12. Эффективная диагностика и решение проблем
Автор — Крис Джоунс
Имейте в виду: чтобы быть экспертом, мало знать, как работает система. Настоящие знания приходят с изучением причин, почему система не работает.
Брайан Редман
Правильное функционирование чего-либо — особый случай среди многих случаев неправильного.
Джон Олспоу
Выявление и устранение проблем — необходимый навык для каждого, кто работает с распределенными компьютерными системами — особенно SRE, — однако он часто рассматривается как врожденный, которым кто-то обладает, а кто-то — нет. Причина в том, что это дело привычно для тех, кто занимается им регулярно. Объяснять, как решать проблемы, так же сложно, как объяснять, как ездить на велосипеде. Но мы уверены, что этому можно научить и можно научиться.
Новички часто ошибаются при решении возникших проблем. Этот процесс зависит от двух факторов: от знания хорошей стратегии решения проблем (вне зависимости от системы) и хороших знаний конкретной системы. Хотя проблему можно исследовать, пользуясь только общими методиками и правилами, такой подход обычно менее эффективен, чем основанный на понимании работы системы. Именно такие знания ограничивают эффективность SRE в новой системе. Не существует полноценной замены знаниям о том, как система построена и как она работает.
Рассмотрим общую модель процесса решения проблем. Читатели, уже имеющие опыт в этом деле, могут не согласиться с описанным далее. Если ваш метод для вас удобен и результативен, нет никаких причин изменять своим привычкам.
Теория
С формальной точки зрения процесс диагностики и решения проблем можно представить как применение гипотетически-дедуктивного метода. Используя результаты наблюдений за системой и теоретические основы для понимания ее поведения, мы последовательно выдвигаем и проверяем гипотезы о причинах произошедшей ошибки.
В идеализированной модели, как на рис. 12.1, мы бы начали с изучения отчета об ошибке, который бы сообщал, что с системой что-то не так. Затем мы проверили бы результаты телеметрии и журналы системы, чтобы узнать о текущем состоянии. С этой информацией и со знанием того, как построена система, как она себя ведет и как распознает ошибки, уже можно предположить возможные причины проблемы.
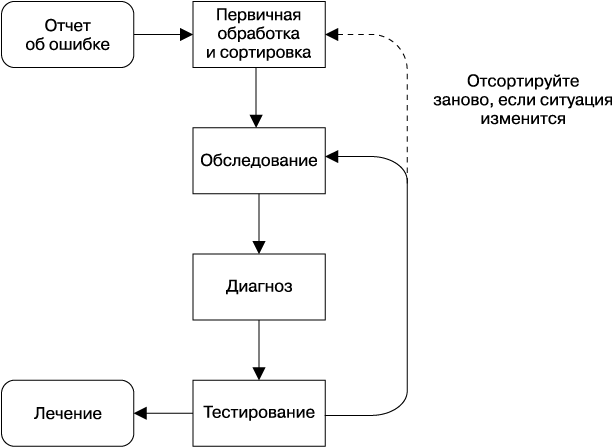
Рис. 12.1. Процесс диагностики и решения проблемы
После этого можно начинать проверять свои предположения, используя один из двух возможных подходов. Мы можем сравнивать текущее состояние системы со своим предположением в поисках подтверждающих или опровергающих доказательств. Или в некоторых случаях можем специально изменить поведение системы, чтобы понаблюдать за результатом. Второй подход углубляет наше понимание состояния системы и возможных причин проблемы. Используя обе стратегии, мы постоянно тестируем систему, пока не найдем источник проблемы, после чего можно принять комплекс мер по устранению и предотвращению ее в будущем и написать отчет. Конечно, непосредственно устранение проблемы должно быть на первом месте, а поиск причин и написание отчета — уже после этого.
| Типичные подводные камни Случаи неэффективного решения возникающих проблем часто бывают результатом ошибок и недоработок на стадиях первичной обработки и сортировки, обследования и диагноза. Обычно эти ошибки и недоработки возникают от недостаточно глубокого понимания системы. Вот типичные подводные камни, которых следует избегать. Мартышкин труд по изучению симптомов, которые не относятся к делу или создают неверную картину состояния системы. Отсутствие понимания того, что и как можно изменить в системе, в ее входных данных и ее окружении для безопасной и эффективной проверки своих гипотез. Рассматривание самых невероятных гипотез о причинах неполадок или, наоборот, зацикливание на причинах предыдущих ошибок в расчете, что они повторятся и на этот раз. Поиск кажущихся зависимостей, которые могут оказаться случайными или же быть связаны с другими проблемами. Избегание первой и второй ловушек — это вопрос знания системы и наличия опыта работы с общепринятыми паттернами, которые используются в распределенных системах. Третья ловушка — это набор заблуждений, которых можно избежать, раз и навсегда запомнив, что не все ошибки равновероятны, или, как говорят врачи, «если слышишь стук копыт, думай о лошадях, а не о зебрах»1. Кроме того, |
| помните, что при прочих равных условиях нужно всегда предпочитать более простые объяснения1. Кроме того, всегда следует помнить, что корреляция между событиями не всегда означает наличие причинно-следственной связи2: некоторые взаимосвязанные события, например потеря пакетов и сбои жестких дисков в кластере, могут иметь одну причину (в данном случае перебои питания), но сами сетевые ошибки, очевидно, не будут ни причиной, ни следствием проблем с жесткими дисками. Более того, чем масштабнее и сложнее система, чем больше ее параметров мы анализируем, тем чаще будут встречаться случайно коррелирующие между собой события3. Понимание этих ловушек в наших рассуждениях — это первый шаг к их избеганию и, как следствие, к более эффективному решению проблем. Методологический подход к осознанию того, что мы знаем, чего мы не знаем и что мы должны знать, облегчает понимание того, что пошло не так и как это исправить. |
Практика
На практике, конечно, процесс диагностики и решения проблем никогда не бывает таким простым, как описано в нашей идеализированной модели. Есть несколько способов сделать его менее болезненным и более продуктивным и для того, кто сталкивается с проблемами в системе, и для того, кто отвечает за их решение.
