16. Словари
Словари (dictionaries) — высокооптимизированный встроенный тип в языке Python. Словарь Python отчасти напоминает обычный словарь, состоящий из слов и определений. Задача словаря — обеспечить быстрый поиск определения по ключевому слову. В обычном словаре для ускорения поиска можно воспользоваться методом бинарного поиска (открыть словарь на середине, определить, в какой половине находится искомое слово, и повторить).
Словарь Python тоже состоит из слов и определений, но они называются ключами и значениями соответственно. Цель словаря — обеспечить быстрый поиск по ключу и извлечь значение, связанное с этим ключом. Как и в обычном словаре, в котором нахождение слова по определению займет много времени (если вы заранее не знаете искомое слово), поиск по значению в словаре Python происходит очень медленно.
В Python 3.6 у словарей появилась новая особенность: ключи теперь сортируются по порядку вставки. Если вы пишете код Python, который должен работать в предыдущих версиях, вы должны запомнить, что до версии 3.6 порядок ключей был произвольным (что позволяло Python выполнять быстрый поиск, но было не особо полезно для конечного пользователя).
16.1. Присваивание в словарях
Словари связывают ключ со значением (в других языках программирования они могут называться хешами, хеш-картами, картами или ассоциативными массивами). Допустим, вы хотите сохранить информацию о человеке. Вы уже видели, как использовать кортеж для представления записи. Словари тоже могут использоваться для решения этой задачи. Так как словари встроены в Python, для их создания можно воспользоваться синтаксисом литералов. В следующем словаре хранится имя и фамилия:
>>> info = {'first': 'Pete', 'last': 'Best'}
ПРИМЕЧАНИЕ
Также словарь можно создать при помощи встроенного класса dict. Если передать классу список пар кортежей, он вернет словарь:
>>> info = dict([('first', 'Pete'),
... ('last', 'Best')])
При вызове dict также можно использовать именованные параметры:
>>> info = dict(first='Pete', last='Best')
Если вы используете именованные параметры, они должны быть допустимыми именами переменных Python, тогда они будут преобразованы в строки.
Для вставки значений в словарь можно воспользоваться индексными операциями:
>>> info['age'] = 20
>>> info['occupation'] = 'Drummer'
В этом примере ключами являются 'first', 'last', 'age' и 'occupation'. Например, 'age' — ключ, которому соответствует значение: целое число 20. Чтобы быстро найти значение, соответствующее 'age', выполните поиск индексной операцией:
>>> info['age']
20
С другой стороны, если вам потребуется определить, какой ключ соответствует значению 20, такая операция будет слишком медленной. В приведенном примере продемонстрирован синтаксис литералов для создания изначально заполненного словаря. Пример также показывает, как квадратные скобки (индексные операции) используются для вставки элементов в словарь и их извлечения. Индексная операция связывает ключ со значением при использовании в сочетании с оператором присваивания (=). Если индексная операция не содержит присваивания, она находит значение, соответствующее заданному ключу.
16.2. Выборка значений из словаря
Как вы уже видели, синтаксис литералов с квадратными скобками может извлечь значение из словаря при использовании квадратных скобок без присваивания:
>>> info['age']
20
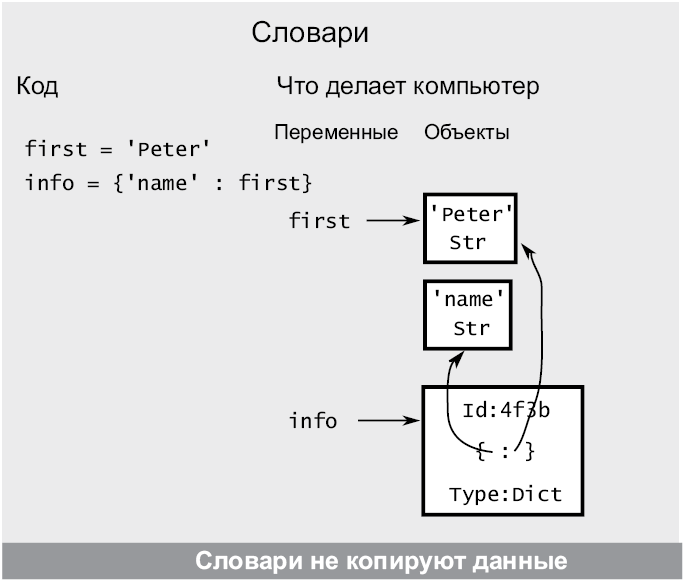
Рис. 16.1. Создание словаря. В данном случае в качестве значения используется существующая переменная. Обратите внимание: словарь не копирует переменную, но создает указатель на нее (увеличивая ее счетчик ссылок)
Впрочем, будьте осторожны — при попытке обратиться к ключу, отсутствующему в словаре, Python выдаст исключение:
>>> info['Band']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'Band'
Поскольку для Python характерно явное выражение намерений программиста и быстрое выявление сбоев, выдачу исключений можно только приветствовать. Вы знаете, что ключ 'Band' отсутствует в словаре. Было бы гораздо хуже, если бы Python возвращал случайное значение для ключа, отсутствующего в словаре. Это привело бы к дальнейшему распространению ошибки в программе и маскировке логического дефекта.
