4. Целевой уровень качества обслуживания
Авторы — Крис Джоунс, Джон Уилкс и Нейл Мёрфи при участии Коди Смита
Под редакцией Бетси Бейер
Невозможно правильно управлять сервисом (не говоря уже о том, чтобы делать это хорошо), не понимая, какие аспекты поведения действительно важны для него и как их измерить и оценить. Для этого мы хотели бы установить уровень качества обслуживания и обеспечить его для наших пользователей независимо от того, используют они внутренний API или общедоступный продукт.
В процессе работы мы прислушиваемся к интуиции и ориентируемся на свой опыт и понимание пожеланий пользователей. В итоге мы стараемся определить показатели уровня качества обслуживания (service level indicators, SLIs), а также целевые показатели (objectives, SLOs) и соглашения (agreements, SLAs). Эти количественные характеристики описывают важные базовые свойства продуктов, их необходимые значения и наши действия в том случае, если мы не можем предоставить ожидаемый уровень обслуживания. В конце концов, подбор подходящих показателей помогает принимать правильные решения, если что-то идет не так, а также дает команде SRE уверенность в исправности сервиса.
В этой главе описывается фреймворк, используемый нами для формирования показателей, их выбора и анализа. Большая часть объяснений осталась бы абстрактной без каких-либо примеров, поэтому для иллюстрации основных моментов мы будем использовать сервис Shakespeare, описанный в подразделе «Shakespeare: пример сервиса» на с. 56.
Терминология для уровня качества обслуживания
Скорее всего, многие читатели знакомы с концепцией SLA, но термины SLI и SLO также заслуживают четкого определения. В повседневной речи термин SLA используется слишком часто и имеет несколько значений в зависимости от контекста. Для ясности мы предпочитаем разделять эти значения.
Показатели
SLI — это показатель (индикатор) уровня качества обслуживания, четко определенное числовое значение конкретной характеристики предоставляемого обслуживания.
Для большинства сервисов ключевым SLI является время отклика, или латентность запросов, — время, которое требуется для того, чтобы вернуть ответ на запрос. В качестве SLI могут также использоваться уровень (или частота) ошибок, который часто выражается как процент от общего количества запросов, и пропускная способность системы, чаще всего измеряемая в запросах в секунду. Результаты измерений обычно агрегируются: например, первичные данные, собранные в пределах «окна измерения», затем усредняются, приводятся к процентному уровню, или к процентилю.
В идеале SLI непосредственно отражает интересующий нас уровень качества обслуживания, но иногда нам доступны только приближенные данные, поскольку желаемые точные измеренные показатели трудно получить или интерпретировать. Например, наиболее релевантным для пользователя показателем часто бывает время отклика на стороне клиента, но измерить задержку можно только на сервере.
Еще один SLI, имеющий значение для отдела SRE, — это доступность: доля времени, когда сервис можно использовать. Обычно она определяется как доля успешных запросов, иногда ее называют выработкой (yield). Аналогично важная для систем хранения данных характеристика долговечность (durability) — это вероятность того, что данные будут сохранены в течение длительного промежутка времени. Хотя 100%-ной доступности достичь невозможно, можно достигать значения, близкого к 100 %. В нашей отрасли высокие значения доступности выражаются количеством девяток, использованных в записи процента доступности. Например, уровни доступности 99 % и 99,999 % могут называться «две девятки» и «пять девяток» соответственно. В частности, текущее значение доступности Google Compute Engine равно трем с половиной девяткам — 99,95 %.
Целевые показатели
SLO — это целевой уровень качества обслуживания: целевое значение или диапазон значений, измеряемые с помощью SLI. Естественная структура SLO выглядит как SLI ≤ целевое значение или нижняя граница ≤ SLI ≤ верхняя граница. Например, мы можем решить, что сервис Shakespeare будет возвращать результат «быстро», и укажем, что среднее время отклика должно быть равно 100 миллисекундам или меньше.
