Дополнительные материалы
Приложения
Приложение 1
Свод правил DevOps
Мы считаем, что DevOps сильно выигрывает от взаимодействия разных направлений менеджмента, усиливающих друг друга и создающих мощную систему, способную изменить традиционные подходы к разработке и поставке IT-продуктов и сервисов.
Джон Уиллис назвал этот процесс «конвергенцией DevOps». Подходы к управлению, ставшие предками DevOps, описаны ниже в порядке появления (отметим, что это не подробные описания, а скорее, заметки, призванные показать развитие мысли и неочевидные связи между направлениями. Они в итоге привели к созданию DevOps).
Бережливое производство
Бережливое производство возникло в 1980-х гг. как попытка формализовать производственную систему компании Toyota и популяризовать такие методики, как систематизирование потока ценности, канбан-доски и всеобщий уход за оборудованием.
Два основополагающих принципа бережливого производства — глубокая вера в то, что время производственного цикла (то есть время, затраченное на преобразование исходных материалов в готовую продукцию) — лучший показатель качества работы, удовлетворенности клиентов и сотрудников, а также того, что одним из главных факторов сокращения времени производственного цикла были небольшие размеры партии. Идеалом был «поток единичных изделий» (то есть поток «1×1»: одна единица исходных материалов — одна единица готовой продукции).
Принципы бережливого производства — систематическое мышление, формулировка четкой цели, использование научного подхода, создание потока и вытягивания вместо выталкивания, изначальное обеспечение качества, управление на основе скромности и уважение к каждому человеку. Все это сосредоточено на создании ценности для клиента.
Гибкая разработка
Agile-манифест был создан в 2001 г. семнадцатью ведущими мыслителями в области разработки ПО. Их целью было преобразование таких «неглубоких» методов, как DP и DSDM, в более широкую систему, куда можно было бы включить более масштабные подходы к разработке, такие как каскадная модель (Waterfall Model) или унифицированный процесс разработки (Rational Unified Process).
Ключевой принцип — «частая поставка работающего программного обеспечения, от нескольких недель до нескольких месяцев, чем быстрее — тем лучше». Два других важных принципа гибкой разработки — небольшие, целеустремленные команды, работающие по модели управления с высоким уровнем доверия, и предпочтение небольшим объемам работы. С гибкой методологией разработки также связаны такие наборы инструментов и методики, как Scrum, Stand-up и так далее.
Конференции Velocity
Конференция Velocity, впервые проведенная в 2007 г., была создана Стивом Судерсом, Джоном Оллспоу и Джессом Робинсом как место, где инженеры эксплуатации и производительности web-сервисов могли бы чувствовать себя как дома. На конференции в 2009 г. Джон Оллспоу и Пол Хэммонд представили основополагающий доклад 10 Deploys per Day: Dev and Ops Cooperation at Flickr («Десять развертываний в день: сотрудничество разработки и эксплуатации во Flickr»).
Гибкая инфраструктура
В 2008 г. на конференции гибкой методологии разработки в Торонто Патрик Дюбуа и Эндрю Шейфер провели сессию единомышленников, посвященную применению принципов гибкой разработки к инфраструктуре, а не только к коду. У них быстро появились последователи, например Джон Уиллис. Позже Дюбуа был настолько впечатлен докладом Оллспоу и Хэммонда 10 Deploys per Day: Dev and Ops Cooperation at Flickr, что провел первую конференцию DevOpsDays в Генте, Бельгия, в 2009 г., где впервые прозвучал термин DevOps.
Непрерывная поставка
Развивая идеи непрерывной сборки, тестирования и интеграции разработки ПО, Джез Хамбл и Дэвид Фарли придумали концепцию непрерывной поставки. В нее входит понятие «конвейер развертывания». Суть в том, что код и инфраструктура всегда готовы к развертыванию и что в развертывание всегда уходит весь код в основной ветке.
Эта идея впервые была представлена на конференции Agile в 2006 г., кроме того, независимо описана Тимом Фитцем в блоге в статье под названием Continuous Deployment («Непрерывное развертывание»).
Тойота Ката
В 2009 г. Майк Ротер написал книгу Toyota Kata: Managing People for Improvement, Adaptiveness and Superior Results. В ней был обобщен его двадцатилетний опыт по анализу и приведению в систему причинных механизмов производственной системы компании Toyota. В книге описываются «невидимые управленческие практики и способы мышления, определяющие успех Toyota в непрерывном улучшении процессов и в адаптации… и то, как другие компании используют похожие методики и способы мышления в своей работе».