Отчет об ошибках
Любая проблема начинается с отчета: он может быть сгенерирован автоматически, либо ваш коллега может просто сказать, что «система стала медленней». Эффективный отчет должен содержать описание ожидаемого поведения, реального поведения и, если возможно, способов его воспроизведения. В идеале отчеты должны быть написаны в едином стиле и храниться в легкодоступном месте, например в системе баг-трекинга. У наших команд часто есть собственные формы или небольшие веб-приложения, которые запрашивают относящиеся к ошибке в сопровождаемой системе сведения, а затем автоматически генерируют так называемый баг (запись об ошибке, ее симптомах, причинах и мерах по устранению) и далее обеспечивает его «жизненный цикл». Хорошей идеей может быть также дополнение баг-репортера инструментами, которые бы пытались сами диагностировать и исправить проблему.
В Google нормальной практикой считается открытие бага по любой проблеме, даже для тех, которые получены по электронной почте или в корпоративном чате (например, IM). Таким образом, формируется журнал мероприятий по исследованию проблем и восстановлению, к которому можно обратиться в дальнейшем. Во многих командах по некоторым причинам не приветствуется передача отчетов непосредственно человеку: такая практика требует дополнительных действий для превращения отчета в баг, способствует появлению низкокачественных отчетов, которые не видны другим членам команды, и ведет к тому, что основная нагрузка по решению проблемы ложится не на дежурного специалиста, а на того, кто знаком отправителю (также см. главу 29).
| У Шекспира проблема Вы находитесь на дежурстве по обслуживанию системы, занимающейся поиском произведений Шекспира, и получаете ошибку ShakespeareBlackboxProbe_SearchFailure: благодаря мониторингу методом «черного ящика» вы обнаружили, что результаты для запроса «виды существ неведомых1» (ориг. the forms of things unknown) не были получены в течение пяти минут. Система оповещений заполнила баг, снабдив его ссылками на результаты мониторинга для поиска в Playbook, и направила его вам. Пора приступать к работе! |
Первичная обработка и сортировка
После того как вы получили отчет об ошибке, следует выяснить, что с ней делать. Проблемы различаются по степени опасности: некоторые могут влиять только на одного пользователя с очень специфическими условиями (такие проблемы часто удается обойти), другие же могут повлечь за собой перебои в работе всего сервиса. Ваши дальнейшие действия должны быть адекватны проблеме: допустимо срочно мобилизовать всех инженеров для решения только что возникшей серьезной проблемы (см. главу 14), но не для исправления давно известного дефекта. Оценка опасности проблемы требует хорошей подготовки, опыта в проектировании, рассудительности и очень часто умения сохранять спокойствие в любой ситуации.
Возможно, при сбоях в системе вы первым делом захотите найти источник проблемы. Не делайте так!
Вместо этого стоит попытаться хотя бы частично возобновить работу системы. Для этого может потребоваться перенаправлить трафик неисправных кластеров на те, которые еще работают нормально, ограничить суммарный трафик, чтобы избежать перегрузки и последовательного отключения всей системы, или же отключить отдельные подсистемы, чтобы снизить нагрузку. Приоритетной задачей должна быть «остановка кровотечения»; вы никак не поможете пользователям, если будете искать причины неисправности, пока ваша система умирает. Конечно, быстрота оказания «первой помощи» не должна помешать сохранению информации о том, что произошло, например, в виде записей в журналах, которые позже помогут вам в поиске причины.
Молодых пилотов учат, что в случае ЧП они все равно должны пилотировать самолет [Gawande, 2009]; поиск проблемы вторичен по сравнению с тем, что нужно безопасно посадить самолет на землю. Такой подход справедлив и для компьютерных систем: например, если неполадка ведет к тому, что часть информации будет утеряна навсегда, «заморозка» системы для предотвращения дальнейшего ее распространения будет наилучшим решением.
Такой порядок нередко смущает неопытных SR-инженеров и кажется им противоестественным, особенно если ранее они занимались разработкой программных продуктов.
Обследование
У нас должна быть возможность подробно исследовать, что происходило с каждым компонентом системы, и установить, правильно ли он работал.
В идеале система мониторинга ведет запись показателей функционирования системы, как это было упомянуто в главе 10. Эти данные — хорошая отправная точка для выяснения, что именно пошло не так. Последовательная запись хронологии операций — эффективный путь к пониманию поведения отдельных компонентов системы, обнаружению зависимостей и, таким образом, к нахождению источника проблемы.
