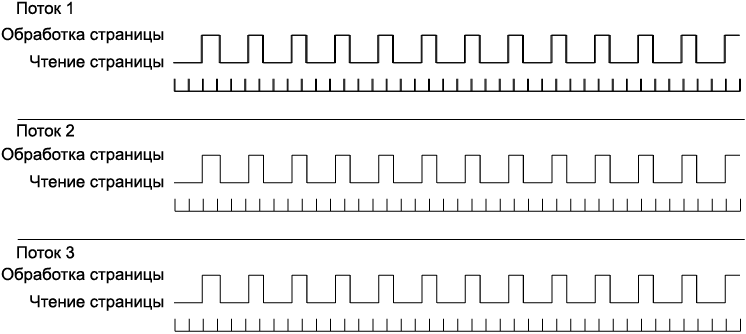
Рис. А.2. Обработка тремя параллельными потоками
Взаимная блокировка
Допустим, у нас имеется веб-приложение с двумя общими пулами ресурсов конечного размера:
• Пул подключений к базе данных для локальной обработки в памяти процесса.
• Пул подключений MQ к главному хранилищу.
В работе приложения используются две операции, создание и обновление:
• Создание – получение подключений к главному хранилищу и базе данных. Взаимодействие с главным хранилищем и локальное сохранение данных в базе данных процесса.
• Обновление – получение подключений к базе данных, а затем к главному хранилищу. Чтение данных из базы данных процесса и их последующая передача в главное хранилище.
Что произойдет, если количество пользователей превышает размеры пулов? Допустим, каждый пул содержит десять подключений.
• Десять пользователей пытаются использовать операцию создания. Они захватывают все десять подключений к базе данных. Выполнение каждого потока прерывается после захвата подключения к базе данных, но до захвата подключения к главному хранилищу.
• Десять пользователей пытаются использовать операцию обновления. Они захватывают все десять подключений к главному хранилищу. Выполнение каждого потока прерывается после захвата подключения к главному хранилищу, но до захвата подключения к базе данных.
• Десять потоков, выполняющих операцию создания, ожидают подключений к главному хранилищу, а десять потоков, выполняющих операцию обновления, ожидают подключений к базе данных.
• Возникает взаимная блокировка. Продолжение работы системы невозможно.
На первый взгляд такая ситуация выглядит маловероятной, но кому нужна система, которая гарантированно зависает каждую неделю? Кому захочется отлаживать систему с такими трудновоспроизводимыми симптомами? Когда такие проблемы возникают в эксплуатируемой системе, на их решение уходят целые недели.
Типичное «решение» основано на включении отладочных команд для получения дополнительной информации о происходящем. Конечно, отладочные команды достаточно сильно изменяют код, взаимная блокировка возникает в другой ситуации, и на повторение ошибки могут потребоваться целые месяцы.
Чтобы действительно решить проблему взаимной блокировки, необходимо понять, из-за чего она возникает. Для возникновения взаимной блокировки необходимы четыре условия:
• Взаимное исключение.
• Блокировка с ожиданием.
• Отсутствие вытеснения.
• Циклическое ожидание.
Взаимное исключение
Взаимное исключение возникает в том случае, когда несколько потоков должны использовать одни и те же ресурсы, и эти ресурсы:
• не могут использоваться несколькими потоками одновременно;
• существуют в ограниченном количестве.
Типичный пример ресурсов такого рода – подключения к базам данных, открытые для записи файлы, блокировки записей, семафоры.
Блокировка с ожиданием
Когда один поток захватывает ресурс, он не освобождает его до тех пор, пока не захватит все остальные необходимые ресурсы и не завершит свою работу.
Отсутствие вытеснения
Один поток не может отнимать ресурсы у другого потока. Если поток захватил ресурс, то другой поток сможет получить захваченный ресурс только в одном случае: если первый поток его освободит.
Циклическое ожидание
Допустим, имеются два потока T1 и T2 и два ресурса R1 и R2. Поток T1 захватил R1, поток T2 захватил R2. Потоку T1 также необходим ресурс R2, а потоку T2 также необходим ресурс R1. Ситуация выглядит так, как показано на рис. А.3.
