32. Развитие модели вовлеченности SR-инженеров
Авторы — Акацио Круз и Ашиш Бамбани
Под редакцией Бетси Бейер и Тима Харви
Вовлеченность SR-инженеров: что, как и почему
В большей части этой книги мы рассматривали, что происходит, когда SR-инженер уже находится у руля сервиса. Немногие сервисы начинают свой жизненный цикл, обладая поддержкой SR-инженеров, поэтому должен быть предусмотрен процесс оценки сервиса. Так можно будет убедиться, что сервис достоин поддержки SRE, обсудить способы исправления любых недостатков, которые мешают получить поддержку SRE, и, собственно, добиться этой поддержки. Мы называем данный процесс освоением.
Существует как минимум два оптимальных способа воспользоваться опытом разработчиков производственных систем и службы SRE, актуальных как для старых, так и для новых сервисов. В первом случае, как и при разработке ПО (когда чем раньше найдена ошибка, тем дешевле ее исправить), чем раньше вы проконсультируетесь со специалистами SRE, тем лучше будет сервис и тем быстрее вы почувствуете эффект. Когда SR-инженеры вовлекаются в работу на ранних стадиях проектирования, время освоения сокращается и сервис оказывается надежнее изначально обычно потому, что нам не приходится тратить время на откат неоптимального проекта или реализации.
Еще один способ, возможно самый лучший, — это упрощение процесса, с помощью которого специально созданные системы с большим количеством вариаций «прибывают» к дверям SRE. Предоставьте разработчикам продукта платформу проверенной SR-инженерами инфраструктуры, с помощью которой они будут создавать свои системы. Эта платформа принесет двойную пользу, ведь она будет как надежной, так и масштабируемой. Используя распространенные приемы работы с инфраструктурой, разработчики смогут сконцентрироваться на инновациях уровня приложения.
В следующих разделах мы рассмотрим каждую из этих моделей по очереди, начав с классической модели PRR.
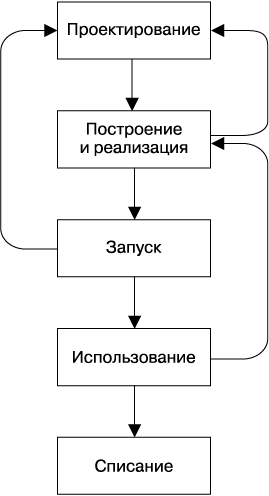
Рис. 32.1. Жизненный цикл типичного сервиса
Модель PRR
Наиболее типичный первый шаг вовлечения SR-инженеров — это проверка готовности продукта (Production Readiness Review, PRR). На этом этапе определяются потребности в надежности для сервиса на основе специфических деталей. Во время PRR SR-инженеры стараются применить все, что они изучили для того, чтобы гарантировать надежность работы сервиса на производстве. Выполнение PRR считается обязательным условием для команды SR-инженеров для принятия ответственности за управление производственными характеристиками сервиса.
На рис. 32.1 показан жизненный цикл типичного сервиса. Проверка готовности продукта может быть начата в любой момент жизненного цикла, но этапы, на которых можно привлечь SR-инженера, со временем могут расширяться. В этой главе мы рассмотрим простую модель PRR и поговорим о том, как ее модификация в расширенную модель вовлечения, а также структура фреймворков и платформы SRE позволили SR-инженерам пересмотреть степень их вовлечения и влияния.
Модель вовлечения SR-инженеров
Служба SRE ответственна за важные сервисы, запущенные в эксплуатацию, и периодически повышает их надежность. SR-инженеры отвечают за несколько характеристик сервиса, которые вместе называются промышленным окружением. Это следующие характеристики:
• системная архитектура и зависимости между сервисами;
• инструментарий, показатели и мониторинг;
• реагирование на чрезвычайные ситуации;
• планирование производительности;
• управление изменениями;
• производительность: доступность, задержка и эффективность.
Вовлекая SR-инженера в работу над сервисом, мы стремимся улучшить нашу систему по всем этим параметрам, что позволяет проще управлять производством сервиса.