Второй незаменимый инструмент — журналирование. Изучение информации о каждой операции и о состоянии системы позволяет понять, что делал каждый процесс в данный момент времени. Возможно, вам придется анализировать журналы одного или нескольких процессов. Трассировка запросов через всю иерархию процессов с использованием таких инструментов, как Dapper [Sigelman, 2010], облегчает понимание работы распределенной системы посредством так называемых диаграмм использования (use-case), что позволяет применять затем различные анализаторы [Sambasivan, 2014].
| Журналирование Текстовые, пригодные для чтения человеком журналы очень полезны для оперативной отладки в реальном времени, в то время как журналы в структурированном бинарном формате позволяют создавать и использовать инструменты, проводящие ретроспективный анализ на основе большого объема информации. Очень полезно иметь несколько уровней детализации, а также возможность повышать уровень по мере надобности, на лету. Такой подход позволяет детально изучать любую операцию (или даже все) без перезапуска процесса, а также возвращать (понижать) уровень детализации журналов сервиса, не нарушая его работу. В зависимости от объема трафика, который обрабатывает ваш сервис, может быть полезно использовать «прореженную» выборку; например, вы можете выбирать для протоколирования каждую тысячную операцию. Следующим шагом может стать добавление языка для правил фильтрации, например «Показать операции, которые соответствуют X», где X может быть любым правилом, например «выбрать вызовы удаленных процедур (RPC) с запросами менее 1024 байт, или операции, ожидание результата которых составило больше 10 мс, или только обращения к процедуре doSome thigInteresting() в rpc_handler.py». Возможно, вы захотите построить свою систему журналирования, которую можно было бы задействовать в любой момент, быстро и с требуемой избирательностью. |
Раскрытие текущего статуса — третий козырь в нашем рукаве. Например, у серверов Google есть интерфейсы, которые демонстрируют в качестве примеров недавно выполненные вызовы удаленных процедур, что позволяет понять, как сервер общается с другими серверами без обращения к описывающей архитектуру документации. Эти интерфейсы также показывают гистограммы частоты ошибок и величин задержек для каждого типа УВП, что позволяет быстро узнать, где начались сбои. Некоторые системы имеют интерфейсы, показывающие их текущую конфигурацию или позволяющие анализировать их данные. Например, серверы Google’s Borgmon (см. главу 10) могут вывести условия, по которым осуществляется мониторинг, или даже сделать пошаговую трассировку конкретных алгоритмов в поисках источника того или иного выходного значения.
Наконец, вам, возможно, понадобится создать тестовое приложение-клиент, чтобы понять, что тестируемый компонент возвращает в ответ на запросы.
| Отладка Шекспира Используя ссылку, предоставленную в отчете мониторинга методом черного ящика, вы обнаруживаете, что к интерфейсу /api/search был отправлен запрос HTTP GET: { 'search_text' : 'the forms of things unknown' } |
| Ожидается, что он получит HTTP-ответ с кодом 200 и данными из JSON, которые выглядит следующим образом: ({"work": "A Midsummer Night's Dream", "act": 5, "scene": 1, "line": 2526, "speaker": "Theseus" }) Система настроена так, что тестовый запрос отсылается раз в минуту; за последние десять минут примерно половина из них была успешной, явной закономерности при этом незаметно. К сожалению, мониторинг не показывает коды ошибок; вы делаете пометку о том, что позже нужно это доработать. Используя curl, вы вручную отправляете запрос к проверяемому интерфейсу и получаете HTTP-ответ с кодом ошибки 502 (Bad gateway — «ошибка шлюза») без какого-либо содержимого. У него есть HTTP-заголовок, поле X-request-trace, в котором показаны адреса серверов, участвовавших в выполнении этого запроса. С имеющейся информацией вы можете начать тестировать эти серверы на предмет того, правильно ли они реагируют на запросы. |
Диагноз
Понимание того, как спроектирована конкретная система, действительно полезно для выдвижения реалистичных гипотез о сути и причинах неполадок, но есть и ряд общих подходов, применимых к любым системам.
Упрощайте и сокращайте. В идеале все компоненты в системе имеют хорошо определенные интерфейсы, которые выполняют преобразование их входных данных в выходные (в нашем случае, получив введенный для поиска фрагмент, компонент должен вернуть текст, в котором найдены совпадения с введенным). После этого можно взглянуть на соединение между компонентами или, что равноценно, на передающуюся между ними информацию, чтобы определить, правильно ли работает компонент. Особенно эффективным бывает ввод заранее известных тестовых данных с последующей сверкой результата (тестирование по методу черного ящика) на каждом шаге обработки, равно как и ввод данных, подготовленных специально для наблюдения возможных причин ошибок. Наличие таких воспроизводимых наборов тестов существенно ускоряет отладку. Кроме того, появляется возможность использовать их и вне «промышленного» окружения, то есть в условиях, когда допустимы гораздо более агрессивные и рискованные воздействия на систему.
«Разделяй и властвуй» — принцип, применимый в решении самых разнообразных задач. В многоуровневой системе, где работа протекает через иерархию (стек) компонентов, обычно лучше начинать отладку с одного конца стека, методично анализируя работу компонентов, один за другим. Такая же стратегия подходит и для использования с системами конвейерной архитектуры. В очень больших системах линейное продвижение от компонента к компоненту может оказаться слишком длительным. Тогда хорошей альтернативой будет разделить систему на две части и начать тестирование с точки «перехода» между ними. Определив, какая часть системы работает правильно (и может быть исключена из рассмотрения), продолжайте деление, пока не дойдете до неисправного компонента.