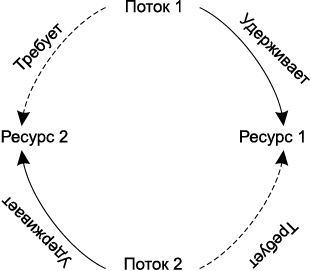
Рис. А.3. Циклическое ожидание
Взаимная блокировка возможна только при соблюдении всех четырех условий. Стоит хотя бы одному из них нарушиться, и взаимная блокировка исчезнет.
Нарушение взаимного исключения
Одна из стратегий предотвращения взаимной блокировки основана на предотвращении состояния взаимного исключения.
• Использование ресурсов, поддерживающих многопоточный доступ (например, AtomicInteger).
• Увеличение количества ресурсов, чтобы оно достигло или превосходило количество конкурирующих потоков.
• Проверка наличия всех свободных ресурсов перед попытками захвата.
К сожалению, большинство ресурсов существует в ограниченном количестве и не поддерживает многопоточное использование. Кроме того, второй ресурс нередко определяется только по результатам обработки первого ресурса. Но не огорчайтесь – остаются еще три условия.
Нарушение блокировки с ожиданием
Вы также можете нарушить взаимную блокировку, если откажетесь ждать. Проверяйте каждый ресурс, прежде чем захватывать его; если какой-либо ресурс занят, освободите все захваченные ресурсы и начните все заново.
При таком подходе возможны следующие потенциальные проблемы:
• Истощение – один поток стабильно не может захватить все необходимые ему ресурсы (уникальная комбинация, в которой все ресурсы одновременно оказываются свободными крайне редко).
• Обратимая блокировка – несколько потоков «входят в клинч»: все они захватывают один ресурс, затем освобождают один ресурс… снова и снова. Такая ситуация особенно вероятна при использовании тривиальных алгоритмов планирования процессорного времени (встроенные системы; простейшие, написанные вручную алгоритмы балансировки потоков).
Обе ситуации могут привести к снижению производительности. Первая ситуация оборачивается недостаточным, а вторая – завышенным и малоэффективным использованием процессора.
Какой бы неэффективной ни казалась эта стратегия, она все же лучше, чем ничего. По крайней мере, вы всегда можете реализовать ее, если все остальные меры не дают результата.
Нарушение отсутствия вытеснения
Другая стратегия предотвращения взаимных блокировок основана на том, чтобы потоки могли отнимать ресурсы у других потоков. Обычно вытеснение реализуется на основе простого механизма запросов. Когда поток обнаруживает, что ресурс занят, он обращается к владельцу с запросом на его освобождение. Если владелец также ожидает другого ресурса, он освобождает все удерживаемые ресурсы и начинает захватывать их заново.
Данное решение сходно с предыдущим, но имеет дополнительное преимущество: поток может ожидать освобождения ресурса. Это снижает количество освобождений и повторных захватов. Но учтите, что правильно реализовать управление запросами весьма непросто.
Нарушение циклического ожидания
Это самая распространенная стратегия предотвращения взаимных блокировок. В большинстве систем она не требует ничего, кроме системы простых правил, соблюдаемых всеми сторонами.
Вспомните приведенный ранее пример с потоком 1, которому необходимы ресурс 1 и ресурс 2, и потоком 2, которому необходимы ресурс 2 и ресурс 1. Заставьте поток 1 и поток 2 выделять ресурсы в постоянном порядке, при котором циклическое ожидание станет невозможным.
В более общем виде, если все потоки согласуют единый глобальный порядок и будут захватывать ресурсы только в указанном порядке, то взаимная блокировка станет невозможной. Эта стратегия, как и все остальные, может создавать проблемы:
• Порядок захвата может не соответствовать порядку использования; таким образом, ресурс, захваченный в начале, может не использоваться до самого конца. В результате ресурсы остаются заблокированными дольше необходимого.
• Соблюдение фиксированного порядка захвата ресурсов возможно не всегда. Если идентификатор второго ресурса определяется на основании операций, выполняемых с первым ресурсом, то эта стратегия становится невозможной.
Итак, существует много разных способов предотвращения взаимных блокировок. Одни приводят к истощению потоков, другие – к интенсивному использованию процессора и ухудшению времени отклика. Бесплатный сыр бывает только в мышеловке!
Изоляция потокового кода вашего решения упрощает настройку и эксперименты; к тому же это действенный способ сбора информации, необходимой для определения оптимальных стратегий.
Тестирование многопоточного кода
Как написать тест, демонстрирующий некорректность многопоточного кода?