Выбрать подходящий SLO нелегко. Начнем с того, что вы не всегда можете определить конкретное значение! Например, для запросов HTTP, поступающих к вашему сервису из внешнего мира, показатель «запросы в секунду» (queries per second, QPS) естественным способом определяется потребностями ваших пользователей и вы не можете сами установить его.
С другой стороны, вы можете сказать: «Хочу, чтобы среднее время отклика было меньше 100 миллисекунд». Постановка подобной цели может, в свою очередь, мотивировать вас написать фронтенд, учитывающий варианты поведения с низкой задержкой, или приобрести соответствующее оборудование.
Опять же это вопрос несколько более тонкий, чем кажется на первый взгляд. Эти два показателя — QPS и время отклика — могут быть связаны друг с другом: чем больше QPS, тем больше задержки. Производительность некоторых сервисов снижается по достижении определенного порога нагрузки.
Определение и объявление SLO задает уровень ожиданий, относящихся к работе сервиса. Это может уменьшить количество необоснованных жалоб к владельцам сервиса по поводу, например, его медленной работы. Не имея явного SLO, пользователи зачастую руководствуются собственными представлениями о желаемой производительности, которые могут не совпадать с соответствующими представлениями разработчиков сервиса. Это может привести как к излишнему доверию к приложению, когда пользователь считает его более доступным, чем на самом деле (как это случилось с Chubby: см. ниже врезку «Плановые отключения глобального сервиса Chubby»), так и к недостаточному доверию, когда потенциальные пользователи считают систему менее надежной, чем она есть.
| Плановые отключения глобального сервиса Chubby Автор — Марк Алвидрес Chubby [Burrows, 2006] — это сервис блокировок Google для слабо связанных распределенных систем. В глобальном случае мы распределяем его копии (реплики) так, чтобы все они находились в разных географических регионах. С течением времени мы обнаружили, что сбои в этой глобальной системе периодически приводят к отключениям сервиса, что зачастую влияет и на конечных пользователей. Как оказалось, сами по себе отключения Chubby происходили настолько редко, что владельцы других сервисов начали использовать обращения к нему, вообще не учитывая возможность его отключения. Высокая надежность сервиса сформировала ложное чувство безопасности, и в результате другие сервисы не могли работать корректно при недоступности Chubby, хоть и происходило это редко. Для этой проблемы было придумано интересное решение: SR-инженеры обеспечивают в целом соответствие глобального сервиса Chubby своим SLO и, возможно, лишь незначительное превышение установленных лимитов. Если в каком-то квартале реальное отключение сервиса не опускало уровень доступности ниже целевого, создавался искусственный сбой, который целенаправленно отключал систему. Такой сбой позволял избавляться от некорректно реализованных зависимостей от Chubby вскоре после их появления. Это заставляет владельцев сервисов считаться с реальными свойствами распределенных систем, причем, скорее всего, еще на ранних стадиях разработки1. |
Соглашения
Наконец, SLA — это соглашения об уровне обслуживания, явный или неявный контракт с вашими пользователями, включающий в себя последствия, которые влечет за собой соответствие (или несоответствие) требованиям SLO. Последствия лучше всего видны, когда затрагиваются финансы — скидки или штрафы, но они могут принимать и другие формы. Простой способ понять разницу между SLO и SLA заключается в том, чтобы задать себе вопрос: «Что случится, если требования SLO не соблюдаются?» Если явных последствий не существует, то, скорее всего, перед вами только SLO.
Отдел SRE обычно не участвует в создании SLA, поскольку SLA тесно связаны с бизнесом и относящимися к продукту управленческими решениями. Однако отдел SRE помогает избегать последствий при нарушении требований SLO. Он также может помочь определить SLI: очевидно, должен существовать некий способ измерить показатели SLO, чтобы не возникло разногласий.