Его вывод: сообщество упустило самую важную методику бережливого производства, описанную как «ката улучшения». Ротер объясняет: в каждой организации есть свои привычные способы организации работы, и важнейший фактор в Toyota — то, они сделали улучшение повседневным процессом и встроили его в ежедневную работу всех сотрудников. Тойота Ката декларирует постепенный, повторяющийся, научный подход к решению проблем. Главная цель — достижение целей компании.
Бережливый стартап
В 2011 г. Эрик Рис написал книгу The Lean Startup: How Today’s Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses, обобщив опыт работы в IMVU, стартапе в Кремниевой долине, организованном в соответствии с принципами Стива Бланка, которые описаны в книге The Four Steps to the Epiphany, и использовавшем методики непрерывного развертывания. Эрик Рис также сформулировал такие важные методики и понятия, как минимально жизнеспособный продукт, цикл «создать — измерить — сделать выводы» и большое число шаблонов непрерывной поставки.
Lean UX
В 2013 г. Джефф Готельф написал книгу Lean UX: Applying Lean Principles to Improve User Experience. В ней описывалось, как улучшить «туманный front-end» и как собственники продукта могут формулировать гипотезы, проводить эксперименты и убеждаться в верности этих гипотез до того, как вкладывать время и ресурсы в возможные компоненты функциональности. Благодаря Lean UX у нас теперь есть инструменты, чтобы полностью оптимизировать поток между выдвижением гипотез, разработкой функциональности, тестированием, развертыванием и предоставлением сервиса пользователям.
Rugged computing
В 2011 г. Джошуа Кормэн, Дэвид Райс и Джефф Уильямс изучили кажущуюся бесполезность обеспечения безопасности приложений и среды на поздних этапах жизненного цикла. В ответ на подобные заявления они создали принцип прочной разработки (Rugged Computing), благодаря чему формируется понимание таких нефункциональных требований, как стабильность, масштабируемость, доступность, выживаемость, устойчивость, безопасность, поддерживаемость, управляемость и защищенность.
Из-за высоких темпов выпуска релизов система DevOps может оказывать существенное давление на тестировщиков и службу информационной безопасности: когда темпы развертывания меняются с ежемесячных или ежеквартальных на сотни или тысячи развертываний в день, привычные двухнедельные сроки работы этих служб уже не соответствуют изменившейся действительности. Принцип прочной разработки показывает, что текущий подход к борьбе с уязвимыми местами промышленных комплексов, описанный в большинстве нынешних программ информационной безопасности, устарел.
Приложение 2
Теория ограничений и ключевых хронических конфликтов
В теории ограничений широко используется метод облака ключевых конфликтов (core conflict cloud, C3). Вот пример облака конфликтов для IT-компаний (рис. 46).
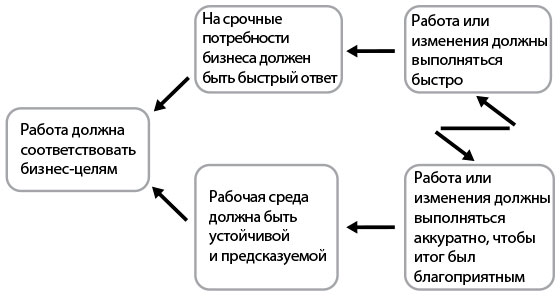
Рис. 46. Ключевой хронический конфликт в любой IT-организации
В 1980-е гг. был распространен ключевой хронический конфликт в промышленности. Любой руководитель завода имел две важные цели: сохранить уровень продаж и сократить издержки. Чтобы поддержать уровень продаж, руководству требовалось увеличить складские площади, чтобы можно было всегда удовлетворить потребительский спрос. И тут возникала проблема.
Ведь, с другой стороны, руководство должно было сократить складские площади, чтобы снизить издержки и чтобы капитал в виде неотгруженной продукции, за которую нельзя получить деньги, не выходил из оборота.
Конфликт удалось разрешить с помощью принципов бережливого производства: уменьшить размеры партий и объемы незавершенного производства, сократить и усилить петли обратной связи. В результате производительность заводов, качество продуктов и удовлетворенность клиентов резко увеличились.
Принципы шаблонов работы DevOps — те же самые, совершившие переворот в промышленном производстве. Они позволяют оптимизировать поток создания ценности и трансформируют потребности бизнеса в возможности и сервисы, удовлетворяющие нужды клиентов.