01: public class ClassWithThreadingProblem {
02: int nextId;
03:
04: public int takeNextId() {
05: return nextId++;
06: }
07:}
Тест, доказывающий некорректность, может выглядеть так:
• Запомнить текущее значение nextId.
• Создать два потока, каждый из которых вызывает takeNextId() по одному разу.
• Убедиться в том, что значение nextId на 2 больше исходного.
• Выполнять тест до тех пор, пока в ходе очередного теста nextId не увеличится только на 1 вместо 2.
Код такого теста представлен в листинге А.2.
Листинг А.2. ClassWithThreadingProblemTest.java
01: package example;
02:
03: import static org.junit.Assert.fail;
04:
05: import org.junit.Test;
06:
07: public class ClassWithThreadingProblemTest {
08: @Test
09: public void twoThreadsShouldFailEventually() throws Exception {
10: final ClassWithThreadingProblem classWithThreadingProblem
= new ClassWithThreadingProblem();
11:
12: Runnable runnable = new Runnable() {
Листинг А.2 (продолжение)
13: public void run() {
14: classWithThreadingProblem.takeNextId();
15: }
16: };
17:
18: for (int i = 0; i < 50000; ++i) {
19: int startingId = classWithThreadingProblem.lastId;
20: int expectedResult = 2 + startingId;
21:
22: Thread t1 = new Thread(runnable);
23: Thread t2 = new Thread(runnable);
24: t1.start();
25: t2.start();
26: t1.join();
27: t2.join();
28:
29: int endingId = classWithThreadingProblem.lastId;
30:
31: if (endingId != expectedResult)
32: return;
33: }
34:
35: fail("Should have exposed a threading issue but it did not.");
36: }
37: }
| Строка | Описание |
| 10 | Создание экземпляра ClassWithThreadingProblem. Обратите внимание на необходимость использования ключевого слова final, так как ниже объект используется в анонимном внутреннем классе |
| 12–16 | Создание анонимного внутреннего класса, использующего экземпляр ClassWithThreadingProblem |
| 18 | Код выполняется количество раз, достаточное для демонстрации его некорректности, но так, чтобы он не выполнялся «слишком долго». Необходимо выдержать баланс между двумя целями; сбои должны выявляться за разумное время. Подобрать нужное число непросто, хотя, как мы вскоре увидим, его можно заметно сократить |
| 19 | Сохранение начального значения. Мы пытаемся доказать, что код ClassWithThreadingProblem некорректен. Если тест проходит, то он доказывает, что код некорректен. Если тест не проходит, то он не доказывает ничего |
| 20 | Итоговое значение должно быть на два больше текущего |
| 22–23 | Создание двух потоков, использующих объект, который был создан в строках 12–16. Два потока, пытающихся использовать один экземпляр ClassWithThreadingProblem, могут помешать друг другу; эту ситуацию мы и пытаемся воспроизвести. |
| 24–25 | Запуск двух потоков |
| 26–27 | Ожидание завершения обоих потоков с последующей проверкой результатов |
| 29 | Сохранение итогового значения |
| 31–32 | Отличается ли значение endingId от ожидаемого? Если отличается, вернуть признак завершения теста – доказано, что код работает некорректно. Если нет, попробовать еще раз |
| 35 | Если управление передано в эту точку, нашим тестам не удалось доказать некорректность кода за «разумное» время. Либо код работает корректно, либо количество итераций было недостаточным для возникновения сбойной комбинации |
Бесспорно, этот тест создает условия для выявления проблем многопоточного обновления. Но проблема встречается настолько редко, что в подавляющем большинстве случаев тестирование ее попросту не выявит. В самом деле, для сколько-нибудь статистически значимого выявления проблемы количество итераций должно превышать миллион. Несмотря на это, за десять выполнений цикла из 1 000 000 итераций проблема была обнаружена всего один раз. Это означает, что для надежного выявления сбоев количество итераций должно составлять около 100 миллионов. Как долго вы готовы ждать?
Даже если тест будет надежно выявлять сбои на одном компьютере, вероятно, его придется заново настраивать с другими параметрами для выявления сбоев на другом компьютере, операционной системе или версии JVM.
А ведь мы взяли очень простую задачу. Если нам не удается легко продемонстрировать некорректность кода в тривиальной ситуации, как обнаружить по-настоящему сложную проблему?
