Книга: Big data простым языком
Назад: Как измерять качество данных?
Дальше: Инструменты управления качеством данных
Как понять, какие измерения качества выбрать?
Мне нравится одно очень интересно исследование, которое провели исследователи из MIT. Оно называется «Beyond Accuracy». Для него исследователи выделили несколько групп пользователей.
В первой группе пользователей, которых они опросили, были студенты MBA.
Во второй группе пользователей, среди которых был опрос, находились уже выпускники MBA, которые проработали в компаниях достаточное количество лет.
Опросы так же отличались друг от друга. Опрос для первой группы включал в себя список возможных измерений контроля качества данных, из которого студенты должны были выбрать предпочтительный.
Напомню, что в исследованиях всегда используют один из трех различных подходов получения научного познания:
• Эмпирический – познание получаем через ощущения.
• Теоретический – осмысление опыта с точки зрения логики.
• Интуитивный – когда мы полагаемся на свой «внутренний» голос при исследовании того или иного события.
В первой группе исследователи применили теоретический подход получения нового знания – а именно списка параметров, «измерений», по которым можно контролировать качество данных.
Во второй группе исследователи применили уже интуитивный подход, чтобы понять, какие из этих параметров на самом деле наиболее важны в принятии решений и их влиянии на бизнес. В этом случае продолжительный опыт бывших выпускников MBA в компаниях являлся тем самым «внутренним фильтром», который помог определить наиболее ценные измерения из большого списка.
Исследователи сформировали список из 32 параметров контроля качества данных (32 параметра – это достаточно внушительно), и попросили сформулировать, как бы выпускники контролировали качество данных.
По итогам опроса получилось 179 уникальных параметров, которые сформулировали участники процесса, то есть в пять с половиной раз больше, чем исследователи изначально заложили в свою модель.
Модель исследователей строилась на четырех основных группах, которые объединяли эти самые параметры:
• Доступность – данные должны быть доступны для пользователя.
• Интерпретируемость – данные должны быть способны к интерпретации. К слову, не пытайтесь использовать мандаринский диалект, если вдруг пишите комментарии в проводках и так далее.
• Релевантность – данные должны быть релевантны для конечного пользователя, если они участвуют в процессе принятия решения.
• Точность – данные должны быть точны для пользователя, то есть быть точными и из достоверных источников.
Во второй группе исследователи отбросили часть новых параметров и показали только 118 параметров контролирования качества данных. Опрос строился на ответах 1500 выпускников MBA, которые уже имели внушительный опыт работы.
Опустим тот факт, что опрос строился через почту, и тогда не было еще нормального работающего Интернета, обратимся лучше к его результатам.
99 из указанных параметров из основного списка оказались абсолютно не важны, когда люди с большим опытом и багажом знаний попытались интуитивно ответить на тот же самый вопрос о том, как контролировать качество данных.
Два параметра пользователи выделили как самые важные – «точность» (accuracy) и «правильность» (correct). Все самые важные параметры исследователи сгруппировали вместе в кластеры, которых получилось ровно четыре.
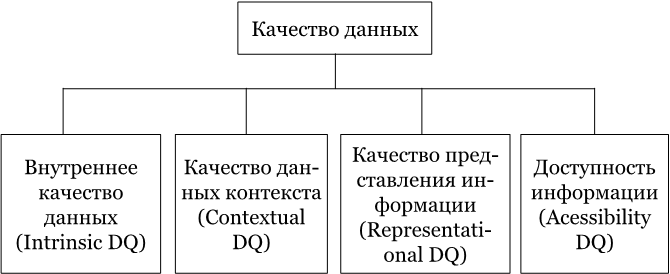
Рисунок SEQ Рисунок \* ARABIC 1 Структура концептуального фреймворка DQ, на основании исследования MIT Beyond Accuracy. 1993
Внутреннее качество данных – включает не только точность, но и два новых измерения – репутацию и правдоподобие. Одна лишь «точность», как оказалось, не дает пользователям уверенности в корректности данных. Им нужно доверять источникам данных.
Качество данных контекста – как оказалось, качество данных по контексту профессиональная литература по работе с данными не распознает, то есть, таких знаний просто не было. Люди не имели представления, как управлять качеством того контекста, который они получают. Единственные доступные материалы были о качестве визуального контекста – графике. Мы это подробно разобрали в главе про «Data Storytelling». Пример реализации контекстных проверок был, как ни странно, в армии Соединенных Штатов Америки во время операции «Буря в Пустыне», где такие проверки были установлены на воздушных судах. Они анализировали для каждой задачи, выполняемой воздушным судном, широкий список параметров, используемый в планировании авиаударов.
Представление качества данных – в первую очередь эта группа касается проблем с форматом данных и с тем, чтобы данные можно было понять и интерпретировать. К примеру, данные по отчетности ВТБ отражаются в российских рублях, в свою очередь, в данных группы Альфа-Банка в публикуемой отчетности вместо рублей уже используются доллары как основная валюта.
Доступность данных – один из самых неоднозначных параметров, потому что управление информационной безопасностью в большинстве проектов и организацией, в которых мне довелось побыть, выведено за периметр как IT-департамента, так и Финансового департамента. Управление информационной безопасностью – это отдельно выделенный лидер внутри организации, поэтому решения в области ИБ в большинстве случаев не участвуют в управлении качества данных.
В итоге, исследователи MIT вывели 15 ключевых измерений того, как можно управлять качеством данных, и сформировали из них следующий фреймворк.
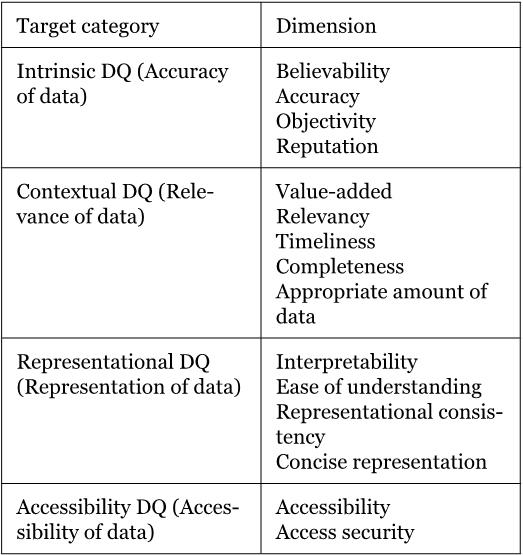
Это было более двадцати лет назад, но на мой скромный экспертный взгляд такой подход по-прежнему актуален, хотя мало где еще используется. Его мы можем смело использовать при подготовке отчета «аппетит к риску», чтобы выбить из менеджмента ресурсы на все свои «хотелки» в области данных.