Приложение 3
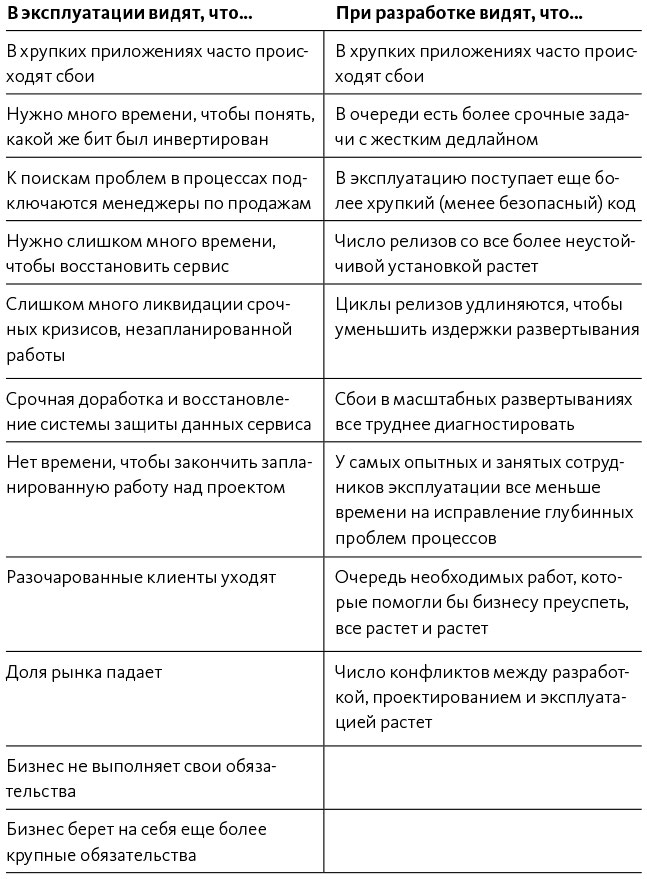
Нисходящая спираль в виде таблицы
Нисходящая спираль, описанная в книге The Phoenix Project, может быть представлена в виде таблицы:
Таблица 4. Нисходящая спираль
Приложение 4
Опасности передачи ответственности и очередей
Проблемы долгого ожидания в очереди обостряются, когда проект много раз передается от инстанции к инстанции, поскольку именно здесь очереди и возникают. На рис. 47 показано время ожидания как функция занятости ресурса производственного участка. Асимптотическая кривая демонстрирует, почему простое изменение, требующее всего-то полчаса, часто отнимает недели для завершения: часто узкие места создают конкретные инженеры и производственные участки с высоким коэффициентом занятости. Когда какой-нибудь производственный участок приближается к 100 %-ной загруженности, любая другая работа неизбежно застревает, пока кто-нибудь наконец не займется пробкой.
На рис. 47 по оси X отложен процент занятости данного ресурса на производственном участке, по оси Y — примерное время ожидания (или, что более точно, длина очереди). Форма кривой демонстрирует: когда загруженность ресурса превышает 80 %, время ожидания зашкаливает.
Время ожидания = (% Занят) / (% Свободен)
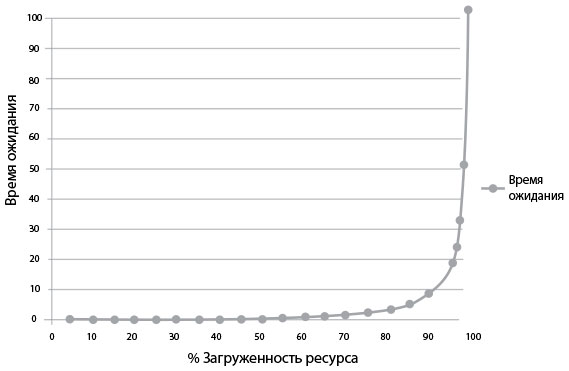
Рис. 47. Размер очереди ожидания и время ожидания как функция процента загруженности (источник: Ким, Бер и Спаффорд, The Phoenix Project, ePub edition, 557)
В книге The Phoenix Project рассказывается, как Билл Шинн и его команда осознали губительное влияние этой зависимости на среднее время подтверждения кода, отправленного в центр управления проектами:
«Эрик рассказал мне во время MRP-8, как время ожидания зависит от использования ресурсов. По его словам, время ожидания — это процент времени занятости, поделенное на процент свободного времени. Другими словами, если ресурс занят половину времени, другую половину он свободен. Время ожидания тогда — 50 % делить на 50 %, то есть одна единица. Будем считать ее равной одному часу.Значит, в среднем наша задача будет ждать в очереди один час, прежде чем сможет выполниться.С другой стороны, если ресурс занят 90 % времени, время ожидания — 90 %, деленное на 10 %, или девять часов. Другими словами, наша задача будет ждать в очереди в девять раз дольше, чем если бы ресурс был занят наполовину.Я завершаю мысль. Все это значит, что при условии, что передача задачи между инстанциями у нас происходит семь раз и что каждый из ресурсов занят 90 % времени, задачи проведут в очереди в сумме девять часов умножить на семь шагов.“Что? Шестьдесят три часа только на ожидание в очереди? — недоверчиво говорит Уэс. — Невозможно!”Патти с усмешкой отвечает: “О, ну конечно. Это ведь всего лишь тридцать секунд ввода команды, да?”»