Как ускорить выявление этого простейшего сбоя? И что еще важнее, как написать тесты, демонстрирующие сбои в более сложном коде? Как узнать, что код некорректен, если мы даже не знаем, где искать? Несколько возможных идей.
Тестирование методом Монте-Карло. Сделайте тесты достаточно гибкими, чтобы вы могли легко вносить изменения в их конфигурацию. Повторяйте тесты снова и снова (скажем, на тестовом сервере) со случайным изменением параметров. Если в ходе тестирования будет обнаружена ошибка, значит, код некорректен. Начните писать эти тесты на ранней стадии, чтобы как можно ранее начать их выполнение на сервере непрерывной интеграции. Не забудьте сохранить набор условий, при котором был выявлен сбой.
• Выполняйте тесты на каждой целевой платформе разработки. Многократно. Непрерывно. Чем продолжительнее тесты работают без сбоев, тем выше вероятность, что:
• код продукта корректен, либо
• тестирования недостаточно для выявления проблем.
Запускайте тесты на машинах с разной нагрузкой. Если вы сможете имитировать нагрузку, близкую к среде реальной эксплуатации, сделайте это.
Но даже после выполнения всех этих действий вероятность обнаружения многопоточных проблем в вашем коде оставляет желать лучшего. Самыми коваными оказываются проблемы, возникающие при определенных комбинациях условий, встречающихся один раз на миллиард. Такие проблемы – настоящий бич сложных систем.
Средства тестирования многопоточного кода
Компания IBM создала программу ConTest, которая особым образом готовит классы для повышения вероятности сбоев в потоково-небезопасном коде.
Мы не связаны ни с IBM, ни с группой разработки ConTest. Об этой программе нам рассказал один из коллег. Оказалось, что всего несколько минут использования ConTest радикально повышают вероятность выявления многопоточных сбоев.
Тестирование с использованием ConTest проходит по следующей схеме:
• Напишите тесты и код продукта. Проследите за тем, чтобы тесты были специально спроектированы для имитации обращений от многих пользователей при переменной нагрузке, как упоминалось ранее.
• Проведите инструментовку кода тестов и продукта при помощи ConTest.
• Выполните тесты.
Если вы помните, ранее сбой выявлялся примерно один раз за десять миллионов запусков. После инструментовки кода в ConTest сбои стали выявляться один раз за тридцать запусков. Таким образом, сбои в адаптированных классах стали выявляться намного быстрее и надежнее.
Заключение
В этой главе мы предприняли очень краткое путешествие по огромной, ненадежной территории многопоточного программирования. Наше знакомство с этой темой нельзя назвать даже поверхностным. Основное внимание уделялось методам поддержания чистоты многопоточного кода, но если вы собираетесь писать многопоточные системы, вам придется еще многому научиться. Мы рекомендуем начать с замечательной книги Дуга Ли «Concurrent Programming in Java: Design Principles and Patterns» [Lea99, p. 191].
В этой главе рассматривались опасности многопоточного обновления, а также методы чистой синхронизации и блокировки, которые могут их предотвратить. Мы обсудили, как потоки могут повысить производительность систем с интенсивным вводом/выводом, а также конкретные приемы повышения производительности. Также была рассмотрена взаимная блокировка и чистые способы ее предотвращения. Приложение завершается описанием стратегий выявления многопоточных проблем посредством инструментовки кода.