Спрашивайте «что», «где» и «почему». Сбоящая система все еще пытается работать и делает что-то — но совсем не то, что от нее требуется. Нужно выяснить, что именно она делает, почему это происходит и, наконец, где расходуются ее ресурсы и куда направляются результаты, — все это может помочь вам в понимании того, что же пошло не так.
| Вскрытие причин наблюдаемых симптомов Симптом: в кластере Spanner очень большая задержка, поэтому вызовы удаленных процедур не успевают дойти до сервера и завершаются по тайм-ауту. Почему: процессор сервера Spanner перегружен задачами и не успевает обслужить все запросы от клиентов. Где расходуется время процессора? Изучение сервера показало, что он сортирует записи в журналах, записанных на диске. Где именно код сортировки тратит время? Он сравнивает пути к файлам журналов на соответствие с регулярными выражениями. Решения: переписать регулярные выражения, чтобы в них не использовались обратные ссылки (backtracking). Попробовать найти уже проверенное решение для похожих задач. Подумайте о переходе на новую версию регулярных выражений RE2, которая не использует обратные ссылки и гарантирует линейную зависимость времени обработки от объема входных данных2. |
Какое воздействие было последним. У систем есть инерция: мы выяснили, что не подверженная внешним воздействиям компьютерная система имеет тенденцию продолжать работать, например, пока не изменится конфигурация или тип нагрузки. Недавние изменения в системе могут быть отличным местом к расследованию того, что пошло не так. Поэтому хорошей отправной точкой для изучения проблемы будет анализ последних изменений в системе.
Хорошо спроектированные системы должны предусматривать средства для полномасштабного протоколирования всех изменений в версиях установленного ПО и в конфигурации на всех уровнях иерархии от файлов программ на сервере, которые обрабатывают пользовательский трафик, и до пакетов, установленных в отдельных узлах в кластере. Взаимосвязь изменений производительности системы и ее поведения с другими событиями в системе и ее среде также могут быть полезны для «табло» мониторинга. Например, вы можете снабдить график детализаций, показывая частоту появления ошибок в период установки новой версии ПО (рис. 12.2).
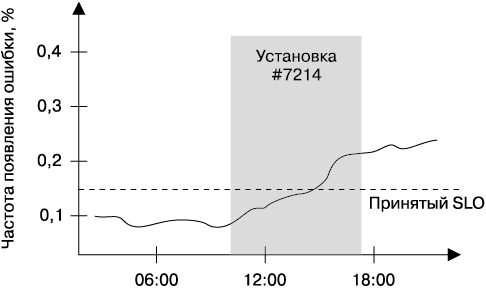
Рис. 12.2. Частота ошибок с момента установки и удаления новой версии
| Отправляя вручную запросы интерфейсу /api/search (см. врезку «Отладка Шекспира» на с. 188) и анализируя списки серверов, участвовавших в передаче результатов, вы можете исключить из рассмотрения проблемы API первого сервера, принявшего запрос, или балансировщик загрузки: ответ вряд ли будет включать в себя такую информацию, если запрос вообще не дошел до поисковых сервисов и потерялся где-то по пути. Теперь вы можете сосредоточиться на бэкенде — анализируя журналы, отправляя тестовые запросы, проверяя полученные ответы и другие показатели работы системы. |
Специфические средства диагностики. Рассматриваемые до сих пор универсальные методы и средства подходят для решения широкого круга задач, но вы, вероятно, считаете, что полезны могут быть и инструменты для диагностики ваших конкретных сервисов. Действительно, SR-инженеры Google тратят немало времени на создание таких инструментов. Хотя многие из этих инструментов подходят только для конкретной системы, обязательно выясните, нет ли для других сервисов и у других команд чего-то подобного, чтобы не тратить время и усилия на ненужное дублирование.
Подтверждение диагноза
Когда у нас остался уже небольшой список возможных причин, пора попытаться найти, какая же именно из них стала источником проблемы. Подтвердить или отклонить гипотезы можно экспериментальным путем. Пусть, например, мы считаем, что проблема вызвана ошибками сети между сервером приложений и сервером базы данных или отказом в соединении со стороны базы данных. Попытки подключиться к БД с таким же набором параметров, как и у сервера приложений, позволяют опровергнуть вторую гипотезу, а проверка доступности сервера БД при известных топологии сети, настройках сетевых экранов и других факторах позволяет опровергнуть первую. Следуя за кодом программ и пытаясь шаг за шагом имитировать его выполнение, мы можем выйти на источник проблемы.
Разрабатывая тесты (которые могут быть и достаточно простыми, как, например, отправка пинга, и, наоборот, достаточно сложными, например отключение трафика в кластере и ввод специально сформированных запросов для выяснения условий возникновения «гонок»), надо руководствоваться рядом соображений.
• В идеальном случае варианты результатов тестов должны быть взаимоисключающими, чтобы с их помощью можно было однозначно подтвердить или опровергнуть группы гипотез. На практике достичь этого не так-то просто.
• Проверяйте в первую очередь очевидные вещи: выполняйте тесты, начиная с самых очевидных и переходя последовательно к более неочевидным, с учетом возможных рисков для системы. Например, есть смысл проверить сначала сетевое соединение между двумя машинами и лишь потом выяснять, не был ли закрыт доступ для этого пользователя в новой версии конфигурации.