Google Search — это пример важного и ответственного сервиса, который не имеет общедоступных SLA: мы стремимся сделать для всех использование сервиса Search максимально эффективным и беспроблемным, но мы не подписывали контракт со всем миром. Тем не менее даже в этом случае могут возникнуть определенные последствия, если сервис окажется недоступен — это грозит ударом по нашей репутации, а также снизит прибыль от рекламы. Многие другие сервисы Google вроде Google for Work имеют явные SLA. Но вне зависимости от того, имеет ли конкретный сервис явные SLA, будет полезно определить для него SLI и SLO и использовать их для управления сервисом.
Хватит теории — приступим к практике!
Показатели на практике
Итак, мы обосновали необходимость выбора подходящих показателей для сервиса. Как определить, что показатели имеют значение для вашего сервиса или системы?
Что важно для вас и ваших пользователей
Вы не должны использовать в качестве SLI каждый доступный показатель своей мониторинговой системы. Понимая, что именно ваши пользователи хотят от системы, вы сможете выбрать разумное количество показателей. Выбор слишком большого их количества приведет к тому, что вам будет трудно уделить достаточное внимание тем из них, кто действительно важен, а выбор слишком малого количества — к тому, что некоторые варианты поведения системы останутся не охваченными измерениями. Чтобы оценить исправность системы, нам, как правило, хватает небольшого набора индикаторов.
С точки зрения релевантности тех или иных SLI, сервисы делятся на несколько больших категорий.
• Для пользовательских сервисов вроде Shakespeare обычно важны доступность, время отклика и пропускная способность. Можем ли мы ответить за запрос? Сколько времени для этого потребуется? Сколько запросов мы можем обработать?
• Для систем хранения чаще делается акцент на времени отклика, доступности и долговечности. Сколько времени нам потребуется для того, чтобы считать или записать данные? Можем ли мы получить доступ к данным всегда, когда это потребовалось? Сохранятся ли в системе данные на тот момент, когда они нам понадобятся? Более подробно эти вопросы обсуждаются в главе 26.
• Для систем обработки больших объемов данных вроде конвейеров важны пропускная способность и общая задержка обработки данных. Сколько данных обрабатывается прямо сейчас? Как долго данные находятся внутри системы? (Некоторые конвейеры также могут иметь целевые значения задержки на отдельных этапах обработки.)
• Для всех систем должна быть важна корректность. Был ли корректен выданный ответ, были ли корректны полученные данные, был ли корректен выполненный анализ? Корректность — это важный показатель исправности системы, даже несмотря на то, что зачастую он является свойством данных, а не инфраструктуры как таковой, и поэтому обычно не входит в зону ответственности отдела SRE.
Сбор показателей
Значения многих показателей наиболее удобно собирать на стороне сервера с помощью мониторинговой системы типа Borgmon (см. главу 10) или Prometheus. Можно также периодически анализировать журналы — например, при определении соотношения количества ответов HTTP 500 к общему количеству запросов. Однако для некоторых систем требуются инструменты, позволяющие собирать данные на стороне клиента. Из-за отсутствия такого рода данных можно пропустить целый ряд проблем, влияющих на пользователей, но не отражающихся в показателях на стороне сервера. Например, если вы сосредоточитесь только на значении времени отклика в серверной части поискового сервиса Shakespeare, то можете не заметить большую задержку, связанную с проблемами в коде JavaScript. В этом случае наилучшим местом измерения задержки готовности страницы будет браузер пользователя.
Агрегирование
Для простоты и удобства использования первичные данные обычно агрегируются. Это нужно делать осторожно.
Кажется, что для некоторых показателей вроде количества обрабатываемых запросов в секунду достаточно просто взять первичные данные, но даже такие измерения неявно агрегируют данные в пределах окна измерения. Мы получаем данные каждую секунду или определяем среднее количество запросов в минуту? Во втором случае мы можем упустить всплески интенсивности поступления запросов, которые длятся всего несколько секунд.