Полные примеры кода
Однопоточная реализация архитектуры «клиент/сервер»
Листинг А.3. Server.java
package com.objectmentor.clientserver.nonthreaded;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.net.SocketException;
import common.MessageUtils;
public class Server implements Runnable {
ServerSocket serverSocket;
volatile boolean keepProcessing = true;
public Server(int port, int millisecondsTimeout) throws IOException {
serverSocket = new ServerSocket(port);
serverSocket.setSoTimeout(millisecondsTimeout);
}
public void run() {
System.out.printf("Server Starting\n");
while (keepProcessing) {
try {
System.out.printf("accepting client\n");
Socket socket = serverSocket.accept();
System.out.printf("got client\n");
process(socket);
} catch (Exception e) {
handle(e);
}
}
}
Листинг А.3 (продолжение)
private void handle(Exception e) {
if (!(e instanceof SocketException)) {
e.printStackTrace();
}
}
public void stopProcessing() {
keepProcessing = false;
closeIgnoringException(serverSocket);
}
void process(Socket socket) {
if (socket == null)
return;
try {
System.out.printf("Server: getting message\n");
String message = MessageUtils.getMessage(socket);
System.out.printf("Server: got message: %s\n", message);
Thread.sleep(1000);
System.out.printf("Server: sending reply: %s\n", message);
MessageUtils.sendMessage(socket, "Processed: " + message);
System.out.printf("Server: sent\n");
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
private void closeIgnoringException(Socket socket) {
if (socket != null)
try {
socket.close();
} catch (IOException ignore) {
}
}
private void closeIgnoringException(ServerSocket serverSocket) {
if (serverSocket != null)
try {
serverSocket.close();
} catch (IOException ignore) {
}
}
}
Листинг А.4. ClientTest.java
package com.objectmentor.clientserver.nonthreaded;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.net.SocketException;
import common.MessageUtils;
public class Server implements Runnable {
ServerSocket serverSocket;
volatile boolean keepProcessing = true;
public Server(int port, int millisecondsTimeout) throws IOException {
serverSocket = new ServerSocket(port);
serverSocket.setSoTimeout(millisecondsTimeout);
}
public void run() {
System.out.printf("Server Starting\n");
while (keepProcessing) {
try {
System.out.printf("accepting client\n");
Socket socket = serverSocket.accept();
System.out.printf("got client\n");
process(socket);
} catch (Exception e) {
handle(e);
}
}
}
private void handle(Exception e) {
if (!(e instanceof SocketException)) {
e.printStackTrace();
}
}
public void stopProcessing() {
keepProcessing = false;
closeIgnoringException(serverSocket);
}
void process(Socket socket) {
if (socket == null)
return;
Листинг А.4 (продолжение)
try {
System.out.printf("Server: getting message\n");
String message = MessageUtils.getMessage(socket);
System.out.printf("Server: got message: %s\n", message);
Thread.sleep(1000);
System.out.printf("Server: sending reply: %s\n", message);
MessageUtils.sendMessage(socket, "Processed: " + message);
System.out.printf("Server: sent\n");
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
private void closeIgnoringException(Socket socket) {
if (socket != null)
try {
socket.close();
} catch (IOException ignore) {
}
}
private void closeIgnoringException(ServerSocket serverSocket) {
if (serverSocket != null)
try {
serverSocket.close();
} catch (IOException ignore) {
}
}
}
Листинг А.5. MessageUtils.java
package common;
import java.io.IOException;
import java.io.InputStream;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.OutputStream;
import java.net.Socket;
public class MessageUtils {
public static void sendMessage(Socket socket, String message)
throws IOException {
OutputStream stream = socket.getOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(stream);
oos.writeUTF(message);
oos.flush();
}
public static String getMessage(Socket socket) throws IOException {
InputStream stream = socket.getInputStream();
ObjectInputStream ois = new ObjectInputStream(stream);
return ois.readUTF();
}
}
Архитектура «клиент/сервер» с использованием потоков
Перевод сервера на многопоточную архитектуру сводится к простому изменению функции process (новые строки выделены жирным шрифтом):
void process(final Socket socket) {
if (socket == null)
return;
Runnable clientHandler = new Runnable() {
public void run() {
try {
System.out.printf("Server: getting message\n");
String message = MessageUtils.getMessage(socket);
System.out.printf("Server: got message: %s\n", message);
Thread.sleep(1000);
System.out.printf("Server: sending reply: %s\n", message);
MessageUtils.sendMessage(socket, "Processed: " + message);
System.out.printf("Server: sent\n");
closeIgnoringException(socket);
} catch (Exception e) {
e.printStackTrace();
}
}
};
Thread clientConnection = new Thread(clientHandler);
clientConnection.start();
}
Вы можете убедиться в этом сами, тестируя код до и после внесения изменений. Однопоточный код приведен на с. 385, а многопоточный – на с. 389.
Это несколько упрощенное объяснение. Впрочем, для целей нашего обсуждения мы воспользуемся этой упрощенной моделью.
На самом деле интерфейс Iterator в принципе не обладает потоковой безопасностью. Он не проектировался с расчетом на многопоточное использование, так что этот факт не вызывает удивления.
Кто-то добавляет отладочный вывод, и проблема «исчезает». Отладочный код «решил» проблему, поэтому он остается в системе.