• Результаты эксперимента могут ввести вас в заблуждение. Например, настройки сетевого экрана могут запрещать доступ только с конкретного IP-адреса, база данных может не пинговаться с вашего компьютера, но будет доступна для сервера приложений.
• Активное тестирование может привести к побочным эффектам, которые повлияют на результат будущих тестов. Например, если позволить процессу использовать больше ресурсов процессора, это ускорит выполнение операций, но может привести к проблемам с многопоточностью. Аналогично включение подробного журналирования может усугубить проблему с задержками и даже исказить результаты теста, и тогда возникает вопрос: проблема усугубляется сама по себе или же из-за журналирования?
• Результаты некоторых тестов бывают слишком ненадежны, чтобы однозначно полагаться на них; их можно лишь принимать к сведению. Например, проблемы многопоточности и «гонок» бывает очень сложно воспроизвести, поэтому вам иногда придется принимать решения без твердых доказательств, в чем именно состоит проблема.
Тщательно записывайте, какие идеи у вас были, какие тесты вы проводили и какие получили результаты. Эта информация может иметь решающее значение, особенно в сложных и запутанных случаях, напоминая, что именно происходило и какие шаги уже предпринимались, чтобы не пришлось их снова повторять. При активном внесении изменений в систему в ходе тестирования, например отдавая больше ресурсов процессу, такие заметки позволят намного легче и быстрее вернуть систему в первоначальное состояние.
Волшебная сила отрицательных результатов
Автор — Рэндалл Босетти.
Под редакцией Джоан Вендт
Отрицательным называют такой результат, когда не был достигнут ожидаемый (положительный) результат, то есть эксперимент прошел не так, как планировалось. Сюда относятся новые технические решения, эвристики и выполняемые человеком операции, которые не дали ожидавшихся улучшений в системе.
Не игнорируйте отрицательные результаты. Понимание своей ошибки представляет большую ценность: очевидный отрицательный результат может помочь в решении самых сложных вопросов — касающихся проектирования системы. Очень часто у команды есть два пути проектирования, кажущиеся одинаково обоснованными, но продвижение по одному из них сопровождается сомнениями, что другой был бы лучше.
Отрицательный результат — окончательный вердикт. Он дает надежную и достоверную информацию о «промышленной» или «разработчицкой» конфигурациях системы, о пределах ее производительности. Он может помочь другим решить, стоит ли им тестировать (или проектировать) те или иные вещи. Например, команда разработчиков решила не использовать определенный веб-сервер, потому что он может поддерживать без блокировок лишь около 800 соединений, а требуется 8000. Когда следующая команда решит оценить этот сервер, вместо того чтобы все начинать с нуля, они смогут воспользоваться задокументированным отрицательным результатом и быстро решить, что: 1) им требуется менее 800 подключений или 2) необходимо решить проблемы с блокировками соединений.
Даже если отрицательный результат неприменим напрямую к чьему-либо эксперименту, та информация, которую он дает, может помочь планировать новые эксперименты или избегать повторения уже известных проблем. Это могут быть микротесты производительности, задокументированные неудачные решения или отчеты об авариях. Вам следует оценить и обсудить масштабы влияния отрицательных результатов при планировании эксперимента, поскольку затрагивающий многие системы и стабильно повторяющийся отрицательный результат для ваших коллег может оказаться даже важнее, чем для вас.
Инструменты и методы переживают конкретный эксперимент и помогают в будущих работах. Например, наличие готовых средств для тестирования и измерений или для генерации тестовой нагрузки позволяет достаточно легко сделать эксперимент более информативным и достоверным. Многие веб-мастеры с пользой применяют Apache Bench (инструмент для тестирования нагрузочной способности веб-серверов), выполняющий большую, сложную и кропотливую работу, хотя поначалу его результаты скорее разочаровывали.
Польза от создания инструментов для повторяющихся экспериментов может проявиться позже: пусть сейчас какое-то ваше приложение не выигрывает от размещения его базы данных на SSD или от ее индексации — от этого может выиграть другое приложение. Если вы написали скрипт, позволяющий легко опробовать эти конфигурации, он поможет оптимизировать и ваш будущий проект.
Публикация отрицательных результатов повышает культуру производства в области обработки данных. Накопление отрицательных результатов и, казалось бы, несущественных сведений способствует повышению качества набора контролируемых параметров и служит примером рационального отношения к огрехам в работе. Открывая другим как можно больше подробностей, вы стимулируете и остальных поступать так же, и это подталкивает всю отрасль в правильном направлении. Наши SR-инженеры уже усвоили это и создают качественные детальные отчеты, что благотворно повлияло на стабильность промышленно эксплуатируемых продуктов.
Публикуйте свои результаты. Если вам нужны результаты экспериментов, то с большой вероятностью они нужны и другим людям. Если вы поделитесь своими результатами, другим не придется проектировать с нуля или ставить похожие эксперименты. Мало кто хочет публиковать отрицательные результаты, поскольку они свидетельствуют о неудаче эксперимента. Некоторые эксперименты обречены изначально, но отчеты о них все равно просматривают. Сведения о множестве экспериментов так никогда и не публикуются, потому что люди думают, что получение отрицательного результата не является движением вперед.