Билл и команда отдают себе отчет, что «простое задание на полчаса» на самом деле требует семи передач по разным инстанциям (например, командам по серверам, по сетевым соединениям, по базам данных, команде виртуализации и, конечно же, Бренту, «звездному» инженеру).
При условии, что все производственные участки были заняты 90 % времени, на рисунке видно, что среднее время ожидания на каждом участке — девять часов. А поскольку задача должна пройти через семь участков, суммарное время ожидания в семь раз больше: это целых шестьдесят три часа.
Другими словами, суммарная доля полезного времени (также известного как длительность процесса) составляла всего 0,16 % от затраченного времени (тридцать минут, поделенных на шестьдесят три часа). Это значит, что 99,8 % всего времени задача бессмысленно провела в очереди ожидания.
Приложение 5
Мифы об индустриальной безопасности
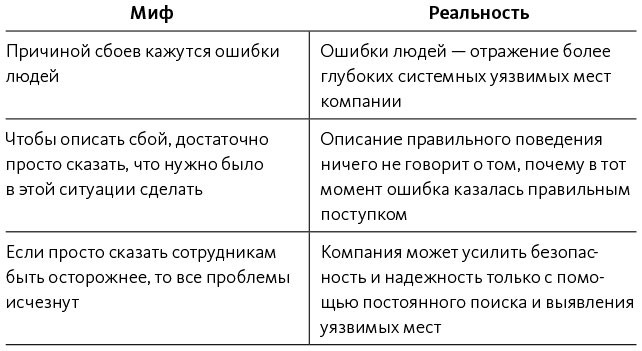
Десятилетия изучения сложных систем свидетельствуют о том, что контрмеры часто основываются на нескольких мифах. Они описаны в книге Дени Беснара и Эрика Холлнагела Some Myths about Industrial Safety.
• Миф 1: «Ошибки людей — главная причина неполадок и инцидентов».
• Миф 2: «Системы в безопасности, если следовать инструкции».
• Миф 3: «Системы можно улучшить с помощью барьеров и ограничений: чем больше уровней защиты, тем выше безопасность».
• Миф 4: «Анализ сбоев может выявить истинную причину сбоя».
• Миф 5: «Расследование сбоя — логичное и рациональное определение его причин, основанное на фактах».
• Миф 6: «Безопасность всегда имеет высший приоритет, она никогда не оказывается под угрозой».
Разница между мифами и реальностью показана ниже (табл. 5).
Таблица 5. Две истории
Приложение 6
Шнур-андон компании Toyota
Многие спрашивают: как работа вообще выполняется, если за шнур-андон дергают больше 5000 раз в день? Если быть точным, не каждое срабатывание системы андон приводит к остановке конвейера. Когда кто-нибудь дергает шнур, у руководителя группы, отвечающего за конкретный производственный участок, есть 50 секунд, чтобы разобраться. Если за это время проблема не была решена, собираемый автомобиль пересечет нарисованную на полу линию, и конвейер остановится.