Рассмотрим систему, которая обрабатывает по 200 запросов каждую четную секунду и 0 запросов в остальное время. Средняя нагрузка такой системы будет такой же, как и нагрузка системы, обрабатывающей каждую секунду по 100 запросов, но ее мгновенная нагрузка в два раза выше средней. Аналогично заманчивым может казаться вычисление среднего времени отклика, но такой подход не раскрывает одну важную деталь: есть вероятность, что большая часть запросов обрабатывается достаточно быстро, и лишь некоторые запросы, находящиеся в удлиненном «хвосте», обрабатываются гораздо медленнее.
Большинство показателей лучше рассматривать не как средние значения, а как распределения. Например, если говорить о показателе времени отклика, то одни запросы будут обрабатываться быстрее, а другие — дольше, причем иногда намного дольше. Простой подсчет среднего значения может скрыть эти «хвостовые» задержки, а также их изменения. На рис. 4.1 показан пример: несмотря на то что обычно запрос обрабатывается примерно 50 миллисекунд, 5 % запросов обрабатываются в 20 раз медленнее! Соответственно, процессы мониторинга и оповещения, учитывающие только усредненные значения задержки, не покажут колебаний в течение дня, хотя в действительности в «хвостовых» задержках заметны значительные изменения (верхняя линия на рисунке).
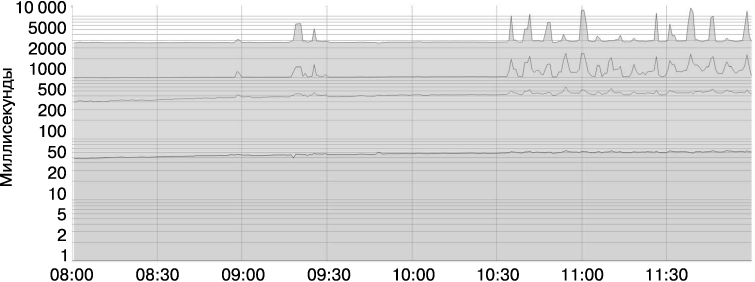
Рис. 4.1. Показаны 50-й, 85-й, 95-й и 99-й процентили задержки системы. Обратите внимание на то, что ось Y имеет логарифмическую шкалу
Использование процентилей в качестве показателей позволяет рассмотреть форму распределения и его различные характеристики: процентиль высокого порядка, например 99-й или 99,9-й, показывает вам предположительно худшие значения, а 50-й процентиль (также известный как медиана) позволяет выделить типичные ситуации. Чем выше разброс значений времени отклика, тем больше будет влиять на пользователя поведение удлиненного «хвоста» распределения, и этот эффект усугубляется при высоких нагрузках из-за особенностей поведения очередей. Исследования, проводимые среди пользователей, показывают, что люди обычно предпочитают чуть более медленную систему, чем имеющую большой разброс времени отклика. По этой причине отдел SRE интересуют только значения высоких процентилей: если пользователя устроит поведение системы на 99,9-м процентиле, то оно устроит его и в обычном случае.
| О статистических заблуждениях Обычно мы предпочитаем работать с процентилями, а не со средним арифметическим набора значений. Это позволяет нам рассмотреть данные в удлиненном «хвосте» распределения, которые существенно отличаются от средних значений. Поскольку вычислительные системы имеют искусственную природу, значения показателей обычно несимметричны. Например, ни на один запрос нельзя получить ответ менее чем за 0 миллисекунд, а при задержке более 1000 миллисекунд выполнение запроса считается неуспешным. В результате нельзя ожидать, что среднее арифметическое и медиана будут иметь равные или хотя бы близкие значения! Мы не торопимся предполагать, что данные будут распределены по нормальному закону, пока сами не убедимся в этом. А вдруг стандартные приближения и интуиция нас подведут? Например, если распределение не соответствует ожиданиям, то процесс, который должен выполняться при появлении выбросов в показателях (скажем, перезапуск сервера в ответ на недопустимое увеличение времени обработки запросов), может запускаться либо слишком часто, либо слишком редко. |
Стандартизация показателей
Мы рекомендуем стандартизировать определение распространенных показателей, чтобы вам не нужно было каждый раз заново их переопределять. Любую характеристику, соответствующую стандартному шаблону определения, в спецификации конкретного показателя можно опустить. Приведем примеры.