Внесите свой вклад, рассказав всем о своих дизайне, алгоритмах и рабочем процессе в команде. Объясните своим коллегам, что отрицательные результаты — это часть необходимых и ожидаемых рисков разработки и в каждой хорошо спроектированной системе есть и их заслуга. Будьте скептичны, когда видите конструкторский документ, анализ производительности или описание, в которых не упоминается о неудачах. Это говорит о том, что либо документ был сильно «вычищен», либо автор был недостаточно точен и честен.
И наконец, публикуйте результаты, которые кажутся вам удивительными, чтобы другие — даже вы сами в будущем — не удивлялись им заново.
Лечение
Итак, в идеале вы свели все причины к одной. Теперь мы должны доказать, что это действительно та самая причина. Исчерпывающее доказательство того, что конкретная причина привела к проблеме, предполагает искусственное воспроизведение ситуации, а это в условиях промышленной эксплуатации может быть затруднено. Из-за нескольких факторов нам часто удается найти только вероятную причину.
• Сложность систем. Скорее всего, было несколько факторов, из которых каждый отдельно взятый сам по себе причиной не был, но все вместе они привели к сбою. Кроме того, поведение реальных систем часто зависит от предыдущих состояний, поэтому для воспроизведения ошибки необходимо, чтобы система уже оказалась в соответствующем, возможно, редком состоянии.
• Воспроизвести проблему в работающей промышленной системе может быть невозможно как из-за сложности приведения ее в нужное состояние, так и из-за неприемлемого времени восстановления работоспособности. Наличие не участвующей в производственном процессе копии системы решает эту проблему, но это требует затрат на поддержание ее в работоспособном и адекватном состоянии.
Как только вы нашли факторы, которые вызвали проблему, самое время все задокументировать: что происходило с системой, как вы выследили проблему, как вы справились с ней и как сделать так, чтобы она не повторилась в будущем. Другими словами, вам нужно написать отчет (несмотря на то что система работает!).
Пример: анализ реальной ситуации
App Engine («движок приложений») — часть облачной платформы Google. Это продукт типа «платформа как сервис», который позволяет разработчикам создавать свои сервисы поверх инфраструктуры Google. Один из наших внутренних клиентов прислал отчет об ошибке. В нем указывалось, что у них резко увеличились задержка, использование ЦП и количество процессов, нужных для обработки трафика в их приложении — системе управления контентом, используемой для создания документации для разработчиков. Клиент не находил в коде таких изменений, которые могли бы потребовать больше ресурсов, трафик приложения тоже не увеличивался (рис. 12.3), и они недоумевали: неужели это произошло из-за изменений в самом сервисе App Engine?
В ходе расследования мы узнали, что задержка действительно на порядок возросла (рис. 12.4) и одновременно вчетверо увеличились загрузка ЦП (рис. 12.5) и количество процессов (рис. 12.6). Что-то явно было не так. И мы начали искать проблему.
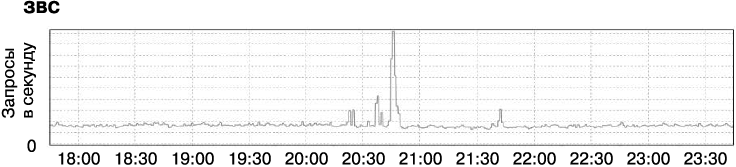
Рис. 12.3. Количество запросов, которое приложение получало в секунду. Видны моменты пиковой нагрузки, после чего она возвращается к нормальной
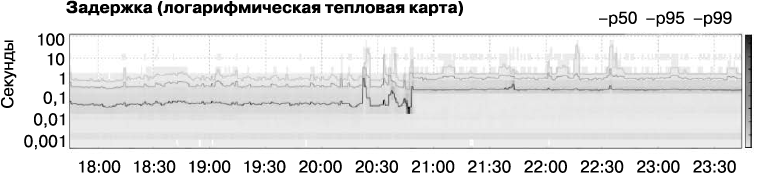
Рис. 12.4. Задержка приложения. Кривые на графике соответствуют величинам задержки, в которые укладывается выполнение соответственно 50, 95 и 99 % запросов. «Карта нагрева» показывает, сколько запросов попадает в каждый интервал
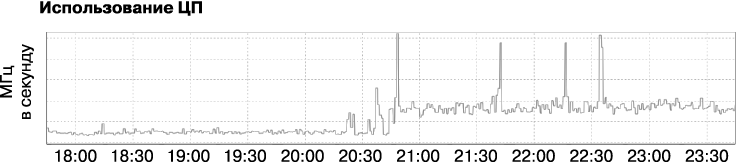
Рис. 12.5. Совокупное использование ЦП приложением
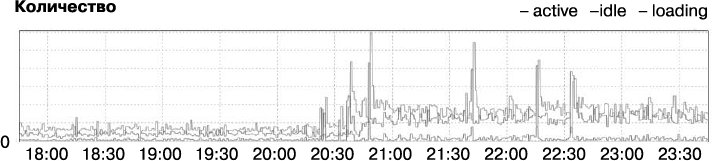
Рис. 12.6. Количество запущенных процессов (экземпляров приложения)
Резкое увеличение задержки и потребления ресурсов обычно указывает на то, что увеличилось количество отсылаемого системе трафика или что изменения произошли в конфигурации системы. Однако здесь мы могли легко отбросить обе эти причины: поскольку рост потребления ресурсов вызван всплеском трафика приложения около 20:45, что может объяснить краткий всплеск в использовании ресурсов, следовало бы ожидать нормализации, как только количество запросов снова снизится до обычного. Такая загрузка не должна была продолжаться в течение нескольких дней, с тех самых пор, как разработчики заполнили отчет об ошибке, а мы начали разбираться с проблемой. Кроме того, перебои начались в субботу, когда некому было менять ни приложение, ни его окружение. Последние изменения кода и конфигурации были сделаны несколько дней назад. Однако, если бы источник проблемы был в сервисе, то такой же эффект наблюдался бы у всех приложений, использующих данную инфраструктуру. Но таких приложений не было.