Альтернативная поддержка
Не все сервисы компании Google получают поддержку SR-инженеров. На это влияют несколько факторов:
• многим сервисам не требуется высокая надежность и доступность, поэтому поддержка может быть предоставлена другими средствами;
• по умолчанию количество команд разработчиков, запрашивающих поддержку SRE, слишком велико и имеющаяся команда SR-инженеров не в состоянии обработать все запросы (см. главу 1).
Когда SR-инженеры не могут предоставить полноценную поддержку, они предлагают другие варианты совершенствования сервиса, например документирование и консультирование.
Документация
Руководства по разработке доступны для внутренних технологий и клиентов широко используемых систем. В Production Guide компании Google задокументированы практические рекомендации для работы с сервисами, определенные из опыта SR-инженеров и разработчиков. Разработчики могут реализовывать решения и рекомендации из этих справочных руководств, чтобы улучшать свои сервисы.
Консультации
Разработчикам также может потребоваться консультация SR-инженеров, для того чтобы обсудить конкретные сервисы или проблемные области. Команда инженеров-координаторов запуска (см. главу 27) тратит большую часть своего времени на консультирование команд разработчиков. Бывает, что и сами SR-инженеры делают это.
Когда запускается новый сервис или внедряется новая функциональность, разработчики обычно консультируются с SR-инженерами о том, как лучше подготовиться к этапу запуска. На консультациях о запуске обычно присутствуют один или два SR-инженера, которые тратят несколько часов на изучение проекта. Далее консультанты встречаются с разработчиками и рассказывают об уязвимых местах, которые требуют внимания, а также обсуждают распространенные решения, которые могут быть внедрены для улучшения сервиса на производстве. Некоторые из этих советов можно почерпнуть из Production Guide, упомянутого ранее.
На подобных консультациях всегда касаются лишь вершины айсберга, поскольку невозможно глубоко вникнуть в суть заданной системы за ограниченный промежуток времени. Некоторым разработчикам таких консультаций оказывается недостаточно.
• Сервисы, которые выросли на несколько порядков после своего запуска и теперь требуют большего времени на изучение, при этом рассмотрения документации и консультирования недостаточно.
• Сервисы, от которых зависит множество других сервисов и которые теперь принимают значительно больше трафика от разных клиентов.
Когда сервисы разрослись до такой степени, что начали сталкиваться со значительными трудностями на производстве, одновременно становясь все более важными для пользователей, вовлечение SR-инженеров попросту необходимо — сервисы должны поддерживаться на производстве по мере их роста.
Проверка готовности продукта: простая модель PRR
Когда команда разработчиков просит SR-инженеров взяться за управление работой сервиса на производстве, SRE оценивают как важность сервиса, так и доступность команд SR-инженеров. Если сервис заслуживает поддержки SRE, а команда SR-инженеров и разработчики приходят к соглашению по поводу объема штата для осуществления этой поддержки, то служба SRE запускает проверку готовности продукта с помощью команды разработчиков.
Цели проверки готовности продукта заключаются в следующем.
• Убедиться, что сервис соответствует принятым стандартам организации производства и операционной готовности и что владельцы сервиса готовы работать с SR-инженерами и пользоваться их знаниями.
• Улучшить надежность сервиса в промышленной эксплуатации и минимизировать количество и степень тяжести ожидаемых инцидентов. PRR нацеливается на все аспекты производства, о которых заботится служба SRE.
После того как будет сделана работа над ошибками и сервис покажется готовым к поддержке SRE, команда SR-инженеров приступает к своим обязанностям.
Это приводит нас к самому процессу проверки готовности продукта. Существует три разных модели вовлечения, связанные друг с другом (простая модель PRR, модель раннего вовлечения, а также фреймворки и платформа SRE). Мы рассмотрим их по очереди.
Сначала мы разберем простую модель PRR, которая обычно нацелена на уже запущенные сервисы, которые должна перехватить команда SR-инженеров. PRR состоит из нескольких фаз, как и жизненный цикл разработки, хотя эта проверка может выполняться параллельно с ним и независимо от него.
Вовлечение
Руководители службы SRE сначала решают, какая команда SR-инженеров подойдет для работы над сервисом.
Обычно выбирают 1–3 SR-инженеров. Эта небольшая группа начинает работу с совещания с командой разработки. На нем рассматриваются следующие темы.