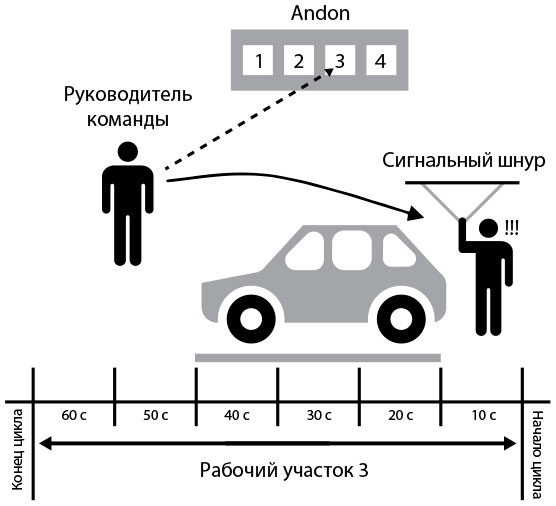
Рис. 48. Шнур-андон компании Тойота
Приложение 7
Коммерческое готовое программное обеспечение
На данный момент, чтобы встроить сложное коммерческое готовое программное обеспечение (commercial off-the-shelf, COTS; например SAP, IBM WebSphere, Oracle WebLogic) в систему контроля версий, придется, возможно, прекратить использовать графические инструменты установки, предоставляемые поставщиком. Для этого нужно разобраться, что именно делает установщик. Возможно, потребуется сделать установку на чистый образ сервера, сравнить файловые системы и ввести добавленные файлы в систему контроля версий. Файлы, не меняющиеся в зависимости от среды, помещаются в одно место («базовая установка»), тогда как специфичные для разных сред помещаются в отдельные папки («тест» или «эксплуатация»). Так установка программ становится просто операцией в системе контроля версий. Прозрачность, повторяемость и скорость операций улучшаются.
Также, вероятно, придется изменить настройки конфигурации приложений, чтобы они были в системе контроля версий. Например, можно преобразовать конфигурации приложений, хранящихся в базе данных, в XML-файлы, или наоборот.
Приложение 8
Совещания для послеаварийной ретроспективы
Ниже приведен простой план совещания по разбору для послеаварийной ретроспективы.
• В самом начале руководитель встречи или координатор произносит небольшую вступительную речь, подчеркивая, что сегодня никто не будет искать виноватых, сосредоточиваться на прошедших событиях или рассуждать о том, что могло бы или должно было быть. Координатор может прочитать главную директиву разбора ошибок (Retrospective Prime Directive) с сайта .
Кроме того, координатор должен напомнить всем, что у контрмер должен быть конкретный исполнитель. Если по окончании совещания контрмера не оказывается приоритетной, то это не контрмера (так делается, чтобы не создавать длинный список хороших идей, которые никогда не воплотятся в жизнь).
• Участники встречи должны составить единую картину того, в каком порядке происходили события во время сбоя: кто и когда обнаружил неполадку, как она была обнаружена (например, с помощью автоматического мониторинга, контроля вручную, письма клиента), когда работоспособность сервиса была восстановлена и так далее. В последовательную цепочку событий также нужно внести все внешние коммуникации во время инцидента.
Используя выражение «цепочка событий», мы формируем в воображении образ линейной последовательности шагов: как формировалось понимание проблемы и как мы в итоге ее исправили. На самом деле, особенно в сложных системах, к сбою приводит много разных событий, и нужно вносить исправления по нескольким путям одновременно. На этом шаге следует отследить все события и все мнения участников и по возможности выдвинуть гипотезы о причинно-следственных связях.
• Далее команда создает список всех факторов, приведших к инциденту: и человеческих, и технических. Потом их можно распределить по категориям, например «проектировочное решение», «восстановление», «фиксация наличия проблемы» и так далее. Команда может использовать такие методики, как мозговой штурм и «бесконечные “как”», чтобы вскрыть более глубокие причины проблемы, если в этом есть необходимость. При этом все точки зрения должны восприниматься уважительно — никто не должен возражать или спорить с реальностью фактора, предложенного кем-то другим. Очень важно, чтобы координатор выделил достаточно времени на эту часть совещания и чтобы команда не пыталась свести все к одной-двум «главным причинам».
• На следующем этапе участники совещания должны определиться со списком корректирующих действий, которые нужно будет выполнить как можно быстрее. Чтобы составить список, полезно устроить мозговой штурм. По итогам необходимо выбрать наилучшие действия для предотвращения таких ошибок в будущем или хотя бы для их более быстрого обнаружения. Туда можно включить и другие способы улучшить рабочие системы.
Наша цель — определить наименьшее число небольших шагов для достижения желаемых результатов, в противоположность глобальным изменениям, отнимающим больше времени и замедляющим введение других необходимых изменений.
Также нужно составить другой список — менее приоритетных идей — и назначить ответственного за него. Если в будущем возникнут похожие проблемы, список может послужить отправной точкой возможных решений.
Участники совещания должны определиться с характеристиками инцидентов и их влиянием на организацию. Например, сбои можно характеризовать следующими показателями.