Мы рассказали о проблеме нашим разработчикам App Engine, чтобы выяснить, не связаны ли проблемы клиента с какими-то особенностями этого сервиса. Они тоже не нашли ничего странного, однако один из разработчиков заметил совпадение между увеличением задержки и увеличением количества специфических обращений к API хранилища данных — вызовов merge_join, которые часто указывают на неоптимальную индексацию данных из базы. Включение в индексацию тех свойств объектов, которые приложение использовало при их выборке из хранилища, ускорило бы эти запросы и, скорее всего, производительность приложения в целом, но мы должны были понять, какие именно свойства подлежат индексации. Беглый анализ кода приложения явных «подозреваемых» не выявил.
Наступило время тяжелой артиллерии: используя Dapper [Sigelman, 2010], мы протрассировали прохождение HTTP-запроса — начиная от его поступления на прокси клиентской стороны и до момента формирования ответа приложением, а затем просмотрели вызовы удаленных процедур всех серверов, участвующих в выполнении этого запроса. Это позволило нам увидеть, какие свойства были включены в выборку из хранилища данных, а затем создать нужные индексы.
В ходе этого исследования мы обнаружили, что запросы к статичным данным, например графическим файлам, в обслуживании которых хранилище не участвует, выполнялись намного медленнее, чем обычно. Обратившись к графикам обращений к отдельным файлам, мы увидели, что всего пару дней назад эти запросы выполнялись намного быстрее. Это означало, что найденная ранее корреляция между merge_join и увеличением задержки была ложной и что наша гипотеза о неоптимальной индексации в корне неверна.
Продолжив изучение аномально медленных запросов к статичному содержимому, мы нашли, что большинство вызовов из приложения проходят через сервис кэширования и поэтому должны выполняться очень быстро — за несколько миллисекунд. Выходило, что запросы должны быть очень быстрыми и вроде бы не могли стать источником проблемы. Однако задержка с момента начала обработки запроса приложением и до первого вызова RPC составляла примерно 250 миллисекунд, в течение которых приложение, скажем так, «что-то делало». Поскольку код, выполняемый сервисом App Engine, предоставляется пользователями, SR-инженеры его не изучают, и мы не могли узнать, что же делает приложение в это время. Dapper также не смог отследить происходящее, так как он видит только вызовы удаленных процедур, которых в этот период не было.
Мы решили, что пока не будем отгадывать эту загадку. У клиента было запланировано открытие доступа к приложению на следующей неделе, и мы не были уверены, что сумеем быстро выяснить суть проблемы и решить ее. Вместо этого мы порекомендовали клиенту выделить приложению больше ресурсов, запросив наиболее мощный ЦП. Сделав это, клиент сократил задержку до приемлемого уровня, хоть и не до такого низкого, как нам хотелось бы. Было решено, что такого уменьшения задержки достаточно, чтобы команда могла считать запуск своего приложения успешным, а изучение проблемы продолжить в свободное время.
К этому моменту, мы начали подозревать, что приложение было жертвой другой распространенной причины внезапного увеличения задержки и потребления ресурсов: изменения в режиме работы. Мы заметили рост количества операций в хранилище данных из приложения как раз перед тем, как увеличилась задержка, но этот рост не был ни большим, ни длительным — и мы отбросили это совпадение как случайное. Однако такое поведение приводило к мысли об общем шаблоне: каждый экземпляр приложения при инициализации считывает объекты из хранилища данных, а затем хранит их в памяти. Таким образом приложение избегает повторного чтения редко изменяемых конфигураций из хранилища, вместо этого обращаясь к объектам в памяти. Далее, длительность обработки запросов часто зависит от объема конфигурационных данных. Мы не могли доказать, что именно это было причиной проблемы, но такое типичное решение обычно считается нежелательным.
Разработчики приложения добавили инструментарий, чтобы понять, где приложение тратит свое время. Они выявили тот метод, который вызывался при каждом запросе, — он проверял, имеет ли пользователь доступ к данному пути в файловой системе. Метод использовал кэширование объектов «белого списка» в памяти приложения, чтобы минимизировать обращения к хранилищу и к сервису кэширования. Как заметил один из разработчиков, «я не знаю, где тут огонь, но дым от закэшированного “белого списка” буквально ест глаза».
Некоторое время спустя проблема была найдена, это был давно существовавший дефект в системе управления доступом: всякий раз при обращении по конкретному пути выполнялось создание объекта «белого списка» и запись его в хранилище. При запуске приложений автоматический сканер безопасности проверял их на уязвимости и как побочный эффект в процессе проверки создавал «белый список» из тысяч объектов в течение примерно получаса. Это множество избыточных объектов затем участвовало в проверках доступа при каждом запросе, что и приводило к задержкам ответов, причем без вызовов удаленных процедур других сервисов. Исправление дефекта — удаление этих объектов после использования — восстановило производительность приложения до ожидаемого уровня.