• Установление SLO/SLA для сервиса.
• Планирование потенциального переформатирования проекта, необходимое для повышения надежности.
• Планирование расписания обучения.
Цель этого этапа заключается в том, чтобы прийти к соглашению о процессе, конечных целях и результатах, что необходимо для вовлечения команды SR-инженеров в работу над сервисом.
Анализ
Анализ — это первый крупный этап работы. Во время этого этапа наблюдатели из SRE изучают сервис и начинают анализировать его недостатки. Они стремятся измерить уровень развития сервиса, а также другие показатели, критически важные для SR-инженеров. Они также исследуют проект сервиса и его реализацию, чтобы убедиться в том, что выбраны подходящие методы производства. Обычно команда SR-инженеров создает и поддерживает чек-лист PRR непосредственно для этапа анализа. Чек-лист уникален для сервиса и, как правило, основан на опыте работы в конкретной области, а также на опыте работы со связанными или похожими системами. В нем также учтены передовые методики из Production Guide. Команда SR-инженеров также может консультироваться с другими командами, имеющими больший опыт работы с определенными компонентами или зависимостями сервиса.
Рассмотрим примеры элементов чек-листа.
• Влияют ли обновления сервиса одновременно на непомерно большую часть системы?
• Соединяется ли сервис с соответствующими обслуживающими экземплярами своих зависимостей? Например, запросы конечного пользователя к сервису не должны зависеть от системы, которая разработана для пакетной обработки данных.
• Запрашивает ли сервис от сети достаточно высокий уровень качества обслуживания (QoS) при взаимодействии с критически важным удаленным сервисом?
• Отправляет ли сервис информацию об ошибках в центральную систему журналирования для анализа? Сообщает ли он обо всех исключительных ситуациях, которые привели к появлению неподходящих ответов или сбоев, видимых конечным пользователям?
• Наблюдаете ли вы за всеми сбоями запросов, заметными пользователям? Настроена ли у вас система оповещения?
Чек-лист также может включать операционные стандарты и практические рекомендации, которыми пользуется определенная команда SR-инженеров. Например, идеально работающая конфигурация сервиса, которая не соответствует «золотым стандартам» команды SR-инженеров, может быть переписана для того, чтобы использовать инструменты SRE для управления масштабирующимися конфигурациями. SR-инженеры проверяют информацию о недавних происшествиях и постмортемы, а также смотрят, какие действия были выполнены после инцидентов. В результате этого анализа они определяют потребность сервиса в реагировании на чрезвычайные ситуации и доступность проверенных операционных элементов управления.
Улучшения и рефакторинг
На этапе анализа определяется, как еще нужно доработать сервис. Это будет очередной шаг, который заключается в следующем.
1. Улучшения приоритизируются в зависимости от их важности для надежности сервиса.
2. Приоритеты рассматриваются вместе с командой разработчиков, затем утверждается план выполнения.
3. Команды SR-инженеров и разработчиков продукта выполняют рефакторинг частей сервиса или реализуют дополнительную функциональность, помогая друг другу.
Продолжительность этого этапа и объем затрачиваемых усилий обычно изменяются от сервиса к сервису. Они также зависят от доступности времени инженеров для рефакторинга, от уровня развития и сложности сервиса в начале обзора, а также от множества других факторов.
Обучение
Ответственность за управление «промышленным» сервисом нередко лежит на всей команде SR-инженеров. Для того чтобы гарантировать, что команда готова, наблюдатели из SRE, выполнявшие PRR, начинают руководить процессом обучения команды. Этот процесс обычно включает в себя изучение всей документации, необходимой для поддержки сервиса. При участии команды разработчиков SR-инженеры выполняют различные задания и упражнения. Это могут быть:
• обзор проекта;
• погружения в разнообразные потоки запросов системы;
• описание настройки промышленного окружения;
• опыт из первых рук для разных показателей работы системы.
По завершении обучения команда SR-инженеров должна быть готова к управлению сервисом.