16.3. Оператор in
Python предоставляет оператор in, который позволяет быстро проверить наличие ключа в словаре:
>>> 'Band' in info
False
>>> 'first' in info
True
Как вы уже видели, in также работает с последовательностями. Оператор in может использоваться со списком, множеством или строкой для проверки принадлежности:
>>> 5 in [1, 3, 6]
False
>>> 't' in {'a', 'e', 'i'}
False
>>> 'P' in 'Paul'
True
ПРИМЕЧАНИЕ
В Python 3 был исключен метод .has_key, который предоставляет ту же функциональность, что и команда in, но работает только со словарями. Любые действия, ведущие к большей универсальности, можно только приветствовать!
Команда in работает с большинством контейнеров. Кроме того, вы можете определить собственные классы, поддерживающие эту команду. Ваш объект должен поддерживать перебор или определять метод .__contains__.
16.4. Сокращенный синтаксис словарей
Метод .get словаря получает значение, соответствующее ключу. Метод .get также может получать необязательный параметр для значения по умолчанию, если ключ не найден. Если вы хотите, чтобы genre по умолчанию присваивалось значение 'Rock', это можно сделать так:
>>> genre = info.get('Genre', 'Rock')
>>> genre
'Rock'
СОВЕТ
Метод .get словарей — один из способов обойти исключение KeyError при попытке использования синтаксиса с квадратными скобками для выборки по ключу, отсутствующему в словаре.
16.5. setdefault
У словарей есть полезный метод с неудачно выбранным именем .setdefault. Этот метод имеет такую же сигнатуру, как .get, и поначалу работает так же: он возвращает значение по умолчанию, если ключ не существует. Кроме того, он также связывает с ключом значение по умолчанию, если ключ не найден. Так как .setdefault возвращает значение, если инициализировать его изменяемым типом (таким, как словарь или список), результат можно будет изменять на месте.