• Интервалы агрегирования: «Среднее значение за минуту».
• Регионы агрегирования: «Все задачи в кластере».
• Частота выполнения измерений: «Каждые 10 секунд».
• Какие запросы нужно включить в выборку: «Запросы HTTP GET, полученные в результате мониторинга методом черного ящика».
• Способ получения данных: «Данные получены путем наблюдения; измерения выполнены на стороне сервера».
• Задержка при доступе к данным: «Время до получения последнего байта».
Для того чтобы сэкономить время, вы можете создать набор повторно используемых шаблонов определений для каждого распространенного показателя. Они также помогут другим понять, что означает каждый конкретный показатель.
Целевые показатели на практике
Подумайте (или узнайте!) о том, что важно для ваших пользователей, а не о том, что вы можете измерить. Зачастую то, что важно для пользователей, трудно или невозможно измерить, поэтому вам придется хотя бы приблизительно оценить их потребности. Однако если вы просто возьмете в качестве показателей то, что легко измерить, вы получите менее полезные SLO. Таким образом, мы выяснили, что лучше двигаться от желаемых целей к конкретным показателям, чем сначала выбирать показатели и лишь затем ставить цели.
Определение целей
Для максимальной прозрачности SLO должны содержать информацию о том, как их измерять, а также условия, при которых они будут действительны. Например, мы можем указать следующее (вторая строка похожа на первую, но здесь мы использовали стандартные умолчания для определений показателей из предыдущего раздела, чтобы не писать лишнюю информацию):
• 99 % (в среднем за одну минуту) вызовов RPC Get будут завершены менее чем за 100 миллисекунд (измеряется для всех бэкенд-серверов);
• 99 % вызовов RPC Get будут завершены менее чем за 100 миллисекунд.
Если вам важна форма кривых производительности, можете указать в SLO несколько целевых значений:
• 90 % вызовов RPC Get будут завершены менее чем за 1 миллисекунду;
• 99 % вызовов RPC Get будут завершены менее чем за 10 миллисекунд;
• 99,9 % вызовов RPC Get будут завершены менее чем за 100 миллисекунд.
Если у вас есть пользователи с неоднородной загруженностью (вроде конвейера обработки массивов данных), для которых важна пропускная способность, и интерактивный клиент, для которого важно время отклика, то для каждого вида рабочей нагрузки лучше задать отдельные целевые показатели качества:
• 95 % вызовов RPC Set, для которых важна пропускная способность, будут завершены менее чем за 1 секунду;
• 99 % вызовов RPC Set, для которых важна величина задержки и которые имеют нагрузку меньше 1 Кбайт, будут завершены менее чем за 10 миллисекунд.
Настаивать на том, чтобы SLO соблюдались 100 % времени, нереально и нежелательно: это может привести к снижению скорости развертывания и внедрения изменений, а также потребовать применения дорогих или излишне консервативных решений. Вместо этого лучше установить допустимый суммарный уровень ошибок — уровень допускаемого несоответствия SLO — и ежедневно или еженедельно отслеживать его выполнение. А ваши руководители, возможно, захотят также видеть ежемесячный или ежеквартальный отчеты по использованию бюджета ошибок. (Суммарный уровень ошибок — это SLO, отражающий соответствие другим SLO!)
Уровень несоответствия SLO — это полезный индикатор исправности сервиса с точки зрения пользователя. Ежедневное или еженедельное отслеживание SLO (и их нарушений) полезно тем, что вы сможете увидеть характер изменений и узнать о потенциальных проблемах еще до того, как они произойдут. Ежемесячный или ежеквартальный отчеты могут пригодиться руководству.