Освоение
Фаза обучения откроет возможность освоения сервиса командой SR-инженеров. Этап освоения включает в себя последовательное перераспределение обязанностей и ответственности за различные части сервиса. Команда SR-инженеров продолжает концентрироваться на разных областях производственной среды, упомянутых ранее. Чтобы можно было запустить сервис в эксплуатацию, команда разработчиков должна быть доступна для оказания поддержки SR-инженерам. Это отношение в дальнейшем станет залогом эффективной непрерывной работы между командами.
Непрерывное улучшение
Популярные сервисы постоянно меняются, подстраиваясь под современные потребности и условия, включая в том числе запросы пользователями новой функциональности, развитие зависимостей системы и обновление технологий. Команда SR-инженеров должна поддерживать стандарты надежности сервиса с учетом этих изменений, непрерывно улучшая его. Ответственная команда SR-инженеров тщательно анализирует работу сервиса во время его использования, обзора изменений, реагирования на инциденты и особенно при написании постмортемов и поиске основных причин. В дальнейшем результаты такого анализа передаются команде разработчиков как указания и рекомендации по внесению изменений в сервис: добавлению новой функциональности, компонентов и зависимостей. Уроки, усвоенные в ходе управления сервисом, также сохраняются в виде практических рекомендаций, которые задокументированы в Production Guide и других источниках.
| Вовлекаемся в работу над сервисом Shakespeare Изначально ответственность за сервис Shakespeare несли его разработчики. Ответственность заключалась в том, что они носили пейджеры, сигнализировавшие об аварийных ситуациях. Однако по мере повышения популярности сервиса и увеличения его прибыльности появилась необходимость в поддержке SRE. Продукт уже был запущен, поэтому SR-инженеры проверили его готовность. Помимо всего прочего, они обнаружили, что информационные панели охватывали не все показатели, определенные в SLO, что требовалось исправить. После того как все проблемы были устранены, SR-инженеры взяли на себя обязанности по реагированию на аварийные ситуации, однако на дежурства ходят и два разработчика сервиса. Разработчики еженедельно проводят собрания, куда зовут и дежуривших работников, где обсуждаются проблемы, появившиеся на прошлой неделе, и способы преодоления грядущих крупномасштабных сбоев или отключений кластера. Предстоящие планы по развитию сервиса обсуждаются и с SR-инженерами, чтобы убедиться, что новые запуски пройдут идеально (однако не забывайте про закон Мерфи, который способен нарушить идиллию). |
Развиваем простую модель PRR: раннее вовлечение
Итак, мы обсудили проверку готовности продукта в виде простой модели PRR, которую можно использовать для сервисов, уже вышедших на стадию запуска. Существует несколько ограничений и условий, связанных с этой моделью.
• Дополнительное взаимодействие между командами может усложнить некоторые виды деятельности команды разработчиков и повысить нагрузку на наблюдателей из SRE.
• Наблюдатели из SRE должны быть доступны и обязаны правильно распределять свои приоритеты и рабочее время.
• Работа, выполняемая SRE, должна быть заметна и достаточно проанализирована командой разработчиков для того, чтобы гарантировать эффективный обмен знаниями. SR-инженеры обязаны, по сути, работать как часть команды разработчика, а не как внешний элемент.
Однако основное ограничение модели PRR вытекает из того факта, что сервис уже запущен и широко развернут, а вовлечение SR-инженеров начинается на очень поздних этапах жизненного цикла разработки. Если PRR будет происходить на более ранних этапах создания сервиса, возможность SR-инженеров исправить его потенциальные проблемы значительно увеличится. В результате успех вовлечения SR-инженеров и будущий успех сервиса, скорее всего, тоже возрастут.
Кандидаты для раннего вовлечения
Модель раннего вовлечения позволяет SR-инженерам раньше начать работать с сервисом для того, чтобы получить существенные дополнительные преимущества. Применение такой модели требует определения важности и/или бизнес-ценности сервиса на ранних этапах жизненного цикла разработки, а также определения того, будет ли сервис масштабироваться или усложняться до такой степени, чтобы ему потребовалась поддержка SR-инженера. К таковым относятся сервисы, которые отвечают следующим условиям.
• Сервис реализует заметную новую функциональность и является частью существующей системы, уже управляемой службой SRE.
• Сервис представляет собой значительно измененную или альтернативную версию существующей системы.
• Команда разработки просит совета у SR-инженеров или предлагает им принять ответственность за сервис после его запуска.