Как облегчить решение проблем
Есть много подходов к тому, как упростить и ускорить диагностику и решение проблем. Вероятно, наиболее общими из них являются следующие.
• Обеспечьте возможность наблюдения за системой: в виде показателей белого ящика и структурированных журналов — снизу доверху, для каждого компонента.
• Разрабатывайте системы с предельно понятными и наблюдаемыми интерфейсами между компонентами.
Доступность информации в целостном виде на любой стадии ее обработки в системе — например, с использованием уникальных идентификаторов запросов во всех вызовах удаленных процедур всех компонентов — дает возможность меньше заниматься гаданием, какие места в журналах прохождения запроса и ответа на него соответствуют друг другу. Это, в свою очередь, позволяет сократить время диагностики и восстановления.
Проблемы, которые приходится искать, часто бывают следствием неверного представления об изменениях в состоянии системы и ее окружения. Упрощение, контроль и журналирование этих изменений делает сами проблемы более редкими, а их диагностику и решение — более простыми.
Итоги главы
Итак, мы рассмотрели кое-какие меры, которые вы можете предпринять, чтобы сделать процесс диагностики и решения проблем ясным и понятным для новичков, в результате чего они тоже смогут стать квалифицированными специалистами. Применение систематического подхода к решению проблем — вместо того чтобы полагаться только на удачу или опыт — позволяет сократить время, необходимое для восстановления системы, что делает работу с ней более продуктивной, удобной и привлекательной для пользователей.
Действительно, использование только общепринятых практик и личных навыков решения проблем часто может быть отличным способом понять, как работает система (см. главу 28).
См .
Например, экспортируемые переменные, описанные в главе 10.
«Зебра», см. ) — профессиональный сленг, обозначающий экзотический диагноз. Выражение приписывается Теордору Вудварду из университета Maryland School of Medicine. Это правило применимо не всегда, но для некоторых систем целые классы проблем могут быть исключены из рассмотрения: например, в хорошо спроектированном кластере файловых систем задержка из-за неисправности одного диска крайне маловероятна.
Бритва Оккама, см. %27s_razor. Но помните также, что проблема может быть не единственной. Например, наблюдаемый в системе набор симптомов с большей вероятностью бывает следствием совместного действия ряда мелких дефектов, чем одной редкой ошибки, которая также объясняет все эти симптомы. См. %27s_dictum.
Конечно же, см. .
Например, у нас нет правдоподобной теории, которая бы объясняла, почему в период с 2000 по 2009 год в США количество защит диссертаций на степень PhD по информатике весьма точно (r2 = 0,9416) коррелирует с потреблением сыра на душу населения ().
Может быть полезно сослаться на перспективный баг-репортер, описанный в [Tatham, 1999], который способен помочь в составлении качественных отчетов об ошибках.
В переводе Ф.И. Тютчева.
Но будьте осторожны — случайная корреляция может направить вас по ложному следу.
Во многих отношениях это похоже на метод «пяти почему» [Ohno, 1988], представленный Таичи Оно для понимания того, в чем корень проблем производственных ошибок.
RE2 — новая версия библиотеки поддержки регулярных выражений, предложенная Google в 2010 году и использующая модель детерминированных конечных автоматов (DFA). По сравнению с RE2, более традиционная библиотека PCRE на основе недетерминированных конечных автоматов (NFA) допускает экспоненциальный рост затрат. RE2 доступна по ссылке .
[Allspaw, 2015] отмечает, что это часто используемая эвристика в разрешении проблем, связанных с перебоями электропитания.
Использование для заметок документа с совместным доступом или чата в реальном времени позволяет иметь временные метки для всех выполненных действий, что полезно для написания отчета. Одновременно вы также делитесь информацией с остальными, что ускоряет их работу и не мешает работать вам.
См. [Meadows, 2008] о подходах к анализу систем, а также [Cook, 2010] и [Dekker, 2014] об ограниченности возможностей найти единственную причину ошибок вместо исследования системы на предмет комплексно действующих факторов.
См. .
Для облегчения понимания мы сократили и упростили описание этого примера.
Хотя запуск продукта с неидентифицированным дефектом не лучшее решение, на практике часто бывает нецелесообразно устранять абсолютно все дефекты. Вместо этого иногда приходится довольствоваться «лучшим из возможного» и по возможности минимизировать риски, руководствуясь здравым смыслом.
Поиск в хранилище данных для ускорения может применять индексы, но часто используемая реализация с кэшированием в памяти проста и удобна для просмотра по списку всех хранящихся так объектов. Однако выигрыш от линейного времени обработки списка незначителен при немногочисленных объектах, а с увеличением их количества может сильно возрасти задержка.
Еще важнее влияние такого решения на логику программы: постоянно храня в памяти копию конфигурационных данных, программа не видит изменений их оригинала в хранилище или в файлах вплоть до явного повторного считывания. Хорошо это или плохо — решать разработчикам. — Примеч. пер.
Описанная ситуация, скорее всего, разрешилась бы быстрее или не возникла бы вовсе, если бы разработчики не злоупотребляли «экстенсивным» подходом к разработке и больше следили за потреблением ресурсов. В частности, выявлять перерасход памяти для хранения структур данных можно и нужно. — Примеч. пер.