Выбор целевых показателей
Выбор целевых показателей (SLO) — это не совсем техническая задача, поскольку в выбранных SLI и SLO (и, возможно, SLA) должны быть также отражены интересы продукта и бизнеса. Аналогично может потребоваться отдать предпочтение тем или иным характеристикам продукта из-за ограничений, накладываемых кадровым составом, сроками выхода продукта на рынок, доступностью аппаратных средств и финансирования. Отдел SRE должен быть частью этого диалога, он участвует в оценке рисков и целесообразности различных вариантов. Мы усвоили несколько уроков, которые могут помочь вам принять более продуктивное решение.
• Не выбирайте цель, основываясь на текущей производительности. Конечно, очень важно понимать характеристики и ограничения системы. Но принятие целевых значений без их критического осмысления может завести вас в тупик: обеспечение соответствия системы заданным показателям будет требовать героических усилий, но ее невозможно будет улучшить без значительной перестройки.
• Не усложняйте. Сложные варианты агрегирования значений SLI могут маскировать изменения в производительности системы. Кроме того, их труднее обрабатывать.
• Не гонитесь за абсолютом. Очень заманчиво потребовать систему, которая может «бесконечно» масштабировать свою нагрузку и которая «всегда доступна». Но в жизни такие требования оказываются нереальными. Даже систему, которая лишь приближается к идеальным значениям, нужно будет очень долго разрабатывать и строить. Эксплуатировать ее также будет очень дорого — и вполне возможно, что она окажется лучше, чем того хотят пользователи.
• Имейте минимальное количество SLO. Выберите те SLO, которых будет достаточно для получения полной информации о характеристиках системы. Обосновывайте необходимость выбранных SLO: если вы не можете победить в дискуссии о приоритетах развития, процитировав нужный SLO, то вам, возможно, лучше избавиться от него. Однако не все характеристики продукта подчиняются SLO: с их помощью, например, трудно выразить уровень «восхищения пользователя».
• Идеал может подождать. Со временем, по мере изучения поведения системы, вы можете совершенствовать определения SLO и целевых значений. Сначала лучше задать в качестве целевого примерное значение, которое вы сможете уточнить позже, а не устанавливать сразу четкое значение и затем снижать его, обнаружив его недостижимость.
SLO могут — и должны — стать главным двигателем при определении приоритетных задач для отдела SRE и разработчиков продукта, поскольку они отражают то, что важно для пользователей. Хорошо построенные SLO — это полезный весомый фактор воздействия на команду разработки. Плохо продуманные SLO могут привести к пустой трате рабочего времени, если команда прикладывает героические усилия для обеспечения соответствия завышенным SLO, или для выпуска некачественного продукта, если SLO оказались недостаточно жесткими. SLO — это мощный рычаг, и пользоваться им нужно с умом.
SLO как инструмент управления
SLI и SLO являются ключевыми звеньями в цепочке управления системами.
1. Отслеживайте и измеряйте SLI системы.
2. Сравните SLI с SLO и решите, требуется ли вмешательство.
3. Если вмешательство необходимо, определите, что должно измениться или произойти для того, чтобы цель была достигнута.
4. Действуйте.
Например, на шаге 2 обнаруживается рост времени отклика и если ничего не предпринимать, то через несколько часов SLO будут нарушены. Тогда шаг 3 может включать в себя проверку предположения о перегруженности процессоров сервера, а также принятие решения о выделении дополнительных ресурсов с целью перераспределения нагрузки. Без помощи SLO вы бы не узнали, что нужно что-то сделать, и не могли бы определить, когда это делать.
SLO формируют ожидания
Опубликованные SLO устанавливают планку ожиданий относительно характеристик системы и ее поведения. Пользователи сервиса (в том числе потенциальные) зачастую хотят знать, на что они могут рассчитывать, чтобы понять, подходит ли он для них. Например, экономная и эффективная сверхнадежная система с низкой доступностью вряд ли заинтересует команду, планирующую создавать сайт для размещения фотографий, зато она отлично подойдет для системы управления записями архива.