Модель раннего вовлечения, по сути, погружает SR-инженеров в процесс разработки. Они концентрируются на тех же показателях, но способы создания сервиса будут отличаться. SR-инженеры участвуют в работе на стадии проектирования и более поздних этапах, в итоге принимая на себя управление сервисом в любой момент во время или после его сборки. Эта модель основана на активном взаимодействии между командами разработчиков и SR-инженеров.
Преимущества модели раннего вовлечения
Несмотря на то что модель раннего вовлечения связана с некоторыми рисками и сложностями, дополнительное участие SR-инженеров на протяжении всего жизненного цикла продукта дает значительные преимущества по сравнению с вовлечением, выполненным на более поздних этапах жизненного цикла сервиса.
Фаза проектирования
Участие SR-инженеров в проектировании может предотвратить множество проблем или инцидентов, которые могли бы случиться позже на производстве. Хотя решения по проекту могут быть отменены или исправлены на более поздних этапах жизненного цикла, такие изменения будут стоить дороже с точки зрения затраченных усилий и сложности. Лучшие инциденты — те, которые никогда не происходят!
Необходимость время от времени искать компромиссы приводит к созданию неидеального проекта. Участие SR-инженеров в проектировании означает, что им заранее известно об этих компромиссах и они частично ответственны за решение использовать неидеальный вариант. Раннее вовлечение службы SRE позволит минимизировать будущие споры насчет проекта, которые могут произойти, когда сервис поступит в промышленную эксплуатацию.
Сборка и реализация
На этапе сборки принимаются решения по техническим характеристикам. Сюда относятся выбор инструментов и определение показателей, управление аварийными ситуациями и плановой работой, использование ресурсов и установка эффективности. На этой стадии SR-инженеры могут повлиять на реализацию проекта и улучшить ее, порекомендовав определенные библиотеки и компоненты или оказав помощь при сборке некоторых элементов управления для системы. Участие службы SRE на данном этапе помогает упростить использование сервиса в будущем и позволяет SR-инженерам получить опыт работы с ним еще до его запуска.
Запуск
SR-инженеры также могут помочь в реализации популярных методов запуска. К одному из них относится «темный запуск», при котором часть трафика существующих пользователей направляется на новый сервис в дополнение к тому, что она поступает и на уже работающую промышленную версию сервиса. Ответы нового сервиса будут считаться «темными», поскольку они не учитываются и не показываются пользователям. Такие приемы позволяют команде понять, как работает сервис, и решить проблемы, не затрагивая существующих пользователей, тем самым снизив риск появления этих проблем после запуска. Постепенный запуск значительно снижает уровень операционной нагрузки и дает команде разработчиков возможность в спокойном режиме исправлять все ошибки и продолжать работать над будущей функциональностью.
После запуска
Если система стабильна во время запуска, то в дальнейшем команде разработчиков не приходится выбирать между улучшением надежности сервиса и добавлением новой функциональности. На более поздних этапах развития сервиса уже будет понятно, требуется рефакторинг или полная смена проекта.
При полноценном участии команда SR-инженеров может быть готова взять на себя управление новым сервисом гораздо раньше, чем это было бы возможно при простой модели PRR. Чем дольше и глубже SR-инженеры вовлекаются в работу над сервисом, тем выше вероятность того, что команды SR-инженеров и разработчиков наладят эффективные отношения, которые со временем будут только укрепляться.
Отстранение от сервиса
Иногда сервису не требуется полноценное управление со стороны SRE — это можно определить после запуска. Или же SR-инженеры могут вовлекаться в работу над сервисом, но не брать на себя управление им. Это говорит о том, что сервис надежный, почти не требует обслуживания и его поддержку способна выполнять команда разработчиков.
Возможны также ситуации, когда SR-инженер вовлекается в работу над сервисом, но нагрузка не соответствует прогнозируемой. В таких случаях усилия, приложенные SR-инженерами, оказываются частью бизнес-риска, который характерен для новых проектов. Команда SR-инженеров может быть перенаправлена для работы над другим проектом, и полученный ими опыт может быть применен в процессе вовлечения.