Метод .setdefault может использоваться для создания накопителя или счетчика ключей. Например, если вы хотите подсчитать количество людей с одним именем, это можно сделать так:
>>> names = ['Ringo', 'Paul', 'John',
... 'Ringo']
>>> count = {}
>>> for name in names:
... count.setdefault(name, 0)
... count[name] += 1
Без метода .setdefault потребовалось бы немного больше кода:
>>> names = ['Ringo', 'Paul', 'John',
... 'Ringo']
>>> count = {}
>>> for name in names:
... if name not in count:
... count[name] = 1
... else:
... count[name] += 1
>>> count['Ringo']
2
СОВЕТ
Подобные операции подсчета встречаются настолько часто, что позднее в стандартную библиотеку Python был добавлен класс collections.Counter. Этот класс позволяет выполнять такие операции в более компактном виде:
>>> import collections
>>> count = collections.Counter(['Ringo', 'Paul',
... 'John', 'Ringo'])
>>> count
Counter({'Ringo': 2, 'Paul': 1, 'John': 1})
>>> count['Ringo']
2
>>> count['Fred']
0
Ниже приведен несколько искусственный пример, демонстрирующий изменение результата .setdefault. Предположим, имеется словарь, связывающий имя музыканта с названием группы, в которой он играл. Если человек по имени Paul участвует в двух группах, результат должен связывать имя Paul со списком, содержащим обе группы:
>>> band1_names = ['John', 'George',
... 'Paul', 'Ringo']
>>> band2_names = ['Paul']
>>> names_to_bands = {}
>>> for name in band1_names:
... names_to_bands.setdefault(name,
... []).append('Beatles')
>>> for name in band2_names:
... names_to_bands.setdefault(name,
... []).append('Wings')
>>> print(names_to_bands['Paul'])
['Beatles', 'Wings']
В развитие темы: без setdefault этот код получился бы более длинным:
>>> band1_names = ['John', 'George',
... 'Paul', 'Ringo']
>>> band2_names = ['Paul']
>>> names_to_bands = {}
>>> for name in band1_names:
... if name not in names_to_bands:
... names_to_bands[name] = []
... names_to_bands[name].\
... append('Beatles')
>>> for name in band2_names:
... if name not in names_to_bands:
... names_to_bands[name] = []
... names_to_bands[name].\
... append('Wings')
>>> print(names_to_bands['Paul'])
['Beatles', 'Wings']
СОВЕТ
Модуль collections из стандартной библиотеки Python содержит удобный класс — defaultdict. Этот класс своим поведением напоминает словарь, но также позволяет задать для ключа в качестве значения по умолчанию произвольную фабрику (factory). Если фабрика по умолчанию отлична от None, она инициализируется и вставляется как значение каждый раз, когда отсутствует ключ. Предыдущий пример может быть переписан с defaultdict в следующем виде:
>>> from collections import defaultdict
>>> names_to_bands = defaultdict(list)
>>> for name in band1_names:
... names_to_bands[name].\
... append('Beatles')
>>> for name in band2_names:
... names_to_bands[name].\
... append('Wings')
>>> print(names_to_bands['Paul'])
['Beatles', 'Wings']
Код с defaultdict получается чуть более понятным, чем с использованием setdefault.
16.6. Удаление ключей
Другая стандартная операция со словарями — удаление ключей и соответствующих им значений. Для удаления элемента из словаря используется команда del:
# Удаление 'Ringo' из словаря
>>> del names_to_bands['Ringo']
СОВЕТ
Python не позволяет добавлять и удалять данные из словаря во время его перебора. В таких ситуациях Python выдает исключение RuntimeError:
>>> data = {'name': 'Matt'}
>>> for key in data:
... del data[key]
Traceback (most recent call last):
...
RuntimeError: dictionary changed size during iteration
16.7. Перебор словаря
Словари также поддерживают перебор командой for. По умолчанию при переборе по словарю вы получаете ключи:
>>> data = {'Adam': 2, 'Zeek': 5, 'Fred': 3}
>>> for name in data:
... print(name)
Adam
Zeek
Fred
ПРИМЕЧАНИЕ
У словарей имеется метод .keys, который тоже перебирает ключи из словаря. В Python 3 метод .keys возвращает представление (view) — «окно» для просмотра ключей, находящихся в настоящий момент в словаре. Представление, как и список, может использоваться для перебора. Однако в отличие от списка, он не является копией этих ключей. Если позднее ключ будет удален из словаря, это изменение отразится в представлении — но не в списке.
Чтобы перебрать значения в словаре, проведите перебор по методу .values:
>>> for value in data.values():
... print(value)
2
5
3
Результат вызова .values также является представлением. Он отражает текущее состояние значений, находящихся в словаре.
Чтобы получать при переборе как ключ, так и значение, используйте метод .items, который возвращает представление:
>>> for key, value in data.items():
... print(key, value)
Adam 2
Zeek 5
Fred 3
Если материализовать представление в список, вы увидите, что список является последовательностью кортежей (ключ, значение) — то, что получает dict для создания словаря:
>>> list(data.items())
[('Adam', 2), ('Zeek', 5), ('Fred', 3)]
СОВЕТ
Помните, что словарь упорядочивается в порядке вставки ключей. Если вам нужен другой порядок, последовательность перебора необходимо отсортировать.