Для того чтобы ожидания пользователей были реалистичными, вы можете воспользоваться следующими тактиками (любой из них или обеими сразу).
• Имейте запас прочности. Применение внутренних SLO, более жестких по сравнению с SLO, показанными пользователям, дает вам пространство для маневра, чтобы отреагировать на хронические проблемы до того, как они станут заметны извне. «Буферная зона» значений SLO позволяет также создавать другие реализации продукта, в которых производительность приносится в жертву другим характеристикам — например, стоимости или простоте обслуживания — и пользователи при этом не будут разочарованы.
• Избегайте перевыполнения. Пользователи в своих действиях исходят из реально предлагаемых, а не из заявляемых характеристик. В частности, это относится к инфраструктурным сервисам. Если производительность вашего сервиса гораздо выше, чем это указано в SLO, пользователи станут полагаться на текущее значение производительности. Вы можете избежать чрезмерной зависимости от качества системы, периодически намеренно отключая ее (например, мы время от времени отключали сервис Chubby, поскольку иначе уровень его доступности был избыточным), ограничивая количество обрабатываемых запросов или проектируя систему так, чтобы она работала с одинаковой скоростью при разных нагрузках.
Понимание того, насколько система соответствует предъявляемым к ней требованиям, поможет решить, следует ли вкладываться в повышение ее производительности, доступности и устойчивости. В противном случае, если сервис работает достаточно хорошо, время ваших сотрудников, возможно, лучше потратить на другие задачи, например на устранение старых недоработок, добавление новых функций или создание новых продуктов.
Соглашения на практике
Создание SLA требует от команд, отвечающих за ведение бизнеса и юридические вопросы, определить соответствующие меры и штрафы, которые будут применены в случае нарушения соглашений. Роль отдела SRE заключается в том, чтобы помочь им понять реалистичность и сложность выполнения SLO, содержащихся в SLA. Большая часть советов по созданию SLO применима и к созданию SLA. Лучше консервативно подойти к тому, что вы рекламируете потребителям, поскольку чем шире будет круг ваших пользователей, тем сложнее будет в дальнейшем изменить или удалить SLA, которые оказались необоснованными или трудновыполнимыми.
Два различных исходных термина (indicator и objectives) приходится переводить одним и тем же словом «показатель», но во втором случае с добавлением «целевой». Нужно помнить: показатель — наблюдаемая количественная характеристика, а целевой показатель — характеристика более высокого порядка, определяемая через желаемые значения показателей и успешность/неуспешность их выполнения. — Примеч. пер.
Сто миллисекунд — это произвольное значение, но, как правило, чем меньше время отклика, тем лучше. Эти причины помогают поверить в то, что «быстрее» лучше, чем «медленнее», и что величина задержки свыше некоторого значения может оттолкнуть пользователей. Обратитесь к статье Speed Matters [Brutlag, 2009] для получения более подробной информации.
Заметим, что в приведенном примере источником проблем был не Chubby, а зависящие от него прикладные сервисы: их некачественная реализация в большинстве случаев компенсировалась качеством инфраструктурного сервиса, и лишь когда эта компенсация не срабатывала, происходил реальный сбой. Радикальные меры (искусственные «аварии») потребовались для того, чтобы разработчики зависимых сервисов выполняли свою работу с должным качеством (а руководство согласилось оплатить эту дополнительную работу). — Примеч. пер.
Большинство людей имеют в виду SLO, когда говорят об SLA. Существует один хороший показатель: если кто-то говорит о «нарушении SLA», они говорят о несоответствии требованиям SLO. Реальное нарушение SLA может привести к судебному иску о нарушении контракта.
Если вы вообще не можете победить в дискуссии об SLO, вам, возможно, не стоит привлекать службу SRE для разработки данного продукта.
Метод «внедрения отказов» [Bennett, Tseitlin, 2012] предназначен для других целей, но он также может помочь в формировании уровня ожиданий.