Развитие процесса разработки сервисов: фреймворки и платформа SRE
Модель раннего вовлечения стала серьезным шагом в развитии модели вовлечения SR-инженеров за пределы PRR, которая могла быть применена только к уже запущенным сервисам. Однако нам все еще предстояло «масштабировать» вовлечение SR-инженеров на следующий уровень, обеспечив еще большую надежность.
Усвоенные уроки
Со временем на базе модели вовлечения SR-инженеров, описанной ранее, было выведено несколько закономерностей.
• Освоение каждого сервиса требовало 2–3 SR-инженеров и, как правило, продолжалось 2–3 квартала. Период освоения для PRR было относительно большим (несколько кварталов). Уровень требуемых усилий был пропорционален числу наблюдаемых сервисов и был ограничен незначительным количеством SR-инженеров, доступных для выполнения PRR. Эти условия привели к разделению сервисов на определенные группы и четкой их приоритизации.
• Из-за того, что для разных сервисов применялись разные методики, каждый участок функциональности реализовывался по-разному. Для того чтобы соответствовать стандартам PRR, функциональность должна была быть повторно реализована отдельно для каждого сервиса или в лучшем случае один раз для каждого подмножества сервисов, использовавших одинаковый код. Эти повторные реализации были бесполезной тратой времени инженеров. Один из типичных примеров — реализация функциональности похожих фреймворков журналирования на одном и том же языке из-за того, что у разных сервисов различалась структура кода.
• Обзор распространенных проблем и сбоев сервисов выявил определенные закономерности, но не было способа быстро решить проблему и доработать одновременно все сервисы. Типичный пример — перегрузка сервисов.
• Вклад SR-инженеров в разработку ПО зачастую был лишь локальным — ограничивался конкретным сервисом. Поэтому оказывалось непросто вывести общие решения, которые впоследствии можно использовать повторно. Из-за этого не существовало простого способа применить новые знания и практические навыки, полученные отдельными командами SR-инженеров, для всех сервисов, которые они поддерживали.
Внешние факторы, влияющие на SRE
Внешние факторы традиционно влияют несколькими способами на организацию SRE и ее ресурсы.
Компания Google все больше следует тренду отрасли, заключающемуся в использовании микросервисов. В результате количество запросов на поддержку SRE и количество сервисов, претендующих на такую поддержку, увеличивается. Поскольку каждый сервис отличается конкретными издержками на сопровождение, даже простые сервисы требуют участия большого количества людей. Микросервисы также предполагают меньший срок развертывания, что было невозможно при использовании предыдущей модели PRR (период разработки длился несколько месяцев).
Наем опытных, квалифицированных SR-инженеров будет дорого стоить. Несмотря на значительные усилия организаций, занимающихся наймом, SR-инженеров для всех нуждающихся в поддержке сервисов всегда не хватает. Обучение такого специалиста длится дольше, чем обучение разработчика.
Наконец, служба SRE ответственна за обслуживание запросов большого и постоянно растущего количества команд разработчиков, которые в данный момент не пользуются поддержкой SR-инженеров. В связи с этим есть необходимость расширить сферу поддержки SRE за пределы исходной модели сотрудничества.
На пути к структурному решению: фреймворки
Для того чтобы эффективно отреагировать на эти запросы, было принято решение разработать модель, учитывающую следующее.
• Закодированные лучшие практические приемы. Возможность зафиксировать в коде то, что хорошо работает в условиях промышленной эксплуатации, чтобы разработчики сервисов могли легко использовать этот код и создавать свои сервисы сразу «готовыми к выходу на производство».
• Решения, используемые повторно. Популярные и простые реализации методов, которые можно использовать для сокращения количества проблем с надежностью и масштабируемостью.
• Общепринятая платформа продукта с унифицированным уровнем управления. Одинаковые наборы интерфейсов для производства, одинаковые наборы операционных элементов управления и одинаковое журналирование и конфигурация для всех сервисов.
• Упрощенная автоматизация и гибкая система. Унифицированный уровень управления, который позволяет выполнять автоматизацию и создавать гибкие системы на новом уровне. Например, SR-инженеры всегда готовы получить релевантную информацию о сбое из одного достоверного источника, вместо того чтобы собирать вручную и анализировать необработанные данные из разных мест (журналы, данные системы мониторинга и т.д.).