Встроенная функция sorted возвращает новый отсортированный список для заданной последовательности:
>>> for name in sorted(data.keys()):
... print(name)
Adam
Fred
Zeek
У функции sorted есть необязательный аргумент reverse для перехода на противоположный порядок вывода:
>>> for name in sorted(data.keys(),
... reverse=True):
... print(name)
Zeek
Fred
Adam
ПРИМЕЧАНИЕ
Ключи могут относиться к разным типам. Единственное требование к ключам — хешируемость. Например, список не является хешируемым, потому что он может изменяться, и Python не может сгенерировать для него хеш, соответствующий текущему содержимому. Если использовать список в качестве ключа, а затем изменить ключ, какое значение должен вернуть словарь — для старого списка, для нового списка, оба сразу? Python не берется гадать и заставляет программиста использовать неизменяемые ключи.
Вы можете вставлять элементы в словарь, используя в качестве ключей целые числа и строки:
>>> weird = {1: 'first',
... '1': 'another first'}
Обычно смешивать разнотипные ключи не рекомендуется, потому что это делает код менее понятным и усложняет сортировку. Python 3 не сортирует списки со смешанными типами без функции key, которая явно указывает Python, как следует сравнивать разные типы. Это один из тех случаев, когда Python позволяет что-то сделать, но это не значит, что вам стоит пользоваться этой возможностью. Как говорил один из основных разработчиков Python Рэймонд Хеттингер (Raymond Hettinger): «Многие вопросы типа “Могу ли я сделать x на языке Python?” равнозначны вопросу “Могу ли я остановить машину на рельсах, если поблизости нет поезда?” Да, можете. Нет, не стоит».
@raymondh
16.8. Итоги
Эта глава была посвящена словарям. Эта структура данных играет важную роль, потому что она является одним из «строительных блоков» Python. Классы, пространства имен и модули — все это во внутренней реализации Python строится на базе словарей.
Словари обеспечивают быстрый поиск или вставку по ключу. Также возможен поиск по значению, но он выполняется медленно. Если вам часто приходится выполнять эту операцию со словарями, это верный признак кода «с душком» — подумайте об использовании другой структуры данных.
Также были представлены способы изменения словаря. В словаре можно вставлять и удалять ключи, а также проверять принадлежность при помощи команды in.
Мы рассмотрели некоторые нетривиальные конструкции, использующие .setdefault для вставки и возвращения значений за одну операцию. Также были представлены специализированные классы словарей Counter и defaultdict из модуля collections.
Поскольку словари изменяемы, вы можете удалять из них ключи командой del. Также возможет перебор ключей словаря в цикле for.
В Python 3.6 появилось упорядочение элементов в словарях. Ключи упорядочиваются в порядке вставки, а не по алфавиту и не в числовом порядке.
16.9. Упражнения
1. Создайте словарь info, в котором хранится ваше имя, фамилия и возраст.
2. Создайте пустой словарь phone с подробной информацией о вашем телефоне. Добавьте в словарь данные о размере экрана, объеме памяти, ОС, фирме-производителе и т.д.
3. Напишите абзац текста в строке, заключенной в тройные кавычки. Используйте метод .split для создания списка слов. Создайте словарь для хранения счетчика вхождений каждого слова в абзаце.
4. Посчитайте, сколько раз используется каждое слово в абзаце текста Ральфа Уолдо Эмерсона.
5. Напишите код для вывода анаграмм (слов, состоящих из тех же букв в другом порядке) из абзаца текста.
6. Алгоритм PageRank использовался для создания поисковой системы Google. Алгоритм назначает каждой странице ранг, основанный на количестве входящих ссылок. Он получает одно входное значение: список страниц, ссылающихся на другие страницы. Каждой странице изначально назначается ранг 1. Выполняется несколько итераций алгоритма — обычно 10. Для каждой итерации:
• страница передает свой ранг, разделенный на количество исходящих ссылок, каждой странице, с которой она связана ссылкой;
• перенесенный ранг умножается на коэффициент затухания, обычно равный 0,85.
Напишите код для выполнения 10 итераций этого алгоритма со списком кортежей входных и выходных ссылок:
links = [('a', 'b'), ('a', 'c'), ('b', 'c')]