Тяжесть инцидента: насколько серьезной была проблема? Этот показатель непосредственно связан с влиянием на сервис и на клиентов.
Время простоя: как долго клиенты не могли пользоваться сервисом?
Время обнаружения: сколько времени потребовалось на то, чтобы заметить, что есть проблема?
Время устранения проблемы: сколько времени потребовалось на то, чтобы восстановить работу сервиса после того, как мы обнаружили сбой?
Бетани Макри из компании Etsy отмечает: «Отсутствие обвинений на совещаниях не означает, что никто не берет на себя ответственность. Но мы хотим понять, какие обстоятельства привели к тому, что человек совершил ошибку, каков был широкий контекст. Главная идея в том, что, исключив ответственность, вы устраняете страх; устранив страх, допускаете честность; тогда честность дает возможность предотвратить сбой».
Приложение 9
Обезьянья армия
После масштабного сбоя AWS EAST 2011 г. в компании Netflix активно обсуждали, как сделать, чтобы системы сами справлялись с неполадками. Из этих дискуссий вырос инструмент под названием Chaos Monkey.
С тех пор этот сервис развился в целый набор инструментов, известный как «Обезьянья армия Netflix» и призванный симулировать разные уровни сбоев.
• Горилла Хаоса (Chaos Gorilla): симулирует отказ целой зоны доступности AWS.
• Хаос-Конг (Chaos Kong): симулирует отказ целого региона AWS, например североамериканского или европейского.
Среди других бойцов Обезьяньей армии можно отметить следующих.
• Обезьяна Задержек (Latency Monkey): создает искусственные задержки или остановку работы на уровне связи «клиент — сервер», соответствующей ограничениям REST, чтобы симулировать плавный отказ сервиса и проконтролировать, что зависимые сервисы отвечают на это надлежащим образом.
• Обезьяна Согласованности (Conformity Monkey): находит и выводит из работы инстансы AWS, не соответствующие стандартным значениям (например, когда инстансы не принадлежат к автоматически масштабируемой группе или когда в каталоге сервиса не указан адрес электронной почты ответственного инженера).
• Обезьяна Доктор (Doctor Monkey): просматривает результаты проверок работоспособности каждого инстанса, выявляет больные инстансы и проактивно отключает их, если ответственные за них инженеры не устраняют проблему вовремя.
• Обезьяна Уборщик (Janitor Monkey): следит за тем, чтобы в облачной среде не было мусора и хлама; ищет неиспользуемые ресурсы и избавляется от них.
• Обезьяна Безопасности (Security Monkey): расширение Обезьяны Согласованности; ищет и выводит из работы инстансы с нарушениями безопасности и уязвимыми местами, например неверно настроенные группы безопасности AWS.
Приложение 10
Transperant Uptime
Ленни Рачицки о преимуществах Transperant Uptime («прозрачности работы сервисов для клиентов»):
1. Снижаются издержки на поддержание сервисов, так как пользователи сами могут идентифицировать проблемы ваших систем без звонков или писем в службу поддержки. Пользователям больше не приходится угадывать, локальные у них проблемы или глобальные, они могут быстрее определить причины сбоя и сообщают о неполадках, уже зная существо проблемы.
2. В противоположность общению один на один по электронной почте контакт с пользователями во время выхода сервиса из строя становится продуктивнее, так как благодаря открытости интернета можно обращаться сразу к большой аудитории. Вы тратите меньше времени на воспроизведение одной и той же информации и можете сосредоточиться на решении проблемы.
3. Создается единый пункт для пользователей, куда они могут обратиться, когда сервис выходит из строя. Вы экономите их время. Иначе они потратили бы его на долгий поиск по форумам или вашему блогу.
4. Доверие — краеугольный камень перехода на модель SaaS (Software as a Service, программное обеспечение как услуга). Ваши клиенты ставят свой бизнес в зависимость от вашего сервиса или платформы. И текущим, и потенциальным клиентам нужна уверенность в вашем сервисе. Им нужно знать, что они не останутся без помощи, если у вас возникнут проблемы. Предоставлять информацию о форс-мажорах в режиме реального времени — лучший способ строить доверительные отношения. Больше вы не оставите клиентов в одиночестве без информации о текущей ситуации.
5. Всего лишь вопрос времени, когда же все серьезные SaaS-провайдеры начнут публиковать данные о работоспособности своих сервисов. Пользователи сами потребуют этого.
Назад: Призыв к действию. Заключение
Дальше: Дополнительная литература