На основе этих принципов был создан набор платформ и служебных фреймворков, поддерживаемый SRE, по одному для каждой обслуживаемой нами системы (Java, C++, Go). Сервисы, построенные с использованием этих фреймворков, имеют общую реализацию. Она спроектирована так, чтобы работать внутри платформы, поддерживаемой SR-инженерами, и обслуживаться командами SR-инженеров и разработчиков. Основное изменение, привнесенное этими фреймворками, заключалось в том, что разработчики теперь могли использовать готовые решения, которые были созданы и одобрены SR-инженерами, а не изменять приложения по спецификациям SRE постфактум либо вовлекать множество SR-инженеров для поддержки сервисов, значительно отличающихся от других сервисов нашей компании.
Приложение обычно содержит бизнес-логику, которая, в свою очередь, зависит от множества инфраструктурных компонентов. Опасения SR-инженеров на тему производственной среды касаются связанных с инфраструктурой частей сервиса. Фреймворки сервисов реализуют код инфраструктуры стандартизированным способом и решают многие производственные задачи. Любая задача инкапсулирована в один или несколько модулей фреймворка, каждый из которых предоставляет целостное решение для проблемной области или зависимости инфраструктуры. Модули фреймворка решают проблемы:
• инструментария и показателей;
• журналирования запросов;
• систем управления, включающих управление трафиком и нагрузкой.
SR-инженеры создают модули фреймворка для того, чтобы реализовать конкретные решения для требуемой производственной области. В результате команды разработчиков могут сконцентрироваться на бизнес-логике, поскольку фреймворк сам по себе заботится о корректном использовании инфраструктуры.
Фреймворк, по сути, является источником программных компонентов и предлагает определенный способ их объединения. Он также может предоставлять функциональность для управления разными компонентами, например следующее.
• Бизнес-логику, организованную в виде структурированных семантических компонентов, которые можно обозначать стандартными терминами.
• Стандартные единицы измерения для инструментария мониторинга.
• Общепринятый формат для журналов отладки запросов.
• Стандартный формат конфигурации для управления сегментацией нагрузки.
• Производительность одного сервера и определение «перегрузки» не противоречат друг другу и могут характеризовать оперативность обратной связи при работе с различными управляющими системами.
Фреймворки повышают согласованность и эффективность работы. Они освобождают разработчиков от необходимости объединять и конфигурировать отдельные потенциально несовместимые компоненты, которые затем должны будут пройти проверку SR-инженеров. Они предлагают единое популярное решение задач промышленно эксплуатируемых сервисов, а это означает, что такие сервисы будут иметь одинаковую реализацию и минимальные различия в конфигурации.
Компания Google использует для разработки приложений несколько полнофункциональных языков программирования, и фреймворки реализованы для каждого из этих языков. Несмотря на то что разные реализации фреймворка (например, С++ против Java) не могут иметь общий код, их цель заключается в том, чтобы предоставлять одинаковые API, поведение, конфигурацию и элементы управления для однотипных задач. Поэтому команды разработчиков могут выбирать языковую платформу, которая лучше всего подходит их запросам и опыту, а SR-инженеры — ожидать привычного поведения на производстве и стандартных инструментов для управления сервисом.
Преимущества новой модели обслуживания и управления
Структурный подход, основанный на фреймворках сервисов, единой производственной платформе и единой системе управления, дает множество преимуществ.
Значительно снижена операционная нагрузка
Производственная платформа, построенная на основе фреймворков с четко прописанными соглашениями, значительно снижает операционную нагрузку по следующим причинам.
• Поддерживает проверки совместимости для кодовой структуры, зависимостей, тестов, руководств по стилю кодирования и т.д. Эта функциональность также гарантирует конфиденциальность данных пользователя, тестирование и совместимость с системой безопасности.
• Предоставляет встроенную функциональность развертывания, мониторинга и автоматизации для всех сервисов.
• Позволяет проще управлять большим количеством сервисов, особенно микросервисов, число которых постоянно увеличивается.
• Дает возможность быстрее развертывать сервисы: путь от идеи до полностью развернутой качественной системы может быть пройден всего за несколько дней!
Универсальная поддержка по умолчанию
Постоянный рост количества сервисов в нашей компании означает, что бо'льшая их часть либо не требует вовлечения SR-инженеров, либо просто ими не поддерживается. Независимо от этого сервисы, которые не получают полной поддержки службы SRE, могут быть построены так, чтобы использовать производственную функциональность, которая разработана SR-инженерами. Распространение поддерживаемых SR-инженерами производственных стандартов и инструментов для всех команд улучшает общее качество обслуживания в компании Google. Помимо этого, все сервисы, которые реализованы на базе фреймворков, автоматически обновляются, когда вносятся изменения в модули соответствующих фреймворков.
Быстрое вовлечение с низкими издержками
Подход с использованием фреймворков приводит к более быстрому выполнению PRR, поскольку мы можем рассчитывать:
• на встроенную функциональность сервисов как часть реализации фреймворка;
• быстрейшее освоение сервисов (обычно выполняется одним SR-инженером примерно за квартал);
• снижение когнитивной нагрузки для команд SR-инженеров, управляющих сервисами на базе фреймворка.
В результате командам SR-инженеров не приходится тратить много времени на оценку сервиса для его освоения и они могут поддерживать высокую планку качества обслуживания.
Новая модель вовлечения, основанная на общей ответственности
Оригинальная модель вовлечения SR-инженеров предлагала всего два варианта: либо полную поддержку, либо полное ее отсутствие.
Наличие производственной платформы, предлагающей распространенную структуру сервиса, соглашения и программную инфраструктуру, сделало возможным тот факт, что команда SR-инженеров отвечает за инфраструктуру «платформы», а команды разработчиков предоставляют поддержку на дежурстве при возникновении проблем с функциональностью — багов в коде приложения. С учетом этой модели SR-инженеры предполагают, что на них лежит ответственность за разработку и обслуживание крупных фрагментов инфраструктуры сервисов, а также систем управления распределением нагрузки, перегрузкой, автоматизацией, трафиком, журналированием и мониторингом.
Эта концепция не соответствует изначально принятому способу управления сервисом. Она влечет за собой новую модель взаимоотношений между командами SR-инженеров и разработчиков, а также новую технологию найма персонала для управления сервисами, которые должны поддерживаться SR-инженерами.
Итоги главы
Надежность сервиса может быть повышена путем вовлечения SR-инженеров, задача которых состоит в систематическом анализе и улучшении его производственных показателей. Изначальный системный подход SR-инженеров компании Google — простой анализ готовности к запуску — значительно усовершенствовался, но его все еще можно было применять только для тех сервисов, которые уже перешли на стадию запуска.
Со временем в Google SRE расширяли и улучшали эту модель. Модель раннего вовлечения подразумевала присоединение SR-инженеров на более ранних этапах жизненного цикла, чтобы они выполняли «проектирование для надежности».
Спрос на SR-инженеров продолжал расти, и необходимость более масштабируемой модели вовлечения стала очевидной. В итоге начали активно разрабатывать фреймворки для производственных сервисов. Их использование значительно упростило процесс сборки сервисов, готовых к передаче в промышленную эксплуатацию.
Все три описанные модели вовлечения все еще используются в компании Google. Однако в Google при создании рабочих производственных систем все активнее применяются фреймворки; эта же практика помогает принципиально усилить проникновение SRE на всех уровнях и тем самым снизить издержки на управление сервисами и повысить (минимальную) планку качества обслуживания в рамках всей организации.
См. страницу «Википедии», посвященную микросервисам: .
Не считая того, что время от времени команды SR-инженеры консультировали разработчиков неосвоенных сервисов.
Новая модель управления сервисом меняет схему найма персонала с двух сторон: во-первых, поскольку почти все сервисы созданы с применением одинаковых технологий, для их поддержки требуется меньше SR-инженеров; во-вторых, она позволяет создавать производственные платформы с разделением зон ответственности между поддержкой самой платформы (выполняется SR-инженерами) и поддержкой логики, уникальной для сервиса, которая остается за командой разработчиков. Команды наполняются с учетом необходимости обслуживать платформу, а не из-за увеличения количества сервисов и могут работать с несколькими продуктами.

